本文前置知识;
- BERT: 详见ELMo, GPT, BERT.
- Transformer: 详见Transformer精讲.
MASS: Masked Sequence to Sequence Pre-training for Language Generation
本文是论文MASS: Masked Sequence to Sequence Pre-training for Language Generation的阅读笔记和个人理解. 最近一个月在忙毕设相关, 所以有些论文看完还没有做笔记, 本文属于对这段时间没有写笔记的论文填坑之一.
Basic Idea
在Pre - training, Fine - tuning下的BERT是没有办法处理生成问题的, 而自回归的结构能较好的处理序列生成问题, 所以作者尝试继续将效果比较好的BERT重新迁移回Transformer的Seq2Seq框架下, 并能与Encoder - Decoder相兼容.
该模型与BART属于相同出发点的模型, 建议也学习一下BART.
MASS
Sequence to Sequence Learning
先来回顾一下标准的Seq2Seq训练过程.
在序列生成任务中, 输入输出为句子对$(x, y)\in(\mathcal{X},\mathcal{Y})$, $x$ 包含$m$ 个Token的源句子, 即$x=(x_1, x_2,\dots, x_m)$, $y$ 为包含$n$ 个Token的目标句子, 即$y=(y_1, y_2,\dots, y_n)$.
在Seq2Seq问题下, 目标为最大化模型参数$\theta$ 下的条件概率$P(y \mid x;\theta)$, 根据极大似然, 并结合语言模型中自回归的特性, 条件概率由链式法则能够被拆分, 目标函数为:
$$
\begin{aligned}
L(\theta ;(\mathcal{X}, \mathcal{Y}))&=\sum_{(x, y) \in(\mathcal{X}, \mathcal{Y})} \log P(y \mid x ; \theta)\\
&=\sum_{(x, y) \in(\mathcal{X}, \mathcal{Y})} \log \prod_{t=1}^{n} P\left(y_{t} \mid y_{<t}, x ; \theta\right)
\end{aligned}
$$
其中, $y_{<t}$ 为$t$ 时刻前自回归模型的输出.
一种最普遍的训练法为将Seq2Seq中Encoder的每个时刻隐态输出全部拿到, 然后用Attention机制在Decoder端对隐态输出加权解码.
Masked Sequence to Sequence Pre - Training
在MASS(MAsked Sequence to Sequence Pre - training for Language Generation)中, 不再采用句子对的方法训练模型, 而是采用去噪编码器的方式训练模型.
在Encoder端, 对于给定的Token数量为$m$ 的单句$x \in \mathcal{X}$, 假设连续地将位置$u \to v,(0<u<v<m)$ 上的Token打上Mask, 打上Mask后的部分记为$x^{\backslash u:v}$, 打Mask前的实际内容被记为$x^{u:v}$. 那么$k=v-u+1$ 就为一共打上Mask的数量.
在Decoder端, Decoder的目标为重构加噪的文本, 即预测出被Mask掉的内容, 由于Teacher Forcing, 训练时的Decoder的输入为移位后的$x^{u:v}$, 其余全为Mask.
标准Seq2Seq的目标函数在引入Mask后就应该被改写为:
$$
\begin{aligned}
L(\theta ; \mathcal{X}) &=\frac{1}{|\mathcal{X}|} \Sigma_{x \in \mathcal{X}} \log P\left(x^{u: v} \mid x^{\backslash u: v} ; \theta\right) \\
&=\frac{1}{|\mathcal{X}|} \Sigma_{x \in \mathcal{X}} \log \prod_{t=u}^{v} P\left(x_{t}^{u: v} \mid x_{<t}^{u: v}, x^{\backslash u: v} ; \theta\right)
\end{aligned}
$$
对于上述过程, 举出一个例子:
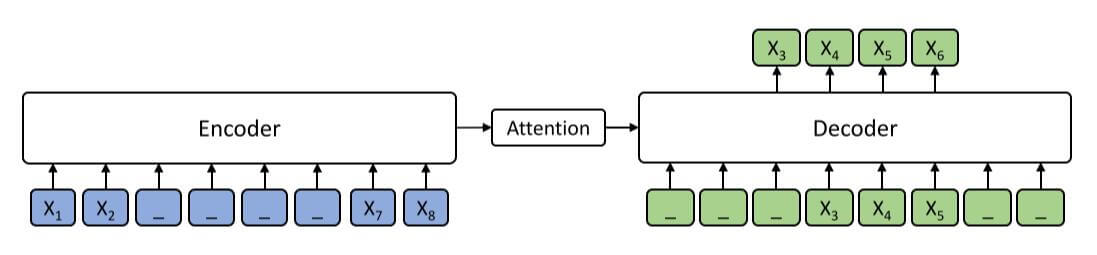
其中_代表[MASK].
我们将长度为$m=8$ 的句子中$x_3, x_4, x_5, x_6$ 连续地打上Mask, 在Decoder端, 除去Encoder中被Mask掉的$x_3, x_4, x_5$, 其余输入全部为Mask.
对于为何Decoder处将不需要被预测的Token都变成Mask, 作者的解释是这样能更好利用Encoder的编码, 结合Attention, 使得Encoder和Decoder更好的联合训练.
连续Mask的长度$k$ 为超参数. 作者巧妙地利用不同$k$ 的取值将BERT和GPT统一在了同一个框架中:
BERT:
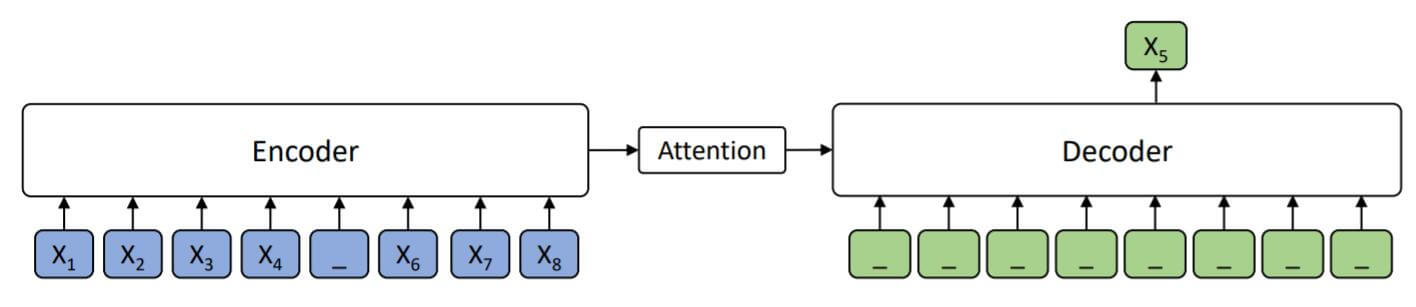
当$k=1$ 时, Decoder没有输入任何额外信息, 单纯利用Encoder的信息预测出被Mask掉的Token. 从双向利用上下文的角度来说, BERT是MASS的一种特殊情况.
GPT:
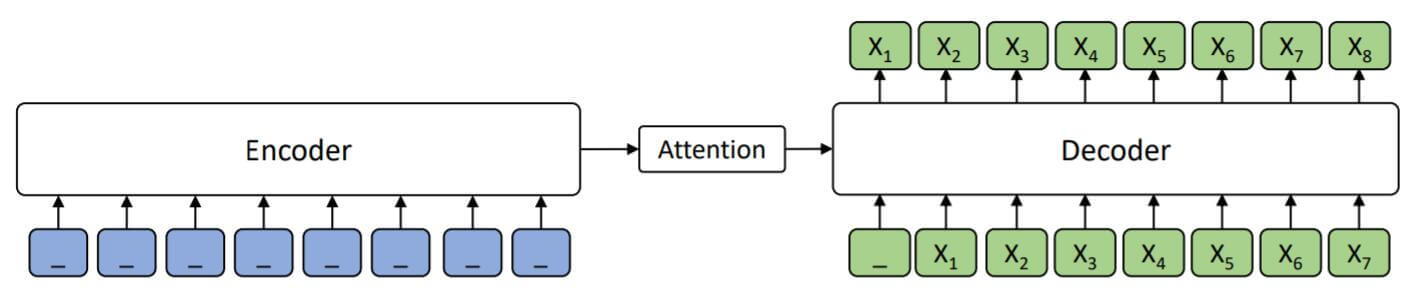
当$k=m$ 时, MASS直接就变成了自回归式的生成模型, 需要预测所有的Token. Encoder没有给Decoder任何信息.
MASS:
MASS便是介于BERT和GPT二者之间的, $k\in(1, m)$.

因此, MASS最大的特点也是在BERT和GPT之间做了一个折中, 以Mask的形式进一步将BERT和GPT的特点结合到同一个框架下.
Discussions
这部分作者简述了MASS的几个特点:
Encoder和Decoder联合训练. 在其他语言模型或BERT中都只是单独训练Encoder或Decoder.
这点是针对预训练来说的, MASS将问题转化为Seq2Seq后, 当然可以做到对于任何问题, 都用联合训练好的Encoder和Decoder解决.
连续的Mask能带给Encoder更好的NLU能力和Decoder更好的解码能力.
使Decoder能从Encoder获取更多的信息, 而不是获取Decoder自身生成的信息.
Experiments
详细的参数设置请参照原论文.
Neural Meachine Translation
无监督机器翻译上的BLEU得分如下:
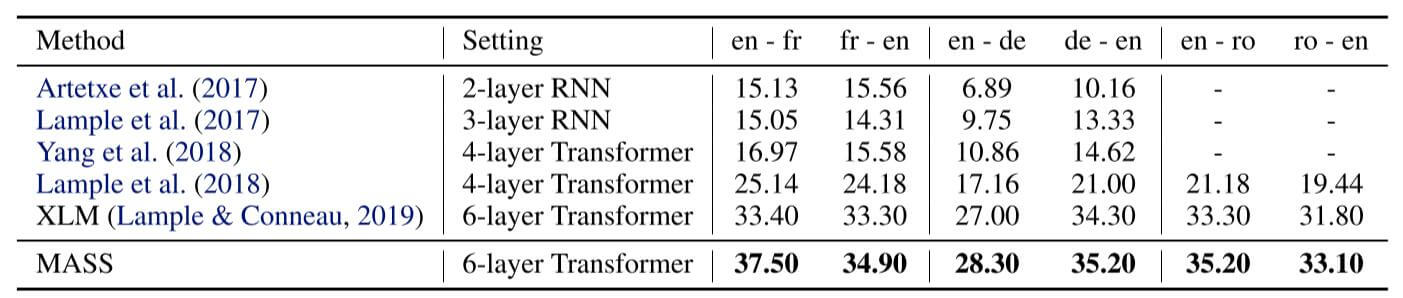
MASS在无监督机器翻译上表现还可以, 除了英语翻译到法语, 剩下的数据集基本上涨了一个点.
与其他预训练方法相比, 结果如下:
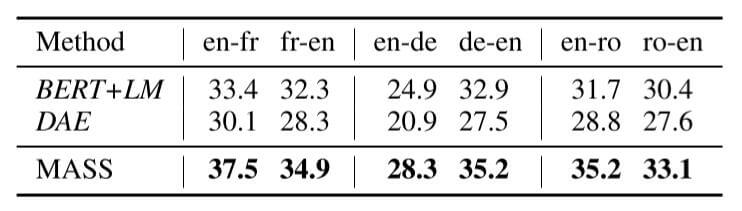
MASS比其他的预训练方法平均涨了3个点左右.
作者还展示了MASS在少资源状态下的机器翻译下的效果:
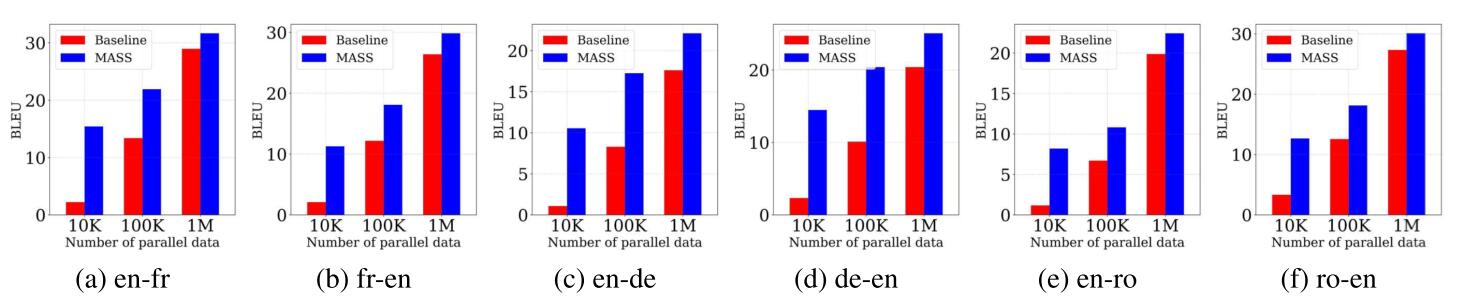
这个实验的Baseline选取还是拿没有预训练的模型和做过预训练的MASS去Fine Tuning后的结果进行比较… 自然是预训练后又微调的效果好. 所以少资源状态下的实验结果和结论都没有说服力, 在下一小节中的低资源实验也是类似的情况, 不再特意说明.
Text Summarization
文本摘要任务上的结果如下:
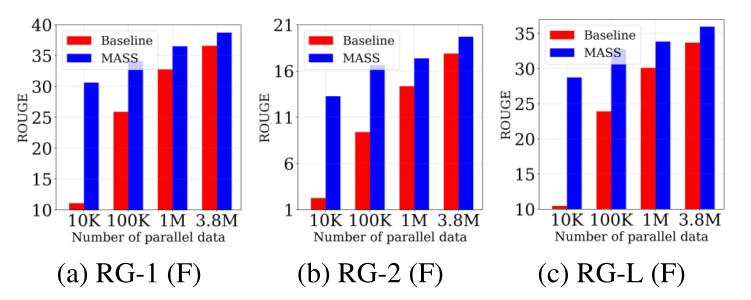
在高资源状态下, 相较于Baseline, 效果有一些提升, 但似乎没有很大.
与其他的预训练方法比较结果如下:
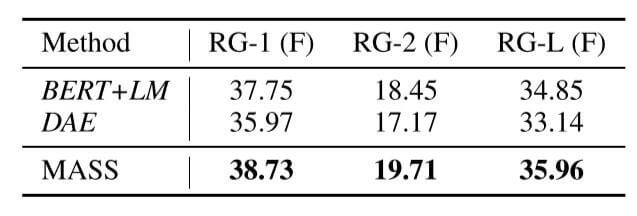
MASS结果有些许提升.
Conversational Response Generation
对话生成任务的PPL如下:
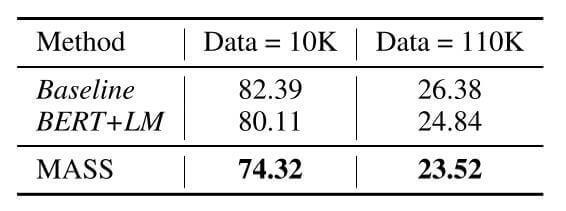
与BERT相比, MASS的PPL低了很多.
Analysis of MASS
Study of Different k
作者探究了$k$ 值的设定对各类任务性能的影响:
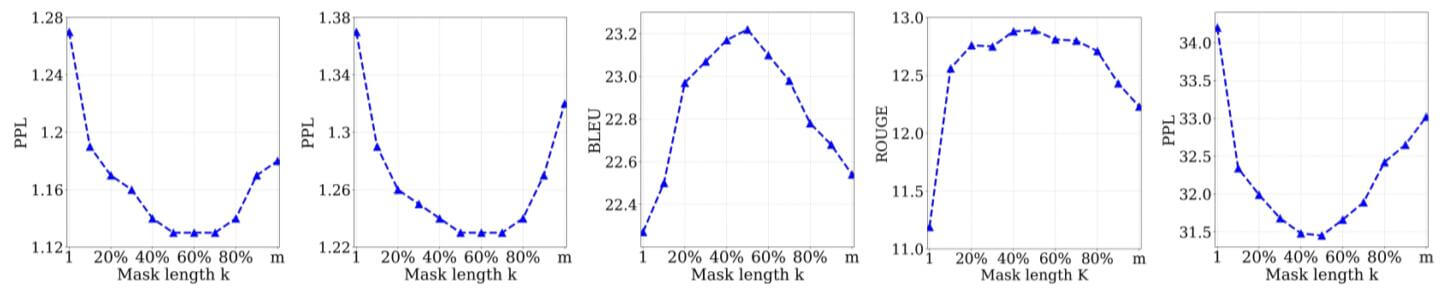
非常神奇的是所有任务几乎都在为$k=50\% \ast m$ 效果最好.
Ablation Study of MASS
作者对MASS的改动做了消融实验:
- 将MASS的连续Mask方式改为离散, 记为Discrete.
- 将Decoder输入的Token不再打Mask, 记为Feed.
在en - fr上的无监督机器翻译结果如下:

MASS的这两个改动确实有性能提升, 但似乎没有特别大的变化.
Summary
MASS与BART属于相同类型的模型, 二者处理思路都是重新把BERT拉回到Seq2Seq框架下做生成任务. 这二者的侧重点不同, MASS更侧重对Decoder的改进, 而BART更侧重对加噪方法做出调整.
从实验结果来看, MASS的性能提升并没有很大, 似乎其有效性也受到争议, 主要原因是实验设计说服力不够.

