2020.10.05: 更新训练技巧.
2020.09.27: 更新Masked Multi - Head Attention理解.
2021.06.08: 更新Teacher Forcing.
2024.09.17: 更新了LN的描述.
2025.02.10: 这篇博客已经好几年了, 甚至还是在我初学的时候写的. 在全文多处添加了一些描述, 并修正了一些错误.
Transformer
Transformer (擎天柱/变形金刚), 是一个基于Attention和SeqSeq的模型, 完全摆脱了CNN和RNN, 整个模型单单只由自注意力和前馈神经网络组成. 该模型出自Attention Is All You Need, 作者探究了Attention机制真正发挥的作用. Transformer在机器翻译等领域取得了革命性的成果, 并且由它衍生了很多在NLP方面的模型, 比如NLP现在通用的模型Bert家族, 以后也会详细研究一下.
本文的图片大多数来自原论文和The Illustrated Transformer这篇博客, 该文很清楚的解释了Transformer中原文的每一个细节, 图片简洁明了, 强烈推荐阅读.
模型结构
在原文中, 作者先在介绍Transformer的细节前抛出了Transformer的大致结构:
如果抛去所有的细节不谈, 能够清晰的看出作者使用了Seq2Seq作为模型的基本结构, 左侧输入为Encoder部分, 右侧输出部分为Decoder, 在Decoder输出后, 用一个加以Softmax的神经层来分类.
在每个Encoder和Decoder之间, 还有Attention 相连接,
这种结构天生就非常适合机器翻译, 如果我们把分类结果与词进行转换, 从高阶的视角来看, 那么结果就是一个机器翻译的Pipeline:
实现细节
不要忘记论文中给出的大致结构, 下面一步步剖析细节如何实现.
Word Embedding
在NLP中, 常将单词词编码为Embedding, 即将每个单词通过查表的方式映射成向量, 以此输入到模型中. 在DL中普遍用Word Embedding做词语向量化.
对Encoder进行输入(Inputs)和对Decoder进行输入(Outputs)时用到了Embedding, 论文中使用到的$d_{model}=512$, 并且在Encoder和Decoder的Embedding共享相同参数.
在NLP中, 直接以整个单词作为最小单位(Token)记录它们的Embedding的话, 会极大地增加词表的大小, 导致单词内部的细信息不能被重复利用, 如英文中的词根, 词缀等许多都含有共性. 所以Transformer使用的词表并非是原始单词, 而是经过BPE(byte-pair encoding) 处理后的”子词”(Sub-word), 但为了方便理解, 本文中还是以”单词”作为Token的描述.
Seq2Seq
其实在大致模型结构中已经提到了, Transformer可以看做是一个许多Encoder组成的编码组件和一个许多Decoder组成的解码组件构成的.
在论文中, 编码组件和解码组件的数量等同, 并且假设$N=6$, 即有6个编码器和6个解码器. 作者在后文中还尝试了取2, 4, 8, 但效果上来说没有6好.
Encoder作用就是用来编码整个输入的序列, Decoder的作用是对Encoder的序列编码进行解码.
因此, 只需要将最后一层Encoder的输出统一提供给每个Decoder, 并不需要将每个Encoder的隐藏状态都提供给每个Decoder.
Encoder
每个Encoder由一个自注意力层(Self - Attention)和一个前馈神经网络层(FFN)组成, 后面会提到它们是如何实现的.
我并不认为这张图做的很好, 因为在右侧的箭头是具有歧义性的, 容易让人认为每层的Encoder都与Decoder有连接, 实际上只有最后一个Encoder和所有的Decoder有连接.
如果将Embedding并添加位置编码后的输入向量设为$x_i$, 经过Self - Attention层的输出设为$z_i$, Encoder目前的向量流如下所示:
当然, 输出$r_i$ 会流入下个Encoder, 当做输入:
Decoder
每个Decoder除了有和Encoder相同的自注意力和前馈神经网络层, 还多了一个对Encoder的Encoder-Decoder Attention, 用来对Encoder编码的序列信息分配不同的权重.
同样, 本图也具有歧义性.
Self - Attention
自注意力是Transformer中提出的一种新结构, 也是核心组件. 这个注意力并非Decoder对所有Encoder的隐藏状态的不同注意力, 而是自身对自身的注意力, 在做语义编码时使得单词在编码时能够根据上下文找到自己的真正含义. 自注意力将注意力采用Q-K-V模式, 即Query, Key, Value. 用不同的矩阵与Embedding输入$x_i$ 做矩阵乘, 就能分别得到对应的$q_i$, $k_i$, $v_i$, 而矩阵是随机初始化得来的, 之后通过学习调整参数. 至于QKV是定义的, 请参考<Seq2Seq和Attention>.
为什么叫Self - Attention呢? 假设我们在执行机器翻译任务, 这个Attention不再是作用于我们给出的一种语言的输入Source和目标语言的输出Target, 而是作用于Source和Source内部, 即源语言的语义编码与原始输入Source之间的Attention, 这样能够获得单词在句子中更好的表示, 也称为”QKV”同源. 如果不好理解这个概念, 结合后文中提到的Cross - Attention就会明白.
这里注意一下维度, 在论文中的Embedding维度$d_{model}=512$, 给出的Key维度和Value维度均为64, 即$d_k=d_v=d_{model}/h=64$, 那么对应QKV的矩阵$W_Q$, $W_K$, $W_V$ 大小应该都是$(512, 64)$.
这样就能根据输入得到一个查询向量$q_i$, 一组键值对$<k_i, v_i>$.
有了QKV, 接下来需要按照Attention的流程计算$q_i$ 和$k_i$ 的Score, 根据论文中提到的缩放点积注意力(Scaled Dot-Product Attention):
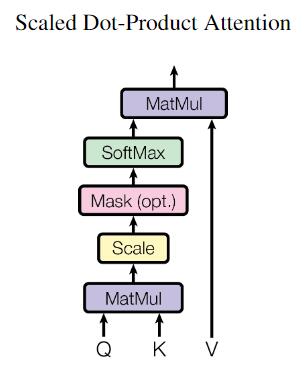
先进行点积, 再进行缩放, 计算完$q_i$ 与句中所有单词的$k$ 的得分(这里采用点积得到)后, 再对Score除以$\sqrt{d_k}$, 完成缩放, 最后再通过Softmax得到Attention权重, 加权求和结果称为$z_i$.
注意, 我们上面的讨论全部都是针对一个单词的, 但是在实际的运算中, 由于Encoder是线性Stack起来的, 所以其实Encoder的训练是可以并行的, 即多个单词做完Embedding后作为一个矩阵并行计算, 假设输入矩阵$X$, 通过$W_Q$, $W_K$, $W_V$ 计算后可以得到$Q$, $K$, $V$:
综上, 将自注意力总结为:
$$
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
$$![]()
这个公式其实在<Seq2Seq和Attention>一文中提到过, 但这里作者对Score使用了归一化, 即除以$\sqrt{d_k}$, $\sqrt{d_k}$ 为Key的维度. 这属于训练的一个Trick, 作者对此的解释如下:
We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by $\frac{1}{\sqrt{d_k}}$.
当$d_k$ 非常大时, 求得的内积可能会非常大, 如果不进行缩放, 不同的内积大小可能差异会非常大, Softmax在指数运算可能将梯度推到特别小, 导致梯度消失.
Multi - head Attention
Multi - head Attention的思路和CNN中的多个卷积核起到的作用明显是一致的. 所谓”多头”, 放在卷积神经网络里就是卷积层多个卷积核的特征提取过程, 在这里就是进行多次注意力的提取, 就像多个卷积核一样, 多次不同的初始化矩阵经过训练可能会有多种不同的特征, 更有利于不同角度的特征抽取和信息提取.
论文中用多个头求出多组的数据堆叠, 也就是图中的$h$ 维:
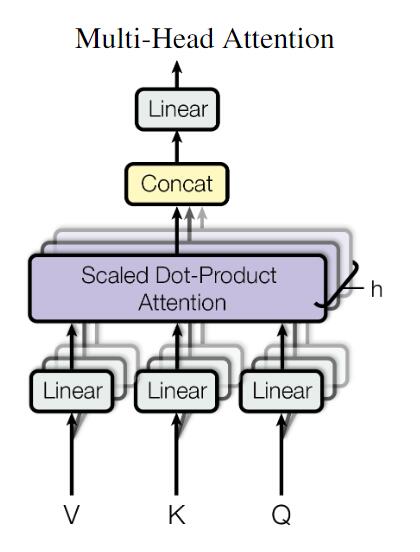
这样就能得到多个不同的Attention结果:
![]()
论文中采用了8个头的注意力, 即$h=8$, 得到多个提取出来的特征:
我们将所有Self - Attention提取的特征全部concat起来, 因为维度比较大, 所以要经过一个输出矩阵$W_O$, 对特征进行进一步压缩, 直到大小和Encoder接收的输入相同:
也就是说经过左侧的6个Encoder, 向量大小仍然不改变.
到现在总结一下Word Embedding以及Encoder的流程:
- 做Embedding和位置编码, 获得输入$X$.
- 通过多头获得多组对应的$Q$, $K$, $V$.
- 通过缩放点积注意力, 多个头分别加权求和求得$Z_i$.
- 将所有$Z_i$ 全部concat起来, 然后经过$W_O$ 的特征提取, 得到最终输出$Z$, 其大小与输入$X$ 是完全相同的.
图中的$R$ 代表除了最开始的Encoder, 其他Encoder都不需要Embedding, 用上一个Encoder的输出作为输入.
对每个头对句子不同部分的注意力进行可视化, 能发现每个头的注意力都在不同的位置上, 作用确实类似于CNN的卷积核, 做到了不同的注意力表示:
Encoder Side
Position-wise Feed Forward neural network
前馈神经网络就是结构中提到的Feed Forward neural network. 当然不单单是一个全连接层, 这里还用到了ReLu作为激活函数, 并且加上了Layer Normalization:
$$
\operatorname{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}
$$
但这里值得说明的是, 在论文中有这样一段:
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
所以FFN本身也可以表示为2个一维的$1\times1$的卷积, 这二者是等价的.
对于并行计算的不同单词, 通过的FFN参数是共享的, 也可以看做不同单词先后通过同一个FFN, 如下图所示:
这也就是为什么我前面要说FFN能够看做是一维卷积, 因为它们对每个单词独立的运算.
并且在经过每个Encoder Layer后, 都不改变数据的大小.
Layer Norm
你应该接触过Batch Norm, Layer Norm也是一种类似于Batch Norm的归一化方式, 同样能起到加快收敛的作用, 在NLP任务中比较常用.
Batch Norm中, 记录下多个Batch中每个Channel在该Batch内和该Batch内所有特征图上计算得到的均值和方差, 最后再进行放缩和平移, 达到每个通道的特征是相互独立的. 这么说可能有点绕, 例如, 对于输入大小为$(N, C, H, W)$ 的图像, 通过BN可以得到大小为$C$ 的均值以及方差, 即大小为$C$ 的均值方差由同个Batch维$N$ 以及特征图大小$H \times W$ 同时求得:
$$
\begin{aligned}
\mu_c &= \frac{1}{NHW} \sum_{i=1}^N\sum_{j=1}^H\sum_{k=1}^W x_{i,c,j,k} \\
\sigma^2_c &= \frac{1}{NHW} \sum_{i=1}^N\sum_{j=1}^H\sum_{k=1}^W (x_{i,c,j,k} - \mu_c)^2
\end{aligned}
$$
Layer Norm是针对整个样本的归一化. 在Layer Norm中, 我们对同一个样本内不同特征进行归一化. 同样的, 对于输入大小为$(N, C, H, W)$ 的图像, LN计算的是所有Channel $C$ 和所有特征图$H \times W$ 尺度下大小为$N$ 的均值和方差:
$$
\begin{aligned}
\mu_n &= \frac{1}{CHW} \sum_{i=1}^C\sum_{j=1}^H\sum_{k=1}^W x_{n,c,j,k} \\
\sigma^2_n &= \frac{1}{CHW} \sum_{i=1}^C\sum_{j=1}^H\sum_{k=1}^W (x_{n,i,j,k} - \mu_n)^2
\end{aligned}
$$
下面这张图非常清晰:
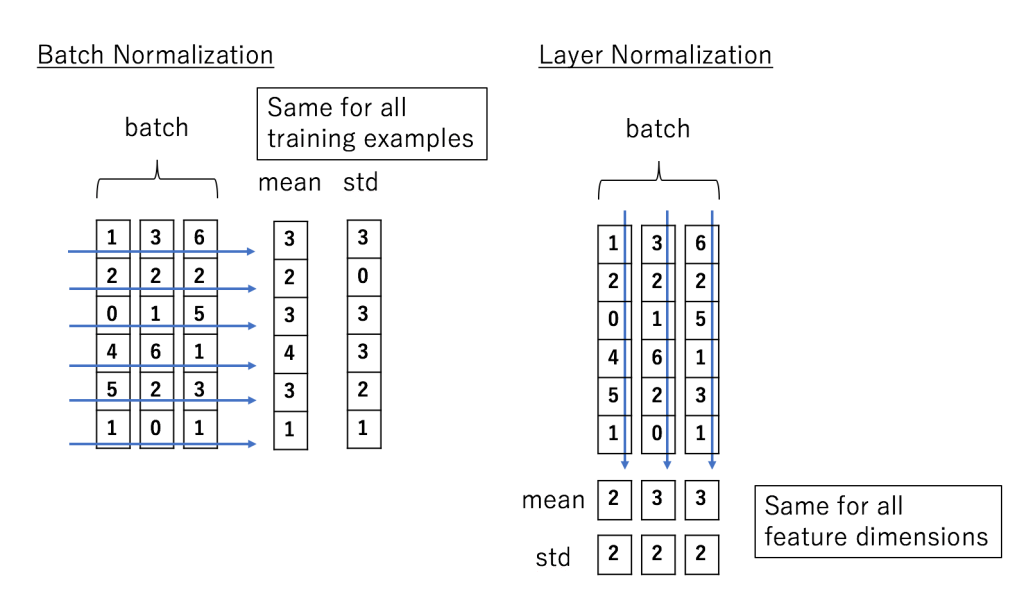
在CV中, 整个样本是$(N, C, H, W)$ 的整张图片. 有趣的是, 在NLP中, Layer Norm却指的是对每个Token表示做的归一化. 与其说它是Layer Norm, 不如说它其实是Instance Norm.
LN与Batch无关, 故对于Hidden Size为$m$ 的句子, NLP任务中的Layer Norm实际上是:
$$
\begin{aligned}
\mu_{j}&=\frac{1}{m} \sum_{i=1}^{m} x_{i j} \\
\sigma_{j}^{2}&=\frac{1}{m} \sum_{i=1}^{m}\left(x_{i j}-\mu_{j}\right)^{2}
\end{aligned}
$$
引入$\epsilon$ 做平滑, 使分母不为0:
$$
\text {LayerNorm}(x)=\frac{x_{i j}-\mu_{j}}{\sqrt{\sigma_{j}^{2}+\epsilon}}
$$
跟Batch Norm一样, 之后也进行平移($\beta$)和放缩($\gamma$)两个可学习参数, 用于增强模型的表达能力:
$$
y = \text{LayerNorm}(x) \cdot \gamma + \beta
$$
如果想了解它为什么和NLP领域比较契合, 详见下文:
- 模型优化之Layer Normalization
- NLP中 batch normalization与 layer normalization
- transformer 为什么使用 layer normalization, 而不是其他的归一化方法?
- 原论文Layer Normalization
大致原因是Batch Norm 对于Embedding后的数据进行归一化, 假设每个Batch是由多个Embedding组成的, 按照Batch方向对每个归一化, 就是对每个词的Embedding整体归一化. 这样做非常没有道理, 不符合NLP的规律, 它反而加强了不同词之间的相关性.
但如果按照Layer Norm, 按照Layer方向, 实际上是分别对每个Embedding后的词向量进行归一化, 这样每个词向量相对独立.
这主要还是CV和NLP的数据属性决定的. 在CV中, 不同样本之间的Channel信息是具有共性的(因为图像还是要用2D来表示), 这部分信息非常重要, 如果归一化会损失很多信息. 而NLP中, 数据是Embedding来的, 本来也没有包含位置信息, 反而不同词向量之间毫无相关性, 关注单词本身的归一化效果会更好.
Residual
残差连接从ResNet中提出也有一定年头了, 作为近些年使用频次比较高效果比较好的结构, 原理不再多赘述了, 在<卷积神经网络小结>和<卷积神经网络发展史>中都有对残差连接的详解.
在Encoder中残差连接伴随着Layer Norm, 每次经过一个子层都要做一次残差连接.
在Decoder中也是同样的, 每次经过子层也都要做残差连接.
Decoder Side
当了解了Encoder的结构后, 结合起Decoder来看一下信息流.
假设只有两个Encoder和两个Decoder的堆叠, 那么信息的流动方向是这样的:
确实只有最后的Encoder将输出传递给了Decoder的Encoder - Decoder Attention. Encoder的输出也是和Decoder唯一的交互途径, 它们通过Encoder - Decoder Attention进行交互(Cross - Attention). 整个Decoder的最终输出就是经过多个堆叠的Encoder计算得来的与Encoder输入大小相同的向量.
Encoder - Decoder Attention
Decoder中的Encoder - Decoder Attention和Encoder中的多头Self - Attention运算机制一致, 唯一不同的就是输入数据的来源.
其中, $Q$ 对应的输入来源于Decoder的Masked Self - Attention(即每个Decoder的Self - Attention层的输出), 而$K$ 和$V$ 对应的输入来源于整个Encoder的最终输出(图中Encoder上方的蓝色向量), 因此也称为”QKV”不同源. 根据这三个输入再结合Encoder - Decoder Attention层中的$W_Q$, $W_K$, $W_V$ 分别得到$Q$, $K$, $V$. 然后再根据缩放点积得到Attention Value.
对于多个经过Encoder的单词形成含有多个单词的矩阵, Decoder是在这一环节实现翻译时对不同单词的Attention的.
注: 下面两张动图比较大, 挂在github上了, 如果没挂梯子可能无法正常显示,
Outputs
因为采用了Seq2Seq的架构, Decoder每过一个时间步不光接受Encoder的输出, 还要重新以上一个Timestep的Decoder输出作为输入, 即论文中提到的”shifted right“. 这种依赖上一时刻的输出作为输入的方式也被称为自回归范式.
Masked Multi - Head Attention
Mask是Transformer中一个关键点. Masked Multi - Head Attention 只出现在Decoder中. 到了Decoder, 可就不再像Encoder那样直接把数据拿过来并行训练了, 如果也像Encoder那样把所有输入的词向量全一股脑堆进去, Decoder做Self - Attention可以无视解码的时间跨度, 获知全部的信息, 因此需要用Mask将当前预测的单词和之后的单词全都遮盖, 否则就没法训练了.
若仍然沿用传统Seq2Seq+RNN的思路, Decoder是一个顺序操作的结构, 我们代入一个场景来看看. 假设我们要执行机器翻译任务, 要将我 是 大宁翻译为I am DaNing, 假设所有参数与论文中提到的参数一样, batch size视为1. 根据前面已知的知识, Encoder堆叠后的输入和Embedding的大小是相同的, 在这里有三个词语, Embedding且通过Encoder后的编码大小为$(3, 512)$. 下面对Decoder进行训练:
- 将起始符
<start>作为初始Decoder输入, 经过Decoder处理和分类得到输出I. - 将
<start> I作为Decoder输入, 经过Decoder处理和分类得到输出am. - 将
<start> I am作为Decoder输入, 经过Decoder处理和分类得到输出DaNing. - 将
<start> I am DaNing作为Decoder输入, 经过Decoder处理和分类得到结束符<end>.
上面提到过, 这种依赖上一时刻的输出作为输入的方式也被称为自回归.
参考将RNN更改为Self - Attention的Encoder思路, 对于这种依赖于前一个时间步预测结果的结构Decoder, 如果想做到并行训练, 需要将上面的过程转化为一个这样的矩阵直接作为Decoder的输入:
$$
\begin{bmatrix}
\text{<start>}& & & \\
\text{<start>}& \text{I} & & \\
\text{<start>}& \text{I} & \text{am} & \\
\text{<start>}& \text{I} & \text{am} & \text{DaNing}
\end{bmatrix}
$$
因为在训练时已知任务标签(即已知翻译的双语平行语料), 所以可以不管Decoder每时间步预测的是什么, 直接将目标语言的语料作为Decoder的整个输入序列.
这种方法被称为Teacher Forcing, 仅在训练阶段使用, 而不能使用在推断过程, 我会在下一节训练技巧中讲讲.
并行训练虽然快了, 但是必须做一些小的处理, 使得Transformer的并行训练与训练好后的推理阶段是一致的, 例如对当前时间步后的输入打Mask.
图片取自Transformer 详解.
在论文的图中, Mask操作顺序被放在$Q$ 和$K$ 计算并缩放后, Softmax计算前. 如果继续计算下去, 不做Mask, 与$V$ 相乘后得到Attention, 所有时间步信息全部都被泄露给Decoder, 必须用Mask将当前预测的单词信息和之后的单词信息全部遮住.
遮住的方法非常简单, 首先不能使用0进行遮盖, 因为Softmax中用零填充会产生错误, $e^0=1$. 所以必须要用$-\infty$来填充那些不能被看见的部分. 我们直接生成一个下三角全为0, 上三角全部为负无穷的矩阵, 与原数据相加就能完成遮盖的效果:
做Softmax时, 所有的负无穷全变成了0, 不再干扰计算:
其实Mask在对句子的无效部分填充时, 也是用同样方法将所有句子补齐, 无效部分用负无穷填充的.
强调: Decoder仍然依赖与先前输出结果作为输入, 所以在正式使用时不能实现并行预测, 但在训练的时结果是已知的, 可以实现并行训练.
Positional Encoding
最后来谈谈位置编码. 因为Transformer采用了纯粹的Attention结构, 不像RNN一样能够通过时间步来反映句子中单词的前后关系, 即不能得知单词的位置信息. 这使得相同的单词被输入到模型时, Transformer并不能区分, 因为它们的Word Embedding是完全一样的. 所以必须让模型知道位置信息保证位于不同位置的相同单词是可区分的, 这点非常重要. 而且, 在NLP任务中, 语序是一个相当重要的属性, 位于文档前面的单词和位于文档后面的单词可能会有不同的含义或比重.
作者通过位置编码在每次进入Encoder和Decoder前将位置信息写入. 这样来看, 与其叫位置编码, 不如叫位置嵌入. 位置编码可以直接与Embedding的向量相加:
作者的做法非常有意思, 对不同的单词位置, 不同的Embedding维度, 它的编码都是唯一的, 应用正弦和余弦函数也方便Transformer学到位置的特征. 如果将当前单词位置记为$pos$, 而词向量的某个维度记为$i$, 那么位置编码的方法为:
$$
\begin{aligned}
P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \\
P E_{(p o s, 2 i+1)} &=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right)
\end{aligned}
$$
计算出来的结果应该是这样的:
如果上面那组式子看起来有些乱, 写成这样或许好些:
$$
\begin{aligned}
P E_{(p o s, 2 i)} &=\sin \left(\frac{p o s}{10000^\frac{2 i}{d_{\text {model }}}}\right) \\
P E_{(p o s, 2 i+1)} &=\cos \left(\frac{p o s}{10000^\frac{2 i}{d_{\text {model }}}}\right)
\end{aligned}
$$
如果按照论文中的设定$d_{model}=512$, 由于奇偶数的计算方式是不同的, 所以$i \in[0, 255]$.
在这个式子中, 编码周期不受单词位置$pos$ 影响, 仅仅与模型开始设计的$d_{model}$ 和Embedding的不同维度$i$ 相关. 对于不同的$i$, $PE$ 的周期是$[2\pi, 10000\cdot2\pi]$.
这样看, 同一位置上的词语, 对于不同的Embedding维度, 都得到不同的编码, 并且随着$i$ 的增大, 位置编码的值的变化就越来越慢. 这种编码对于不同维度的Embedding来说是唯一的, 因此模型能够学习到关于Embedding的位置信息.
下面这个热图非常直观, 分开来看. 对于相同的Position的词语, 它不同维度的Embedding往往具有不同周期而交错的$\sin$ 和$\cos$ 组合, 而对于Embedding的同一个维度和不同Position的单词, 在Position上呈现出周期性.

同样, 用折线图表示不同位置和编码后值的关系:
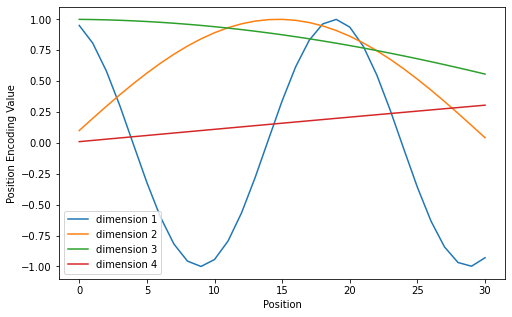
起初, 我并不知道为什么这种方法Work. 在看过浅谈 Transformer-based 模型中的位置表示后, 感觉似乎有些道理. 作者意在利用正弦余弦的数学性质(周期性, 和角公式), 使得偏移了的一定position, 记为$k$ , 能够得到正弦余弦的不同线性组合(总感觉这种编码在通信的某个地方应该很常用, 只是DL第一次用而已).
三角函数性质:
$$
\left\{\begin{array}{l}
\sin (\alpha+\beta)=\sin \alpha \cos \beta+\cos \alpha \sin \beta \\
\cos (\alpha+\beta)=\cos \alpha \cos \beta-\sin \alpha \sin \beta
\end{array}\right.
$$
得到偏移后, 即$pos+k$ 的$PE$:
$$
\left\{\begin{array}{l}
PE(pos+k, 2i)=PE(pos, 2i) \times PE(k, 2i+1)+PE(pos, 2i+1) \times PE(k, 2i) \\
PE(pos+k, 2i+1)=PE(pos, 2i+1) \times PE(k, 2i+1)-PE(pos, 2i) \times PE(k, 2i)
\end{array}
\right.
$$
除了公式计算, 作者也实验了其他对于位置编码的方式, 比如通过训练得到, 但由于实际效果与计算得来相仿, 那么还不如通过公式计算直接得到位置编码.
Final Output
最终输出很简单, 根据Decoder的输出经过FC层和Softmax得到对应的单词.
注意, Decoder的Embedding层和最后输出经过Softmax前的Linear层也是共享权重的.
训练技巧
让Transformer跑的起来离不开下面说的这些训练技巧.
WarmUp
在原文中, Optimizer使用Adam, 除了设置参数$\beta_1 = 0.9$, $\beta_2 = 0.98$, $\epsilon=10^{-9}$外, 还设置了Warmup:
$$
\text {lrate}=d_{\text {model }}^{-0.5} \cdot \min \left(\text {step}_{-} \text {num}^{-0.5}, \text {step_num} \cdot \text {warmup_steps}^{-1.5}\right)
$$
我按照step增长, 做出WarmUp对应的learning rate变化图:
在开始时学习率大, 然后逐渐变小. 对于越大的$d_{model}$ 来说, 初始的斜率越小. 论文中设置$\text{warmup_step}=4000$. 许多后续的模型也用到了WarmUp.
Label Smoothing
在<卷积神经网络发展史>中提到过, 这里再重复一下. 标签平滑可以看做是一种添加到损失公式中的一种正规化组件, 因为独热编码后的标签只有0和1, 可能有些过于绝对, 标签平滑提供了一种手段来使其中的0也能分配到一些数值. 假设输入为$x$, 一共需要对$c$ 个类进行划分, 则标签平滑后的结果$y\prime$ 为:
$$
y\prime = (1 - \epsilon) \cdot x + \frac{\epsilon}{c}
$$
直接贴代码, Show you my code!
a = torch.tensor([0, 0, 1.])
b = torch.tensor([0, 1.])
# input_tensor is a tensor in pytorch
def label_smoothing(input_tensor, epsilon=0.1):
classes = input_tensor.shape[-1] # compute the number of classes
return (1 - epsilon) * input_tensor + (epsilon / classes)
print('label_smoothing(a):', label_smoothing(a))
print('label_smoothing(b):', label_smoothing(b))
"""
label_smoothing(a): tensor([0.0333, 0.0333, 0.9333])
label_smoothing(b): tensor([0.0500, 0.9500])
"""在论文中设置$\epsilon_{ls}=0.1$. 标签平滑可能会提高句子的困惑度, 因为添加了更多的不确定性, 但会提高准确率和BLEU.
Residual Dropout
在进行残差连接时, 每个子层进行add和batch norm之前, 都添加了Dropout. 原论文中设置$P_{\text {drop}}=0.1$, 个人认为Dropout没有前两种技巧作用大.
Teacher Forcing
在模型的训练阶段, Decoder的所有正确输入是完全已知的, 如果自回归预测在某个时间步$t$ 解码出错, 则会导致$t$ 时刻后所有的预测结果都产生偏差.
Teacher Forcing通过将自回归模型解码过程中的所有输入强制修正为Ground Truth来避免了这个问题.
Teacher Forcing有诸多优点:
- 解决了训练阶段自回归式模型的串行问题, 能够使得模型训练时并行.
- 避免了模型训练时预测一步错步步皆错的问题.
- 由于干涉了训练错误的情况, 加快了模型的收敛速度.
但它也同时容易产生矫枉过正的问题:
- Exposure Bias: 这是最为常见的问题. 在训练时因为受到干涉, 很容易产生训练推断不一致.
- Overcorrect: 有时候模型解码有自己的想法, 但因为Teacher Forcing的干涉, 导致生成的句子四不像.
- No diversity: Teacher Forcing对Ground Truth的约束是非常强的, 模型的多样性受到严重限制.
Teacher Forcing的衍生问题, 请阅读关于Teacher Forcing 和Exposure Bias的碎碎念.
其他问题
摘自牛客网: NLPer看过来, 一些关于Transformer的问题整理.
不过以目前的眼光来看, 这些问题都已经过时了. 现在的Seq2Seq的概念是一种范式, 而不是以前的RNN-Attention.
Transformer相比于RNN/LSTM, 有什么优势? 为什么?
- RNN系列的模型并行计算能力很差.
- Transformer的特征抽取能力比RNN系列的模型要好(实验结论).
为什么说Transformer可以代替RNN-seq2seq?
这里用代替这个词略显不妥当, RNN-seq2seq虽已老, 但始终还是有其用武之地, seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中, 并将其作为Decoder端首个隐藏状态的输入, 来预测Decoder端第一个单词(token)的隐藏状态. 在输入序列比较长的时候, 这样做显然会损失Encoder端的很多信息, 而且这样一股脑的把该固定向量送入Decoder端, Decoder端不能够关注到其想要关注的信息.
上述两点都是RNN-seq2seq模型的缺点, 后续论文对这两点有所改进, 如著名的Neural Machine Translation by Jointly Learning to Align and Translate, 虽然确确实实对RNN-seq2seq模型有了实质性的改进, 但是由于主体模型仍然为RNN(LSTM)系列的模型, 因此模型的并行能力还是受限, 而transformer不但对RNN-seq2seq模型这两点缺点有了实质性的改进(多头交互式attention模块), 而且还引入了self-attention模块, 让源序列和目标序列首先”自关联”起来, 这样的话, 源序列和目标序列自身的embedding表示所蕴含的信息更加丰富, 而且后续的FFN层也增强了模型的表达能力(ACL 2018会议上有论文对Self-Attention和FFN等模块都有实验分析, 见论文: How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures), 并且Transformer并行计算的能力是远远超过seq2seq系列的模型, 因此我认为这是transformer优于RNN-seq2seq模型的地方.
Transformer中句子的encoder表示是什么?如何加入词序信息的?
Transformer Encoder端得到的是整个输入序列的encoding表示, 其中最重要的是经过了self-attention模块, 让输入序列的表达更加丰富, 而加入词序信息是使用不同频率的正弦和余弦函数.

