本文前置知识:
Transformer: 详见Transformer精讲.
BERT, GPT: 详见ELMo, GPT, BERT.
BART和mBART
本文是如下论文的阅读笔记和个人理解:
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Multilingual Denoising Pre-training for Neural Machine Translation
BART
Basic Idea
Transformer浑身都是宝, 相较于直接延续Transformer的Seq2Seq架构, 更广为使用的是把Encoder和Decoder的单独堆叠, 分别对应着只使用Encoder的BERT和只使用Decoder的GPT. 如果只是单纯的使用其中的某一部分, 就会造成两个鸿沟:
BERT: 具备双向语言理解能力的却不具备做生成任务的能力.
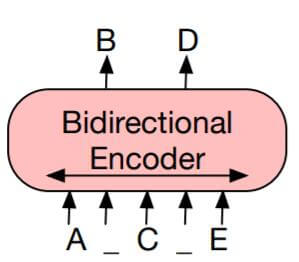
GPT: 拥有自回归特性的却不能更好的从双向理解语言.
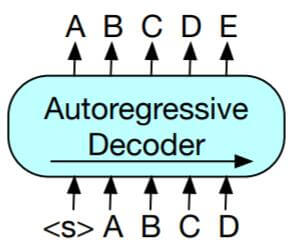
因此, 作者希望将二者融合, 让模型保留双向语言理解能力的同时, 也能解决生成任务.
BART Model
BART(Bidirectional and Auto - Regressive Transformers)的结构非常的简单, 既然只使用Encoder或者只使用Decoder不能让鱼和熊掌兼得, 那就重新把它们组装回来:
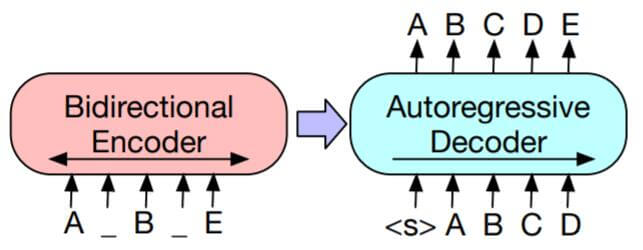
左侧为BERT(Transformer Encoder), 右侧为GPT(Transformer Decoder).
所以BART采用的其实还是标准Transformer结构, 如果把Encoder和Decoder组装回来, 就又成了标准Transformer:
但是, BART所采用的输入数据和训练目标和Transformer完全不一样, 换句话说, 作者希望BART所做的事情和Transformer是完全不一样的, 这也是BART与Transformer的最大区别.
作者指出, BART和BERT有两点最大的 不同:
- 除了对Encoder的堆叠外, 还使用了Decoder, 并添加了Encoder和Decoder之间的Cross Attention(其实就是结构和标准Transformer一样).
- BERT在预测时加了额外的FFN, 而BART没使用FFN. 整体来说, 包含了Decoder的BART只是比同级别的BERT多了10%的参数.
Pre - Training BART
BART使用的是类似BERT的Denoising AutoEncoder的形式来训练的, 即模型需要对被添加噪声的数据去噪, 恢复出原始数据.
我猜测, 之所以BART名字是仿照BERT, 而不是仿照Transformer最大原因, 是因为BERT和BART都是去噪自编码器, 而Transformer不是.
BART允许对原始数据做任意形式的噪声干扰, 作者提出了五种可行的添加噪声的方式:
- Token Masking: 与BERT打
[Mask]的策略完全相同. - Token Deletion: 直接随机删除某些Token.
- Text Infilling: 同时选中多个连续的Token, 仅替换成一个
[Mask], 或者在原始数据中随机插入Mask Token(即使没有数据缺失). 模型不知道[Mask]对应的是多少个Token, 也不知道[Mask]是否有效. 这就要求模型有强大的学习能力. - Sentence Permutation: 将一个文档中的句子之间的顺序打乱.
- Document Rotation: 从文档中随机选定一个Token作为整个文档的起始Token, 对文档Rotation. 该方法令模型能识别文档的起始Token.
上述五种方式的示例如下:
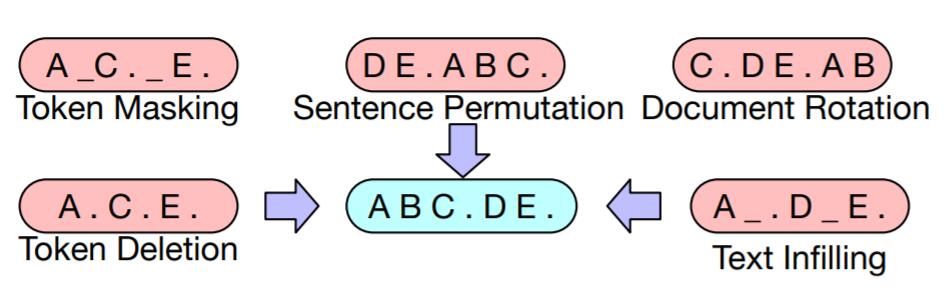
即使有Decoder, 也不需要让Encoder和Decoder对应的部分对齐. 在极端情况下, 所有的原始信息都丢失了, 此时BART相当于Language Model. BART添加噪声的方式不单包含了Token Masking, 还包含了更为复杂的噪声, 它们也可以互相组合. 想从这些噪声中按照原语序恢复出句子还是非常困难的, 因为它们包含了缺失, 乱序的情况.
在输入加噪的数据后, BART先通过Encoder双向编码, 再通过Decoder用自回归极大似然解码, 恢复出原始序列.
Fine - Tuning BART
BART在预训练后, 需要对下游任务微调. 对于不同的任务, BART有不同的使用方法:
Sequence Classification: 对序列分类任务, Encoder和Decoder以相同的数据输入, 利用Decoder的最后一次输出代表整个句子的表示, 类似于BERT中的
[CLS]. 只不过BART是有Decoder的, 所以需要让Decoder的输出作为整个句子的表示.Token Classification: 对于Token分类任务, Encoder和Decoder也以相同的数据输入, BART也将Decoder中所对应Token的输出作为分类的隐藏状态.
Sequence Generation: 对于序列生成任务, BART直接适应生成任务, 对Encoder和Decoder微调即可. 该类任务包括文本摘要, 问答等.
Machine Translation: 机器翻译任务比较特殊, 因为它的任务输入和输出是两种不同的语言.
结合先前在机器翻译上的研究, 额外添加一个专门用于外语映射的Encoder(例如其他语言映射到英语)将有助于模型性能的提升. 所以BART需要训练一个新的Encoder来将源语言与目标语言语义空间对齐, 来替代掉BART原来的Word Embedding, 在完成对齐后, BART将把源语言转换为目标语言, 与Transformer保持一致.
训练分为了两个阶段:
- 一阶段中, 对BART的大多数参数冻结, 只更新随机初始化的源语言Encoder, BART的位置编码, BART Encoder的第一层Self - Attention投影矩阵.
- 二阶段中, 对整个BART(包含后来添加的Encoder)中的所有参数做少次迭代.
对于上述四种任务的处理概括为下图:
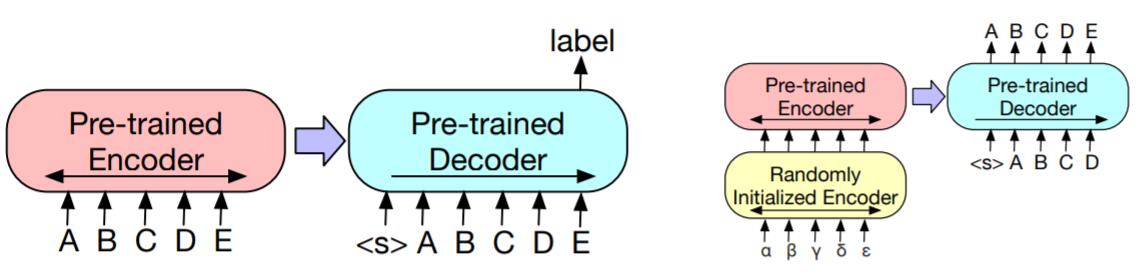
左侧为处理分类问题的示意图, 右侧为处理机器翻译的示意图.
Experiments
详细的实验设置请参照原论文.
Comparsion Pre - Training Objectives
作者做了各不同预训练目标的模型的效果对比, 这些模型并不是原始论文中的模型, 而是作者或多或少调整过的. 其中所使用的模型分别类似于:
- Language Model: GPT.
- Permuted Language Model: XLNet.
- Masked Language Mode: BERT.
- Multitask Masked Language Model: UniLM.
- Masked Seq - to - Seq: MASS.
实验结果如下:
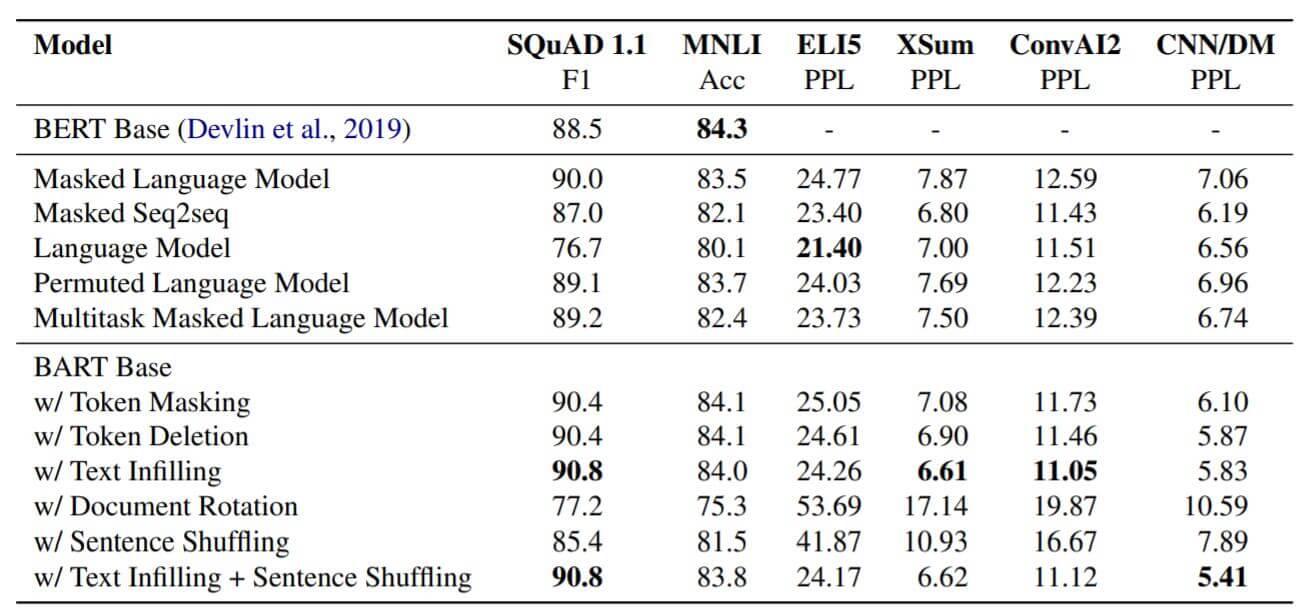
从实验中看到, 使用Text Infilling的效果非常好, 只使用Document Rotation和Sentence Shuffling的效果比较差. 并且, 预训练的有效性高度取决于任务, 自回归式的模型有利于解决生成类任务.
Discriminative Tasks
各类Large模型在SQuAD和GLUE上的结果如下:
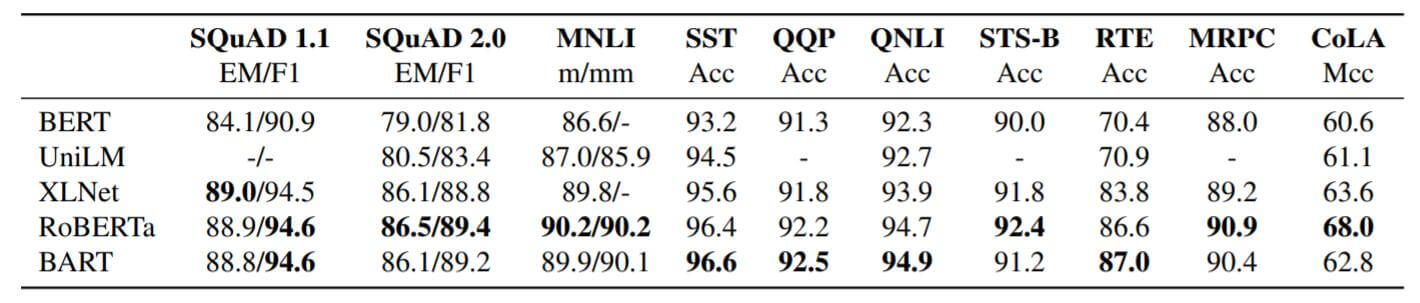
RoBERTa和BART的表现相似, 但是BART能够在不牺牲性能的情况下将任务扩展到生成任务上, 这对BART来说是一个独天得厚的优势, 因为扩展只带来了将近10%的参数量增长.
Generation Tasks
Summarization
在摘要任务上的实验结果如下:
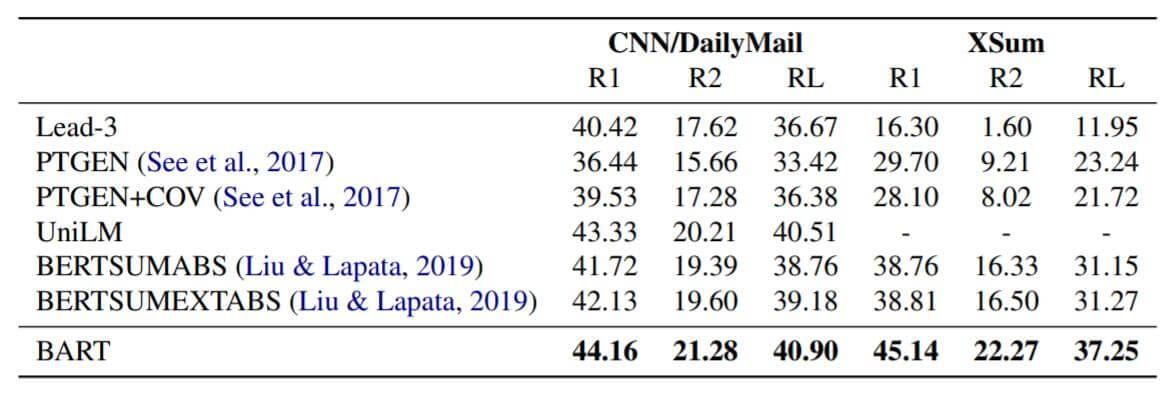
Dialogue
在对话任务上的结果如下:
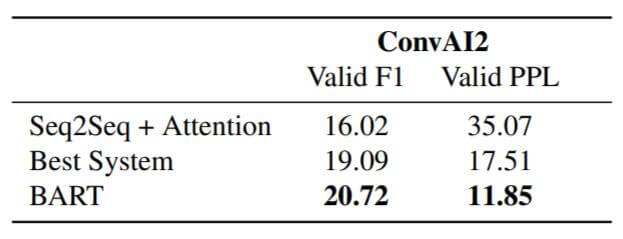
Abstractive QA
抽象问答数据集上结果如下:
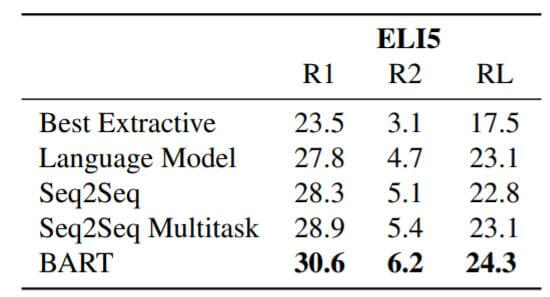
Machine Translation
在机器翻译任务上结果如下:
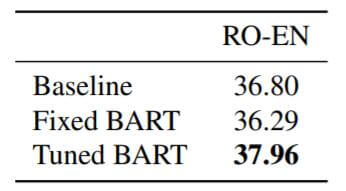
Baseline是标准Transformer. Fixed BART和Tuned BART分别代表单向翻译和使用反向翻译的BART. 没有反向翻译的BART效果不太好, 可能涉及到过拟合, 使用反向翻译后应该增强了泛化能力, 效果得到了改善.
反向翻译指的是, 将目标语言输入模型得到源语言的预测结果, 其中预测错误的内容将视为噪声, 将该预测结果再重新输入新的模型, 让它生成目标语言, 这是一种常见的文本数据增强方式.
mBART
但我不是MT方向的, 所以实验部分我只挑着看了比较关键的部分. 之所以把mBART也写在这篇文章中, 是因为mBART只是作为BART的多语言版本, 没有本质上的结构变化, 作者展示了一种基于BART处理机器翻译问题的方法, 比较有趣, 在本文中作为扩展内容.
mBART(Multilingual Bidirectional and Auto - Regressive Transformers)是BART的多语言版本, 用于处理不同语言之间的机器翻译问题.
mBART Model
mBART仍然是分为Pre - Training和Fine - Tuning两个阶段. Pre - Training将使用多个语种的语料作为预训练数据.
Pre - Training mBART
预训练阶段延续了BART的做法, 仍然采用Denoising AutoEncoder的方法令mBART的每条数据在单语言内训练. 目标是将单语言文本加噪干扰后再恢复回来. 作者采取了两种BART中的加噪方式:
- Sentence Permutation: 打乱句子和句子之间的顺序.
- Word - Span masking: 连续的Mask掉一些内容, 并且只用一个
[Mask]替换.
除此外, mBART的初衷是多语言模型, 必须将语种的信息加入. 在文本输入结束后, 在句子末尾处需要加上句子结尾标识<\s>和对应语言的标识[LID].
Fine - Tuning mBART
微调阶段才针对机器翻译任务训练. 用[LID]替换Decoder原来的第一个输入[Start], 表明要翻译成哪个语种.
Sentence Level MT和Document Level MT的主要区别就在于文本的长度不同, Document Level MT更困难一些.
上述方法概括为下图:
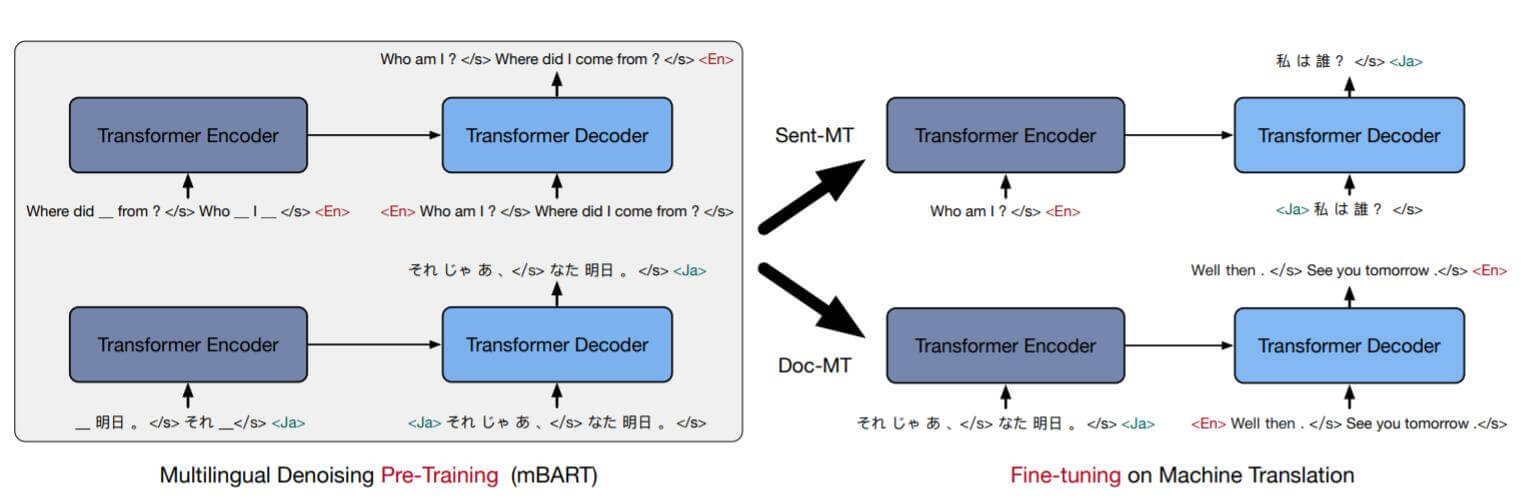
左侧为预训练阶段, 每条数据使用单语言文本并加噪, mBART将其恢复为原来的单语言文本. 右侧为微调阶段, 针对某两种语言之间做微调, 输入为源语言, 期望输出为目标语言, Decoder的首次输入为目标语言的<LID>.
Language Transfer
作者额外提出了一种新的语言迁移的无监督机器翻译方式.
常见的的反向翻译示意图如下:
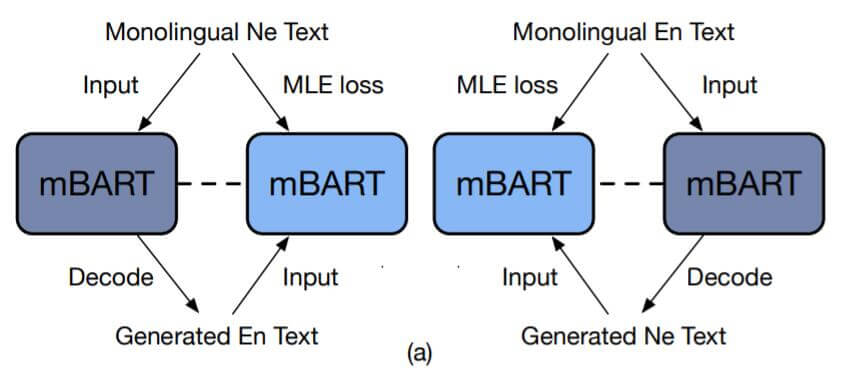
先用预训练权重初始化翻译模型, 然后对目标语言到源语言的翻译模型做训练, 生成源语言的文本作为扩充数据, 再将之前的平行语料和新生成源语言的文本共同作为训练数据, 训练源语言到目标语言的模型.
而作者提出的语言迁移方法如下:
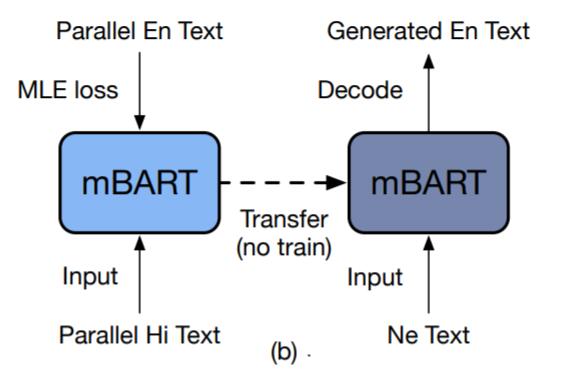
直接在预训练阶段就注入多语言的平行语料, 使得模型能学习到不同语种之间潜在的共性, 在Fine Tuning后, 直接就能应对相似语种的翻译任务.
Experiments
详细的实验设置请参照原论文.
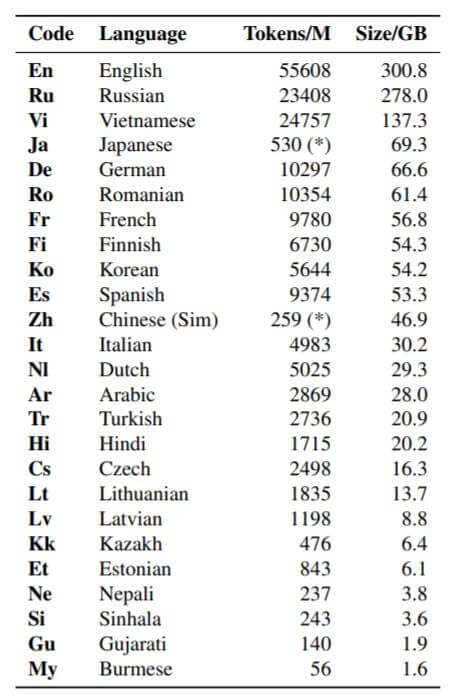
文中mBART25代表用25种语言预训练出的mBART. 文章中实验所涉及到的语言代码分别如下:
在低资源数据集上结果如下:
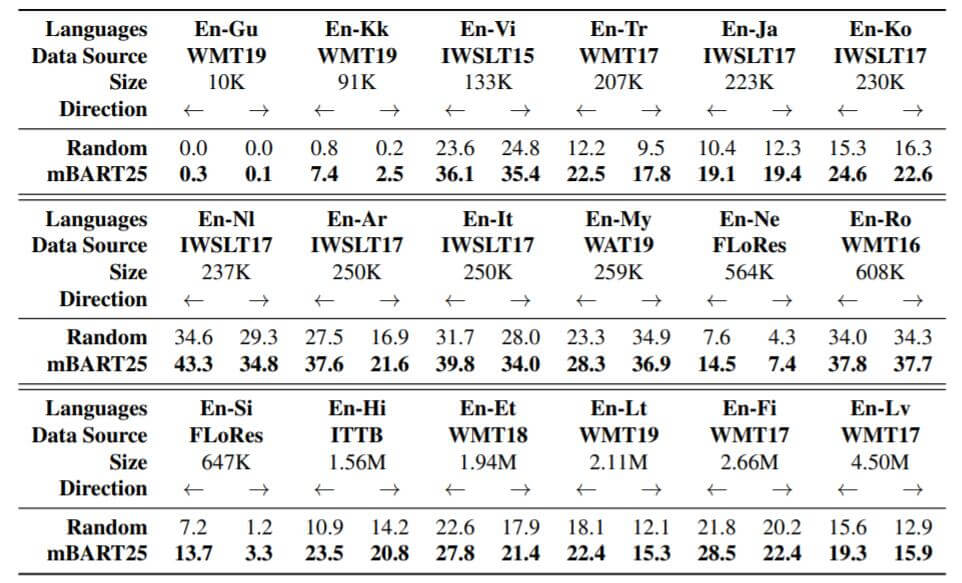
Random代表不对每种翻译任务使用预训练, 直接在该任务上训练. mBART25效果要好.
在高资源数据集上结果如下:
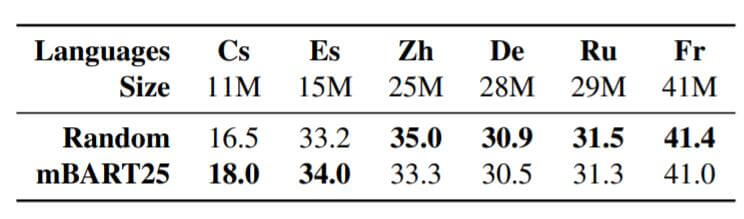
结果显示, 当数据集大小增加后, 不做预训练的效果反而是要好一点, mBART和Random表现相近.
作者尝试了不同语种到英文的Fine Tuning, 并使用不同的Testting Language观察不同Fine Tuning Language对最终结果的影响:

灰色的部分为同一个语系中的语言.
这个表格意味着:
- 主对角线上Fine Tuning时所采用的语料为
X-EN, Testing时测试的任务为X-X. - 同一X轴上代表使用的Fine Tuning Language相同(
X-EN), 但采用了不同的Testing Language. - 同一Y轴上代表采用了不同的Fine Tuning Language, 但使用的Testing Language相同(
X-X).
除去翻译最好的是自己的语言外, 次优的一般都是同一语系下的其他语言. 确实说明了语言之间存在一定的共性.
Summary
BART算是BERT和GPT的集大成者, 它的结构和标准Transformer一致, 但与Transformer不同点在于数据输入和训练目标, 以自回归式去噪自动编码器的形式存在.
因为使用了Transformer Decoder, 使得BART具有了BERT不具备的处理生成任务的能力, 实验结果表明, 没有损失性能, 也没有添加过多的参数.
作者尝试了包括Masking在内的多种噪声的添加方式, 这些噪声的干扰非常强大, 强制要求模型也要有与之匹配的预测能力.
mBART作为BART多语言版本, 给出了一种基于BART的多语言机器翻译上的处理思路, 也揭示了机器翻译中同一语系下不同语种之间的一些潜在共性.

