本文前置知识:
- BERT: 详见ELMo, GPT, BERT.
UniLM: Unified Language Model Pre-training for Natural Language Understanding and Generation
本文是论文Unified Language Model Pre-training for Natural Language Understanding and Generation的阅读笔记和个人理解.
Basic Idea
作者认为, 当前流行的语言模型有三大类, 分别是以单向(左向右或右向左)的语言模型ELMo, GPT, 以双向为代表的语言模型BERT, 以及由各类Encoder和Decoder组合使用的Seq2Seq类模型:
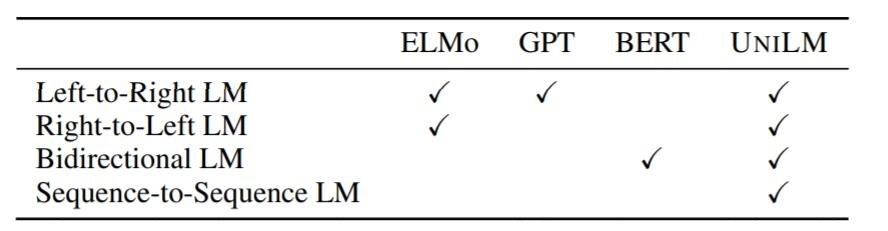
单向, 双向, Seq2Seq类的模型的优缺点各不相同, 所擅长的下游任务也不同, 对语言的编码方式更是不同:

尽管这三类模型各有千秋, 但从来没有人尝试把上述三类模型统一到同一个模型中:
因此, 作者提出UniLM(Unified pre-trained Language Model), 将上述三大类模型统一到同一个语言模型中, 共享同一组参数.
UniLM
Input Representation
对于输入的序列$x$, 无论是作为单向语言模型的文本段, 还是对于双向语言模型训练时所使用的文本对, 都在输入文本段前添加起始Token[SOS], 添加在文本段结束时添加结束Token[EOS].
此外, [EOS] 不光作为NLU任务中的边界标记, 还作为NLG任务中的生成结束标记.
分词时采用WordPiece.
Backbone Network: Multi - Layer Transformer
本部分即Transformer Encoder.
对输入的Token表示$\left\{\mathbf{x}_{i}\right\}_{i=1}^{|x|}$, 输入第0层Transformer中获得初始上下文表示$\mathbf{H}^{0}=\left[\mathbf{x}_{1}, \cdots, \mathbf{x}_{|x|}\right]$, 经过$L$层Transformer堆叠$\mathbf{H}^{l}=\text { Transformer }_{l}\left(\mathbf{H}^{l-1}\right), l \in[1, L]$, 获得最终表示$\mathbf{H}^{l}=\left[\mathbf{h}_{1}^{l}, \cdots, \mathbf{h}_{|x|}^{l}\right]$.
每层Transformer层中的自注意力头输出$\mathbf{A}_l$ 可以被表示为:
$$
\begin{aligned}
\mathbf{Q} &=\mathbf{H}^{l-1} \mathbf{W}_{l}^{Q}, \quad \mathbf{K}=\mathbf{H}^{l-1} \mathbf{W}_{l}^{K}, \quad \mathbf{V}=\mathbf{H}^{l-1} \mathbf{W}_{l}^{V} \\
\mathbf{M}_{i j} &=\left\{\begin{array}{ll}
0, & \text { allow to attend } \\
-\infty, & \text { prevent from attending }
\end{array}\right.\\
\mathbf{A}_{l} &=\operatorname{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d_{k}}}+\mathbf{M}\right) \mathbf{V}_{l}
\end{aligned}
$$
其中, $\mathbf{W}_l^Q, \mathbf{W}_l^K, \mathbf{W}_l^V$ 为线性投影矩阵, $\mathbf{M}$ 为Mask矩阵, 决定Token能够给予哪些部分注意力.
UniLM使用不同的Mask矩阵$\mathbf{M}$ 来决定模型在接下来的运算中能对哪些Token给予注意力. 所以UniLM能直接通过更改$\mathbf{M}$ 在使用同一组参数的条件下改变模型的运行模式, 非常灵活.
Pre - Training Objectives
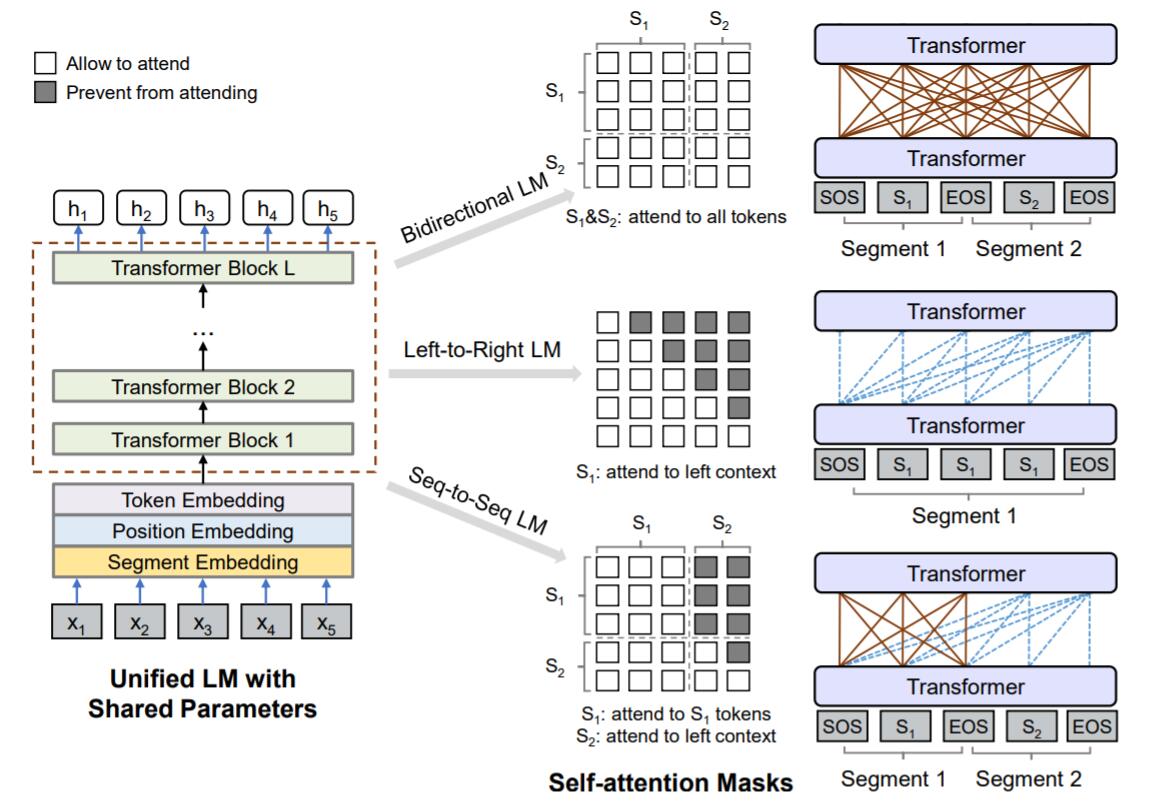
在上一节说过, 双向语言模型, 单向语言模型, 亦或许是Seq2Seq架构下的语言模型, 都能够通过修改Self - Attention Mask的形式实现:
UniLM仍然采用BERT类似的完形填空式作为目标, 采用最小化交叉熵的方式来优化模型参数.
在预训练, 作者介绍了单向, 双向, Seq2Seq三类目标在UniLM中的实现方式(其实加上NSP是四类, 但NSP仅在双向语言模型目标中使用):
Unidirectional LM - (上图中间): 对于单向语言目标, 不对输入分段, 只输入文本段$\text{S}_1$. 在左到右或右到左的单一方向是时序可见的, 因此只需要将$\mathbf{M}$ 的上三角或下三角设置为$-\infty$, 其余位置置零即可.
Bidirectional LM- (上图顶端): 对于双向语言目标, 使用了NSP任务, 输入文本段$\text{S}_1, \text{S}_2$, 与BERT训练方式保持一致. Token之间是全部互相可见的, 因此$\mathbf{M}=\mathbf{0}$.
Sequence-to-Sequence LM - (上图底部): 对于Seq2Seq目标, 输入源序列$\text{S}_1$ 和目标序列$\text{S}_2$, 并在 Encoder对应的$\text{S}_1$ 应该是双向可见的, 故$\mathbf{M}$ 的左侧为$\mathbf{0}$. 在Decoder对应的$\text{S}_2$, 上下文只应该单向可见, 即$\mathbf{M}$ 右侧$\text{S}_2$ 的上三角为$-\infty$, 其余为$\mathbf{0}$.
例如, 在预训练阶段, 对于Seq2Seq任务的输入$\text{S}_1=[t_1, t_2]$, 输出$\text{S}_2=[t_3, t_4, t_5]$, 将以
[SOS], $t_1$, $t_2$,[EOS], $t_3$, $t_4$, $t_5$,[EOS]的形式输入到模型中. $t_2$ 只能看见[SOS], $t_1$, $t_2$,[EOS], 而$t_4$ 可以看到[SOS], $t_1$, $t_2$,[EOS], $t_3$, $t_4$.在打Mask时, 如果Mask掉的部分为$\text{S}_1$ 的Token, 则有助于模型学到双向Encoder, 若Mask掉的部分为$\text{S}_2$ 的Token, 则有助于让模型学到单向Decoder. 另外, 由于
[EOS]是可以被Mask掉的, 在预测时可以教会模型何时该结束生成.仔细一想其实挺巧妙的, 因为这样并不需要明确的在模型中划分出Encoder和Decoder的位置. 也就意味着整个模型的所有区域都有可能被当做是Encoder或者Decoder.
在UniLM实际训练过程中, 总的Loss为三者的加和. 并且对各类训练目标分配时间是均匀的, 即有$\frac{1}{3}$ 时间采用双向语言训练目标, $\frac{1}{3}$ 时间采用Seq2Seq训练目标, 从左到右和从右到左的单向语言训练目标各有$\frac{1}{6}$ 时间 . 因为只是对Mask做出了调整, 因此与BERT完全兼容, UniLM参数直接使用BERT - LARGE初始化.
这三种类型的训练难度可能不同, 这里将它们平均考虑应该是出于探索, 不带来过多的麻烦.
Fine - Tuning on Downstream NLU and NLG Tasks
- 对NLU任务, 采用
[SOS]处的输出作为整个输入的表示, 记为$\mathbf{h}_1^L$, 可以由此计算文本在分类任务上的概率$\operatorname{softmax}\left(\mathbf{h}_{1}^{L} \mathbf{W}^{C}\right)$, $C$ 为类别数, 最大化类别标签的概率即可, 该部分与BERT一致. - 对NLG任务, 令输入的源序列$\text{S}_1$, 目标序列$\text{S}_2$, 以
[SOS], $\text{S}_1$,[EOS], $\text{S}_2$,[EOS]的形式输入. 训练目标为最大化在给定上下文条件下, 被Mask部分原来内容的概率. 但在精调阶段, 只对$\text{S}_2$ 中的内容打Mask.
Experiments
详细的实验参数设置请参考原论文.
Abstractive Summarization
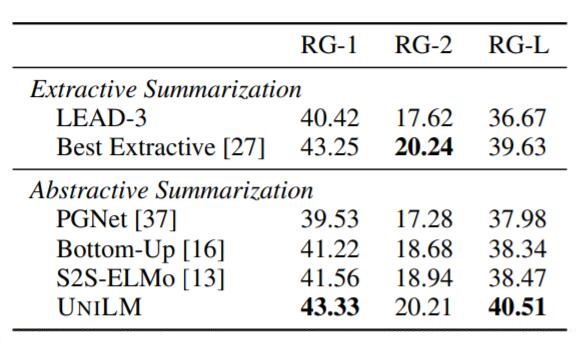
在CNN / DailyMail上的抽取式摘要和生成式摘要结果如下:
Gigaword上生成式摘要结果如下:
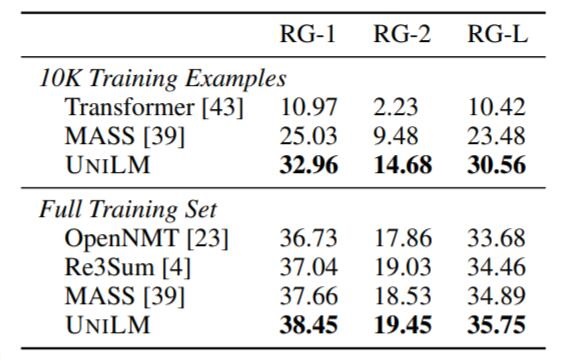
UniLM要比Baseline有小幅提升, 并几乎全面领先.
Question Answering (QA)
Extractive QA
抽取式QA的在SQuAD上的结果如下:
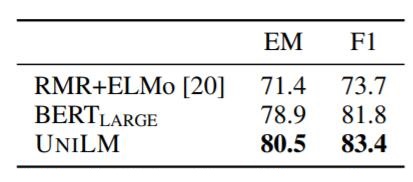
在CoQA上结果如下:

Generative QA
生成式QA在CoQA上结果如下:
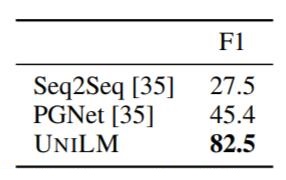
相较于指针生成网络, 在生成式QA上有非常明显的进步.
Question Generation
SQuAD上问题生成结果如下:
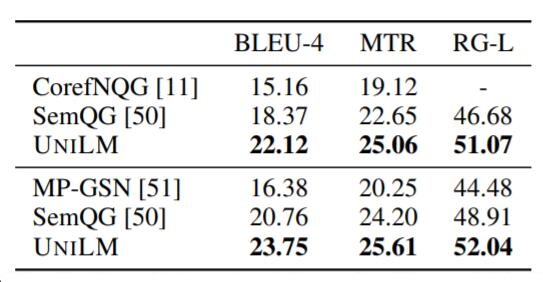
作者还使用UniLM所生成的问题让QA中的模型结果涨了四个点:
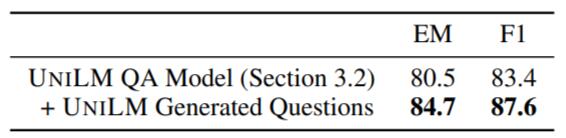
据作者所述, 这应该是一种数据增强方法, 用生成的500w个可回答的问题, 以及经过更改后不可回答的400w个问题, 反喂给QA的UniLM微调少量Epoch, 结果有提升.
Response Generation
对话生成结果如下:

与Baseline相比, 若假设数据集所采取的评价指标是有效的, UniLM已经超过人类表现, 甚至更加精简.
GLUE Benchmark
在GLUE上的结果如下:

UniLM达到了新SOTA.
Summary
同是出自MSRA的论文, UniLM与MASS所尝试的思路是完全相反的.
如果说MASS是将BERT搬到了Seq2Seq上, 那么UniLM则是将Seq2Seq搬入了BERT体系, 用Mask来实现Seq2Seq的思路还是挺巧妙的, 个人感觉UniLM比MASS要有趣一些. 从结果上来看, UniLM将各类任务推向了新SOTA.

