本文的前置知识:
- RNN
- Transformer
- Language Model
ELMo, GPT, BERT
本文是对ELMo, GPT, BERT三个模型的结构介绍以及个人理解, 多图预警.
Introduction
由于NLP领域的数据标注难度非常大, 成本很高, 所以必须要采用无监督或半监督的方法来在数据集不够充足的情况下提高模型的通用表示能力. 从Word2Vec(2013)到Glove(2014), 再到ELMo(2017), GPT-1(2018), BERT(2018), GPT-2(2019), GPT-3(2020)… 前人已经在预训练领域做了不少的探索. 由于NLP领域在自然语言的表示上非常困难, 特别注重于感知和理解, 现有的算法对机器要求又比较高, 所以NLP的发展进度比CV是滞后一些的, 在CV上早就出现了预训练模型, 也就不难理解为什么会在预训练上摸索了.
之所以把ELMo, GPT, BERT这三个模型放在一起说, 是因为BERT作为NLP中的又一个里程碑(并不是因为BERT模型本身创新点有多少, 而是它代表本阶段的所有技术融合)将这三个模型进行了对比. 这三个模型像是NLP近四年在预训练领域的探索过程的缩影, 从ELMo出现以来, NLP的ImageNet时代就来临了. 除此外, 它们三个都与单词结合上下文表示有关. 但无论哪种预训练模型, 都离不开强大的数据集和高算力支撑.
本文的图片来自于:
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
The Illustrated GPT-2 (Visualizing Transformer Language Models)
ELMo, GPT, BERT的原论文.
芝麻街那几个小人的图片来源出自网络.
其余图片的具体来源不再注明是来自于哪篇文章的, 请自行到对应模型的文章查找. 上述三篇文章均来自
jalammar, 选择他的文章做图片来源的理由太简单了, 并不是因为内容准确(自然语言不具有像数学语言一样的精确性), 而是因为颜值高.
当然Word2vec我认为没必要再细说了, 现在所有的词嵌入都是基于Word2vec的, Word2vec更像是一个”死“的稠密向量, 单词嵌入后就是唯一的表示, 不能根据其在句子中的位置和上下文关系而改变其含义, 这就为处理一词多义问题添加了难度.
ELMo
ELMo全称是Embeddings from Language Models, 出自Deep contextualized word representations.

上面这个小人就是芝麻街里的角色ELMo. ELMo是一种基于Embedding的高级词向量表示.
前面说过, Word2vec具有局限性, 不能够表示一个单词的多种意思. 作者认为一个好的词向量有两个优点:
- 能表示复杂的单词特性, 例如语义和语法信息.
- 词向量能适应多种语境有不同的体现, 即结合语境的一词多义.
ELMo也是基于这两个点出发, 尝试通过更深的方法来实现基于上下文来表示单词的模型, 能够学习到更复杂的语义特征, 所以也说它是更高级的词向量.

在上图中, ELMo指出对于不同的语义, 具有不同的词向量.
ELMo在执行不同的Task时或不同的语境时, 同一个词得到的词嵌入也可能是不同的.
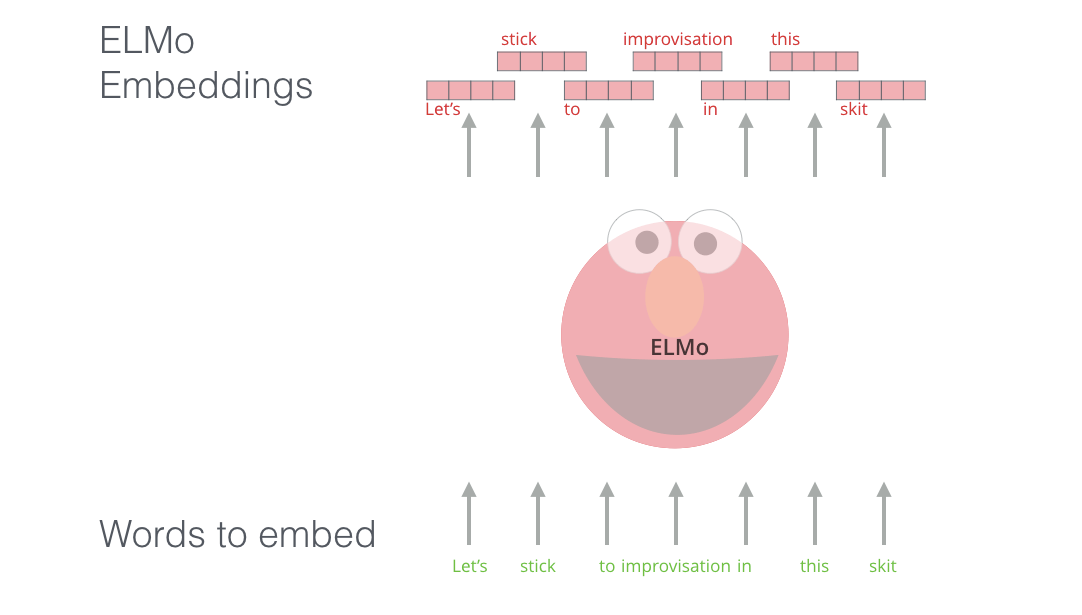
Bidirectional Language Models
虽然ELMo自称是双向语言模型, 但实则不然. 先抛出这个结论, 在本小节结束的时候再点出.
论文中指出, 高层LSTM能够捕捉结合语境的词意信息, 而底层LSTM能捕捉语法上的特征, 把它们结合起来, 非常有利于下游任务的执行, 这也恰恰就是作者认为的优秀的词向量的特性.
ELMo采用无监督的方法, 利用语言模型的特点, 对句子本身的单词进行移位预测, 依赖串行结构以当前时刻以前的单词预测本时刻单词输出的性质也叫作自回归(Transformer的Decoder也是自回归结构). 文本数量非常庞大, 无需任何标签就能从中学习.
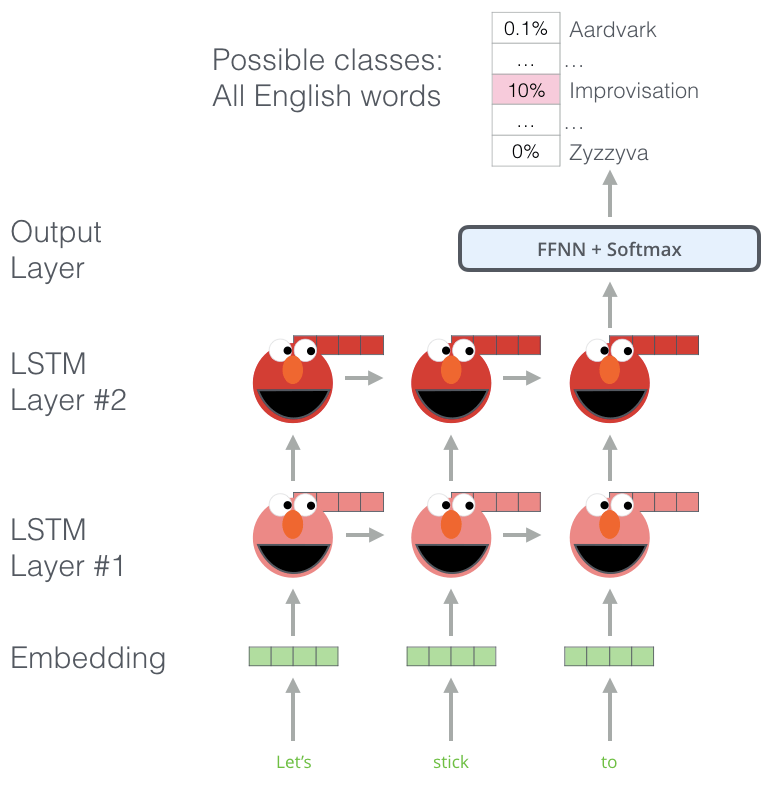
如图中, LSTM在已知前三个单词”let’s”, “stick”, “to”的情况下需要预测”improvisation”.
另外, 引入从左向右和从右向左的两个单向LSTM能更好的结合上下文, 获得更复杂的语义表示. 对于多层的LSTM, 每层输出的隐态被作为下一层的输入继续传递.

这两个单向而反向的LSTM的权重将在预训练完成后被保存, 在正式预测时派上用场.
对于上述过程, 我们用数学语言来描述. 对于序列中的$N$ 个Token, $\left(t_{1}, t_{2}, \ldots, t_{N}\right)$, 第$k$ 个Token前的序列被描述为$\left(t_{1}, \ldots, t_{k-1}\right)$, 那么根据语言模型, 序列$\left(t_{1}, t_{2}, \ldots, t_{N}\right)$ 的概率就应该表示为:
$$
p\left(t_{1}, t_{2}, \ldots, t_{N}\right)=\prod_{k=1}^{N} p\left(t_{k} \mid t_{1}, t_{2}, \ldots, t_{k-1}\right)
$$
如果把上面的方向叫做Forward, 相应的, 与之相反的方向就称为Backward, 描述如下:
$$
p\left(t_{1}, t_{2}, \ldots, t_{N}\right)=\prod_{k=1}^{N} p\left(t_{k} \mid t_{k+1}, t_{k+2}, \ldots, t_{N}\right)
$$
对与语言模型, 普遍采用极大似然来调整两个单向LSTM的参数, 只要最大化向前和向后的对数概率就好:
$$
\begin{array}{l}
\sum_{k=1}^{N}\left[\log p\left(t_{k} \mid t_{1}, \ldots, t_{k-1} ; \Theta_{x}, \overrightarrow{\Theta}_{L S T M}, \Theta_{s}\right)\right.
\left.+\log p\left(t_{k} \mid t_{k+1}, \ldots, t_{N} ; \Theta_{x}, \overleftarrow{\Theta}_{L S T M}, \Theta_{s}\right)\right]
\end{array}
$$
其中$\overrightarrow{\Theta}_{L S T M}$ 和 $\overleftarrow{\Theta}_{L S T M}$ 分别代表两个LSTM的参数, $\Theta_{x}$ 代表Token的表示, $\Theta_{s}$ 代表Softmax层在两个LSTM维护的参数. 在论文中提到, 在某些任务中加入L2正则$\lambda \lVert\mathbf{w}\rVert _{2}^{2}$ 效果可能会更好.
再强调一遍, 这两个LSTM是单向工作的:
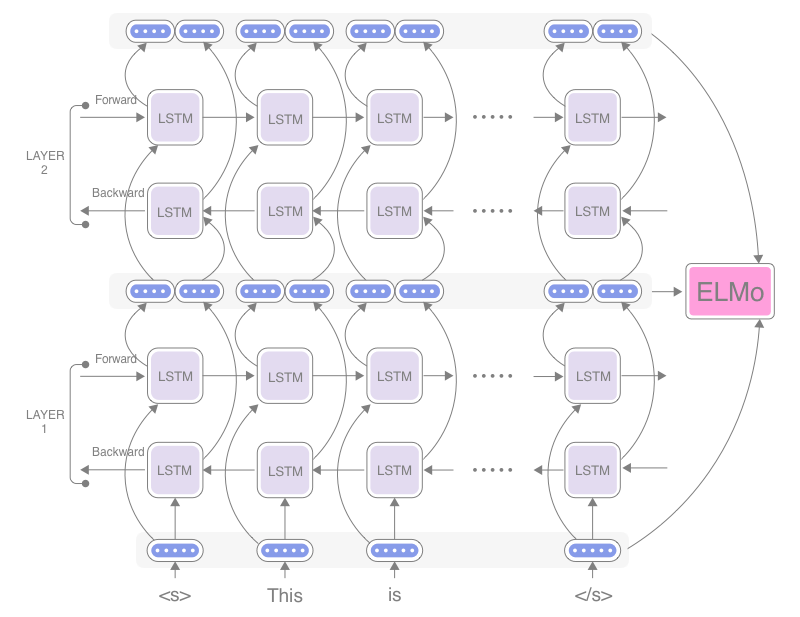
ELMo Architecture
在ELMo中, 并非直接采用Word2vec作为输入, 而是在Embedding后采用了字符级的CNN作为替代输入. 作者认为字符级CNN是一种更加不敏感的上下文表示, 也有可能Word2vec本身就限制了多语义的表达.
如果输入用$\mathbf{x}_{k}^{L M}$ 表示, 一共有$L$ 层LSTM, 在论文中采取$L = 2$. 而Forward的LSTM最终的隐态输出为$\overrightarrow{\mathbf{h}}_{k, j}^{L M}$, Backward输出为$\overleftarrow{\mathbf{h}}_{k, j}^{L M}$, 那么$k$ 应该能被$2L+1$ 个参数表示, 称这个参数集合为$R_k$, 并将两个LSTM的隐态合并后有:
$$
\begin{aligned}
\mathbf{h}_{k, j}^{L M}&=\left[\overrightarrow{\mathbf{h}}_{k, j}^{L M} ; \overleftarrow{\mathbf{h}}_{k, j}^{L M}\right] \\
R_{k} &=\left\{\mathbf{x}_{k}^{L M}, \overrightarrow{\mathbf{h}}_{k, j}^{L M}, \overleftarrow{\mathbf{h}}_{k, j}^{L M} \mid j=1, \ldots, L\right\} \\
&=\left\{\mathbf{h}_{k, j}^{L M} \mid j=0, \ldots, L\right\}
\end{aligned}
$$
为了更好的解释ELMo对下游任务是如何运作的, 将$R_k$和所有参数都表示为一个向量:
$$
\mathbf{E} \mathbf{L M o}_{k}=E\left(R_{k} ; \mathbf{\Theta}_{e}\right)
$$
对下游任务, ELMo对不同的Task采用了不同的权重.
$$
\mathbf{E} \mathbf{L} \mathbf{M} \mathbf{o}_{k}^{t a s k}=E\left(R_{k} ; \Theta^{t a s k}\right)=\gamma^{t a s k} \sum_{j=0}^{L} s_{j}^{t a s k} \mathbf{h}_{k, j}^{L M}
$$
$\text { s }^{\text {task}}$ 是经过Softmax标准化后的权重, $\gamma^{\text {task}}$ 是一个缩放因子. 对于每层LSTM, 它的标准化权重都是分别计算的, 最终是将所有层LSTM的隐态分别加以Softmax, 再相加求和, 这样对于不同的Task, ELMo就能学习到词向量在面对不同任务时的不同线性组合.
如下图, 最终的ELMo向量是由两个LSTM拼接后的向量和每层LSTM在经过Softmax后得到的权重加权求和而成的.

下面是ELMo在面对不同任务时Softmax所学习到的权重情况的可视化, 确实证明了ELMo对不同的任务下, 关注的权重不同, 对同样的词语有不同的表达:
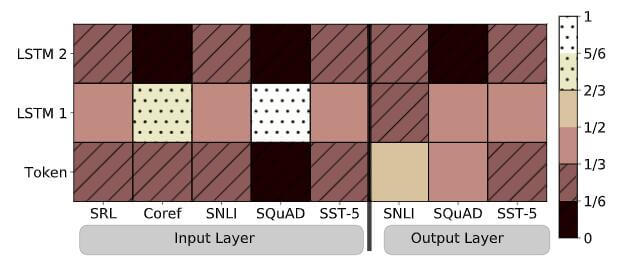
- SRL: Semantic role labeling.
- Coref: Coreference resolution.
- SNLI: Textual entailment.
- SQuAD: Question Answer.
- SST-5: Sentiment analysis.
How to Use ELMo
在使用ELMo的时候, 要冻结两个LSTM的参数. 最简单的用法就是把LSTM最后一层的隐态输出作为词向量使用, 也可以老老实实将每层的LSTM隐态输出都加权求和. 具体怎么使用, 还是要结合任务复杂程度来确定.
作者在论文中提到, 可以将$\mathbf{E} \mathbf{L} \mathbf{M} \mathbf{o}_{k}^{t a s k}$ 和 输入$\mathbf{x}_{k}$ 一起concat起来, 即$\left[\mathbf{x}_{k} ; \mathbf{E} \mathbf{L} \mathbf{M} \mathbf{o}_{k}^{t a s k}\right]$, 加强表示, 然后作为词向量送入RNN, 也可以将$\mathbf{x}_{k}$ 替换为$\mathbf{h}_{k}$, 和ELMo向量concat起来, 即$\left[\mathbf{h}_{k} ; \mathbf{E} \mathbf{L} \mathbf{M} \mathbf{o}_{k}^{t a s k}\right]$.
总而言之, 怎么用都行.
Fake Bidirectional Language Model
现在来说说小节开始时遇到的那个问题:
ELMo所谓的双向实际上是通过两个单向且反向的LSTM实现的, 并不是直接使用双向LSTM, ELMo并非是原论文中所称的”deep bidirectional language model (biLM)”, 这点在BERT论文中曾有提到过:
BERT uses masked language models to enable pre-trained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.
Similar to ELMo, their model is feature-based and not deeply bidirectional.
当你了解BERT后, 会发现作者虽然一直在强调双向语言模型, 但ELMo并不是真正意义上的双向语言模型.
那么为什么不采用双向LSTM实现呢?
两个单向的LSTM和一个双向LSTM之间的区别, 对于单层的LSTM, 双向和单向差别无非就是hidden state是否concat或者add到一起. 但对于多层来说, 涉及到序列前后信息泄露的问题, 深层双向LSTM会被泄露上下文词语的位置信息, 导致模型学到了不该学习的东西, 也就失去了预训练的效果.
Transformer Review
之所以把Transformer Review放在这里, 是因为剩下的两个模型和Transformer关系很大, 如果有基础的可以直接跳过.
Seq2Seq
如果你还不了解Transformer, 在这个小节能帮你快速回顾关于Transformer的部分知识, 因此所有的描述都非常简陋, 更详细的内容请看我之前写的<Transformer精讲>.
Transformer采用Seq2Seq架构, 分为Encoder和Decoder两个部分:
Encoder包括一个前FFN层和一个自注意力层, 结构如下:
Decoder包括FFN层, 一个对接Encoder的自注意力层, 和一个Mask自注意力层, 结构如下:
Self - Attention
General Self - Attention
这个注意力说的是不加Mask的自注意力, 即出现在Encoder的第一层和Decoder的第二层. 每个自注意力层通常有多个头, 类似于CV中的卷积核, 能够抽取不同角度的特征. 我们先不考虑多头, 反正它的操作也是一致的, 最后再合并即可.
但是经过自注意力的vector的大小是不发生变化的(下图可能有shape错误). 自注意力机制一共有三步.
首先, 每个Embedding的Token分别经过三个矩阵, 创建query vector, key vector, value vector.
其次, 根据Transformer中提出的缩放点积注意力, 分别计算上下文其他Token对当前的Score, 并经过Softmax, 得到注意力权重:
最后, 将注意力权重与对应的value vector加权求和得到结果.
Masked Self - Attention
在Encoder中, 所有Embedding是并行输入的, 这并不会影响Decoder的输出. 但我们提过, Decoder具有自回归性:
在解码时, 解码是单向的, 如果我们将所有数据并行输入, 那么就会造成信息泄露.
Mask正是为保证Decoder的自回归性和计算并行而存在的, 因为在解码时, Decoder应该只能看到当前时刻应该解码的内容和之前解码过的内容, 如下图:
灰色的向量代表Decoder不应该看见那部分信息. 我们添加一个Mask, 使得并行输入的矩阵的对角线以上的部分都不能被Decoder所解码:
我们来复现这个过程, 在Softmax之前先计算出Score矩阵:
具体对Score加Mask的方法就是将主对角线上的所有元素都变为负无穷:
这样在做Softmax时, 主对角线上的信息会自动被屏蔽为0:
这也就等价于Decoder对当前时刻以后的内容是不可知的:
GPT
GPT的想法非常简单, 因为在NLP中有相当多种类的任务, 尽管有大量的未标注数据, 但用于指定任务的标注过的数据却很少, 这不能很好地评判已训练过的模型性能. GPT尝试用一种通用, 任务无关的模型结构解决所有NLP问题. 对于不同的Task, 只需要在无监督的预训练后进行监督的Fine tune就行了, 这与CV界的Transfer Learning相同:
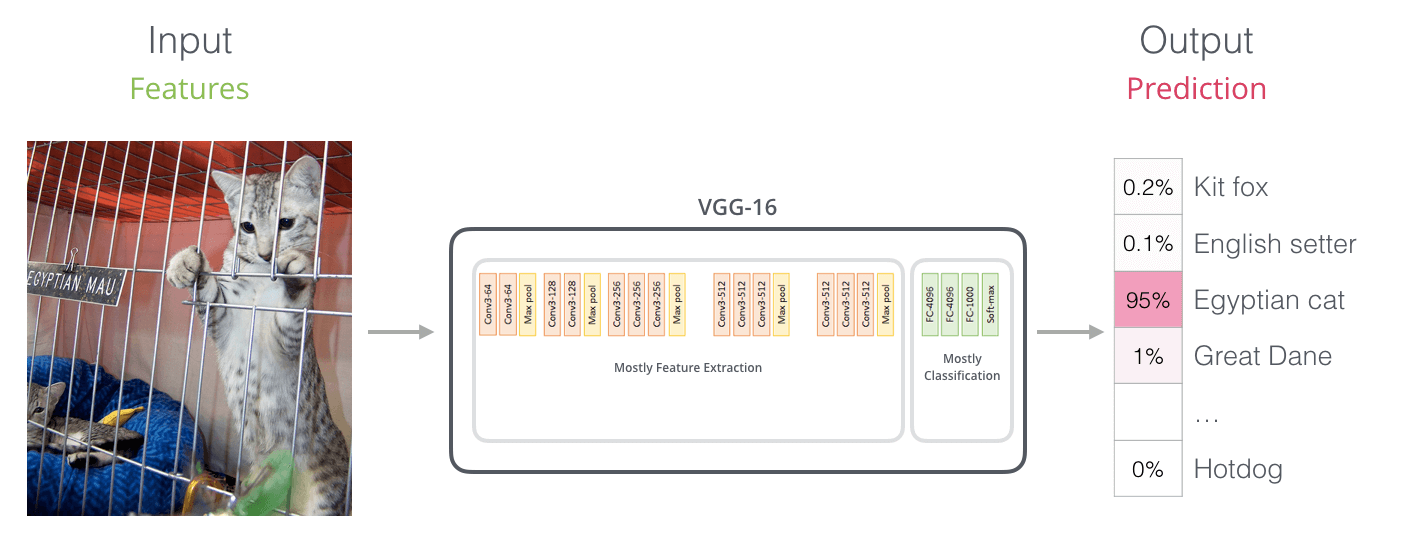
GPT的三个模型几乎都是相同架构, 只是有非常非常少量的改动. 但一代比一代更大, 也更烧钱. 所以我对GPT系列的特点就是: 钞能力, 大就完事了. 其影响力和花费的成本是成正比的.
先抛出三代GPT的论文出处:
- GPT - 1: Improving Language Understanding by Generative Pre-Training
- GPT - 2: Language Models are Unsupervised Multitask Learners (可能需要魔法才能看)
- GPT - 3: Language Models are Few-Shot Learners
因为架构相同, 后两篇论文大多数内容都是对增加参数后成果的展示. 时间不充裕建议只看第一篇, 因为每代区别不大, 本节一代为主, 二代为辅, 三代先挖个坑, 以后会补.
jalammar并没有做GPT - 1的图, 并且每代间又没有明显的结构区别, 所以就直接用二代的图了.
GPT - 1其实并没有广泛的引起人们的关注, 反倒是GPT - 2和3让它火了一把. 最出名的就是GPT - 2生成的那篇关于独角兽的文章:

对此, 我个人认为除了生成的结果十分惊艳外, 确实有些炒作的成分. 惊艳是因为第一次见到机器能够生成如此有趣而附带一些逻辑的内容. 炒作主要原因是媒体夸大事实宣传, 博人眼球, 次要原因不难理解OpenAI也是需要科研资金的嘛. GPT目前相对于其他的NLP模型来说, 强是肯定的, 只是说代价太大了. 第二代和第三代强调了GPT有Few shot Learning和Zero shot Learning的潜力, 在巨大数据集的情况下, 模型甚至都没有收敛… 三代甚至不需要Fine tune…
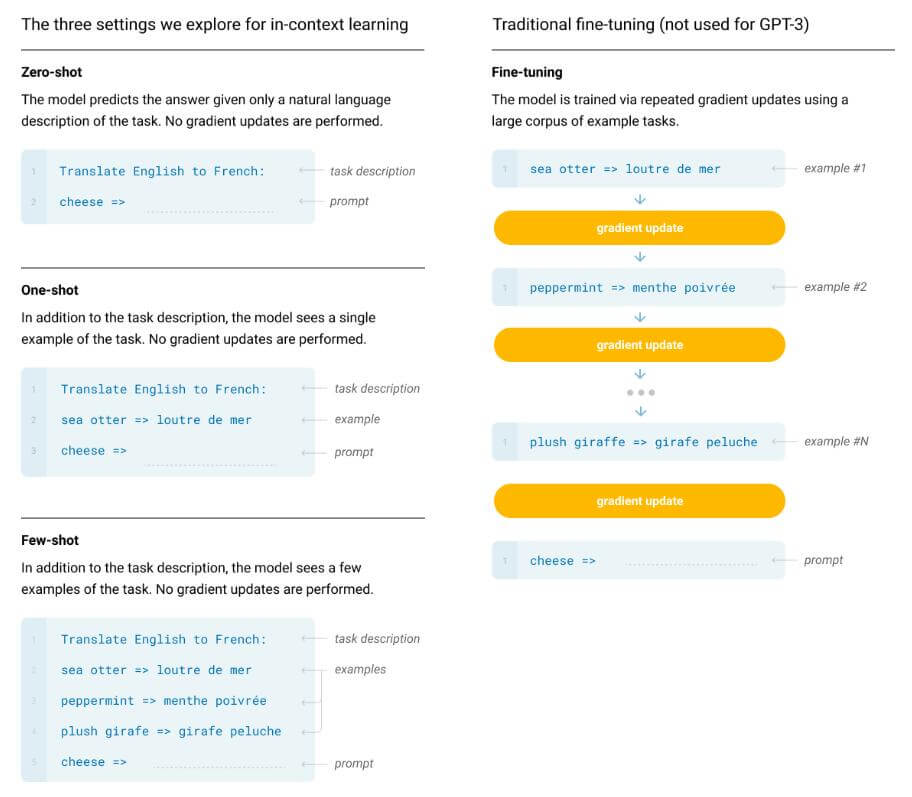
Few - shot: 给出一个自然语言任务的一些范例, 但这些范例不能更新权重(算是一个限制, 给出更多信息).
One - shot: 仅给出一个范例, 让模型给出结果.
Zero - shot: 不给任何范例, 直接让模型给出结果.
在论文中, GPT - 3的Zero - shot和One - shot在某些任务上确实超过SOTA, 但相较人类还有很大差距. Few - shot比前二者有很大提升. 说明在没给出足够多信息的条件下, GPT - 3对问题理解能力还是比较差的.
Why Transformer Decoder?
言归正传, 来说GPT的具体结构. 受Transformer影响, GPT(Generative Pre-Training)采用Transformer作为基本的Block结构. 作者指出LSTM将预测能力限制在短距离内, 所以才采用使用Attention的Transformer作为长距离的信息抽取器. 当然, 这里只使用Decoder, 就需要去掉Decoder对Encoder的自注意力层, Mask后的自注意力保护了Decoder的自回归性:
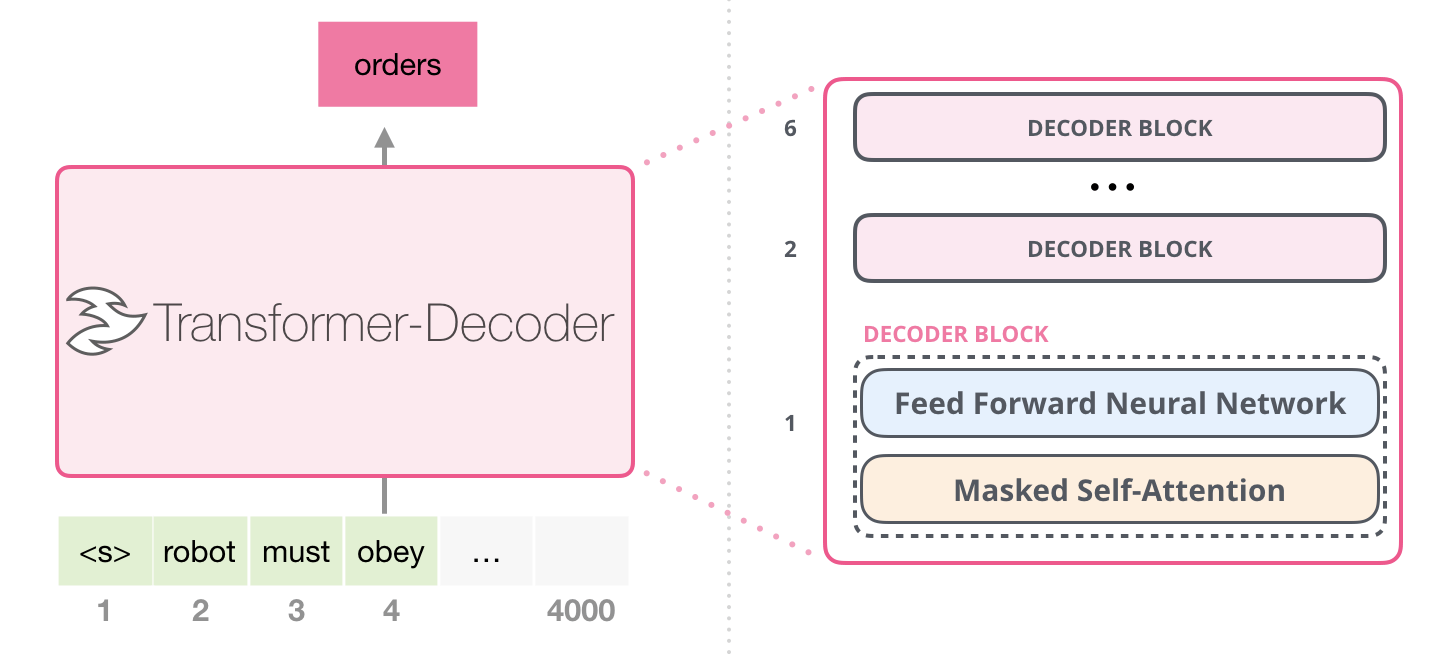
在GPT一代中, 采用了12个Decoder堆叠.
Unsupervised pre-training
与标准语言模型一样, 对于无监督语料库中的Token $\mathcal{U}=\left\{u_{1}, \ldots, u_{n}\right\}$, 都采用极大似然优化:
$$
L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right)
$$
其中$k$ 为上下文窗口, $\Theta$ 是神经网络参数, 它们会用随机梯度下降得到训练.
对于GPT来说, 选用Transformer的Decoder做最基本的Block. 将输入一层一层嵌套, 经过$n$ 个Transformer Block, 其数学表达为:
$$
\begin{aligned}
h_{0} &=U W_{e}+W_{p} \\
h_{l} &=\text { transformer_block }\left(h_{l-1}\right) \forall i \in[1, n] \\
P(u) &=\operatorname{softmax}\left(h_{n} W_{e}^{T}\right)
\end{aligned}
$$
其中, $U=\left(u_{-k}, \ldots, u_{-1}\right)$ 是上下文向量, $n$ 为Decoder的层数.
$W_e$ 是Token的Embedding矩阵(一代嵌入维度只有768一种):
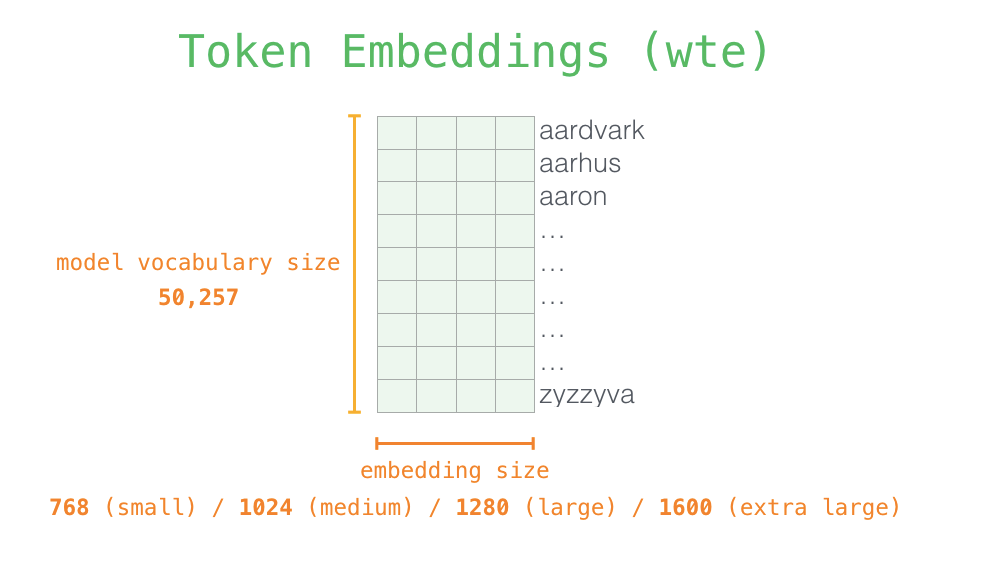
$W_p$ 是Positional Embedding矩阵. 与Transformer不同, GPT的位置编码并非是通过三角函数计算来的, 而是通过训练学习到的.
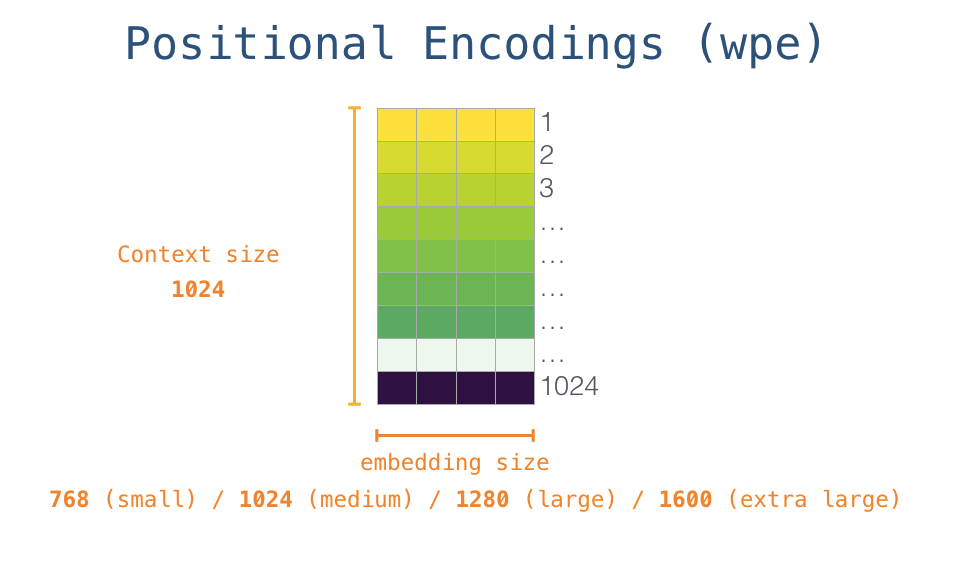
$h_0$ 是嵌入后的向量和学习到的位置编码向量之和:

然后就经过Transformer Block的自回归得到Decoder部分的输出$h_l$ :
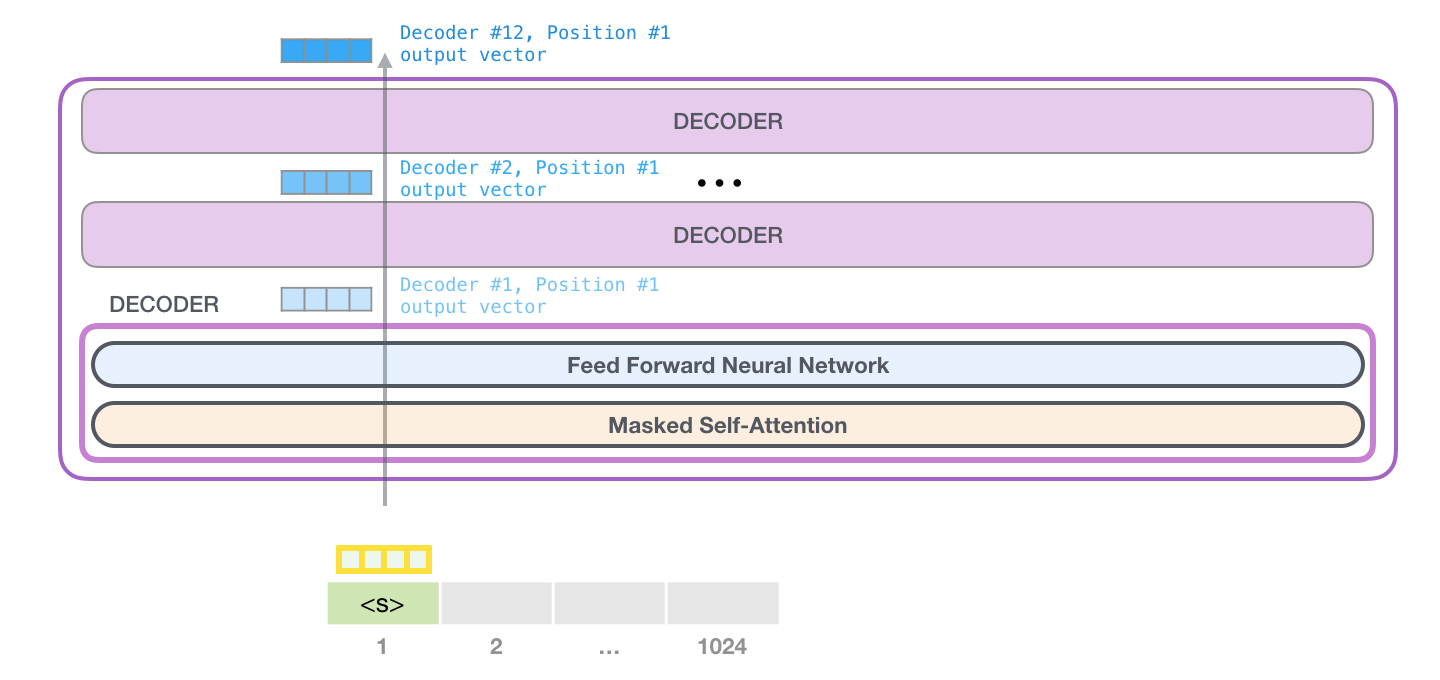
对Decoder部分的输出做个总结吧(因为重复太多次了, 省略了再跑一遍的过程, 想看完整的去这里):

在得到最后输出前, 最后还需要再与Embedding相乘一次, 再通过Softmax得到结果$P(u)$:

“logits”就是在Softmax前的值, 后一般接一个Softmax输出标准化的概率. 在GPT二代中, 不再像一代直接选择概率最高的单词, 而是从top_k 中以某个概率选择单词, 这样来避免陷入永无止境的循环之中.
参数量实在是太大了, 每个部分占到的参数都非常非常多:
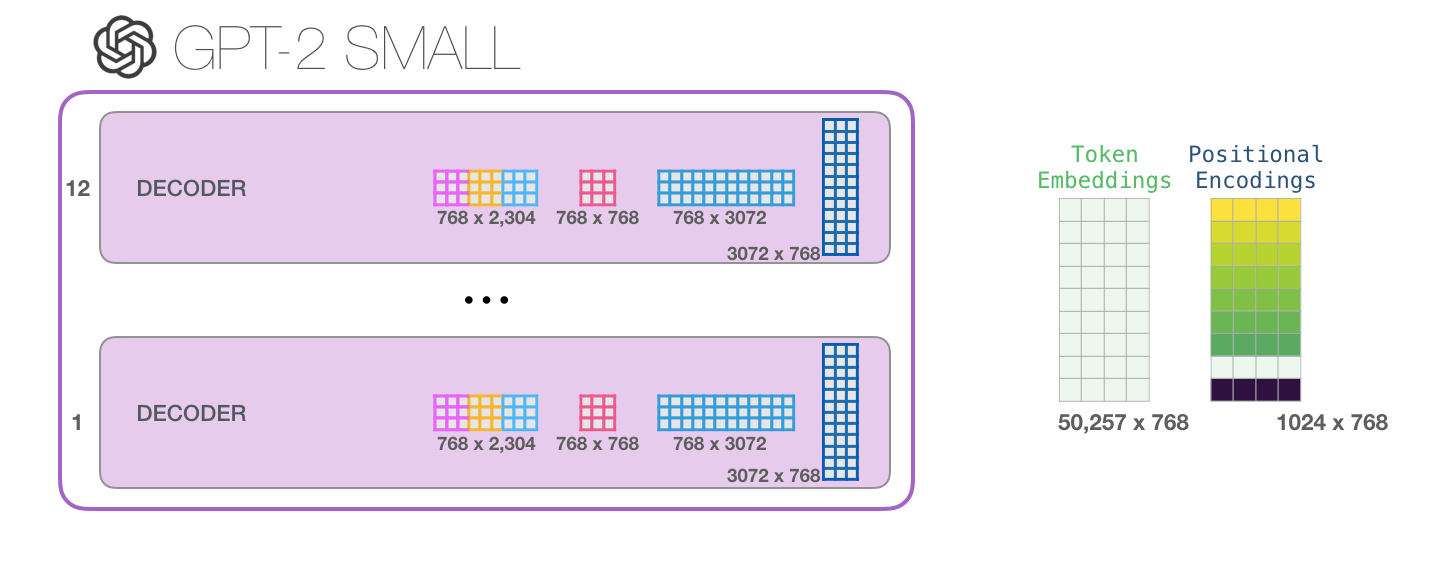
Supervised Fine-tuning
首先要加载预训练的权重, 然后要让预训练模型适应特定的任务, 对额外参数进行微调, 所以还要继续在当前基础上再加Linear层适应输出. 假设给出数据集$\mathcal{C}=(x^{1}, \ldots, x^{m}, y)$, 在通过一堆Transformer Block后得到的最终输出为$h_{l}^{m}$, 最后加一个Linear层参数为$W_y$, 有:
$$
P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right)
$$
有了标注的数据, 仍然采用极大似然进行优化:
$$
L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right)
$$
无监督学习反作用于监督学习可以有一些提升. 所以在Fine tune这里用了前面无监督预训练的Loss做辅助训练. $\lambda$ 是超参, 论文中设置$\lambda=0.5$.
$$
L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda \ast L_{1}(\mathcal{C})
$$
在微调中, 只有最后外接的$W_y$ 和句子之间的代表分隔符的Token的Embedding(看Overview and GPT in Specific Task)是需要额外进行学习的.
More Details
一些超参的设置请参考原论文, 这里只说容易被忽略的点.
BPE
BPE(byte pair encode), 也称为字节对编码, 其主要目的是数据压缩, 现在已经被作为重要的提升NLP模型性能的算法. 这种编码拆除了语言学特性, 但通过统计学方法更好的解决语言类问题. 做法请参考论文Neural Machine Translation of Rare Words with Subword Units, 我认为日后有必要把几个subword技巧做个对比.
GeLU
在GPT中使用的激活函数是GeLU(Gaussian Error Linerar Units)不是ReLU!
GeLU原文中作者给出的近似公式:
$$
\text{GeLU}(x) = 0.5x(1 + \text{tanh}[\sqrt{\frac{2}{\pi}}(x+0.044715x^3)])
$$
具体内容请见论文Gaussian Error Linear Units (GELUs).
WarmUp
Fine tune阶段使用了线性衰减的WarmUp, 请参考我在<Transformer精讲>中的内容.
Overview and GPT in Specific Task
Overview
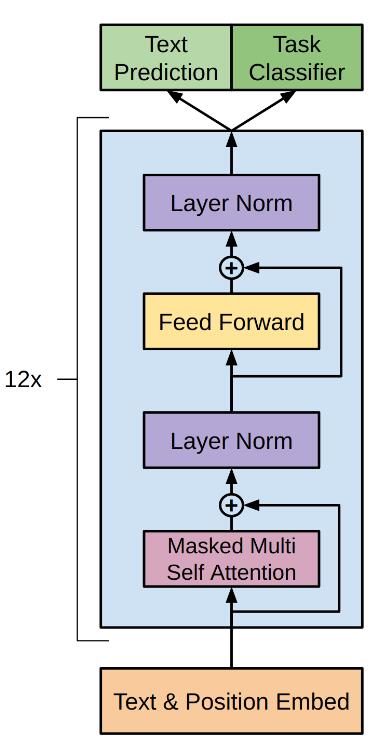
GPT的结构非常简单, 实质就是12个Transformer Decoder的堆叠, 最后再根据任务需要接入结构以完成最终任务.
这里能看出GPT的一个缺点, 虽然Self - Attention能够很好地利用全局的文章信息, 但是由于Decoder自回归性的限制, GPT是一个单向语言模型, 在Summary部分会继续与其他模型进行对比.
Input Transformations

执行不同的任务时, 需要对输入进行相应的调整. 在微调的过程中, 对于每种任务的开始和结束都需要加入标记$\langle s\rangle,\langle e\rangle$, 下文不再强调, 两段不同的内容之间需要加入分隔符$ $ $ .
Classification
做分类任务非常简单, 在原输入两侧加上开始结束标记即可, 可以直接使用原来的模型微调.
Textual entailment
文本蕴含任务, 将premise和hypothesis拼接起来, 在二者之间加入分隔符.
Similarity
句子相似度任务, 在句子A和句子B之间加上分隔符, 再交换句子A和句子B的位置, 分别传入Transformer, 将二者结果add起来, 传入Linear.
Question Answering and Commonsense Reasoning
QA和常识推理任务, 将内容文本和回答分别组合, 并在之间加上分隔符, 传入Transformer, 分别经过Linear, 经过Softmax, 最后得到概率分布.
GPT还能做其他的事情, 例如音乐生成之类的, 感兴趣自己了解下:
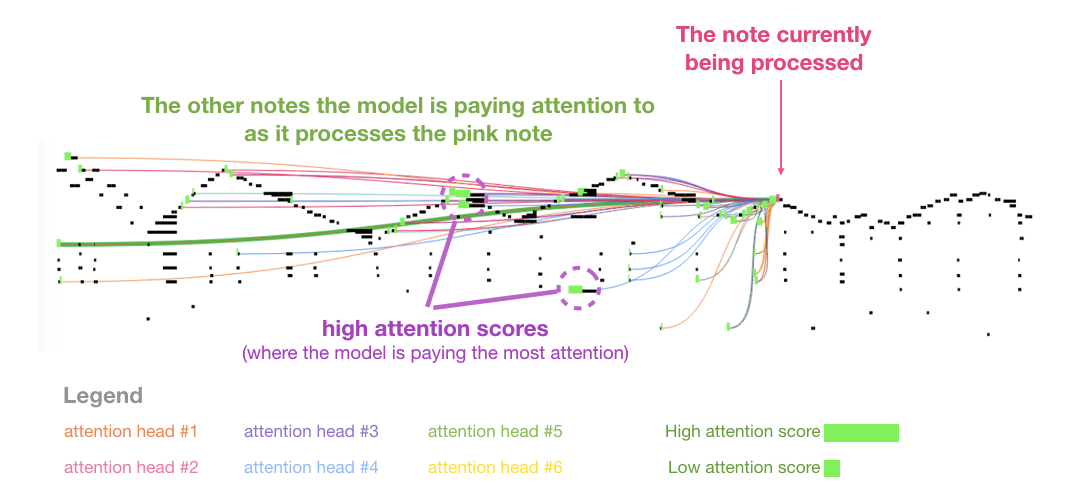
Difference Between GPT - 1 and GPT - 2
GPT一代到二代仅发生了几个不同:
用了更大的数据集, 尤其是网页文本, 40G.
增加了海量参数, 并推出了几个不同的版本, 一个比一个大:
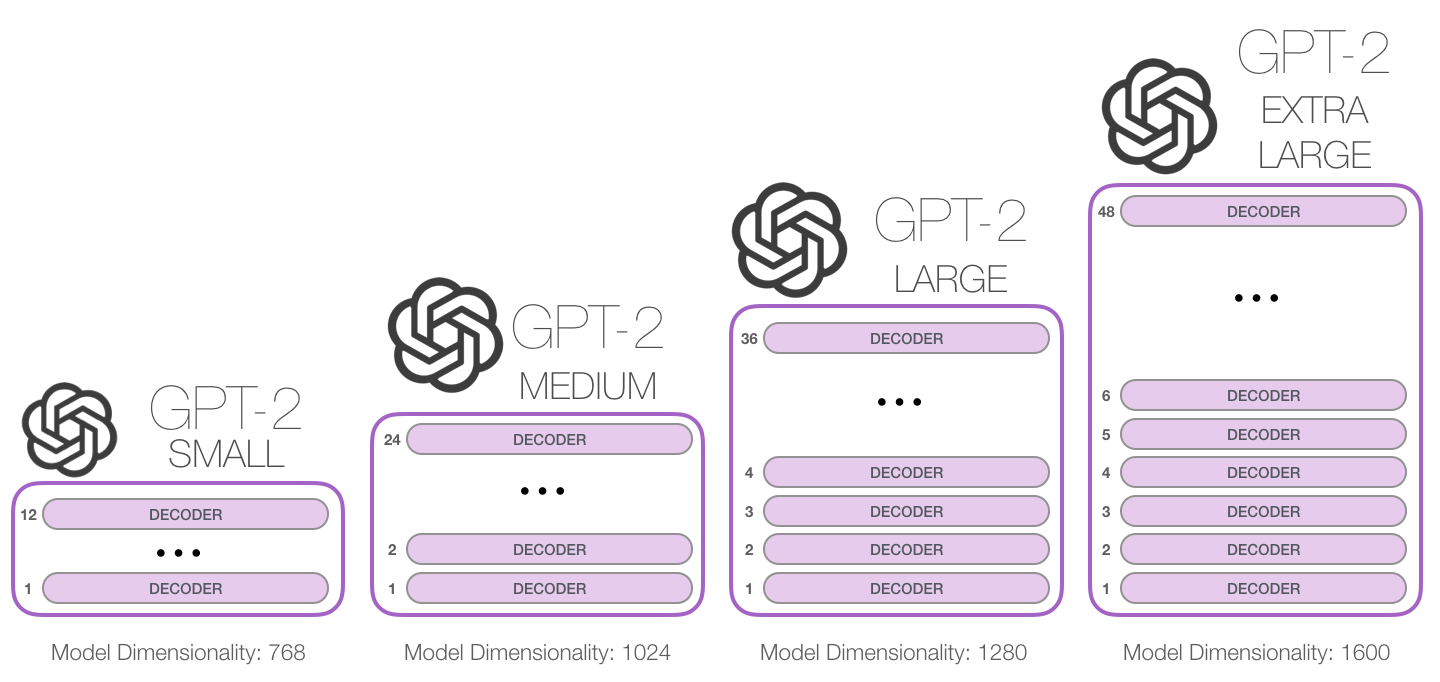
除了使用的Decoder个数不同, 它们的Embedding维度也是不同的.
直接去掉了Fine - tune层, 直接输入任务和所需的内容就能得到输出.
将Layer Norm放到了每个子层的输入前, 并且在最后一个自注意力层后添加了Layer Norm. 通过放缩权重更换了残差层的初始方式.
Postscript
其实GPT一直都存在伦理上的问题. 有些人认为语言模型训练来自于语料, 语料的偏见会导致模型带有偏见. 而且GPT当初被OpenAI认为过于危险, 可能在只经过fine tune后被恶意滥用, 没有将这个庞然大物的参数开放.
但可以通过下面几个链接去体验GPT - 2(可能需要魔法):
最后说一些自己的感想, 不想看的可以跳过这段.
GPT经历了三代, 有那么一点哲学和讽刺的意味. 第三代的1750亿参数几乎已经逼近了参数量的极限, 但实际上GPT产生的文章并没有媒体文章渲染的那么恐怖, GPT生成的内容还是经常犯一些常识性的错误, 即使是靠堆参数, 模型也并没有真的做到”Natural Language Understanding”, “大”真的意味着它智能了吗? 我们接触的世界是一个多模态的世界, 而计算机不能真正触及我们所接触的任何物体, 只能通过我们提供的数据来做到”认知”. 尽管我对AI发展持乐观态度, 但现在人们所强调的技术方法绝对不能有效的构造一个智能体, 虽是一条过渡的必经之路, 但有些矫枉过正. 至少人类距离强人工智能还有非常遥远的一段距离(如果非要形容, 距离可能是光年为单位), 任重而道远.
BERT
也受到Transformer的影响, BERT像GPT一样把Transformer加入了自然语言理解中, 也尝试训练一个预训练模型, 只经过微调就能适应NLP领域的各种任务. 现在的BERT已经遍地开花, 很多NLP任务都是BERT或者BERT的魔改在屠榜.

上面这个小人就是BERT, 与ELMo同样都来自芝麻街. 其实除了BERT, 大家还拼凑过Grover, ERNIE, Big Bird…这些全是芝麻街的小人, 只不过有些凑的比较强行就是了.
BERT出自论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 我认为这篇论文的附录才是本体… 正文着重于讲BERT的训练方式, 与前人模型的区别, 以及取得的效果. 虽然正文也很重要, 但附录里才有BERT的具体实现方法, 以及与ELMO, GPT的对比. 所以在看这篇论文时, 一定记得看Appendix.
BERT(Bidirectional Encoder Representations from Transformers)延续了GPT的Pre - train + Fine tune的思路, BERT也是冲着通用语言模型的目标去的, 并适配了一套对任何任务不用变更输入模式的训练方法.
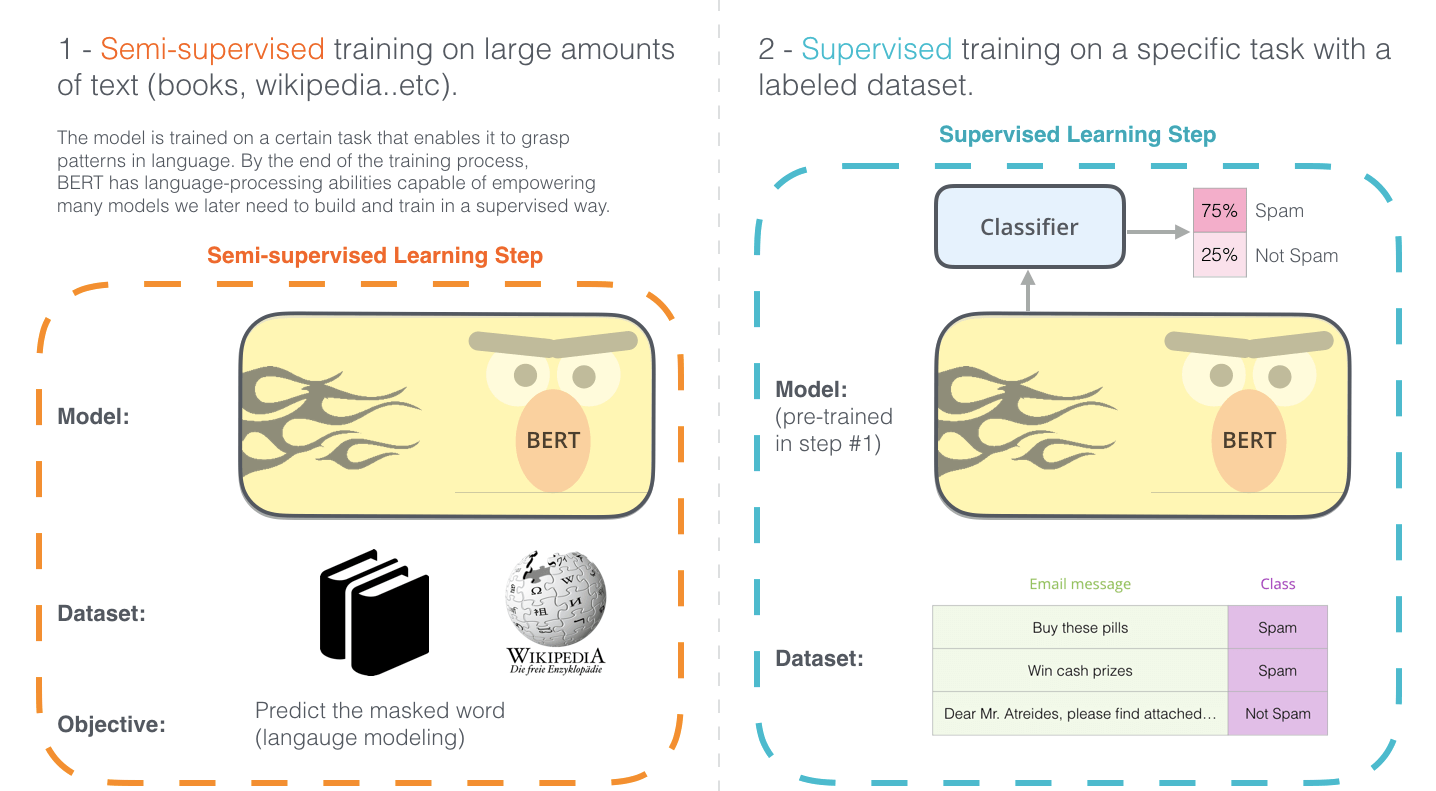
在预训练和微调好了之后, 只需要接上一层FFN和Softmax就能做到分类:
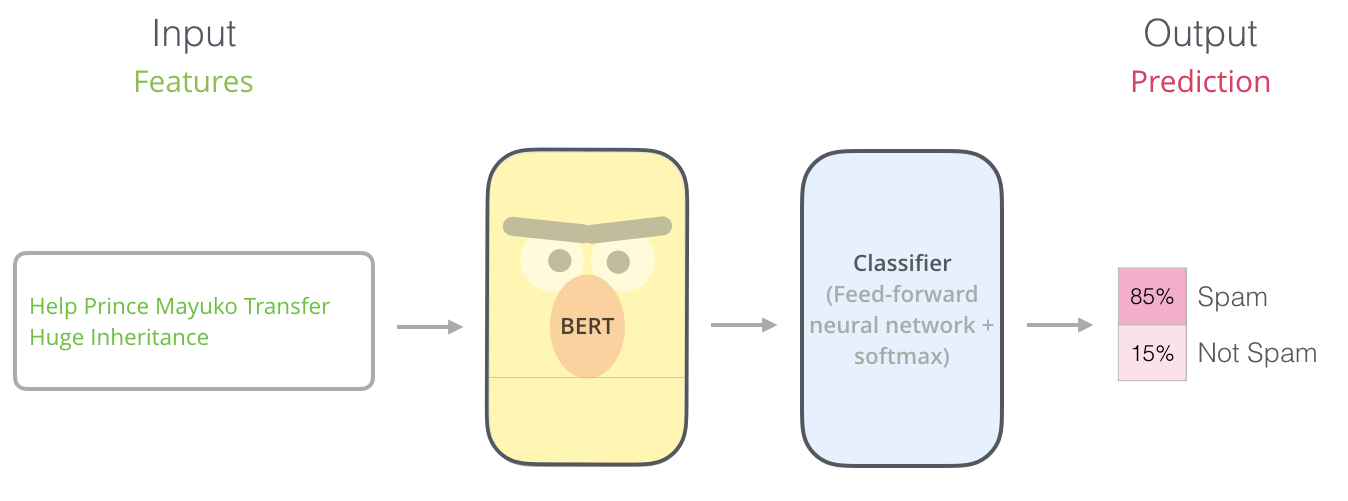
另外, BERT可以抽取词向量, 近期已经被作为Word2vec的替代者了:
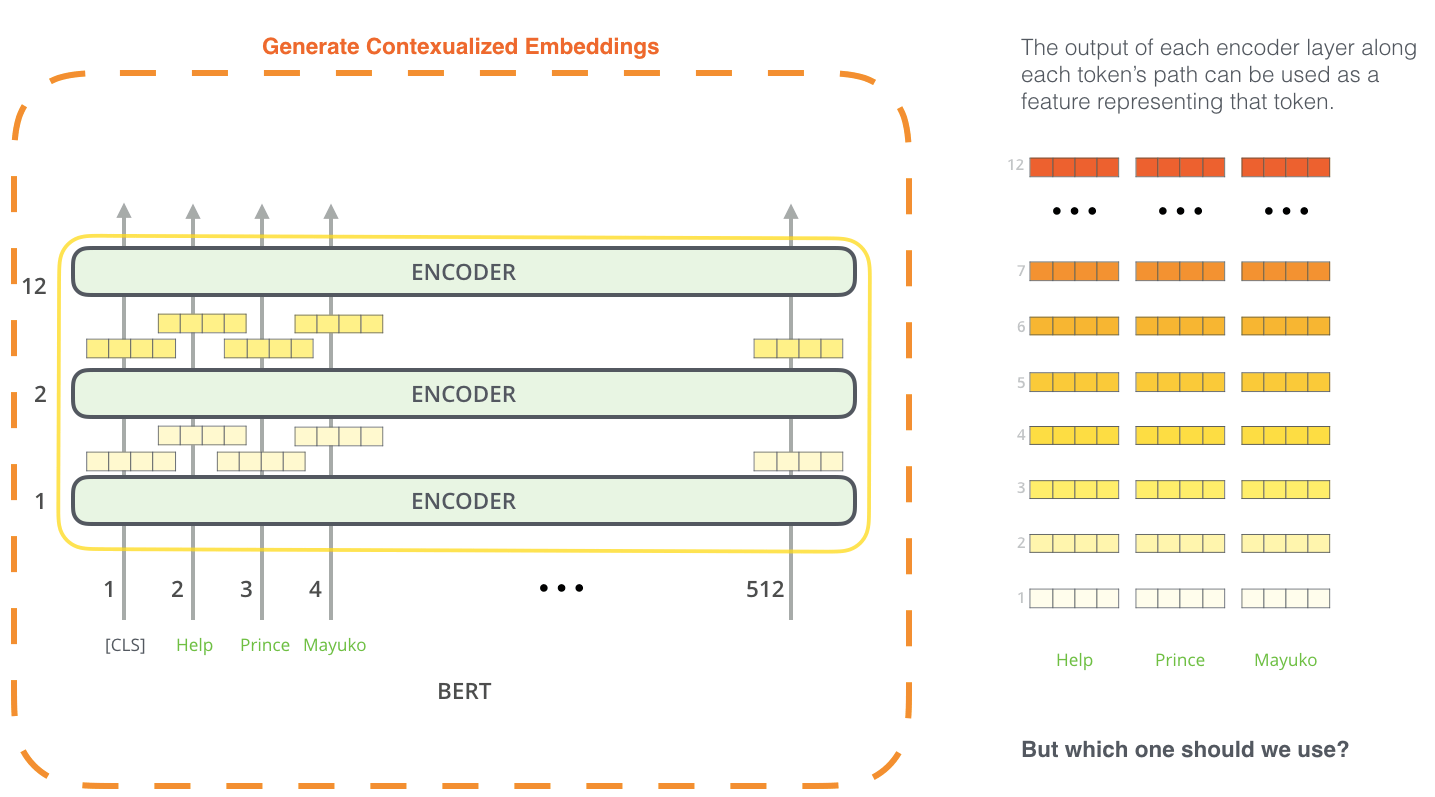
在论文中, 作者对BERT提取的不同特征效果做了对比, 这也证实了BERT具有特征抽取能力:
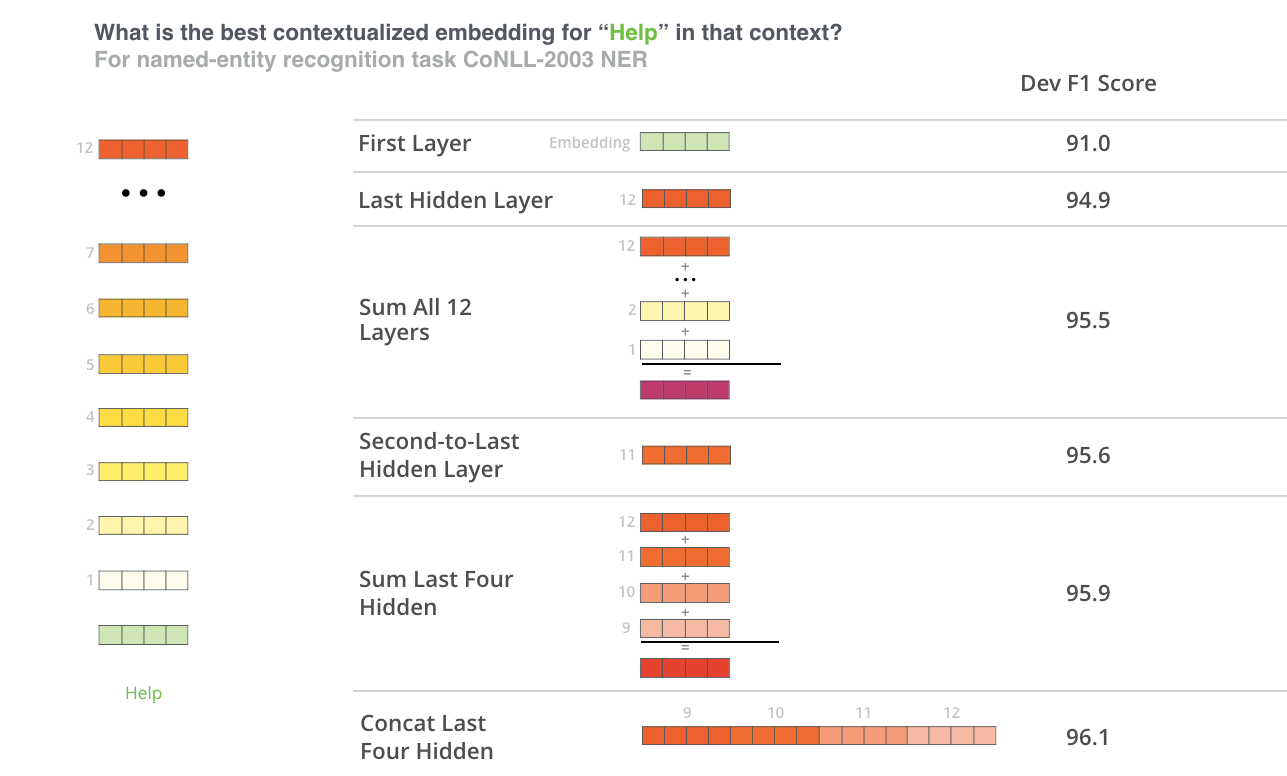
似乎将最后4层拼接起来的F1得分要高一些.
Model Architecture
在BERT论文中指出了ELMo和GPT的不足: 它们不是双向语言模型, 所以BERT采用了多层双向的Transformer Encoder作为堆叠基础结构.
所谓的双向Transformer实际上是Transformer Encoder, 所谓的”双向”是体现在MLM中(见Masked Language Model).
We note that in the literature the bidirectional Transformer is often referred to as a “Transformer encoder” while the left-context-only version is referred to as a “Transformer decoder” since it can be used for text generation.
在论文中, BERT发表了两个不同的版本, $\mathbf{B E R T}_{\mathbf{B A S E}}$ 和 $\mathbf{B E R T}_{\mathbf{LARGE}}$.

根据论文中的参数给出对比二者的对比:
| 模型 | 堆叠层数$L$ | 隐藏层大小$H$ | 自注意力层头数$A$ | 共计参数 |
|---|---|---|---|---|
| BERT (Base) | 12 | 786 | 12 | 110M |
| BERT (Large) | 24 | 1024 | 16 | 340M |
| Transformer | 6 | 512 | 8 | / |
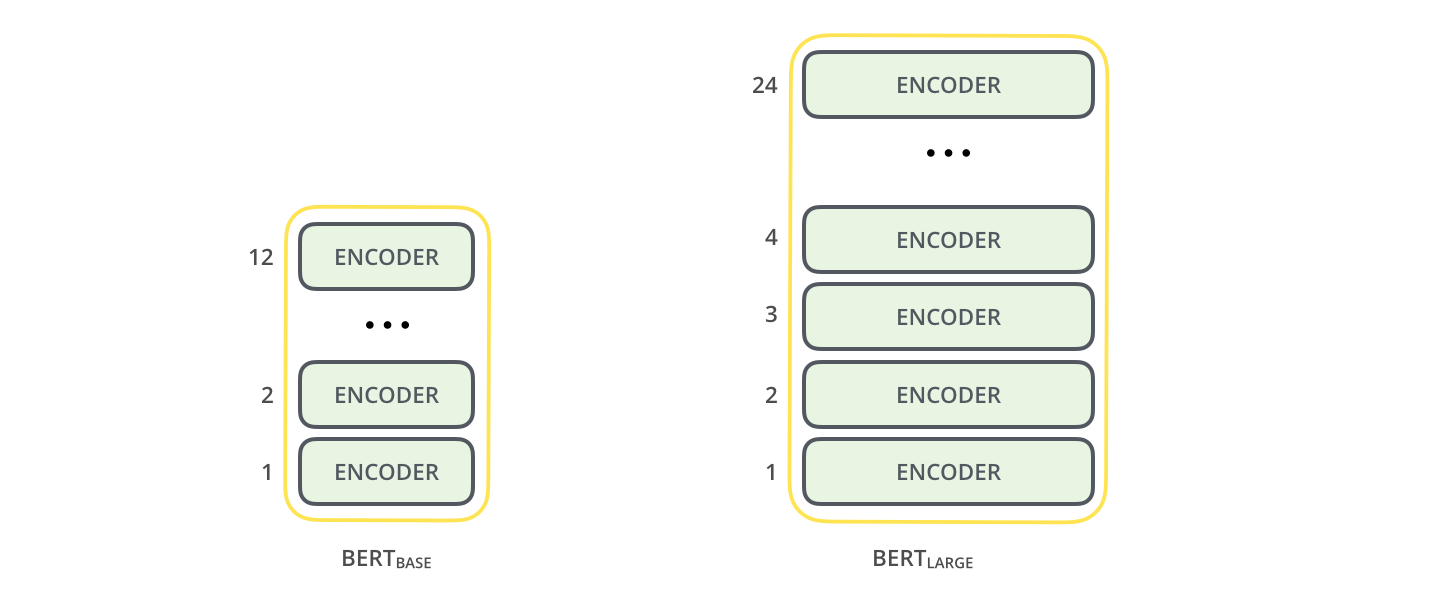
此外, 在论文脚注中提到, FFN的大小为$4H$, 也采用了GeLU作为激活函数, 并使用了10000步的WarmUp.
Input / Output Representations
[CLS]
在BERT中, 永远都将第一个位置输入分类提示符[CLS], 如果执行的是分类任务, 第一个位置最终会输出一个向量, 作为分类依据.
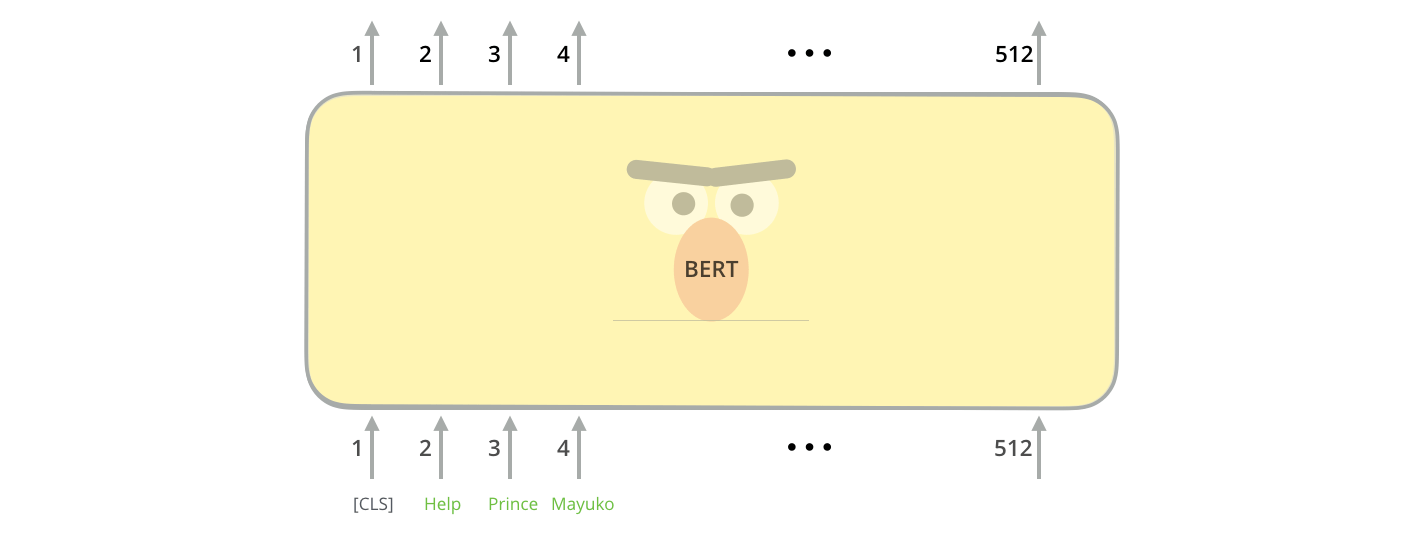
BERT接受一些系列单词输入, 经过Transformer Encoder的堆叠, 得到输出.
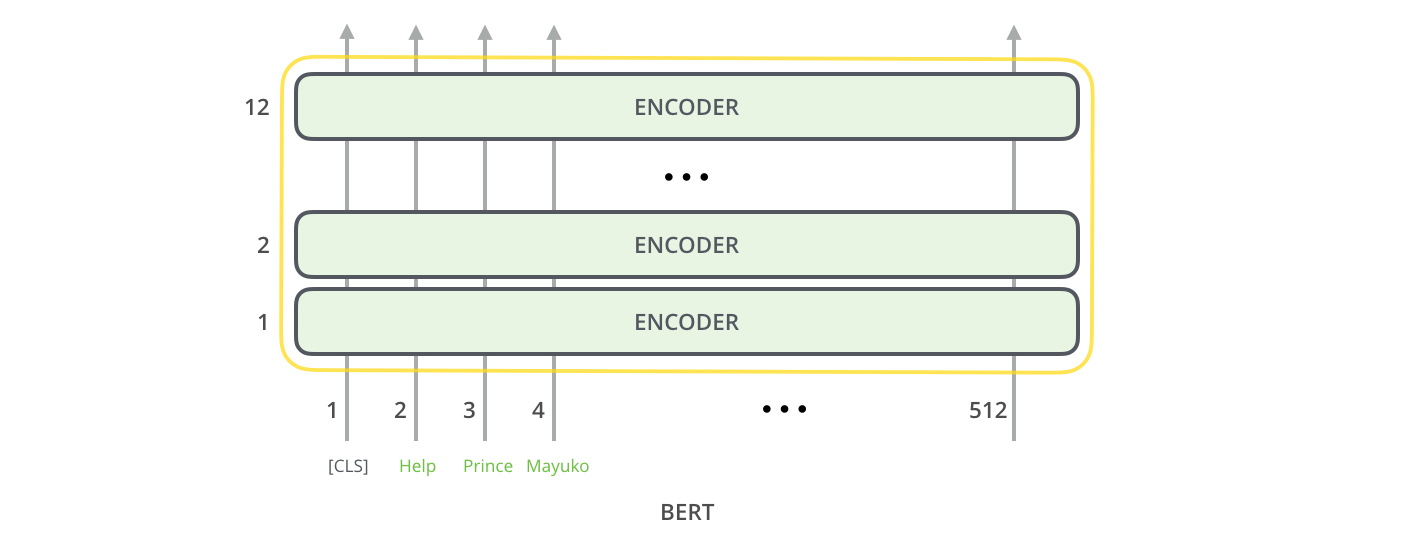
其实对于BERT来说, [CLS] 到底放在哪是无所谓的, 只是放在第一个习惯于我们理解.
在执行分类下游任务时(不是训练时), 其他位置无论有多少隐态输出, 我们都忽略, 只看[CLS] 对应位置上的输出, 也就是第一个位置:

进行分类任务所搭建的网络也是在第一个位置上继续的, 结构也可以任意调整:
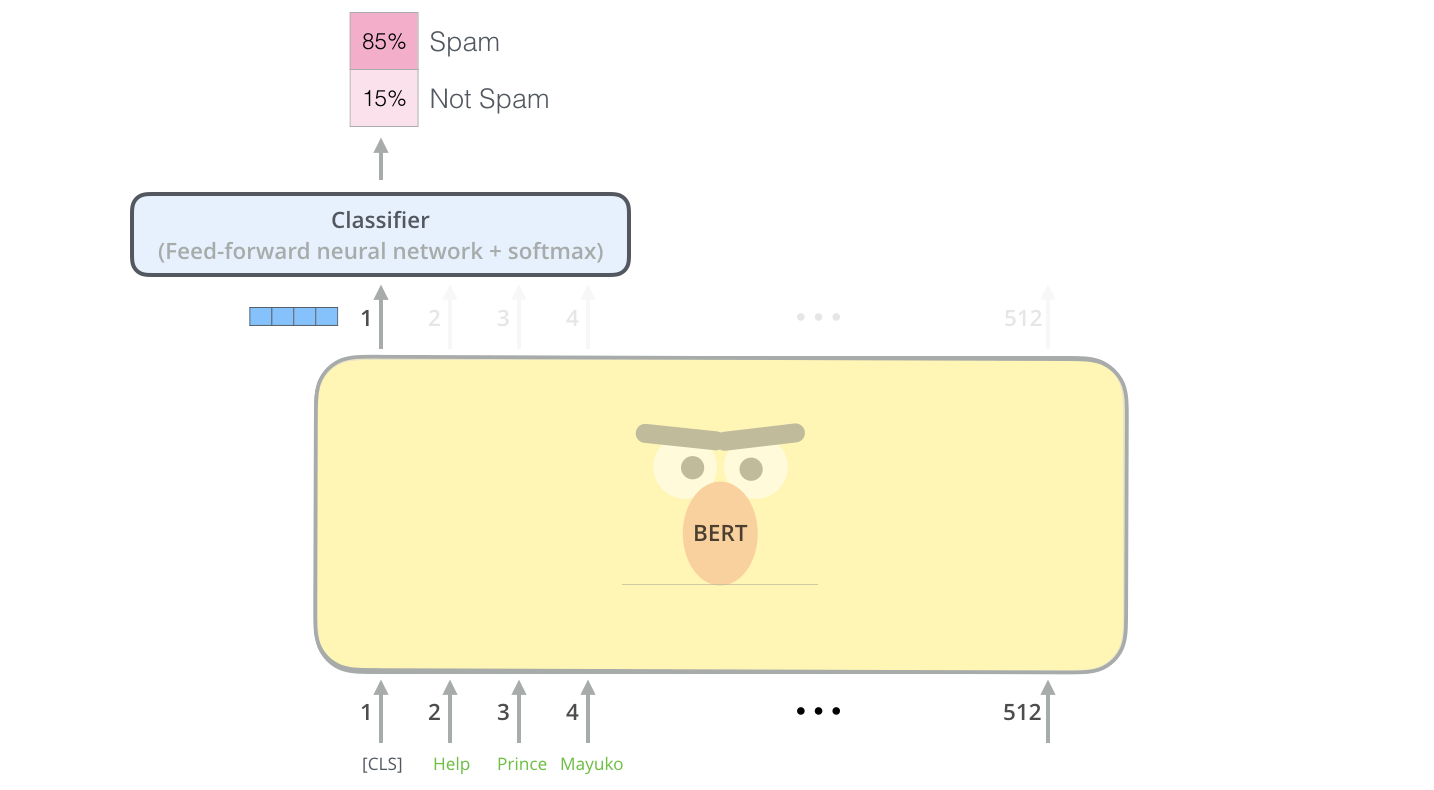
[SEP]
对于任何任务, BERT的输入永远都是将一对句子放在同一个序列中, 无论这对句子是真正连续的上下文还是随机拼接的. BERT句子和句子之间用分隔符[SEP] 隔开, 在结尾也要加上一个[SEP].
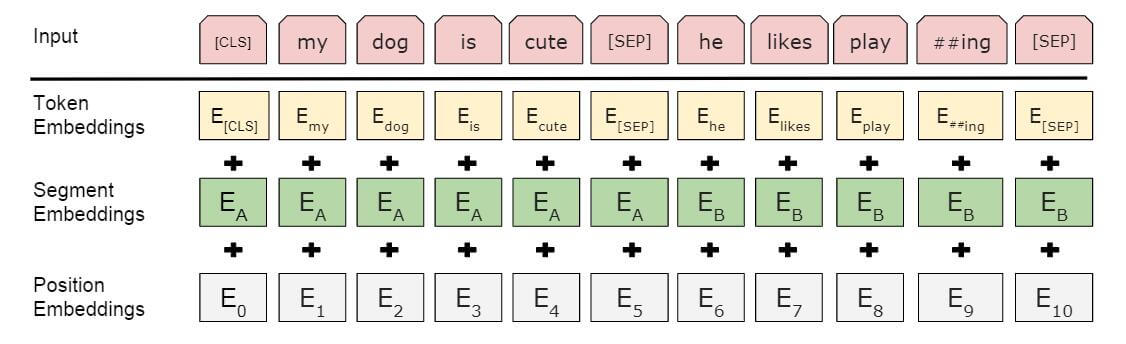
Embedding
输入编码由三个部分组成:
- Token Embedding: 就是每个Token的Embedding.
- Segment Embedding: 该Embedding起到了区分句子A和句子B的作用, 对A和B分别加以不同的编码.
- Position Embedding: 与GPT一样, 位置信息也是学习来的, 而非公式计算.
Pre - trained Task
BERT采用了两种无监督任务, 使BERT能学到双向的上下文信息, 而且这种信息不是通过Forward和Backward获取的, 而是一次性获得的, 这就促使BERT成为一个双向语言模型. 在论文中, 指出预训练BERT的损失函数为下述两个任务的损失和.
Masked Language Model
在双向深度的结构中, 会伴随着信息泄露, 在原文中称为”See itself“, 模型能够通过深层网络来自两个方向的信息得知此处的内容. 为了训练这种网络, BERT训练时采用随机Mask的方法, 使BERT必须通过上下文预测出这个位置的Token, 然后用极大似然来调整参数. 这其实就是在模仿我们做完形填空, 该方法也就是BERT能被称之为双向语言模型的根本原因.
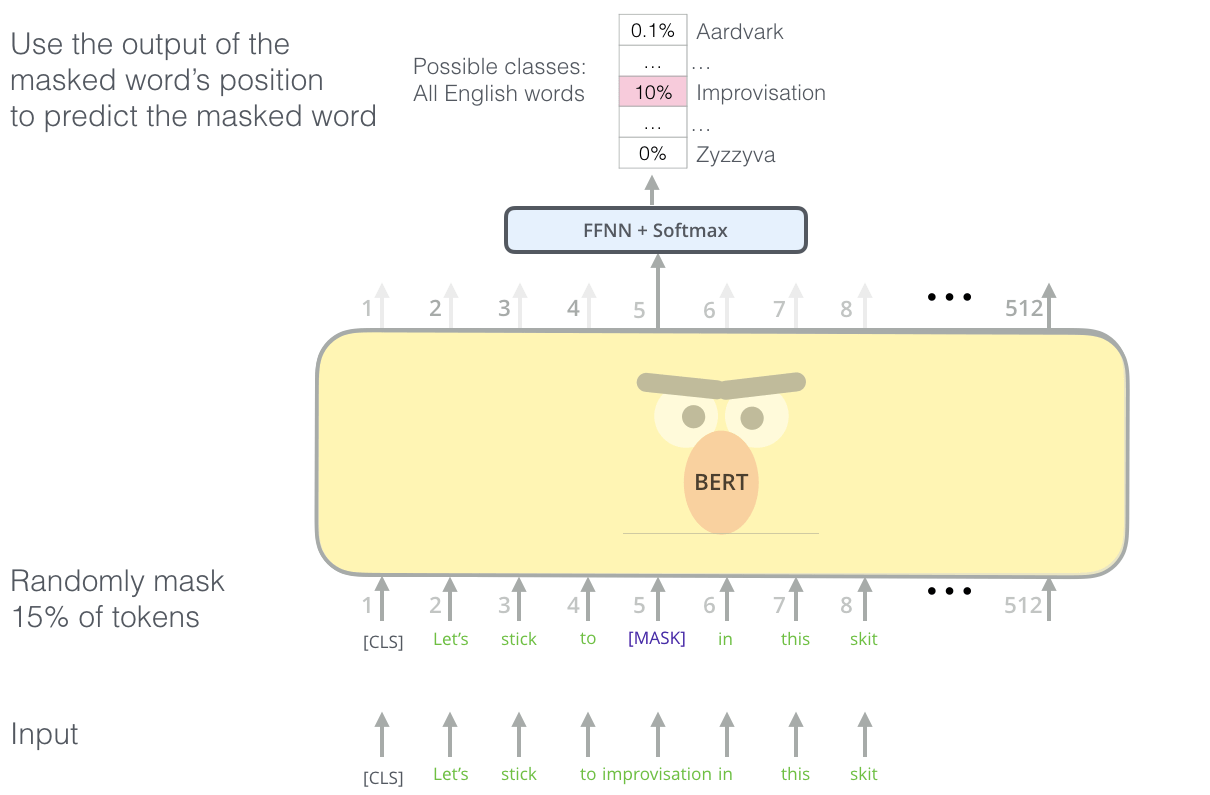
这种方法为什么有效?
因为BERT使用的是Transformer Encoder, 与Decoder不同, 是一种不带有自回归性的结构, 在Mask后, 无论怎么阅读句子, 对已经被Mask的位置内容都不可知, 只能强迫BERT根据上下文进行推测.
因此, 该任务中, BERT直接根据上下文推测, 而非像ELMo一样采用两个单向的结构:
$$
P\left(w_{i} \mid w_{1}, \ldots, w_{i-1}, w_{i+1}, \ldots, w_{n}\right)
$$
你看这式子, 是不是和CBOW非常像?
但是在Fine tune的时候不可能对单词进行Mask, 这样就会导致预训练和微调的不匹配, 为缓解这种问题, 在每个句子中, 有15%的词会被选中, 在选中单词后有三种可能性:
- 80%的概率将被选中的单词替换为
[MASK]. - 10%的概率将被选中的单词替换为随机词.
- 10%的概率对被选中的单词不进行替换.
这就给BERT一种非常迷惑的感觉, “即使没有Mask的单词仍然有可能是错的, 知道的也要预测, 不知道的还要预测“. 这就更加强迫BERT除了学到上下文关联外, 对每个词必须有理解能力.
另外, 随机替换在语料充足时并不会降低太多的模型性能, 因为它只有1.5%的几率发生.
当然, 因为每次只预测15%的Token, 模型的收敛速度会下降.
Next Sentence Prediction
另一种无监督任务比较好理解, 就是让BERT根据句子A和句子B, 在[CLS]处输出这两个句子是否是连贯的上下文. 无论是QA问题, 还是自然语言推理(NLI), 都是建立在理解相邻文本该关系基础之上的.
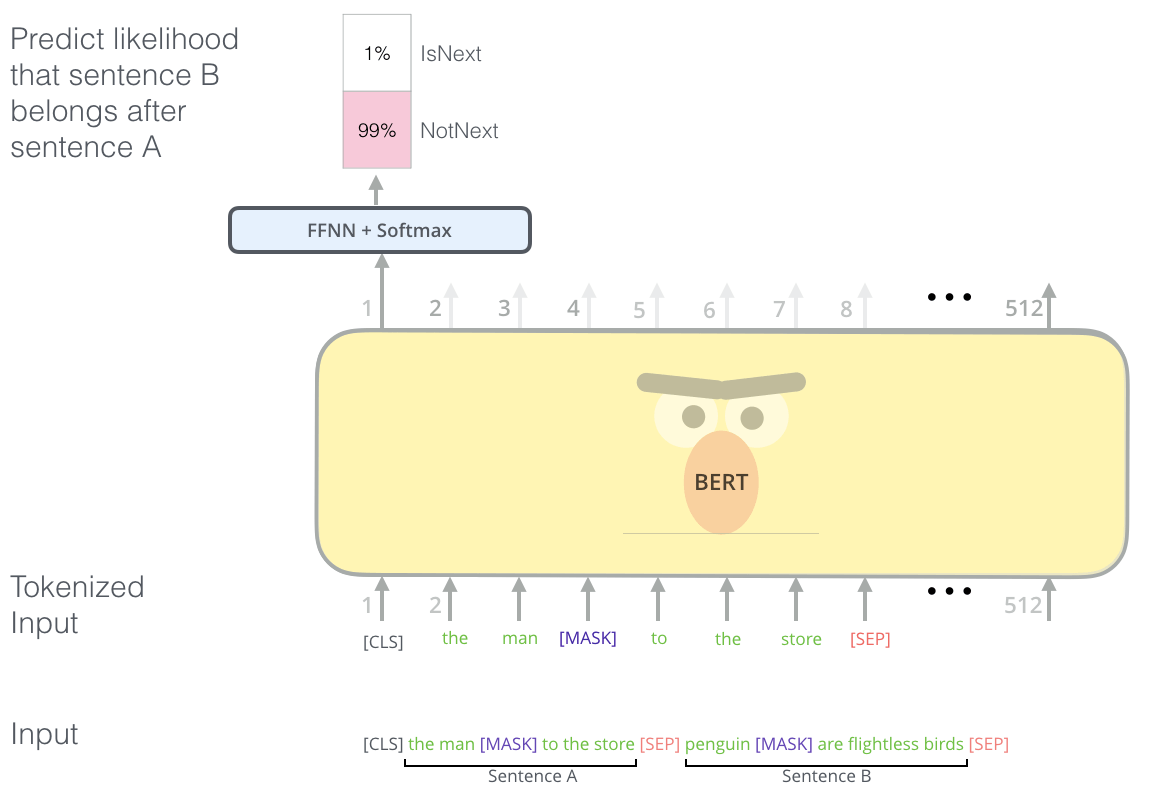
在挑选两个句子时, 句子A与B是否相关各有50%的几率.
论文中给出示例如下:
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext##less是word piece产生的, 先挖个坑以后填.
Fine - Tune
从预训练到微调, BERT可以很轻松的发生转换:
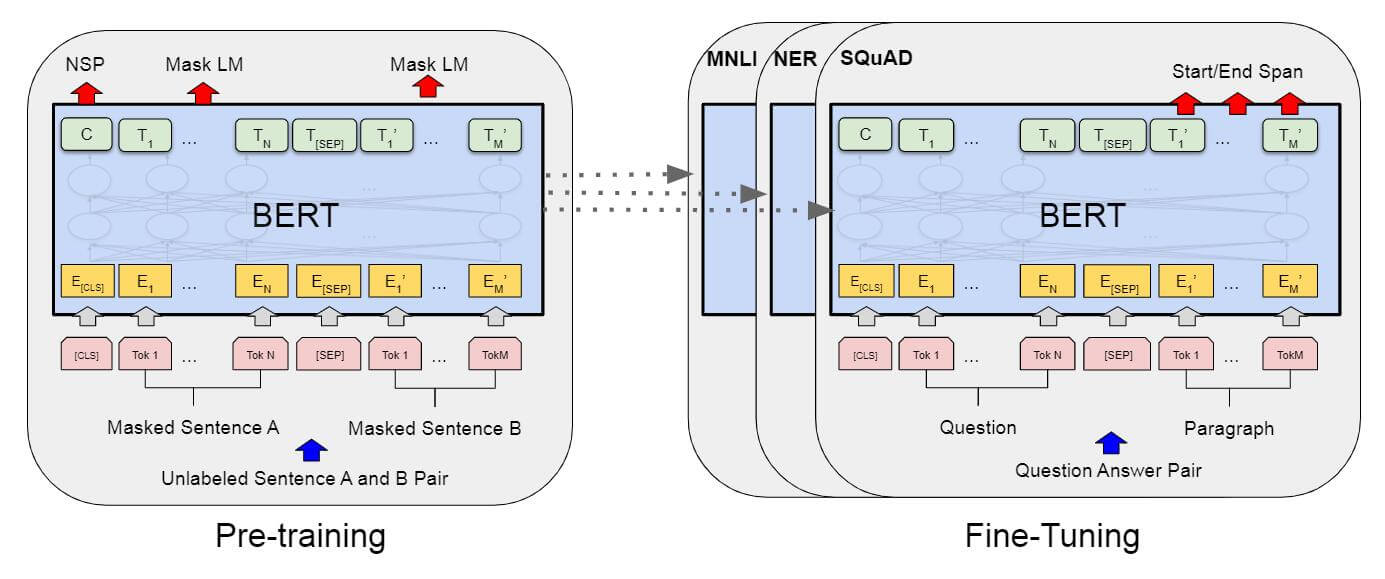
$C$ 为[CLS]对应位置的最终输出, $T_i$ 代表第$i$ 个Token对应位置的输出. $E_i$ 代表Embedding.
在不同任务上的微调方式可能是不同的, 但仍然不用对模型结构进行改动:
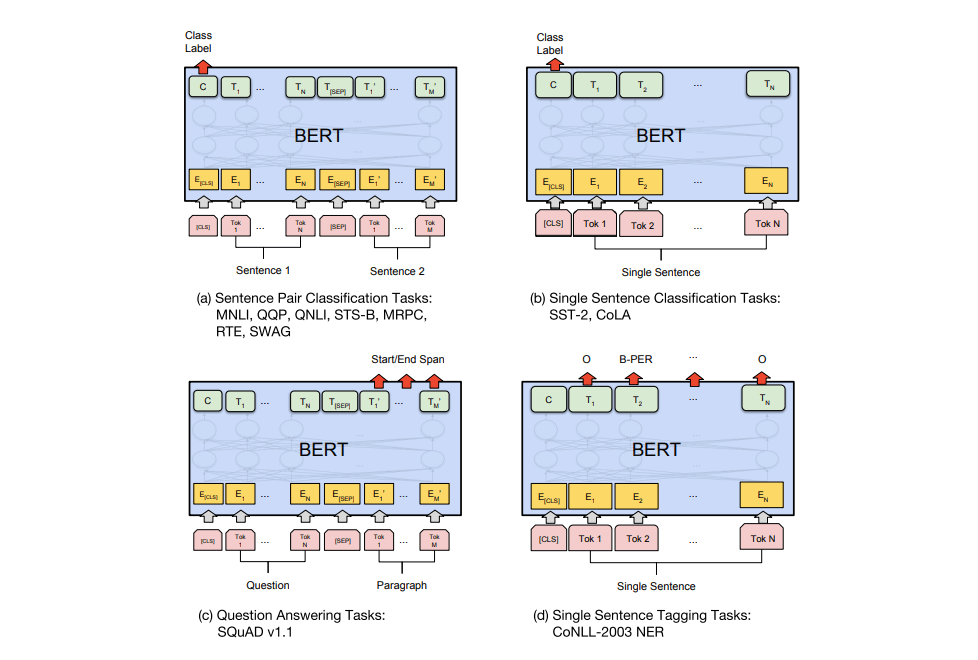
图中的四类任务分别为:
(a): 句子匹配分类任务.
(b): 单个句子分类任务.
(c): QA类任务. SQuAD中问题的答案一定在原文中会出现, 所以输出的是在原文中起始和结束的位置.
(d): 命名体识别任务.
(a)和(b)是Sequence级的任务, (c)和(d)是Token级的任务. BERT在这些任务上都有具体的处理方法, 详情参见论文.
BERT in One Word
总的来说, BERT像一个近些年人们在NLP上探索成果的融合, 但结合了自监督学习, Token Mask + 双向LM训练, Pre - train + Finetune的思想, 将Transformer, 位置编码一起使用. 现在NLP已经进入到BERT时代, 几乎由BERT魔改得到的模型都能取得显著的成果.
Summary
这部分, 我们把ELMo, GPT, BERT三个模型放在一起来看, 可能有些零碎.
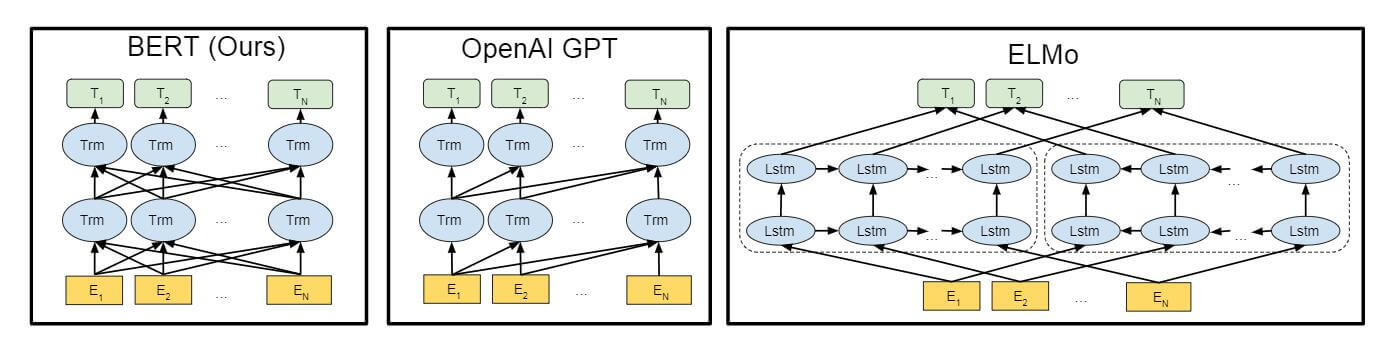
在三个模型中, 只有BERT是真正能够捕捉所有层的上下文信息的. 这受益于Transformer中的自注意力机制, 将所有Token之间的距离直接缩短到1, 加权求和. ELMo和GPT都是单向捕捉信息的.
三个模型的Basic Block: LSTM, Transformer Decoder, Transformer Encoder. GPT和BERT都是用Transformer组件作为基础Block.
GPT在预训练时并没有引入
[CLS]和[SEP], BERT全程引入.GPT和BERT是基于微调的方法, 模型结构不用发生变化, 而ELMo是基于特征的方法, 仅用于抽取特征.
对Input来讲, ELMo在Embedding后用字符级CNN, GPT采用BPE, BERT用了Word Piece. GPT有位置编码, BERT有位置编码和段编码. 这些不同也与模型的输入方式有关.

