ConvBERT: Improving BERT with Span-based Dynamic Convolution
本文前置知识:
- Light Weight Convolution: 详见基于轻量级卷积和动态卷积替代的注意力机制.
- Depthwise Separable Convolution, Group Convolution: 详见深度可分离卷积与分组卷积.
- BERT: 详见ELMo, GPT, BERT.
本文是论文ConvBERT: Improving BERT with Span-based Dynamic Convolution的阅读笔记和个人理解. 属于随缘填坑系列.
Basic Idea
作者发现, BERT的中所使用的Self Attention每次请求都需要全局的信息, 但实际上并不是每次Attention都需要全局信息, 有时只需要局部信息即可, 所以Attention总是伴随着计算冗余, 总体来看BERT也没有高度局部化的操作, 但很多头部都只学习了自然语言局部信息.
因此, 作者希望能够使用一种直接捕捉局部信息的方法, 从而降低Attention的复杂度.
ConvBERT
Motivation
既然作者是希望能够获得捕捉局部信息的能力, 还对参数压缩有一定的需求, 那么很容易就想到了用卷积.
在经典Transformer中的Attention机制的公式为:
$$
\operatorname{Self}-\operatorname{Attn}(Q, K, V)=\operatorname{softmax}\left(\frac{Q^{\top} K}{\sqrt{d_{k}}}\right) V
$$
即最简单的缩放点积, 在这里就不多做说明了.
Parameters Redundancy
Self - Attention在处理问题时可能会存在参数冗余的问题:

从BERT的注意力中能够看到, 相当多的权重被分配在在对角线邻近的位置上, 说明了自然语言结构中的邻近信息在很多时候是起作用的, 这也引起了相当多的权重冗余.
Convolutional based Attention
在前面的研究工作中介绍过, 使用卷积能够一定程度上来缓解参数冗余的问题, 例如轻量级卷积:
$$
\operatorname{LConv}(X, W, i)=\sum_{j=1}^{k} W_{j} \cdot X_{\left(i+j-\left\lceil\frac{k+1}{2}\right\rceil\right)}
$$
以及以轻量级卷积为基础, 做出一定改进的动态卷积:
$$
\operatorname{DConv}\left(X, W_{f}, i\right)=\operatorname{LConv}\left(X, \operatorname{softmax}\left(W_{f} X_{i}\right), i\right)
$$
Span - based Dynamic Convolution
在基于轻量级卷积和动态卷积替代的注意力机制中提到过:
注意力权重的生成只取决于当前时刻的输入, 而与前时刻和后时刻输入无关, 这是一个严重缺陷.
基于这个改进点, 作者将当前时刻输入的邻近信息也加入了动态调整当前时刻输出的机制, 并称之为区间动态卷积.
自注意力, 动态卷积, 区间动态卷积这三者之间的差别能够很容易的用如下图示对比, 也可以顺带引出区间动态卷积的本质:
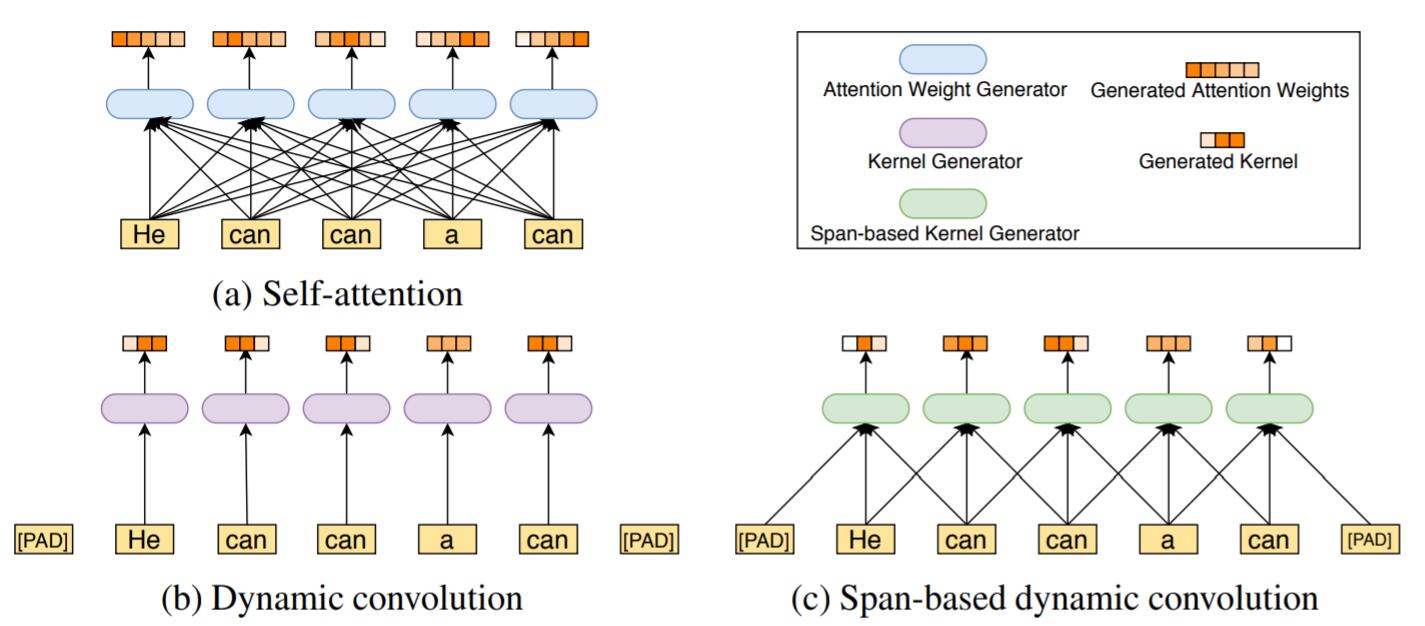
自注意力与所有基于卷积方法, 特征之间有更加稠密的影响, 但在作者的论文中认为许多交互是不必要的, 即存在特征冗余, 导致了模型参数的冗余. 动态卷积的当前时刻输出仅会取决于当前时刻输入, 结合周围语义动态调整权重的能力比较差, 因为它分配权重时完全没有结合上下文信息. 区间动态卷积算是在二者之间取了个折中, 能结合小区间范围内的信息对卷积核的参数做更好的权重分配, 即能够契合语言局部性的特点, 也能结合语境做出判断.
因此, 考虑将区间动态卷积和自注意力兼容, 需要考虑一种结合区间信息动态生成卷积核的方法. 作者使用输入$X$ 用Self - Attention的方式生成对应的$Q$ 和 $V$, 接着使用深度可分离卷积抽取与区间内容相关的$K_s$, 然后动态地生成卷积核权重:
$$
f\left(Q, K_{s}\right)=\operatorname{softmax}\left(W_{f}\left(Q \odot K_{s}\right)\right)
$$
$\odot$ 为逐元素点乘, $W_f$ 为可训练的权重矩阵.
自注意力, 动态卷积, 区间动态卷积三者的运算流程结构图如下:
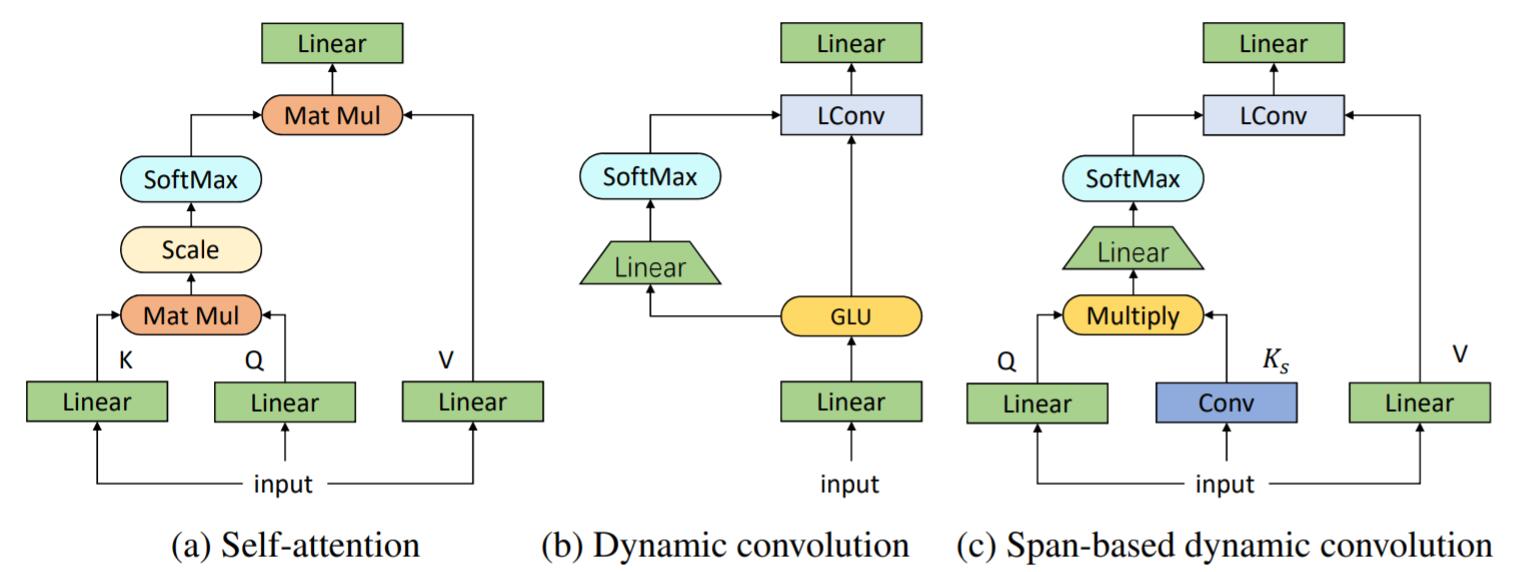
明显的能看出来, 在附加了局部信息后, 区间动态卷积与动态卷积相比更像自注意力, 仅替换了某些线性算子, 相较动态卷积而言去掉了GLU, 不会引入过多的参数.
将这种生成卷积核的方式融入轻量级卷积, 称为区间动态卷积:
$$
\operatorname{SDConv}\left(Q, K_{s}, V ; W_{f}, i\right)=\operatorname{LConv}\left(V, \operatorname{softmax}\left(W_{f}\left(Q \odot K_{s}\right)\right), i\right)
$$
与动态卷积的式子相比, 将$\operatorname{LConv}$ 中的第一个参数由输入$X$ 替换为自注意力模式中的$V$, 并将生成卷积核参数的方式替换为结合区间信息的$\operatorname{softmax}\left(W_{f}\left(Q \odot K_{s}\right)\right)$.
ConvBERT Architecture
Mixed Attention
因为自注意力机制和区间动态卷积是可以兼容的, 所以可以将这二者以某种形式混合起来.
混合Attention就是将区间动态卷积与Self - Attention做了混合, 这二者之间是没有交互的, 直接通过一个Concat操作将二者拼接起来:
$$
\text {Mixed-Attn}\left(K, Q, K_{s}, V ; W_{f}\right)=\operatorname{Cat}\left(\text {Self-Attn}(Q, K, V), \operatorname{SDConv}\left(Q, K_{s}, V ; W_{f}\right)\right)
$$
这样的设计可以让模型不仅限于局部特征的捕捉, 而是以多角度来捕捉整个文本的信息.
自注意力和区间动态卷积共享相同的$Q, V$, 使用不同的方式来生成$K$.
Bottleneck Design for Self - Attention
针对冗余参数, Bottleneck的设计能够有助于模型学习到更紧凑的信息:
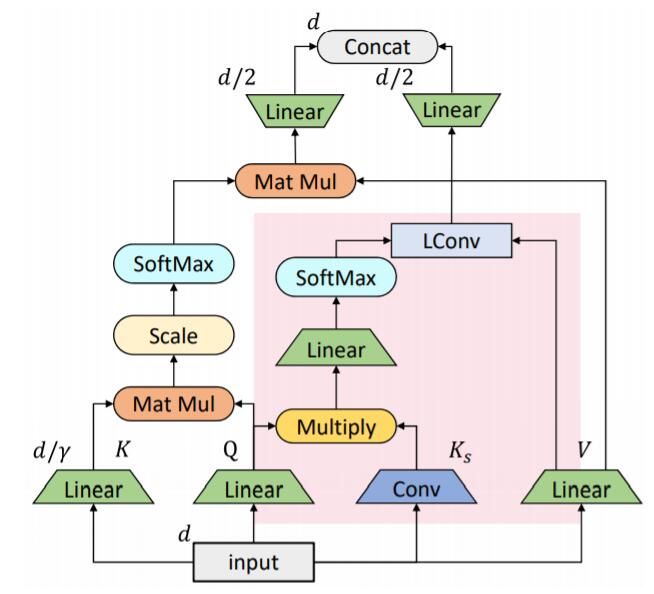
作者提出的Bottleneck加入缩放因子$\gamma$ , 当$\gamma>1$ 时, 将特征维数缩小为$d/\gamma$, 并降低注意力头的数量为原来的$1/\gamma$.
同时, 这样的设计也可以保证模块的有序堆叠, 输入大小和输出大小一致.
Grouped Feed - Forward Module
因为FFN中占了很多参数, 所以作者希望通过分组的方式来减小开销. 与多头注意力类似, 分组卷积分别将特征分组提取后再Concat起来:
$$
\displaylines{
M=\Pi_{i=0}^{g}\left[f_{\frac{d}{g} \rightarrow \frac{m}{g}}^{i}\left(H_{\left[:, i-1: i \times \frac{d}{g}\right]}\right)\right], M^{\prime}=\operatorname{GeLU}(M)
\\
H^{\prime}=\Pi_{i=0}^{g}\left[f_{\frac{m}{g} \rightarrow \frac{d}{g}}^{i}\left(M_{\left[:, i-1: i \times \frac{m}{g}\right]}^{\prime}\right)\right]
}
$$
其中$H, H^\prime \in R^{n\times n}$, $M, M^\prime \in R^{n\times n}$, $f_{d_1 \rightarrow d_2}(\cdot)$ 表示将$d_1$ 维映射到$d_2$ 维的FC层. $g$ 为分组的组数, $\Pi$ 为Concat操作.
后续的实验表明, 精度下降可以忽略不计.
Experiments
在实验中, 作者使用了开源网页数据集OpenWebText(32G)来对标BERT所用的训练数据. 作者采用$\gamma=2$ 来缩小特征维度, 注意力头的数量也为原来的一半. 其余详细的实验设置请参考原论文.
Ablation Study
消融实验结果如下:
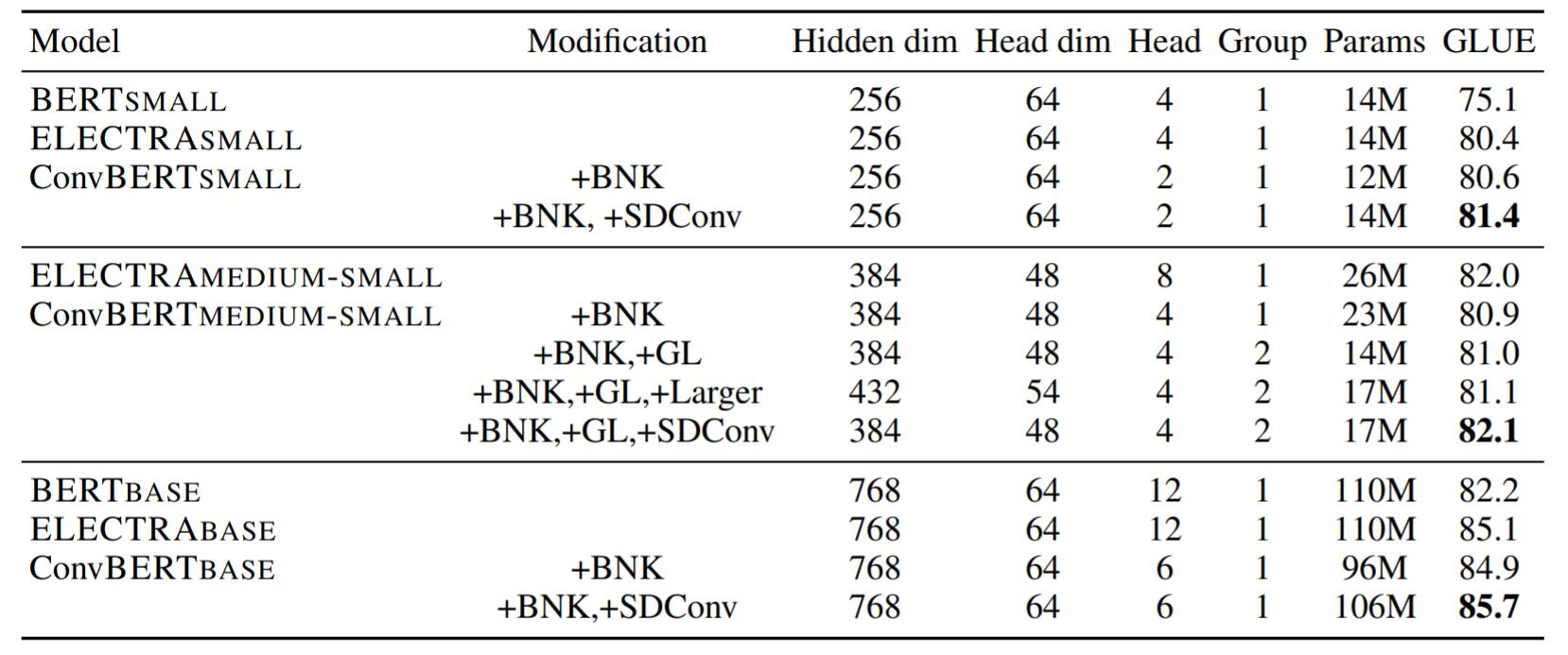
小Trick对提升模型性能有一些帮助, 但总体来说区间动态卷积的提升比较大.
Kernel Size
对于Kernel Size实验结果如下:
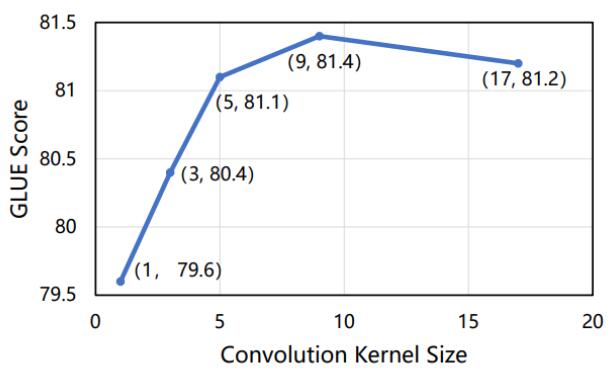
模型性能先是随着卷积核的大小提升而提升, 在达到一定阈值后性能反而下降. 很有可能是感受野逐渐扩大, 覆盖到整个输入序列, 此前性能均在提升. 而Kernel Size覆盖整个输入序列时, 模型效果稍有下降.
这个实验再一次佐证了作者的猜想.
Ways to integrate convolution
如下作者探究不同形式的卷积对模型性能的影响:

肯定是区间动态卷积比较好, 因为区间动态卷积本身就是由其他卷积形式变换而来的.
Comparison results
GLUE
其中标有十字架标志的模型是基于知识蒸馏的方法, 在GLUE上的结果如下:
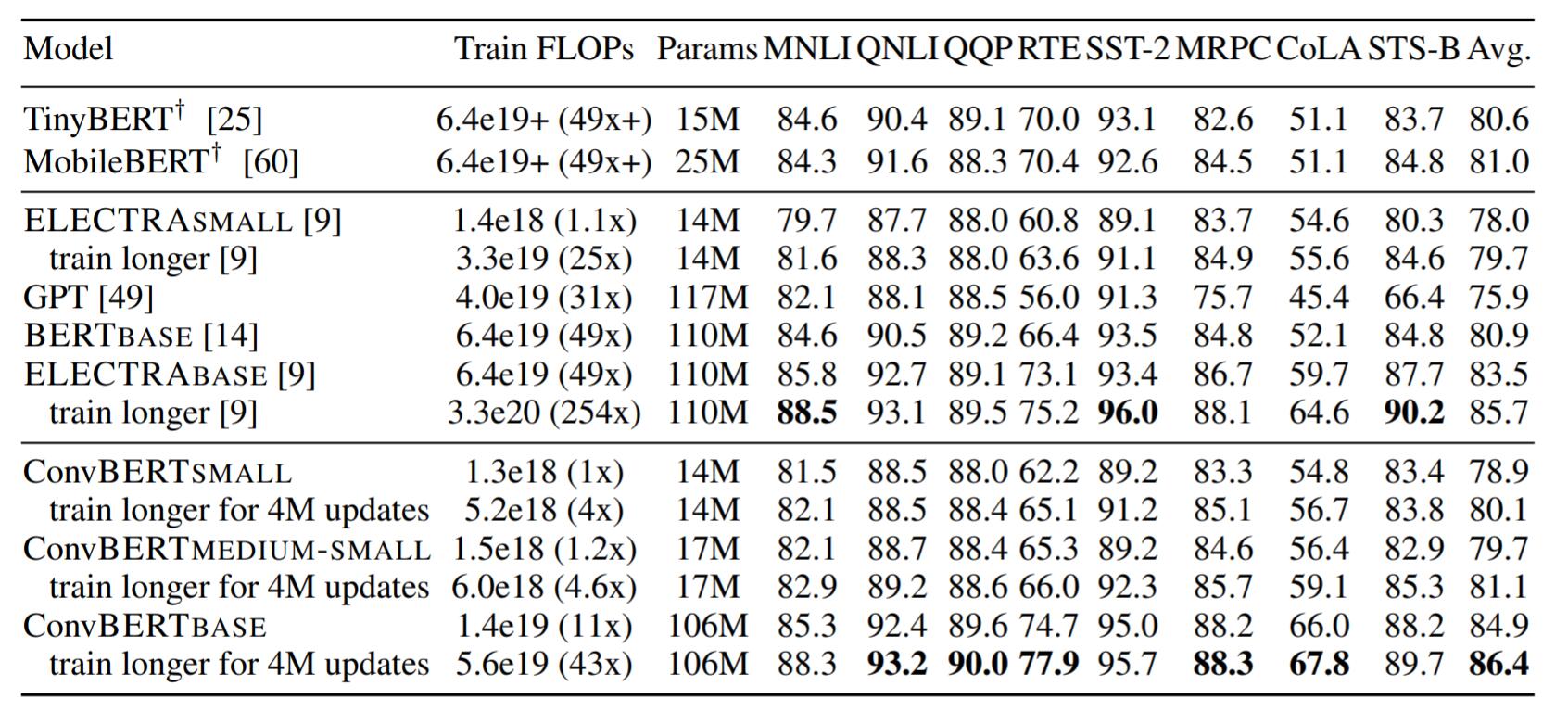
ConvBERT在低资源的情况下结果良好.
SQuAD
在问答数据集SQuAD上的结果如下:
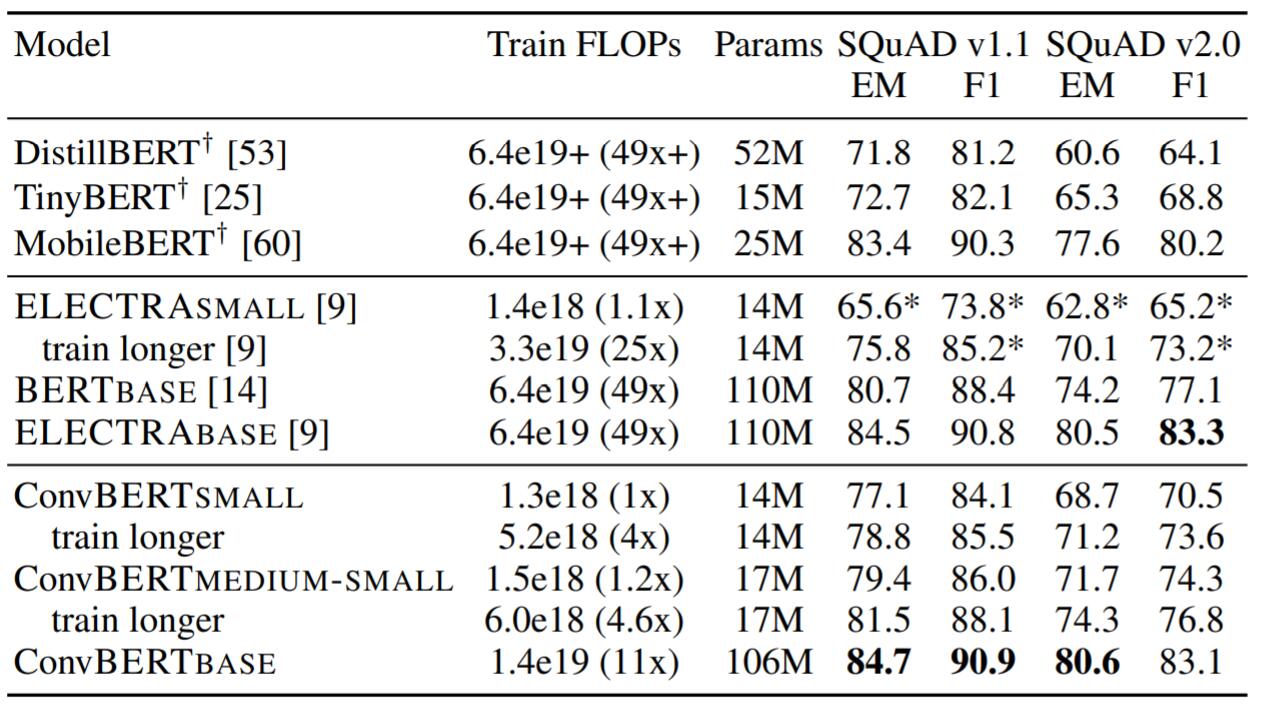
延长训练后, 虽然训练所需的计算量下降了, 但是仍然能够达到近似ELECTRA的效果. 极大地减少了训练成本.
Summary
本文中仍然是一篇NLP领域的论文, 我读它的原因主要是为了获取在Attention上改动的灵感.
作者在轻量级卷积的基础上进一步的将卷积核的权重生成动态化. 设计了一种新型Bottleneck, 进一步的优化了BERT的结构, 并在其中加入了卷积操作, 大幅的降低了训练成本, 但似乎这种方法不够简洁.
作者没有将自注意力完完全全的去掉, 也说明了NLP中Self - Attention必然是不能被其他方法直接取代的.
后面实验主要也对比的Baseline主要也是小模型系列, 不知与大模型相比效果如何(虽然有点不公平).
训练过程中也使用了一些小Trick, 没有这些小Trick可能不会有特别亮眼的效果.

