本文前置知识:
- BERT(Transformer Encoder).
PPKE: Knowledge Representation Learning by Path-based Pre-training
本文是论文PPKE: Knowledge Representation Learning by Path-based Pre-training的个人理解和阅读笔记. 论文本身非常短, 公式插图风格完全沿用了CoKE, 也出自同一研究小组.
Basic Idea
传统的KGE方法将三元组作为一个训练单元, 但忽略了图中存在的上下文拓扑结构信息. 与语言模型中的上下文一样, 关系路径能够被认为是KG中的一种上下文关系, 作者称之为”图上下文信息“.
不可靠关系在KG中常见, 但使用可靠的关系做KRL是非常必要的, 尤其是在涉及到推理的问题上.
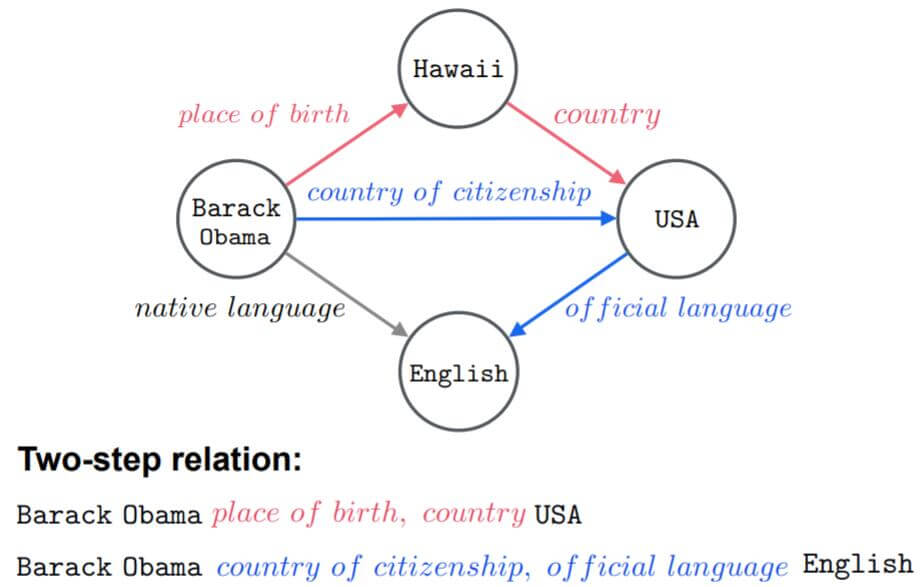
作者还指出, 前人所发现的基于路径或上下文信息的方法都无法通过基准数据集来证明图上下文信息能改善模型性能.
因此, 作者尝试提出基于路径的预训练KGE模型PPKE(Path - based Pre - training model to learn Knowledge Embeddings), 目标是将实体间的图上下文信息集成进KGE模型的参数中, 并且它是一种预训练模型.
PPKE
如果你已经了解了CoKE, 那么
基于预训练模型的思路, 模型的训练分为Pre - train和Tuning两个部分.
Path - Based Pre - training
Input Representation
头实体$h$ 到尾实体$t$ 的路径输入被表示为$\left\{h, r_{1}, \ldots, r_{n}, t\right\}$, 其中$r_i$ 代表长度为$n$ 的路径中第$i$ 跳的关系,
那么三元组$\left\{ h, r, t \right\}$ 可以被认为是路径长度$n=1$ 时的一个特殊情况.
与CoKE不太一样的是, 为了避免位置偏差, 作者将尾实体的位置放到了头实体后, 关系路径之前. 这点也是与CoKE的最大不同点.
故, 三元组的输入形式应该为:
$$
\boldsymbol{x}=\left\{h, t, r_{1}, \ldots, r_{n}\right\}
$$
为了区分实体和关系的不同角色, 必须对它们加以不同的位置编码.
这点与CoKE相同, CoKE也没有对不同的元素加以不同的类型编码, 实体和关系直接不加以区分, 只加位置编码.
如果将输入变为Embedding的形式, 如下所示:
$$
\mathbf{E} = \left\{\mathbf{E}^{h}, \mathbf{E}^{t}, \mathbf{E}^{r_{1}}, \ldots, \mathbf{E}^{r_{n}}\right\}
$$
Masked Entity Predicition
与BERT的食用方法相同, 也是用Masked Language Model的训练方式来训练. 针对Link Prediction任务, 只需要将要预测的实体所在位置打上[Mask]. 例如:
$$
\begin{aligned}
\mathrm{Input} &=[\text {Barack Obama}] [\text{MASK}] [place\ of\ birth] [country] \\
\mathrm{Label} &=[\text{USA}]
\end{aligned}
$$
其中$[\cdot]$ 代表输入的元素.
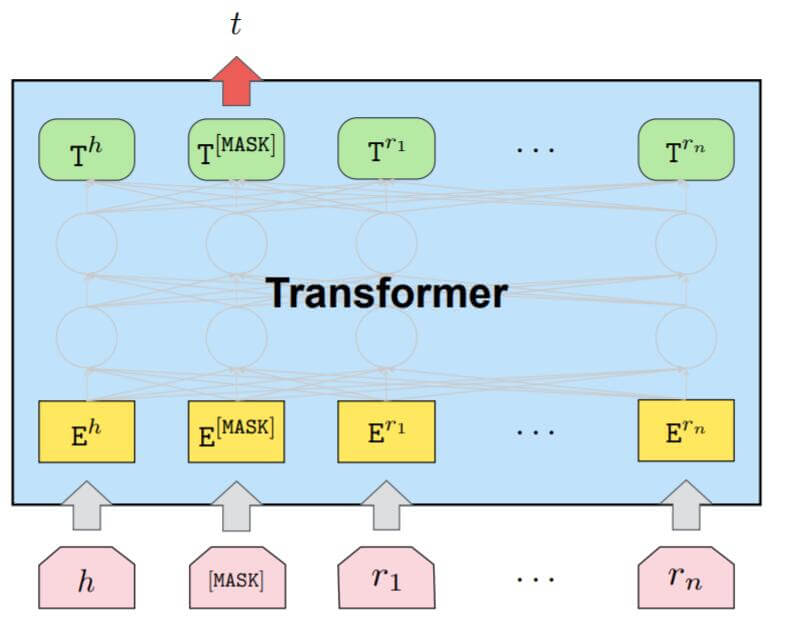
与上图一致, PPKE使用Transformer Encoder对图上下文信息编码, 假设$e$ 为被Mask的实体, $\mathbf{T}^{[\mathrm{MASK}]}$ 代表$[\text{MASK}]$ 位置上的隐态输出, 那么目标就是最大化$[\text{MASK}]$ 位置的输出分类概率:
$$
\begin{aligned}
\boldsymbol{p}^{[\mathrm{MASK}]} &=\operatorname{softmax}\left(\mathbf{T}^{[\mathrm{MASK}]} \cdot \mathbf{V}^{\mathcal{E}}\right) \\
\mathcal{L} &=-\log \boldsymbol{p}_{e}^{[\mathrm{MASK}]}
\end{aligned}
$$
其中$\boldsymbol{p}^{[\mathrm{MASK}]} $ 为实体词表中的候选实体的概率向量, $\mathbf{V}^{\mathcal{E}}$ 为实体的Embedding矩阵.
然后用极大似然来优化模型参数:
$$
\hat{\boldsymbol{\theta}}=\underset{\boldsymbol{\theta}}{\operatorname{argmax}} \sum_{\left(\boldsymbol{x}, \boldsymbol{m}_{e}\right) \in \mathcal{X}} \log p\left(\boldsymbol{x}_{e} \mid \boldsymbol{x} \circ \boldsymbol{m}_{e} ; \boldsymbol{\theta}\right)
$$
Fine - tuning
Link Prediction
链接预测的目标是预测三元组中缺失的头实体$h$ 或者尾实体$t$. 即预测$((h, r, ?) \rightarrow t)$, 或者$((?, r, t) \rightarrow h)$.
详细的例子如下:
$$
\begin{aligned}
\text { Input }_{\text {head }}&=[\text{MASK}] \text {[USA]}[country\ of\ citizenship] \\
\text { Label }_{\text {head }}&=[\text {Barack Obama}] \\
\text { Input }_{\text {tail }}&=[\text {Barack Obama}] \text {[MASK]} [country\ of\ citizenship]\\
\text { Label }_{\text {tail }}&=[\text{USA}]
\end{aligned}
$$
对于这类任务, 给定训练集$\mathcal{D}_{x e}$, 训练目标是最大化给定数据集中由输入预测出实体$e$ 的概率:
$$
\hat{\boldsymbol{\theta}}_{\boldsymbol{x} \rightarrow \boldsymbol{e}}=\underset{\boldsymbol{\theta}_{\boldsymbol{x} \rightarrow e}}{\operatorname{argmax}} \sum_{\boldsymbol{x} \in \mathcal{D}_{\boldsymbol{x} e}} \log p\left(e \mid \boldsymbol{x} ; \boldsymbol{\theta}_{\boldsymbol{x} \rightarrow \boldsymbol{e}}\right)
$$
Relation Prediction
与Link Prediction类似, 任务由预测三元组中的头尾实体变为了预测它们之间的关系$r$, 即$((h, ?, t) \rightarrow r)$. 例如:
$$
\begin{aligned}
\text { Input }_{\text {rel }}&=[\text {Barack Obama}][\text {USA}] \text {[MASK]} \\
\text { Label }_{\text {rel }}&=[country\ of\ citizenship]
\end{aligned}
$$
同样的, 给定训练集$\mathcal{D}_{\boldsymbol{x} \boldsymbol{r}}$, 目标是最大化给定数据集中由输入预测出关系$r$ 的概率:
$$
\hat{\boldsymbol{\theta}}_{\boldsymbol{x} \rightarrow \boldsymbol{r}}=\underset{\boldsymbol{\theta}_{\boldsymbol{x} \rightarrow r}}{\operatorname{argmax}} \sum_{\boldsymbol{x} \in \mathcal{D}_{\boldsymbol{x} r}} \log p\left(r \mid \boldsymbol{x} ; \boldsymbol{\theta}_{\boldsymbol{x} \rightarrow \boldsymbol{r}}\right)
$$
所以针对任务和数据集进行Fine - tuning时, 作者使用的全部是三元组.
Experiments
作者主要针对FB15k, FB15k - 237, WN18RR这三个数据集做了实验.
Settings
在预训练的阶段, 作者只使用了两跳关系组成的组合$(h, r_1, r_2, t)$, 称为四元组进行预训练. 受制于计算资源的限制, 作者在FB15k - 237和FB15k上只随机选取了一部分作为数据集. 其余的参数设置请参见原论文.
Results
Link Prediction
在FB15k - 237和WN18RR上的Link Prediction结果如下:
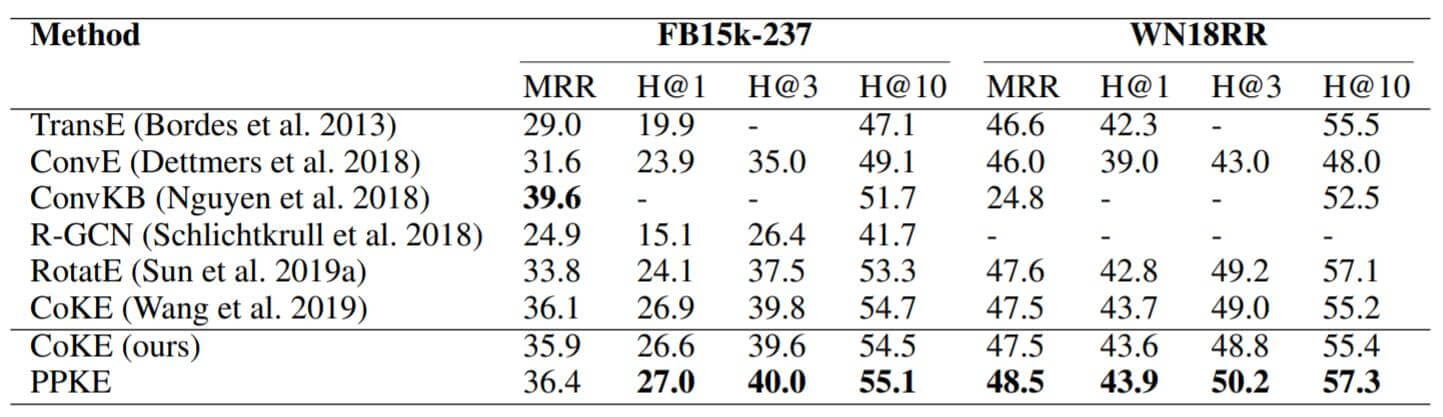
使用的Baseline比较有代表性, 也包括了之前的工作CoKE. PPKE取得了不错的效果, 尤其是在WN18RR上表现比较好.
当然我觉得可能还有来自于训练方式上的收益, 预训练可能会带来更高的精度.
Relation Prediction
作者在FB15k和FB15k - 237上的Relation Prediction结果如下:
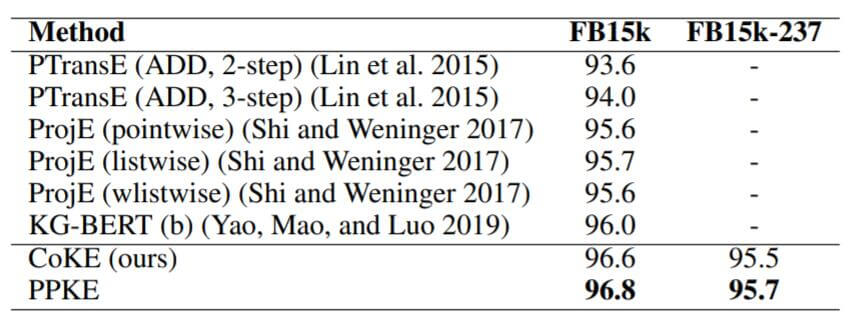
能够看到, 作者给出的Baseline只在FB15k上有结果, 而FB15k - 237上只与CoKE做了对比. 预测数据集中的关系比预测实体要简单的多. 所以CoKE和PPKE的差距并不是很大.
Discussion
Ablation study
为探究PPKE取得好效果的原因, 作者将CoKE, 预训练和未预训练的PPKE做了对比:
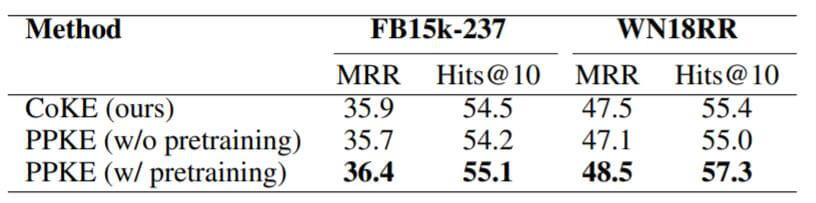
如果只看MRR和Hits@10的话, 不使用预训练的PPKE比CoKE的结果还要差一些, 结果大致相同, 作者认为差异来自于参数差异. 但是引入预训练后, PPKE的性能有很大提升.
Visual Illustration
同样使用了类似CoKE的实验手法, PPKE也是用T - SNE做了可视化:

作者将预训练过程中头尾实体相同的三元组和四元组做采样, 将尾实体Mask掉后让已经预训练好的模型去预测尾实体, 然后对得到的隐态输出做降维可视化.
不同的颜色代表不同的采样组, 相同的颜色中的点拥有一致的头尾实体, 圆点代表三元组预测得出的隐态输出, 倒三角代表四元组预测得出的隐态输出.
在大多数的采样组中, 聚合度都很高, 意味着PPKE无论对于三元组和四元组的分类结果都比较好, 包含路径的知识已经被注入到参数中.
Summary
PPKE总体上来说是CoKE的延续, 与CoKE差距很小. 其主要贡献是将预训练思想引入了KGE领域中(其实这点很重要), 分为预训练和Fine - tuning两个阶段.
总感觉在预训练和精调时候使用的数据输入模式不太一样有点怪怪的, 但BERT也是一个怎么使用都可以的结构, 再加上作者已经对三元组和四元组输入都做了实验, PPKE能起作用也不足为奇了.
