本文前置知识:
- BERT: 详见ELMo, GPT, BERT.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
本文是论文ALBERT: A Lite BERT for Self-supervised Learning of Language Representations的阅读笔记和个人理解. 最近忙着毕业季, 赶巧眼病又发作了, 就拖更了几天.
Basic Idea
现有的NLP模型都太大了, 计算资源短缺已经成为越来越显著的问题.
一般来说, 参数到达一定数量后增加参数只能带来轻微的性能提升, 模型参数过多后还容易出现过拟合, 反而导致性能下降. 作者尝试使用减少参数的多种方法, 构造一个轻量级的BERT, 能逼近原BERT的效果.
ALBERT
ALBERT(A Lite BERT)尝试使用三种主要的手段来节省额外的参数开销.
Factorized Embedding Parameterization
在BERT系列模型架构中, Token的Embedding大小$E$ 和Encoder的Hidden Layer大小$H$ 是完全绑定的, 即$E \equiv H$, 独热编码会直接通过Embedding转换到大小为$H$ 的维度.
从建模角度来说, Word Embedding更多强调上下文无关的表示, 即Token本身在无语境时最多出现的意思, 而Hidden Layer Embedding更多强调上下文相关的表示. 但实际上我们应该希望上下文相关的部分能使用更多参数, 即$H \gg E$, 这样能最大化BERT中的参数的使用效率.
从实践角度来说, NLP经常需要非常大的字典大小$V$, 如果$E \equiv H$, 增大$H$ 的同时必然增大$E$, $H$ 和$E$ 绑在一起的思路就不太实用.
因此, ALBERT将这一部分拆分为两步, 把独热编码直接转换到$H$ 的过程拆分为两个步骤, 先映射到低维嵌入空间$E$, 然后再投影到隐层大小$H$. 这样就将Embedding这部分的参数大小从$O(V \times H)$ 缩少到$O(V \times E + E \times h)$. 当$E\ll H$ 时能减少很多参数.
例如, 词表大小$V=30000$, 在BERT中, $E=H=768$, 不考虑位置编码, Embedding的总参数为$30000 \times 768$. 在ALBERT中, $E \ne H$, 假设$E=128, H=768$, Embedding总参数为$30000 \times 128 + 128 \times 768$, 确实有减少.
Cross - Layer Parameter Sharing
因为BERT是Transformer Encoder堆叠起来的, 假如只用训练一组共用参数, 然后让所有层都使用这一组参数, 岂不是能大幅减少参数? 确实, ALBERT利用这种方法减少了相当多的参数量.
但即使是多层参数复用, 也有多种复用方法. 每个Transformer Encoder由FFN和Multi Head Attention组成, 所以就有仅复用Attention, 仅复用FFN, 直接复用Encoder三种复用方式, 作者在后文的实验中探索了这三种方式的效果.
下图为每一层中同一个Token的表示的L2距离和余弦相似度:
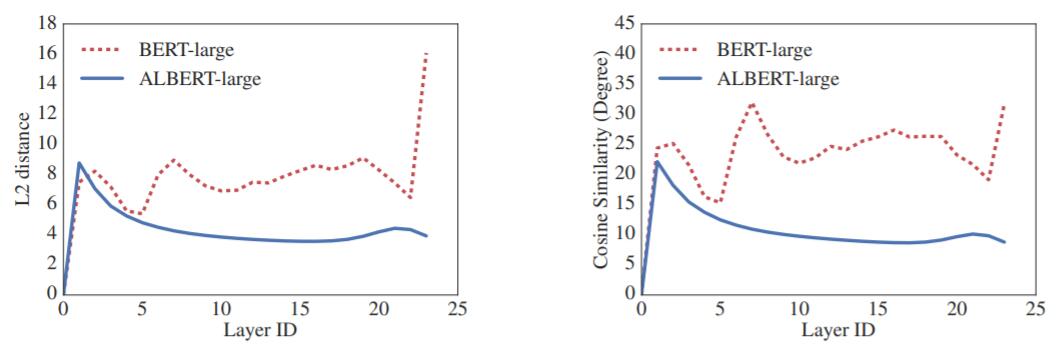
ALBERT比BERT的曲线要平滑得多, 这说明共享参数有助于稳定网络参数.
跨层的参数共享, 应该是ALBERT中减少参数最有效的方法, 对于共享参数对性能产生的负面效果, 在训练阶段使用一些Trick能弥补一些.
Inter - Sentence Coherence Loss
作者指出, NSP任务是可以偷懒的. NSP任务将同一个文档中的两个连续句子的句子对作为正例, 将不同文档的两个句子的句子对作为负例. 因此, NSP任务实际上可以划分为Topic Prediction和Coherence Prediction两个任务:
- Topic Prediction: 预测前后两个句子的主题是否相同.
- Coherence Prediction: 预测前后两个句子是否是真正连续的.
Topic Prediction的难度远小于Coherence Prediction, 所以NSP不一定能真正有益于模型在下游任务上的表现, 也符合其他研究人员的结论.
ALBERT也废除了NSP任务, 但从NSP的Coherence Prediction角度出发, 设计了SOP(Sentence Order Prediction)任务. SOP任务保留Coherence Prediction, 将同一个文档中顺序正确的两个连续句子的句子对作为正例, 将它们交换顺序后的句子对作为负例, 这样就消除了Topic Prediction的目标.
Experiments
详细的参数设置请参照原论文, 作者将ALBERT在实验中所用到的几个设置与BERT进行了对比:
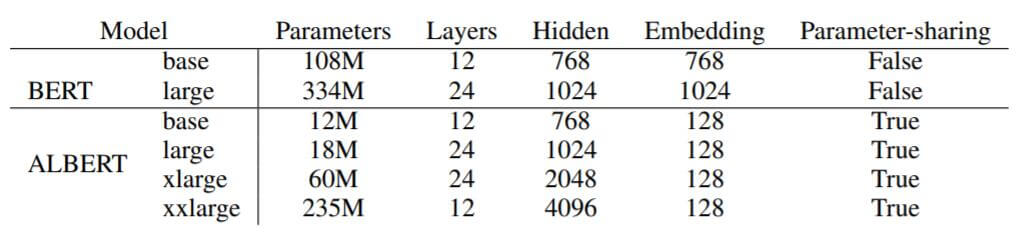
ALBERT - xxlarge的层数是12而非24, 说明此时宽的模型比深的模型效果要更好, 可能层数已经达到极限.
4096的HIdden Size与BERT - large相比已经相当大了.
与BERT不同的是, ALBERT在90%的情况下都使用最大的文本输入长度, 仅有10%的概率使用比最大文本长度更小的输入.
并且, 作者借鉴了SpanBERT中的N - Gram Masking, 即每次生成Mask都有$p(n)$ 的概率生成长度为$n$ 的Mask:
$$
p(n)=\frac{1 / n}{\sum_{k=1}^{N} 1 / k}
$$
作者设置最大长度$n=3$.
Overall Comparision between BERT and ALBERT
作者将BERT的各类配置与ALBERT的各类配置在相同训练量的多个任务上做了实验, 结果如下:

ALBERT - xxlarge应该是打榜用的, 性能超过了BERT - large. ALBERT - large的性能已经接近于BERT - large.
在作者设置的ALBERT配置中, 同等型号的ALBERT比BERT的速度要快一些, 但同等型号的ALBERT性能却要比BERT差许多. 只有跨配置比较, 才能保证性能相似, 但跨配置的ALBERT在推理速度上不占优势.
Factorized Embedding Parameterization
作者调整了ALBERT - base的$E$ 大小, 分别对比了共享参数和不共享参数的情况.

从结果来看, 在复用Encoder的情况下, $E=128$ 似乎是一个比较好的解, $E > 128$ 性能开始退化.
Cross - Layer Parameter Sharing
针对仅复用Attention, 仅复用FFN, 直接复用Encoder三种情况, 作者在各类下游任务上做了实验, 结果如下:
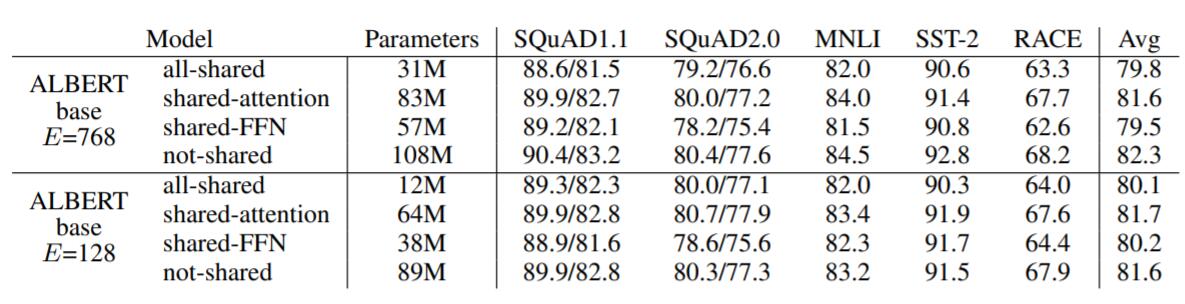
不共享参数的情况自然是性能最好的, 共享FFN似乎比较容易掉点.共享Attention影响没有那么大. 作者坚持复用Encoder的策略.
Sentence Order Prediction (SOP)
作者比较了不使用额外任务, NSP, SOP三者之间对ALBERT - base的影响, 结果如下:

使用NSP确实会损害模型性能, 使用SOP确实会让模型涨点, 但是SST - 2的性能和不使用额外任务相当.
Train for the Same Amount of Time
在前面的实验中, ALBERT - xxlarge比BERT - large的速度要慢许多. 通常情况下, 更长的训练时间会有更好的性能, 这可能导致二者比较的不公平.
作者在此不再控制二者训练量相同, 而是将BERT和ALBERT拉到了相同训练时间下比较, 结果如下:

在同训练时间下, ALBERT要优于BERT, 即ALBERT训练较为高效.
Additional Training Data and Dropout Effects
RoBERTa和XLNet比BERT所使用的数据要多得多, 作者尝试将额外的训练数据添加到训练中, 前后对比结果如下:

除去SQuAD, 其他下游任务的性能略有提升, 这是因为除去维基百科的数据集, 其他数据相对于SQuAD来说是一种噪声, 即Out of Domain, 也许维基百科数据集已经能比较有针对性的解决SQuAD问题了.
即使是训练了1M Step, ALBERT也没有找到局部最优, 所以作者在ALBERT上去掉了Dropout, 使得性能有进一步的提升:
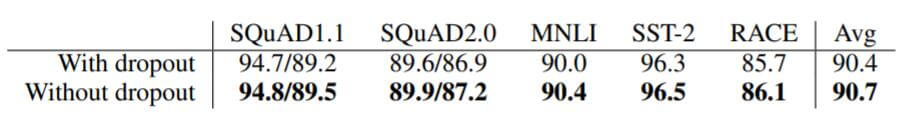
其实很好理解为什么去掉Dropout后模型能继续训练下去, 模型本身都没法达到过拟合, 何谈防止过拟合? 在模型没能找到局部最优时, 加入正则化手段自然而然会损害训练.
上面二者在训练过程中对ACC的影响如下:
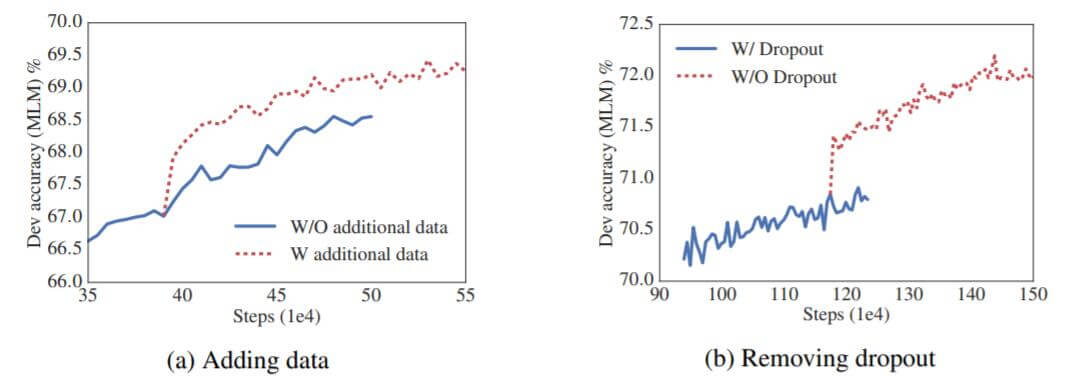
添加额外数据和移除Dropout后, 验证集ACC有显著提升.
Current SOTA and NLU Tasks
作者把流行的Baseline放到一起在GLUE上做了对比, 结果如下:
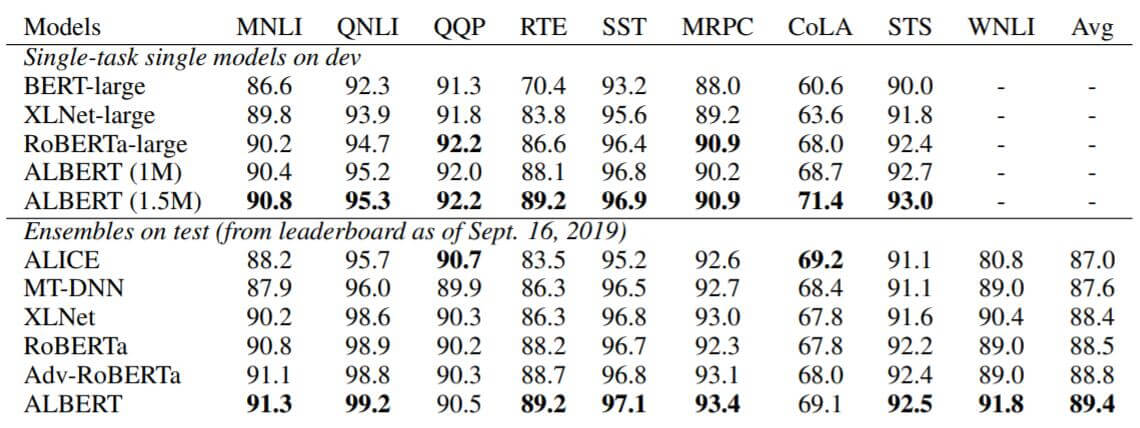
ALEBRT(1M) 代表ALBERT在该任务上Train了1M个Step, 与RoBERTa训练量相同.
在SQuAD和RACE上的结果如下:
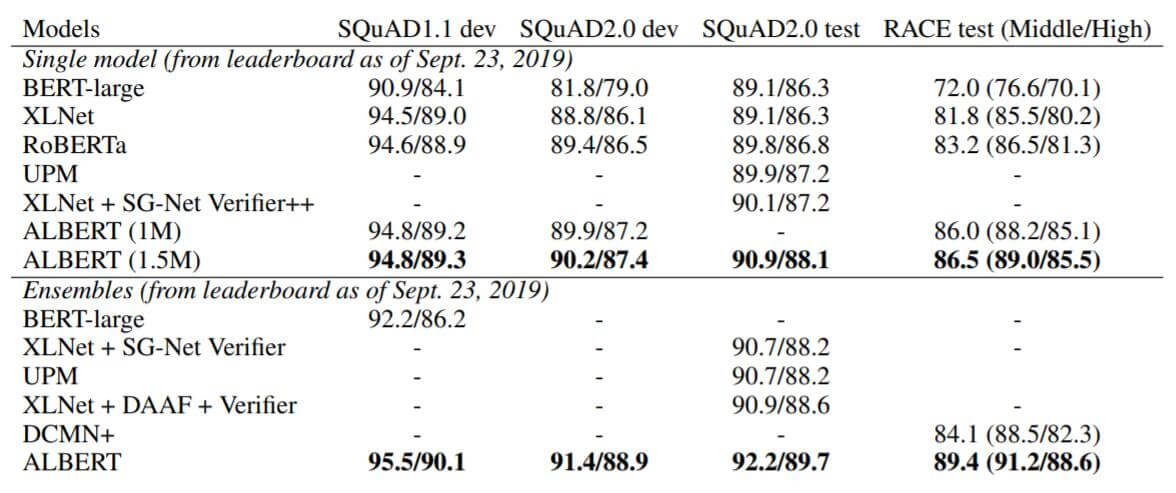
ALBERT仍然是SOTA.
附录中还有一些对加强ALBERT宽度和深度的实验, 结果都表明当深度或宽度到达一定阈值后, 性能不再能继续增加, 甚至有时会出现退化.
Summary
ALBERT的主要贡献是减了参数, 而不是计算量. 换句话说, 只能让BERT跑起来, 但推理阶段跑的快不快就不管了. 这似乎显得ALBERT有些鸡肋了, 因为减少模型参数后它的精度仍然会受到影响, 如果继续增大深度运算量又是个门槛($H$ 比较大, 而且层数多了, 肯定会增大运算量), 这点大家好像吐槽比较多.
ALBERT能够与BERT媲美的本质可能是$H$ 增大所带来增益要超过缩小参数带来的负面效应.
ALBERT的改进点都比较偏向于工程, 比起论文它更像一篇炼丹报告…, 看实验结果感觉应该是到ALBERT所使用的压缩方法的性能顶峰了.
模型压缩的目的从来都不是使得小模型的效果好过大模型, 而是利用某种方式, 使得模型的参数量或计算量减少, 同时不会带来明显的性能下降.

