本文前置知识:
- Transformer: Transformer精讲.
- BERT, GPT: ELMo, GPT, BERT.
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
本文是论文Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 的阅读笔记和个人理解. T5的论文更像是一篇详细扎实的实验报告, 所以本文不再按照常规结构讲解, 所有详细的实验参数和训练过程请参照原论文.
所谓万物皆可生成, 任何任务都可以转化为Sequence to Sequence的形式完成, 只是不同的任务转化为生成后的任务难度有所差异.
T5是谷歌在2019年, 后BERT时代, 面向生成的Transformer的一次全面探索, 甚至是一次无穷尽的探索, 再一次展示了唯一真理”Money is All You Need”.
其实T5在此基础上还有个小升级T5 1.1, 基本大差不差. 后来又有个mT5是T5的多语言版本, 重新构建了多国语言预训练数据集, 模型沿用的是T5 1.1, 感兴趣的可以自行了解, 咱们在这就只说说T5初始版本.
Text - to - Text Framework
T5全称为Text-to-Text Transfer Transformer, 无论是何种任务(MT, QA, 文本分类等等), 全部使用文本作为输入, 并且用生成的文本作为输出. 这种方式最大的好处在于提供了预训练时和微调时的目标一致性. 所以谷歌才要探索这种基于生成式的预训练方式.
如何将所有任务转化成text to text形式? 图中列举了几种将不同形式任务统一到text - to - text框架下的例子:
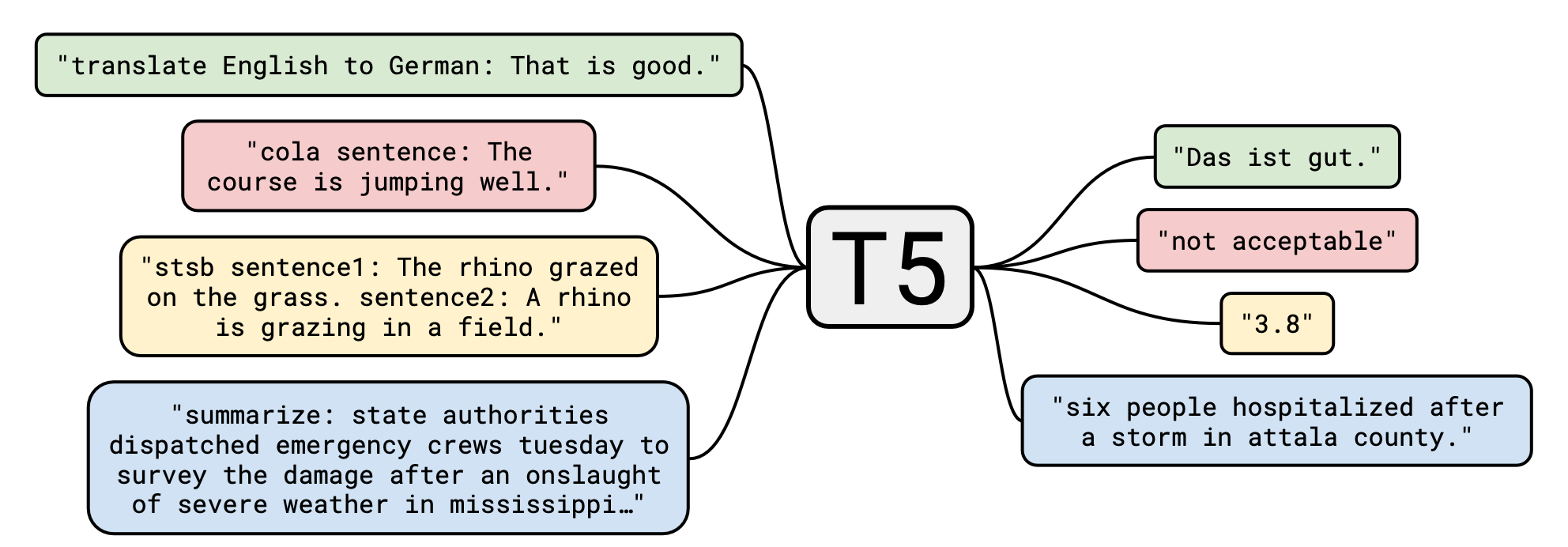
如果你能在其他NLP论文看到类似这样的图, 左边几个大框框右边几个小框框中间一个模型名字框框, 不出意外它一定是用T5或者T5的改进版做的预训练.
- 机器翻译: 直接在训练数据前面加上
translate X to Y,X和Y是不同种的语言. - 文本分类: 让模型输出一个单词, 代表不同种类的标签.
- 情感分析: 加上任务前导名, 并在句子前加上
sentence:. - 文本摘要: 在文本前面加上
summarize:. - 语义相似度: 最特殊的一类任务. 加上任务前导名, 在两个句子前分别加上
sentence1:,sentence2:.
它们的输出都直接是任务中的标签文本, 注意是标签文本. 也就是说, 像STS - B这种语义相似度的任务, 也是靠直接输出文本来完成的, 而非加个回归头输出数值. STS - B的相似度标签大多是在1 - 5之间的, 作者按0.2为一个增量步长把它改为了一个21分类任务, 如果有相近的值全部四舍五入到相应的类别里.
直觉上来讲这是比较离谱的, 但其实想想这样的统一也才符合T5的终极定位, 所有任务都用文本输入, 文本输出.
对于所有的分类问题(包括STS - B), 如果T5在分类任务中输出了不属于Label的单词, 直接记为错误.
不同文本的预处理方式实际上是个超参, 所以作者没有做探索, 因为方式实在是太多了.
在经过数据预处理后, 在这种任务大一统的情况下, 直接允许作者使用相同的模型架构, 损失函数, 超参等, 完成所有的NLP任务.
详细的任务预处理例子请参照原论文附录D.
Differences between Transformer and T5
T5做的所有实验均是基于Transformer架构的, 和普通Transformer仅有一些不显著的不同:
Relative Positional Injection: T5中给模型注入的是相对位置信息, 但并没有采用在输入时直接加上位置编码引入位置信息的方式. Query和Key的绝对位置差值对应着不同的相对位置. T5令每个注意力头直接学习不同相对位置的Attention Score(就是在Softmax之前的logits), 在模型计算完Attention Score后直接加到上面. 每个注意力头都有自己的相对位置Embedding, 但所有层都共享同一套相对位置Embedding.
注意! 既然该操作是直接加到Attention Score上的, 这意味着每次Attention都会完成一次注入. 这强化了T5对相对位置的感知.
其实, T5的相对位置其实不是一个值, 一个相对位置区间, 例如Query和Key的绝对位置差分别为
1, 2, 3, 4,1可能对应着最近的Attention Score, 而2, 3同时对应着中距离的Attention Score,4对应着最远的Attention Score. 这点可以参考Hugging face的T5实现中的_relative_position_bucket函数.Activation Function: 从BERT使用的GeLU又退回了ReLU.
No Bias Item: 从Attention到FFN, T5去掉了所有Linear的bias.
Normalization: T5使用的是Pre Norm, 而非Post Norm. 此外, 与上一条相关, 把Layer Norm替换为了 RMS Norm, 即去掉了跟均值相关的那项:
$$
\begin{aligned}
y_{i,j,k} = \frac{x_{i,j,k} - \mu_{i,j}}{\sqrt{\sigma_{i,j}^2 + \epsilon}}\times\gamma_k + \beta_k,\quad \mu_{i,j} = \frac{1}{d}&\sum_{k=1}^d x_{i,j,k},\quad \sigma_{i,j}^2 = \frac{1}{d}\sum_{k=1}^d (x_{i,j,k}-\mu_{i,j})^2 \\
\Downarrow \\
y_{i,j,k} = \frac{x_{i,j,k}}{\sqrt{\sigma_{i,j}^2 + \epsilon}}\times\gamma_k,&\quad \sigma_{i,j}^2 = \frac{1}{d}\sum_{k=1}^d x_{i,j,k}^2
\end{aligned}
$$
除去上述几点外, 其实还有一个区别, 计算Attention Score的时候不用除以$\sqrt{d}$, 这么做的具体原因在浅谈Transformer的初始化、参数化与标准化中提到, 强烈建议阅读.
C4: Colossal Clean Crawled Corpus
不光有T5, 这篇文章还扔出来个C4(Colossal Clean Crawled Corpus), 这个名字起得挺搞的, 译为巨大号清洁爬下来的语料库. 它是爬虫从大量公开可用的HTML里爬下来的, 还没清洗时有20T大小.
爬下来的数据非常不干净, 它做了如下清洗工作:
- 仅保留结尾有标点的句子.
- 去掉少于5个句子的页面, 保留至少3个单词的行.
- 去掉有脏话, 涩涩之类坏词的页面.
- 去掉包含Javascript的句子, 和网页警告的是否开启JS有关.
- 去掉包含
lorem ipsum占位符的页面, 和测试网页排版有关. - 去掉所有包含花括号的页面, 和代码有关, 比如JS, Java, C都广泛使用花括号.
- 以三句为一个单位去重.
清洗出的文本大约有750G, 作为预训练数据.
Experimentsss…
T5的结构和训练细节是单纯考实验得来的, 每次做完一部分实验, 就确定T5的一部分细节. 待T5的训练细节固定后, 又对C4和训练策略做了探索.
Model Architecture
不同体系的模型主要区别就在Attention Mask上:
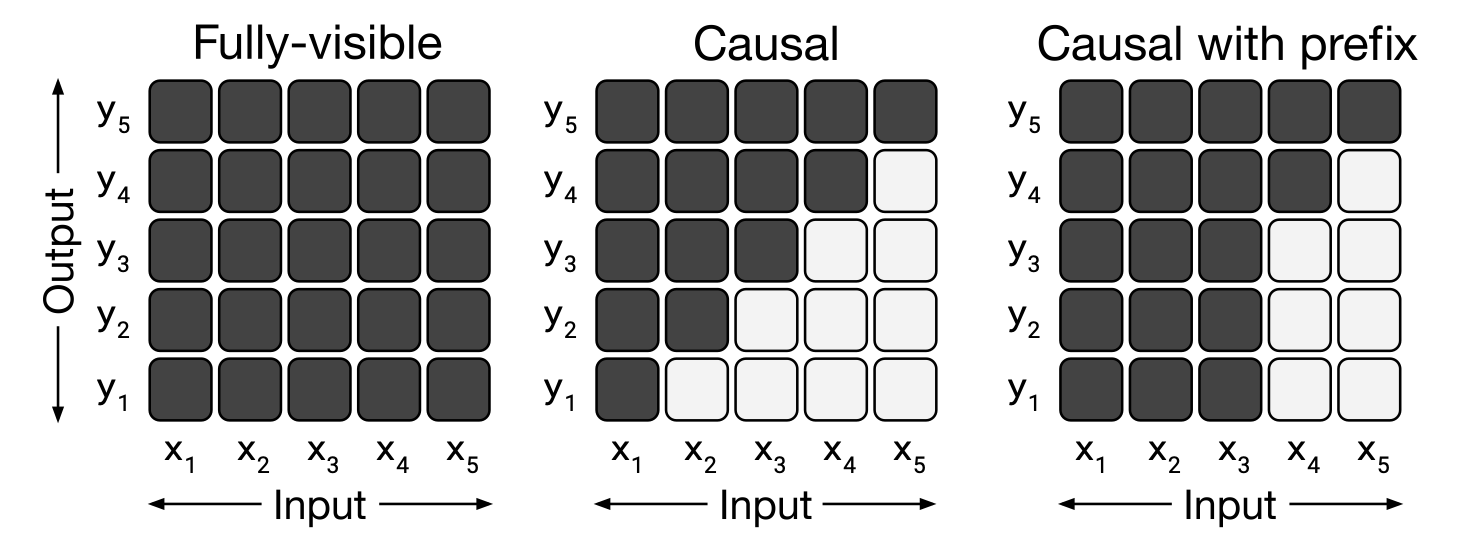
图中横轴为Attention的输入, 纵轴为输出. 黑色代表可以对该元素给予注意力, 白色代表不能对该元素给予注意力.
- Fully - Visible: 输入对每个时间步的输出完全可见, 即Transformer Encoder的Attention Mask.
- Causal: 输出仅能依赖当前时间步及之前的输入, 即Transformer Decoder的Attention Mask.
- causal with Prefix: 是前面二者的混合, 输入的一部分Fully - Visible, 一部分是causal.
不同类型的Attention Mask造就了Transformer各类不同结构的诞生:

此处的x 和y代表输入序列和输出序列.
- Left: 标准的Encoder - Decoder结构, Encoder是全可见的, Decoder解码时可以看见全部的Encoder信息和已经解码的Decoder信息. Vallina Transformer就是这种结构, 后来这个流派又多了MASS, BART这样的模型.
- Middle: 比较纯粹的语言模型, 完全的自回归式生成. 当然这种模型也可以通过强行拼接不同的任务前导文本来执行不同的任务, 并入text to text框架中. 这个流派比较典型的是GPT.
- Right: 就是上面Encoder和Decoder的共生体, 它的最大特点就是不做Encoder和Decoder的区分, 即共用一个Transformer. 而且它在解码的时候只能使用同层的Token表示, 换句话说, 它的编码和解码过程是同步进行的, 这一流派的代表是UniLM.
一个非常有意思的看法是, XLNet这类的Permuted Language Model可以视为Prefix LM, 结合XLNet比较特殊的Attention Mask, 或许你会认同这种观点. 该观点来自于张俊林.
下面直接看实验结果:
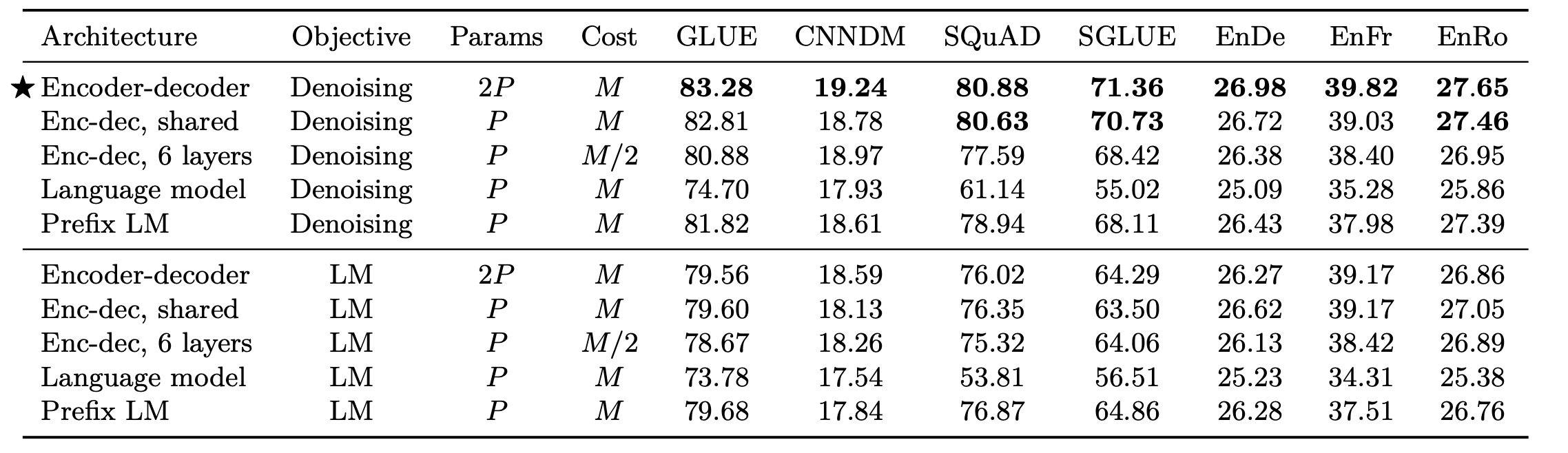
标准的Encoder - Decoder最好, 但是参数最多. 所以T5选择Encoder - Decoder作为架构.
共享Encoder和Decoder的参数似乎没有对结构有太多影响, 这点在ALBERT里也有说.
在非生成类任务上, 完全自回归的结构不太给力, 参数量和计算成本一个好处也没捞到, 大多数任务的性能还被人甩了好几条街.
Denoisiong作为训练目标确实提升了模型的能力, 几乎所有模型所有数据集表现都比LM要好.
Denoising Object for Text to Text Framework
这个Denoising是啥呢? 为了适配text to text框架, 受BERT中打Mask和Word Dropout启发, 作者提出了一种适用于text to text框架的Mask方法. 该方法从原文本中随机采样15%的Token变为不同的Mask, 不同被Mask掉的Token会被替换成不同类型的Mask. 模型将被要求生成Mask Token和与之对应被Mask掉的原内容, 以及最终的结束Token:

在这个例子中, 原文本的for inviting 被替换为<X>, last 被替换为<Y>, 结束Token为<Z>. 从例子中来看, 多个连续Token如果同时被Mask, 只需要被替换为一个Mask Token, 因为生成类模型不需要多个Mask Token就能恢复出被遮掉的内容.
在下一节中, 该方法将会与其他训练方式对比.
Unsupervised Objectives
以Thank you for inviting me to your party last week. 为例, 作者列举了其他的无监督训练目标:

BERT - style的Inputs中的
apple是由last随机替换得到的.
Disparate High - Level Approaches
首先从Prefix LM, Denosing, Deshuffling三大类的角度来看它们的差距:

BERT - style比其他两类都要好, Prefix LM在翻译上还算可以, 但理解类任务不够出色, Deshuffling可能因为完全颠倒语序语义损失太多了, 训练时全是乱序的句子, 下游任务全是正确的句子, 表现比较差.
Simplifying the BERT objective
既然BERT - style是最好的, 那就把所有Denoising方法放在一起对比:

总的来说保留Mask Token比较好, 和MASS - style对比, 连续的Mask只替换成一个Token就好, 不需要保留多个.
Varying the Corruption Rate
很明显不同的打Mask几率有不同的效果:
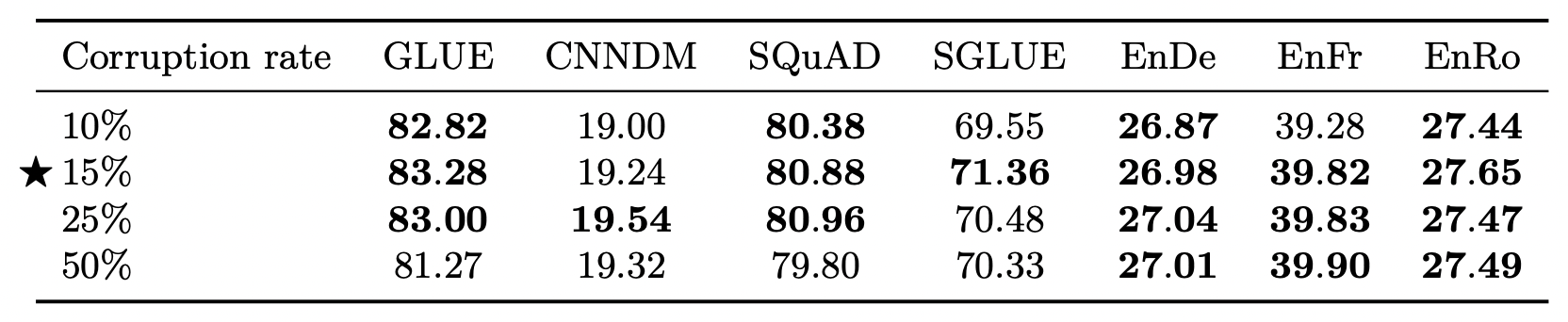
从实验上来看, 15%是一个比较好的值, 看来BERT开了一个好头. 比较大的打Mask率似乎对GLUE的影响比较大, SGLUE掉了一个点, 对其他任务影响好像都不是特别特别明显? 按理说给句子遮上一半会损失特别多的语义.
Corrupting spans
出于对训练效率的考虑, 每次发生打Mask的动作时, 都会给要预测的目标序列多加一个引导预测的Mask Token, 被Mask掉的Token不连续的越多, 目标序列就越长.
对每个Token单独判断是否要Mask似乎不如直接Mask掉Span来得快, 这样可以保证目标序列里的Mask Token占比较少, 训练速度就比较快. 同时, 这个想法曾在SpanBERT上被验证为有益于BERT预训练, 所以作者做了直接Mask掉Span的实验.
作者所设计的方法是将给Token打Mask的比例和要Mask掉的Span个数设为超参, 以此来控制平均Mask掉的Span长度.
咱举个例子, 当前序列有500个Token, 所设置的被Mask掉的Token占比为15%, 要Mask掉25个Span, 则总共有500 x 15% = 75个Token会被Mask, Mask掉的Span的平均长度为75 / 25 = 3, 即[Mask]和被Mask掉的Token比例为1:3. 同时, 在固定被Mask掉的内容的Span长度的情况下, 它们全是不连续的, 目标序列长为75 + 25 = 100.
同样在前面所述的环境下, 采用独立同分布(长度为1)打Mask的方式, 仍是在500个Token中Mask掉15%的Token, 则目标序列长为75 + 75 = 150.
实验结果如下:
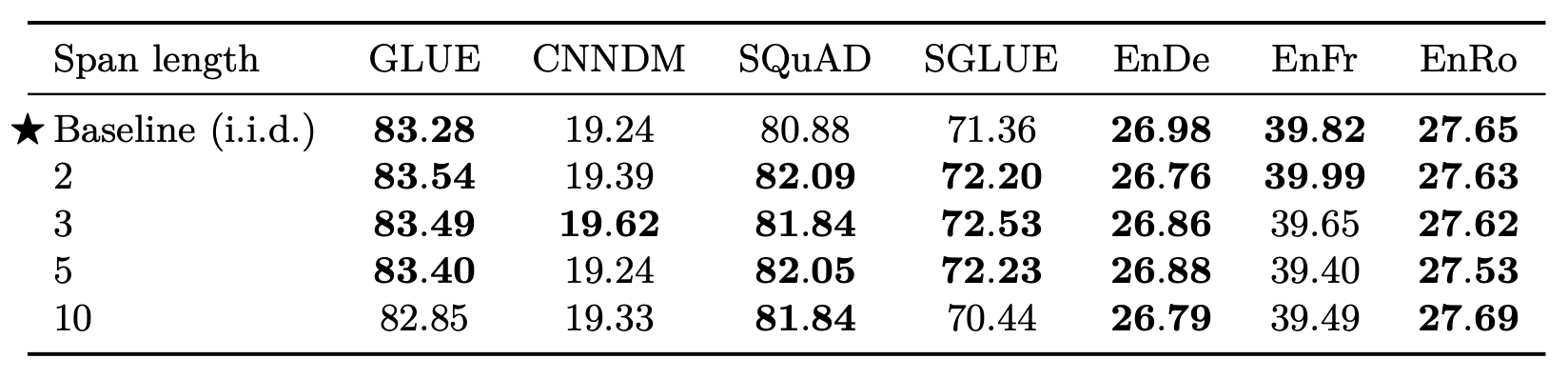
在1, 2, 3, 5的设定下来看差异真的不是特别大, Mask掉长度为3的Span似乎比独立同分布的Mask掉Token在除了MT以外的任务要好一些. 但是Mask掉Span的训练速度比较快, 所以作者采用了Span长度为3的Mask方法.
Discussion
作者对无监督目标做出的搜索路径如下:
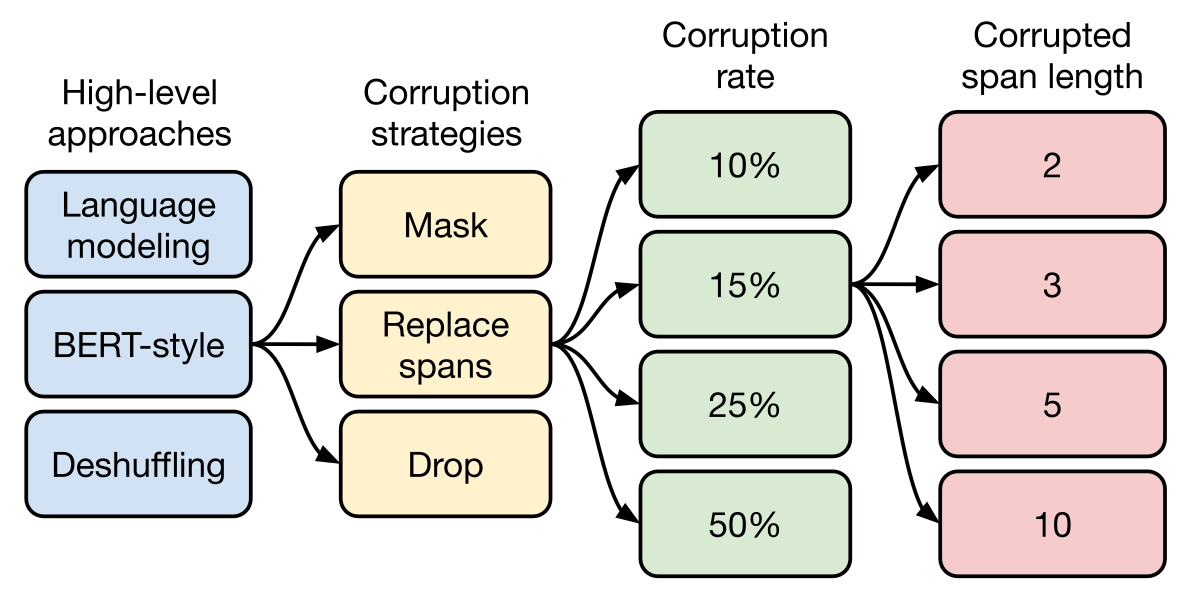
作者选择的路径是 BERT - style -> Replace spans -> 15% -> 3.
Pre - training Datasets
Unlabeled datasets
作者希望比较不同数据集给模型预训练带来的影响, 顺便评估一下C4.
不同预训练数据集结果如下:
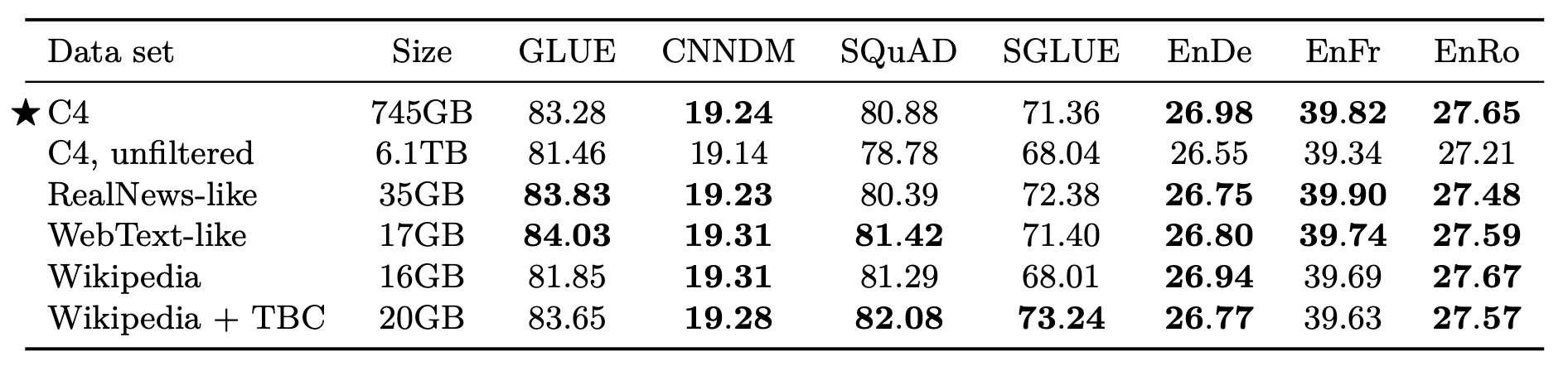
我粗略的介绍一下数据集, C4 unfiltered是指不适用启发式规则过滤的C4, 它的噪声比C4要大的多的多. RealNews和WebText的like版本指的是使用C4的启发式过滤规则过滤后的数据集.
结论如下:
- C4的启发式过滤还是挺有效的, 没过滤的C4明显效果拉了.
- 即使域内数据没有标签, 特定领域数据集预训练对特定任务有效, 感兴趣的可以细搜这些数据集覆盖的区域和不同任务的测试数据来源.
Pre - training Datasets Size
创建C4的核心在于扩大数据规模, 并尽量保证样本的不重复性. 作者尝试探索预训练期间多次重复样本对下游任务的影响. 作者尝试缩小C4的规模, 以达到多次重复数据的目的. 实验结果如下:
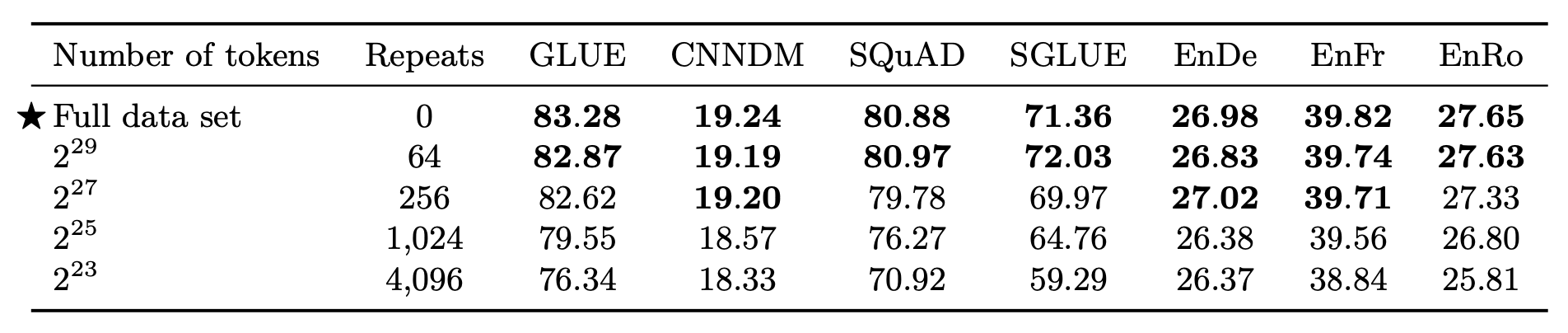
结果表明, 越多次重复, 下游任务表现越差.
至于把C4的规模缩小会不会导致真正有用的样本被减少, 我个人觉得C4实在太大了, 所以截断C4可能不会导致其样本多样性的缺失… 而且每次Mask都是随机的, 所以模型也不会看到完全相同的样本.
作者怀疑模型随着重复次数过多, 学会直接死记硬背预训练数据集, 导致下游任务学习的时候效果就变差了, 作者做出了各规模数据集的Training Loss:
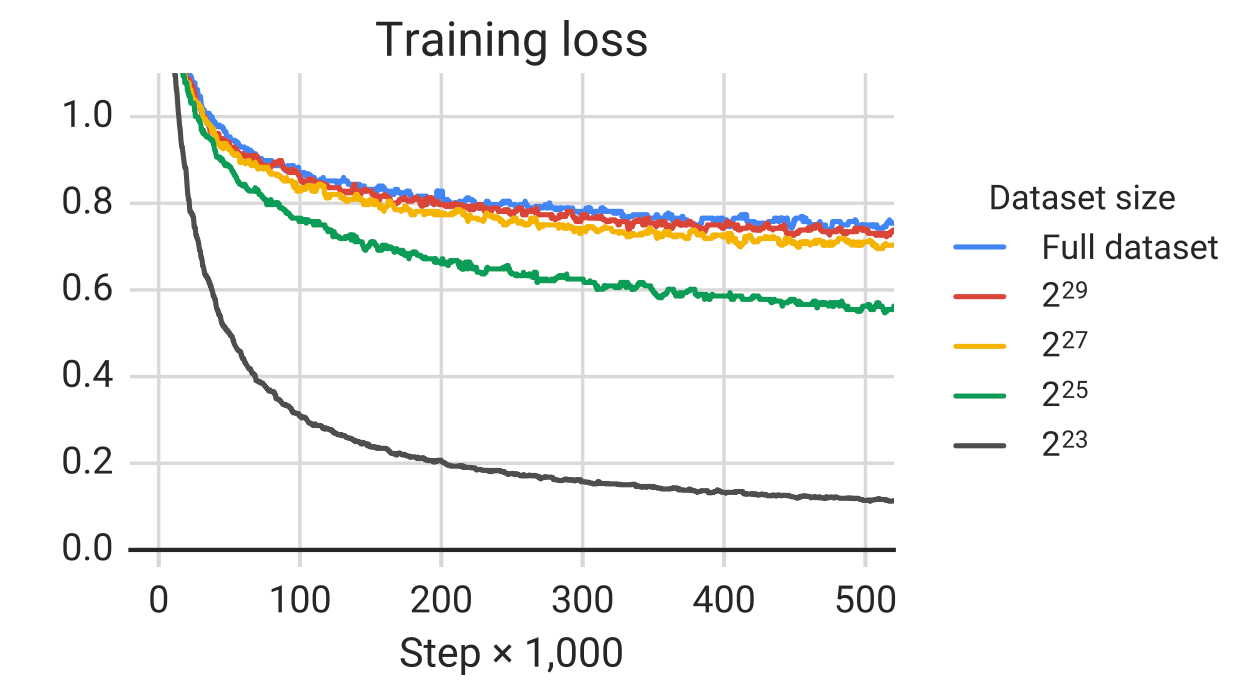
Training Loss随着数据集的缩小而减小, 这就意味着可能模型有记忆现象, 因为数据集越小, 重复的次数就越容易多, 但是做下游任务的时候就越不容易.
Training Strategy
Fine - Tuning Methods
不同的训练策略会给模型在下游任务的表现带来不同影响.
作者在这里列举了两种高级一点的Fine Tuning方法:
- Adapter: 在Fine Tuning的时候不调原来模型参数, 而是只调一些在原模型基础上加进去的即插即用插件, 以代替更新预训练模型的参数, 详情请见论文Parameter-efficient transfer learning for NLP.
- Gradual Unfreezing: 随时间逐步解冻模型的参数, 逐步使得模型所有参数都参与更新. 先只微调模型的最后一层, 训练一定次数后解冻倒数第二层, 直到整个模型都解封.
结果如下:
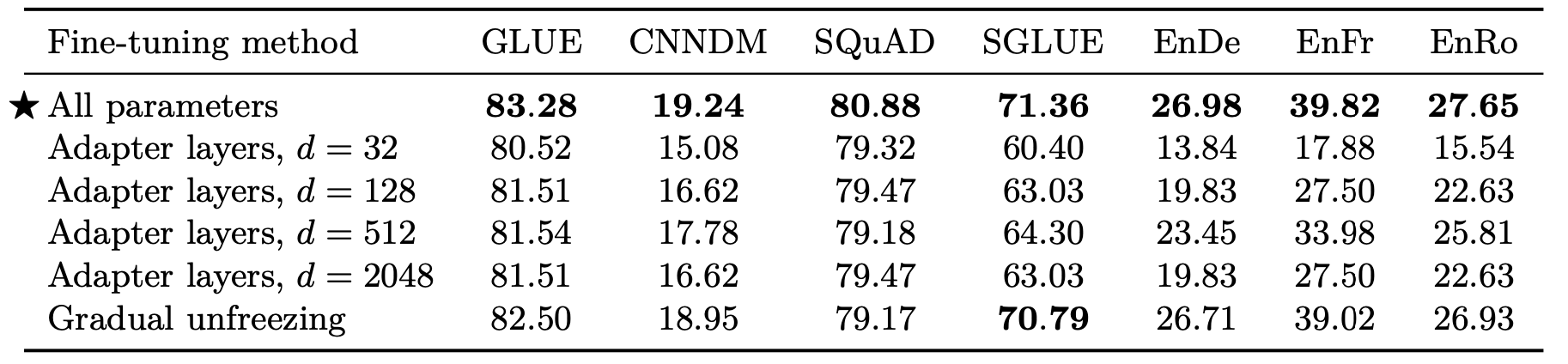
各种大小的Adapter似乎都不如Gradual Unfreezing, 根据作者所述, Adapter只在资源比较少的任务上设置比较小的d时效果比较好. 但总的来说还是微调全部参数效果最好.
Multi - Task Learning
前面测试的都是预训练 + 微调的表现, 还没有测试过多任务下的表现. 在text to text下, T5的多任务训练比较简单, 只需要把不同任务的数据集混到一起. 而MTL比较关键的地方在于需要在每个任务之间做权衡, 不能让某个任务的数据过少或过多. 因此作者想了一些办法来控制每类任务的数据集大小, 详情请参照原论文.
最终结果如下:
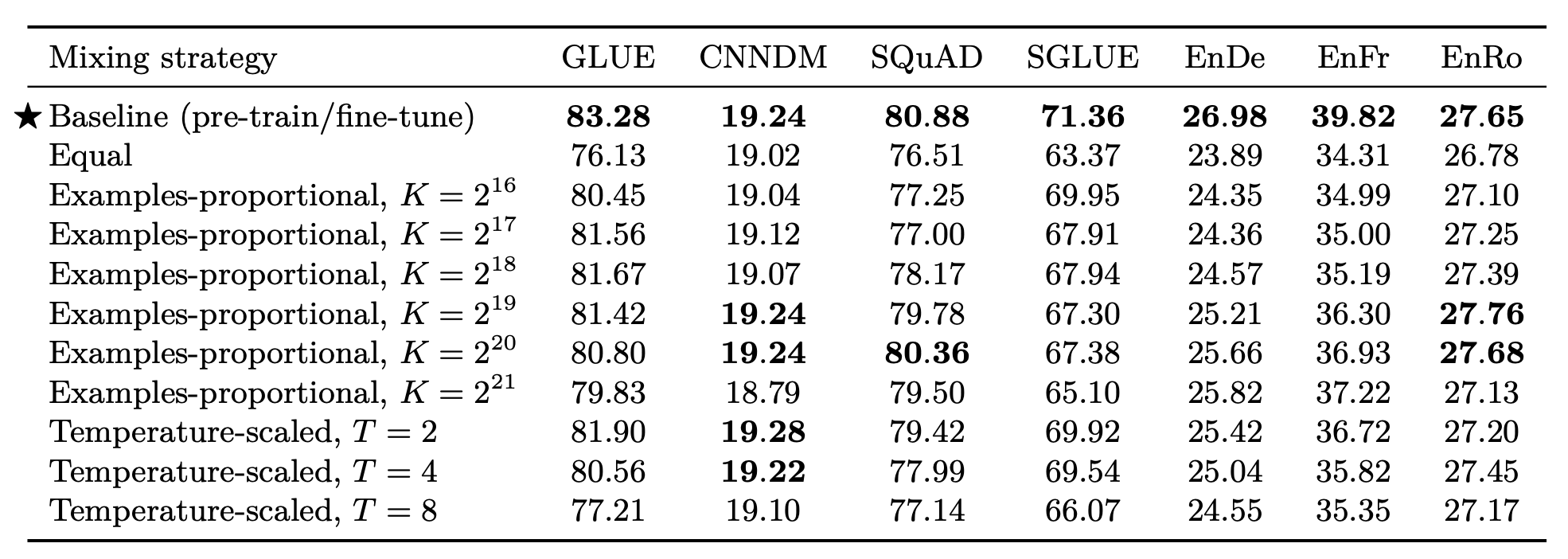
总的来说, 用直接多任务训练不如预训练 + 微调.
此处的MTL应该指的是不做预训练, 把各类任务的数据混到一块训练, 所以和预训练必然差着很大的数据量级.
Combining Multi - Task Learning with Fine - Tuning
作者将多任务学习扩展到预训练上, 即同时对所有任务预训练, 然后有监督的对单任务微调.
把预训练 + 微调和MTL放到一起对比. 结果如下:

单任务学习的预训练 + 微调是最好的, 多任务预训练 + 微调几乎和它一样. 但是多任务预训练可以在预训练期间就监视下游任务的性能, 所以作者最终为T5采纳了多任务预训练的策略.
对于翻译这种任务来说, 有监督比无监督要好, 除去翻译任务外无监督效果更好一些.
Scaling
大模型和更长的训练时间, 一般都会带来提升. 作者测试了不同规模的模型, 不同训练时间, 以及集成后的模型性能:
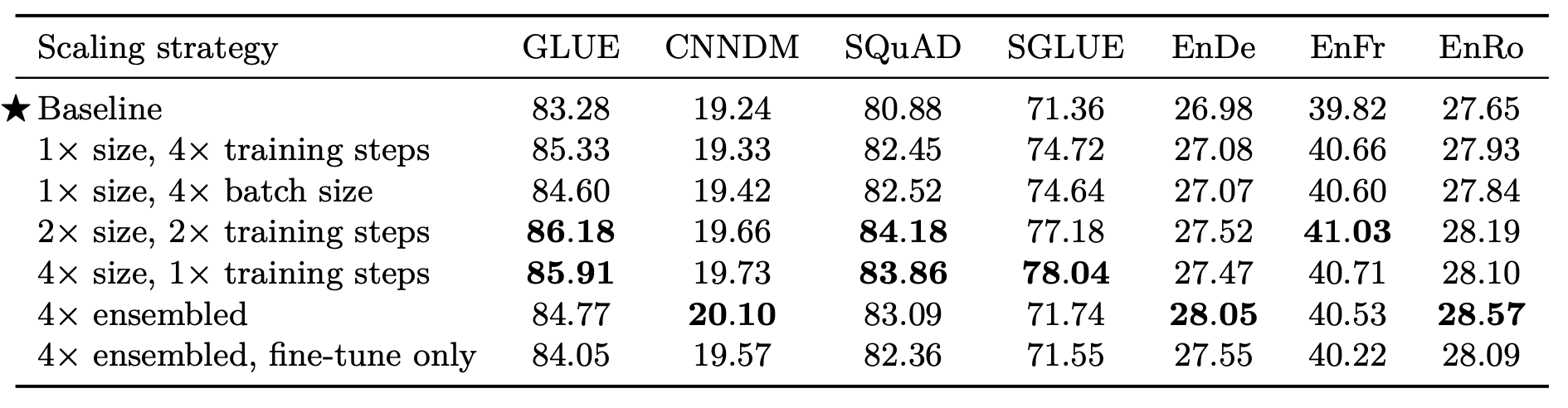
结论显而易见, 大模型, 长时间都会让性能更好. 但是似乎增大batch size相较于提高训练步长没有那么大提升. 模型分别预训练再微调集成比使用相同的预训练再微调集成效果好.
当然这些讨论都是建立在像C4这样大规模数据集上的, 模型可能没有完全收敛. 如果数据不够多, 模型可能在训练一段时间就收敛了, 训练再长时间也没用.
Summary
总的来说, T5给出了以下的主要结论:
- 模型架构: 原生Transformer最好.
- 训练目标: 类似BERT的Denosing, 15%的Mask几率.
- 训练策略: 全参数微调最好, 多任务预训练后微调和无监督预训练后微调性能相当.
- 模型大小: 小模型给长训练时间不如大模型给短训练时间.
最后再给大家看一眼T5论文的最后一页:
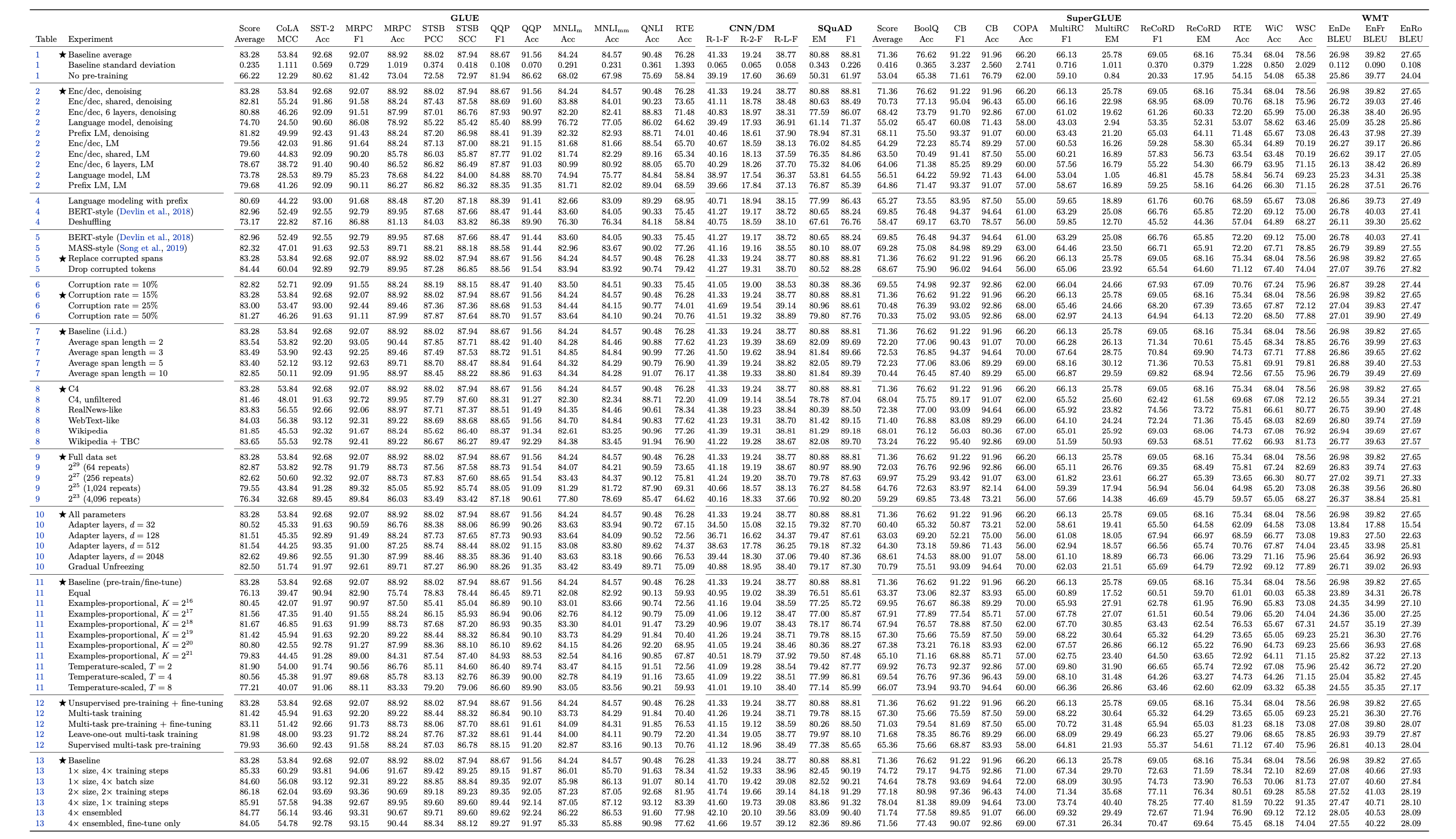
确实看着让人头皮发麻, 这足以证明T5是在”Money is All You Need”, “全面探索”两个前提下的结果. 不得不说这种研究只有大公司能做得起.
我不太建议去读T5的原文, 因为实在是太长了, 但T5中涉及到的引文还是值得看看的, 因为这篇论文几乎把所有当时比较火的预训练模型做了个大串烧, BERT, GPT, MASS, BART, UniLM, ALBERT, 甚至还有SpanBERT, 扩展的话XLNet也算… 这些文章我也都做过笔记, 感兴趣的可以去看下.

