本文前置知识:
PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
本文是论文PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction 的阅读笔记和个人理解, 论文来自ACL 2021.
Basic Idea
最近的RTE方法收到一些限制, 例如冗余关系预测, 基于边界的抽取缺少泛化能力, 效率问题等.
作者希望通过一个关系检测模块, 来检测文本中的潜在关系, 以代替使用所有关系预测三元组中所对应的实体, 并兼容RTE中存在的EPO, SEO问题.
PRGC
PRGC(Potential Relation and Global Correspondence)的模型特别简单, 简单到一张图就能说的清楚:
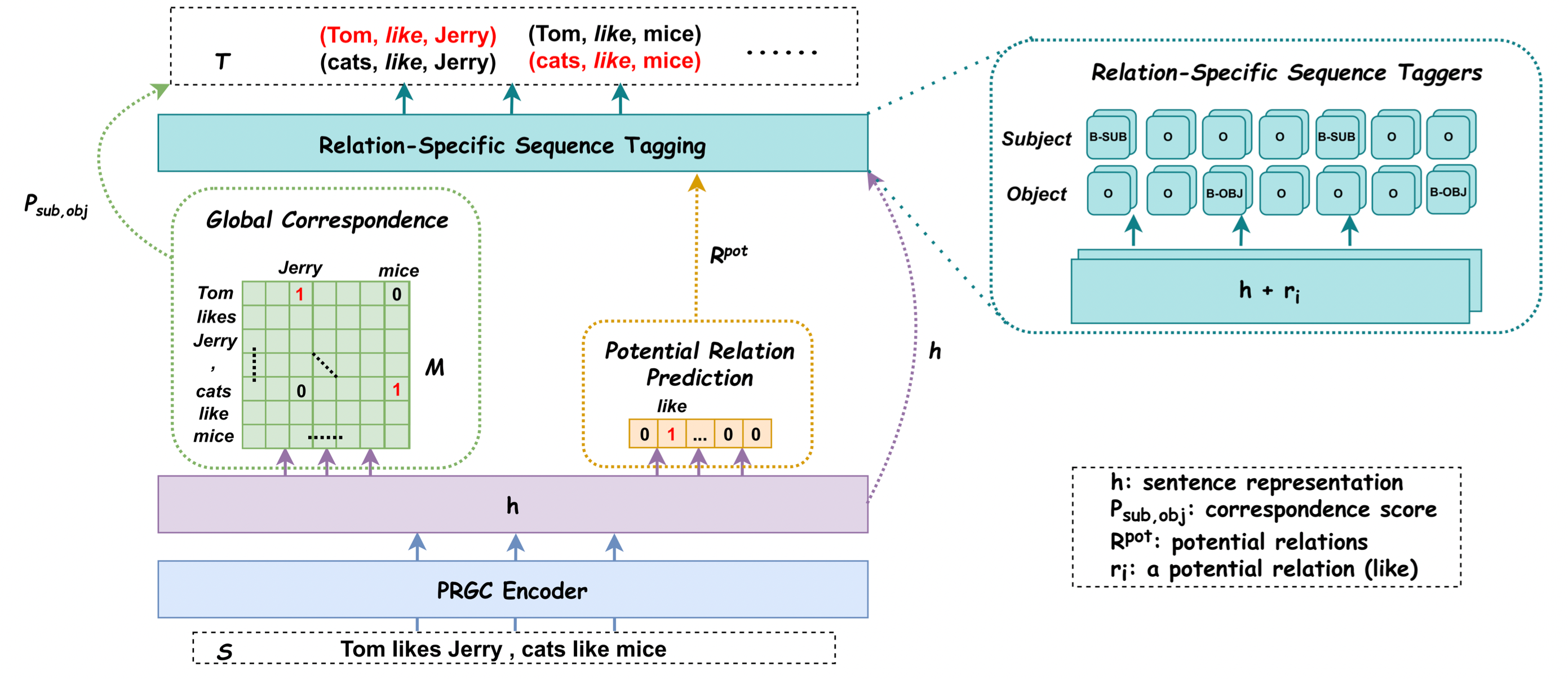
Problem Definition
对于含有$n$ 个Token的句子$S=\set{x_1, x_2, \dots, x_n}$, 其目标是找出句子中含有的关系三元组$T(S) = \set{(s, r, o) \mid s, o \in E, r \in R}$, 其中$E, R$ 分别代表实体集合和关系集合.
作者将其拆分为三个子任务:
- Relation Judgement: 检测句子$S$ 中的所有潜在关系$Y_r(S) = \set{r_1, r_2, \dots, r_m \mid r_i \in R}$, $m$ 为潜在关系数量.
- Entity Extraction: 抽取出句子$S$ 在潜在关系$r_i$ 下的实体, 用BIO标注, 即$Y_e(S, r_i \mid r_i \in R) = \set{t_1, t_2, \dots, t_n}$, 其中$t_j$ 为Tag.
- Subject - Object Alignment: 找到句子$S$ 中的头尾实体与关系类型无关的全局对应关系, 用矩阵$\mathbf{M}$ 来表示, $Y_s(S) = \mathbf{M} \in \mathbb{R}^{n\times n}$.
作者对每个明确的子任务设计了相应的模块, 并将之前非常有代表性的模型CasRel和TPLinker作为对比:
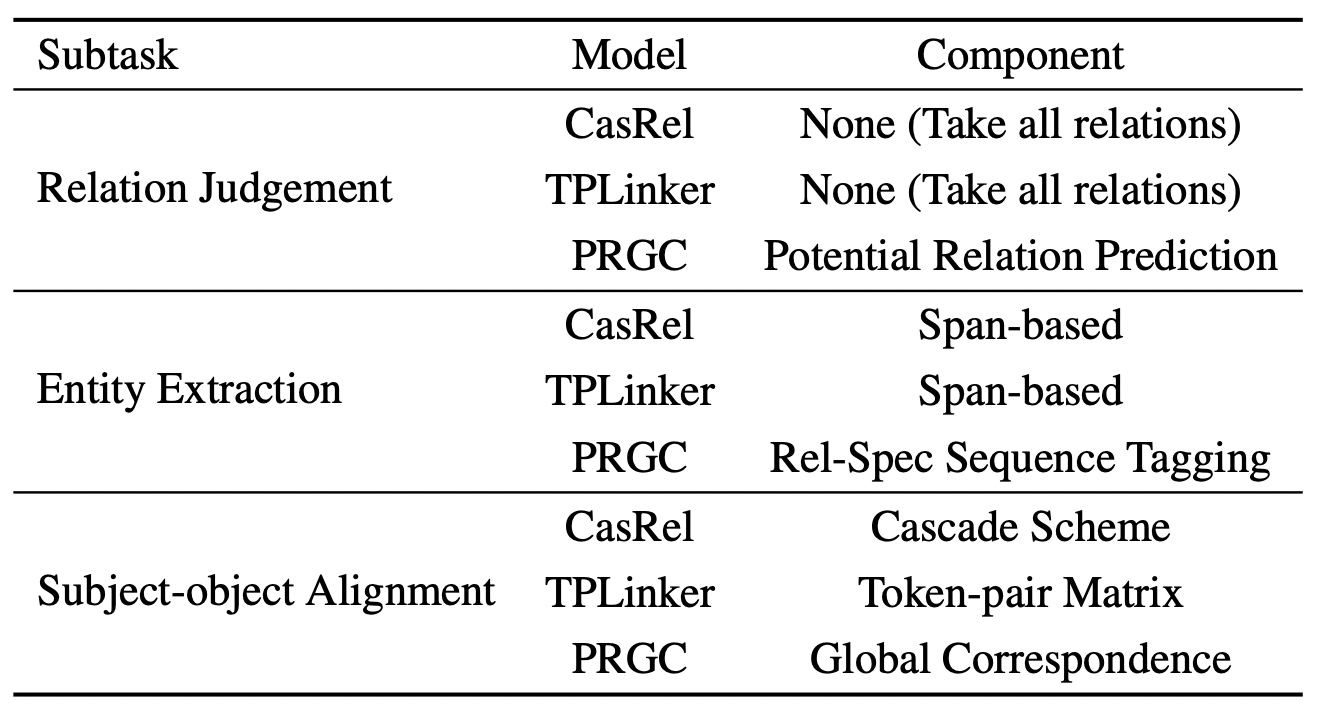
CasRel和TPLinker不特意检测文本中存在的关系, 而是对所有的关系下可能的头实体和尾实体做检测.
从子任务的角度设计模型, 能看出PRGC属于Pipeline模型的一种.
作者指的Span - based应该并不是实际意义上的基于Span的处理, 而是Binary Tagging和Table Filling.
PRGC Encoder
直接用BERT作为Encoder:
$$
Y_{enc}(S)= \set{h_1, h_2, \dots, h_n \mid h_i \in \mathbb{R}^{d\times1}}
$$
PRGC Decoder
Decoder才是模型的主要部分.
Potential Relation Prediction
为解决冗余关系预测的问题, 作者先抽取出句子中的所有潜在关系. 对于含有$n$ 个Token的句子$S$ 的Embedding$\mathbf{h} \in \mathbb{R}^{n\times d}$, 每个潜在关系存在的概率$P_{rel}$ 可以由如下方式得到:
$$
\begin{aligned}
\mathbf{h}^{a v g} &=\operatorname{Avgpool}(\mathbf{h}) \in \mathbb{R}^{d \times 1} \\
P_{r e l} &=\sigma\left(\mathbf{W}_{r} \mathbf{h}^{a v g}+\mathbf{b}_{r}\right)
\end{aligned}
$$
其中$\mathbf{W}_r$ 可训练参数, $\sigma$ 为Sigmoid函数.
作者将Relation Judgement建模为一个多标签二分类任务, 当$P_{rel} > \lambda_1$ 时视为关系存在, $rel$ 对应的输出标为1, 否则为0.
Relation - Specific Sequence Tagging
在获取了潜在关系后, 作者将分别抽取潜在关系下的头实体和尾实体, 但此时的头实体和尾实体并没有成对, 因为它们还没有经过对齐. 在标注实体时采用BIO标签, 作者认为标注实体边界使得模型更倾向于记住实体的位置, 而限制了泛化能力.
每个Token所属类别概率计算方式如下:
$$
\begin{array}{r}
\mathbf{P}_{i, j}^{s u b}=\operatorname{Softmax}\left(\mathbf{W}_{s u b}\left(\mathbf{h}_{i}+\mathbf{u}_{j}\right)+\mathbf{b}_{s u b}\right) \\
\mathbf{P}_{i, j}^{o b j}=\operatorname{Softmax}\left(\mathbf{W}_{o b j}\left(\mathbf{h}_{i}+\mathbf{u}_{j}\right)+\mathbf{b}_{o b j}\right)
\end{array}
$$
其中 $\mathbf{u}_j \in \mathbb{R}^{d\times 1}$ 为第$j$ 个关系的Embedding, 所有的关系Embedding被存储在$\mathbf{U} \in \mathbb{R}^{d\times n_r}$ 中, $n_r$ 为关系数. $\mathbf{h}_i$ 为第$i$ 个Token的表示, $\mathbf{W}_{sub}, \mathbf{W}_{obj} \in \mathbb{R}^{d\times 3}$ 为可训练参数, $3$ 为$\set{\text{B, I, O}}$ 的大小.
和先前的RTE模型标注方式不太一样, 使用的是BIO标签. 随着RTE领域的发展, 越来越多的模型不再使用Binary标签标注边界.
Global Correspondence
获取所有潜在关系下不成对的头实体和尾实体后, 接着用一个关系无关的矩阵$\mathbf{M}$ 来判断, 句子中的Token Pair之间潜在的头尾实体是否可以构成一个三元组.
矩阵$\mathbf{M}$ 中的元素代表起始位置Token Pair $i, j$ 所代表的实体之间可以构成一对头尾实体的概率$P_{i_{sub}, j_{obj}}$:
$$
P_{i_{s u b}, j_{o b j}}=\sigma\left(\mathbf{W}_{g}\left[\mathbf{h}_{i}^{s u b} ; \mathbf{h}_{j}^{o b j}\right]+\mathbf{b}_{g}\right)
$$
其中$\mathbf{h}_i^{sub}, \mathbf{h}_j^{obj} \in \mathbb{R}^{d \times 1}$ 为第$i, j$ 个Token的表示, 代表着一对潜在的头实体和尾实体. $\mathbf{W}_g \in \mathbb{R}^{2d \times 1}$ 为可训练参数, $\sigma$ 为Sigmoid函数.
仅当$P_{i_{sub}, j_{obj}} > \lambda_2$ 时视为$i, j$ 可以构成一对头尾实体, 再结合之前抽取出的潜在关系, 可以联合解码出一个三元组.
Training Strategy
根据上述设计的三个子模块, 分别给出相应的损失函数:
$$
\begin{aligned}
\mathcal{L}_{r e l}&=-\frac{1}{n_{r}} \sum_{i=1}^{n_{r}}\left(y_{i} \log P_{r e l}+\left(1-y_{i}\right) \log \left(1-P_{r e l}\right)\right) \\
\mathcal{L}_{s e q}&=-\frac{1}{2 \times n \times n_{r}^{p o t}} \sum_{t \in\{s u b, o b j\}} \sum_{j=1}^{n_{r}^{p o t}} \sum_{i=1}^{n} \mathbf{y}_{i, j}^{t} \log \mathbf{P}_{i, j}^{t}
\\
\mathcal{L}_{g l o b a l}&=-\frac{1}{n^{2}} \sum_{i=1}^{n} \sum_{j=1}^{n}\left(y_{i, j} \log P_{i_{s u b}, j_{o b j}}
+\left(1-y_{i, j}\right) \log \left(1-P_{i_{s u b}, j_{o b j}}\right)\right)
\end{aligned}
$$
其中, $n_r$ 为全关系数量, $n_r^{pot}$ 为潜在关系数量.
Potential Relation Prediction和Global Correspondence都可以看做是多标签二分类问题, 所以都用二分类交叉熵优化. 而Relation - Specific Sequence Tagging和NER大多数一致, 视为序列标注问题, 使用多分类交叉熵优化.
给这三个模块相对应的任务Loss简单加权求个和作为最终Loss:
$$
\mathcal{L}_{\text {total }}=\alpha \mathcal{L}_{r e l}+\beta \mathcal{L}_{s e q}+\gamma \mathcal{L}_{\text {global }}
$$
$\alpha, \beta, \gamma$ 为超参, 作者在这里简单的设它们三个均为1.
Experiments and Analysis
详细的参数设置请参照原论文.
Datasets
所选用的数据集是NYT, WebNLG和它们的部分匹配版本, 详细信息如下:
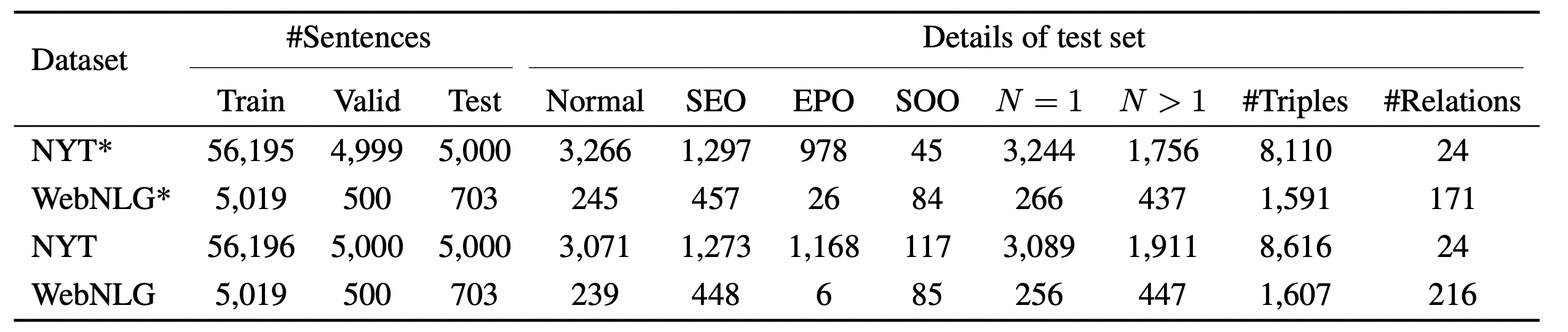
作者在论文中还单列了一种存在的三元组情况, SOO(Subject Object Overlap), 从统计信息中可以看出这类三元组占比其实没有那么大. 也有某些论文把它称作HTO(Head Tail Overlap), 都是一个意思.
例如,
[[Lebron] James] is a good basketball player.中存在的三元组为(Lebron James, first name, Lebron), 头尾实体存在内部的嵌套关系.
Experimental Results
Main Results
在各个数据集上结果如下:
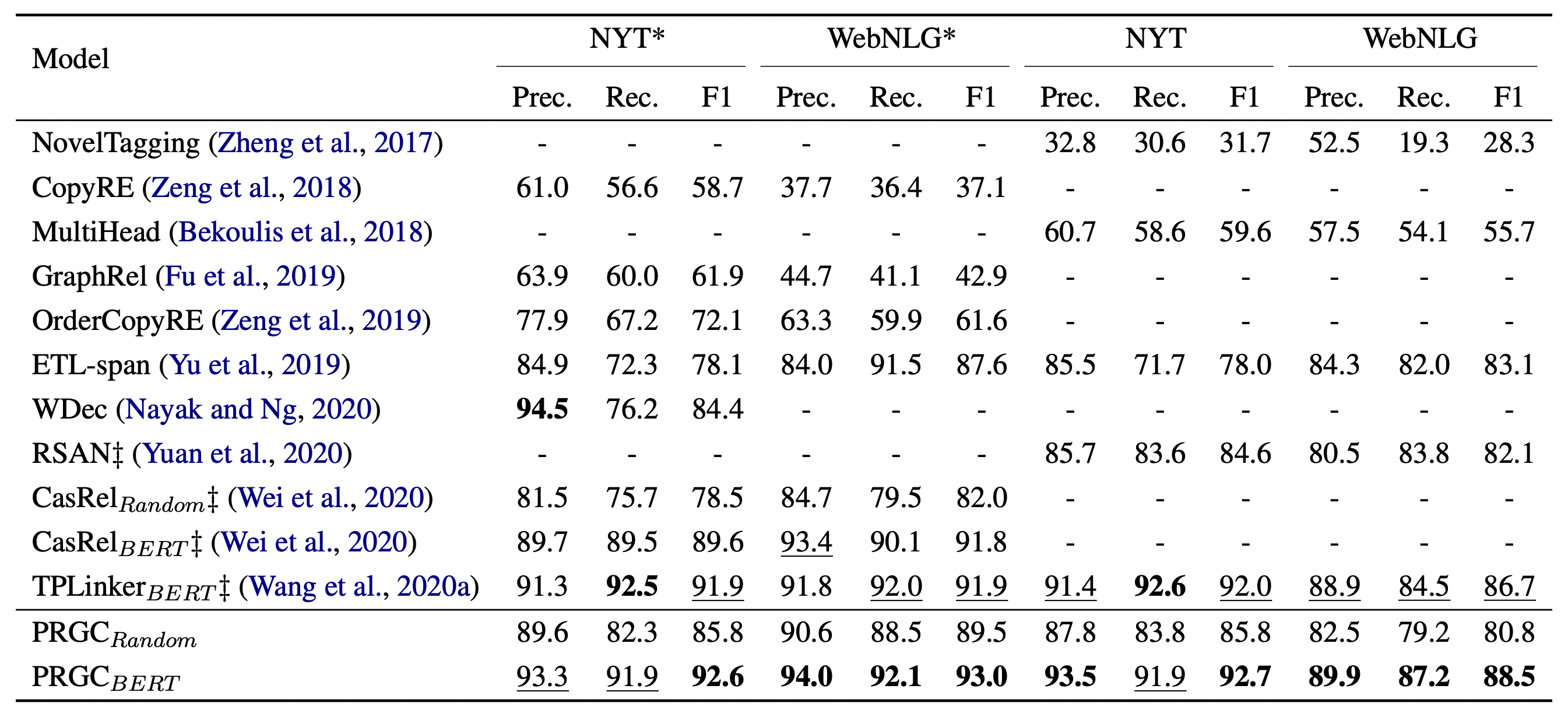
效果达到了SOTA. PRGC - Random指BERT的参数随机初始化.
Detailed Results on Complex Scenarios
按三元组的种类分别统计F1结果如下:
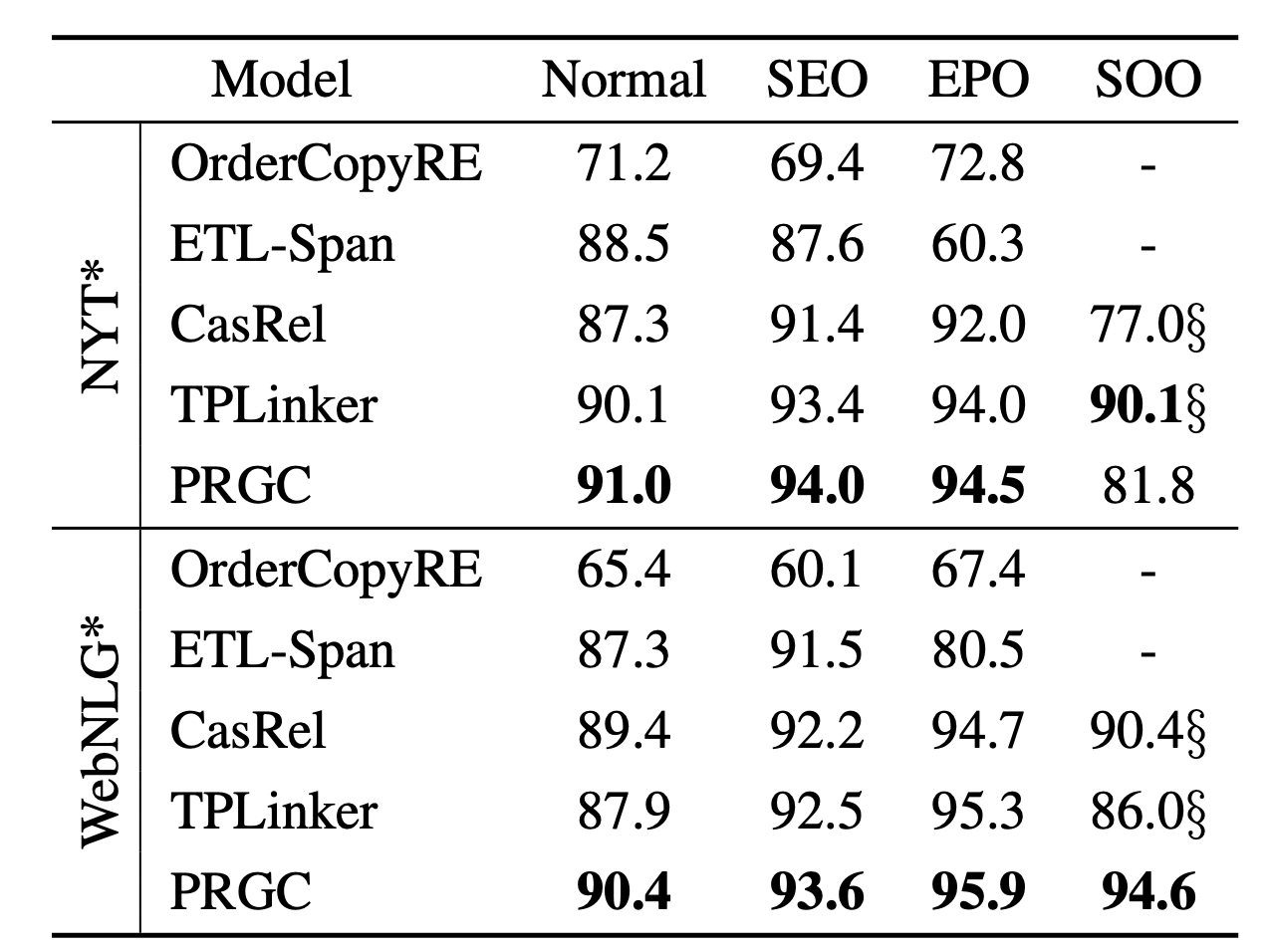
作者认为NYT*上的SOO三元组数量太少了, 所以导致结果可信度比较低, WebNLG*的结果比较可靠.
按样本中三元组个数分类统计F1结果如下:
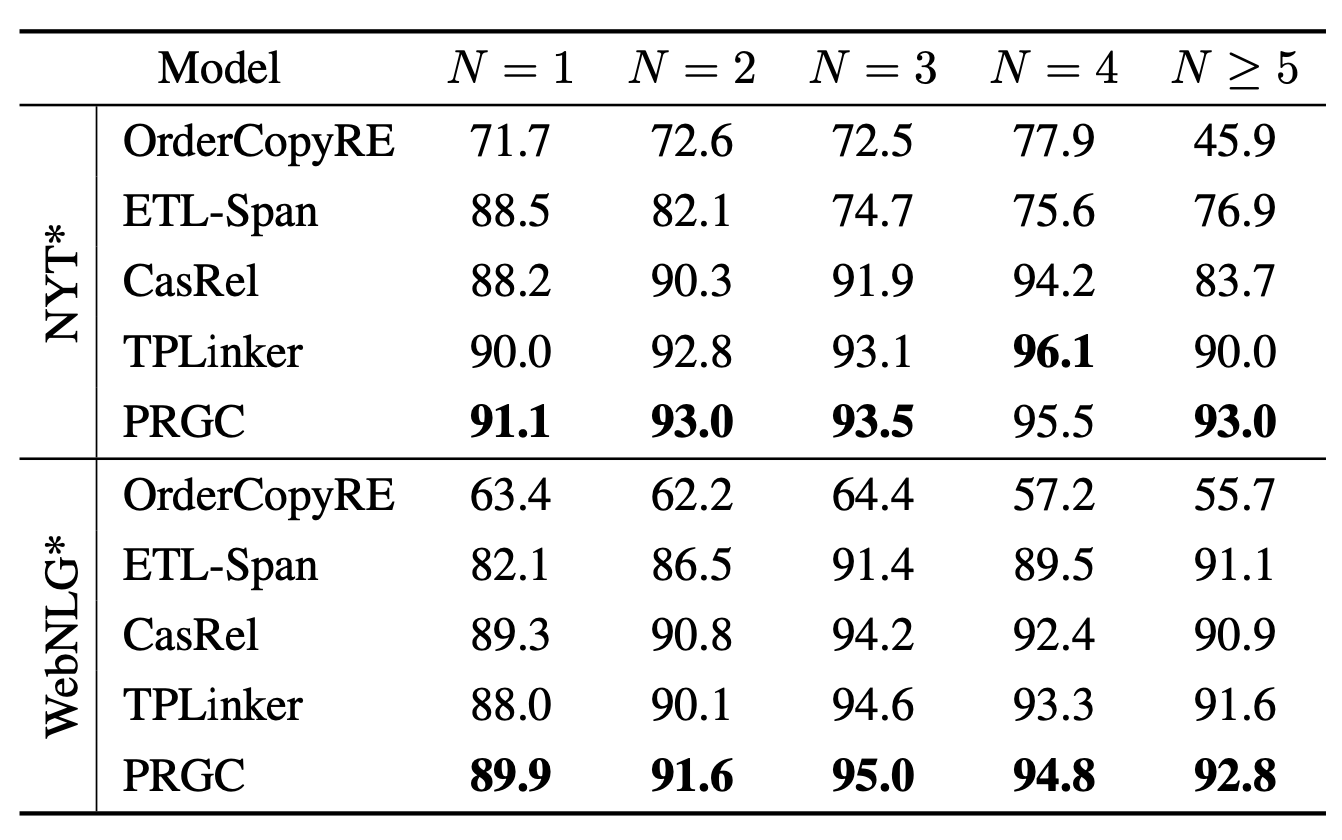
PRGC各数量三元组均有不错的抽取性能.
Analysis
Model Efficiency
作者主要对比了CasRel, TPLinker和PRGC在复杂度, 计算量, 参数, 推理时间上的表现:
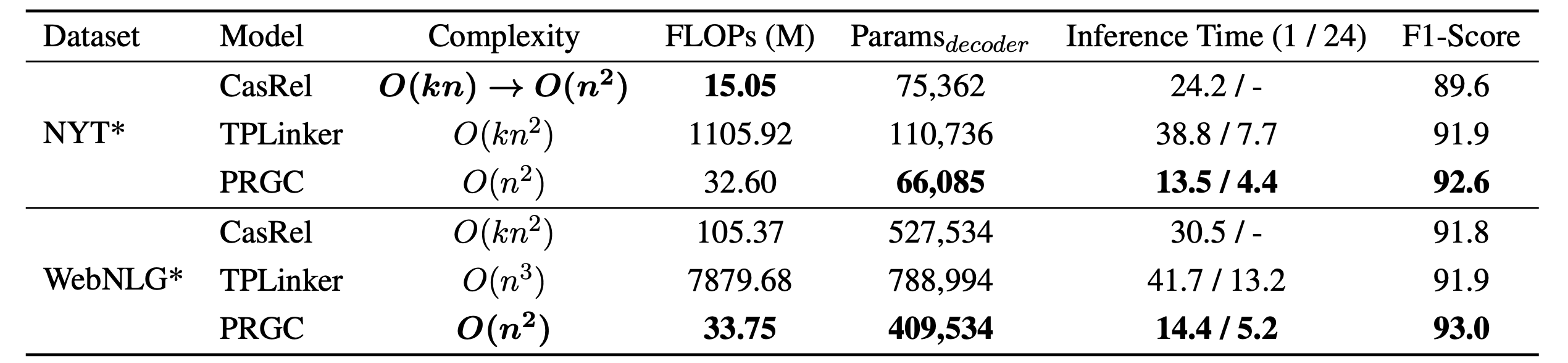
因为去掉了大量的冗余关系, 每条样本几乎只需要使用两三个关系, 所以大大减少了计算量和推理时间.
作者也对比了CasRel, TPLinker, PRGC在WebNLG* 验证集上的收敛速度:
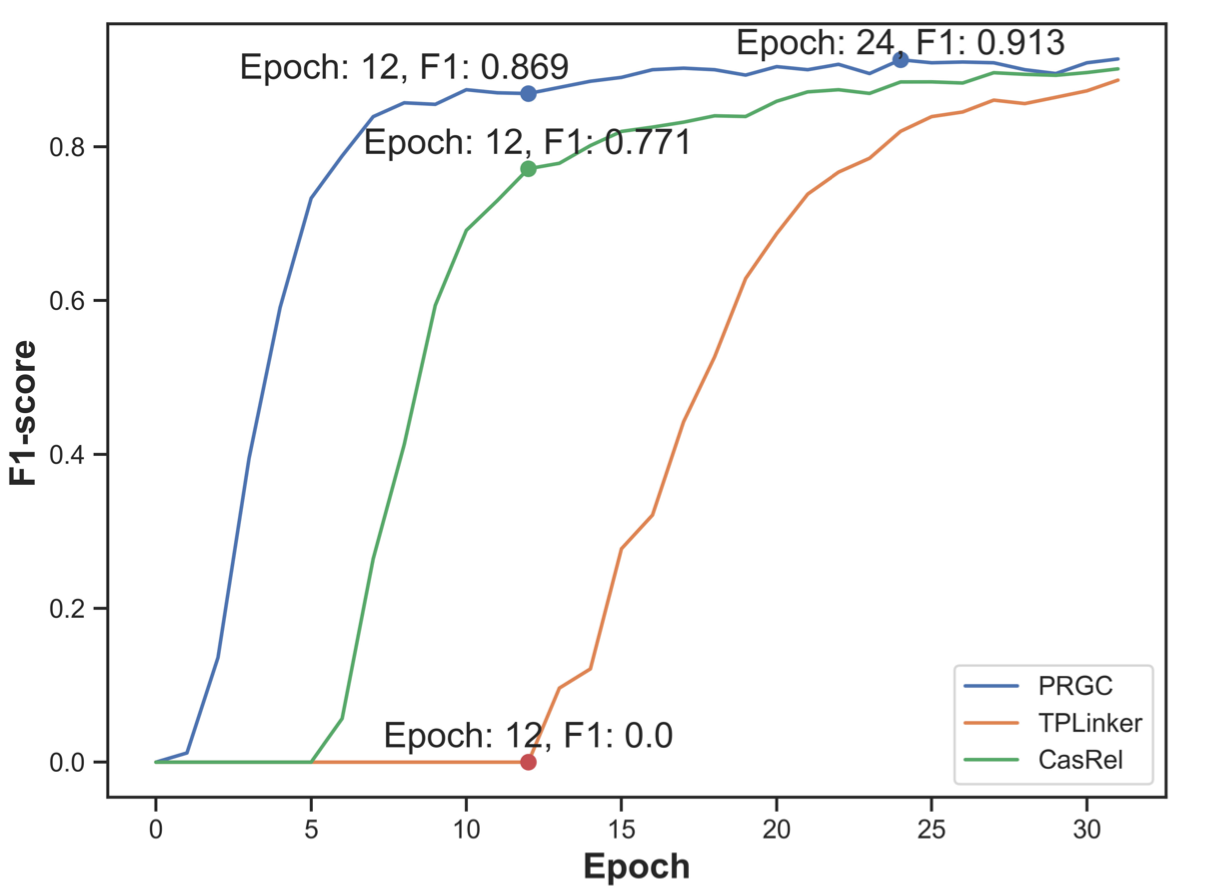
PRGC收敛速度明显比TPLinker更快.
Ablation Study
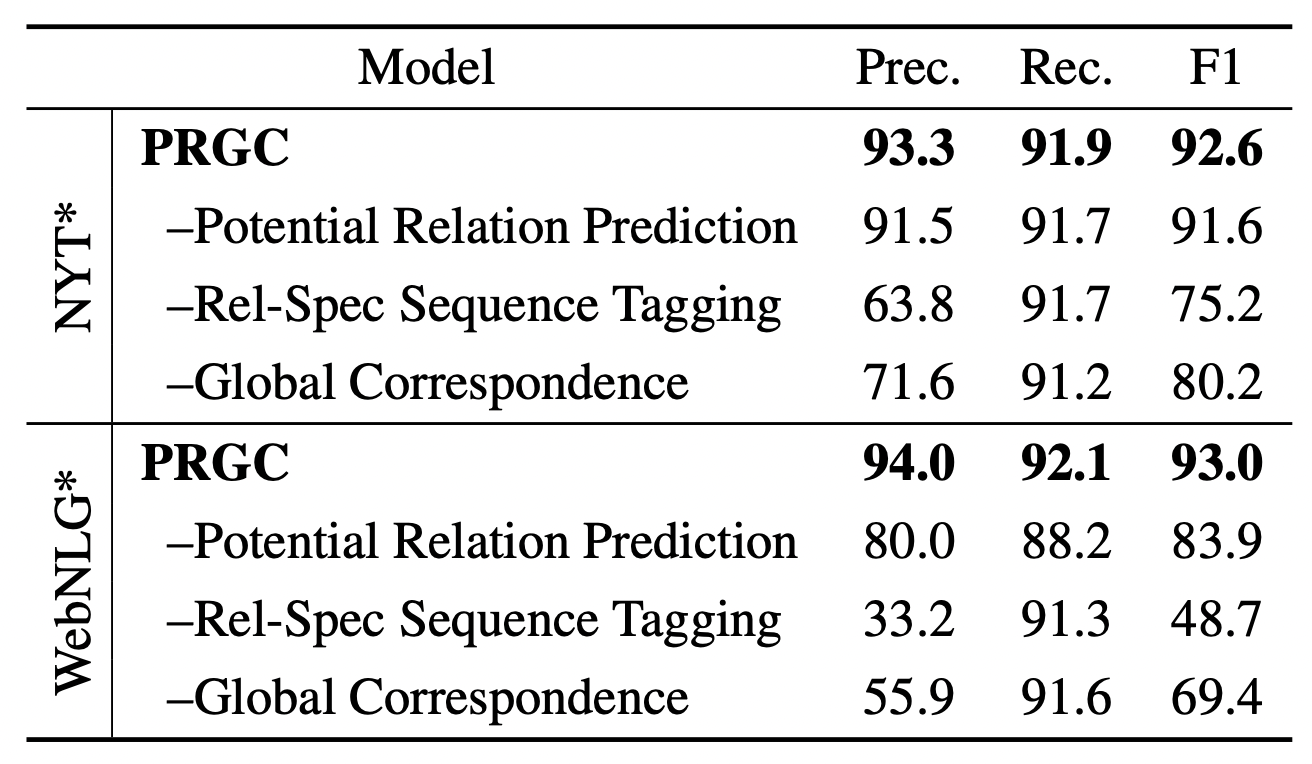
作者探究了PRGC Decoder中各组件所带来的影响:
还有一个关于Rel - Spec Sequence Tagging的Case:

根据实验结果观察, 有如下结论:
Potential Relation Prediction: 去掉该组件后, 不再过滤冗余关系, 而是采用全关系预测. 关系数量比较少的NYT受影响不大, 而WebNLG下降的比较多. 由此说明该组件有良好的过滤冗余关系作用.
其实相对后面两个组件来说这个组件影响并不够大, 可能比较强的点在加速上.
Rel - Spec Sequence Tagging: 将BIO的标注方式替换为抽取实体Span的标注方式后, 精度骤减. 联合Case可以说明该模块使得模型更倾向于关注语义而非关注实体位置, 并且更关注关系.
Global Correspondence: 去掉该组件, 改用启发式最近匹配原则构成三元组, 对精度有很大影响.
Global Correspondence能保证前面两个组件精度低的情况下, 最后组成三元组时的精度, 就怕前面漏标(召回低).
Summary
PRGC把任务拆解为三个子任务: 潜在关系预测, 关系特化的实体标注, 头尾实体对齐, 并按照三个子任务设计了相应的三个模块, 简单明了, 直接有效. 整体来说模型并不复杂, 论文包装的比较好, 给每个模块都找到了相应的解释.
但是因为每个模块的设计思路是按照三元组抽取来的, 所以存在Pipeline模型的通病, Exposure Bias. 如果关系抽错了, 那后面都会错, 如果实体漏标了, 也没法补救.

