TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
本文是论文TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking的阅读笔记和个人理解, 论文来自COLING 2020.
Basic Idea
虽然人们注意到在现有的实体关系抽取工作中, 含有重叠三元组的问题(感觉是特指CasRel), 例如:
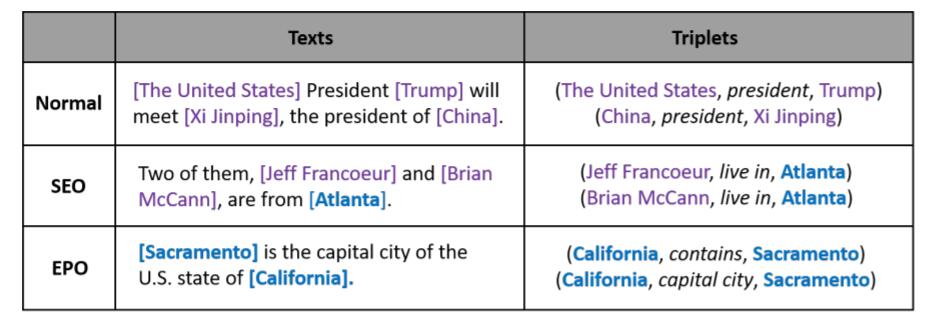
- EPO(Entity Pair Overlap): 实体对重叠是指实体对之间具有多种关系, 这些三元组共享相同的实体.
- SEO(Single Entity Overlap): 单实体重叠是指有单个实体被多个三元组共享.
但现有基于分解的方法仍然受到曝光偏差(Exposure Bias)的困扰, 即Subject和Object的抽取存在先后顺序上的影响, 如果Subject抽取错误, 则会导致错误累积.
所以作者希望一步到位(One Stage)同时抽取Subject和Object, 来规避曝光偏差问题.
TPLinker
HandShaking Tagging Scheme
Tagging
TPLinker将联合抽取建模为Token Pair之间的链接问题(Token Pair Linking Problem).
对于给定的句子中所有的Token Pair, 作者将其之间的链接考虑为:
EH-to-ET: 两Token分别为同实体的起止位置(Entity Head to Entity Tail).
SH-to-OH: 两Token分别为Subject和Object的起始位置(Subject Head to Object Head).
ST-to-OT: 两Token分别为Subject和Object的结束位置(Subject Tail to Object Tail).
简单的记头为实体的起始位置, 尾为实体的结束位置.
对于上述三种链接的情况, 作者给出了一个例子:
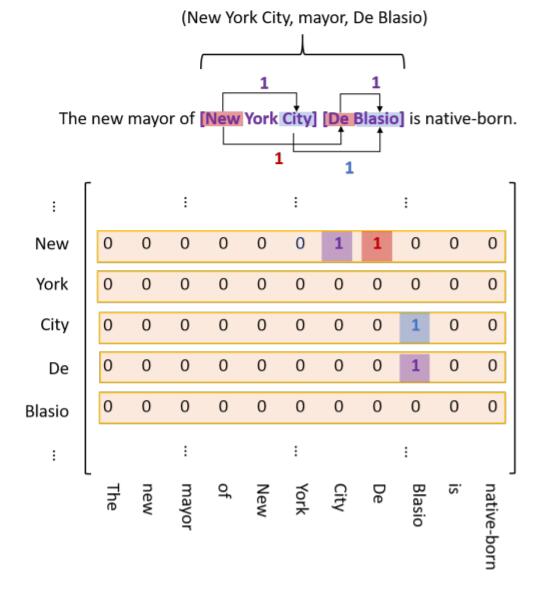
我们从图中与上述三类链接做对应:
- EH-to-ET: 图中的紫色Tag, (
New,City) 就分别是New York City的头尾, (De,Blasio) 分别是De Blasio的头尾. - SH-to-OH: 图中的红色Tag, (
New,De) 分别是给定关系下New York City和De Blasio的头. - ST-to-OT: 图中的蓝色Tag, (
City,Blasio) 分别是给定关系下New York City和De Blasio的尾.
并且, 在关系major中New York City 和De Blasio 分别为Subject和Object.
该建模能够解决SEO问题, 例如嵌套实体New York 和New York City 在关系major 中都共享Object De Blasio(图中未标注), 我们观察量两嵌套Subject和Object的不同Link Type包含的Token Pair:
| Subject | EH-to-ET | SH-to-OH | ST-to-OT |
|---|---|---|---|
New York | (New, York) | (New, De) | (York, Blasio) |
New York City | (New, City) | (New, De) | (City, Blasio) |
尽管两嵌套实体有相同的SH-to-OH, 但其他两种Link的Token Pair并不相同, 自然能区分出共享Object的两个三元组.
除此外, 作者从中有更深的思考:
- 若按图中方式建模, 矩阵会非常稀疏. 并且因为实体的尾永远都在头的前面. 过于稀疏会导致负样本过多, 不易于优化.
- 在EH-to-ET这类Link Type中, 矩阵的下三角永远都是0, 浪费了大量空间.
- 有趣的是, Object可能出现在Subject前面, 所以对于SH-to-OH和ST-to-OT这两种链接类型, 直接把下三角丢掉是错误的.
基于上述问题, 作者巧妙的将下三角的值全部映射到上三角的对应位置, 并把原来的下三角的1转而记为与上三角做区分的2, 在解码阶段做区分就可以了, 如下图所示(注意关系不再是上图的major, 变成了born in, 与刚才的Subject和Object的位置刚好相反, 也就是上文所述第三点的场景):
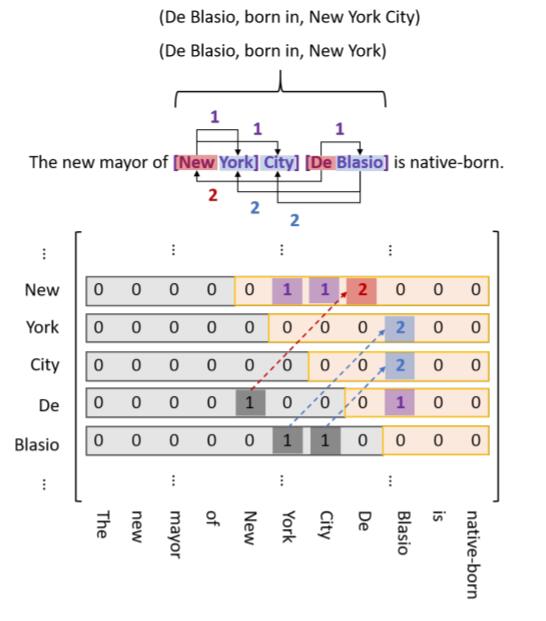
这一映射是我觉得全文最绝的一点.
在下三角时, (De, New) 之间的Link Type为SH-to-OH, 但映射到上三角后, Token Pair内完全颠倒了, 变成了(New, De).
不要紧, 同时交换Token Pair的两Token位置和Link Type的指向, 交换前后是等价的. 也就是说, 若想保持原来SH-to-OH原含义不变, 映射后也必须颠倒, 即OH-to-SH, 也就是反向链接, 即图中的箭头回指. ST-to-OT也同理, (Blasio, York) 映射到上三角后变为(York, Blasio), ST-to-OT变为OT-to-ST.
前文提到SEO能处理了, 那EPO呢? 直接参照CasRel把层叠标注的思想引进过来就行了, 即对每个不同的关系都创建出一张表来分别标注, 也就是关系特化的标注, 这样就能处理同一实体对存在多关系的EPO问题.
应该注意到, 当遇到单个Token实体时, SH-OH和ST-OT会落在同一位置, 因此必须使用两张表来区分它们.
在TPLinker中, EH-to-ET没有必要做关系特化, 因为这种链接类型处理的是Token Pair是否归属于同一实体的问题, 不涉及到跨实体之间的关系. 而SH-to-OH, ST-to-OT是不同实体之间的链接, 涉及到关系, 需要做关系特化.
Decoding
解码过程可以直接拿图来说. 将Token Pair之间的表结构展平,每张表都视为一个序列, 这样方便我们观察不同Relation特化的表的标注情况:
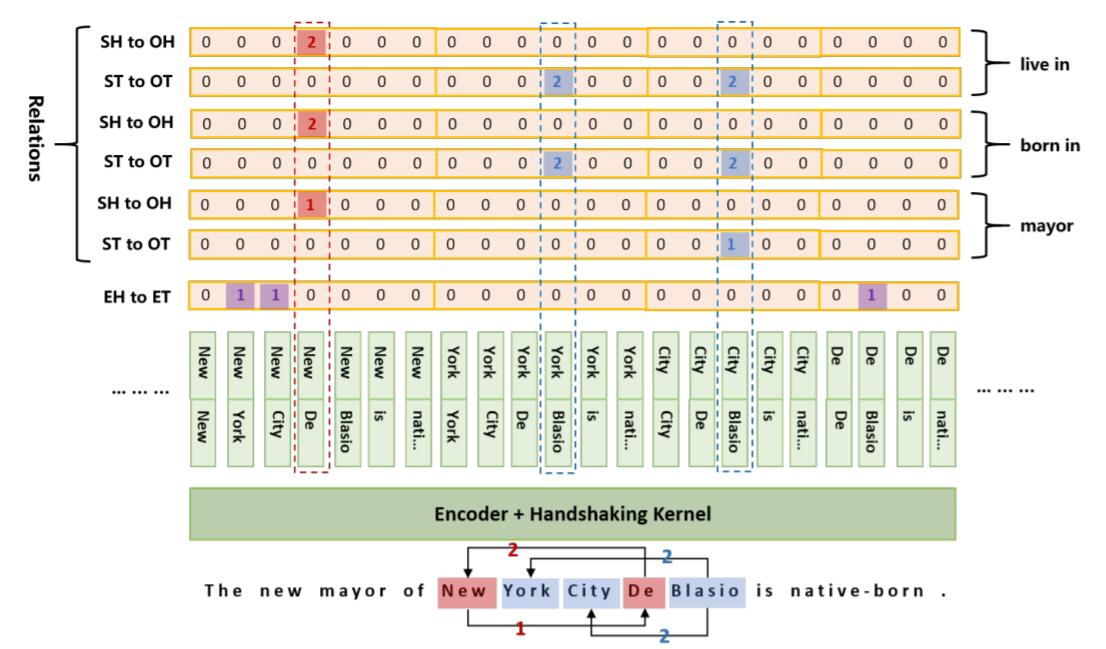
EH-to-ET分别有三个Token Pair, (New, York), (New, City), (De, Blasio), 分别对应实体New York, New York City, De Blasio, 这是区分是否为同实体的Tag, 必须要与其他两种Link Type结合使用.
在关系major中, SH-to-OH标为1的Token Pair为(New, De), 且ST-to-OT标为1的Token Pair为(City, Blasio), 二者均为同向且顺向, 故抽取出三元组(New York City, major, De Blasio).
别忘了2代表反向链接. 在关系born in中, ST-to-OT标为2的Token Pair为(York, Blasio), 结合SH-to-OH标为2的Token Pair(De, New), 二者均为同向且逆向, 故抽取出三元组(De Blasio, born in, New York).
在该图中, EH-to-ET需要一张表, SH-to-OH, ST-to-OT做了关系特化, 分别每个关系需要一张表, 共计$2|R| + 1$ 张表. 但是由于做了下三角舍弃的优化, 若句长为$n$, 每张表只有$\frac{n^2+n}{2}$ 个元素.
TPLinker的解码流程伪代码如下:

可以概括为:
- 根据EH-toET的表, 检测所有存在的实体, 存入字典$D$.
- 对每一种关系, 根据ST-to-OT的表记录Subject和Object的尾位置存入集合$E$. 将Tag为1的顺序记下来, 及Tag为2的逆序记下来.
- 对每一种关系, 根据SH-to-OH的表获得Subject和Object的头位置(Tag为1, 2, 同上), 直接去$D$ 中查询对应的实体对, 查询到后去$E$ 中做匹配, 如果命中, 则抽取出三元组.
Token Pair Representation
对于长为$n$ 的句子$[w_1, w_2, \cdots, w_n]$, 首先将每个Token都用Encoder(应该是BERT之类)映射成上下文相关的低维表示$\mathbf{h_i}$, 然后按如下方式生成$(w_i, w_j)$ 之间的Token Pair表示$\mathbf{h}_{i, j}$:
$$
\mathbf{h}_{i, j}=\tanh \left(\mathbf{W}_{h} \cdot\left[\mathbf{h}_{\mathbf{i}} ; \mathbf{h}_{\mathbf{j}}\right]+\mathbf{b}_{h}\right), j \geq i
$$
其中$\mathbf{W}_h, \mathbf{b}_h$ 为可学习参数.
Handshaking Tagger
我们只需要很简单的对Token Pair之间的表示做Softmax就好:
$$
\begin{aligned}
&P\left(y_{i, j}\right)=\operatorname{Softmax}\left(\mathbf{W}_{o} \cdot \mathbf{h}_{i, j}+\mathbf{b}_{o}\right) \\
&\operatorname{link}\left(w_{i}, w_{j}\right)=\arg \max _{l} P\left(y_{i, j}=l\right)
\end{aligned}
$$
记Token Pair $(w_i, w_j)$ 之间的链接标签为$l$, $P(y_{i, j}=l)$ 为预测值为标签的概率.
这样就可以把前面图中的所有Token Pair之间的打上Tag.
Loss Function
损失函数为NLL Loss:
$$
L_{l i n k}=-\frac{1}{N} \sum_{i=1, j \geq i}^{N} \sum_{\ast \in\{E, H, T\}} \log P\left(y_{i, j}^{\ast}=\hat{l}^{\ast}\right)
$$
$N$ 为句子长, $\hat{l}$ 为正确Tag, $E, H, T$ 分别代表EH-to-ET, SH-toOH, ST-to-OT.
Experiments
详细的参数设置请参照原论文.
Dataset
作者所采用的数据集为常用数据集NYT和WebNLG, 统计信息如下:

下文中, NYT*, WebNLG*, 均代表部分匹配下的结果, 否则为精准匹配结果.
Main Results
作者将TPLinker与Tagging类, 生成类的模型, 以及其他类的模型放在一起做了对比, 结果如下:
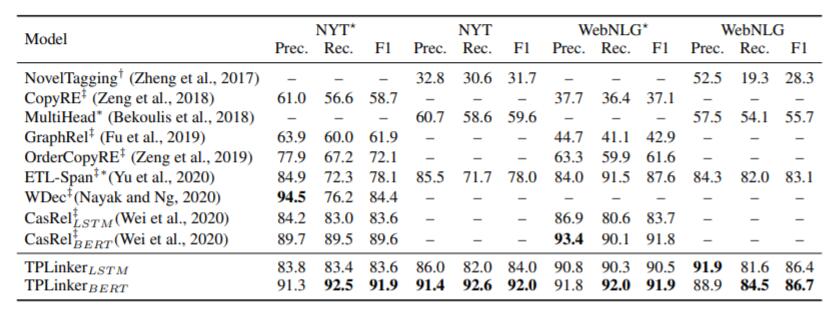
主要观察CasRel和TPLinker之间的性能差距. TPLinker在LSTM下与CasRel取得了相近的性能, BERT抽取出的特征对TPLinker的增益比CasRel要大得多.
Analysis on Different Sentence Types
作者对三元组不同类型, 每条样本中三元组的个数分类, 观察TPLinker的能力, 结果如下:
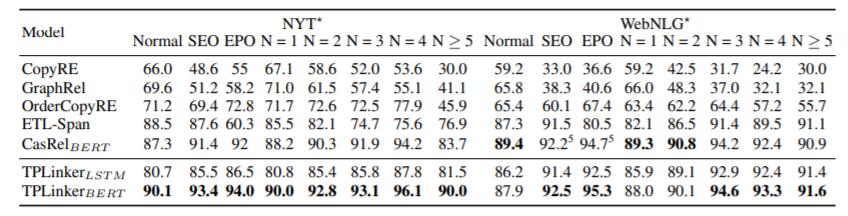
从中观察到, TPLinker不太受句子中三元组数量增多的影响, 同时处理SEO和EPO问题的效果也都很不错.
Analysis on Computational Efficiency
最后, TPLinker的解码相对于其他模型来说是比较复杂的, 或许从直观上来看, 这可能成为TPLinker的弱势, 所以作者还做了TPLinker和CasRel的复杂度比较:

TPLinker的推理时间其实并没有像想象中的那么长, 也算是打消了直观上的疑虑.
Summary
本质上, TPLinker巧妙的将联合抽取问题建模为Token Pair之间的关系抽取问题, 使得联合抽取一步到位, 不但规避了归纳偏置问题, 还能同时处理EPO, SEO问题. 效果也超越了之前SOTA的CasRel.
方法很简练, 没有花里胡哨. 本篇论文有颇多值得思考的地方, 除了对抽取任务本身的考量, 能看得出来作者的工程思维很强, 在比较容易被质疑的算法复杂度部分提出了一种减少空间开销的实现, 并专门做了时间开销的比较, 这是值得学习的地方.

