Joint Entity and Relation Extraction with Set Prediction Networks
本文是论文Joint Entity and Relation Extraction with Set Prediction Networks 的阅读笔记和个人理解.
Basic Idea
现有的基于Seq2Seq的方法, 在训练阶段需要将三元组集合转化为Sequence输入到模型中, 这样存在预测三元组之间顺序的问题, 但实际上句子中抽取出的三元组是无序的. 作者希望将RTE问题转化直接的集合预测问题, 并使用非自回归Decoder来解决集合预测问题.
SPN
Task Definition
对与输入序列$X$, Relational Triple Extraction的任务目标是抽取所有目标三元组$Y=\set{(s_1, r_1, o_1), \dots, (s_n, r_n, o_n)}$, 其条件概率为:
$$
P(Y \mid X ; \theta)=p_{L}(n \mid X) \prod_{i=1}^{n} p\left(Y_{i} \mid X, Y_{j \neq i} ; \theta\right)
$$
其中$p_L(n|X)$ 建模了句子中目标三元组的数量, $p\left(Y_{i} \mid X, Y_{j \neq i} ; \theta\right)$ 代表目标三元组$Y_i$ 与句子中其他存在的三元组$Y_{j \neq i}$和输入序列$X$ 同时相关.
Sentence Encoder
Sentence Encoder直接用BERT, 提取到的特征为$\mathbf{H}_e \in \mathbb{R} ^{l \times d}$, $l$ 为包括[CLS]和[SEP]的序列长度.
Non - Autoregressive Decoder for Triple Set Generation
首先来介绍下, Non - Autoregressive Decoder(NAD)最早使用在机器翻译中, 与三元组抽取问题出发点完全不同. 生成译文时如果是自回归的方式太慢了, 非自回归的生成方式可以一次性生成所有译文. 具体的, 在Decoder进行解码时并非一步一步的遵循自回归将输入反复喂入Decoder中得到单步生成内容, 而是使用多个Query向量同时喂入Decoder中以得到全部的生成内容:
该图出自最早采用NAD的论文Non-Autoregressive Neural Machine Translation, 当时所使用的方法是将输入端内容复制多次喂入Decoder, 与现在使用的Query Embedding相似.
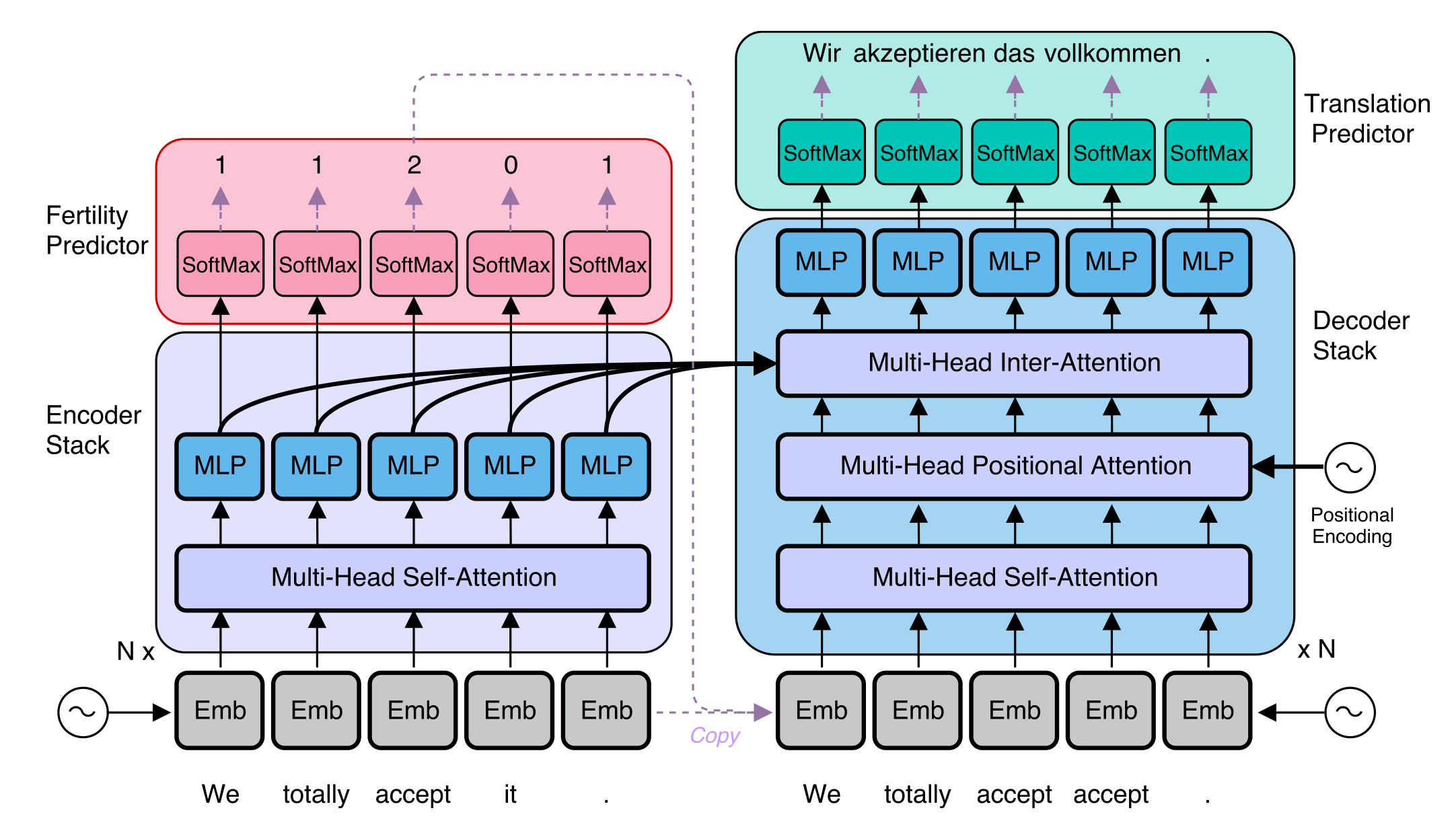
Input
现在我们回归正题. 前人已有方法往往将三元组抽取建模为序列生成问题, 由于使用的是自回归Deocder, 模型生成三元组时明显存在三先后生成顺序的问题:
$$
P(Y \mid X ; \theta)=\prod_{i=1}^{n} p\left(Y_{i} \mid X, Y_{j<i} ; \theta\right)
$$
而作者将三元组抽取视为一个用NAD完成的集合预测问题, 式子同Task Definition中给出的句子中所有目标三元组条件概率公式:
$$
P(Y \mid X ; \theta)=p_{L}(n \mid X) \prod_{i=1}^{n} p\left(Y_{i} \mid X, Y_{j \neq i} ; \theta\right)
$$
在解码前, Decoder需要知道句子中的目标三元组个数. 作者简单的设$p_L(n|X)$ 为一个常数. 对于每个句子, Decoder需要预测比句子Ground Truth中三元组数量$n$ 稍大一点的固定的集合数$m$, 以达到三元组全覆盖的效果. 具体的, 在词表中添加$m$ 个可学习的Query Embedding, 在Decoder解码时一次性输入即可.
Architecture
SPN的模型结构本身其实比较简单, 就是由BERT和NAD以及最后分类用的FFN组成:
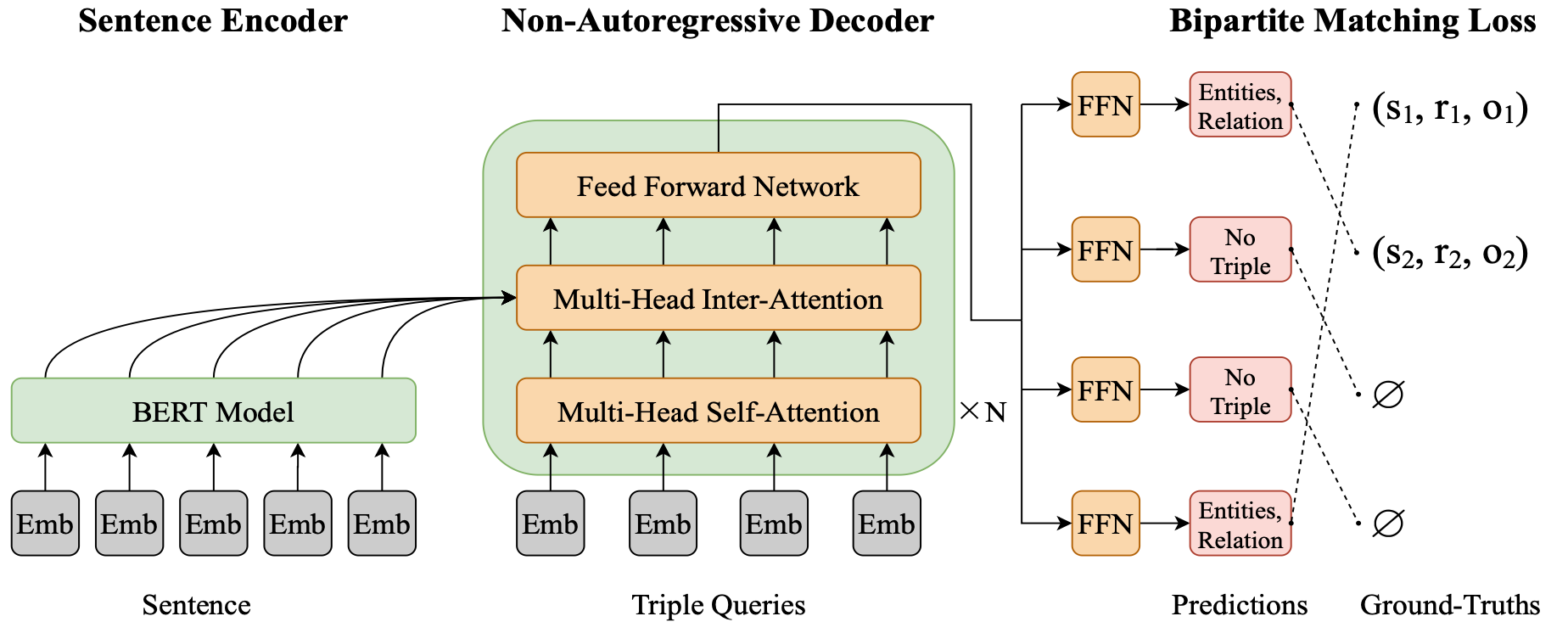
将$m$ 个三元组Query Vector同时输入NAD, 同时获得所有三元组表示记为$\mathbf{H}_d \in \mathbb{R}^{m \times d}$, Decoder生成的三元组中的关系和实体由不同的FFN得到.
由于使用的是NAD, 所有三元组是被一次性生成的, 所以Decoder可以做到双向解码, 同Encoder的双向上下文.
每个Decoder的输出$\mathbf{h}_d \in \mathbb{R}^d$, 目标三元组对应的关系$r$ 的概率$\mathbf{p}^r$ 可以由下式得到:
$$
\mathbf{p}^{r}=\operatorname{softmax}\left(\mathbf{W}_{\mathbf{r}} \mathbf{h}_{\mathrm{d}}\right)
$$
其中, $\mathbf{W}_r$ 为可训练参数.
每个目标三元组中的实体由起始位置和结束位置分别确定, 也就是做$l$ 分类. Decoder每个输出$\mathbf{h}_d$ 和BERT下的句子输出 $\mathbf{H}_e$ 同时将Subject和Object的下标分别确定下来:
$$
\begin{aligned}
\mathbf{p}^{s-s t a r t} &=\operatorname{softmax}\left(\mathbf{v}_{\mathbf{1}}^{\mathbf{T}} \tanh \left(\mathbf{W}_{\mathbf{1}} \mathbf{h}_{\mathrm{d}}+\mathbf{W}_{\mathbf{2}} \mathbf{H}_{\mathbf{e}}\right)\right) \\
\mathbf{p}^{s-e n d} &=\operatorname{softmax}\left(\mathbf{v}_{\mathbf{2}}^{\mathbf{T}} \tanh \left(\mathbf{W}_{\mathbf{3}} \mathbf{h}_{\mathrm{d}}+\mathbf{W}_{\mathbf{4}} \mathbf{H}_{\mathbf{e}}\right)\right) \\
\mathbf{p}^{o-s t a r t} &=\operatorname{softmax}\left(\mathbf{v}_{\mathbf{3}}^{\mathbf{T}} \tanh \left(\mathbf{W}_{\mathbf{5}} \mathbf{h}_{\mathrm{d}}+\mathbf{W}_{\mathbf{6}} \mathbf{H}_{\mathbf{e}}\right)\right) \\
\mathbf{p}^{o-e n d} &=\operatorname{softmax}\left(\mathbf{v}_{\mathbf{4}}^{\mathbf{T}} \tanh \left(\mathbf{W}_{\mathbf{7}} \mathbf{h}_{\mathrm{d}}+\mathbf{W}_{\mathbf{8}} \mathbf{H}_{\mathbf{e}}\right)\right)
\end{aligned}
$$
其中, $\set{\mathbf{W}_i \in \mathbb{R}^{d \times d}}^8_{i=1}, \set{\mathbf{v}_i \in \mathbb{R}^{d \times d}}^4_{i=1}$ 为可学习参数, $t$ 为包含空关系在内的所有关系总数, $l$ 为句子长度.
Bipartite Matching Loss
由于将联合抽取视为一个集合预测问题, 所以在优化时使用自回归时所采用的有序交叉熵就不太合适了, 因为自回归中的交叉熵是对每个时间步Decoder的输出分别应用上去的. 但是在三元组抽取任务中, 三元组本身是无序的, 模型生成的顺序和Ground Truth不一定完全匹配.
对此, 作者的解决思路非常简单, 既然原来交叉熵是有序的, 那我做全排列穷举出所有的顺序, 找到一个和Ground Truth相匹配的序列不就行了? 没错, 该过程可以抽象为一个二部图匹配问题, 需要找到模型预测结果和Ground Truth之间的一个最优匹配结果:
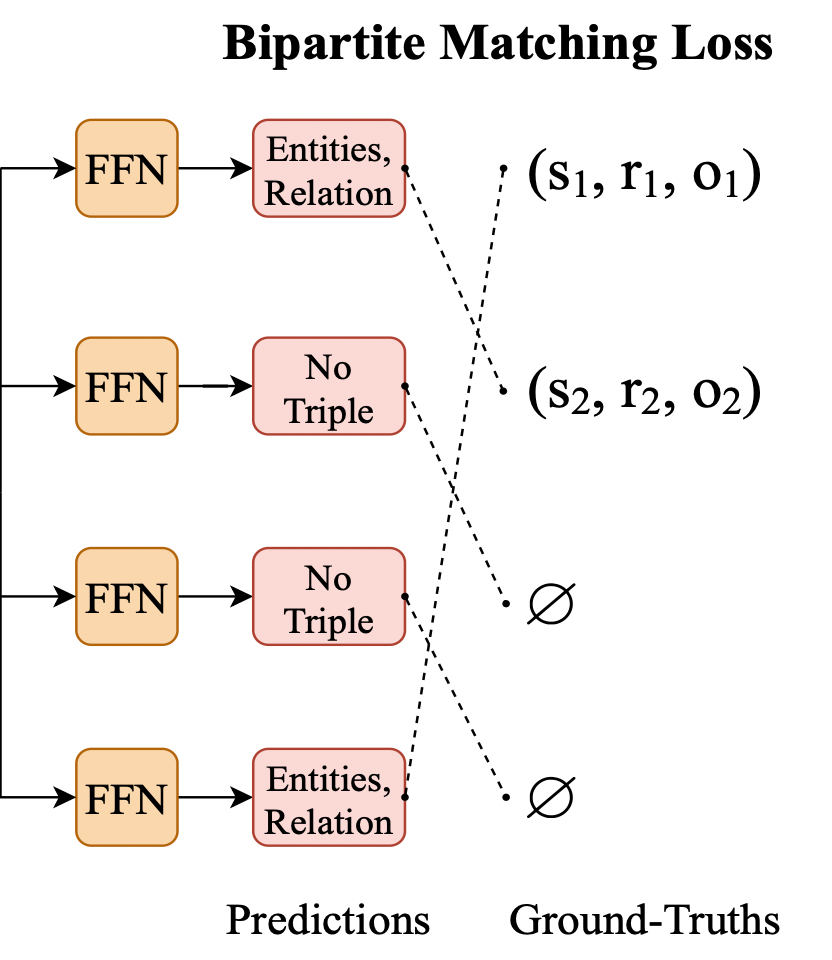
假定$\mathbf{Y}=\left\{\mathbf{Y}_{i}\right\}_{i=1}^{n}$ 为Ground Truth, $\hat{\mathbf{Y}}=\left\{\hat{\mathbf{Y}}_{i}\right\}_{i=1}^{m}$ 为模型预测到的三元组. 因为$m$ 比$n$ 要稍大些, 所以把多出来的那部分用空三元组填上.
更为具体的, 需要找到使得Cost最小的三元组排列顺序$\pi^\star$:
$$
\pi^{\star}=\underset{\pi \in \Pi(m)}{\arg \min } \sum_{i=1}^{m} \mathcal{C}_{m a t c h}\left(\mathbf{Y}_{i}, \hat{\mathbf{Y}}_{\pi(i)}\right)
$$
其中$\Pi(m)$ 代表长度为$m$ 的全排列空间, $\mathcal{C}_{m a t c h}\left(\mathbf{Y}_{i}, \hat{\mathbf{Y}}_{\pi(i)}\right)$ 为Ground Truth$\mathbf{Y}_i$ 和排列顺序为$\pi(i)$ 时的模型预测结果$\hat{\mathbf{Y}}_{\pi(i)}$ 之间的Cost.
接着定义二部图匹配的Cost, 每个三元组实际上由五元组确定, 即Ground Truth $\mathbf{Y}_i = \left(r_{i}, s_{i}^{\text {start }}, s_{i}^{e n d}, o_{i}^{\text {start }}, o_{i}^{e n d}\right)$, 模型预测结果 $\hat{\mathbf{Y}}_{i}=\left(\mathbf{p}_{i}^{r}, \mathbf{p}_{i}^{s-s t a r t}, \mathbf{p}_{i}^{s-e n d}, \mathbf{p}_{i}^{o-s t a r t}, \mathbf{p}_{i}^{o-e n d}\right)$, 定义$\mathcal{C}_{m a t c h}\left(\mathbf{Y}_{i}, \hat{\mathbf{Y}}_{\pi(i)}\right)$ 如下:
$$
\begin{aligned}
\mathcal{C}_{\text {match}}\left(\mathbf{Y}_{i}, \hat{\mathbf{Y}}_{\pi(i)}\right)
&=-\mathbb{1}_{\left\{r_{i} \neq \varnothing\right\}}\left[\mathbf{p}_{\pi(i)}^{r}\left(r_{i}\right)\right.\\
&+\mathbf{p}_{\pi(i)}^{s-start}\left(s_{i}^{start}\right) \\
&+\mathbf{p}_{\pi(i)}^{s-e n d}\left(s_{i}^{end }\right) \\
&+\mathbf{p}_{\pi(i)}^{o- start }\left(o_{i}^{start }\right) \\
&+\mathbf{p}_{\pi(i)}^{o-e n d}\left(o_{i}^{end }\right)\left.\right]
\end{aligned}
$$
在指示函数$\mathbb{1}$ 影响下, $\mathbf{p}_{\pi(i)}^{r}(r_i)$ 就代表模型预测排列为$\pi(i)$ 时关系为$r_i$ 的概率, 对于实体位置的表示同理.
上式即计算预测关系$r_i$ 不为空时, Ground Truth对应的关系类型, Subject, Object的起始位置和结束位置的概率的和.
如果Ground Truth所对应的预测概率比较大, 那么Cost就比较小, 这种排序就越有可能是对Ground Truth的最优排序.
作者在这里采用匈牙利算法来完成二部图匹配, 由此可以得到Ground Truth所对应的最优模型预测排序, 由此规避生成三元组顺序与Ground Truth不一致的问题.
扩展阅读:
匈牙利算法的作用是找到二部图的最大或最小匹配(要求二部图的两个集合节点数相同), 在这里是找到$\mathbf{Y}$ 和$\hat{\mathbf{Y}}$ 之间Cost的最小匹配.
最后按照最优的排列顺序$\pi^\star$ 去计算负对数似然, 最大化最优排序下对应的关系预测概率和实体起始结束位置概率:
$$
\begin{aligned}
\mathcal{L}(\mathbf{Y}, \hat{\mathbf{Y}}) &=\sum_{i=1}^{m}\left\{-\log \mathbf{p}_{\pi^{\star}(i)}^{r}\left(r_{i}\right)\right.\\
&+\mathbb{1}_{\left\{r_{i} \neq \varnothing\right\}}\left[-\log \mathbf{p}_{\pi^{\star}(i)}^{s-s t a r t}\left(s_{i}^{start }\right)\right.\\
&-\log \mathbf{p}_{\pi^{\star}(i)}^{s-e n d}\left(s_{i}^{end}\right) \\
&-\log \mathbf{p}_{\pi^{\star}(i)}^{o-s t a r t}\left(o_{i}^{start }\right) \\
&\left.\left.-\log \mathbf{p}_{\pi^{\star}(i)}^{o-e n d}\left(o_{i}^{end}\right)\right]\right\}
\end{aligned}
$$
没理解也不要紧, 原文附录中有一个完整的例子, 可以帮助大家理解二部图匹配损失, 可以自行查阅原论文.
Experiments
详细的参数设置请参照原论文.
Datasets
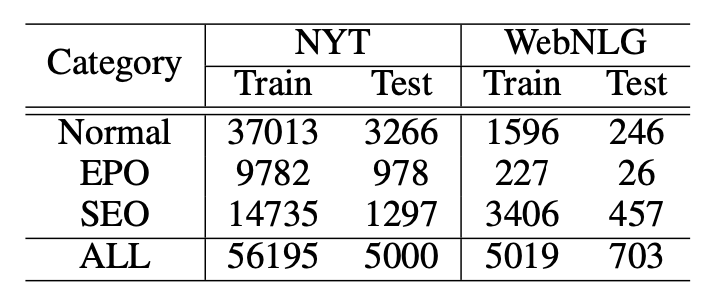
所采用的数据集是两个常用数据集NYT24和WebNLG, 具体信息如下:
Main Results
在NYT24上, SPN的部分匹配和精准匹配结果如下:
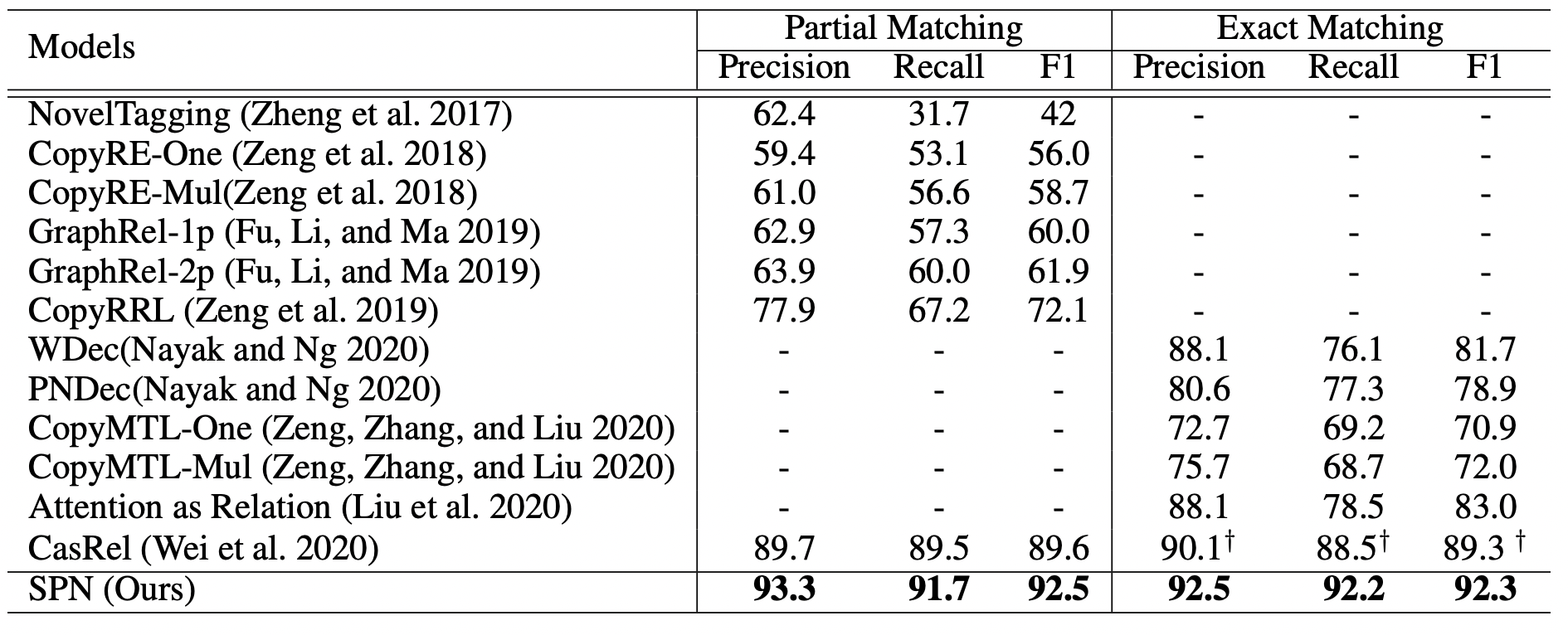
当时最厉害的SOTA还是CasRel, SPN超过了CasRel, 实际上也超过了同年的TPLinker.
在WebNLG上结果如下:
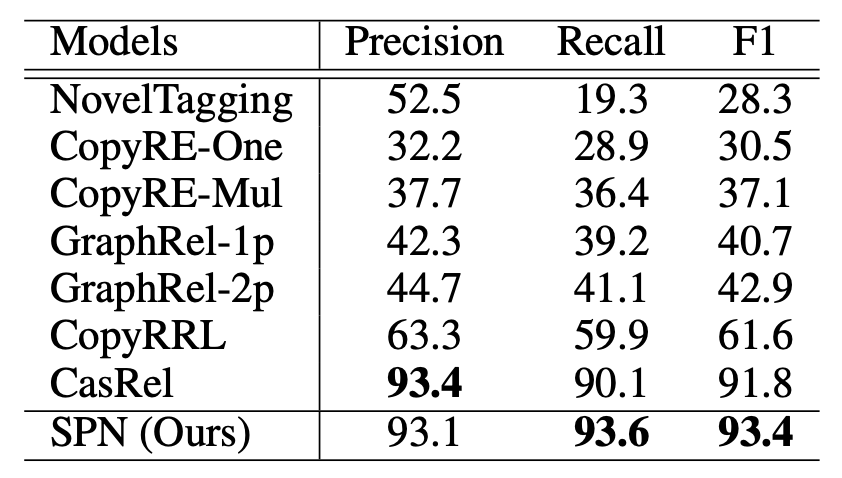
在WebNLG上SPN的Recall比CasRel要高得多, 个人认为这种收益来自于比Ground Truth多数量稍一点的Query Embedding, 且和SPN同时抽取实体和关系有关(CasRel是两阶段抽取).
分类看实体和关系的抽取结果如下:
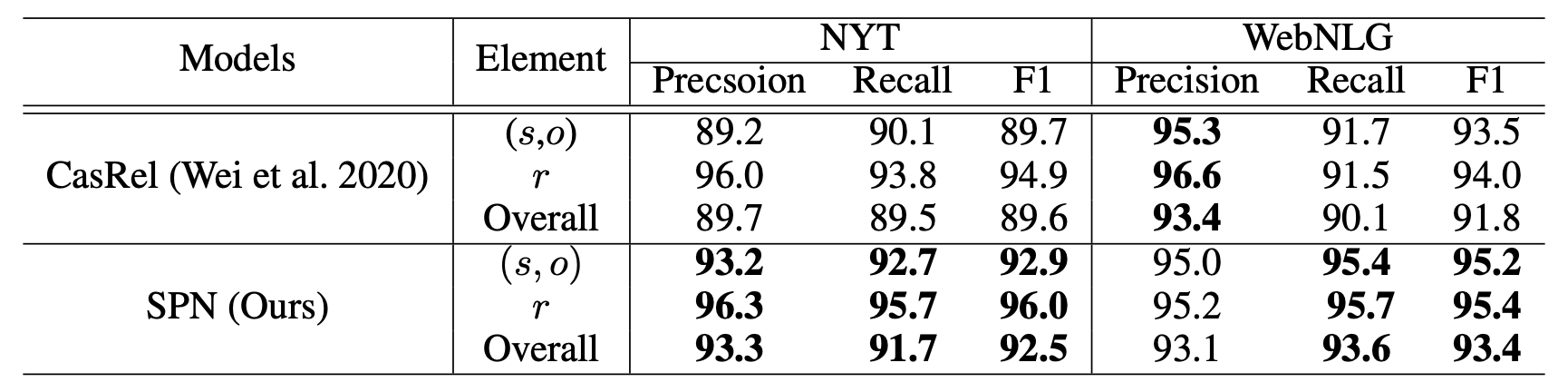
CasRel除了在WebNLG的精度上稍稍比SPN好一点, 其余地方都不如SPN.
Ablation Study
SPN在NYT24上的消融实验结果如下:
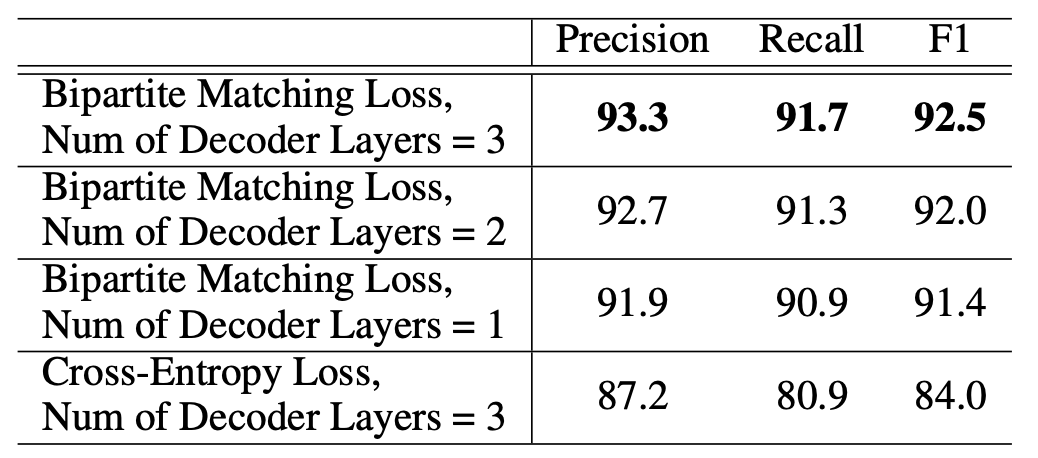
不使用二部图匹配损失, 而是强套一个交叉熵上去, 严重的影响了Recall, Precision也有很大影响, NAD和二部图匹配损失才是最为重要的核心部分. 从Decoder层数来看的话, 单纯堆叠层出带来的增益没想象中那么小.
Sentences with Different Number of Triples
将句子中的三元组个数进行分类, 结果如下:
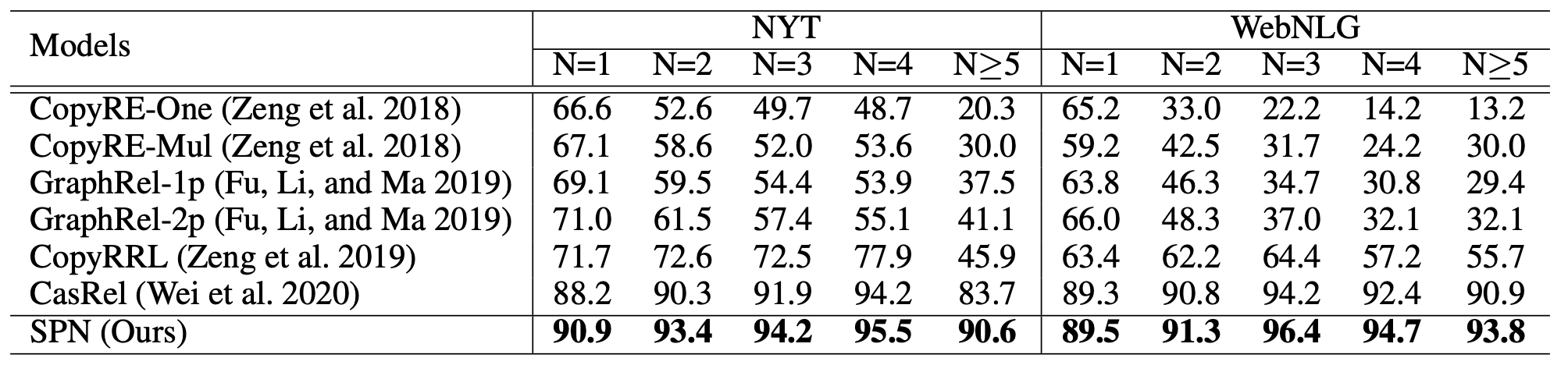
SPN的各类型抽取效果都比CasRel好, 在NYT上的多三元组抽取比CasRel好挺多.
Different Overlapping Patterns
按照不同的重叠类型区分句子, 结果如下:
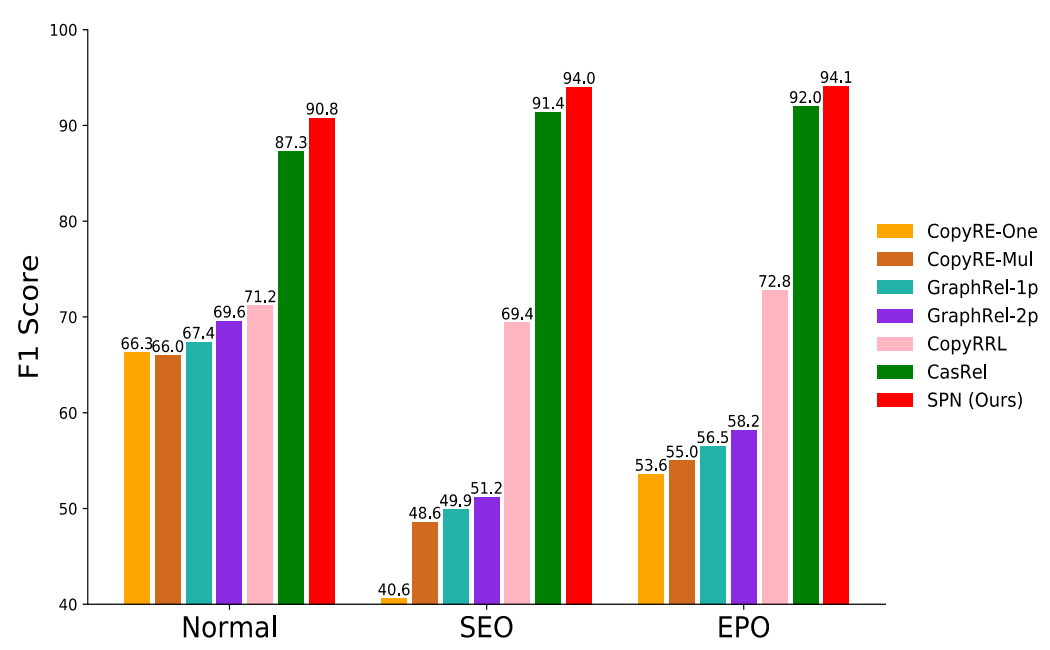
SPN本身并没有设计特别针对SEO和EPO的优化方法, 似乎对普通三元组的抽取能力提升更大些.
Summary
SPN算是生成和Tagging混合的RTE模型, 不同于前人所使用的生成式方法, 将三元组抽取完全建模为自回归生成式任务, 而是将RTE建模为集合预测问题, 避免了三元组生成时存在的先后顺序问题, 同时因为使用了NAD, 获得了双向解码的能力, 使得每个三元组生成时都可以考虑到其他三元组的信息.
也是很巧, NAD因为在机器翻译中难以保证序列的生成顺序而导致性能降低, 而在RTE问题中根本不需要考虑三元组之间的顺序问题, NAD用在这里非常合适.
SPN性能不错, 相对于模型结构本身, 把三元组抽取建模成集合预测的思想倒是比较重要, 在NAD的选取和二部图匹配损失的设计上都有体现.
另外, 有兴趣的小伙伴可以看看DETR: End-to-End Object Detection with Transformers这篇文章, SPN和DETR实际上是几乎一样的.

