本文前置知识:
RFBFN: A Relation - First Blank Filling Network for Joint Relational Triple Extraction
本文是论文RFBFN: A Relation-First Blank Filling Network for Joint Relational Triple Extraction的阅读笔记和个人理解, 论文来自ACL 2022.
Basic Idea
现有的RTE工作要么忽略了关系的语义信息, 要么抽取Subject和Object带有先后顺序:
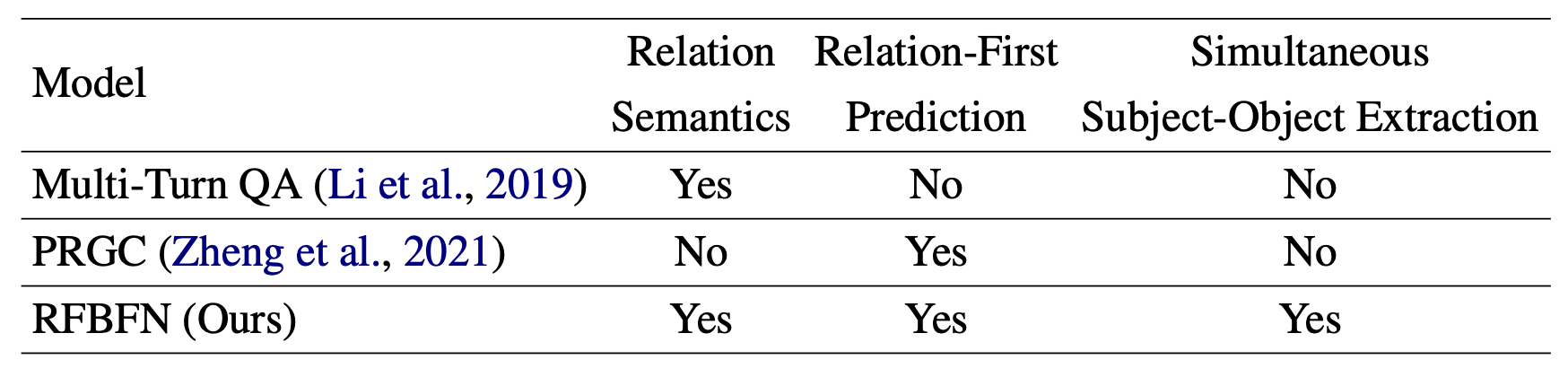
针对上述两点, 作者希望提出一种兼顾关系间语义信息, 且不带有Subject和Object的预测顺序的模型.
RFBFN
Task Definition
输入一个包含[CLS] Token $x_{cls}$ 在内有$n$ 个Token的句子$X=(x_1, x_2, \dots, x_n)$, 任务目标为抽取出句子中所有可能的三元组$T(X) = (e_i, r_{ij}, e_j)$, $e_i, e_j$ 分别为代表Subject和Object的Token, $r_{ij} \in \mathcal{R}$ 为二者间的关系, $\mathcal{R}$ 为预先定义好的关系集.
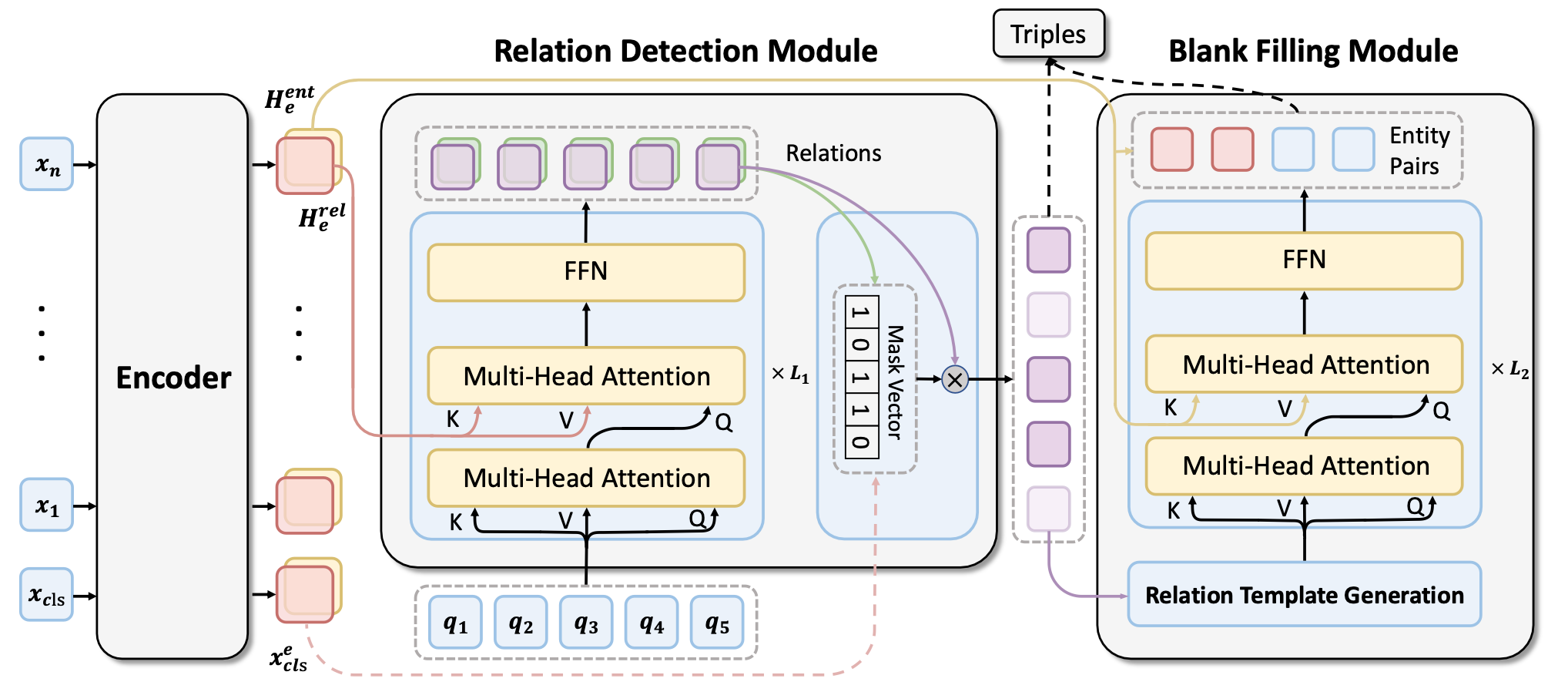
Overview
按序分为三部分:
- Span - Level Encoder: 从输入文本中抽取出Span表示.
- Relation Detection Module: 预测句子中的潜在关系, 并过滤掉不相关的关系.
- Blank Filling Module: 用很多指明关系的模板作为输入, 预测该关系下对应的实体对.
将关系抽取任务建模为完形填空任务, 可以兼顾考虑关系的语义信息, 同时抽取出Subject和Object:
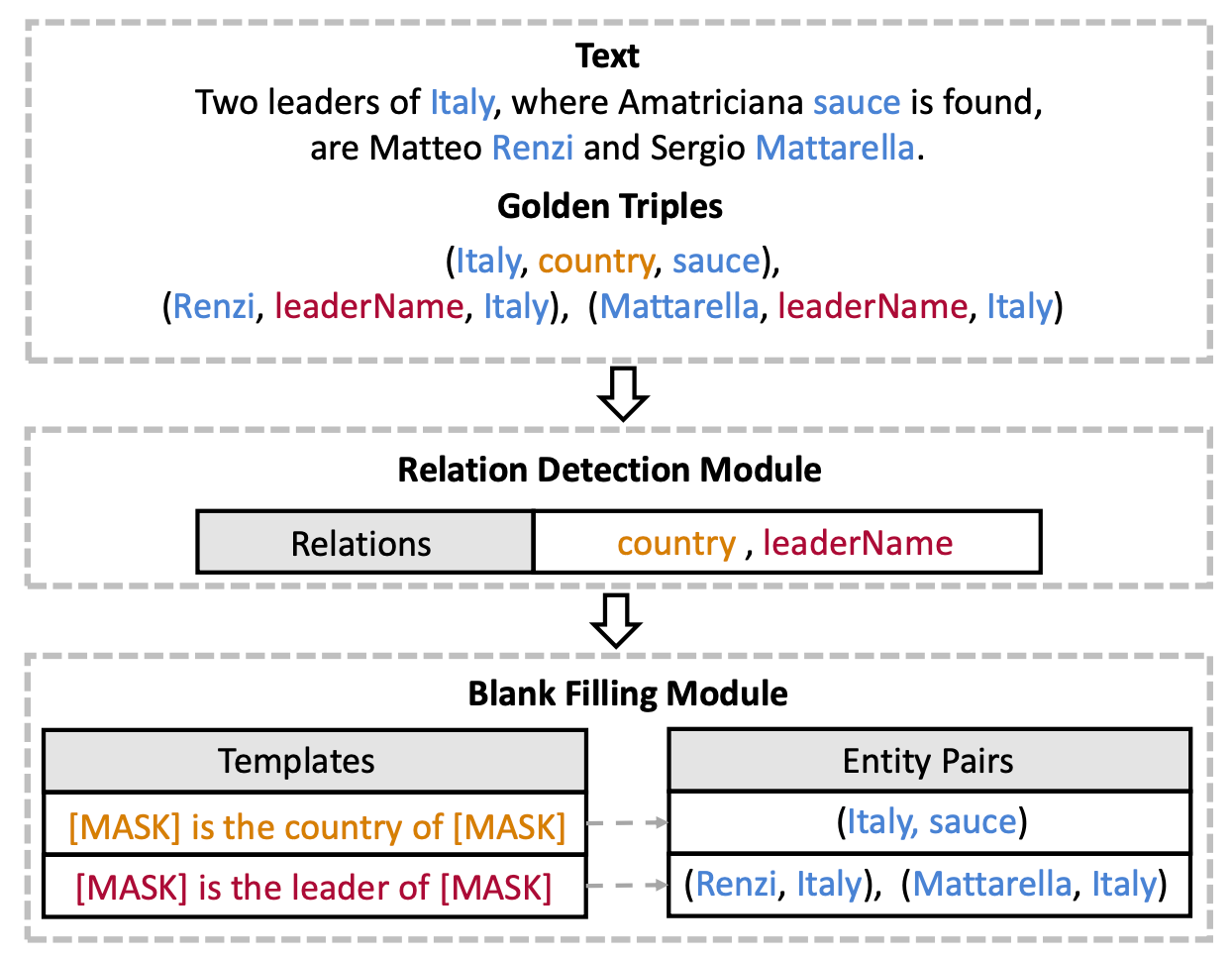
模型概览图如下:
Span - Level Encoder
Span - Level Encoder通过BERT来抽取句子中的Span表示. 令$S=(s_1, s_2, \dots, s_{n_s})$ 为输入句子$X$ 中的所有Span, 则对于Span $s_i \in S$, 其表示$\mathbf{h}_i^e$ 定义为:
$$
\mathbf{h}_{\mathrm{i}}^{\mathrm{e}}=\left[\mathbf{x}_{\mathrm{START}(\mathrm{i})}^{\mathrm{e}} ; \mathbf{x}_{\operatorname{END}(\mathrm{i})}^{\mathrm{e}} ; \phi\left(\mathbf{x}_{\mathrm{i}}\right)\right]
$$
其中$\mathbf{x}_{\text{START(i)}}^e, \mathbf{x}_{\text{END(i)}}^e$ 为上下文感知的边界Token, $\phi(\mathbf{x}_i)$ 为跟Span长度相关的Embedding. 记Encoder输出的所有Span表示为$\mathbf{H}^e \in \mathbb{R}^{n_s \times d}$, $d$ 为Embedding维度.
然后分别将$\mathbf{H}^e$ 通过两个不同的FFN获得Span中的关系表示$\mathbf{H}_{\mathrm{e}}^{\mathrm{rel}}$ 和实体表示$\mathbf{H}_{\mathrm{e}}^{\mathrm{ent}}$:
$$
\begin{aligned}
&\mathbf{H}_{\mathrm{e}}^{\mathrm{rel}}=\mathbf{W}_{r e l} \mathbf{H}^{e}+\mathbf{b}_{r e l} \\
&\mathbf{H}_{\mathrm{e}}^{\mathrm{ent}}=\mathbf{W}_{e n t} \mathbf{H}^{e}+\mathbf{b}_{e n t}
\end{aligned}
$$
其中, $\mathbf{W}_{rel}, \mathbf{W}_{ent} \in \mathbb{R} ^{d \times d}, \mathbf{b}_{rel}, \mathbf{b}_{ent} \in \mathbb{R}^d$ 均为可学习参数.
Relation Detection Module
与之前大多数对关系的处理方式不同, 之前大多同时考虑所有关系, 引入了相当多的冗余计算.
作者先抽取句子中关系的候选集, 然后在这些候选关系的基础上再做Subject和Object的预测.
与SPN类似的, RFBFN使用Non - Autoregressive Decoder(NAD)并将关系作为二元分类问题抽取出来.
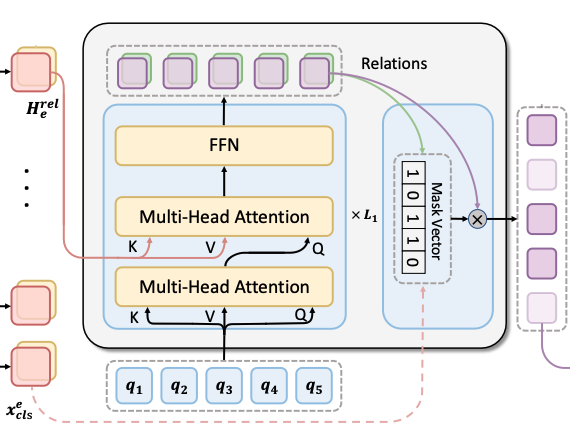
Potential Relation Extractor
具体的, NAD被输入多个可学习的Query Embedding $\mathbf{Q} \in \mathbb{R}^{\mathrm{n}_q \times d}$, 其中$n_q$ 为句子中最大可能的关系数量. NAD涉及到的信息流如节初图所示.
用先前计算好的关系侧Span表示$\mathbf{H}^{\text{rel}}_{\text{e}}$ 作为NAD的输入, NAD的输出为$\mathbf{H}^{\mathrm{r}} \in \mathbb{R}^{\mathrm{n_q} \times \mathrm d}$. 第$i$ 个输出$\mathbf{h}_{\mathrm{i}}^{\mathrm{r}}$ 所对应的关系类型概率$\mathbf{p}_{\mathrm{i}}^{\mathrm{r}}$ 由线性层后Softmax得到:
$$
\mathbf{p}_{\mathrm{i}}^{\mathrm{r}}=\operatorname{Softmax}\left(\mathbf{W}_{\mathrm{r}} \mathbf{h}_{\mathrm{i}}^{\mathrm{r}}+\mathbf{b}_{\mathrm{r}}\right)
$$
其中$\mathbf{W}_r \in \mathbb{R}^{|\mathcal{R}| \times d}, \mathbf{b}_r \in \mathbf{R}^{|\mathcal{R}|}$ 为可学习参数, $|\mathcal{R}|$ 为关系类型的总数. 因为存在Decoder输出的先后顺序问题, 和SPN一样的使用了二部图匹配损失.
Candidate Relation Judgement
在预测完句子中潜在的关系子集后, 需要过滤掉无关关系以有效生成模板.
Candidate Relation Judgement以NAD的输出表征$\mathbf{H}^\mathrm{r}$ 和[CLS] 的Embedding作为输入, 以一个Mask向量$\mathbf{M}$ (其中的值都是布尔值)作为输出, 以确定该类型关系是否在该句子中成立:
$$
\mathbf{M}=\sigma\left(\mathbf{W}_{\mathrm{s}}\left[\mathbf{H}^{\mathrm{r}} ; \mathbf{x}_{\mathrm{cls}}^{\mathrm{e}}\right]+\mathbf{b}_{\mathrm{s}}\right)
$$
其中$\mathbf{W}_s, \mathbf{b}_s$ 为可学习参数, $\sigma$ 为Sigmoid激活函数. $\mathbf{M}$ 中的值越大, 该句子中包含该关系的置信度就越大.
在Potential Relation Extractor中, 由于使用的是Softmax, 所以每个Query Embedding一定都有一个对应的关系, 但对于这个句子并不一定真的成立, Candidate Relation Judgement的作用就是判断每个关系是否在该句子中成立.
Blank Filling Module
实体对抽取被作者建模为识别上下文中的Span并填入模板的空中. 作者为每个候选关系类型建立待填充的模板(缺失处用[MASK]表示), 当实体被识别时需要填入Subject和Object的对应槽位.
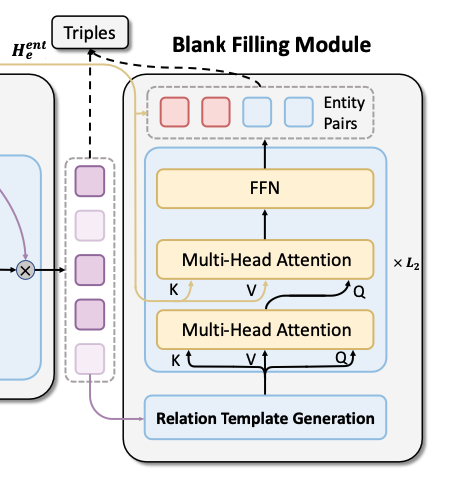
Relation Template Generation
每种关系的模板由关系的语义信息和Subject, Object槽位组成.
例如关系leaderName 对应着模板[MASK] is the leader of [MASK]. 作者认为该关系模板蕴含着关系的语义信息, 对RTE很重要, 具体模板的构成形式如下:
$$
T_{r}=\left(m_{1}^{r}, t_{1}^{r}, t_{2}^{r}, \ldots, t_{n_{t}}^{r}, m_{2}^{r}\right)
$$
其中$m_1^r$ 代表Subject的空槽, $m_2^r$ 代表Object的空槽, $t_1^r, t_2^r, \dots, t_{n_t}^r$ 为关系$r$ 的Token. 每种关系模板被复制$k$ 次, 之间用[SEP] 拼接. 其中$k$ 比句子中预设好的三元组数量稍微大一点的数, 这样能抽取出同种关系下的多个实体对.
将Relation Template复制多次和多个Query Embedding从形式上来说是一样的.
Entity Pair Extractor
对于给定的关系模板和Span表示$\bar{\mathbf{H}}=\left[\mathbf{H}_{\text{e}}^{\text{ent}} ; \mathbf{x}^{\text{e}}_{\text{cls}}\right]$, Entity Pair Extractor的作用在于抽取模板中对应的实体对. 作者同样使用和关系抽取时一样的NAD作为特征抽取器. NAD涉及到的信息流如节初图所示.
在每层Transformer Decoder Layer中, 多头自注意力建模了空槽和语义关系的关联, 多头跨注意力建立了Span信息和模板之间的关联.
经过NAD处理后, 空槽表示为$\mathbf{H}_{\text{r}}^{\text{blk}} \in \mathbb{R} ^ {2\text{k} \times \text{d}}$, Span对每种关系$r$ 下的第$i$ 个槽位的表示由下式获得:
$$
\mathbf{h}_{\mathrm{i}, \mathrm{r}}^{\mathrm{b}}=\tanh \left(\mathbf{W}_{\mathrm{b}}^{1} \bar{\mathbf{H}}+\mathbf{W}_{\mathrm{b}}^{2} \mathbf{h}_{\mathrm{i}, \mathrm{r}}^{\mathrm{blk}}+\mathbf{b}_{\mathrm{b}}\right)
$$
其中$\mathbf{W}_\text{b}^1, \mathbf{W}_\text{b}^2 \in \mathbb{R} ^{\text{d} \times \text{d}}, \mathbf{b}_{\text b} \in \mathbb{R} ^ \text b$ 为可学习参数. 对于多余出来的不需要填入实体的槽位, 答案被设置为[CLS].
最后用Softmax来获得句子中应该填入槽位的实体的概率:
$$
\mathbf{p}_{\mathrm{i}, \mathrm{r}}^{\mathrm{b}}=\operatorname{Softmax}\left(\mathbf{u}_{\mathrm{b}}^{\mathrm{T}} \cdot \mathbf{h}_{\mathrm{i}, \mathrm{r}}^{\mathrm{b}}\right)
$$
其中$\mathbf{u}_b \in \mathbb{R}^d$ 为可学习参数, 作者使用基于Span的方法抽取实体对, 所以实体可以在不使用指针网络或序列标注时被同时抽取.
其实本质仍然是指针网络, 只不过从Token Level换成了Span Level.
Joint Training
作者的模型分为关系检测和实体对抽取两个任务. 作者以多任务学习联合训练该模型, 即共享Encoder.
预测实体对时, 作者根据实体在文本中的出现的顺序排序, 然后用交叉熵计算实体对抽取的损失:
$$
\mathcal{L}_{e n t}=-\sum_{r=1}^{n_{d}} \sum_{i=1}^{2 k} \log \mathbf{p}_{\mathrm{i}, \mathrm{r}}^{\mathrm{b}}\left(\mathrm{y}_{\mathrm{i}, \mathrm{r}}^{\mathrm{b}}\right)
$$
其中$\mathrm{y}^{\mathrm{b}}_{\mathrm{i,r}}$ 为实体Span的Ground Truth, $n_d$ 为检测到的关系数.
但是对于关系就不一样了, 同样由于使用NAD, 在句子中检测出的关系是不应该具有顺序特性的, 所以使用与SPN相同的二部图匹配损失, 穷举出所有预测出的关系顺序, 找到一种与Ground Truth相匹配的最小Cost顺序$\pi^\ast$:
$$
\pi^{\ast}=\underset{\pi \in \Pi\left(\mathrm{n}_{\mathrm{q}}\right)}{\operatorname{argmin}}\left(-\sum_{\mathrm{i}=1}^{\mathrm{I}_{\mathrm{q}}} \mathrm{I}\left(\mathrm{y}_{\mathrm{i}}^{\mathrm{r}}\right) \cdot \mathbf{p}_{\pi(\mathrm{i})}^{\mathrm{r}}\left(\mathrm{y}_{\mathrm{i}}^{\mathrm{r}}\right)\right)
$$
其中$\Pi\left(\mathrm{n}_{\mathrm{q}}\right)$ 为全排列策略空间, $\mathrm{y}_\mathrm{i}^\mathrm r$ 为关系的Ground Truth, $I(y_r^i)$ 为指示函数, 若$\mathrm{y_i^r} \neq \varnothing, \mathrm{I(y_i^r)}=1$, 否则为0. 关系侧的Loss定义为最优排序下的交叉熵:
$$
\mathcal{L}_{r e l}=-\sum_{\mathrm{i}=1}^{\mathrm{n}_{\mathrm{q}}} \log \mathbf{p}_{\pi^{*}(\mathrm{i})}^{\mathrm{r}}\left(\mathrm{y}_{\mathrm{i}}^{\mathrm{r}}\right)
$$
二部图匹配损失详见SPN.
最后对两个任务的Loss做个加权:
$$
\mathcal{L}=\lambda \mathcal{L}_{e n t}+(1-\lambda) \mathcal{L}_{r e l}
$$
实验中作者将$\lambda$ 设为0.5, 即视两个任务同等重要, 且二者学习难度相同.
Experiments
详细的实验参数请参照原论文.
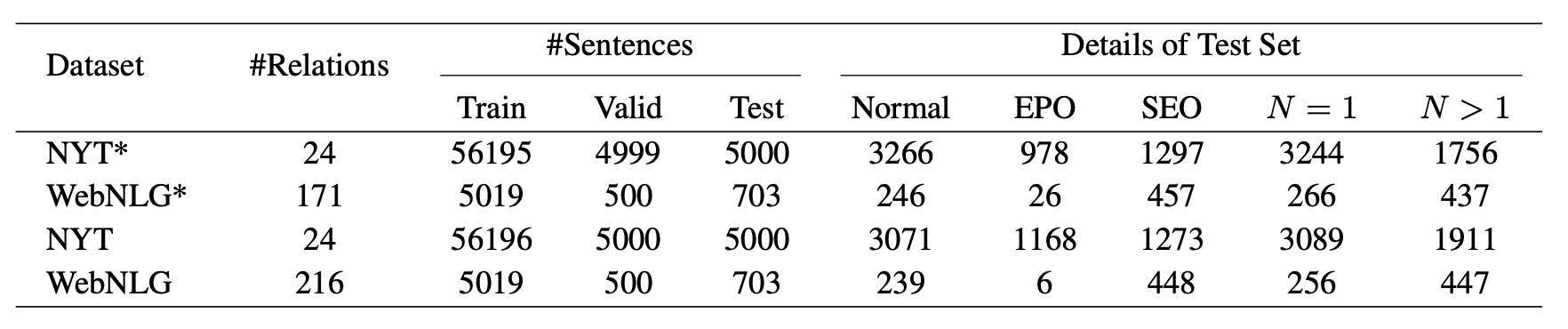
Datasets
作者选用两个常用数据集NYT和WebNLG的精准匹配和部分匹配版本做为实验数据集, 统计数据如下:
Main Results
在上述数据集上主要实验结果如下:
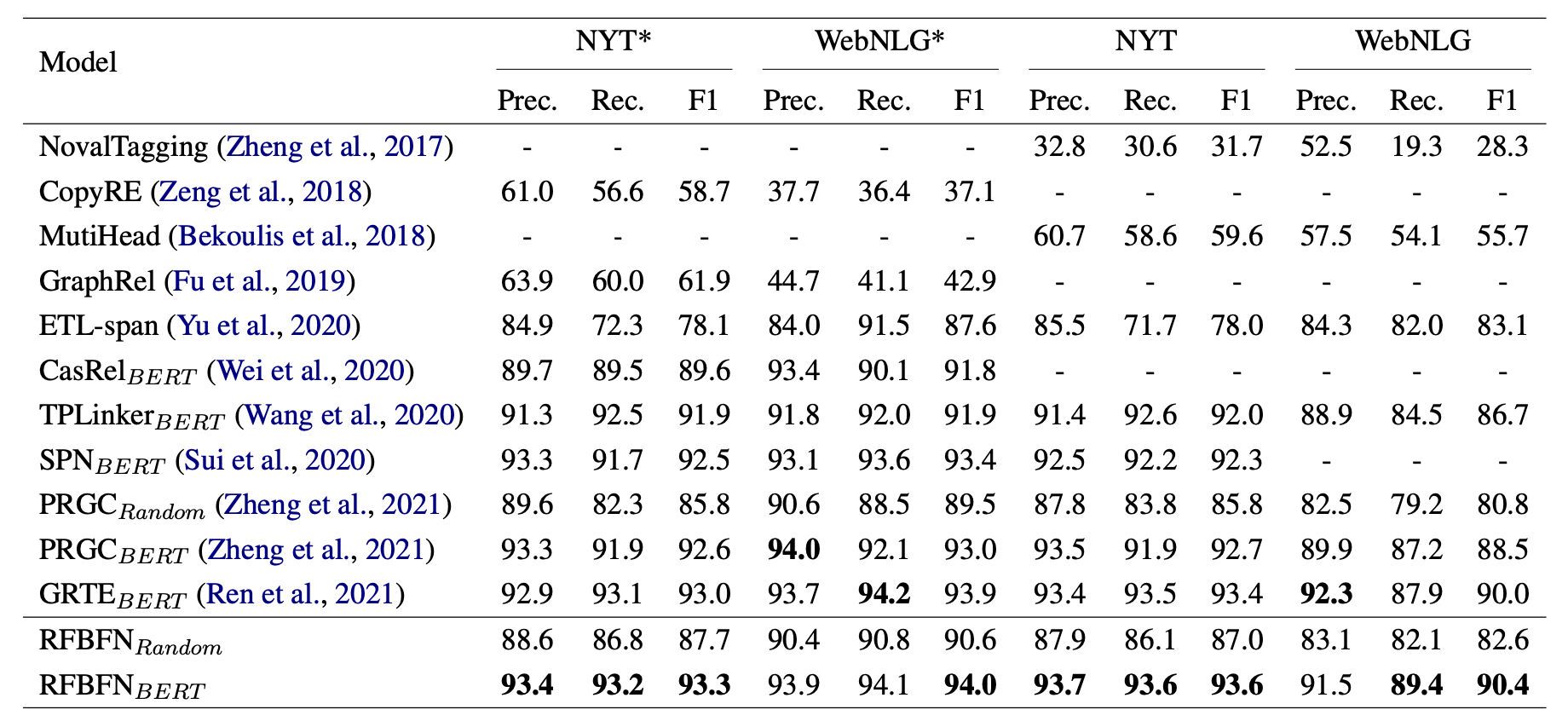
看起来RFBFN的Precision和Recall都比其他模型更要均衡一些, 所以相对应的F1也偏高一点.
在不用预训练模型的时候比PRGC结果要好, 主要的提升来自于Recall, 我认为主要原因其一是RFBFN采用了Span Level的方式而非PRGC中Token Level的方式抽取实体, 可能会有一些提升, 再者是Fill in the Blanks的方式可能更契合BERT原来的预训练任务.
Detailed Results on Complex Scenarios
在NYT, WebNLG部分匹配上按照不同类型区分的F1 Score如下:
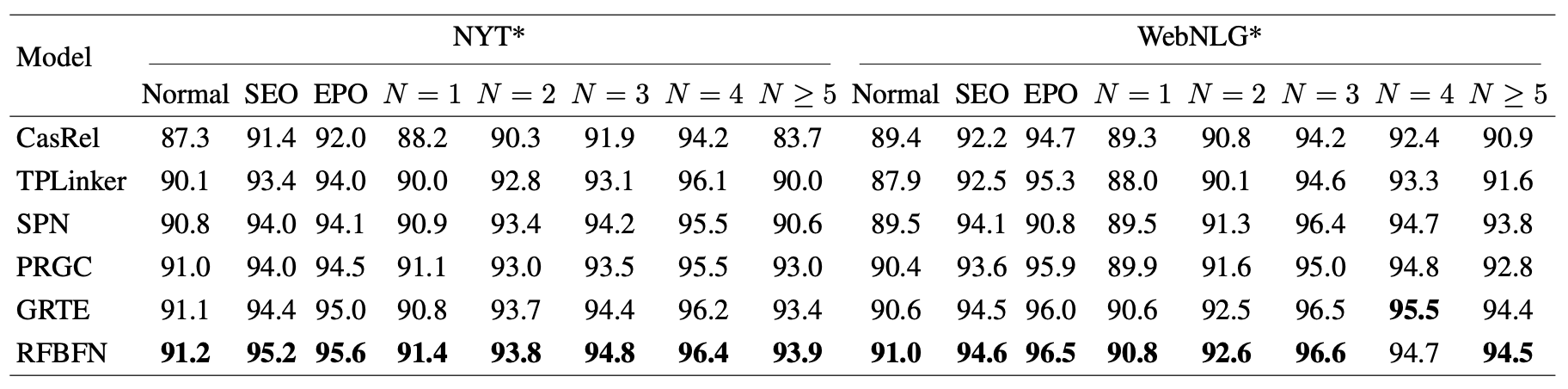
RFBFN几乎全面优于Baseline模型.
Results on Different Subtasks
在NYT, WebNLG部分匹配上各个子任务的实验结果如下:
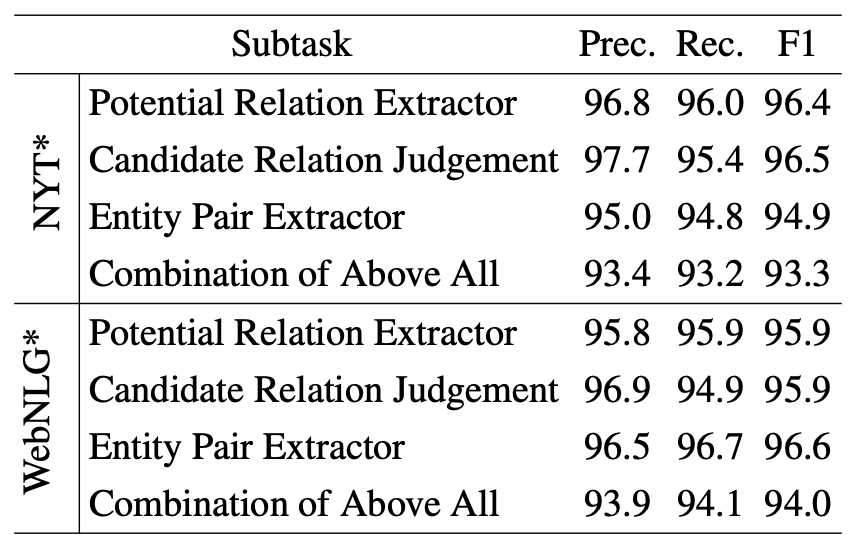
在NYT*上性能被实体识别拖了后腿, 但在WebNLG*上相反, 作者将其归因于后者的关系种类众多.
Analysis
Ablation Study
在WebNLG*消融实验结果如下:

它们分别对应着如下改动:
- - Relation Detection Module: 直接移除Relation Detection Module, 假设句子中所有关系都成立, 喂给Entity Pair Extractor. 因为WebNLG* 关系太多了, 作者只选了正样本和30%的负样本.
- - Candidate Relation Judgement: 直接移除Candidate Relation Judgement, 即忽略Relation Detection Module里面抽取出的错误关系.
- - Relation Template Generation: 把Relation Template换成Relation Embedding.
- - NA Entity Pair Extractor: 替换NAD里面的Unmasked Self Attention为causal Mask, 即按序生成Subject和Object.
- - Joint Training: 不再共享Encoder, 使用两个独立的Encoder做训练.
影响最大的是Relation Detection Module和NA Entity Pair Extractor. Entity Pair Extractor更倾向于从正确的关系模板中抽取实体, 所以喂进去负样本时表现下降很严重(体现在Precision上), 让Non - Autoregressive变成Autoregressive去生成Subject和Object也显示出了不同时抽取带来的不一致性.
关于Relation Template Generation的影响, 作者特地做了个Case Study:
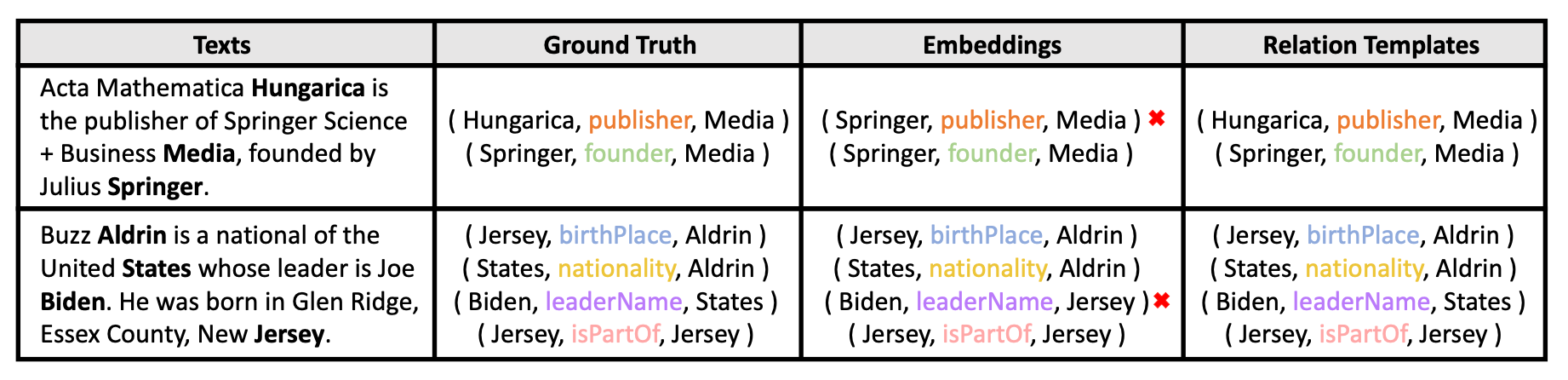
使用Relation Embedding的模型不能正确理解关系的语义信息, 相反Relation Template可以.
Visualization
假设一句子中的三元组Ground Truth为(Brom, club, Arnhem) 和 (Brom, club, Graafschap), 输入Entity Pair Extractor的关系类型为club, Entity Pair Extractor中的Attention Score Heatmap如下:
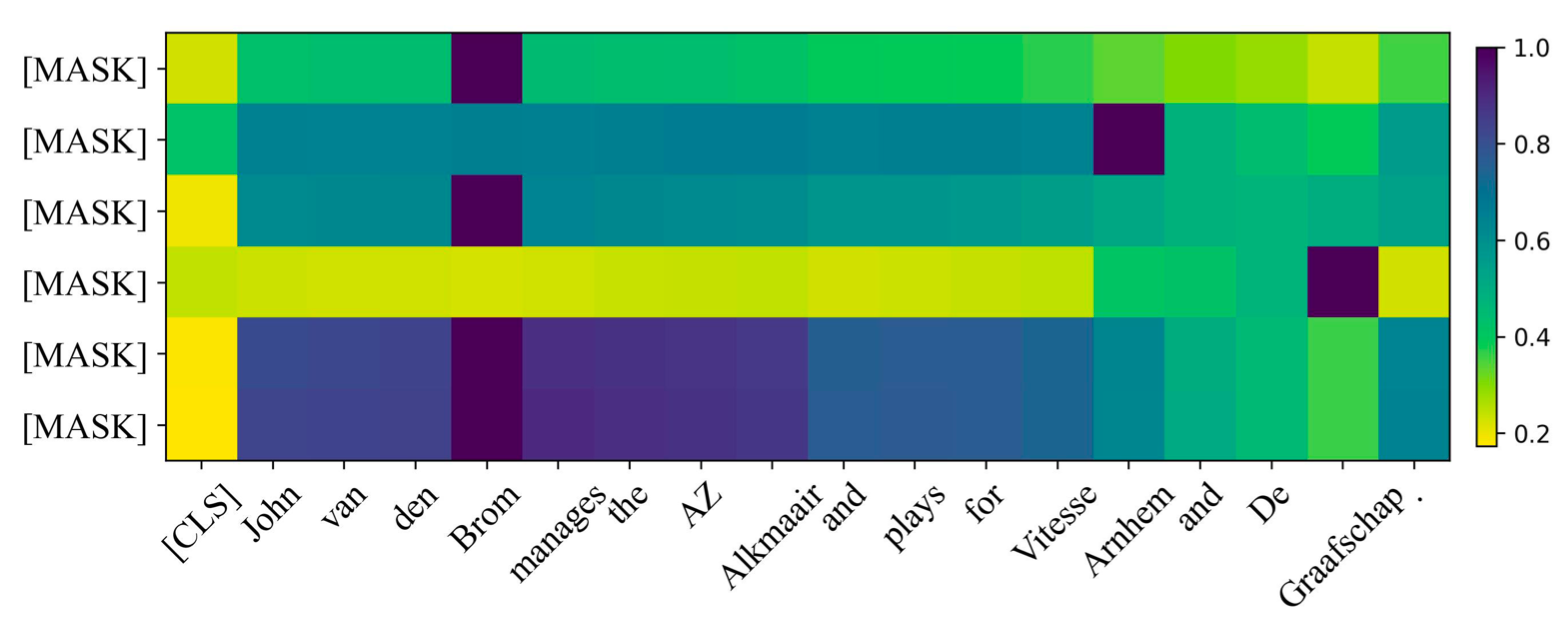
能够看到不同的槽位可以把Attention放到对应关系下的实体上.
按理说最后两个
[MASK]应该把注意力放到[CLS]上才对, 因为Label中设定多余的槽位答案为[CLS].当然也可能有一种解释,
[CLS]本身就是反映句子语义的, 所以在这里注意力分散是因为[CLS]与句子本身的语义相似, 所以对无论是Attend到[CLS]还是分散到其他地方都是合理的.
Summary
我认为RFBFN算是SPN的一种改进, 是一个类似与PRGC的Pipeline模型, 先抽取关系, 然后根据关系构造出模板, 通过完形填空的方式抽取出实体. 它将SPN里的NADecoder Layer同时应用到了关系侧和实体侧.
由于使用NAD, 多次采用穷举的方法解决每个步骤的抽取问题: 穷举Span, 穷举Relation(指Query Embedding), 穷举Entity Pair(指复制模板多次).
虽然最后取得了优越的性能, 但说实话看着工程量和计算量都挺大的, 尤其是Span的引入占大头, 算是拿时间换性能吧.

