本文前置知识:
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
- 论文: TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis, ACL 2025 Findings, Zhou Zhao组.
- 代码: GitHub - AaronZ345/TCSinger2: PyTorch Implementation of TCSinger 2(ACL 2025): Customizable Multilingual Zero-shot Singing Voice Synthesis.
- Demo: TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis | Demo page of TCSinger 2.
Basic Idea
现有的SVS模型在Zero-Shot上存在以下问题:
- 对有标注的边界信息(音素, 音符)存在过度依赖问题, 导致它们在Zero-Shot场景下缺乏鲁棒性或表现不佳.
- 现有的SVS模型缺乏通过Prompt来对多层次风格的有效控制能力.
为解决上述问题, 作者提出了TCSinger的续作TCSinger2.
TCSinger 2
Overview
TCSinger2整体框架如下:
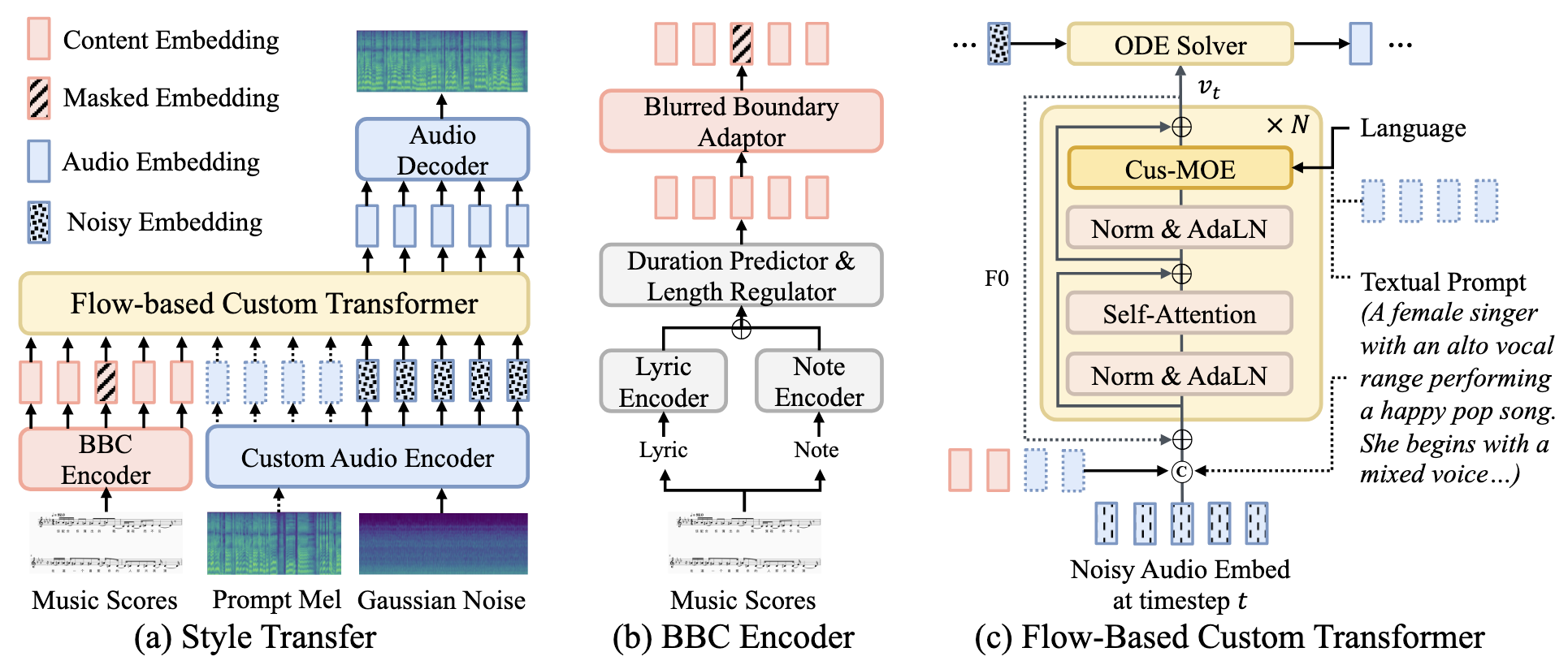
左边看架构分为几个部分:
- BBC Encoder: 引入边界模糊来克服边界标注不精确的问题.
- Custom Audio Encoder: 为了引入更多种形式的Prompt来完成多层次风格表示, 必须要有一个Aligned Encoder.
- Flow-based Custom Transformer: 增强个性化
- Audio Decoder: 完成Latent到Mel的转化.
整体流程为, BBC Encoder用Note和Lyrics预测Duration. Custom Audio Encoder编码Prompt Mel, Noise. 然后给到Flow-based Custom Transformer一起做生成. 最后用Audio Decoder把Latent解码成Mel.
BBC Encoder
BBC Encoder(Blurred Boundary Content Encoder)的功能是对边界内容进行模糊编码.
BBC Encoder的存在很大一部分原因受限于现在的SVS数据集标注不精确(包括GTSinger, M4Singer等数据集), 所以加BBC提升模型鲁棒性. 因为很多数据集是MFA + 人工校对的, 相较于其他的领域, 受限于版权等问题, 量又不可能堆的非常大. 一个模糊的表示能让模型适应这些错误.
BBC Encoder的结构如下:
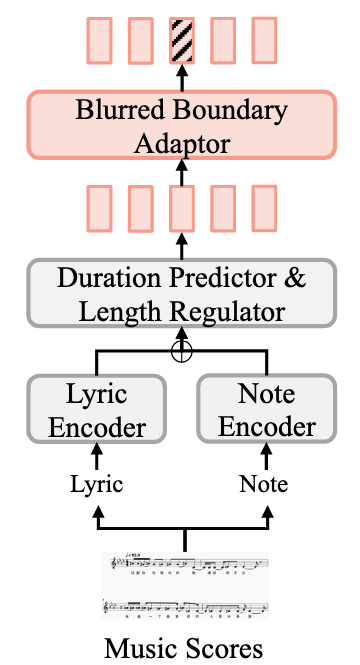
非常常见的结构, 分别对Lyric $l$ 和Note $n$ 进行编码, 然后预测Duration, 然后再做Length Regulation. 最后用一个Blurred Boundary Adapter来完成Blurring Boundary Content.
具体的, Blurred Boundary Adapter通过打Mask的方式来将边界模糊. 对于一个给定的Frame-Level Sequence $[z_{c1}, z_{c1}, z_{c1}, z_{c1}, \dots, z_{cn}, ]$ (每个Note $n$ 具有一定Duration), 在每个Phoneme和Note Boundary上随机打$m$ 个Mask, 得到$z_c = \left[z_{c 1}, \varnothing, z_{c 2}, z_{c 2}, \varnothing, \ldots, z_{c n}\right]$.
作者设置$m=8$ , 并且不对长度非常短的数据应用Content Blurring. 这样子能使监督信号, 鲁棒性, 压缩率, 采样率几个因素达到权衡.
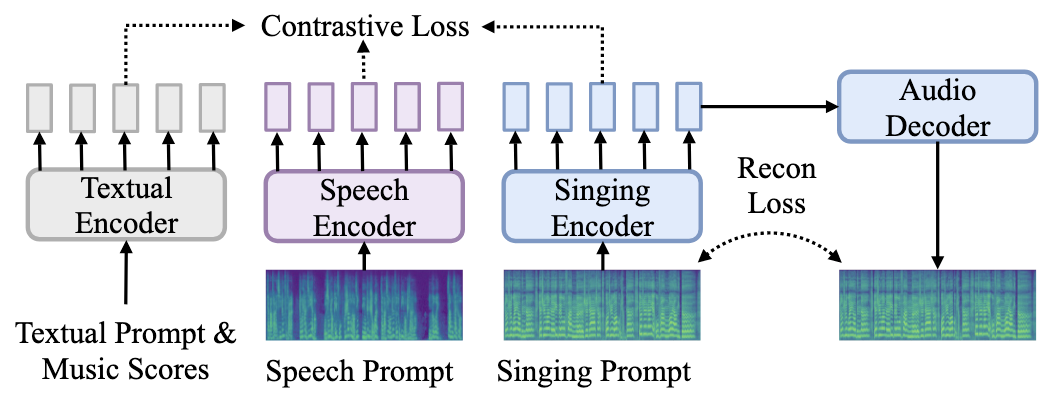
Custom Audio Encoder
Custom Audio Encoder完成了Singing, Speech, Text三者的表示对齐, 这样TCSinger2就能执行多样化Prompt支持下的各类工作.
基于Singing Prompt $p_{si}$, Speech Prompt $p_{sp}$, 含有Content $C$ 的Textual Prompt $p_{te}$, 可以构成一个三元组$(z_{psi}, z_{psp}, z_{ptc})$. 对齐它们三者, 定义Contrastive Loss:
$$
\mathcal{L}_{p_{s i}^i, p_{s p}^i}=\log \frac{\exp \left(\operatorname{sim}\left(z_{s i}{ }^i, z_{s p}{ }^i\right) / \tau\right)}{\sum_{j=1}^N \exp \left(\operatorname{sim}\left(z_{s i}{ }^i, z_{s p}{ }^j\right) / \tau\right)}
+\log \frac{\exp \left(\operatorname{sim}\left(z_{s p}{ }^i, z_{s i}{ }^i\right) / \tau\right)}{\sum_{j=1}^N \exp \left(\operatorname{sim}\left(z_{s p}{ }^i, z_{s i}{ }^j\right) / \tau\right)}
$$
$\text{sim}(\cdot)$ 为余弦相似度.
当然, 光对歌声和语音的$p_{si}$ 和$p_{sp}$ 做Contrastive Loss肯定是不够的. 还要分别让歌声和语音与文本端的对齐, 即$p^i_{sp}$ 与$p^i_{te}$, $p^i_{si}$ 与$p^i_{te}$ 的对齐. 所以总的Loss为:
$$
L_{contras}=-\frac{1}{6N}\sum\limits_{i=1}^N(\mathcal{L}_{p_{si}, p_{sp}} + \mathcal{L}_{p^i_{sp}, p^i_{te}} + \mathcal{L}_{p^i_{si}, p^i_{te}})
$$
此外, 为了保证$z_{psi}$ 具有对歌声建模的完整性, 还需要对$z_{psi}$ 进行重构. 所以还需要重构损失 $L_{rec}$.
Audio Decoder用L2 Loss $\mathcal{L}_{\text{recon}}$和LSGAN-style的Discriminator Loss $\mathcal{L}_{\text{adv}}$ 进行训练.
上述过程如下图所示:
Flow-based Custom Transformer
歌唱是一个高度复杂且风格多变的技能, 建模起来具有难度. 作者将Custom-MOE和
FM(Flow Matching)结合到一起, 提出Flow-based Custom Transformer, 整体结构如下:
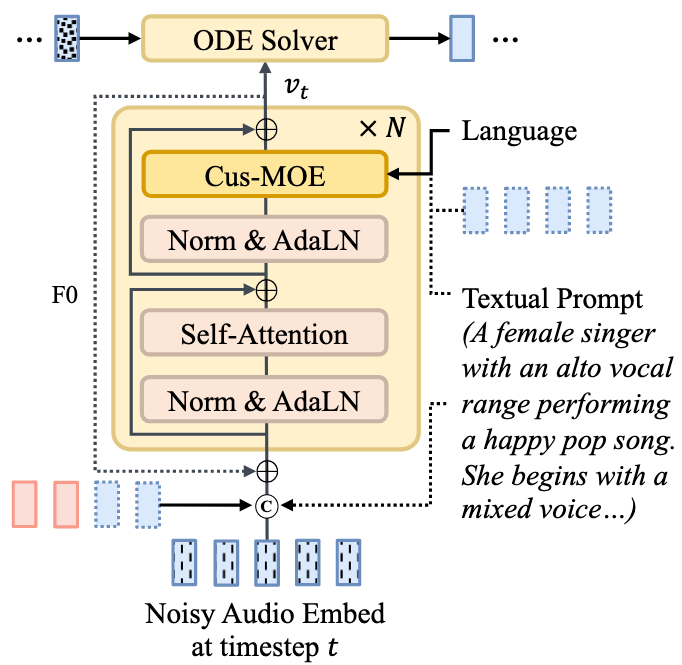
流程上来看, 就是FM的整体框架, 但是把FFN换成了Cus-MOE. Text Prompt从Cus-MOE和Noisy Audio Embedding两端注入.
Norm采用了RMSNorm和DiT里的AdaLN. Frame-Level Feature用了RoPE.
Flow-based Transformer
训练期间, 将高斯噪声$\epsilon$ 与Audio Encoder的输出$\hat{m_{gt}}$ 线性组合来获得$t$ 时刻的表示$x_t$. 然后将BBC Encoder获得的Content Embedding和$x_t$ 拼接, 送入Flow-based Transformer解码.
与现在的主流LDM(Flux, Stable Diffusion3)等一样, FM是在Latent里面做的.
可选的, 如果有从Custom Audio Encoder中获得的Audio Prompt Embedding $z_{pa}$, $z_{psi}$, $z_{psp}$ 都可以一起拼接.
当在用Text Prompt控制风格的时候, 应该将Text Prompt编码为$z_{pt}$, 代替$z_{pa}$ 完成拼接后序的解码.
对于每个时间步$t$, 用FM目标来训练Flow-based Transformer:
$$
\mathcal{L}_{\text {flow }}=\mathbb{E}_{t, p_t\left(x_t\right)}\left||v_t\left(x_t, t \mid C ; \theta\right)-\left(\hat{m_{g t}}-\epsilon\right)\right||^2
$$
$p_t(x_t)$ 代表$t$ 时刻$x_t$ 的分布. 另外, 根据StyleSinger的结论, 作者使用第一个Block的输出来预测F0.
Cus-MOE
Cus-MOE的比较简单:
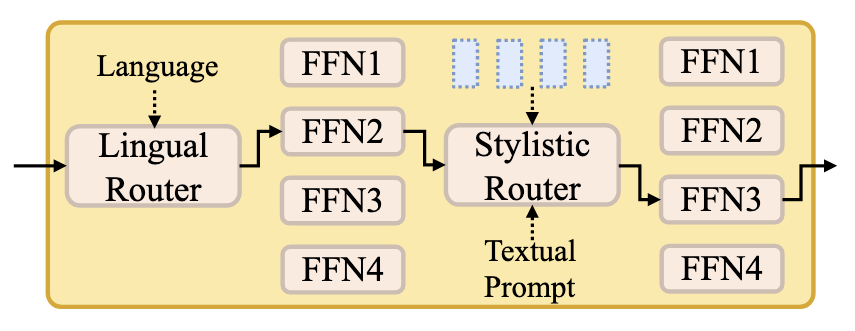
Cus-MOE有两个Expert Groups, 即Lingual-MOE与Stylistic-MOE:
- Lingual-MOE: 根据歌词的语言来选择语言专家, 每个专家负责不同的语系.
- Stylistic-MOE: 根据Audio Prompt或者Textual Prompt的条件, 选择细粒度不同风格的咋婚假, 每个专家负责的唱法不同.
路由策略采用dense-to-sparse Gumbel-Softmax. 令$h$ 为hidden states, $g(h)_i$ 为专家$i$ 的Routing Score. 为防止负载不均, 采用Load-Balancing Loss:
$$
\mathcal{L}_{\text {balance }}=\alpha N \sum_{i=1}^N\left(\frac{1}{B} \sum_{h \in B} g(h)_i\right)
$$
$B$ 为Batch Size, $N$ 为专家数量, $\alpha$ 控制正则化强度.
Training and Inference Procedures
Training Procedures
预训练期间, Custom Audio Encoder / Decoder的Loss如下:
- Contrastive Loss $L_{contras}$.
- 重建L2损失 $L_{rec}$.
- LS-GAN-styled的Discriminator Loss $L_{adv}$.
TCSinger2的最终训练损失主要分为以下几项:
- $L_{dur}$: BBC Encoder里对数尺度的Phoneme-Level MSE.
- $L_{pitch}$: 对数尺度的音高MSE.
- $L_{balance}$: Cus-MOE中每个专家的负载.
- $L_{flow}$: Flow-based Transformer的FM Loss.
Inference Procedures
TCSinger2在不同的Prompt下会执行不同的任务:
- 对于没见过的Singing Prompt, 无论是跨语言还是同语言, 都可以执行Zero-Shot Style Transfer.
- 对于不同语言的歌词和Singing Prompt, 执行的是Cross-Lingual Style Transfer.
- 如果给定自然语言形式的Textual Prompt, 可以执行Multi-Level Style Control.
- 如果给定Speech Prompt, 可以执行Speech-to-Singing(STS) Style Transfer.
训练时候采用CFG, 以0.2的概率直接丢弃输入的Prompt. 推理时, 将输出的向量场改为:
$$
v_{c f g}(x, t \mid C, P ; \theta)=\gamma v_t(x, t \mid C, P ; \theta)+(1-\gamma) v_t(x, \mid C, \varnothing ; \theta)
$$
$\gamma$ 为平衡创造性和可控性的CFG Scale Factor, 作者设为3.
Experiments
详细的实验设置和超参设置请参考原论文. 作者使用8卡4090训练, Vocoder为预训练HiFi-GAN.
Datasets
数据集和TCSinger的一代大差不差, 不同在于多引入了Opencpop和一部分扩充数据:
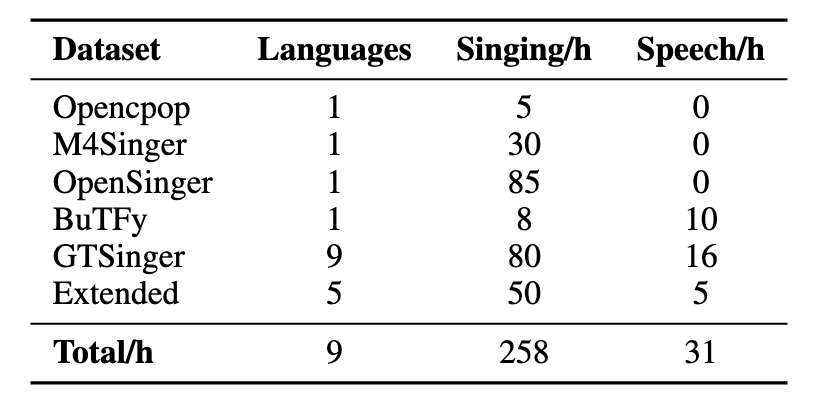
对于缺乏风格标签的数据, 还聘请了有音乐背景的专家进行指导完成手动标注. 并将这部分标签用GPT-4o生成Textual Prompt.
Main Results
Style Transfer
Cross Lingual Style Transfer效果如下:
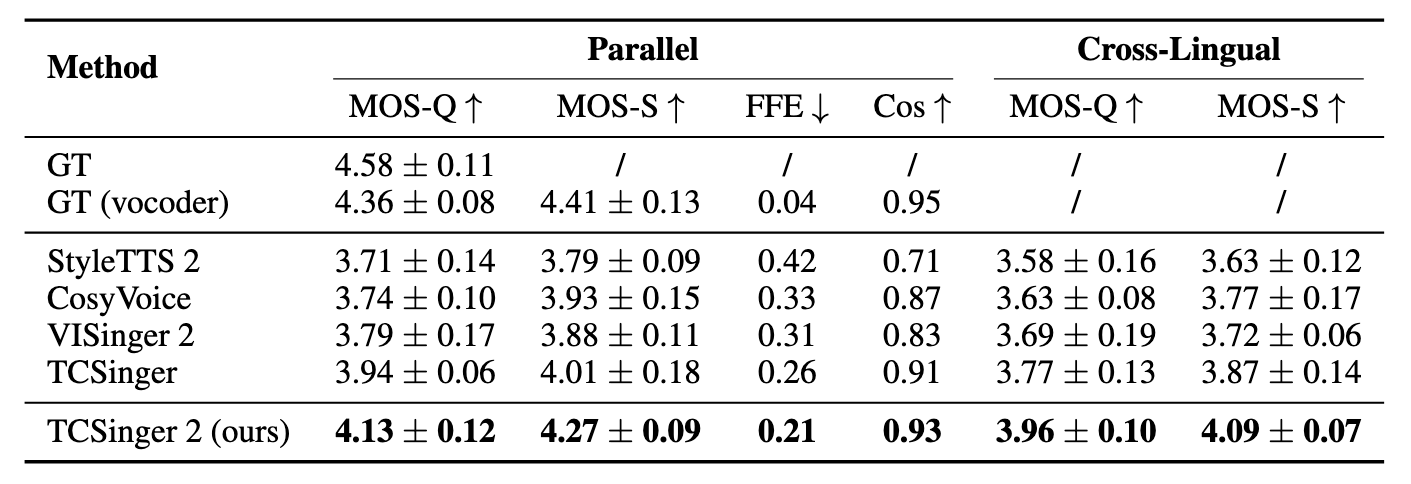
TC2效果还是明显要好过其他Baseline的. 在平行语料的FFE上有了比较大的改进, 说明F0比以前要准确.
Style Control
作者在其他模型里加了Cross-Attention来处理Textual Prompt. 实验结果如下:
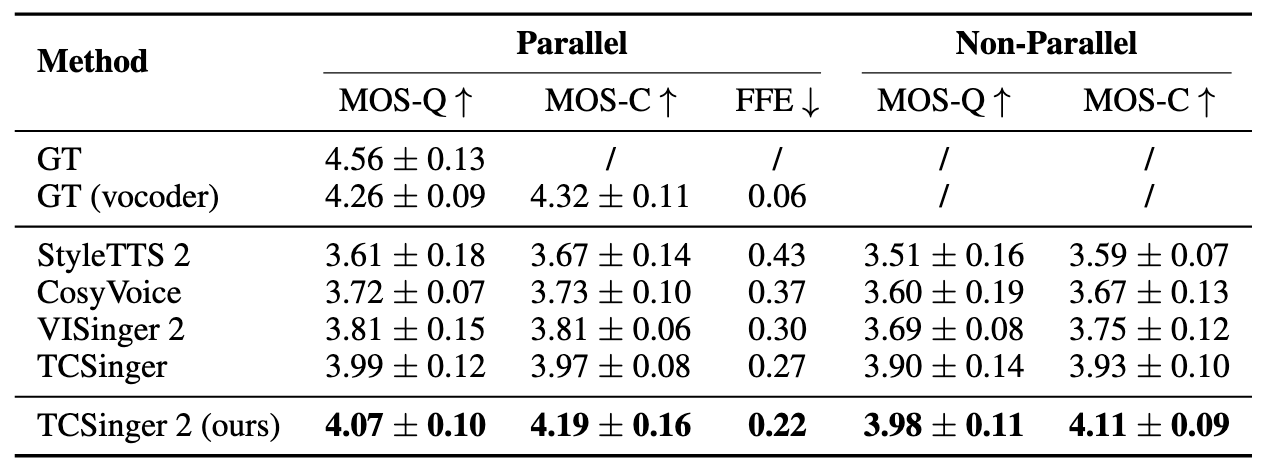
平行语料的MOS-Q已经快接近Vocoder的GT了.
作者也对不同的唱法做了可视化:

TC2能针对不同的风格有效控制.
Speech-to-Singing
Zero-shot的STS表现如下:
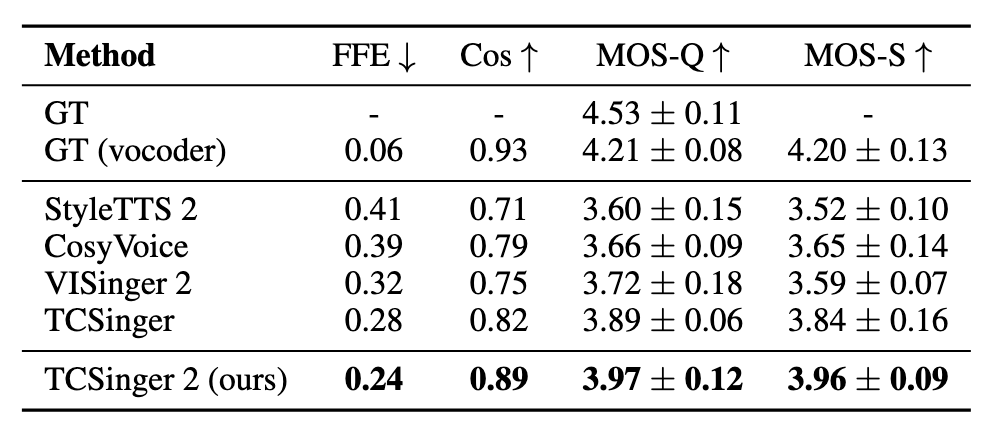
看起来TC2比TC要强很多.
STS这个任务其实是能否完成客制化的关键. 因此看下游应用能不能有效就要看Zero-Shot STS的表现.
Ablation Study
Style Transfer和Style Control上的消融实验如下, CAE代表Custom Audio Encoder:
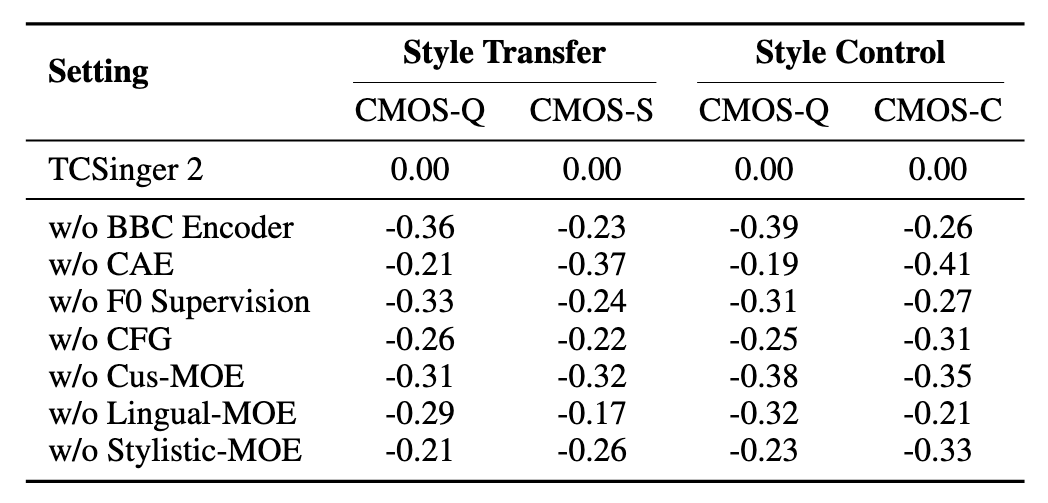
- BBC Encoder发挥了比较大的作用, 直接移去差异很明显, 能有效缓解边界标注质量差的问题.
- Custom Audio Encoder的Align去掉掉点也比较明显, 但相较于其他模块, 对CMOS-Q影响似乎不够大. 说明各类Prompt的对齐对歌手的相似度和控制影响要大一些.
- Cus-MOE去掉的话掉点也挺多的, 尤其是Style Control, 在目前规模的数据下, Cus-MOE对Style Transfer和Style Control还是挺有帮助的.
Summary
虽然是TCSinger的续作, 但实际上路线和之前完全不一样了. 只能说它们做的都是多语言, 可控的Zero-Shot SVS吧. 整体思路用Latent Flow做生成.
感觉缝的内容也比较多, 从这上面来看明显在相对小规模的数据约束下, Zero-Shot SVS做起来比较困难. 由于版权, 成本等原因限制, SVS这个领域严重缺乏数据, 直接大大大的思路很可惜不能直接套过来.

