HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
本文是论文HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis 的阅读笔记和个人理解. 论文来自NeurIPS 2020.
其实如果只看结构, 比较推荐直接阅读作者提供的源码.
HiFi - GAN
Support by DeepSeek.
HiFi - GAN是一种声码器(Vocoder), 而Vocoder是一种用于将声学特征(梅尔频谱, 线性频谱等)转换为语音波形的技术或模型. 它是语音合成系统中的关键组件, 负责将高层次的声学特征映射为具体的语音信号.
从HiFi - GAN的结构角度来说, HiFi - GAN由一个Generator, 两个Discriminator组成.
Generator
宏观上, Generator $G$ 是一个全卷积网络, 以梅尔谱作为输入, 并以声波作为输出.
它会被由反卷积和MRF构成的结构上采样$|k_u|$ 次(也就是$|k_u|$ 个子块), 以匹配声波的原始分辨率:
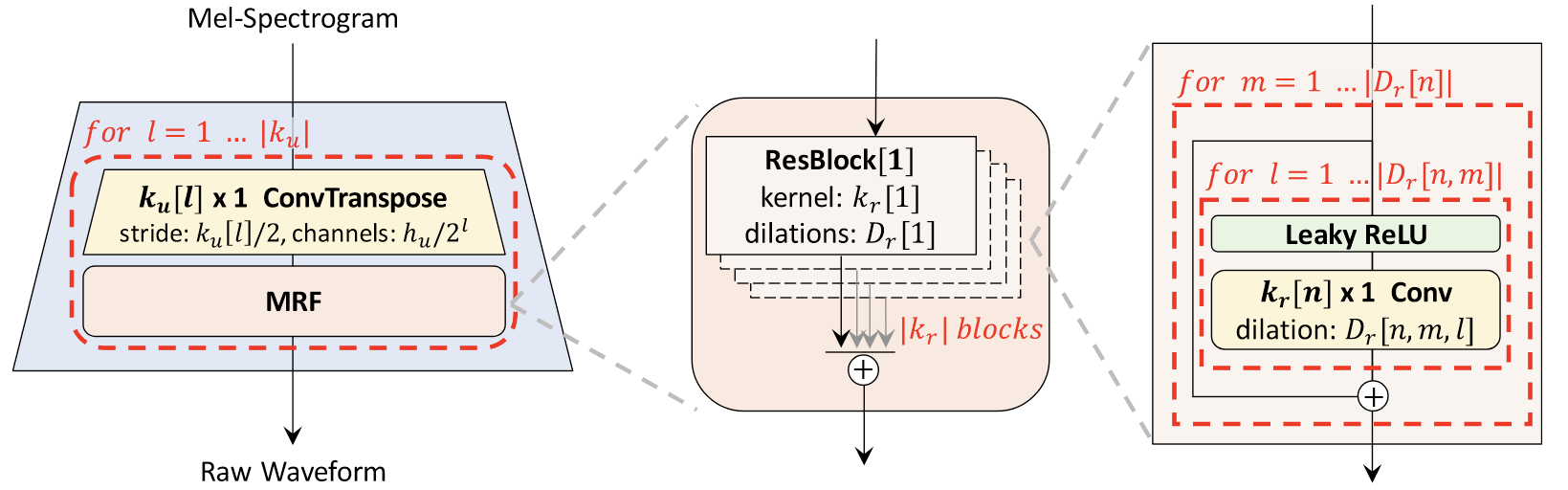
其中的Multi - Receptive Field Fusion(MRF)由$|k_r|$ 个连续的ResBlock组成. 第$n$ 个ResBlock中是由LeakyReLU和不同膨胀率$D_r[n]$ 和不同卷积核大小$k_r[n]$ 的CNN组成的.
MRF的若干个连续ResBlock会将抽取到的特征全部相加, 得到下一次上采样之前的特征.
在论文作者公开的代码中有两种ResBlock实现, 一种是将Dilation Rate为
[1, 3, 5]和普通卷积交替使用, 参数相对多. 另外一种只有Dilation Rate仅有[1, 3]的卷积交替.
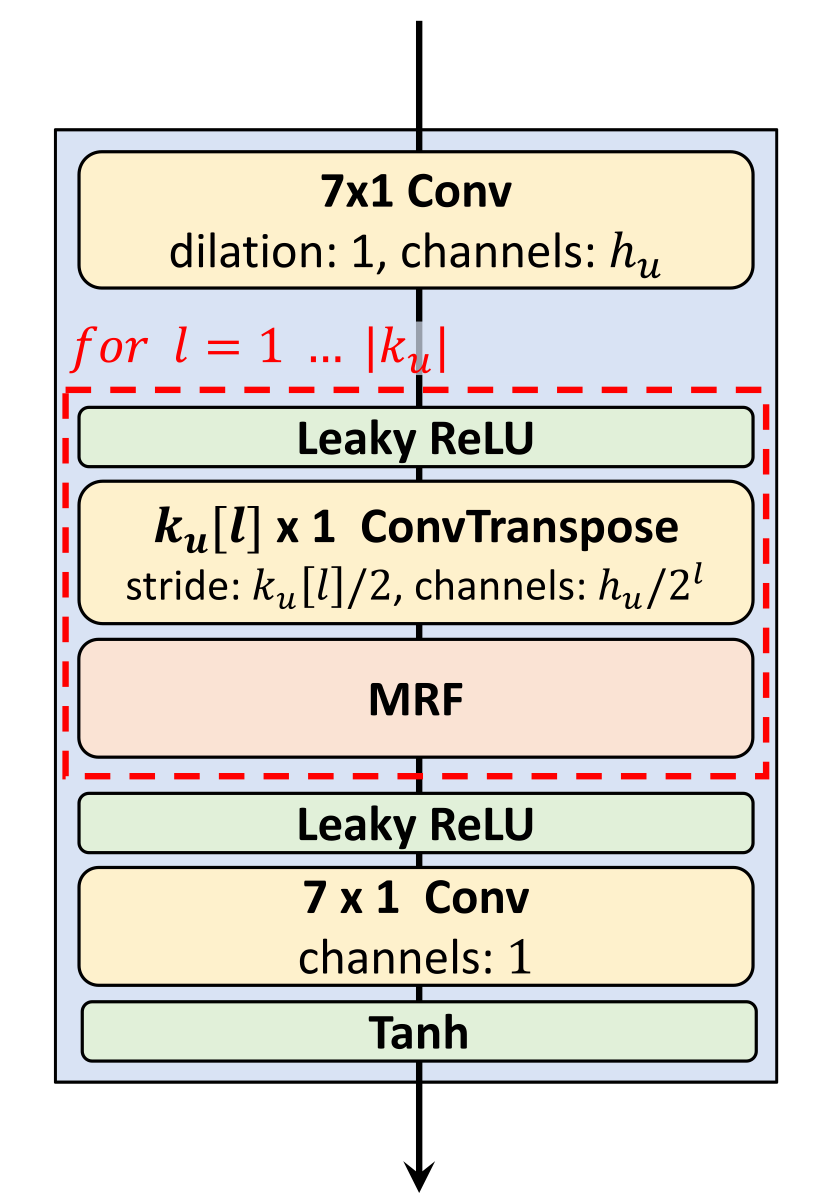
事实上, 作者在梅尔谱表示进入MRF前, 使用一个Conv1d 完成梅尔谱的编码, 并在MRF堆叠之后, 使用一个LeakyReLU, 一个Conv1d, 并以最终Tanh 的激活值作为输出:
Discriminator
Multi - Period Discriminator
为了使得Discriminator也编码原始波形的长距离依赖, 作者设计了Multi - Period Discriminator(MPD), 对不同距离下的波形做判别, 这似乎是在GAN based Vocoder中的首次提出的.
将总时长为$T$ 的一维原始波形沿时间取间隔$p$, 将原始波形Reshape成宽为$p$, 高为$\frac{T}{p}$ 的二维数据.
然后用大小为$p \times 1$ 的二维卷积核, 独立的处理每个Period中的同一个位置的波形数据. 若如此做, 每个$p \times 1$ 的卷积核会处理从波形中以周期$p$ 均匀采样到的波形数据.
这里提到的二维卷积核, 虽然名义上实现采用的是Conv2d, 但实际上它也可以用Conv1d来实现, 这个二维卷积核仍然是$p \times 1$ 的大小, 每次单独处理的仍然是一个一维数据序列.
下图是一个$p=3$ 的示意图:
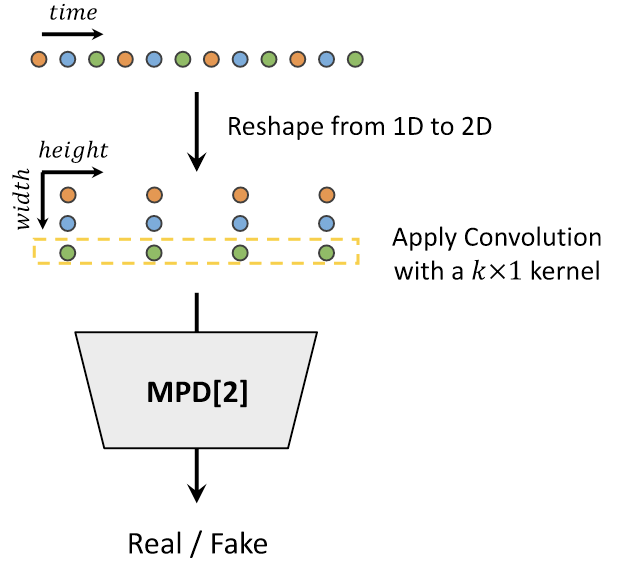
为了体现”Multi Period”, 作者设置了若干个”Sub discriminator”, 分别设置 [2, 3, 5, 7, 11] 的$p$.
每个”Sub discriminator” 内部由5个$5 \times 1$ 的Conv2d和Leaky ReLU堆叠构成:
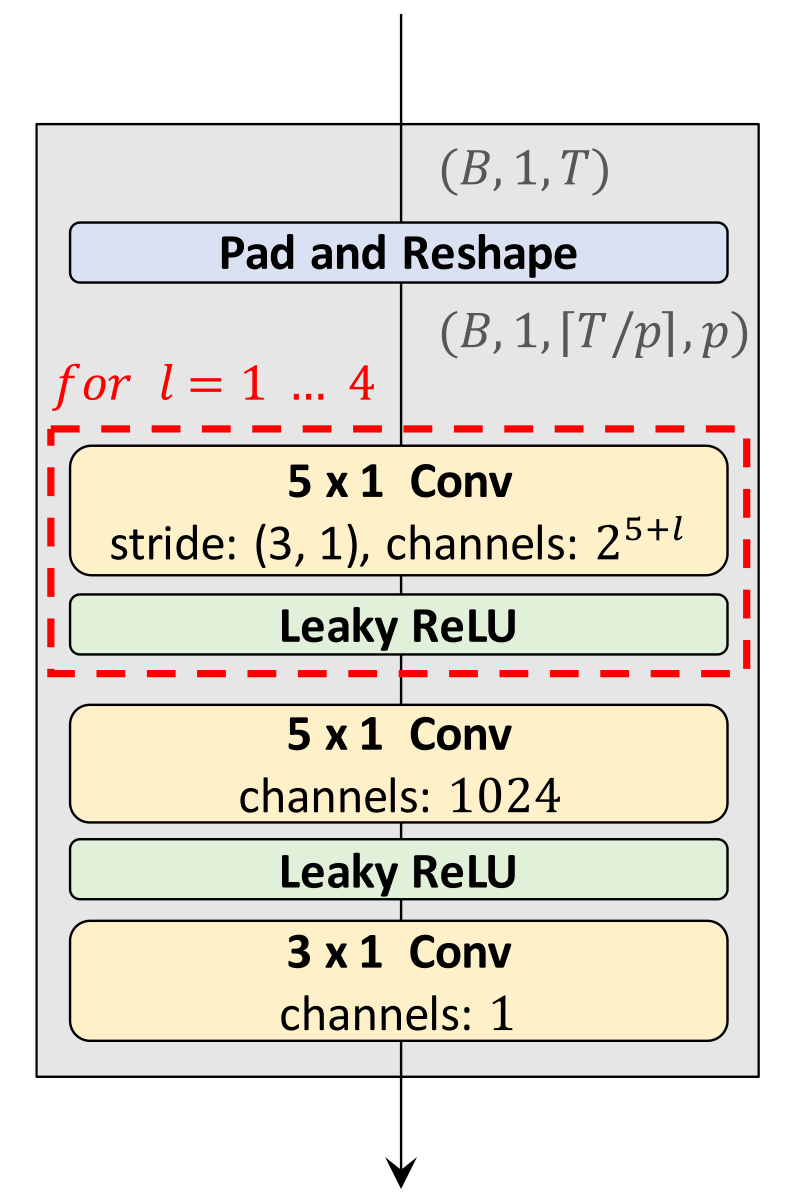
堆叠后由一个$5 \times 1$ 的Conv2d完成后处理, 最后将二维展平为一维.
Multi - Scale Discriminator
这个结构在MelGAN中使用过.
与MPD类似的, Multi - Scale Discriminator(MSD) 由三种不同尺度的”Sub discriminator”组成, 它们分别对三种不同尺度下的音频声波做判别: 1x(原尺寸), 2x平均池化, 4x平均池化.
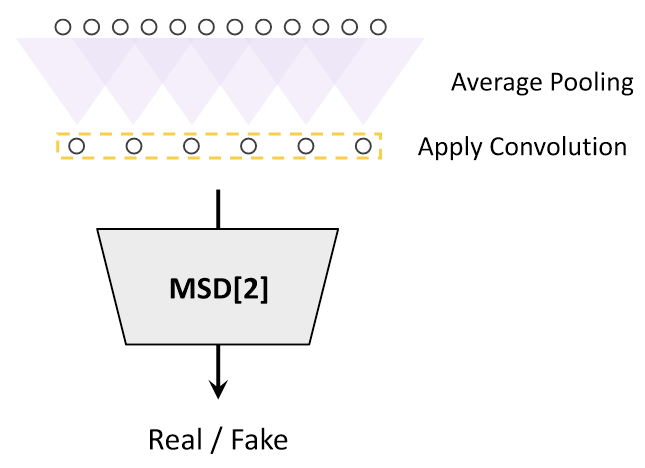
每个”Sub discriminator” 内部由若干个分组卷积堆叠而成.
Normalization
除了MSD中的第一个Sub Discriminator(在原始波形尺度上的判别器)被应用了Spectral Normalization外, 几乎在HiFi - GAN中所有的参数都被施加了Weight Norm用于加速训练.
Weight Norm是一种解耦向量大小和方向的重参数方法, 它将每个参数拆解为方向向量$\mathbf{v}$ 和幅度向量$g$, 用于加速训练:
$$
\mathbf{w} = g \dfrac{\mathbf{v}}{\Vert\mathbf{v}\Vert}
$$
Training Loss Terms
GAN Loss
首先是GAN的Adversarial Loss:
$$
\begin{aligned}
& \mathcal{L}_{\text {Adv }}(D ; G)=\mathbb{E}_{(x, s)}\left[(D(x)-1)^2+(D(G(s)))^2\right] \\
& \mathcal{L}_{\text {Adv }}(G ; D)=\mathbb{E}_s\left[(D(G(s))-1)^2\right]
\end{aligned}
$$
$x$ 为音频的原始波形, $s$ 为输入条件, 在这里是梅尔谱.
Mel - Spectrogram Loss
梅尔谱Loss就是一个Reconstruction Loss:
$$
\mathcal{L}_{M e l}(G)=\mathbb{E}_{(x, s)}\left[\Vert\phi(x)-\phi(G(s))\Vert_1\right]
$$
其中, $\phi$ 为将梅尔谱转换为波形的函数(这个过程本身就是可微的).
Feature Matching Loss
与MelGAN相同, 为了使得波形$x$ 与Generator$G$ 生成的波形$G(s)$ 进一步相似, 作者在这里还添加了一个Discriminator $D$ 对$x$ 捕获的特征$D(x)$ 与$D$ 对$G(s)$ 捕获的特征$D(G(s))$ 之间的特征匹配Loss:
$$
\mathcal{L}_{F M}(G ; D)=\mathbb{E}_{(x, s)}\left[\sum_{i=1}^T \frac{1}{N_i}\left\Vert D^i(x)-D^i(G(s))\right\Vert_1\right]
$$
$T$ 为Discriminator的层数, $D^i, N_i$ 分别为Discriminator的第$i$ 层的特征和特征数.
Final Loss
最终GAN的Loss为:
$$
\begin{aligned}
& \mathcal{L}_G=\mathcal{L}_{\text {Adv }}(G ; D)+\lambda_{f m} \mathcal{L}_{F M}(G ; D)+\lambda_{\text {mel }} \mathcal{L}_{M e l}(G) \\
& \mathcal{L}_D=\mathcal{L}_{A d v}(D ; G)
\end{aligned}
$$
作者设定$\lambda_{fm}=2, \lambda_{mel}=45$.
由于每个MPD和MSD有多个Sub discriminator, 所以在计算与Discriminator相关的每一项Loss时, 实际上是取每个Sub discriminator的输出结果计算得到的Loss求和最后取平均得到的. 上述Loss的形式化描述为:
$$
\begin{aligned}
& \mathcal{L}_G=\sum_{k=1}^K\left[\mathcal{L}_{\text {Adv }}\left(G ; D_k\right)+\lambda_{f m} \mathcal{L}_{F M}\left(G ; D_k\right)\right]+\lambda_{\text {mel }} \mathcal{L}_{M e l}(G) \\
& \mathcal{L}_D=\sum_{k=1}^K \mathcal{L}_{A d v}\left(D_k ; G\right)
\end{aligned}
$$
其中$D_k$ 代表第$k$ 个MPD或MSD的Sub discriminator.
Experiments
详细的模型参数设置和实验设置请参考原论文.
实验数据集有两个:
- LJSpeech: 由13100条单Speaker的短时长朗读 7 本纪实类英语书籍的录音组成的数据集, 共计将近24小时, 采样率为22kHz.
- VCTK multi - speaker: 由44200条109位不同口音的Native English Speaker构成的数据集, 将近44小时, 采样率为44kHz, 作者将其降为22kHz.
此外, 还设计了三种不同参数规格的HiFi - GAN V1, V2, V3:
- V1参数量最多, 属于常规设置.
- V2是比V1的Hidden Size小很多的版本, 但具有和V1相同大小的感受野, 进需要0.92M参数.
- V3相比于V1具有更少的层数但维持住了感受野大小.
MOS Score
Support by DeepSeek.
MOS Score(Mean Opinion Score, 平均意见分数) 是一种用于评估合成语音质量的主观评价指标. 它通过人类听众对语音的自然度, 清晰度, 流畅度等方面进行打分, 从而反映合成语音的整体质量. 通常采用1到5分的评分标准:
- 1分: 质量极差, 完全无法理解.
- 2分: 质量差, 理解困难.
- 3分: 质量一般, 可以理解但不够自然.
- 4分: 质量良好, 接近自然语音.
- 5分: 质量优秀, 与自然语音几乎无差别.
对于所有音频质量的主观评估, 采用MOS作为评估指标. 作者是在Amazon Mechanical Turk上对结果进行的众包测试.
Audio Quality and Synthesis Speed
作者进行了LJSpeech上反演频谱的MOS Test, 结果如下:
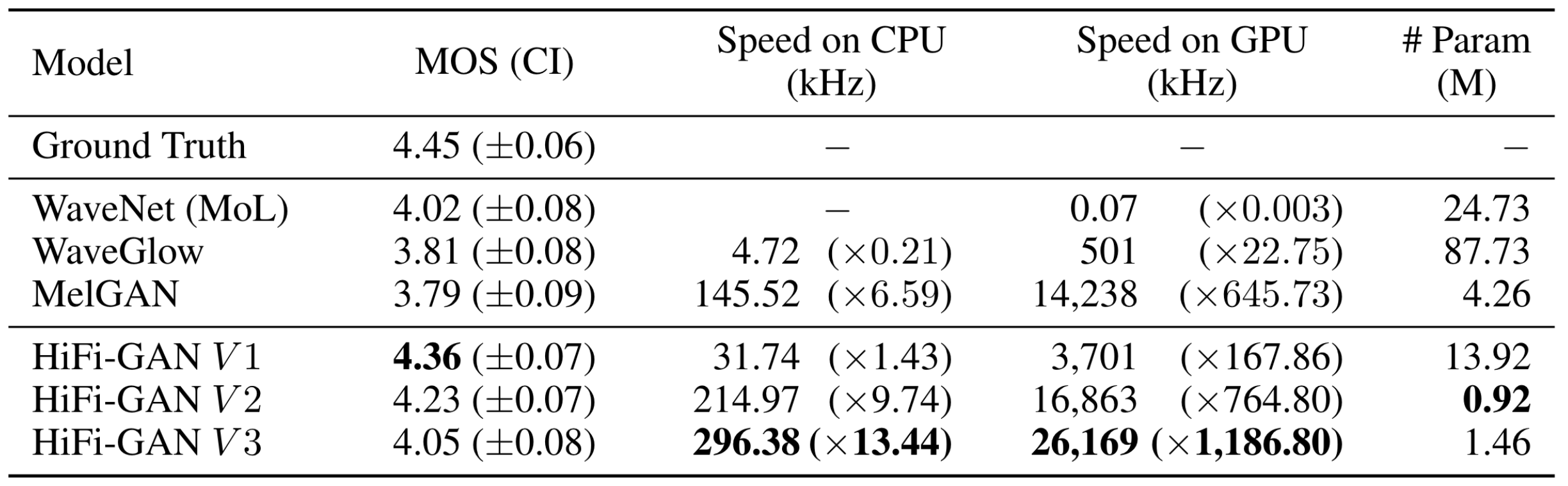
HiFi - GAN在参数量, 推理速度占优势的情况下能达到更好的性能, 而且在参数量相对少得多的设置下仍然能取得比先前方法更好或相近的表现, 尤其是在GPU推理加速的情况下速度非常快, 能满足Vocoder的实时推理需求. 这都体现出HiFi - GAN作为Vocoder的潜力.
此外, 能够观察到, GAN based Method在参数量和推理速度上都有优势.
Ablation Study
下面作者在LJSpeech上进行了消融实验:
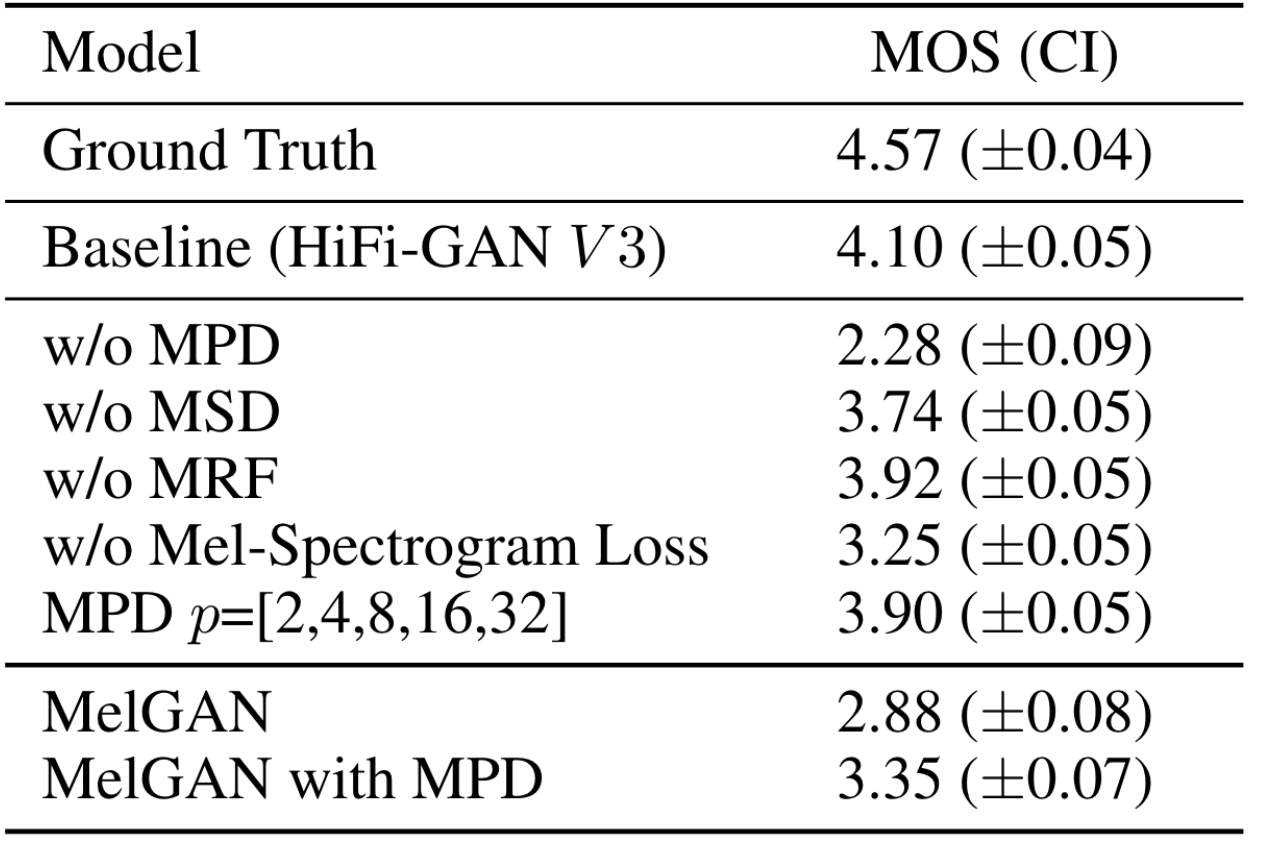
在去掉MPD后, HiFi - GAN的性能有显著的下降, 同时在给MelGAN加上MPD后, MelGAN的性能有了显著的提升, 这证明了MPD的建模有效性, 也说明了在Vocoder中的长距离依赖建模是比较重要的. 此外, 梅尔谱Loss也会有比较大的影响.
Generalization to Unseen Speakers
为了验证HiFi - GAN的泛化能力, 作者将HiFi - GAN直接在Unseen Speaker Dataset(VCTK multi - speaker)上进行推理, 结果如下:
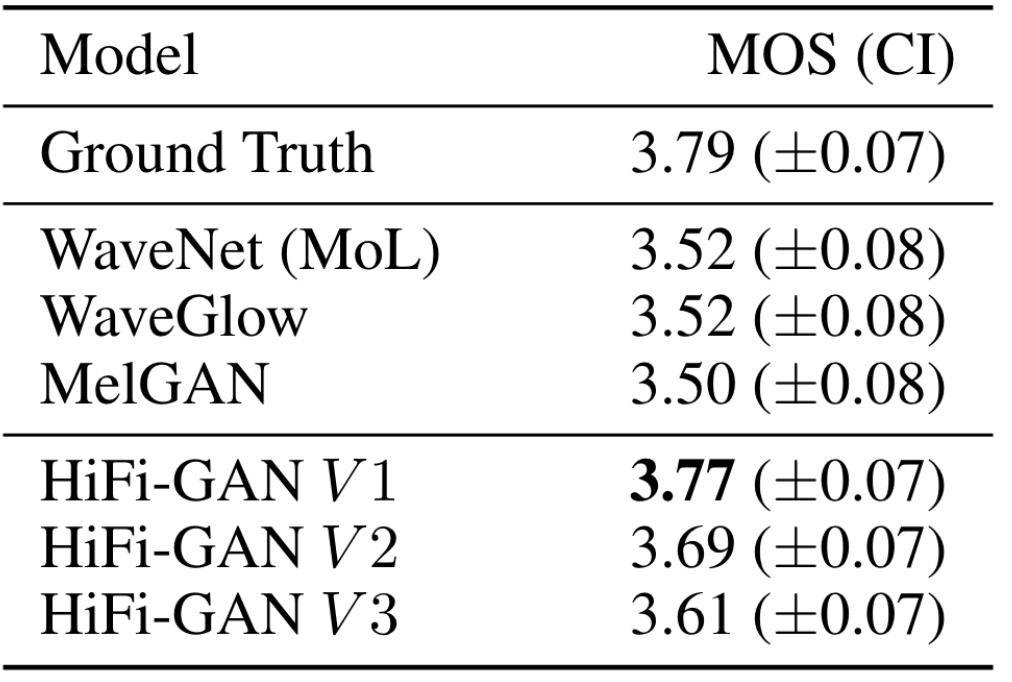
HiFi - GAN的表现甚至快接近于Ground Truth.
End-to-End Speech Synthesis
最后作者直接把HiFi - GAN放到TTS任务上, 用Tacotron2完成文本到梅尔谱的生成, 然后直接用Vocoder解码, 做了微调和不微调两种:
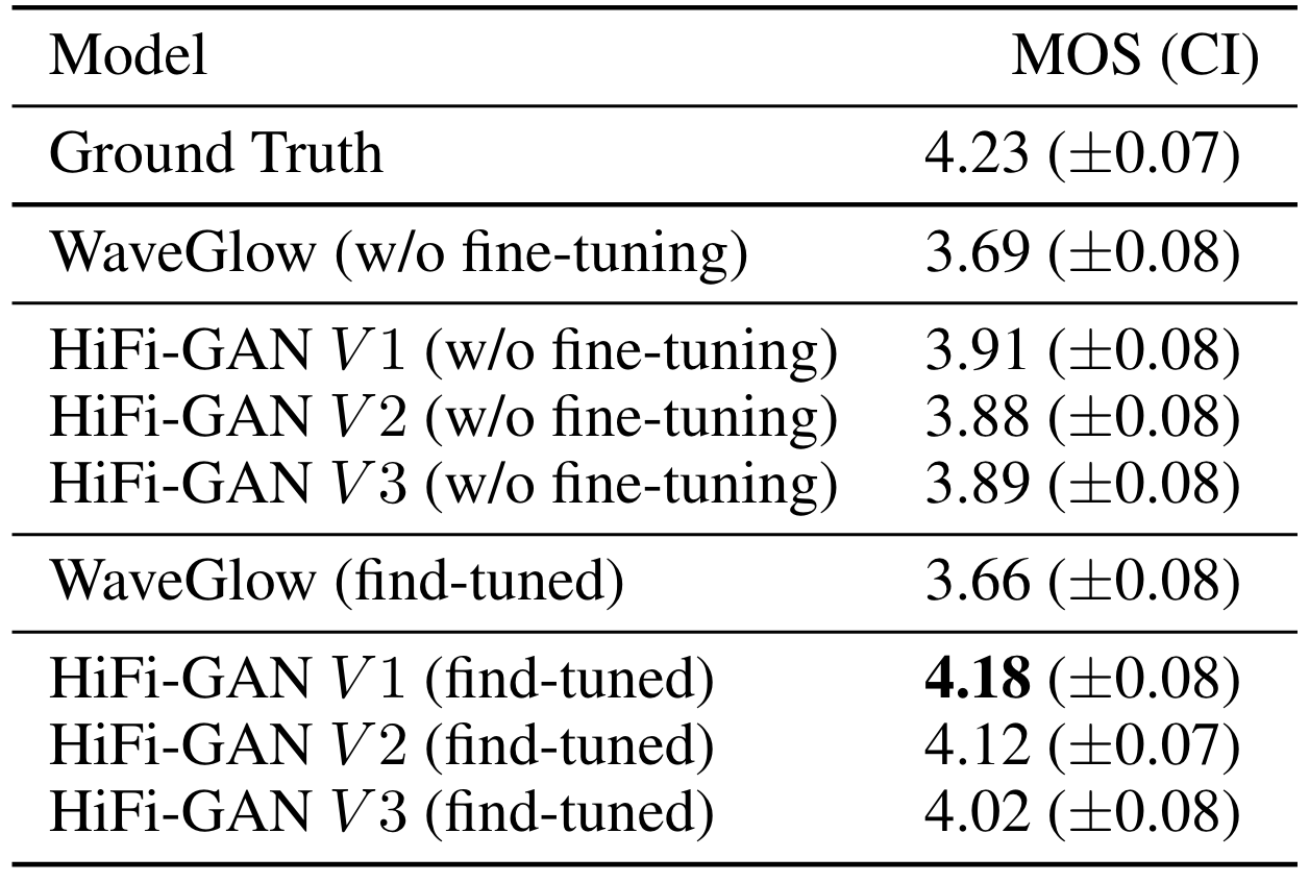
无论是否微调, 效果都超过WaveGlow. 微调后效果更好.
作者认为, 无论是否微调, 最终合成音频的效果都和Ground Truth差距比较大, 作者发现这是Tacotron2本身生成的梅尔谱就比较Noisy了, 所以作者在这个基础上继续对Tacotron2做了微调, 结果如下:
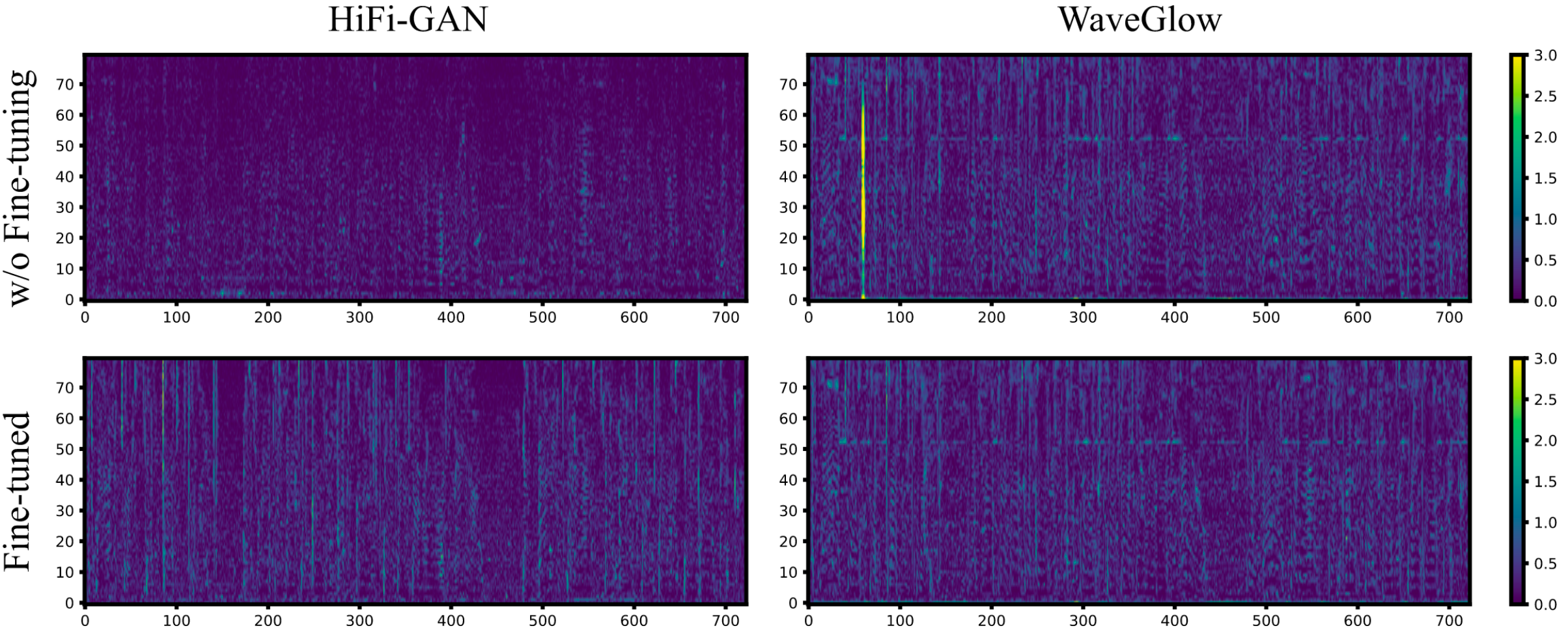
HiFi - GAN的提升比较明显, 但WaveGlow提升就不是很明显, 这表明HiFi - GAN对E2E的TTS系统适应性比较好.
Summary
HiFi - GAN作为声码器(Vocoder) 中相当具有代表性的作品, 相较于传统的Autoregressive模型有显著的推理优势, 性能表现也较好, 尤其是在BigVGAN, EVA - GAN没有出来之前, HiFi - GAN还是挺能打的.
不过性能表现较好可能也受限于主观评估指标有偏的问题, 按现有经验评价HiFi - GAN是在实际应用中音色很准, 但比较明显的缺点就是容易带电. HiFi - GAN还是在诸多项目中被实际应用过, 例如MockingBird, DiffSinger 等.
网络结构也相对比较简单, 不过以现在的眼光来看与CNN相关模型设计的论文感觉无非就是用各种CNN堆感受野, 或者用Dilated Convolution堆感受野, 然后再加上一些小Trick… 说实话, 感觉看论文不如直接看代码… 所以这里也直接附上代码链接, 推荐阅读.
另外, 这次也是首次尝试将LLM用于博客写作中, 能够灵活运用LLM节省自己的搜索时间还是非常方便的.

