TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
- 论文: TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control, EMNLP 2024, Zhou Zhao组.
- 代码: GitHub - AaronZ345/TCSinger: PyTorch Implementation of TCSinger(EMNLP 2024): Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control.
Basic Idea
传统歌声合成(Singing Voice Synthesis)依赖可见歌手的训练数据, 难以处理Zero-shot(即完全未见过的歌手). 现有方法在风格建模(如演唱方法, 情感, 节奏, 技巧, 发音)和多层次控制上存在不足, 导致生成结果缺乏风格细节.
作者提出TCSinger来解决上述问题. TCSinger是首个支持跨语言的Speech / Singing Style Transfer的Zero-Shot SVS模型, 并且具有Multi-Level Style Control的能力.
TCSinger
Overview
在TCSinger中, 首先作者将Content, Style(Singing Method, Emotion, Rhythm, Technique, Pronunciation), Timbre三部分做了解耦, 用不同的结构来建模它们:
- Content: Phoneme Encoder, Note Encoder对Music Score编码, 得到Content Embedding.
- Style: 采用Clustering Vector Quantization(CVQ)对Style离散化处理.
- Timbre: 对于同一歌手的不同Audio Prompt, 用Timbre Encoder得到Timbre Vector.
对上述信息分别编码后, 一股脑输入到一个语言模型Style and Duration Language Model(S&D-LM)中, 预测出目标歌声的Style Embedding和Phoneme Duration.
之后, 采用Pitch Diffusion Predictor来预测F0, 并用Style Adaptive Decoder解码得到目标歌声的梅尔谱.
上述过程对应的Overview如下:
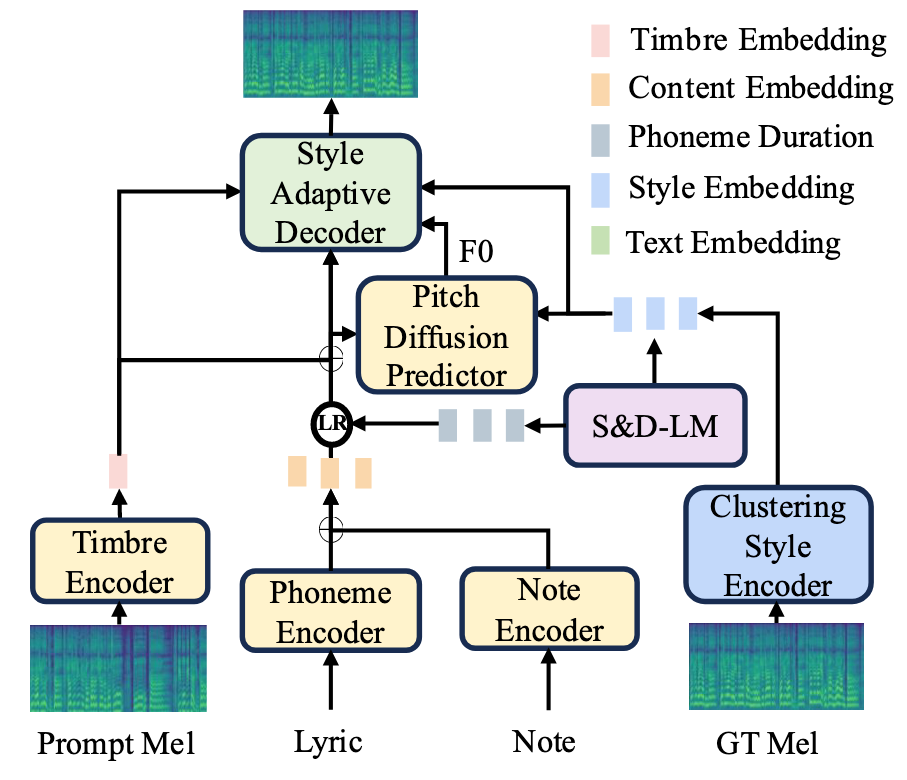
图中LR为Length Regulator.
Clustering Style Encoder
Clustering Style Encoder整体比较简单, 主要将梅尔谱转换为离散的Style Representation, 结构如下所示:

将梅尔谱作为VQ Module来获得一个离散的Style Representation.
CVQ出自论文Online Clustered Codebook, 其主要思想是选取Anchor控制利用率不高的Codebook Entry进行在线更新, 从而提高Codebook Entry的利用率. 在本文中只起到VQ的作用, 只是更加稳定与紧凑, 因此不多叙述.
Style Adaptive Decoder
使用VQ来获取风格信息是有损的, 而且相似的风格很有可能被编码进相同的Codebook Indices, 引入了一种新的Mel-Style Adaptive Normalization, 这样即使用VQ, 也能合成多样风格的歌声.
Style-Adaptive Decoder是一个8步的Diffusion Model, FFT作为Denoiser. Decoder每层都会应用Mel-Style Adaptive Normalization, 如下图所示:
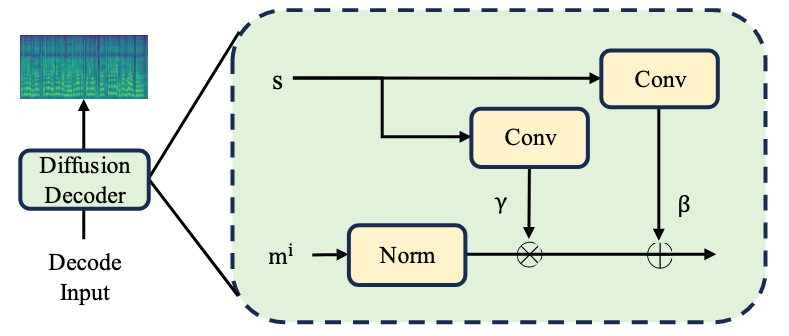
设Decoder第$i$ 层的输出为$m^i$, Mel-Style Adaptive Normalization定义如下:
$$
m^i=\phi_\gamma(s) \frac{m^{i-1}-\mu\left(m^{i-1}\right)}{\sigma\left(m^{i-1}\right)}+\phi_\beta(s)
$$
其中, $\phi_\gamma(\cdot), \phi_\beta(\cdot)$ 分别为两个用于将Style Embedding $s$ 缩放平移的可学仿射变换. 即使是相似的风格, 在进行Scale & Shift后, Decoder被鼓励输出更加多样化的音频.
在训练Decoder的时候同时采用MAE和SSIM作为Loss.
S&D-LM
这里比较有意思, 作者这里认为Singing Style经常表现出局部与长期的依赖, 并且它们随时间变化, 与Content关系不太密切. 所以这里作者用了Language Model来做建模, 即Style and Duration Language Model(S&D-LM).
S&D-LM可以实现两个功能, Zero-Shot Style Transfer与Multi-Level Style Control, 它们预期的输出都是Target Style $\tilde{s}$ 与Target Phoneme Duration $\tilde{d}$, 只是输入不同.
Style Transfer
对于给定的Target Lyrics $\tilde{l}$, Target Notes $\tilde{n}$, 以及与Audio Prompt对应的Mel-Spec $m$, Lyrics $l$, Notes $n$, TCSinger的目标是要根据Audio Prompt合成含有Target Timbre $\tilde{t}$ 和Target Style $\tilde{s}$ 的歌声Mel-Spec $\tilde{m}$.
所以, 首先用不同的Encoder来提取不同的表示, Style $s$, Timbre $t$, Content $c$, Target Content $\tilde{c}$:
$$
\begin{aligned}
& s=E_{\text {style }}(m), t=E_{\text {timbre }}(m), \\
& c=E_{\text {content }}(l, n), \tilde{c}=E_{\text {content }}(\tilde{l}, \tilde{n}),
\end{aligned}
$$
其中$E$ 代表每种属性的Encoder. Target Timbre $\tilde{t}$ 与Source Timbre $t$ 几乎是一样的, 所以只剩下Target Style $\tilde{s}$ 没有解决了, 作者希望用Language Model将$\tilde{s}$ 预测出来.
S&D-LM为Decoder-Only的Transformer, 则进行Style Transfer时, 对Target Style $\tilde{s}$ 和Target Phoneme Duration $\tilde{d}$ 的自回归的预测过程形式化为:
$$
\begin{aligned}
p(\tilde{s}, \tilde{d} \mid s, d, c, \tilde{t}, \tilde{c} ; \theta)=
\prod_{t=0}^T p\left(\tilde{s}_t, \tilde{p}_t \mid \tilde{s}_{<t}, \tilde{d}_{<t}, s, d, c, \tilde{t}, \tilde{c} ; \theta\right)
\end{aligned}
$$
其中$\theta$ 为S&D-LM的参数.
最后, 令$P$ 为Pitch Diffusion Predictor, $D$ 为Style Adaptive Decoder, 可以得到Target F0和Target Mel-Spec $\tilde{m}$:
$$
\begin{aligned}
& F 0=P(\tilde{s}, \tilde{d}, \tilde{t}, \tilde{c}) \\
& \tilde{m}=D(\tilde{s}, \tilde{d}, \tilde{t}, \tilde{c}, F 0)
\end{aligned}
$$
Style Control
由于S&D-LM是一个Language Model, 所以可以用Text Prompt来表示Audio Prompt中的$s$ 和$d$对应的风格.
当执行Style Control的时候, 用Text Encoder对Global Style Prompt(Singing Method, Emotion) $s$ 和Phoneme-Level Prompt(Technique for each Phoneme) $d$ 的对应的Text Prompt $tp$ 进行编码, 然后与$c$ 和$\tilde{c}$ 拼接起来作为S&D-LM的输入, 因此Style Control的预测过程形式化变为:
$$
\begin{aligned}
p(\tilde{s}, \tilde{d} \mid tp, c, \tilde{t}, \tilde{c} ; \theta)=
\prod_{t=0}^T p\left(\tilde{s}_t, \tilde{p}_t \mid tp, c, \tilde{t}, \tilde{c} ; \theta\right)
\end{aligned}
$$
训练期间, 对Style Information用CE, Phoneme Duration用MSE.
具体的, 对于Global Style Embedding为Emotion(Happy / Sad), Singing Method(Bel Canto / Pop), Phoneme-Level Style Embedding为Techniques(Mixed Voice, Falsetto, Breathy, Vibrato, Glissando, Pharyngeal).
由于S&D-LM需要实现两项功能, 所以在训练的时候是以概率$p$ (文中没写, 代码似乎一半一半)采样决定要进行Style Transfer还是Style Control, 在训练的时候采用Teacher-Forcing:
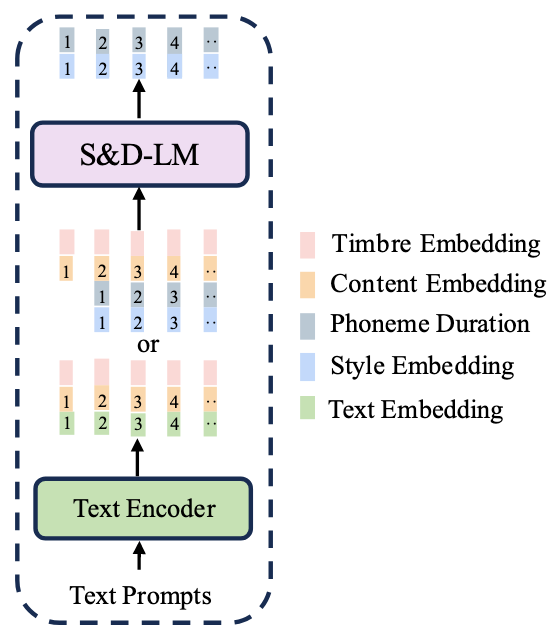
Training and Inference Procedures
Training Procedures
Loss由五个部分组成:
- CVQ Loss: 用CVQ Loss $\mathcal{L}_{CVQ}$ 优化整个Clustering Style Encoder.
- Pitch Reconstruction Loss: 用于训练Pitch Diffusion Predictor的两个Loss, Gaussian Diffusion Loss $\mathcal{L}_{gdiff}$, Multinomial Diffusion Loss $\mathcal{L}_{mdiff}$. 非重点不展开说, 详见附录.
- Mel Reconstruction Loss: 用于训练Style Adaptive Decoder的Loss, MAE $\mathcal{L}_{mae}$ 和SSIM $\mathcal{L}_{ssim}$.
- Duration Prediction Loss: 用于训练S&D-LM预测Duration的Loss, MSE $\mathcal{L}_{dur}$, 对数尺度下的Prediction和GT的MSE.
- Style Prediction Loss: 用于训练S&D-LM预测Style的Loss, CE Loss $\mathcal{L}_{style}$.
需要满足的约束比较多, 所以数据相对来说稍大一些会好点.
Inference with Style Transfer / Style Control
TCSinger的Inference过程:
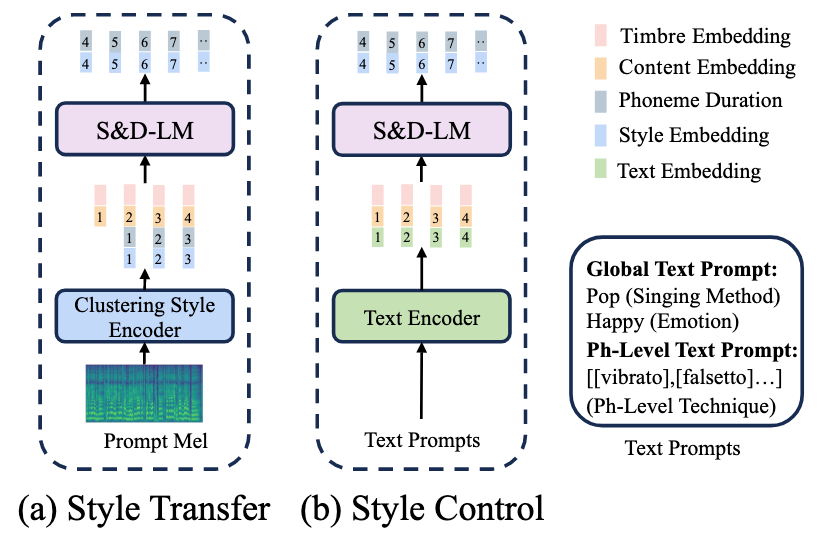
和训练模式一样, 只不过AR的时候没有GT了. Style Transfer就给Style Embedding和Phoneme Duration, Style Control就给Text Embedding.
在进行Speech-to-Singing(STS)任务的时候, 使用Speech Audio Prompt, 其余步骤不变.
Experiments
详细的实验设置和超参数设置请参照原论文.
Dataset
作者共使用累计294小时的语音和歌声开源数据:
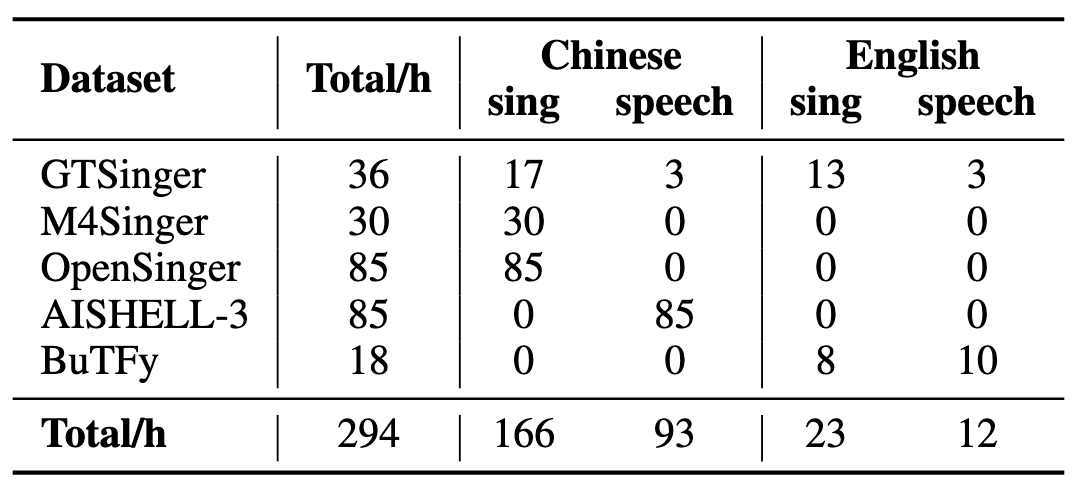
GTSinger, M4Singer, OpenSinger, PopBuTFy这几个数据全是他们组的…
在进行评估的时候随机选择40位没见过的歌手作为测试集来评估TCSinger的Zero-Shot能力.
Details
计算资源为4卡3090Ti, 用Adam在Main SVS Model上训练了300k Steps, S&D-LM 100k Steps. Vocoder为预训练的HiFi-GAN.
评估指标:
- Subjective Metrics: MOS(Mean Opinion Score), CMOS(Comparative Mean Opinion Score), MOS-S(Singer Similarity), MOS-C(Style Controllability).
- Objective Metrics: COS(Singer Cosine Similarity), MCD(Mean Cepstral Distortion), FFE(F0 Frame Error).
Main Results
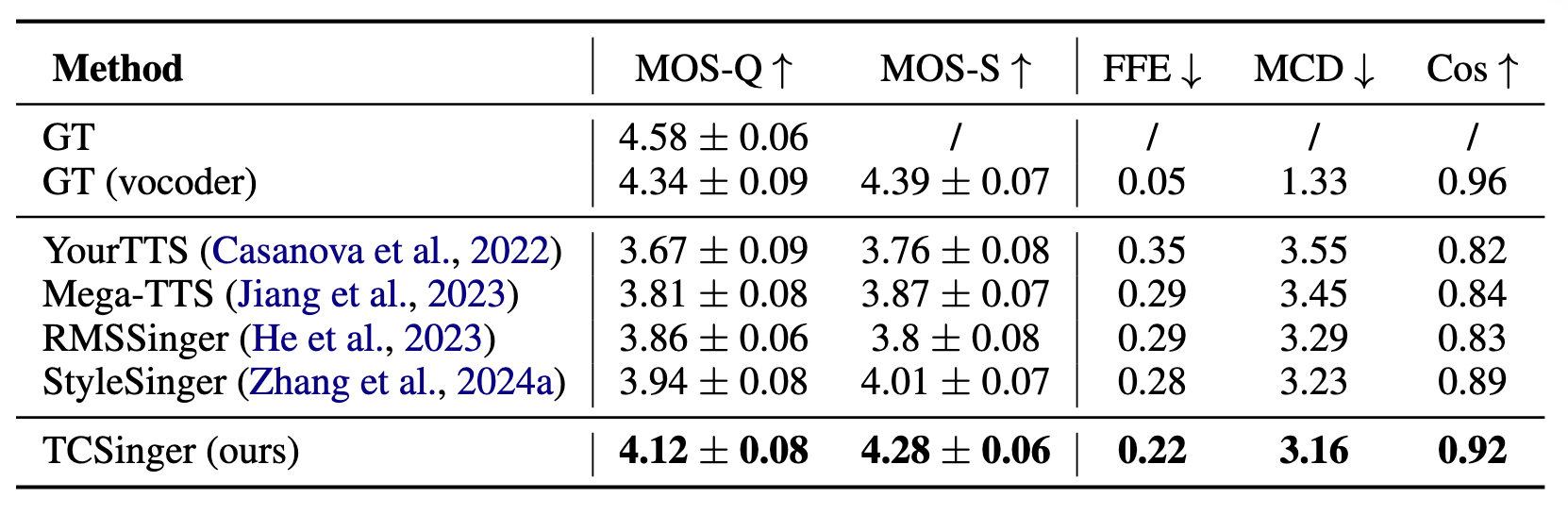
Zero-Shot Style Transfer
在Zero-Shot Style Transfer中, TCSinger表现挺不错的, MOS-Q, MOS-S都比较高.
从生成的梅尔谱中看TCSinger合成效果也是相对不错的:
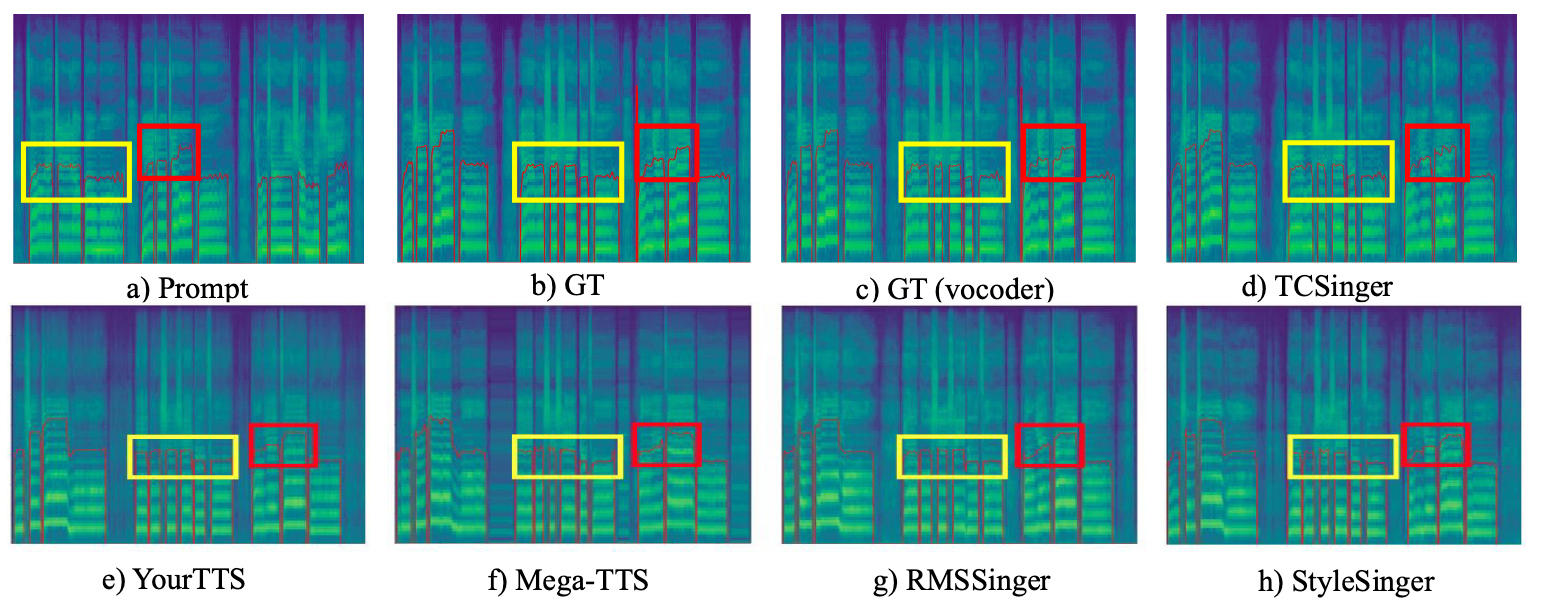
这么一看StyleSinger其实也还不错. 还能观察到SVS模型生成的结果和TTS有明显差距.
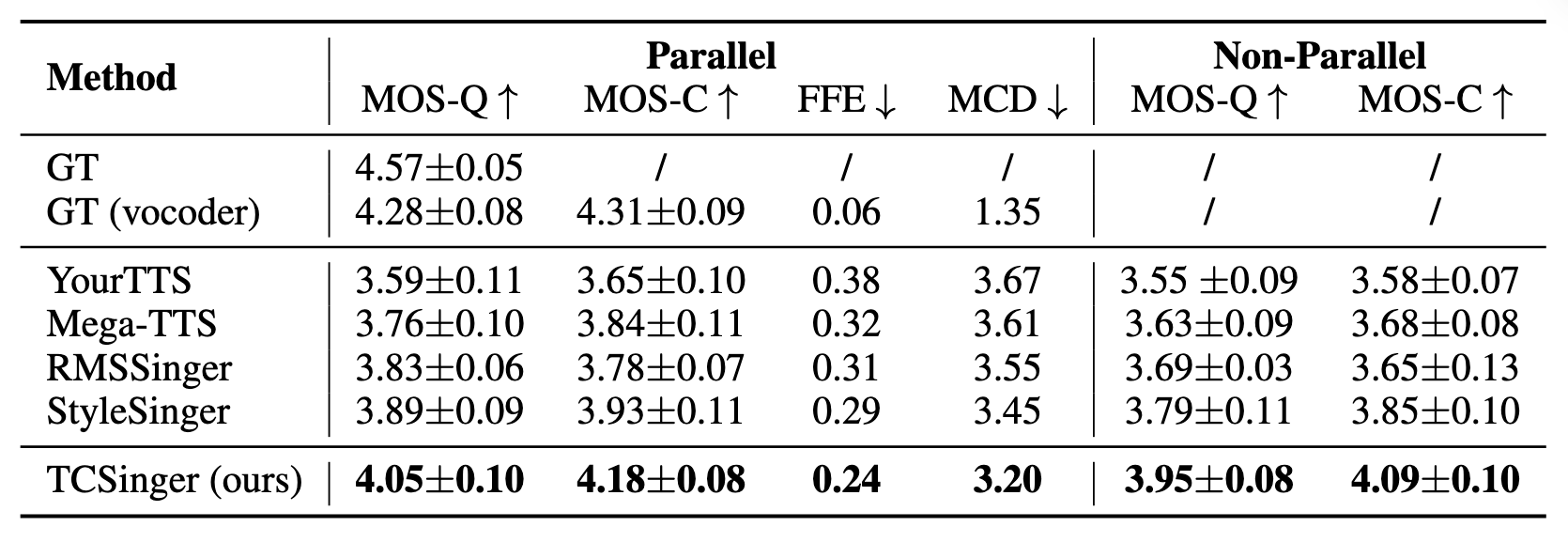
Multi-Level Style Control
Multi-Level Style Control中TCSinger也是效果比较好:
Cross-Lingual Style Transfer
Cross-Lingual Style Transfer结果如下, 表现出较好的跨语言合成能力:
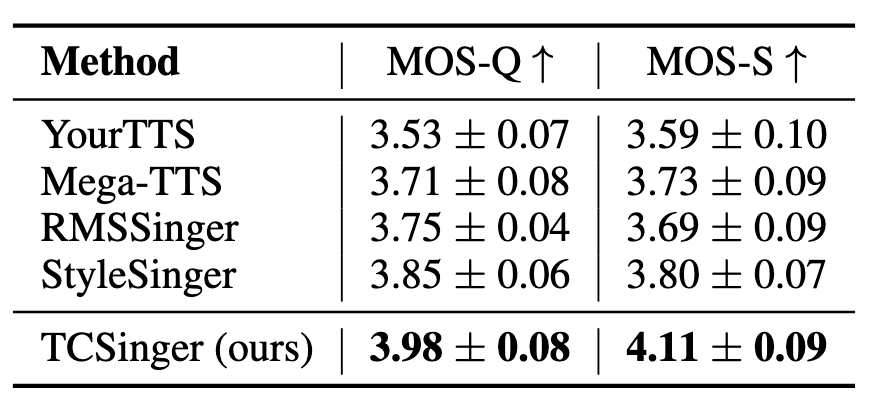
Speech-to-Singing Style Transfer
Speech-to-Singing Style Transfer上结果如下:
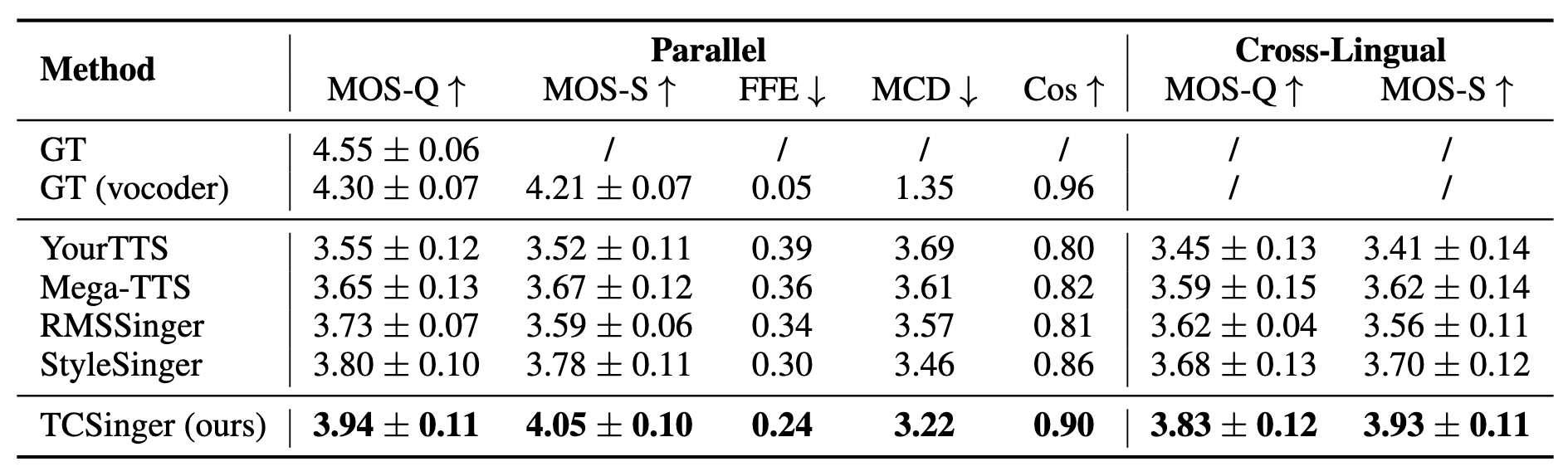
看起来TCSinger在Cross-Lingual下也有比较好的表现, 尤其是在STS这种相对较难的任务下也能优于其他方法.
Ablation Study
消融实验结果如下:
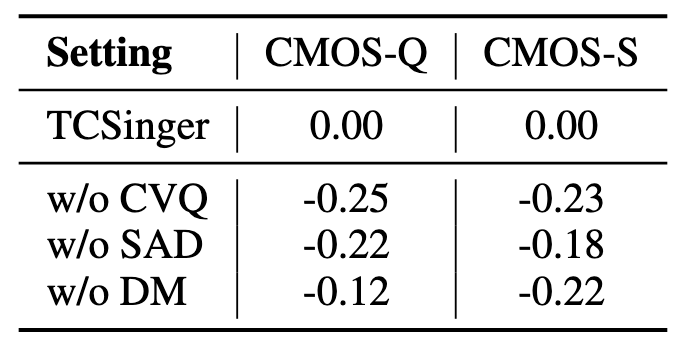
SAD为Style Adaptive Decoder, DM为S&D-LM里的Duration Model.
如果把CVQ换成普通的VQ Module(w/o CVQ), 掉点居然是三个里面最多的, 可能也是因为TCSinger里都是由离散化的Style在驱动的, 看来一个稳定紧凑的离散表示确实有利于TCSinger.
w/o DM 为令S&D-LM仅预测Style, Duration采用FastSpeech 2直接预测, 仍然掉点. 也算验证了Style Modeling中的Style和Duration之间的耦合性, 二者联合建模会收益更大.
不过不知道为什么CMOS-Q掉的并不是很多? 反而在CMOS-S中下降相对明显.
此外, 附录中还有一些消融实验, 感兴趣自行查阅.
Summary
TCSinger从Style Modeling入手, 可以通过Style Transfer和Style Control在Zero-Shot SVS上合成高质量歌声.
乍一看, 整篇文章很多东西都直接引用其他工作, 乍一看觉得是缝合怪.
但是再一想, 其实TCSinger的本质和缝不缝都没太大关系… Encoder是VQ, S&D-LM也是VQ(AR Generation), 这不全是VQ吗? 还有Zero-Shot? 在5202年的今天来看, 这明摆了就是在SVS任务上为离散化生成路线(Speech-LLM)在小规模数据和模型上进行尝试啊…
TCSinger也有续作, TCSinger 2感觉是一个完全不同的画风, 先挖坑再说.

