ReInceptionE: Relation-Aware Inception Network with Joint Local-Global Structural Information for KGE
本文是论文ReInceptionE: Relation-Aware Inception Network with Joint Local-Global Structural Information for Knowledge Graph Embedding的阅读笔记和个人理解.
Basic Idea
作者观察到基于卷积的方法存在如下限制:
- ConvE中没有融入结构化信息.
- ConvE的性能仍然被交互次数所限制.
而KBAT直接从多跳的图角度出发, 考虑N阶邻居的关系和它们本身对中心节点的影响, 但是仍需多跳推理, 所以它只考虑了邻居的局部信息. 因此, 利用局部和全局信息结合可能会从中受益.
例如, 在下图中, 对于(Jack London, nationality, ?)这个问题, 我们能够从局部邻居观察到(Jack London, place_lived, Oakland)存在, 因为Oakland在Embedding中与America非常近, 所以也会增加America的预测分数. 同时, 对于关系nationality的全局信息, 即它存在的三元组所对应的头实体集合和尾实体集合也能帮助我们提升结果得出America的概率:
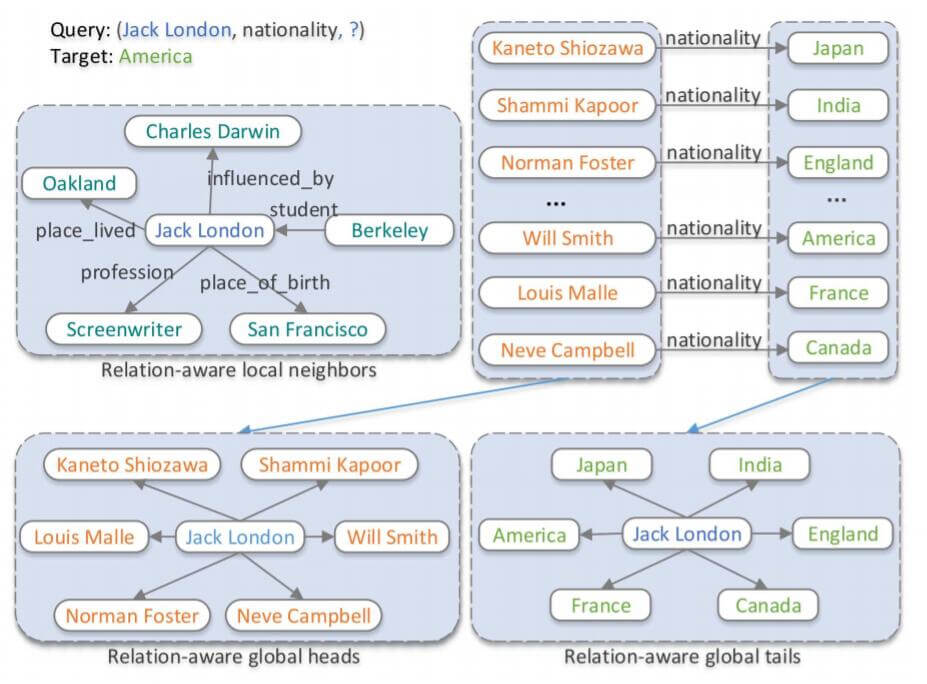
这也可能会潜在的导致局部和全局信息冲突所带来的混淆问题, 即多个实体的分数高度近似, 模型将会很难区分它们. 可能说的比较极端.
此外, 在这个例子中,
nationality应该不是在这篇论文中提出的笛卡尔积关系, 因为头实体和尾实体的数量实在是太大了.
根据上述Conv类模型存在的缺陷, 作者希望用Inception来增加头实体和关系之间的交互次数, 用Attention丰富局部和全局信息.
ReInceptionE
ReInceptionE(Relation - aware Inception network with joint local-global structural information for knowledge graph Embedding) 将Inception和KBAT的优势结合到了一起, 作者先用Inception在实体和关系之间交互, 生成头实体和关系之间的查询向量, 然后从局部和全局两个角度集成信息, 用Attention把信息融合到一起.
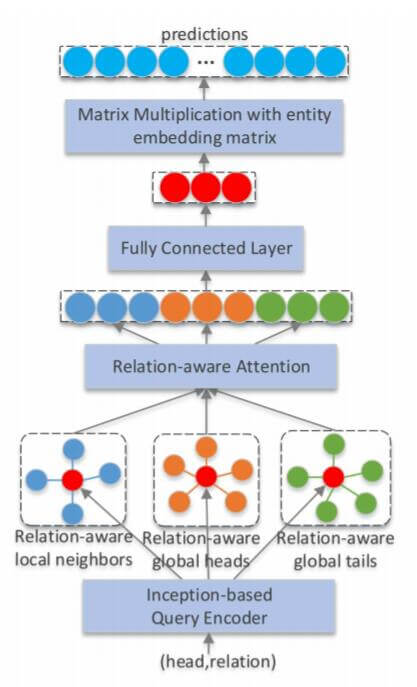
Inception - based Query Encoder
除去和ConvE实体关系嵌入的拼接方式不同, 这小节基本就是在讲Inception, 有基础可以跳过.
作者指出, 在ConvE中其实并没有最大化实体和关系的交互次数. 因为ConvE是通过Concat的方式把二者拼接到一起, 只有最中间的交界处才有卷积核对二者的交互. 为了能够尽可能多的使头实体嵌入$\mathbf{v}_h$ 和关系嵌入$\mathbf{v}_r$ 整合, 作者使用Stack的方式在Channel维上把二者堆叠到一起, 这样在抽取特征时直接就能对二者共同交互:
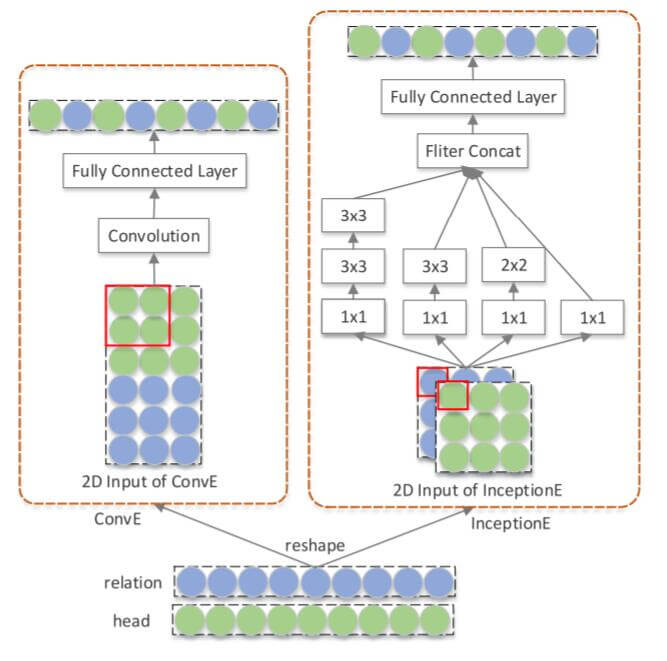
CoPER也是针对这个点改进的, 只不过使用的是参数生成的方法, 避免了Concatenate这种加性操作.
在Inception中, 在这里, 先使用$1\times1$ 卷积能提供最直接的实体嵌入$\mathbf{v}_h$ 和关系嵌入$\mathbf{v}_r$ 的信息整合作用:
$$
\mathbf{v}_{1 \times 1}=\operatorname{Relu}\left(\left[\mathbf{v}_{h} \lVert\mathbf{v}_{r}\right] \ast \omega_{1 \times 1}\right)
$$
其中$\ast$ 为卷积操作, $\omega_{1\times1}$ 为$1\times1$ 的卷积核权重. $\lVert$ 为Stack操作.
在整合过后, 由于Inception通过多尺度的方式捕获不同角度的高阶信息, 所以会使用不同大小的卷积核, $\mathbf{v}_{2\times2}, \mathbf{v}_{3\times3}$ 分别代表在$\mathbf{v}_{1\times1}$ 后接一个$2\times2$ 和$3\times3$ 卷积的结果.
Inception中, 不同大小卷积核抽取后的特征图可能宽高不同, 使用Padding可以保证它们的特征图不变, 以正确的Stack到一起.
接着, 在Inception中, 还使用了两个$3\times3$ 的卷积代替一个$5\times5$ 的卷积, 以此捕获大空间上的交互:
$$
\mathbf{v}_{2(3 \times 3)}=\operatorname{Relu}\left(\operatorname{Relu}\left(\mathbf{v}_{1 \times 1}^{2(3 \times 3)} \ast \omega_{3 \times 3}^{1}\right) \ast \omega_{3 \times 3}^{2}\right)
$$
$\mathbf{v}_{1 \times 1}^{2(3 \times 3)}$ 为输入的交互特征, 即$1\times1$ 卷积后的结果, $\omega_{3\times3}^1, \omega_{3\times3}^2$ 分别为两个$3\times3$ 的卷积核参数.
最后, 把前面的多尺度信息Stack起来, 然后打平, 扔进一层FC层:
$$
\begin{aligned}
\mathbf{v}_{q} &=\text { Inception }\left(\mathbf{v}_{h}, \mathbf{v}_{r}\right) \\
&=\operatorname{Relu}\left(\operatorname{vec}\left(\left[\mathbf{v}_{1 \times 1}\lVert \mathbf{v}_{2 \times 2} \lVert \mathbf{v}_{3 \times 3} \lVert \mathbf{v}_{2(3 \times 3)}\right]\right) \mathbf{W}\right)
\end{aligned}
$$
$\mathbf{W}$ 为一层FC的参数.
整体交互的输出结果$\mathbf{v}_q$, 视作是头实体嵌入$\mathbf{v}_h$ 和关系嵌入$\mathbf{v}_r$ 之间的查询结果.
Relation - Aware Local Attention
下面, 作者从图视角对局部信息用KBAT的方式做集成.
在上小节中, 已经用Inception获得了头实体嵌入$\mathbf{v}_h$ 和关系嵌入$\mathbf{v}_r$ 之间的查询结果$\mathbf{v}_q$.
在图视角中, 头实体$h$ 的邻居集为$\mathcal{N}_{q}=\left\{n_{i}=\left(e_{i}, r_{i}\right) \mid\left(e_{i}, r_{i}, h\right) \in \mathcal{G}\right\}$, 对于每个邻居$n_i = \left(e_i, r_i\right)$, 都可以计算它们的查询编码:
$$
\mathbf{v}_{n_{i}}=\operatorname{Inception}\left(\mathbf{v}_{e_{i}}, \mathbf{v}_{r_{i}}\right)
$$
接着用$\mathbf{v}_q$ 和$\mathbf{v}_{ni}$ 计算Attention Score $s_i$:
$$
s_{i}=\operatorname{LeakyRelu}\left(\mathbf{W}_{1}\left[\mathbf{W}_{2} \mathbf{v}_{q} \lVert \mathbf{W}_{3} \mathbf{v}_{n_{i}}\right]\right)
$$
然后计算Attention Weight $\alpha_i$:
$$
\alpha_{i}=\frac{\exp \left(s_{i}\right)}{\sum_{n_{j} \in \mathcal{N}_{a}} \exp \left(s_{j}\right)}
$$
为了保留原始查询嵌入的信息, 这里也加上了类似残差的操作:
$$
\mathbf{v}_{n}=\operatorname{Relu}\left(\sum_{n_{i} \in \mathcal{N}_{q}} \alpha_{i} \mathbf{W}_{3} \mathbf{v}_{n_{i}}\right)+\mathbf{W}_{2} \mathbf{v}_{q}
$$
把上述Relation - Aware Attention操作记为下式:
$$
\mathbf{v}_{n}=Re A t t\left(\mathbf{V}_{n}, \mathbf{v}_{q}\right)
$$
$\mathbf{V}_n = \left\{ \mathbf{v}_n \mid n_i \in \mathcal{N}_q \right\}$ 为局部邻居向量的集合.
Relation - Aware Global Attention
每个实体的局部邻居数量都不同, 可能会导致稀疏性. 稀疏性会影响KGE的准确率. 作者根据关系$r$, 提取出同一种关系的头实体$\mathcal{H}_{r}=\left\{e_{i} \mid\left(e_{i}, r, e_{j}\right) \in \mathcal{G}\right\}$ 所共享的信息, 以及尾实体$\mathcal{T}_r=\left\{e_{j} \mid\left(e_{i}, r, e_{j}\right) \in \mathcal{G}\right\}$ 共享的一些隐含信息.
即构建下面的这两个子图Relation - aware global heads和Relation - aware global tails, 对每个关系所对应的头尾实体集合用Attention做了聚合.
上述操作只需要将同关系所对应的头实体集$\mathcal{H}_r$ 视为查询向量$\mathbf{v}_q$ 的邻居, 尾实体集$\mathcal{T}_r$ 也视为$\mathbf{v}_q$ 的邻居, 再做Relation - Aware Local Attention就可以了:
$$
\mathbf{v}_{r h}=Re A t t\left(\mathbf{V}_{r h}, \mathbf{v}_{q}\right)
$$
$\mathbf{V}_{rh}=\left\{\mathbf{v}_{h_{ri}}\mid h_{ri} \in \mathcal{H}_r\right\}$ 是对应关系中的所有头实体集合.
$$
\mathbf{v}_{r t}=ReAtt\left(\mathbf{V}_{r t}, \mathbf{v}_{q}\right)
$$
$\mathbf{V}_{rt}=\left\{\mathbf{v}_{t_{ri}}\mid t_{ri} \in \mathcal{T}_r\right\}$ 是对应关系中的所有尾实体集合.
Joint Relation - Aware Attention
最后, 将前面包含局部信息的查询向量$\mathbf{v}_n$, 包含全局信息的查询向量$\mathbf{v}_{rh}, \mathbf{v}_{rt}$ 一并拼接起来, 再做最后一次线性投影, 就得到了最终的查询向量$\mathbf{v}_q^\prime$:
$$
\mathbf{v}_{q}^{\prime}=\mathbf{W}_{4}\left[\mathbf{v}_{n}\lVert\mathbf{v}_{r h} \lVert \mathbf{v}_{r t}\right]+\mathbf{b}
$$
$\mathbf{W}_4, \mathbf{b}$ 为权重矩阵和偏置项.
打分函数为计算查询嵌入$\mathbf{v}_q^\prime$ 与尾实体嵌入$\mathbf{v}_t$ 的点积相似度:
$$
f(h, r, t)=\mathbf{v}_{q}^{\prime T} \mathbf{v}_{t}
$$
然后通过最大化正例三元组的条件概率的方式来调整模型参数:
$$
p(t\mid h, r)=\frac{\exp (\lambda f(h, r, t))}{\sum_{\left(h, r, t^{\prime}\right) \in \mathcal{G}^{\prime} \cup\{(h, r, t)\}}\exp \left(\lambda f\left(h, r, t^{\prime}\right)\right)}
$$
$\lambda$ 为平滑参数, $\mathcal{G}^\prime$ 为负采样获得的三元组集合.
总体上用交叉熵来优化模型:
$$
\mathcal{L}=-\frac{1}{|\mathcal{E}|} \sum_{i=0}^{|\mathcal{E}|} \log p\left(t_{i} \mid h_{i}, r_{i}\right)
$$
$\mathcal{E}$ 为$\mathcal{G}$ 中的有效实体总数.
Experiments
详细的超参数设置请参照原论文.
Main Results
作者在WN18RR和FB15k - 237这两个数据集上与诸多Baseline进行了比较:
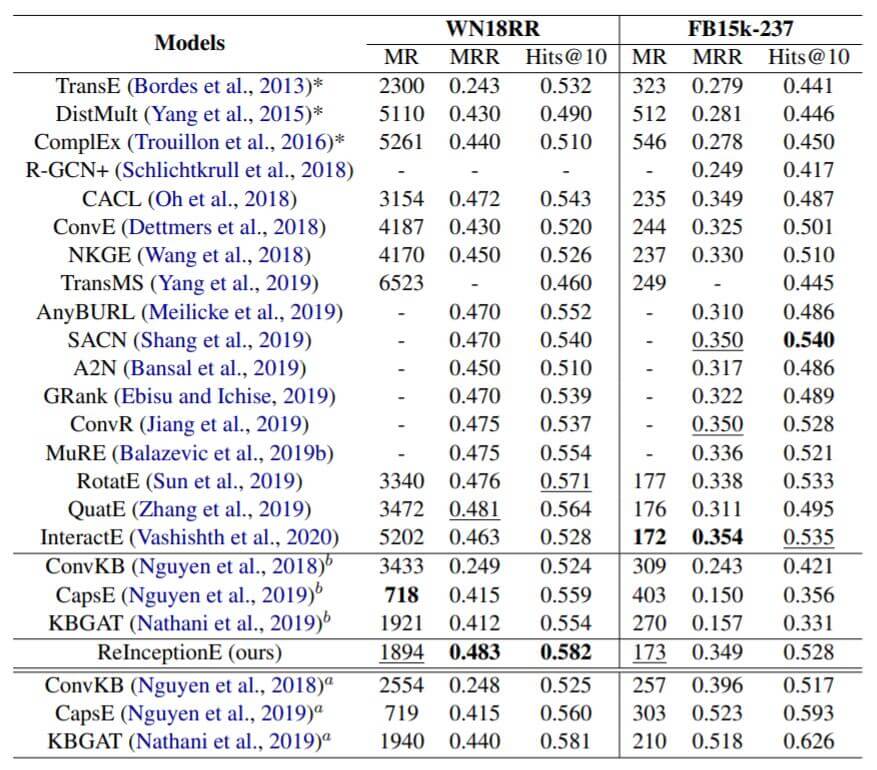
Baseline有很多是基于图或基于CNN的方法. 右上角角标b代表从另一篇论文重新运行代码得出的结果, a代表作者从原论文中得到的结果.
ConvKB, CapsE, KBGAT的评估协议是不公平的, 我建议不要关注这三个模型的结果.
ReInceptionE其实也并没有超出其他Baseline很多的性能, 感觉效果其实差不多.
明显在关系比较少的WN18RR上效果比关系很多的FB15k - 237上效果要好, 我估计是因为Attention的问题. Attention在数据量小的情况下非常脆弱. 关系数量多了但数据总量没怎么增长时, 依赖关系作出判断的模型会因关系的长尾问题暴露出很大缺陷.
Impact of Different Modules
作者探究了在两个数据集上ReInceptionE各组件的影响:
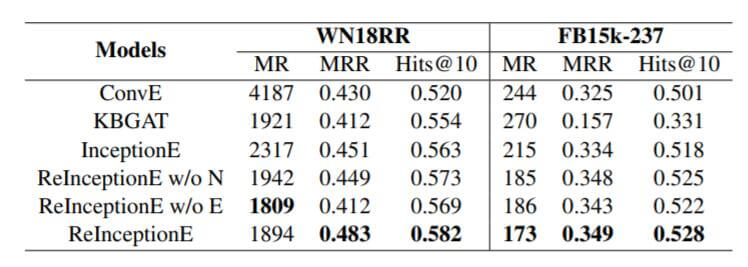
ReInception w/o N是模型不使用局部信息, ReInception w/o E是不使用全局信息. 单独使用InceptionE的效果就比ConvE好很多, 在加入局部信息后, 效果比KBAT也有改善. 与只使用局部信息相比, 只使用全局信息更不利于模型区分三元组. 二者结合的情况下, 效果最佳.
Evaluation on Different Relation Types
在WN18RR和FB15k - 237上对不同种类的关系预测结果如下:
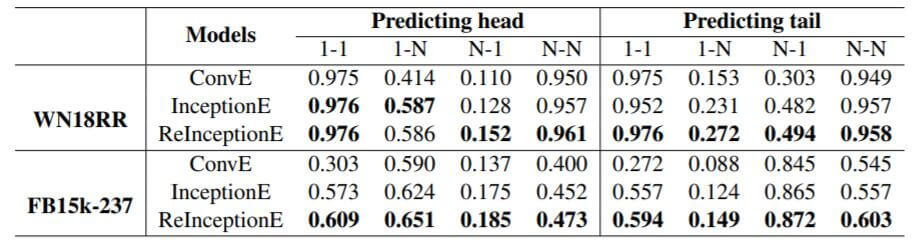
相比于ConvE和InceptionE, ReInceptionE有改善, 看起来加入Inception的作用要更大.
Case Study
作者还分析了两个小案例:
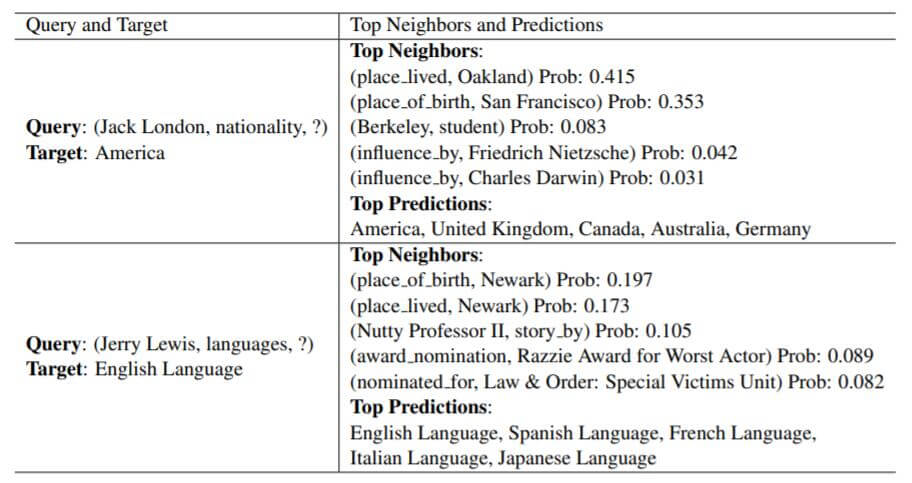
通过Attention学习得到的重要邻居往往权重都比较高, 它们都是与Target相关或能够利用它推断出Target的三元组.
Summary
ReInceptionE使用Inception作为增加实体与关系交互的基本组件, 并在KBAT的基础上集成局部和全局信息, 用Relation Aware Attention的方式将二者融合到一起,
我之前一直都想做一种基于图的多尺度关系感知的Attention, 和这篇论文思路几乎一致.
有句话说得好:
增加交互来提升性能的方法应该是有上限的, 基于CNN的方法核心就是最大化实体Embedding和关系Embedding的交互, 如果再以交互为核心扩展基于CNN的方法, 可能从中的收益不大.
从本文中看到, 即使利用CV早期做出的某个具体BottleNeck套过来, 尤其是引入早期CV中效果最好的多尺度的BottleNeck来提升交互次数, 也仍然没有带来质的飞跃. 所以不得不让人怀疑继续增加交互的有效性.

