Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
本文是论文Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation的阅读笔记和个人理解, 论文本身比较简单.
CLIP 打通了文本与视觉之间的连接桥梁, 不难想到在文本与音频这两个结合紧密的领域中也得有一个模型来完成跨模态连接的问题.
于是CLAP(Contrastive Language-Audio Pretraining)应运而生, 这个模型和名字很有意思, 因为在ICASSP 2023上有两篇同样名字为CLAP的模型同时出现.
分别是:
- LAION-CLAP: Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation, 来自LAION-AI.
- MS-CLAP: CLAP: Learning Audio Concepts From Natural Language Supervision, 来自微软.
在抱抱脸上的提供的CLAP是LAION-CLAP, 流传和影响力也更为广泛.
CLAP
Overview
CLAP框架图如下:
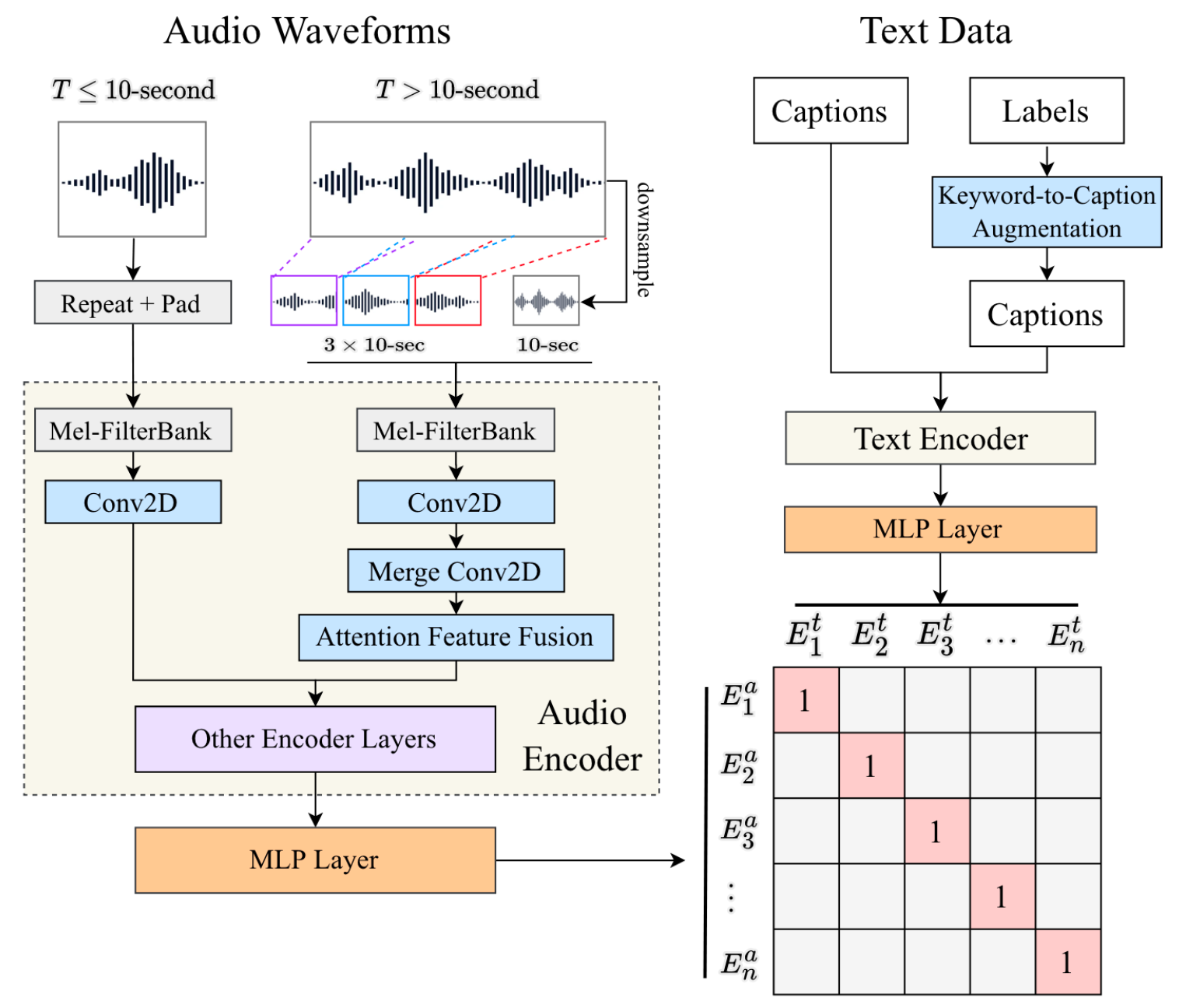
明显的, CLAP也是遵循CLIP结构的双塔结构与训练方式:
- Audio Encoder会用Conv2d和一些其他的Encoder Layer(最后选择的起始是类似Swin Transformer的HTS-AT)完成对Audio的编码. 在时间长不同的情况下会有不同的处理流程.
- Text Data被Keyword-to-Caption Augmentation增强后再送入Text Encoder中编码.
- 最后用Audio Encoder获得的表示和Text Encoder的表示通过MLP做Contrastive Learning.
Contrastive Language - Audio Pretraining
与CLIP类似, 用两个两层的MLP将Audio Feature $X_i^a$ & Text Feature$X_i^t$ 投影到多模态对齐的语义空间:
$$
\begin{aligned}
E_i^a & =M L P_{\text {audio }}\left(f_{\text {audio }}\left(X_i^a\right)\right) \\
E_i^t & =M L P_{\text {text }}\left(f_{\text {text }}\left(X_i^t\right)\right)
\end{aligned}
$$
其中$f(\cdot)$ 为Audio / Text Encoder.
接着用Contrastive Loss:
$$
L=\frac{1}{2 N} \sum_{i=1}^N\left(\log \frac{\exp \left(E_i^a \cdot E_i^t / \tau\right)}{\sum_{j=1}^N \exp \left(E_i^a \cdot E_j^t / \tau\right)}+\log \frac{\exp \left(E_i^t \cdot E_i^a / \tau\right)}{\sum_{j=1}^N \exp \left(E_i^t \cdot E_j^a / \tau\right)}\right)
$$
$\tau$ 为可学的温度系数, $N$ 为样本总数, 实际训练中为Batch Size.
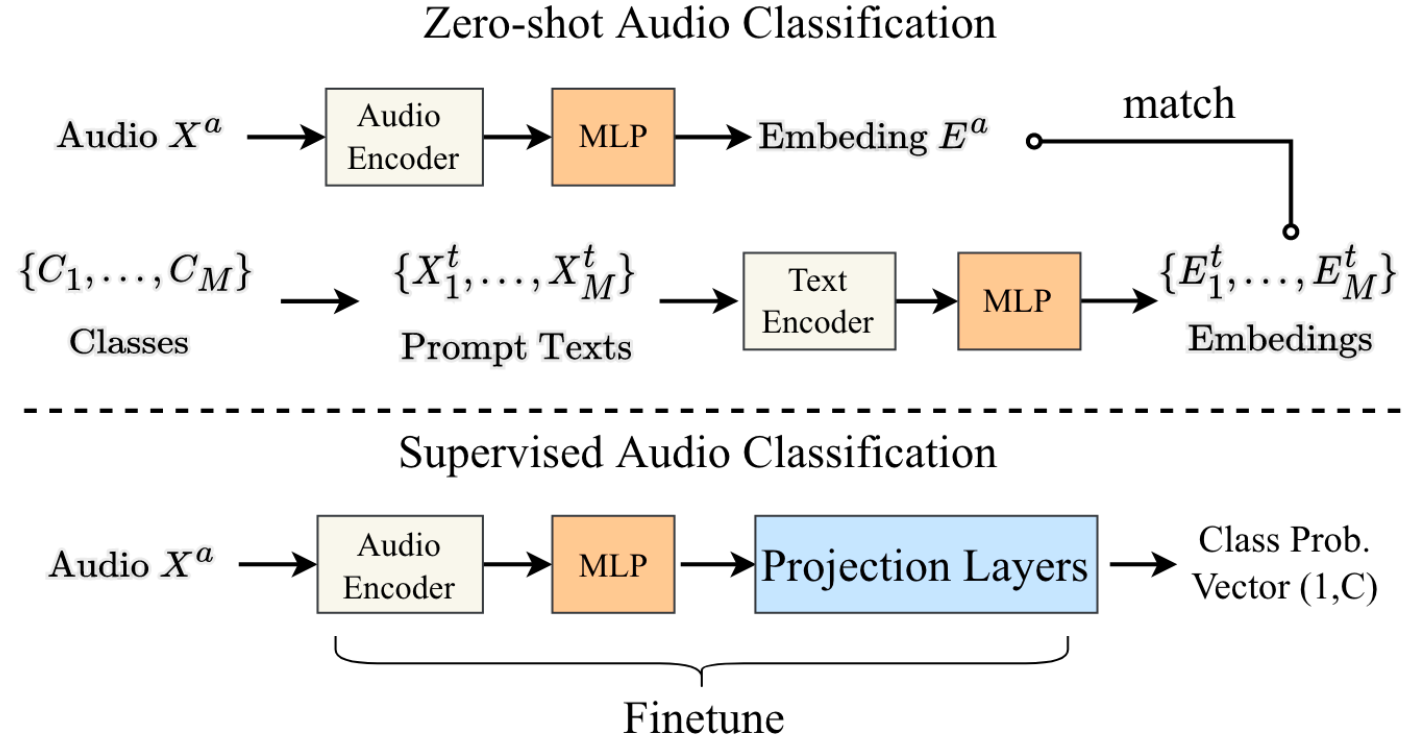
Downstream Tasks in Inference Stage
各类下游任务在Inference时候分别这样做:
- Text-to-Audio Retrieval: 获得Audio Embedding $E_p^a$, 并用余弦相似度找到在$E^t = \{E_1^t, \dots, E_M^t\}$ 内最相近的$E_q^t$.
- Zero-shot Audio Classification: 对于M个Audio Class $C = \{C_1, \dots, C_M\}$, $X^t$, 构建M个Prompt, 比如”the sound of
class name“,即$X^t = \{X_1^t, \dots, X_M^t\}$, 然后就可以像Text-to-Audio Retrieval一样, 对于给定的 $X_p^a$, 找到最临近的Text $X_q^t$, 以此完成Zero-shot Audio Classification. - Supervised Audio Classification: 对于给定的$X_p^a$, 获得它的Embedding $E_p^a$, 然后直接接一个Linear Head做有监督分类.
Audio Encoders and Text Encoders
有很多种方法都可以当Audio Encoder和Text Encoder.
作者会在实验中组合尝试.
Feature Fusion for Variable - Length Audio
对于输入总长度为$T$ s的音频, 作者设定固定长$d=10$ s. 对于不同长度的音频, CLAP有不同的处理方法(其实是包含关系):
- 对于$T\leq d$ s的音频, CLAP会将其直接重复若干次, 然后再做Zero Padding. 例如一条3s的音频, 将其重复3次, 然后再Padding 1s. 最后用一个Conv2d提取特征.
- 对于$T > d$ s的音频, CLAP先将$T$ s的音频降采样到$d$ s作为全局输入, 随机选取三条$d$ s的音频切片, 分别从前, 中, 后各取一条. 全局输入会被用一个Conv2d做Projection(此时就是$T \leq d$ 的情况), 得到Global Feature $X_{\text {global }}^a$, 剩下三条局部输入会被用一个额外的Conv2d聚合, 得到$X_{\text {local }}^a$.
最后再将两种特征融合:
$$
X_{\text {fusion }}^a=\alpha X_{\text {global }}^a+(1-\alpha) X_{\text {local }}^a
$$
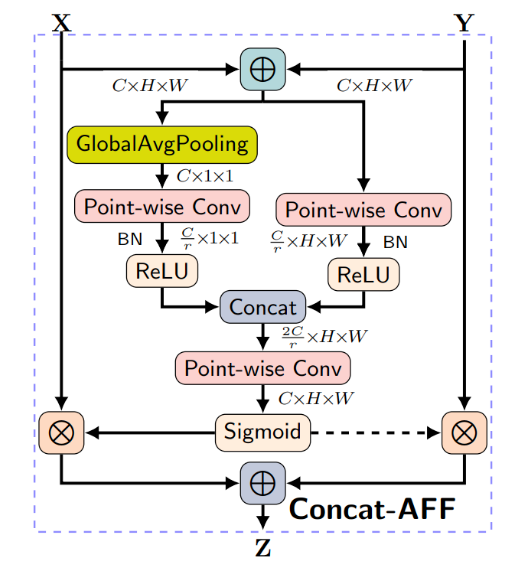
其中系数$\alpha = f_{AFF}(X^a_{global}, X^a_{local})$ 由Attention Feature Fusion(AFF)结构得到:
Training Dataset
作者使用了三个数据集作为训练数据:
- Audioset: 大约1.9M的音频样本, 每个音频只有标签.
- AudioCaps+Clotho (AC+CL): 大约有55K的Audio-Text Pairs.
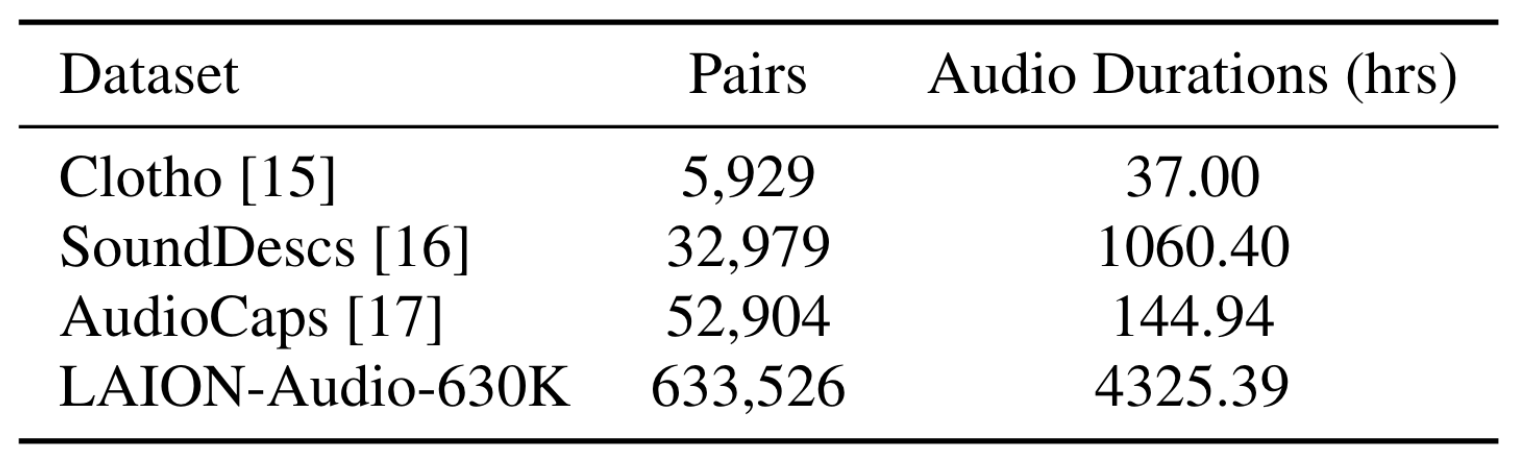
- LAION-Audio-630K: 收集了共含63K的Audio-Text Pairs, 共计4325小时. 从公开源中收集了人类活动, 自然声音, 音频音效等. 其中也有对应的相关文本描述, 其大小与之前的公开数据集对比如下:
作者设定所有音频的采样率均为48kHz, 并且将仅有类别标签可用的数据标签转换为”The sound of label-1, label-2, …, label-n“的Caption, 或者是用下面提到的Keyword-to-Caption Augmentation将这些Label转换为Caption.
Keyword-to-Caption Augmentation
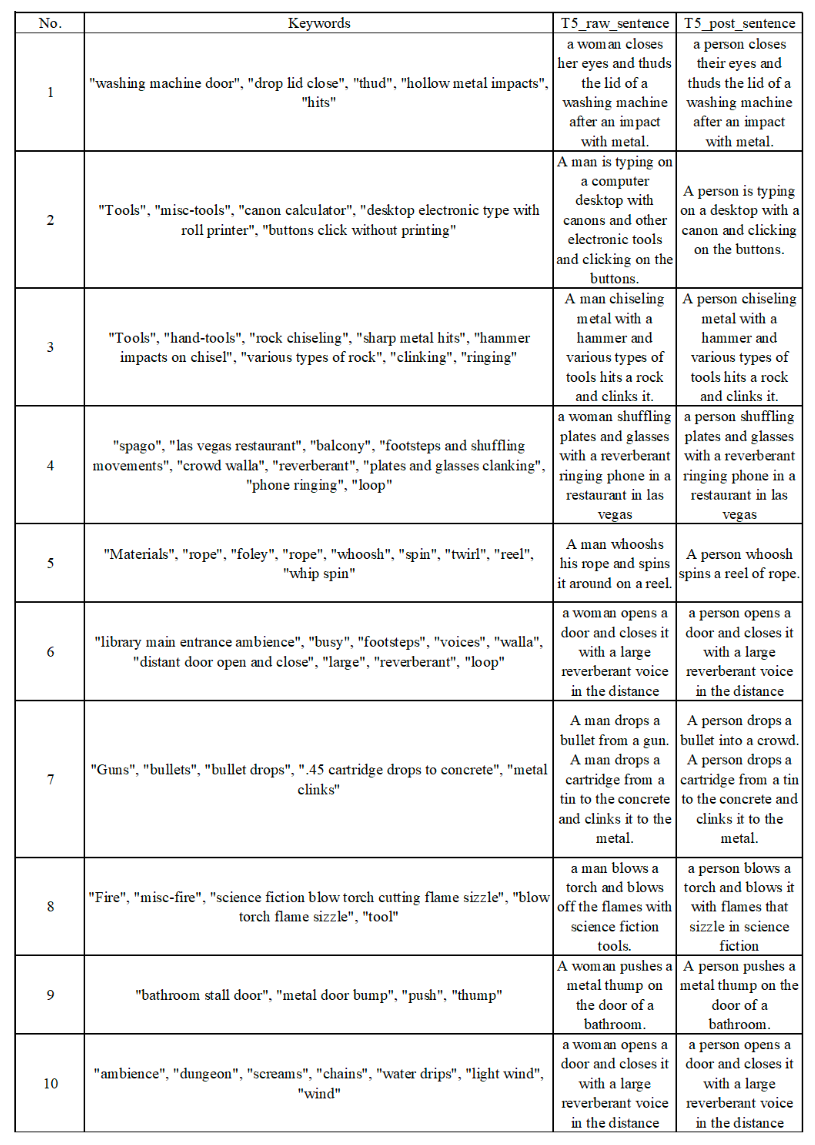
某些数据集提供了对音频的关键字, 作者使用T5将Keywords转换为Captions(Keyword-to-Caption Augmentation, K2C Aug.), 并去除了一些性别偏见, 并进行后处理. 因此可以将Audio Sample和Text Caption的总数扩充到2.5M.
转换完的一些例子如下所示:
Experiments
详细的模型参数设置和实验设置请参考原论文.
Text-to-Audio Retrieval
Audio and Text Encoders
为对比不同Text Encoder的效果, 作者采用PANN, HTS-AT作为Audio Encoder, 以CLIP 的Text Encoder, BERT, RoBERTa作为Text Encoder, 结果如下:
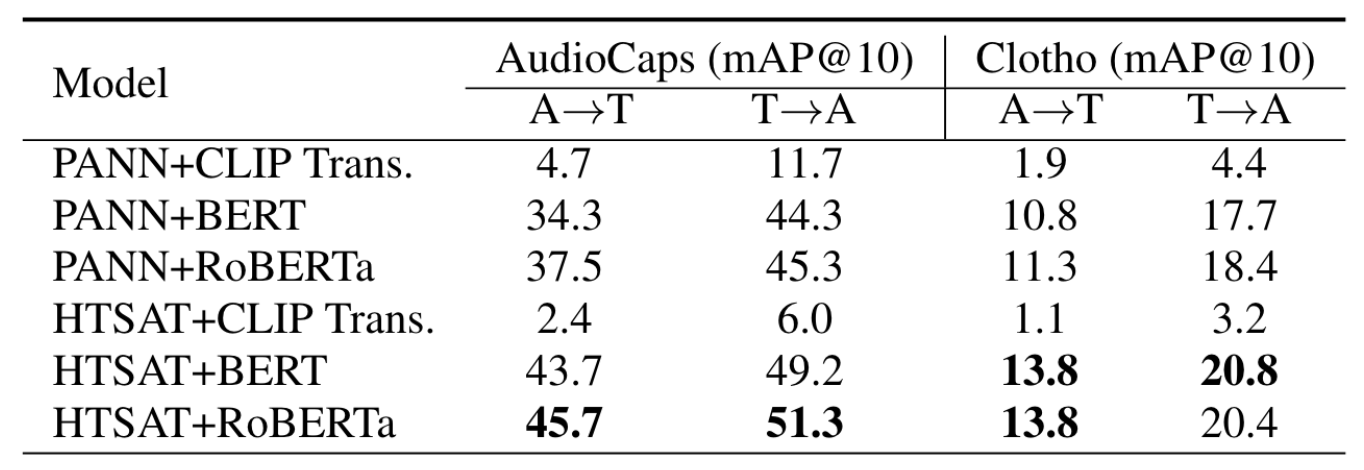
CLIP Text Encoder表现很差, 我怀疑真实原因可能是因为它在VL上已经做过超大规模对齐. 作者也认为是CLIP在原来的VL大规模数据上过拟合严重. RoBERTa表现最好, 这与它们在纯文本任务上的表现类似.
因此, CLAP的双塔实际上由HTS-AT和RoBERTa共同组成.
Dataset Scaling & Keyword-to-Caption and Feature Fusion
进一步观察Dataset Scaling和K2C & Feature Fusion带来的影响, 结果如下:
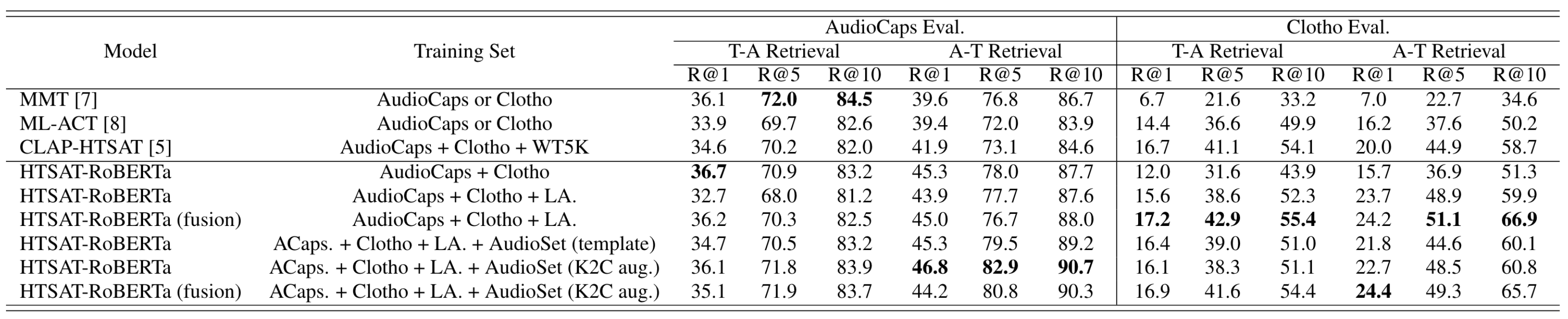
数据集增大后, 效果变得更好. 加入LA后再AudioCaps上反而有下降, 作者认为是Audio Encoder的预训练权重来自AudioSet, AudioCaps包含与AudioSet相似的音频. 所以此时CLAP泛化能力提高, 但在AudioCaps上的适应性变差了, 所以Clotho上才会有明显提高.
此外, 观察到单独加Fusion和单独加K2C aug后, 都能使得模型的表现更好.
Zero-shot and Supervised Audio Classification
在音频分类数据集上的Supervised和Zero-Shot表现如下:
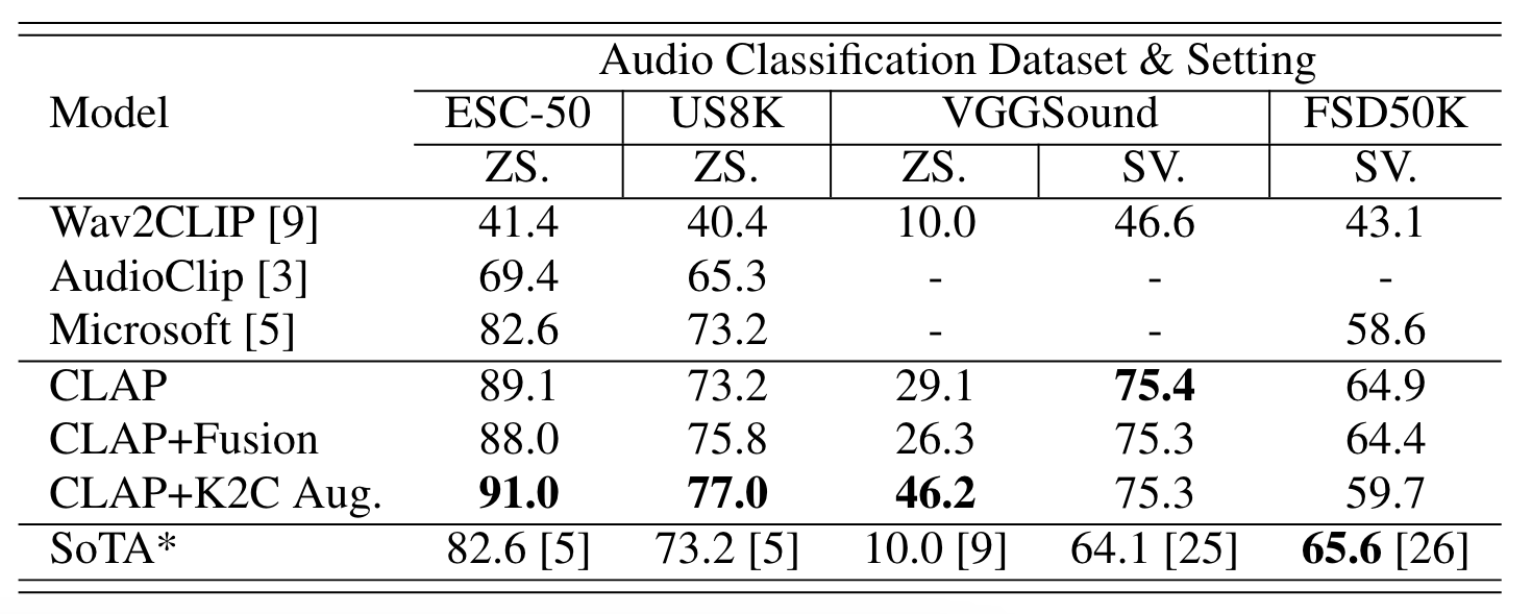
Fusion和K2C加在CLAP上都分别有提升, 而且ZS表现相较于之前的模型有很大提升.
Summary
CLAP作为音频模态的CLIP, 不光提供了一个非常好的Audio-Text Backbone, 也提供了一个大规模数据集LAION-Audio-630K. CLAP的存在使得后续一些下游任务和与多模态相关的音频任务获得了更多的可能.
另外, 同样的idea, LAION-CLAP和MS-CLAP做出来差别还是挺大的, 可能是因为大家在乎的点不太一样… 实验结果上显示MS-CLAP要弱于LAION-CLAP, 在其他Audio Research中LAION-CLAP也是用的更多些.

