本文前置知识:
- BERT(详见ELMo, GPT, BERT)
RoBERTa: A Robustly Optimized BERT Pretraining Approach
本文是论文RoBERTa: A Robustly Optimized BERT Pretraining Approach的阅读笔记和个人理解. RoBERTa已经被广泛的应用于各类由BERT衍生的模型参数初始化, 可以视为是完全体形态的BERT.
Basic Idea
作者在文章中指出, 训练是一个非常重要的过程, 但BERT在发布时并没有得到很好的训练, 导致其性能看起来比现在的自回归语言模型性能要略差(例如XLNet). 但实际上, 对BERT应用一些训练技巧对提升BERT性能影响是非常大的. 因此, 作者重新对BERT施加了一些训练技巧, 使得BERT的性能得到了进一步提升, 并且具有更强的鲁棒性.
RoBERTa
RoBERTa(Robustly optimized BERT approach). RoBERTa只是应用了更好的训练技巧, 因此整体结构是没有发生任何变化的. 如果对BERT的结构不熟悉, 建议回顾BERT的知识.
Dynamic Masking
作者总结出三种Mask的方法:
- 纯静态Mask: 就是BERT中使用的Mask, 在数据预处理阶段就进行, 每个Epoch所Mask同一句中的Token位置都是相同的.
- 改进一点的静态Mask: 将每个Sentence都重复N次, 这样可能在预处理阶段能得到N种不同的Mask. 因为扩大了每个Epoch的数据量, 训练的Epoch要是原来的1/N倍.
- 动态Mask: 每个Sentence给BERT之前动态Mask, 即生成一种新的Mask方式. 这样每个Epoch拿到的Mask基本上是不同的.
从Mask的方法上来看, 动态Mask并没有引入太多的计算花费, 但是却大大提升了训练时句子的多样性. 为了证明其有效性, 作者将上述三种Mask方式的性能将BERT(Base)在SQuAD上的F1 Score, MNLI - m和SST - 2上的ACC做了比较:
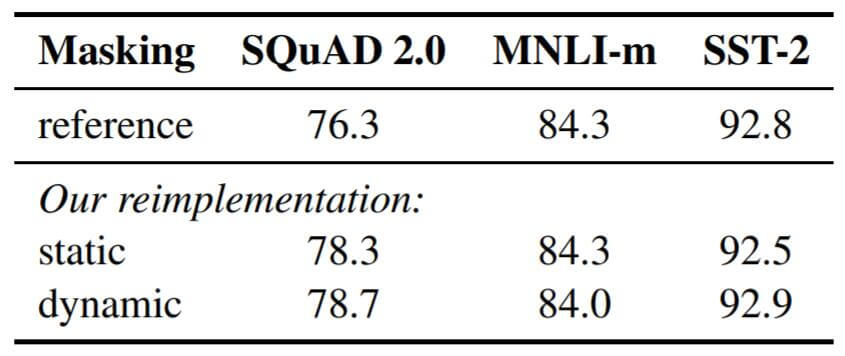
其中reference来自XLNet中给出的BERT(Base)数据. 每种方式都采用了5轮的随机初始化.
从中能看出, 改进后的静态Mask与原版Mask性能相仿, 动态Mask要比改进后的静态Mask稍好一点. 但动态Mask又不会引入太高的时间开销, 这样的增益还是很划算的.
Training without NSP
在BERT中, 训练时候采用了预测Mask和NSP两种训练任务. NSP(Next Sentence Prediction)任务是它随机的将两段连续或毫不相关的文档拼在一起, 然后用[CLS]位置的输出预测两段文字是否来自于统一文章(或者说连续不连续).
其实在早一点的多篇论文中指出, NSP任务虽然在BERT中被假设非常重要, 但实际上NSP任务会导致BERT的退化. 越来越多的人开始质疑NSP任务的必要性. 作者为了观察各种训练方式之间的差异, 设计了如下四种训练方式:
- Segment - Pair + NSP: 与训练BERT时的方案无异. 每次输入两段来自同一文档或多个文档的内容. 内容总长度必须少于512个Token.
- Sentence - Pair + NSP: 每次只输入两个来自同一文档或多个文档的句子. 每次输入的序列长度肯定小于512个Token, 所以用增大Batch Size的方式来让这种方式的总Token数与Segment - Pair + NSP总Token数相近.
- Full - Sentences: 全部输入可能来自于同一文档或多个文档的连续句子, 直到填满为止. 序列长度最多512个Token. 在切换不同文档时, 在之间加上特殊的分隔符. 不采用NSP任务.
- Doc - Sentences: 全部输入来自同一文档的句子, 即只从一篇文档中对连续句子采样, 如果文档的内容少于512个Token, 则动态增大Batch Size使得其与Full - Sentences总Token数量相近.
实验结果如下:
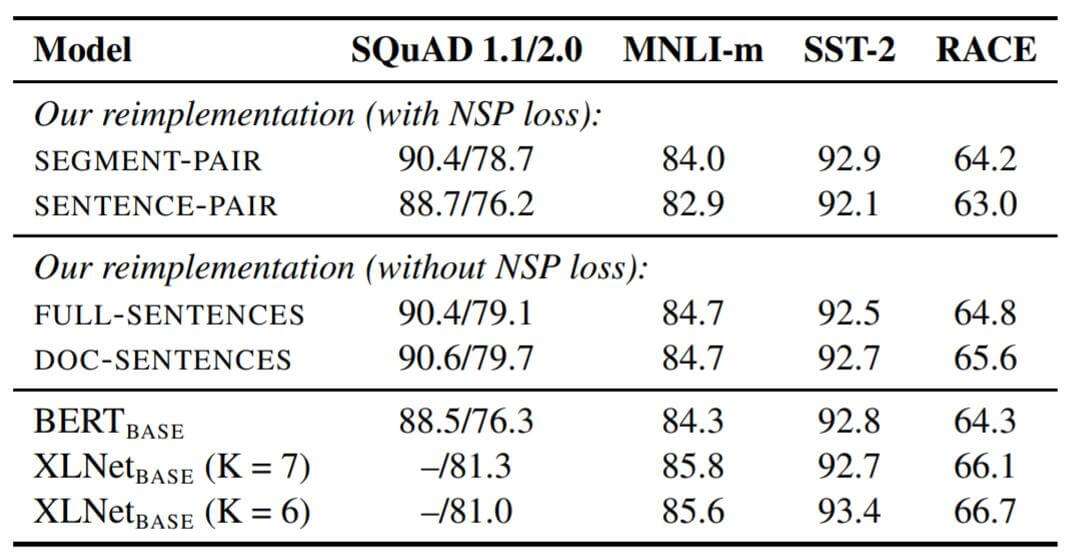
作者得出了以下结论:
- 观察方式1和方式2, 使用单个句子明显的损失了下游任务的性能. 可能模型并不能从句子中学习到长范围的依赖.
- 观察方式1和方式4, 即BERT的原始训练方式与不适用NSP的训练方式, 移除NSP能稍微增强下游任务的性能.
但是由于表现最好的Doc - Sentences需要动态调整Batch Size, 作者还是采用了Full - Sentences作为后文实验方式.
Bigger, bigger, and bigger
DataSet
XLNet用了126G的数据, 当时BERT训练只用了十几个G的数据, 所以对比是很不公平的. RoBERTa在数据上不能落后, 一口气用了160G的数据. 分别由以下部分组成:
| 数据集名称 | 大小(GB) | 说明 |
|---|---|---|
| BookCorpus | 16 | BERT训练时候用的数据 |
| CC - NEWS | 76 | 过滤后的新闻类数据 |
| OpenWebText | 38 | 根据网友点赞数从URL中提取的帖子文本 |
| Stories | 31 | 故事类数据 |
| 总计 | 161 |
更大量的数据对BERT提升是巨大的, 使之能够与XLNet相对公平的进行比较.
从辩证的角度来说, 更大量的数据也会使模型的偏见和歧视性更强. 在数据上的偏见消除是非常重要的, 目前来说没有太好的解决方案.
Batch Size
先前有大量实验表明, 适量增大Batch Size有益于模型的收敛, 更能使训练稳定, 并有助于提高模型的性能. 更大的Batch Size也能帮助快速训练. 作者做了增大Batch Size对性能影响的实验, 保证Batch Size和Step的积不变, 即维持相同的计算开销, 实验结果如下:
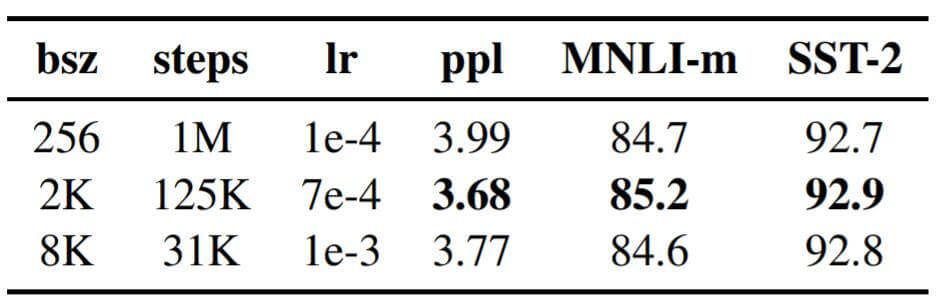
适量增大Batch Size确实有助于提高模型的性能, 但考虑到更大Batch Size在训练速度上带来的优势, 作者只采用了8K的Batch Size, 而非效果最好的2K Batch Size.
本小节叙述一些无关紧要的参数调整. 除去峰值Learning Rate, 和Warmup的次数, RoBERTa延续了BERT的原始参数. 考虑到RoBERTa采用了更大的Batch Size, 所以将Adam中的Beta2从0.999 换为了0.98.
RoBERTa不会随机的将短句注入, 并且前90%的训练中不会使用缩短的序列, 只使用全长序列.
RoBERTa还采用了BPE缩小词表, 进一步提升了性能.
Experiments
作者从增大数据量和增长训练时间两个角度做了实验:
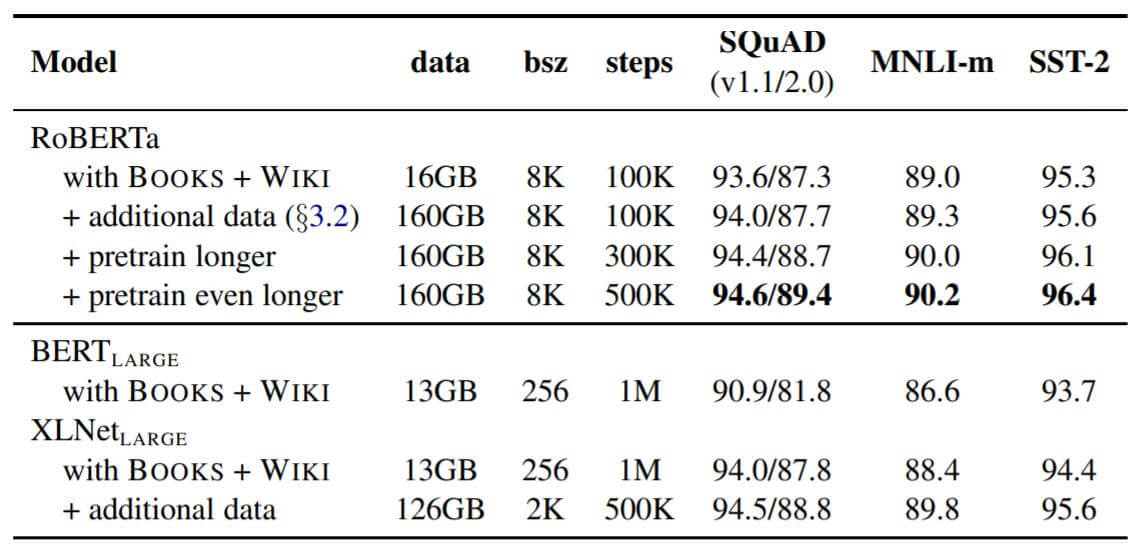
从逐步添加训练技巧的流程来看, RoBERTa在和BERT使用十几G数据的情况下提升非常大, 也和XLNet在用13G时的性能不分高下, 证明了RoBERTa改进的正确性. 逐渐增大训练数据量和训练时长(这里是通过Step调整), RoBERTa逐渐碾压了XLNet.
然后将RoBERta与GLUE排行榜中其他的模型也进行了实验:
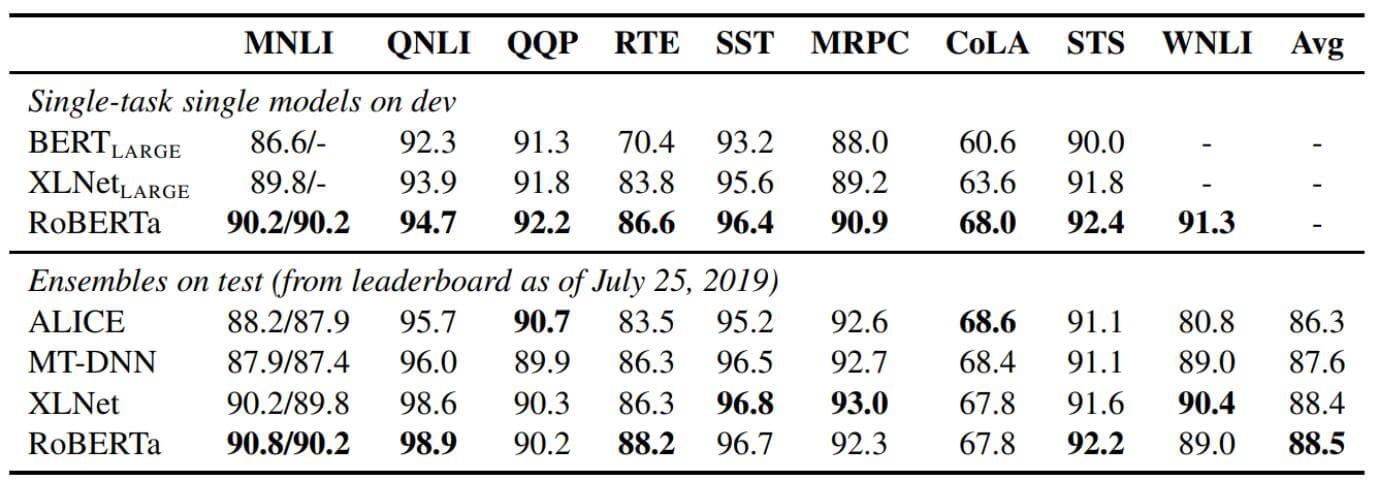
RoBERTa作者提到, 对于GLUE有两种Fine - Tune的方式:
- 单任务, 对每个GLUE任务分别进行Fine - Tune, 并且只用相应任务的训练数据.
- 多任务, 在测试集上进行比较. 但与排行榜上其他的模型不同, 其他模型对多任务进行Fine - Tune, RoBERTa只对单任务进行Fine - Tune.
从实验结果中来看, RoBERTa比没训练好的BERT提升相当的大.
Summary
作者实际上在RoBERTa中主要做了四件事:
- 用更大的Batch Size, 更多的Data, 更长的训练时间. 就是更大.
- 废除NSP的训练目标, 这个非常重要.
- 将静态Mask换为动态Mask.
- 用更长序列训练(不怎么重要).
严格意义上来说, RoBERTa才是BERT的完全体. 这提供给大家一个非常好的预训练基准, 而且在其他论文中也鼓励用RoBERTa而不是BERT进行比较, 因为BERT的训练是不够充分的.

