本文前置知识:
EVA-GAN: Enhanced Various Audio Generation via Scalable Generative Adversarial Networks
本文是论文EVA-GAN: Enhanced Various Audio Generation via Scalable Generative Adversarial Networks 的阅读笔记和个人理解. 论文来自冷月(NVIDIA), 同时也是Fish Audio的创始人.
EVA - GAN
EVA - GAN完成了GAN based Vocoder在数据, 模型规模上的Scaling, 它本质上是HiFi-GAN的进化版.
Loss Function
GAN - based Vocoder的目标是将梅尔频谱相同, 由GAN Loss, Mel Spectrum Loss, Feature Matching Loss三个部分组成.
GAN Loss (Adversarial Loss):
$$
\begin{aligned}
&L_{a d v}(G)=\mathbb{E}\left[(D(G(s))-1)^2\right] \\
&L_{a d v}(D)=\mathbb{E}\left[(D(x)-1)^2+(D(G(s)))^2\right]
\end{aligned}
$$
其中$x$ 为声波的Ground Truth, $s$ 为音频信号的梅尔谱, $D, G$ 分别为GAN的判别器和生成器.
Mel Spectrum Loss:
$$
L_{m e l}(G)=\mathbb{E}\left[\Vert\phi(x)-\phi(G(s))\Vert_1\right]
$$
其中$\phi(\cdot)$ 为得到梅尔谱的函数.
Feature Matching Loss:
$$
L_{f m}(G)=\mathbb{E}\left[\sum_{i=1}^T \frac{1}{N_i}\left\Vert D^i(x)-D^i(G(s))\right\Vert_1\right]
$$
$T$ 为Discriminator的总层数, $N_i$ 代表Discriminator的第$i$ 层.
Data Scaling
传统的Vocoder使用的数据是相对比较少的, 并且先前的数据质量也相对较差, 存在比如采样率只有24k, 缺乏多样性等诟病. 在BigVGAN中发现, 将数据规模进一步Scaling能取得相当大的提升, 所以作者在这优先考虑的就是Scaling Dataset.
为此, 作者从Youtube和网易云爬取了包括中文, 英语, 日语等多种语言且多种乐器的音乐共计1.6w小时, 构成数据集HiFi - 16000h.
此外, 为进一步增强语音表现, 作者从PlayerFM上收集了各类语言的音频共计2w小时, 构成数据集PlayerFM - 20000h.
在训练的时候, 除去歌声本身, Vocoder也被要求生成一些噪声或者其他物体的声音.
不过上述数据集需要在抱抱脸上获得许可才能访问数据集:
- fish-audio-private/hifi-16kh · Datasets at Hugging Face
- fish-audio-private/playerfm-20000h · Datasets at Hugging Face
Model Scaling
在TTS上, 与BigVGAN中的发现一致, 较大的模型在中等规模的数据集上也好于小模型. 所以作者将EVA - GAN从16.3M直接Scaling到174.4M.
Overview
从宏观角度来讲, EVA - GAN的Generator从模型角度做了两点改进:
- 引入了ConvNeXt中的一维卷积模块.
- 将HiFi - GAN中的Leaky ReLU替换成了SiLU.
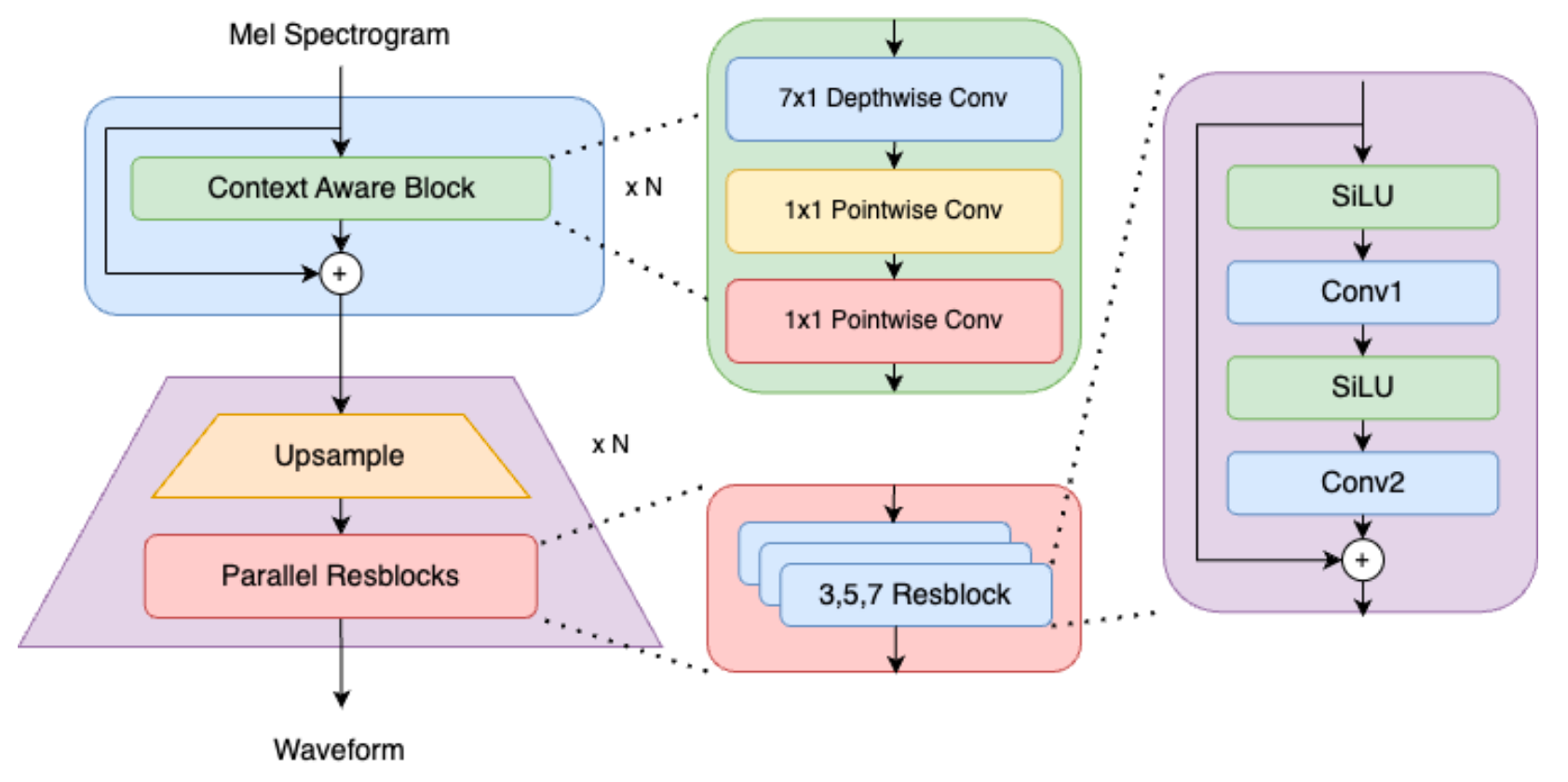
MPD沿用了HiFi - GAN中的MPD中的MRD.
Context Aware Module
由于在Scaling的时候会消耗大量的资源, 所以作者认为采用ConvNeXt 中的一维卷积的模块Context Aware Module(CAM)能够降低计算压力, 并在性能上取得显著的改进. 作者称其为”The Free Lunch”.
Renew Training Paradigm
在BigVGAN中在模型各方面的表现与计算效率之间做出了妥协, EVA - GAN在这方面做出改进, 让更大的模型成功训练.
- Larger Context Window: 从HiFi-GAN 和BigVGAN 的小窗口(32 / 64帧) 提高到256帧, 这可以取得更好的效果, 也当然带来了更高的计算资源消耗. 所以剩下几点基本上都针对消耗问题做出了优化.
- SiLU in - place activation: 作者发现Leaky ReLU对加速收敛没有帮助, 直接将Generator和Discriminator中的激活函数替换为原地操作的SiLU减少了30%的GPU显存消耗.
- Gradient Checkpoint: 256帧的上下文窗口就算在A100上也吃不消, 所以作者用了Gradient Checkpoint, 降低了30%的计算效率, 但将显存消耗从46G砍到了16G.
- TensorFloat32: 虽然混合精度在LLM上训练很常见, 但作者的设备遇到了fp16训练不稳定的情况(梯度范数很大), 且在bf16上表现不佳. 由于A100支持TensorFloat32(tf32), 作者使用TensorFloat32进行训练.
- Loss Balancer: 在训练的时候由于有多项Loss的混合, 所以如何平衡它们成为了一个问题. 参考前人的工作, 作者引入了Encodec中的Balancer来解决Loss的平衡问题.
- Human-In-The-Loop Artifact Measurement: 作者团队开发了一个Human-In-The-Loop Artifact Measurement toolkit, 其中包含对SMOS的标注工具和CLI, 用于持续监控和评估生成音频的质量, 以确保符合人类感知.
Experiments
详细的模型参数设置和实验设置请参考原论文. 应该本身是实验记录性质的缘故, 原文写的比较乱, 这里我也写的简单一些.
Evaluation Metrics
作者采用了如下几种Metrics:
- Multi - resolution STFT (M-STFT): 用于测量多种分辨率下的频谱距离.
- Periodicity error & Voiced / Unvoiced classification: GAN - based Vocoder中普遍存在浊音 / 清音分类上普遍存在可听错误时, 音频质量会比较低. 该指标能够衡量这种错误出现的频率, 从而提供一个判断音频质量的角度.
- Perceptual evaluation of speech quality (PESQ): 广泛使用的语音质量的自动评估标准.
- Similarity Mean Opinion Score (SMOS): 用于衡量合成语音与目标说话人之间的音色相似度.
LibriTTS
在LibriTTS上, EVA - GAN表现如下:
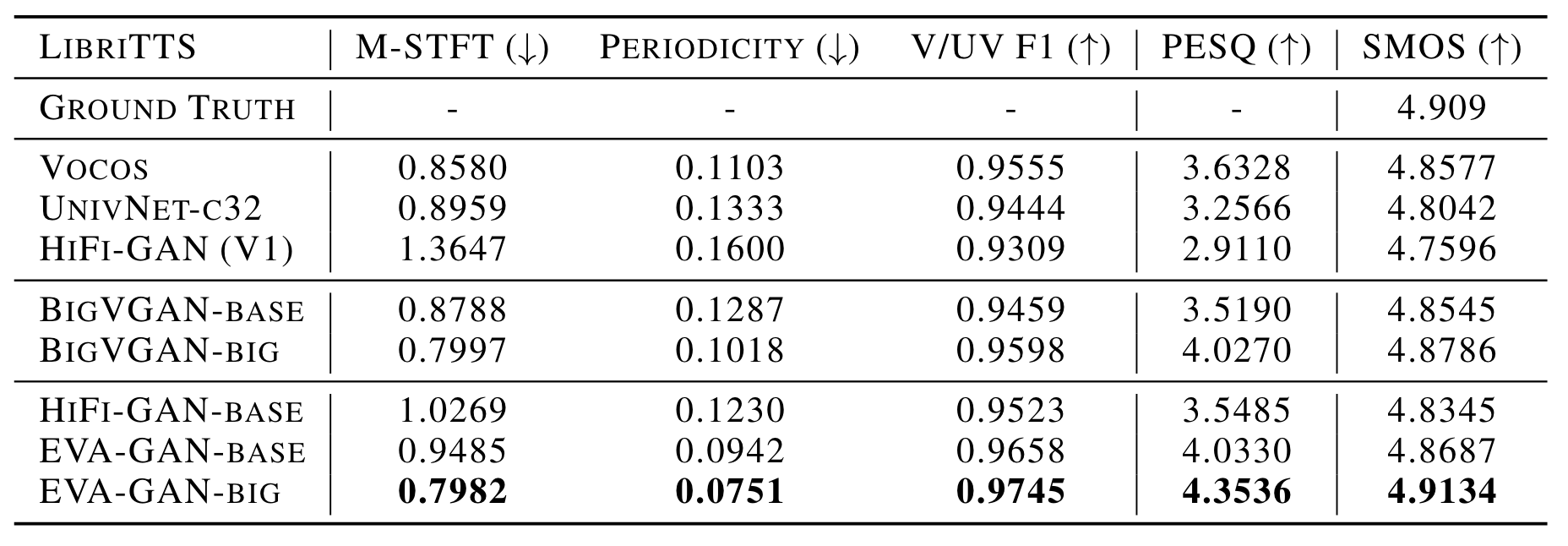
与相对小的模型HiFi - GAN相比, EVA - GAN取得了显著优势.
与同等规模的BigVGAN相比, EVA - GAN也能有更亮眼的表现.
DSD - 100
作者从DSD - 100随机选择了五类中的10个Track的5秒音频做了合成测试, 各类片段的SMOS结果如下:
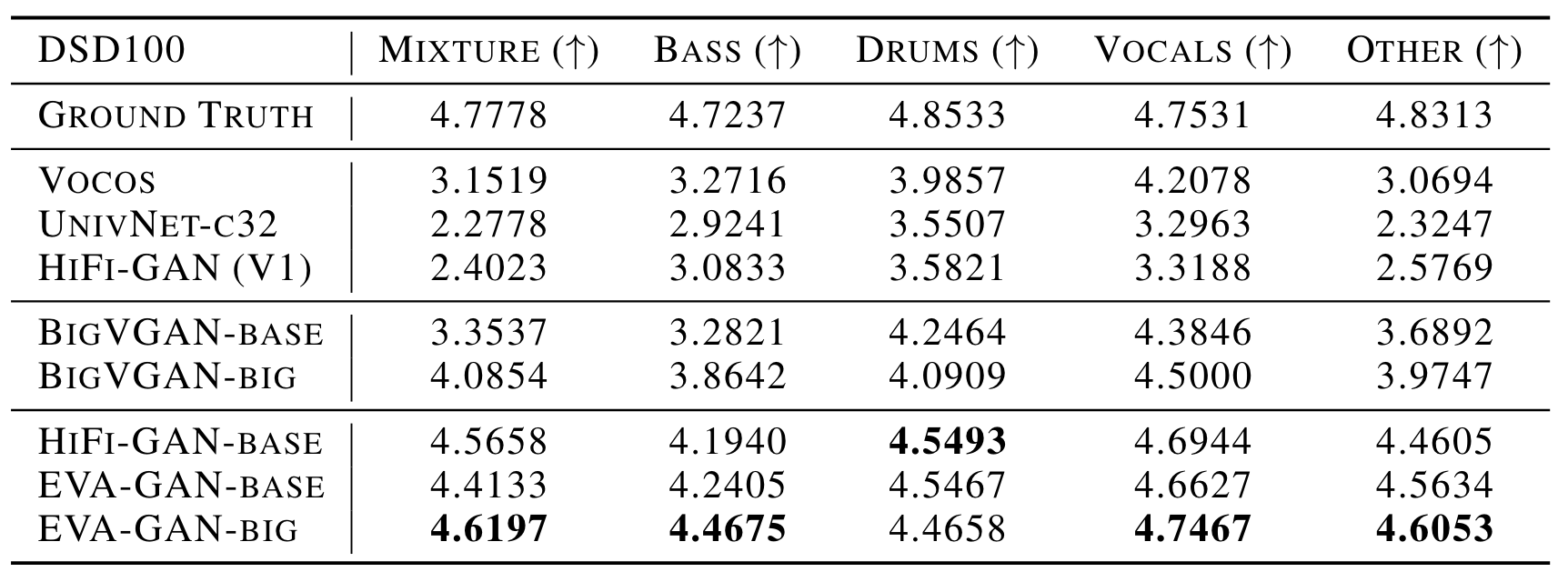
Scaling确实有效果. 不过不知道为什么EVA - GAN的big版本在鼓音频上的合成效果比较差.
Ablation Studies
作者将各类消融实验结果分散在各个表中了, 直接说结论:
- 更先进的训练方法和更大的数据集效果更好.
- CAM在EVA - GAN中表现还不错.
- 固定数据量不变, 单纯增大模型, 可以带来更好的效果.
HiFi - GAN和EVA - GAN各规模的对比:

EVA - GAN的big版本比base要大很多, 但推理时间只增长了一倍, 换来了不错的性能提升.
Spectrogram Visualizations
作者将各类GAN - based Vocoder在歌声合成场景下横向对比, 重新对比波形转换成的[梅尔频谱](../Basic Knowledge/Audio Concept.md#梅尔频谱):
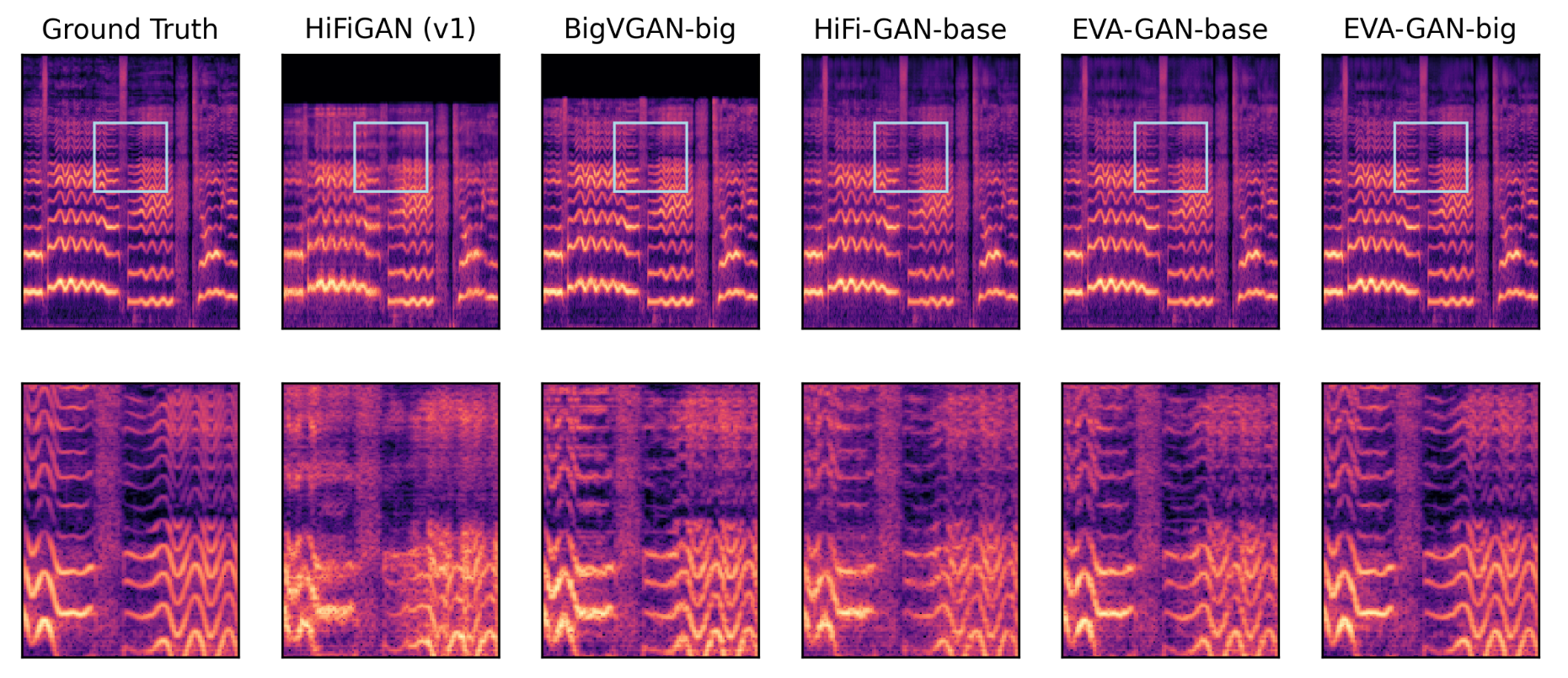
从梅尔谱结果上可以看到, HiFi - GAN生成的谱子波形分辨率很低, EVA - GAN提高了生成的质量. 尤其是在高频区域, 包括EVA - GAN - base在内, 表现都不是很好, EVA - GAN - big才能有比较清晰的建模.
Summary
EVA - GAN是一个在模型规模和数据规模都Scaling过后的HiFi - GAN, 在实验设计上参考了很多BigVGAN的东西. 还是能从这篇报告中找到很多和Vocoder的相关文献的. EVA - GAN的增强版本Firefly - GAN也被用在了Fish-Speech中.
从实验结果来看, 高频信息在Scaling(主要是数据更充足)后确实能够得到更充分的建模, 且差距也比较明显. 高频本身也是网络较难学到的信息.
在Model Scaling的同时也并没有特别的增加推理时长, 感觉还是算相对友好. 毕竟推理时长变长了一倍, 但Vocoder参数可不止涨了一倍, 可能要归功于CAM.
要是数据集能进一步公开就更好了.

