Knowledge Graph Embedding Based Question Answering
本文是论文Knowledge Graph Embedding Based Question Answering的阅读笔记和个人理解.
Basic Idea
作者发现KBQA中的三个挑战问题:
- 谓词(关系)有多种自然语言的表示法.
- 实体也会有严重的模糊性而产生大量候选答案, 即实体的歧义问题.
- 用户的问题领域可能是开放的, KG也有可能是不完整的, 这对鲁棒性有一定的要求.
Knowledge Embedding可以将实体映射为低维向量, KG中的关系信息会被保存, 各种KRL会非常有益于下游任务. 因此, 作者希望提出一种基于KGE方法, 并能够回答所有自然语言问题的框架.
KGE能够保证得到的单词表示的质量, 因为每个嵌入表示都是与整个KG交互的结果, 并且它也能保持相似的关系或实体之间的表示相似性.
在本文中, 作者只关注了最简单的QA, 直接使用一个三元组就能描述整个问题, 而非多跳推理的问题.
KEQA
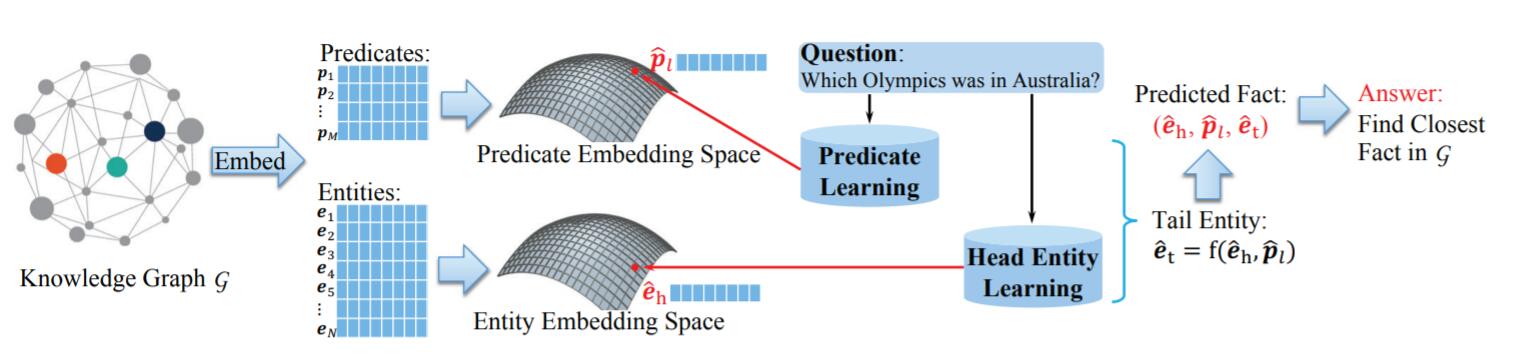
KEQA的大致思路是通过某种结构, 对自然语言中的整个句子抽取出与Knowledge Embedding相似的表示, 即希望用句子抽取后的表示空间等价于Knowledge Embedding的空间.
Predicate and Head Entity Learning Models
Knowledge Graph Embedding
对于头实体$\mathbf{e}_h$, 谓词(关系)$\mathbf{p}_\ell$, KGE方法能通过打分函数$f(\mathbf{e}_t, \mathbf{p}_\ell)$得出对应的尾实体$\mathbf{e}_t$, 即$\mathbf{e}_t \approx f(\mathbf{e}_h, \mathbf{p}_\ell)$. 通过KGE, 我们能获得一个KG中的实体嵌入表示集$\mathbf{E}$ 和谓词嵌入表示集$\mathbf{P}$.
当KGE训练完成时, 实体和关系的表示将会固定下来, 这样才能保存住KG的信息. 若继续在后续训练时更新Embedding, 将会对原有信息扰动. 所以KGE只是做了空间指示作用.
Neural Network Based Predicate Representation Learning
有了KGE中获取的$\mathbf{P}, \mathbf{E}$, 接着需要将自然语言中的谓词表示(在三元组中也是关系)与KGE空间相对齐, 作者在这里采用了比较简单的双向LSTM + Attention:
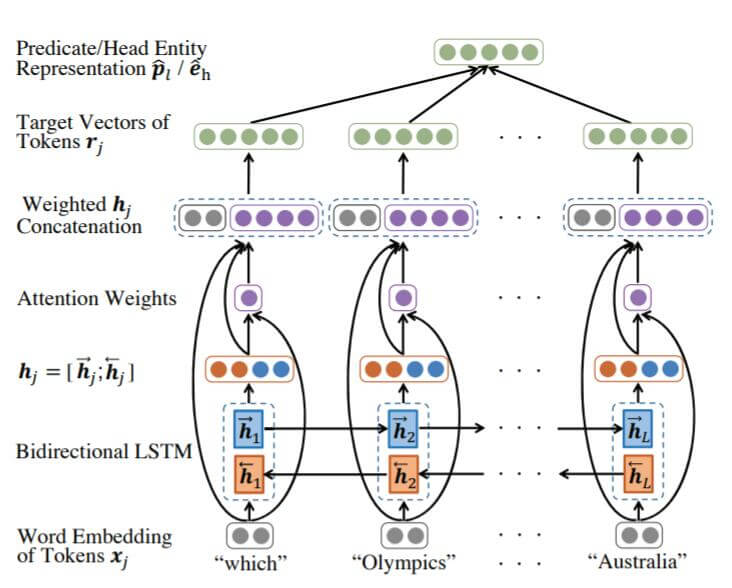
其实在作者发布的代码中, 用的是GRU, 不过都大差不差了.
图中在绿色向量$\mathbf{r}_j$ 和拼接后的向量$\mathbf{h}_j$ 之间还有一个FC层没画出来.
先将自然语言的Token转换为Embedding(图中灰色), 记为$\mathbf{x}_j$, 然后再用双向LSTM获取双向表示$\mathbf{h}_j$ (图中红色蓝色).
下述数学表达都是LSTM, 左右双向同理, 下面只是单向:
$$
\begin{array}{l}
\mathrm{f}_{j}=\sigma\left(\mathbf{W}_{x f} \mathbf{x}_{j}+\mathbf{W}_{h f} \overleftarrow{\mathbf{h}}_{j+1}+\mathbf{b}_{f}\right) \\
\mathbf{i}_{j}=\sigma\left(\mathbf{W}_{x i} \mathbf{x}_{j}+\mathbf{W}_{h i} \overleftarrow{\mathbf{h}}_{j+1}+\mathbf{b}_{i}\right) \\
\mathbf{o}_{j}=\sigma\left(\mathbf{W}_{x o} \mathbf{x}_{j}+\mathbf{W}_{h o} \overleftarrow{\mathbf{h}}_{j+1}+\mathbf{b}_{o}\right) \\
\mathbf{c}_{j}=\mathbf{f}_{j} \circ \mathbf{c}_{j+1}+\mathbf{i}_{j} \tanh \left(\mathbf{W}_{x c} \mathbf{x}_{j}+\mathbf{W}_{h c} \overleftarrow{\mathbf{h}}_{j+1}+\mathbf{b}_{c}\right) \\
\overleftarrow{\mathbf{h}}_{j}=\mathbf{o}_{j} \circ \tanh \left(\mathbf{c}_{j}\right)
\end{array}
$$
将最初的$\mathbf{x}_j$ 和双向LSTM抽取得到的$\mathbf{h}_j$ 拼到一起, 计算Attention Score $q_j$ 和注意力权重$\alpha_j$ (图中紫色):
$$
\begin{aligned}
\alpha_{j} &=\frac{\exp \left(q_{j}\right)}{\sum_{i=1}^{L} \exp \left(q_{i}\right)} \\
q_{j} &=\tanh \left(\mathbf{w}^{\top}\left[\mathbf{x}_{j} ; \mathbf{h}_{j}\right]+b_{q}\right)
\end{aligned}
$$
将注意力权重与$\mathbf{h}_j$ 加权, 与$\mathbf{x}_j$ 拼接得到隐态$\mathbf{s}_j=[\mathbf{x}_j;\alpha_j\mathbf{h}_j]$. 之后再经过一个FC层得到最终的结果$\mathbf{r}_j$.
然后对求得的每个Token的最终表示$\mathbf{r}_j$ (图中绿色) 求个平均, 得到与KGE中谓词表示$\mathbf{p}_{\ell}$ 相似的表示$\hat{\mathbf{p}}_{\ell}$:
$$
\hat{\mathbf{p}}_{\ell}=\frac{1}{L} \sum_{j=1}^{L} \mathbf{r}_{j}^{\top}
$$
其中$L$ 是问题的句子长度.
Neural Network based Head Entity Learning Model
对于一个自然语言问题, 作者用类似获取谓词表示的方法获取头实体表示$\hat{\mathbf{e}}_{h}$, 用同样的架构获取头实体的表示, 也与KGE空间相对齐.
这样直接把NER这步给省略掉了, 规避了自然语言中实体表示的模糊性问题.
Head Entity Detection Model
因为自然语言问题中的候选实体可能过多, 所以需要一个头实体检测模型来减少问题中的候选实体, 从一个句子中选择一个或几个连续的Token作为实体名称.
同样是使用双向LSTM去处理整个句子:
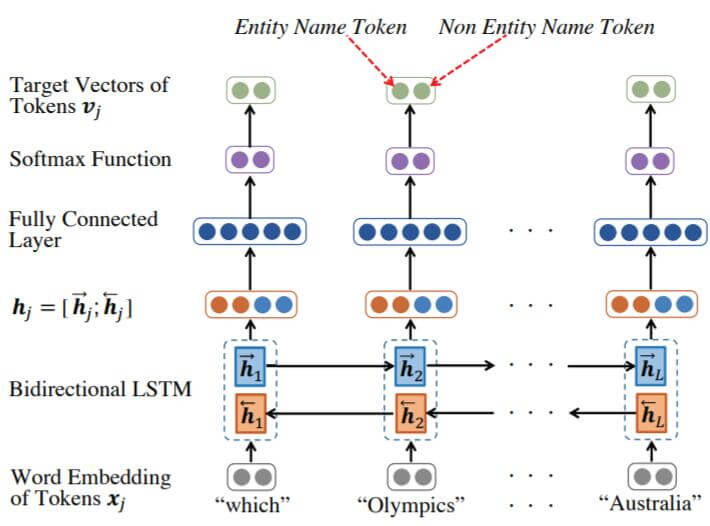
先获取词嵌入$\mathbf{x}_j$, 再使用双向LSTM获得$\mathbf{h}_j$, 后接一个FC层和Softmax, 能获得两个概率, 分别是该Token属于实体名的概率$\text{HED}_{\text{entity}}$, 和Token不属于实体名的概率$\text{HED}_\text{non}$.
这样, 相连的HED可能是同一个实体, 而不相连的HED可能是多个实体名. 在获取完实体名后, 再从KG中找到对应的候选实体集, 很大程度上缩小了与KG中实体匹配的范围.
Joint Search on Embedding Spaces
如果只是想简单的缩小模型与KGE空间中的距离, 只需计算模型抽取出的表示与KGE空间中表示的范数. 但这显然没有考虑过KGE中保留的关系信息.
基于前面的谓词学习模型, 实体学习模型, 头实体检测模型, 作者提出了对三种模型的联合距离度量:
$$
\begin{aligned}
\underset{(h, \ell, t) \in C} {\operatorname{minimize}} \quad\lVert\mathbf{p}_{\ell}-\hat{\mathbf{p}}_{\ell}\rVert_{2}+\beta_{1}\lVert\mathbf{e}_{h}-\hat{\mathbf{e}}_{h}\rVert_{2}+\beta_{2}\lVert f\left(\mathbf{e}_{h}, \mathbf{p}_{\ell}\right)-\hat{\mathbf{e}}_{t}\rVert_{2}
\\\ -\beta_{3} \operatorname{sim}\left[n(h), \mathrm{HED}_{\text {entity}}\right]-\beta_{4} \operatorname{sim}\left[n(\ell), \mathrm{HED}_{\text {non}}\right]
\end{aligned}
$$
其中, $\beta_1,\beta_2,\beta_3,\beta_4$ 是预定义的超参, 即损失中四项的权重, 用来衡量所对应的影响力. $n(\cdot)$ 代表取实体或谓词的具体名的操作.
第一, 二项均用于缩小模型抽取出的头实体和谓词表示与KGE空间中相应表示的距离, 第三项用于缩小尾实体表示与KGE中相应实体表示的距离. 第四项和第五项针对头实体检测模型, $\operatorname{sim}[\cdot;\cdot]$ 是度量两个字符串之间相似性的函数, 在这里最大化标出的头实体和目标实体之间的相似度, 以及句子的非实体部分和真实谓词之间的相似度.
KEQA的框架执行流程如下:

大致流程是:
- 分别训练谓词学习模型, 实体学习模型, 头实体检测模型. 训练谓词和实体表示模型时最小化模型结果与KGE相应表示的距离. 训练头实体检测模型时采用极大似然.
- 训练结束后, 面对每个问题, 分别用谓词学习模型和实体学习模型抽取出问题的谓词表示$\hat{\mathbf{p}}_\ell$ 和头实体表示$\hat{\mathbf{e}}_h$.
- 使用头实体检测模型检测出问题中出现的头实体$\text{HED}_{\text{entity}}$.
- 在KG中找到与检测出的头实体所匹配的候选集$\mathcal{C}$, 然后用KGE的打分函数$f(\cdot)$, 将$\hat{\mathbf{p}}_\ell$ 和$\hat{\mathbf{e}}_h$ 预测出相应的尾实体.
- 根据预测出的尾实体, 计算出与当前三元组联合距离最小的三元组, 作为答案返回.
头实体检测模型训练时采用的损失与联合距离度量略有不同, 训练时采用的是极大似然, 但在计算联合距离时采用的是字符串相似度.
KEQA对不同的损失项的优化实际上是分步运行的, 并且不同损失项针对的是不同模型.
Experiments
实验部分详细的参数请参照原论文.
Datasets
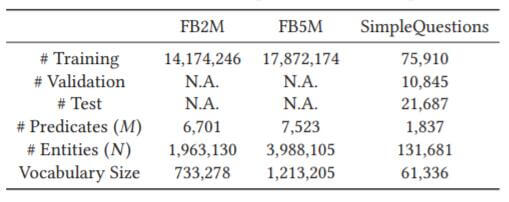
因为本文探讨的是简单问题的回答, 作者除了采用FB2M, FB5M外, 还使用了从FB2M中的子集数据集SimpleQuestions, 统计信息如下:
Effectiveness of KEQA
KEQA在FB2M, FB5M上的实验结果如下:
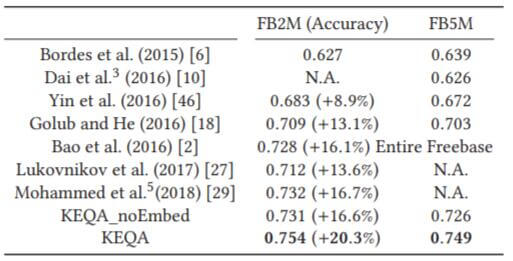
其中, KEQA_noEmbed是随机得到的Embedding, 没有经过KGE训练.
相较于提出的Baseline, 提升比较大. 在引入Knowledge Embedding后, 模型性能有了进一步的提升, 但其实在没引入KGE模型的情况下, 本身的效果也还可以, 因为它仍然超过了其他的Baseline.
Generalizability and Robustness Evaluation
为检测KEQA的鲁棒性, 作者从两个角度做了实验:
- 对KEQA使用不同的KGE方法.
- 对所有的谓词划分为三个组, 然后将训练集, 验证集, 测试集的问题按照谓词划分为三组. 这样测试集中出现的谓词肯定没有在训练集和验证集中出现过, 三类数据的谓词都是相互独立的. 按照该方法将SimpleQuestions改进为SimpleQ_Missing.
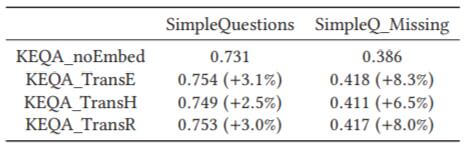
不同的KGE方法对结果其实没有太大的影响. 最简单的TransE就能有不错的结果. 对于新的数据集, 在TransE的帮助下仍然有40%左右的精度, 比不依赖KGE方法要高一些.
Parameter Analysis
为了探究联合距离度量中每项的贡献程度, 作者分别采用三种设置:
- Only_Keep: 仅保留五项中的该度量.
- Remove: 从五项中删除该项度量.
- Accumulate: 逐项添加度量.
实验结果如下:
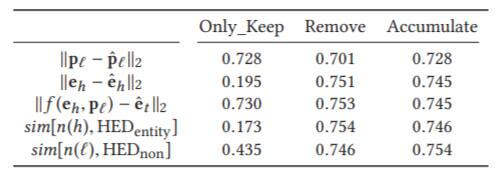
仅保留实体相关项的精度都非常低, 而仅保留谓词项的精度都比较高, 这也侧面说明了关系在KGE中发挥的重要作用, 实际上就是在针对关系学习.
在第一二项均保留的情况下, 结合谓词信息, 实体信息能够得到充分的利用.
第五项仍然使得模型性能涨了一个点, 说明问题中的某些Token可能和谓词共享信息.
我认为第三项和第一二项可能是近似等价的, 而不是互为补充的.
因为第三项的引入并没有使得模型性能提升产生多大的变化, 但仅保留时仍然发挥了相当重要的作用, 而且在删除第三项时也没有对性能产生太大的影响.
即仅保留第三项时没有第一二项, 性能好. 删除第三项, 剩下其余四项, 性能没有明显变化. 在已经有第一二项的情况下, 加上第三项, 几乎无提升.
Summary
KEQA是一种基于Knowledge Embedding的问答框架, 能从繁杂的自然语言中直接抽取出谓词表示和实体表示, 缓解了自然语言的模糊性和歧义性问题. 并通过头实体检测模型过滤掉非常多的候选实体三元组, 缩小搜索范围. 同时, 作者充分结合了KGE能够保存关系信息的特性, 提出了联合距离度量.
除此外, 我个人认为联合度量中第三项的必要性是有待商榷的.
BERT具有类似KGE获取表示的能力, 在依托KGE方法的KEQA的框架下, 结合一些上下文相关的KGE方法可能会有奇效, 例如CoKE, CoLAKE, 因为它们与KEQA类似能够利用自然语言信息的能力, 而不单单是利用知识本身.
本文只关注于最基本的单跳简单问题, 该如何扩展到多跳复杂问题?

