CoLAKE: Contextualized Language and Knowledge Embedding
本文前置知识:
- BERT
- Self - Attention
2020.11.11: 想通了CoLAKE在训练时最关键的部分.
2020.11.22: 在读完KEPLER后, 重温一遍CoLAKE, 更新实验部分.
本文是论文CoLAKE: Contextualized Language and Knowledge Embedding的阅读笔记和个人理解. 这篇论文的很多工作与KEPLER相似, 建议先阅读我对KEPLER的讲解, 再来看CoLAKE.
Basic Idea
这两年关于KGE的PTM很火爆, 论文开头便指出了现在将知识注入的PTM的劣势, 这些现存的嵌入一般都是空洞的, 静态的, 不灵活的. 这些PTM都有一些共同的短板:
- 实体嵌入是单独训练的, 然后再使用到PTM中, 导致知识嵌入和语言嵌入不是同时嵌入的, 即没有真正做到联合嵌入.
- 在做实体嵌入时, 很少能全部的捕捉到丰富的上下文信息, 导致模型的性能被预训练的实体嵌入所限制.
- 预训练的实体嵌入是静态的, 当知识图谱发生轻微变化时(例如添加一个新的实体), 需要重新训练.
基于上述缺点, 作者提出了CoLAKE, 这是一种能够根据上下文, 实现语言和知识的联合嵌入的Masked Language Model.
CoLAKE
CoLAKE(Contextualized Language and Knowledge Embedding), CoLAKE能根据知识上下文和语言上下文来动态的表示实体. 对于每个实体, 将该实体与知识相关联的部分作为子图, 视为该实体的上下文. CoLAKE能动态访问不同的常识, 根据背景知识来更好的帮助模型理解实体在上下文中的含义, 而并非只关注实体本身.
题外话:
其实我第一次听CoLAKE这个名字是在前两天举办的YSSNLP上, 邱锡鹏老师在预训练模型的演讲里提的. 我当时感觉哈利波特那个图(下面第一张图就是)好像在哪见过, 后来确实在邱老师9月份演讲的PDF里找到了, 只不过没标模型的名字而已.
当时还有听众提出了一个问题: 外部知识应该如何引入影响来语义的呢?
邱老师虽然没给出具体的方案, 但指出了大致的一条思路: Token的表示可能会根据外部知识的影响或变化, 从而改变它的表示, 这样能获得更精确的语义表示.
读完这篇10月份发的论文才明白, 其实邱老师说的是CoLAKE.
Word - Knowledge Graph
WK Graph(Word - Knowledge Graph)是为了处理异构的语言和知识图谱而引入的, 这种结构能将它们统一在同一个数据结构下. 知识在知识图谱中的存储方式是三元组, 而语言的存储方式一般是无结构化的文本数据. Transformer的自注意力机制可以看做是基于单词的全连接图, 所以图是表示知识和语言更通用的结构.
WK Graph Example
下面来举一个例子体会WK Graph的作用, 在本节先关注这张图片的左侧:
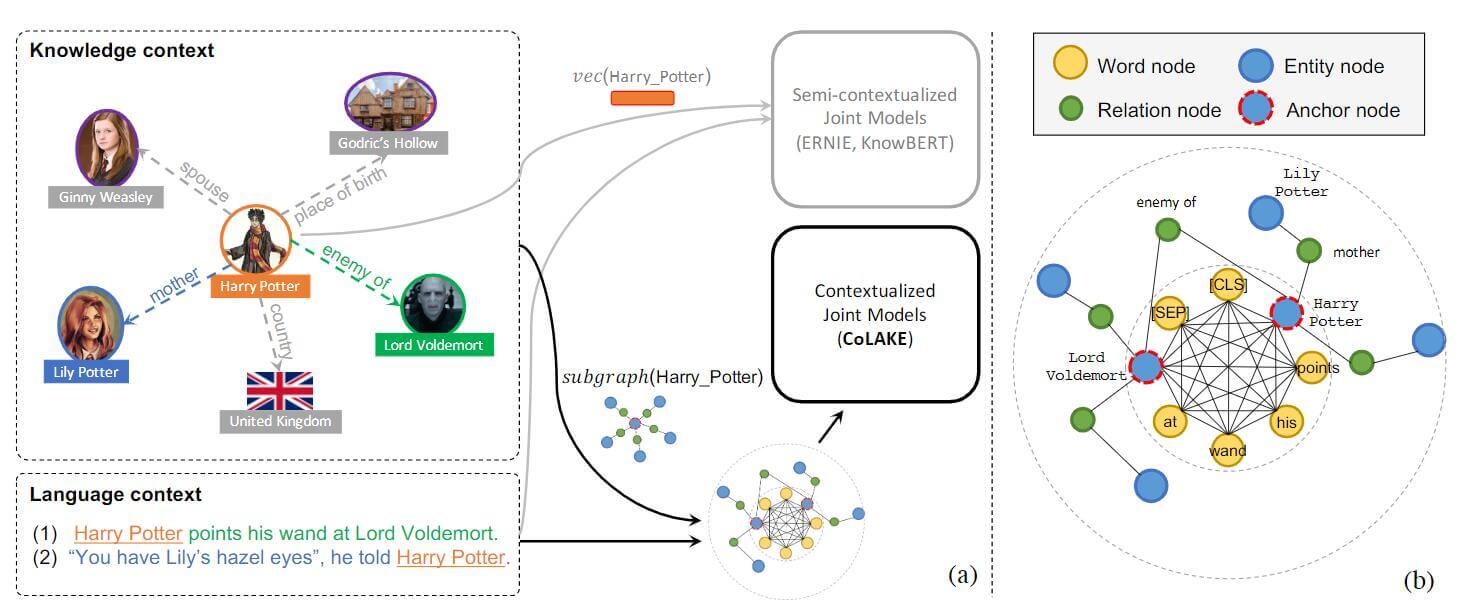
像ERNIE, KnowBERT之类的模型的实体嵌入和语言嵌入是半上下文联合的, 而CoLAKE是全上下文联合嵌入. 那么模型在CoLAKE中如何理解下面这两个句子呢?
- Harry Potter points his wnad at Lord Voldemort.
- “You have Lily’s hazel eyes”, he told Harry Potter.
CoLAKE能在KG中搜索Harry Potter相关的知识, 得到(Harry Potter, enemy of, Lord Voldemort)和(Harry Potter, mother, Lily Poter)这两个三元组在图中的表示. 然后用前者来帮助理解句子1, 后者帮助理解句子2. 这样就使得知识能够在不同的上下文中更灵活的运用.
右侧说明了Word - Knowledge Graph的结构. 内圈是原文中多个单词全连接形成的Word Graph, 而外圈是经过知识扩展过的Knowledge Subgraph. 二者以相同的实体为桥接处, 将Word Graph和Knowledge Subraph拼接就形成了Word - Knowledge Graph.
Graph Construction
本节主要说明WK Graph是如何生成的.
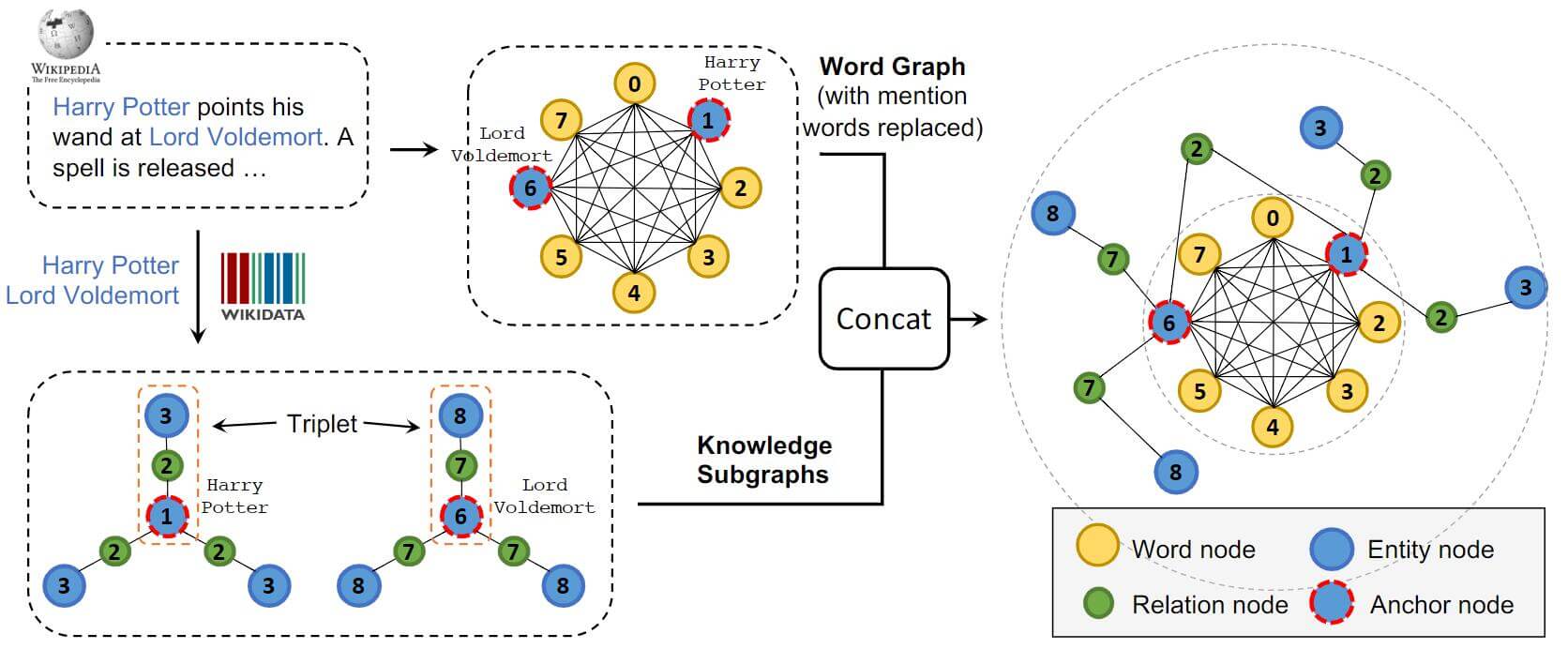
生成图的方式其实没有想象中的复杂. 我们先通过实体连接器将KG中能被找到的实体作为锚点(Anchor Nodes), 然后将基于KG延伸出的Subgraph在这个锚点的基础上进行扩展. 锚点在图中用红色的虚线外轮廓标识. 延伸的过程有利于将Knowledge Subgraph和Word Graph的实体嵌入进同一个空间, 这也就是一直在强调的联合嵌入.
在Word Graph中有三种类型的节点, 分别是Word Nodes, Entity Nodes, Relation Nodes, 也就分别对应着图中黄色, 蓝色, 绿色的节点.
注意观察图中的节点编号, 在锚点的Knowledge Subgraph中, 锚点连接的实体和关系节点的编号是依赖于锚点的, 这种方式也称为Soft - Position Index, 在之后还会提到.
CoLAKE只使用了与锚点相邻的15个随机关系和实体作为Subgraph, 然后并入WK Graph中.
CoLAKE Architecture
CoLAKE的整个结构基于BERT. 所以使用的Basic Blcok是Transformer Encoder. 如果对BERT不了解的建议参考我以前写的<ELMo, GPT, BERT>, 对Transformer不理解的请参照<Transformer精讲>, 看完后理解起来会好一些.
话不多说, 直接看结构图:
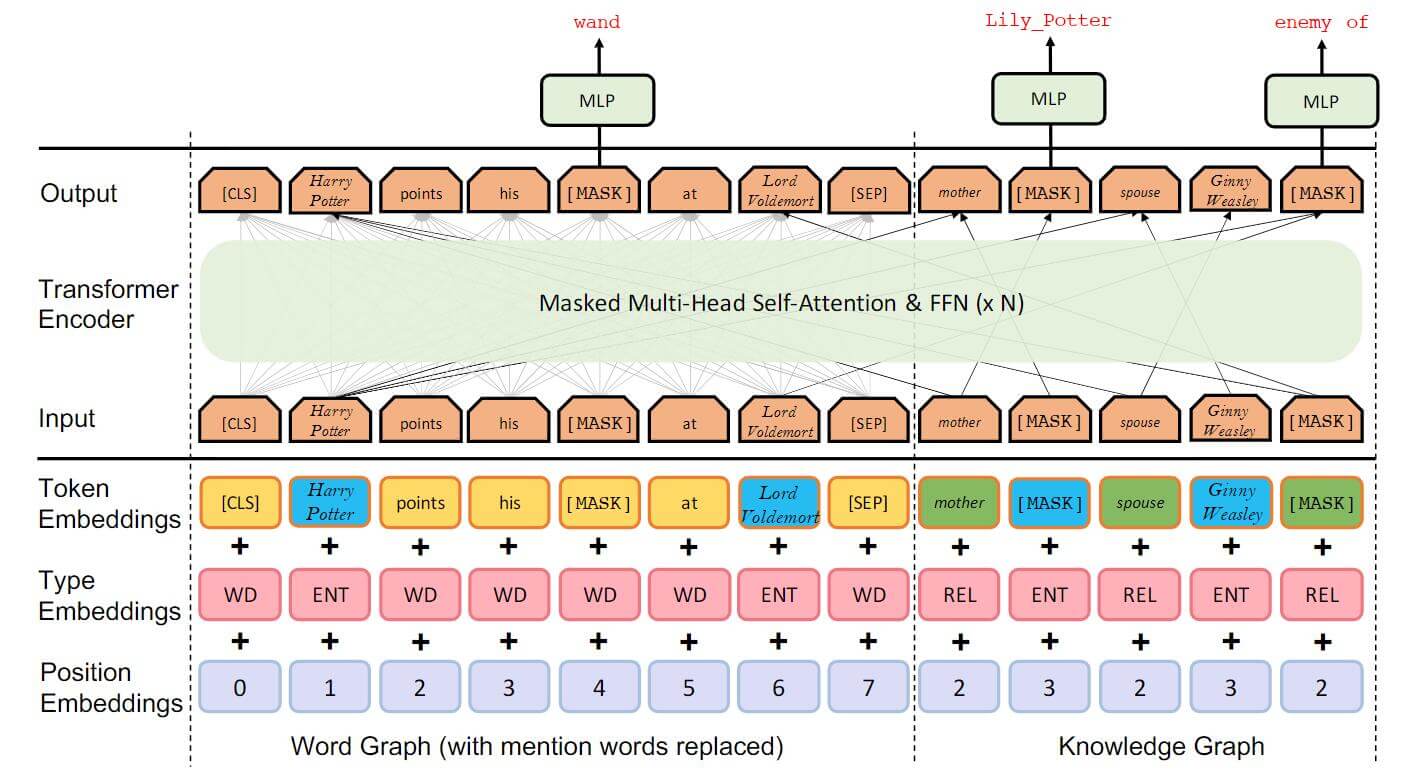
请观察CoLAKE与BERT的不同点. 并且这幅图画的非常严谨, 在右侧的Knowledge Graph并不是全连接的, 左侧的Word Graph是全连接的, Token Embedding的颜色与之前Word Graph颜色也是相对应的.
Embedding Layer
CoLAKE对BERT的Embedding做了改动. 在BERT中采用的Encoding是Token Encoding, Segment Encoding, Position Encoding. 而CoLAKE中使用的是Token Encoding, Type Encoding, Position Encoding.
Token Embedding
对于Token的Embedding不必多说, CoLAKE与BERT都还是使用查表的方式, 但CoLAKE是单词, 实体, 关系分别查找:
- 对于单词的Embedding, CoLAKE使用了BPE, 能减小词表, 这已经是一种常见的Subword技巧.
- 对于实体和关系, 我们分别建两张表, 直接学习实体和关系的独立表示.
Type Encoding
CoLAKE不涉及到Segment的问题, 所以将Segment Encoding替换成了Type Encoding. 在Word Graph中有三种类型的节点, 分别是Word Nodes, Entity Nodes, Relation Nodes. 所以要对这三种类型分别加以编码.
Position Encoding
与BERT相比, CoLAKE多了Knowledge Subgraph, 所以使用了Soft - Position Index的方式对Knowledge Subgraph中的节点进行位置编码.
Soft - Position Index: 允许重复的Position出现, 将以锚点作为头实体的三元组记为$<h, r, t>$, 若锚点头实体在句子中的位置为$x$, 则关系$r$ 位置记为$x+1$, 尾实体位置记为$x+2$. 这样能够保证三元组的位置连续.
Masked Transformer Encoder
对于图中的节点矩阵$\mathbf{X}$ , 附加Mask的注意力机制如下:
$$
\begin{aligned}
\mathbf{Q}, \mathbf{K}, \mathbf{V} &=\mathbf{X} \mathbf{W}^{Q}, \mathbf{X} \mathbf{W}^{K}, \mathbf{X} \mathbf{W}^{V} \\
\mathbf{A} &=\frac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d_{k}}} \\
\operatorname{Attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) &=\operatorname{Softmax}(\mathbf{A}+\mathbf{M}) \mathbf{V}
\end{aligned}
$$
Mask矩阵$\mathbf{M}$ 可以通过以下方式求得:
$$
\mathbf{M}_{i j}=\left\{\begin{array}{ll}
\quad 0 & \text { if } x_{i} \text { and } x_{j} \text { are connected } \\
-\inf & \text { if } x_{i} \text { and } x_{j} \text { are disconnected}
\end{array}\right.
$$
认真看一下, 这个Mask的作用可不是Transformer Decoder中的Mask, 它是取决于节点矩阵的, 只是为了能让节点只能看到邻近一跳的信息.
Pre - Training Objective
CoLAKE也是一个Masked Language Model, 所以它也是通过对句子中的Token随机Mask, 然后从词表中基于上下文将Mask的Token预测出来. 将BERT的Mask模式迁移到图中, 只是将Mask Token变为Mask Node, 我们仍然是对15%的Node进行随机选中, 但选中后的操作略有不同, 下面将BERT和CoLAKE做个对比:
| 概率 | BERT | CoLAKE |
|---|---|---|
| 80% | 将被选中的Token替换为[Mask] | 将被选中的Node替换为[Mask] |
| 10% | 将被选中的Token替换为任意词 | 将被选中的Node替换为与原节点同类的节点 |
| 10% | 不做任何替换 | 不做任何替换 |
在WK Graph中有三大类节点, 被Mask后所对应的意义是不同的:
Masking Word Nodes: 与BERT的情况是一致的, 但CoLAKE在预测Word时除了依赖上下文还能依赖知识做出预测, 因为锚点与Word是全连接的关系, 而锚点受到知识的影响.
Masking Entity Nodes: 如果被Mask的实体是锚点, 那么则依靠它的上下文进行预测. 如果不是锚点, 那么CoLAKE的目标就是KGE.
Masking Relation Nodes: 如果Mask的是两锚点之间的关系, 那么目标就与关系抽取一致. 否则, 目标就是预测两实体之间的关系, 这与传统的KGE方法相似.
然而, 在预训练时预测被Mask的锚点可能比较简单, 模型很容易就能用外部知识而不是依赖上下文完成这个人物, 因此在预训练时会丢掉50%的锚点邻居.
在Mask做训练时, 从Knowledge Embedding的角度来看待, CoLAKE的方式有点像多任务训练. 因为Mask了不同属性的节点会导致CoLAKE所利用的信息不同, 执行任务的初始条件也不同.
我开始对Mask掉锚点后仍然能够利用知识库中的内容表示疑惑, 我开始认为在不知道锚点的情况下, 知识库中所存在的知识应该是不能成功进行链接的. 后来我从另一个角度出发, 作为人类, 我们常已知了句子中的上下文和锚点相关的知识(除去锚点本身), 我们完全可以根据其他与锚点相关的属性和实体来猜出锚点是什么, 这样就完全说得通了.
Model Training
CoLAKE通过对三种不同类型的节点进行训练, 采用交叉熵作为损失函数. 但是因为知识图谱中的实体数量实在是太庞大了, 所以实现CoLAKE有两个问题:
实体数量较大, 训练输入时几乎不可能在GPU上维护一个entity embedding矩阵, 作者给出的解决方案是把entity embedding放在CPU上, 把模型的其他部分放在多张GPU上, GPU上的训练进程从CPU中读出entity embedding同时向CPU写入对应的梯度, CPU上的进程根据收集的梯度对entity embedding进行异步地更新.
实体数量过于庞大导致Softmax十分耗时, 所以简单的采用负采样解决这个问题.
该部分来自CoLAKE: 同时预训文本和知识. 问题1隐射出当前KG和NLP发展可能还是受算力的制约, 相较与CV, NLP需要更多的计算来表达信息.
Experiments
DataSet and Implementation Details
CoLAKE主要用了两个数据集:
- English Wikipedia.
- Wikidata5M(出自KEPLER).
CoLAKE使用英文的维基百科作为预训练数据, 使用了Hugging Face的Transformer来实现, 和RoBERTa一样使用BPE, 直接使用了RoBERTa的权重初始化, 在1e-4的学习率下只训练了一轮.
Knowledge Driven Tasks
在知识驱动型任务上, 作者主要将CoLAKE与同样的注入知识的PLM进行横向对比, 其次与不注入知识的RoBERTa和BERT纵向对比, CoLAKE表现相当不错:
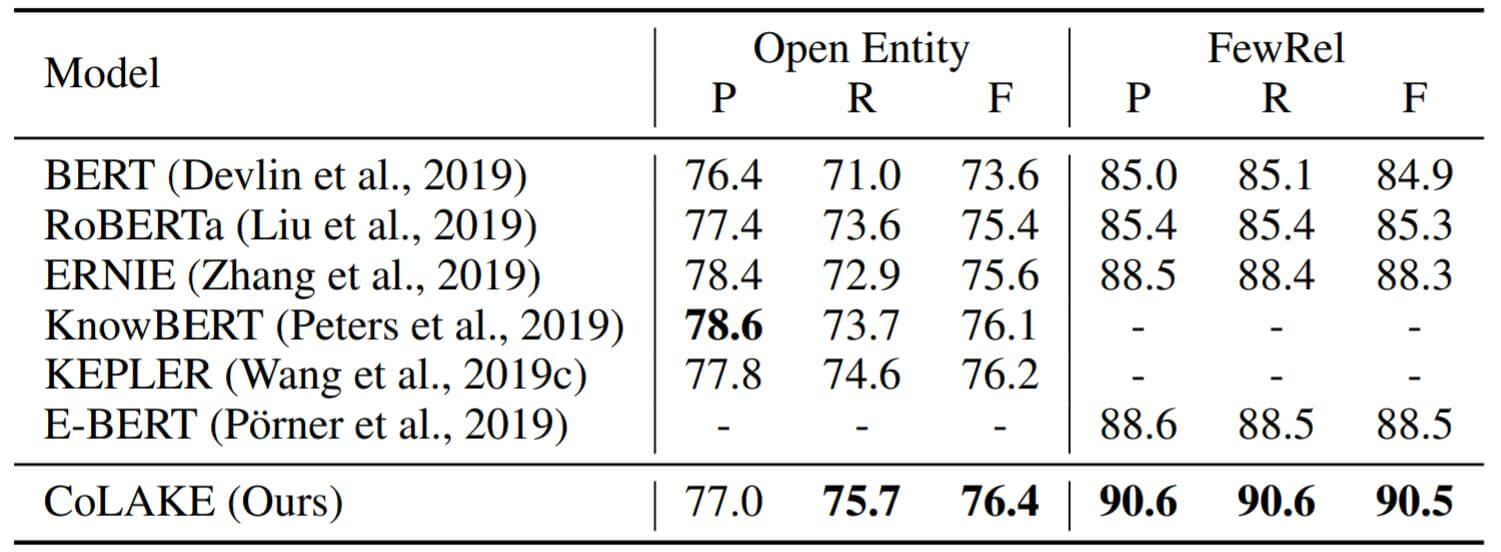
左侧Open Entity对应的任务为实体分类, 右侧FewRel对应的任务为关系抽取.
Knowledge Probing
LAMA(LAnguage Model Analysis) probe任务的目的是定性的测量模型到底存储了多少常识. 作者希望通过LAMA来观察CoLAKE对知识的掌握程度, 为公平起见, 作者还对所有模型只使用词汇之间有交集的部分.通过对Mask掉的知识进行预测, 取得它们的P@1, 实验结果如下:
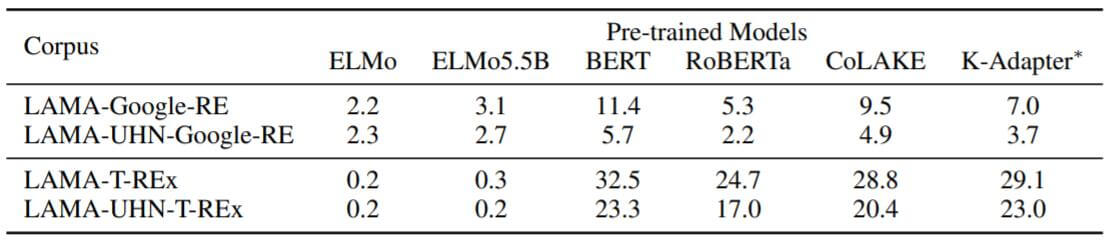
BERT的表现倒是很亮眼. 作者认为K - Adapter比CoLAKE在两个数据集上效果好的原因是基于RoBERTa的LARGE版本, 并且使用了LAMA的一部分数据进行训练. CoLAKE总体而言的表现比RoBERTa要好非常多.
BERT比使用更多数据的RoBERTa效果好太多了, 这与提出LAMA的论文Language Models as Knowledge Bases?结论一致.
Language Understanding Tasks
目前的许多研究表明, 注入知识后, PLM的NLU能力可能会退化. 作者在GLUE常用数据集上对RoBERTa, KEPLER, CoLAKE做了实验:

从实验结果来看, CoLAKE并没有发生很严重NLU能力退化, 与KEPLER相比, 真的只是比RoBERTa差一点点, KEPLER就退化的比较严重.
从这个实验来看, NLU能力是和语言知识相关的, 如果给模型灌输一些世界知识, 原来存储语言知识的部分可能会被干扰, 可能是引入了许多的噪声, 我们或许还没有很好的掌握如何运用这些知识.
我认为将KEPLER和CoLAKE放在一起对比, 一定是CoLAKE的WK Graph起到了某种作用, 能够保留模型对语言模型的理解能力. 沿着这个思路, 图或网的结构是非常重要的. 如果对CoLAKE的WK Graph进一步改进, 或许能够提升模型的NLU能力.
Word - Knowledge Graph Completion
因为CoLAKE加入了 Word - Knowledge Graph的结构, 它本质上已经变为了一个预训练好的GNN. 作者希望利用这个特性, 来测试CoLAKE对结构和语义特征的建模能力. 只要在FewRel上做关系抽取, 就能使其对关系进行补全.
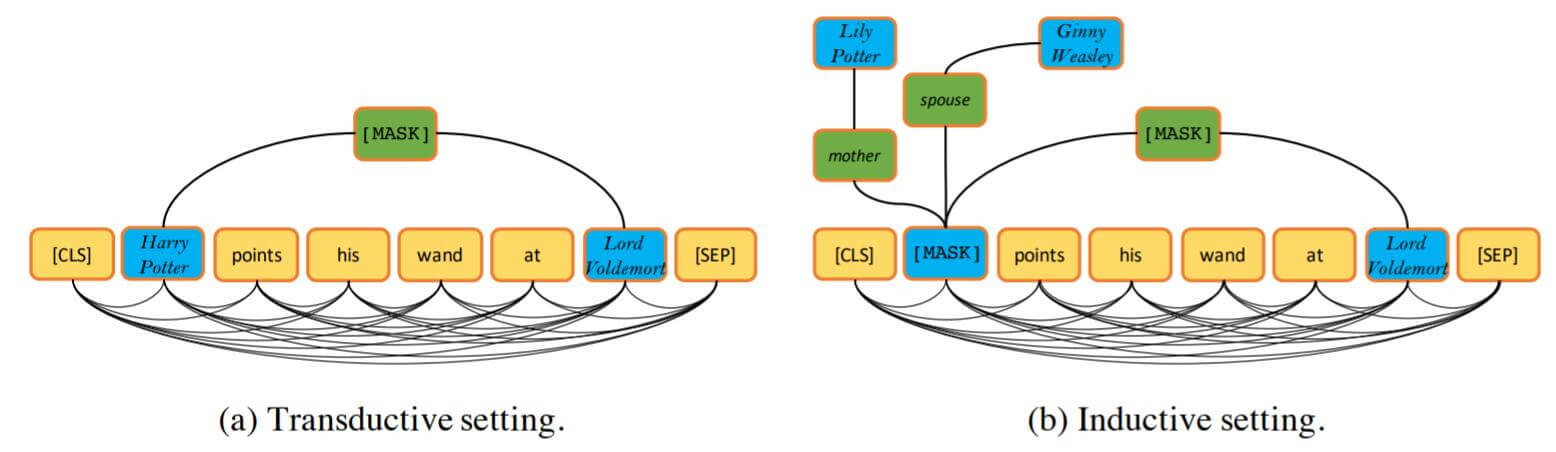
与KEPLER相同, 这里作者给出了两种设置:
- Transductive setting: 对于每个样本, 两个实体$h, t$, 和它们的关系$r$, 可能分别在训练, 验证, 还是测试中出现过. 但它们的整体表示三元组$(h, r, t)$ 却没有在训练数据中出现.
- Inductive setting: 对于每个样本, 至少有一个实体在训练阶段是模型没见过的. 这更考验模型的推断能力. 即将两个实体中至少一个在训练阶段没见过的实体进行Mask, 然后利用其邻居节点来预测该节点的表示.
实验结果如下:
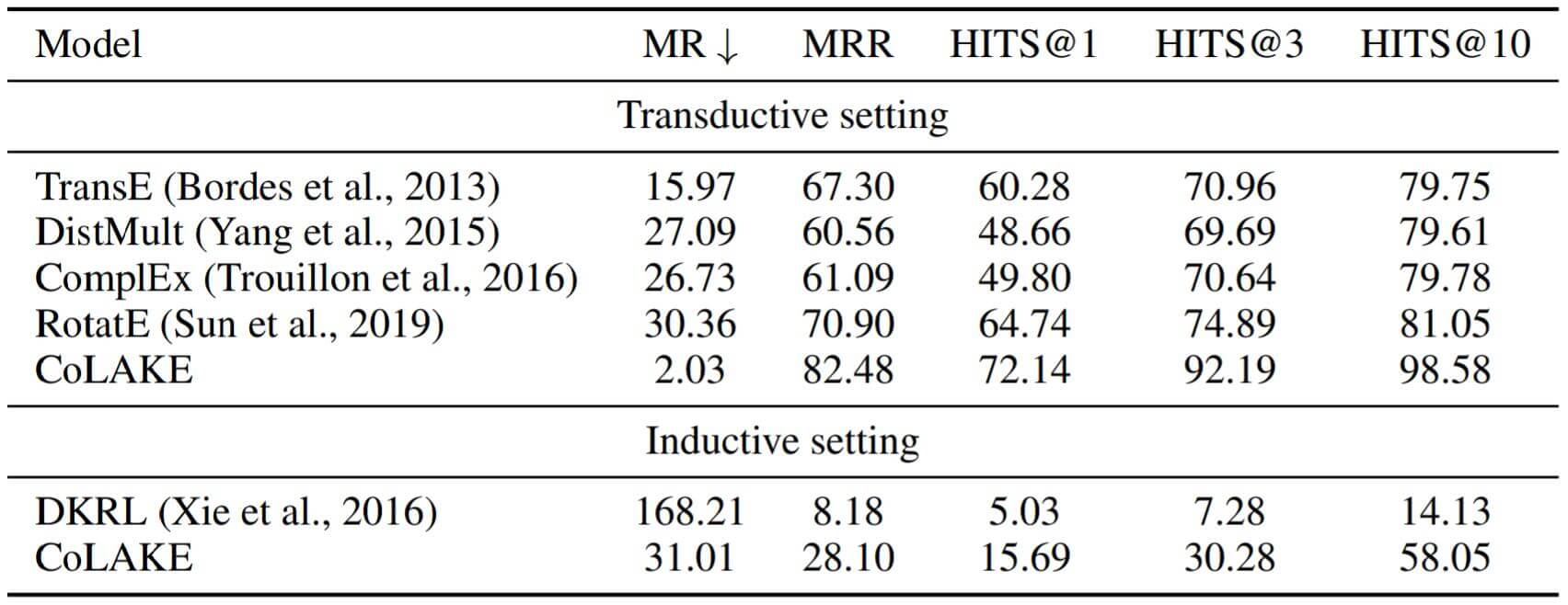
CoLAKE无论在Transductive Setting还是Inductive Setting上都比Baseline强大非常多.
Summary
CoLAKE有如下特点(或说主要贡献):
- 它是一个Masked Language Model, 并能将上下文知识表示和上下文语言表示联合嵌入.
- 由于Word - Knowledge Graph的存在, 它能够轻松地将异构的知识信息和语言信息融合.
- 因为它本质上是一个预训练的图神经网络, 所以具有结构感知能力, 并且易于扩展.
CoLAKE真的是和我理想中将外部知识注入PTM的方式非常相似了.
CoLAKE提供了一个统一的数据结构. 这样非常有利于将来其他形式的数据注入到其中, 当然注入的方式可能是一个值得研究的问题.
顺带一提, 从这些Knowledge Enriched PTM来看, BERT非常受大家的青睐, 说明BERT与XLNet相比更为简洁, 容易被大家所理解和接受.

