本文前置知识:
- AlexNet(详见卷积神经网络发展史)
- Attention(详见Seq2Seq和Attention)
- TransE(详见TransE: Translating Embeddings for Modeling Multi-relational Data)
Integrating Image-Based and Knowledge-Based Representation Learning
本文是论文Integrating Image-Based and Knowledge-Based Representation Learning的阅读笔记和个人理解. 这篇论文是刘志远老师<知识图谱与深度学习>中2.8节提到的模型.
Basic Idea
研究人员发现, 语言的理解和生成是由大脑不同位置的区域负责的, 这些区域对应了许多现实生活中的事物.
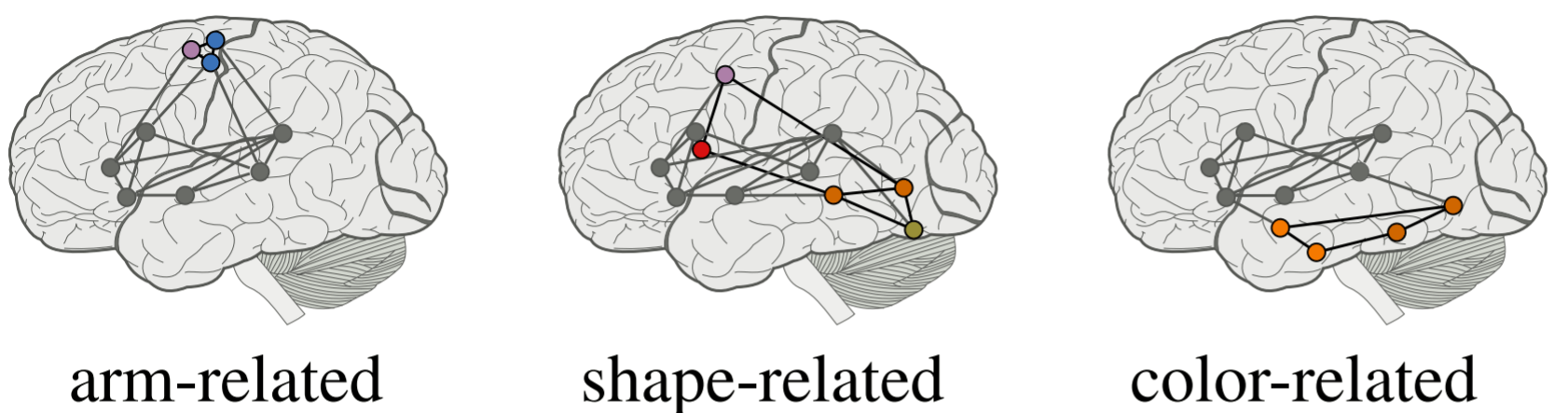
有时, 图片之间也能暗含关系:

即若A是B的一部分, 我们的视觉也认为A的周围应该有B.
作者认为, 我们理解世界是通过Knowledge Base(实体和关系的结构化三元组), 和Image Representation(通过Deep Convolutional Networks). 所以作者研究了基于图片的知识表示模型IKRL Model(Image - Based Knowledge Representation Learning Model).
在先前的KRL方法中, 只使用了KG中的关系信息. 然而KG中的结构化信息经常过于简单, 或者不完整, 会限制知识表示在下游任务中的表现. KRL是允许向表示中添加实体图像信息的, 而基于结构和图片的表示能够从多方面表示实体.
Model Architecture
受到大脑的启发, 通过编码和图像两种手段来对实体进行表示, $\mathbf{h}_S, \mathbf{t}_S$ 是基于结构化的表示(SBR)的头实体和尾实体, $\mathbf{h}_I, \mathbf{t}_I$ 是基于图片的表示(IBR)的头实体和尾实体.
Joint Energy Function
我们将基于结构化的表示(SBR)和基于图片的表示(IBR), 融合起来, 形成一个IKRL Model, 联合能量函数如下:
$$
E(h, r, t)=E_{S S}+E_{S I}+E_{I S}+E_{I I}
$$
联合能量函数中有四项, 这四项分别是:
- $E_{S S}=\lVert\mathbf{h}_{S}+\mathbf{r}-\mathbf{t}_{S}\rVert$: 和TransE的能量函数一模一样.
- $E_{II}=\lVert\mathbf{h}_{I}+\mathbf{r}-\mathbf{t}_{I}\rVert$: 与TransE的能量函数也一样, 但是是图片版本的.
- $E_{SI}=\lVert\mathbf{h}_{S}+\mathbf{r}-\mathbf{t}_{I}\rVert$, $E_{IS}=\lVert\mathbf{h}_{I}+\mathbf{r}-\mathbf{t}_{S}\rVert$: 这两项希望能将SBR和IBR投入相同语义空间.
其中实体向量$\mathbf{h}_S, \mathbf{h}_I, \mathbf{t}_S, \mathbf{t}_I$ 都是归一化过的, 关系$\mathbf{r}$ 不是, TransE论文中曾提到关系的归一化对学习到关系没太大影响. 但是请注意, 在这里SBR和IBR共用同一个关系向量$r$, 关系的表示是不能从图像中直接学到的. 共享关系向量能够作为两种实体表示之间的转换, 也能方便它们嵌入到同一语义空间中.
模型结构的概览图如下:
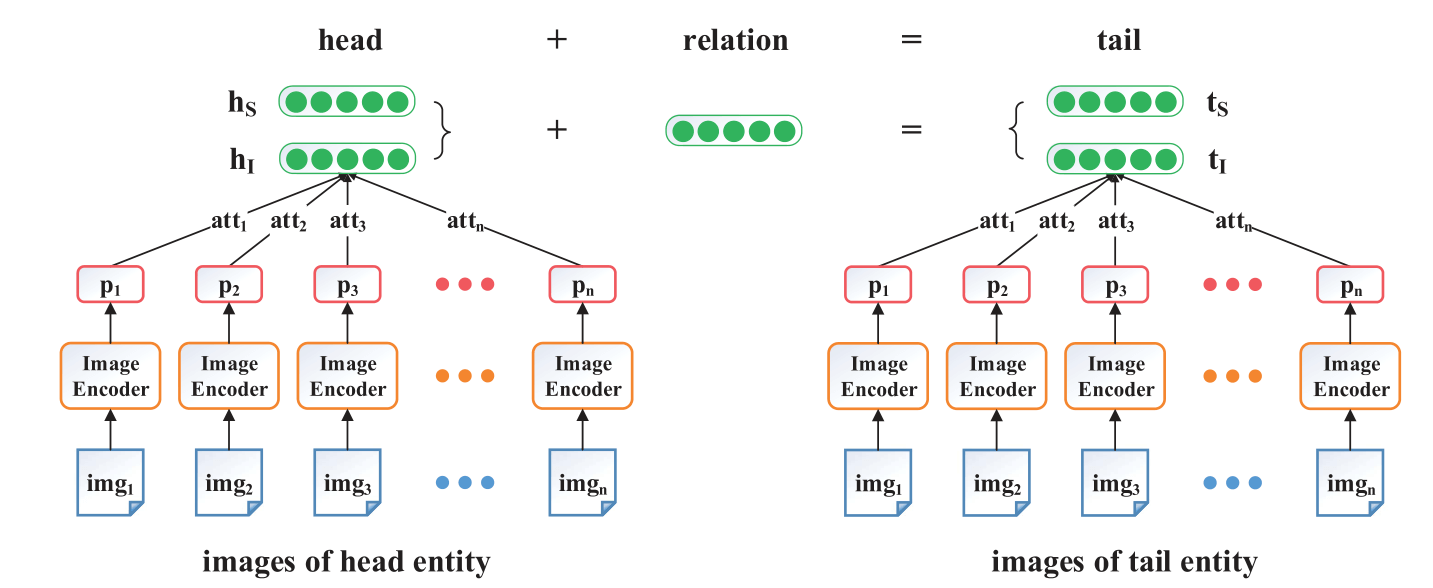
因为考虑到融入了IBR, 所以每个实体的多个图片都被送入Image Encoder中, 然后在通过注意力机制让模型考虑每张图片的重要性, 然后SBR和IBR联合学习整个能量函数.
Image Encoder
图像对IKRL来说是非常重要的, 因为图像能够从外观等多个方面刻画实体. 此外, 多张图片可能从不同角度提供同一个实体的不同特性, 我们用$I_{k}=\left\{\mathrm{img}_{1}^{(k)}, \mathrm{img}_{2}^{(k)}, \ldots, \mathrm{img}_{n}^{(k)}\right\}$ 来表示多张图片.
既然涉及到图像, 那么比较成熟的方案肯定是用CNN提取视觉特征了, 用CNN对每张图像构建特征表示.
Image Encoder由图像表示模块和图像投影模块组成:
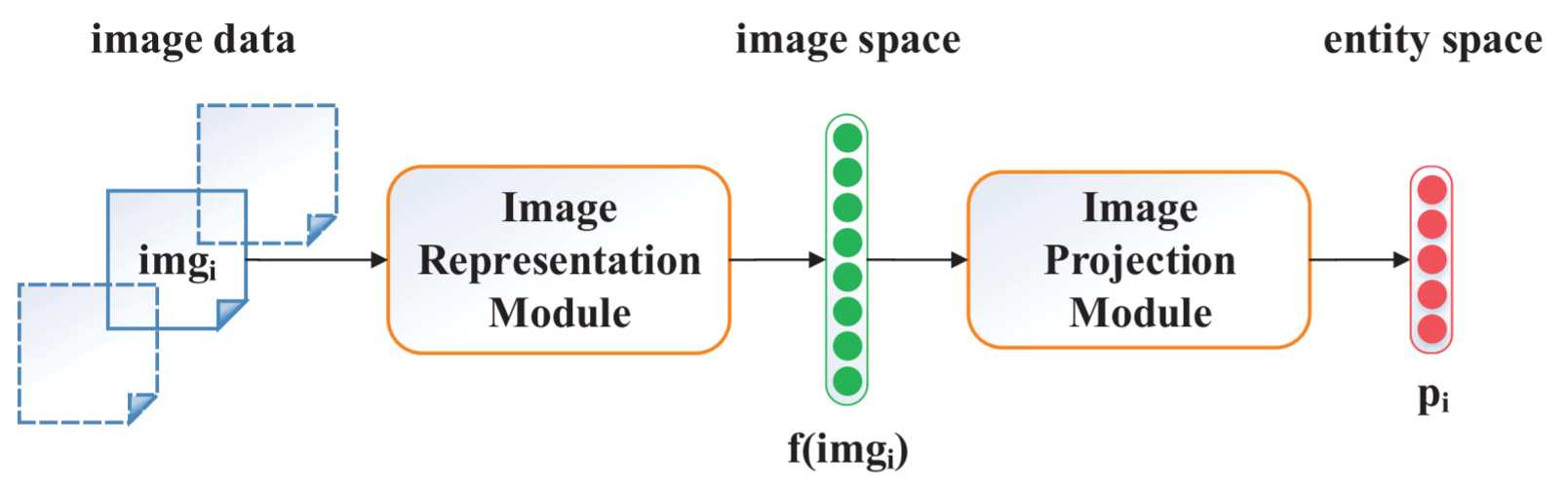
Image Representation Module
图像表示模块主要依赖于CNN对特征进行抽取, 将实体在图像空间中进行表示. 作者在这里只使用ALexNet(确实比较老), AlexNet是一个只由5层Conv层和2层全连接层组成的神经网络:
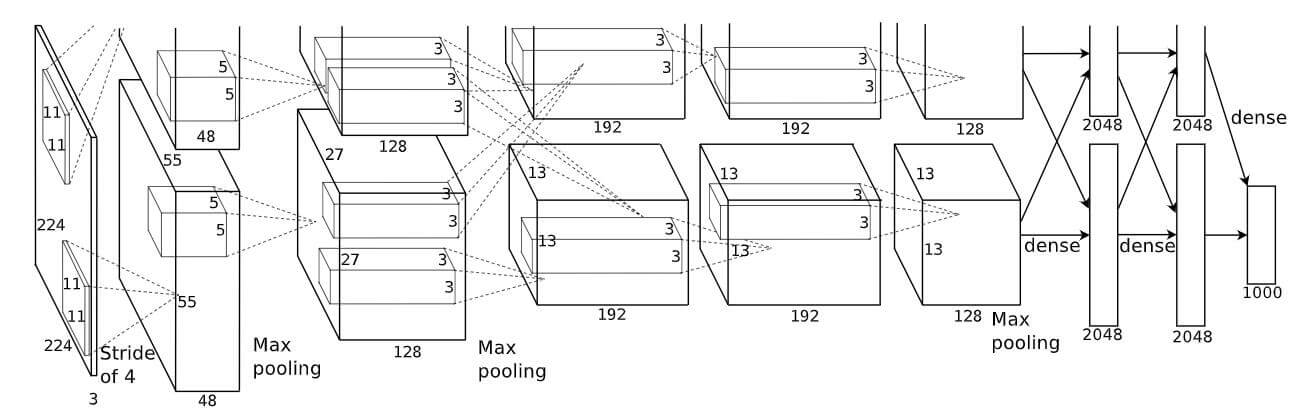
将图像Reshape成$224\times 224$ 的大小, 然后接上5层Conv层, 2层全连接层就得到了实体的图像表示.
这里使用AlexNet肯定不是最好的选择, 我猜测作者出于实验性目的才使用了AlexNet.
Image Projection Module
因为IBR和SBR不在同一个语义空间中, 所以需要用一次变换将它们投入相同的实体空间中:
$$
\mathbf{p}_{i}=\mathbf{M} \cdot f\left(\mathrm{img}_{i}\right)
$$
$\mathbf{p}_i$ 指图片表示, $f(\cdot)$ 表示神经网络的输出. 当然, 这个投影矩阵$\mathbf{M}$ 在每个实例之间共享.
Attention Based Multi - Instance Learning
Attention在IKRL中起到了非常大的作用. 因为Attention让更多信息性的图片对IKRL有更多的贡献. Attention在IKRL中被用于多实例学习, 因为绝大多数实体都有不止一张不同的图片, 但视觉信息经常伴随着噪声, 所以相当有必要对实体所对应的图片进行选择. 论文后面实验会多次说明这一点.
细想一下, 其实我们也是这样的, 我们善用注意力去选择表征实例, 而滤掉不相关的实例.
在IKRL中, 实例级别的注意力能将每个实例与实体进行匹配, 得到实例对实体的权重:
$$
\operatorname{att}\left(\mathbf{p}_{i}^{(k)}, \mathbf{e}_{S}^{(k)}\right)=\frac{\exp \left(\mathbf{p}_{i}^{(k)} \cdot \mathbf{e}_{S}^{(k)}\right)}{\sum_{j=1}^{n} \exp \left(\mathbf{p}_{j}^{(k)} \cdot \mathbf{e}_{S}^{(k)}\right)}
$$
其中$\mathbf{e}_{S}^{(k)}$ 代表第$k$ 个实体的SBR.
在获取了权重后, 对图像表示加权求和, 得到IBR:
$$
\mathbf{e}_{I}^{(k)}=\sum_{i=1}^{n} \frac{\operatorname{att}\left(\mathbf{p}_{i}^{(k)}, \mathbf{e}_{S}^{(k)}\right) \cdot \mathbf{p}_{i}^{(k)}}{\sum_{j=1}^{n} \operatorname{att}\left(\mathbf{p}_{j}^{(k)}, \mathbf{e}_{S}^{(k)}\right)}
$$
除了上述普通的Attention外, 作者还用两种方法与之进行比较:
- 如果对每张实例分配相同权重, 称为$\text{AVG}$.
- 如果只选权重最大的实例作为$\mathbf{p}_{i}^{(k)}$, 称为$\text{MAX}$.
在后续的实验中, 会比较这三种方法之间的性能.
Loss Function
作者使用最大化间隔的Hinge Loss来训练:
$$
L=\sum_{(h, r, t) \in T} \sum_{\left(h^{\prime}, r^{\prime}, t^{\prime}\right) \in T^{\prime}} \max \left(\gamma+E(h, r, t)-E\left(h^{\prime}, r^{\prime}, t^{\prime}\right), 0\right)
$$
其中$\gamma$ 代表间隔. 与现在的其他KRL模型训练一样, 都有负采样:
$$
T^{\prime}=\left\{\left(h^{\prime}, r, t\right) \mid h^{\prime} \in E\right\} \cup\left\{\left(h, r, t^{\prime}\right) \mid t^{\prime} \in E\right\}
\cup\left\{\left(h, r^{\prime}, t\right) \mid r^{\prime} \in R\right\}, \quad(h, r, t) \in T
$$
但这里的负采样不光替换实体, 而是随机替换三元组中的实体和关系.
Optimization and Implementation Details
IKRL模型中, 所有的参数为$\theta=(\mathbf{E}, \mathbf{R}, \mathbf{W}, \mathbf{M})$, $\mathbf{E}$ 代表SBR的Embedding, 包括$\mathbf{h}_s, \mathbf{t}_s$. $\mathbf{R}$ 代表关系嵌入. $\mathbf{W}$ 代表神经网络的参数, $\mathbf{M}$ 是投影矩阵的参数. 作者使用SGD来优化模型, $\mathbf{E}, \mathbf{R}$ 直接用TransE的参数初始化, $\mathbf{M}$ 随机初始化.
Experiments
详细试验参数设置请参考原论文, 不过我认为本论文是一篇实验性的工作, 参数设置上没有太多意义. SBR的实体和关系Embedding维度$d_s=50$, 并且最多为每个实体使用10张图片.
DataSet
因为没有现成的Image Based Knowledge Dataset, 所以作者团队自己搞了一个WN9 - IMG. 这个数据集先从WN18中抽出一部分三元组, 然后从ImageNet中抽出来一部分图片, 组成了基于图片的数据集. 这个数据集中只有9种关系, 6555个实体. 不同关系的数据集分布如下所示:
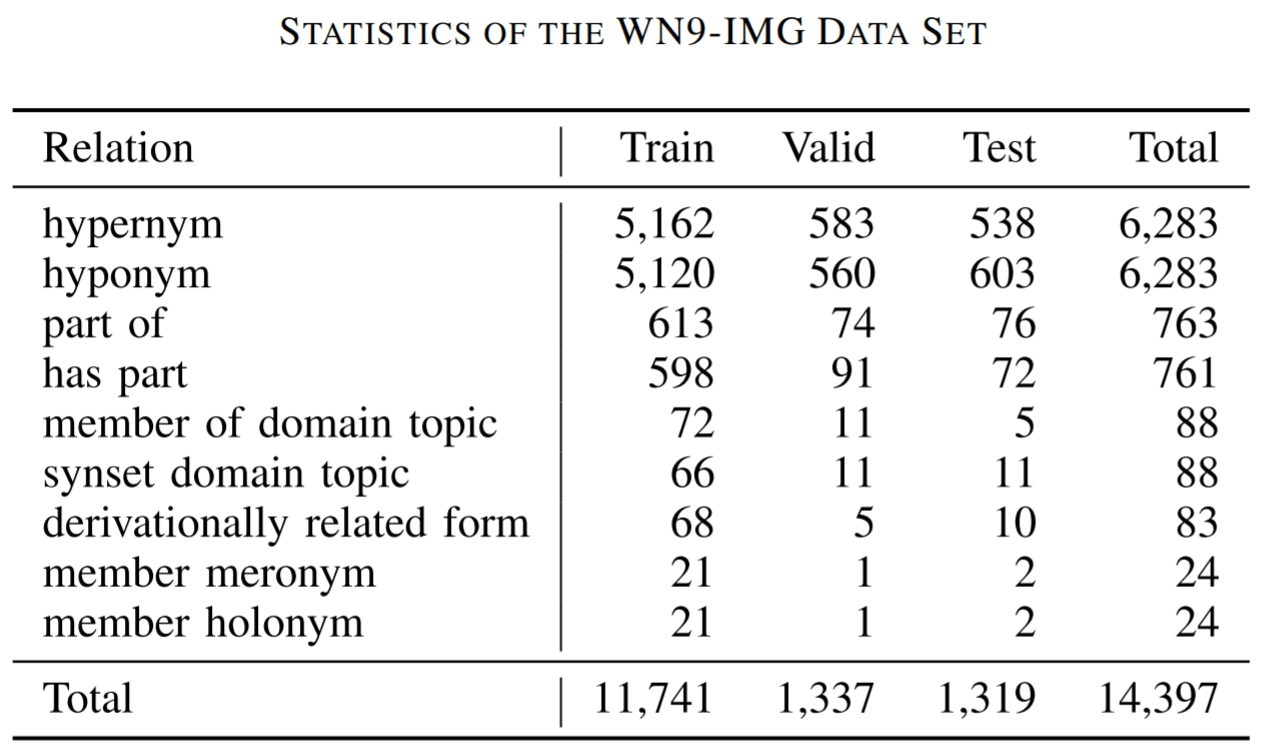
8类实体数量如下所示:
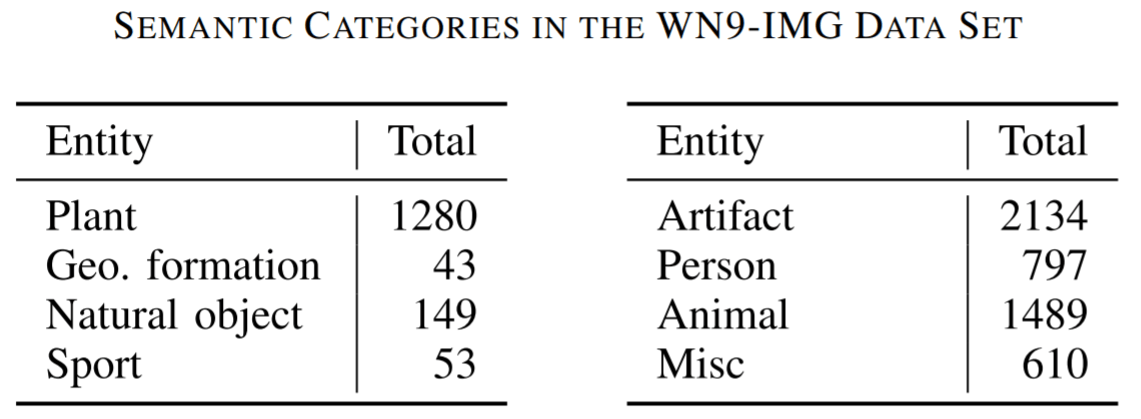
Entity Prediction
在训练时, 仍然使用IBR和SBR混合的方式进行训练. 只是在测试时对使用的信息进行改动:
- SBR: 在测试时只使用基于结构的表示.
- IBR: 在测试时只使用基于图像的表示.
- UNION: 二者都可以使用.
在与TransE和TransR的比较中, IKRL的表现非常好:
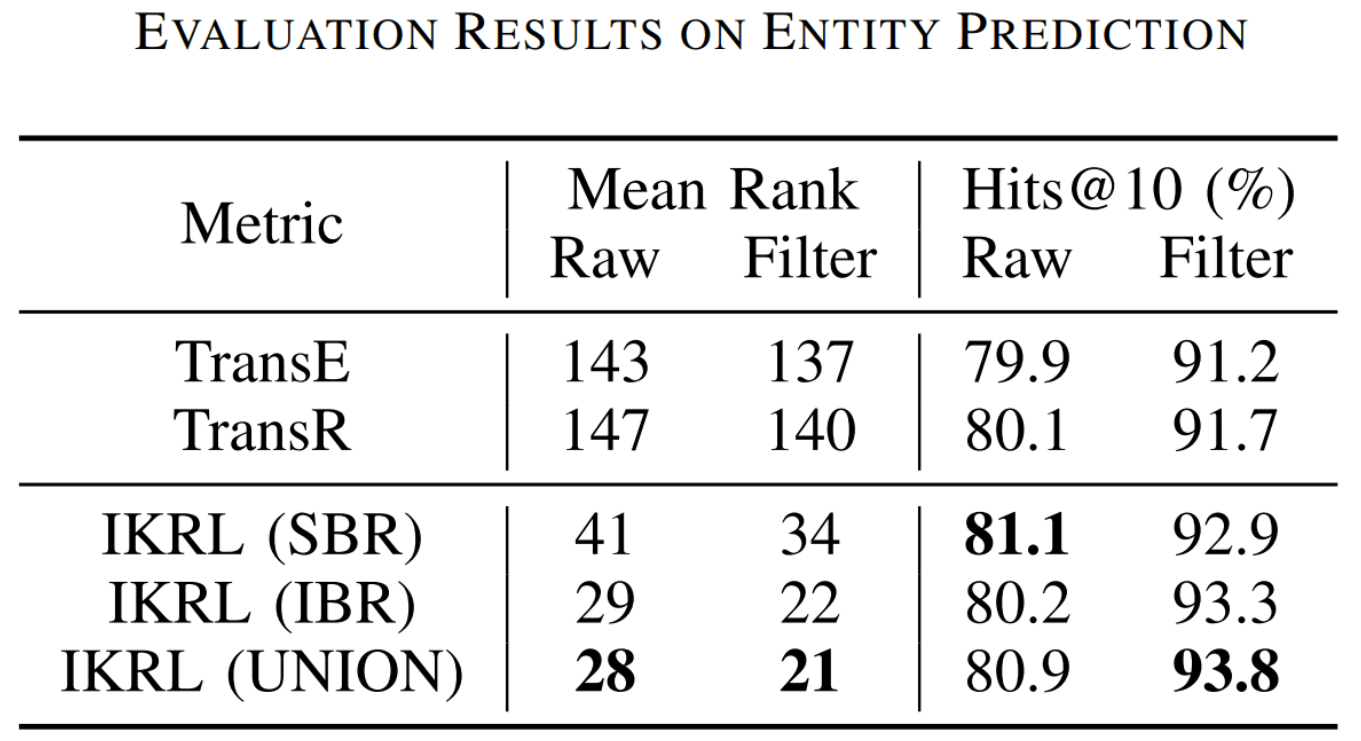
从结果中得到以下结论:
- 无论是哪种IKRL, 全面碾压TransE和TransR, 证明了实体图像中丰富的视觉信息能帮助更深入的理解实体.
- 相比于只使用SBR训练(TransE), 融合了IBR的表示训练有极大的提升. 因为IKRL能通过能量函数中的两种表示进行混合项训练, 也间接地学习到了一部分图像信息, 这也是为什么测试时只使用SBR就能得到很大提升.
- 在MR上显示出的效果提升比较大. 作者认为MR是更多关注Embedding在空间上的整体效果, 而Hits@10对错误比例更加敏感. IKRL因为融入了图片信息, 能从图片中间接的发现KG中没有体现的直接关系, 可以利用图片的中发现的潜在关系.
- IKRL是基于TransE进行训练的, 但仍然比TransR效果好, 说明IKRL有更好的鲁棒性, 能更好的用在基于平移模型的改进模型上.
我有些惊讶, 仅仅只使用IBR带来的效果居然这么好. 是不是说明了模型在训练阶段使用了SBR后, 在不同任务上SBR测试阶段的意义是不同的? 可能有些任务不需要SBR?
作者还对Attention的三种方式的效果进行了比较:
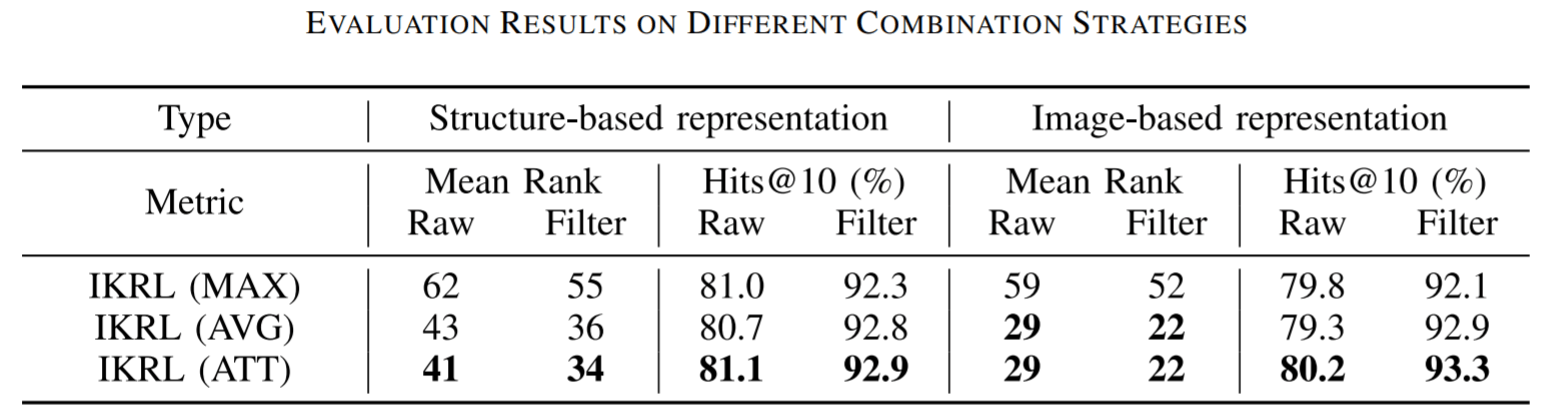
MAX最差, 这是因为单一图片提供的视觉信息有限. AVG其次, 虽然考虑到了所有实例, 但不可避免的引入了噪声. 普通的Attention是最好的, 它能够根据图片的质量来对实例进行筛选.
Triple Classification
在三元组分类任务上, 作者对每种关系依据验证集设置一个阈值$\delta_r$, 用阈值来对三元组分类是否正确进行分类. 例如当$\lVert\mathbf{h}+\mathbf{r}-\mathbf{t}\rVert>\delta_r$ 时, 分类错误, 反之分类正确. 其他模型同样按照自己的评分函数分类判断.
在不同的Attention种类下, 结果如下所示:
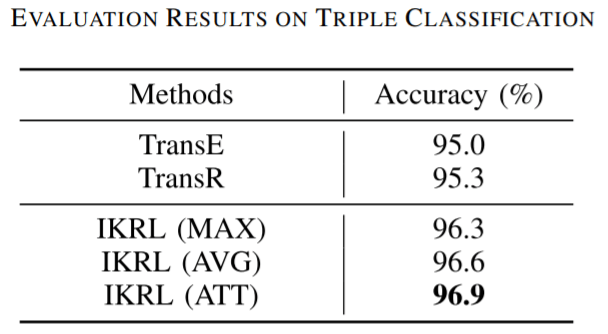
仍然是与Entity Prediction相似的结论. 融入视觉信息的表示是一件非常重要的事情, 并同时证明了Attention保证了图像的质量, 充分利用实体的多样性, 增强了模型的鲁棒性.
Representation Analysis
SBR and IBR
作者分别基于SBR和IBR计算了数据集中所有类别的实体之间的协方差:
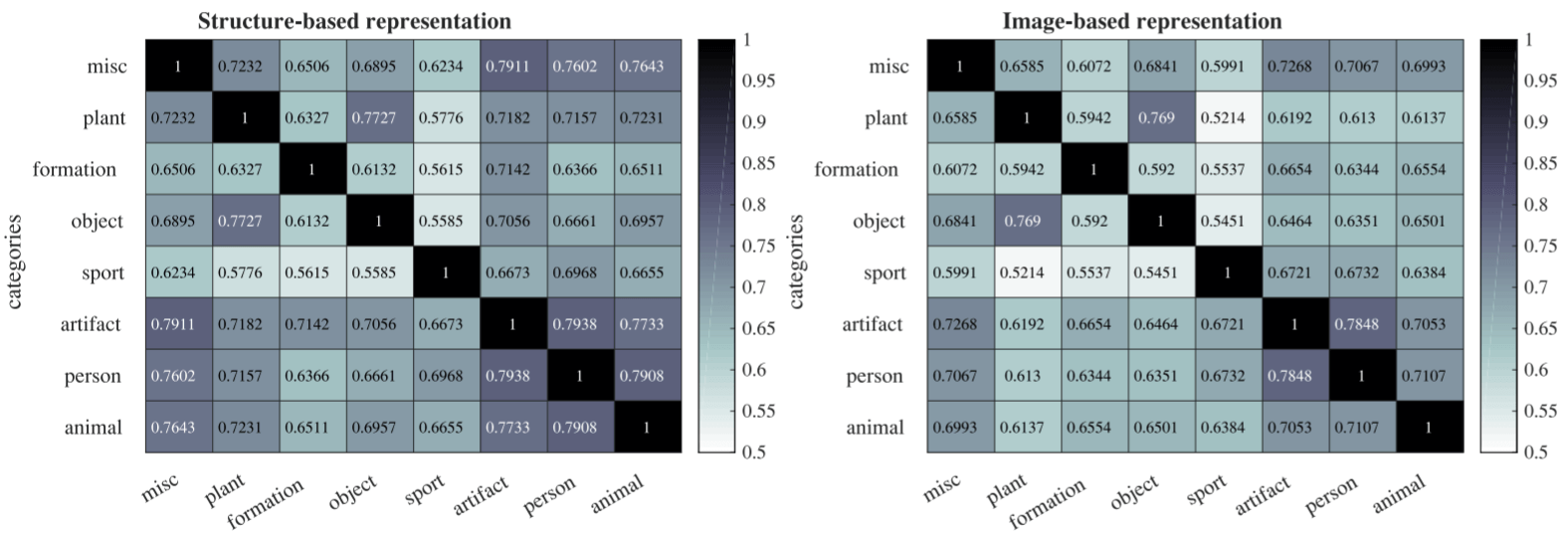
从中不难发现, IBR能对不同类别的实体相区分(不同类之间相关性差), SBR将少数类别的实体相连接(有些类相关性强). 但在IBR中, Plant和Object似乎具有很高的相关性.
IBR更容易基于外观区分实体, SBR更善于基于功能区分实体, 如下图:

左侧”sport”从图像上来看并不相似, 但功能相似. 右侧”aritifact”从图像上看上去非常相似, 但功能不相似.
作者分别对SBR和IBR进行了PCA降维成2维后绘制出实体在坐标系中的位置, 并用RSA做可解释性分析:
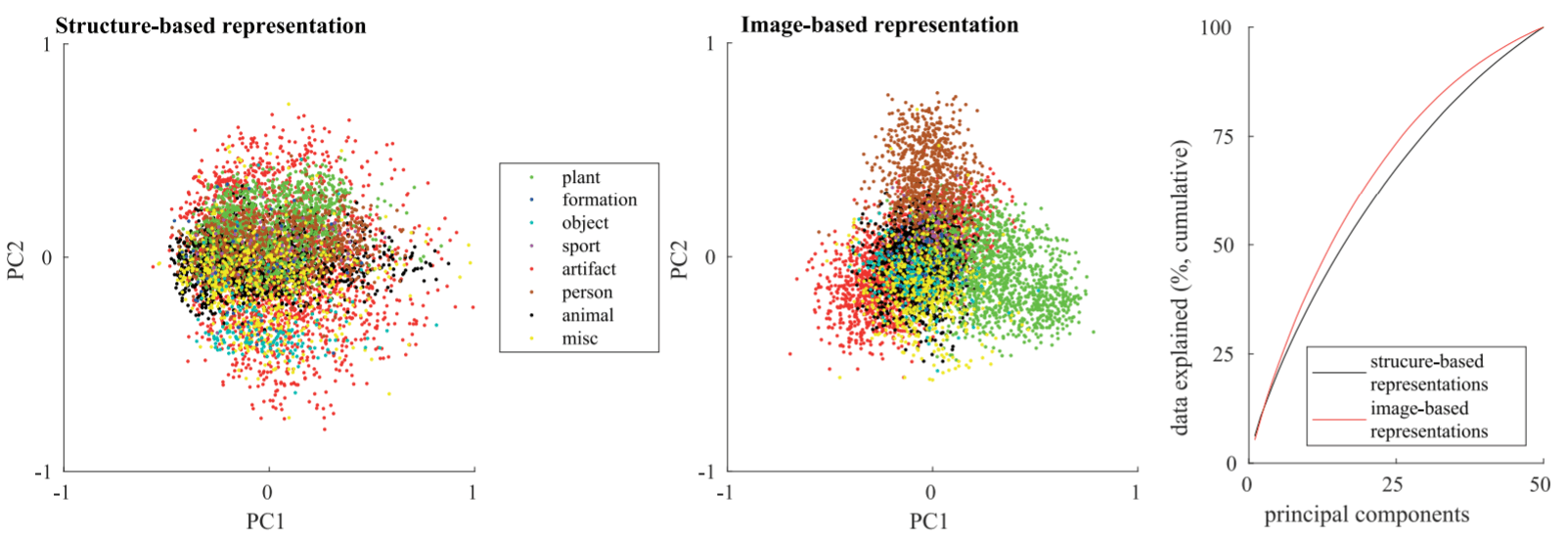
SBR(左), IBR(中), 主成分可解释性(右). IBR能够明显的将各关系的实体分开, SBR效果就差一些. 从数据可解释性来看, 除了随维度增大可解释性增强, 但从表示类型来看, IBR也是始终要强于IBR的.
Relation Analysis
作者将关系也做PCA和RSA:
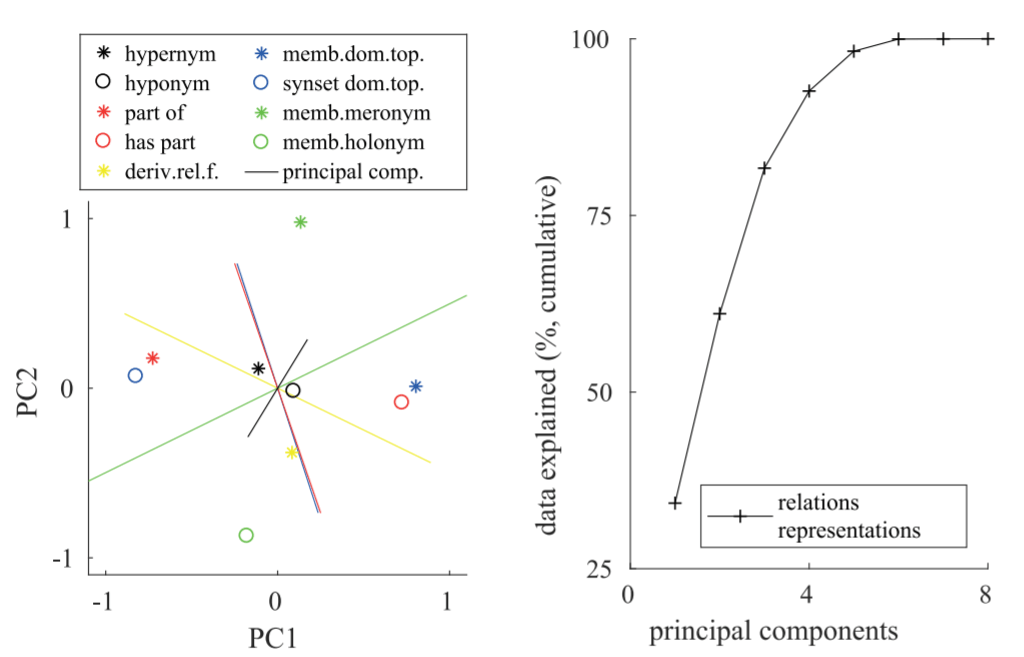
能很清楚的看到, 反义关系往往处于某个主成分正交轴的对立面. RSA图中看到, 在主成分没有达到8时可解释性已经收敛, 说明目前学到的关系复杂度是比需求要大的.
Case Study
作者在这里对案例进行了分析.
Attention
首先是对Attention对实例筛选的结果进行了可视化:

例如”cycling”这个实体, 真正的骑行图像被赋予了高注意力, 而没有自行车的图像被赋予低注意力. “typewirter”中, 整体打印机的图片被赋予高注意力, 而打印机局部细节的图片被赋予低注意力. 在”riding”中, 人类骑马的图片被赋予高注意力, 马群自己走的照片被赋予低注意力.
这证明了注意力能自动从图像中学习知识表示, 减少低质量图片的噪声.
Semantic Translation in Image Representation Space
然后, 作者发现, 在跨模态的图像 - 知识空间中, 像Word2Vec一样, 也含有语义平移规则:
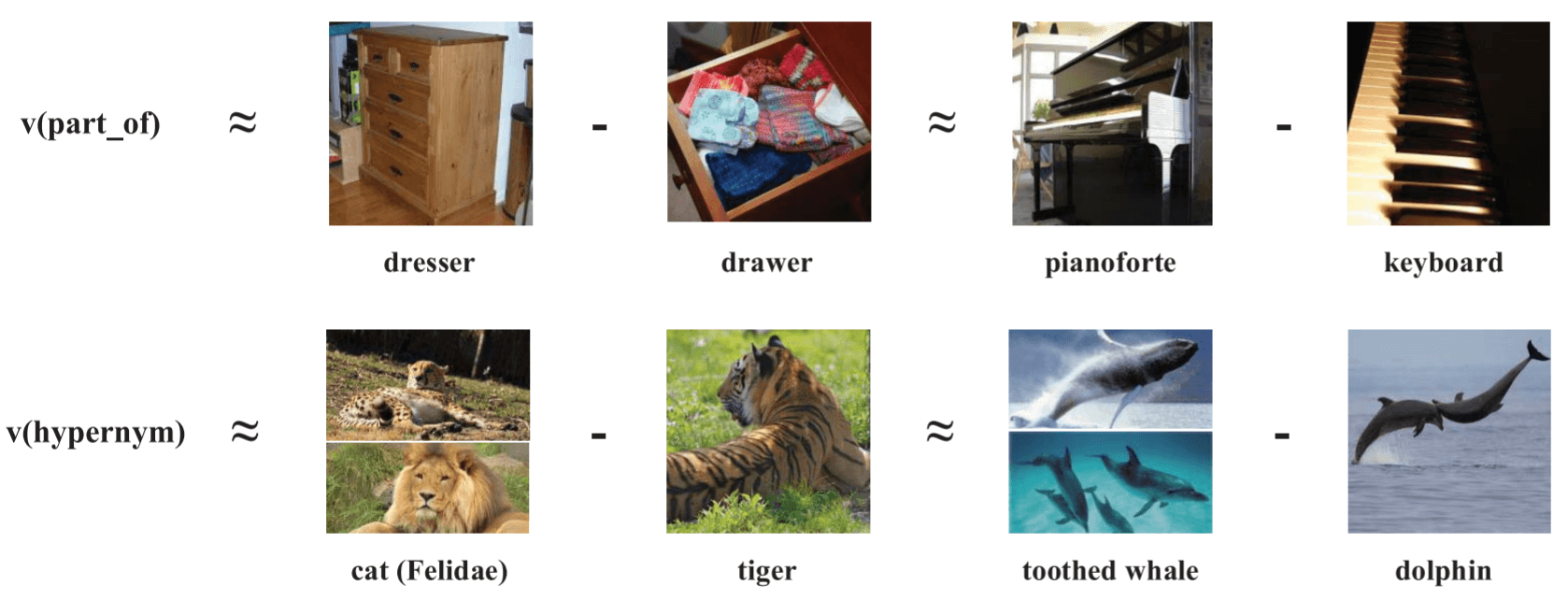
在图像的表示中, 柜子和抽屉的差, 与钢琴和琴键之间的差大致相等, 表示出”属于”的关系. 这体现了编码的语义规则性.
Summary
IKRL介绍了一种基于图像的知识表示方法. 将基于结构化的表示(SBR)和基于图片的表示(IBR)融合在了一起, 并用Attention做图片的自动过滤, 提高模型的性能和鲁棒性.
我认为, 这篇文章比较有价值的有以下几个部分:
- 论文中提出的多实例学习思路确实不错, 或许多模态都可以用多实例学习作为接口, 将实体与不同模态之间的数据进行自动对齐和筛选.
- 做了很多的分析类实验, 虽然使用的模型都是最原始最简单的, 但这些可视化探究都是非常有价值的, 我认为相当多的可视化都得益于图像.
- 提供了基于图像的知识数据集WN9 - IMG.
我认为的缺点有:
- 在处理SBR时只用了TransE, 在处理IBR时只用了非常早的AlexNet. 那么在对关系建模时就肯定会遇到对多关系建模的痛点. 但想必这篇论文也只是一次尝试和探索, 而非追求性能.
- 没有与更多的KRL方法进行对比, 但想必在后续肯定会有相关工作.
我认为实验还揭示了另一个点, 或许在某些任务上融入语言特征并不能起到很大的作用. 比如本论文提到的模型, 如果只用IBR, 也能取得相当好的效果. 当然不排除作者提出的KRL模型没有对三元组使用其他方法优化的因素. SBR确实能够在某些任务上使模型完成更复杂的任务, 并与IBR互补. 但从本论文的结果来看, 并不能很大幅度的提升性能.
希望脑科学和神经科学能快快进步, 给深度学习发展带来更多动力和想法.

