LeNet
LeNet可以说是CNN的开山鼻祖之一了, 虽然它不是CNN的起点, 但是可以称为CNN兴起的标志. 它由图灵奖得主LeCun Yann在1998年的Gradient-based learning applied to document recognition提出.
CNN最早的模型框架就是由LeNet给出的, 即卷积+池化+FC层的基本结构.
诸如局部感知, 权值共享, 池化等操作都是从这里开始的, 并深远的影响了以后的卷积神经网络发展.
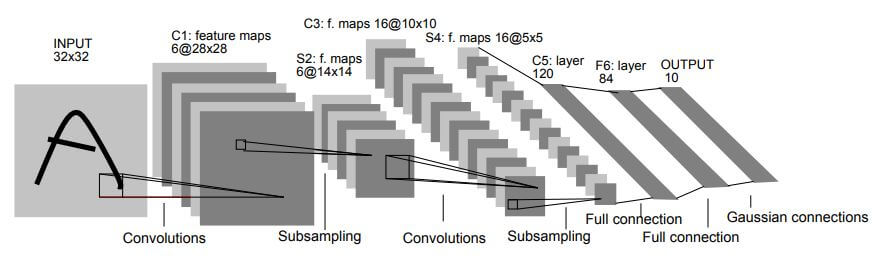
对当时的深度神经网络(也就是多层感知机)来说冲击非常大. 相较于MLP来说, LeNet所采用的的权值共享和局部连接大幅度降低了模型参数数量, 并对于手写数字识别提升到更高的准确率. 并且LeNet还设计了MaxPool通过下采样提取特征. 当时采取的激活函数是Tanh, 因为它关于原点对称, 比Sigmoid收敛快.
可惜当时LeNet受限于时代背景, 直到后来GPU运算的普及和2009年ImageNet这样大规模的数据集的出现, 才被人发现它的价值.
AlexNet
2012年另一个具有划时代意义的模型AlexNet横空出世. AlexNet在2012年ImageNet竞赛中以超过第二名10.9个百分点的绝对优势, 一举夺冠, 引起了相当大的轰动. 此前深度学习沉寂了很久, 但自AlexNet诞生后, 所有的ImageNet冠军都是用CNN来做的.
AlexNet的论文是ImageNet Classification with Deep Convolutional Neural Networks.
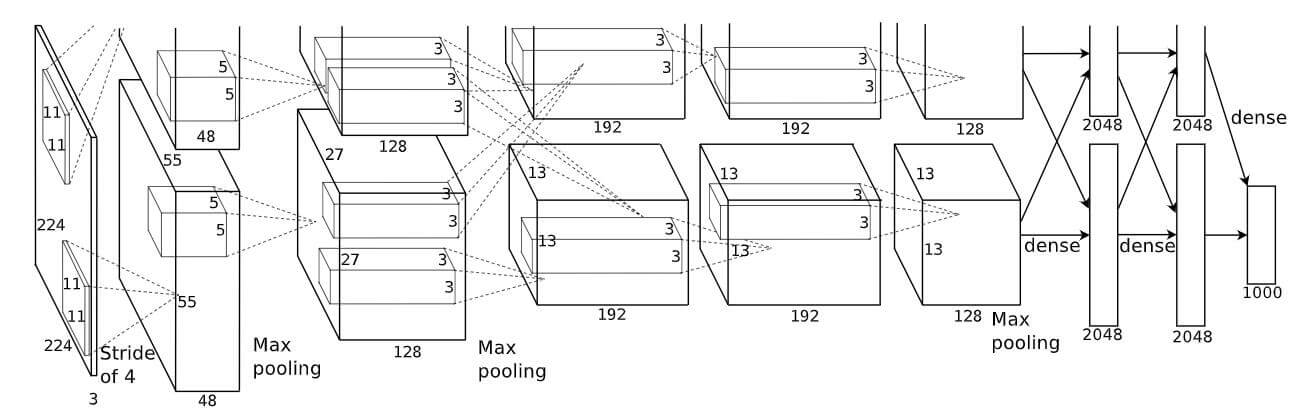
AlexNet的特点:
- 相较于LeNet, AlexNet的网络深度更深.
- 在每个卷积层后首次使用了ReLU作为激活函数.
- 添加了Local Response Normalization(LRN, 局部响应归一化) 层提高准确率, 但似乎2015年的VGG中却提到LRN没什么用.
- 设计和使用了Dropout, 来减轻模型过拟合程度.
- 使用了数据增强, 对训练数据施以裁剪, 旋转等.
- 基于当时的算力限制, AlexNet将图像分割为上下两块分别训练, 然后用FC层合并在一起.
但是AlexNet的卷积核很大, 训练起来非常困难, 并且反向传播时最靠近输入端的卷积核更难利用梯度来更新自身的值.
VGGNet
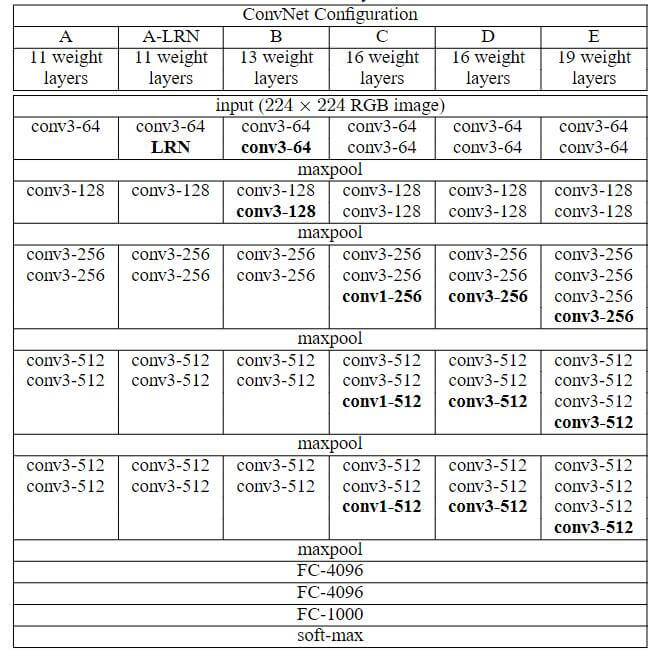
VGGNet是由牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发, 在Very Deep Convolutional Networks for Large-Scale Image Recognition中提出的深度卷积神经网络, 取得了ILSVRC2014比赛分类项目的第二名, 而第一名是同年提出的GoogLeNet.
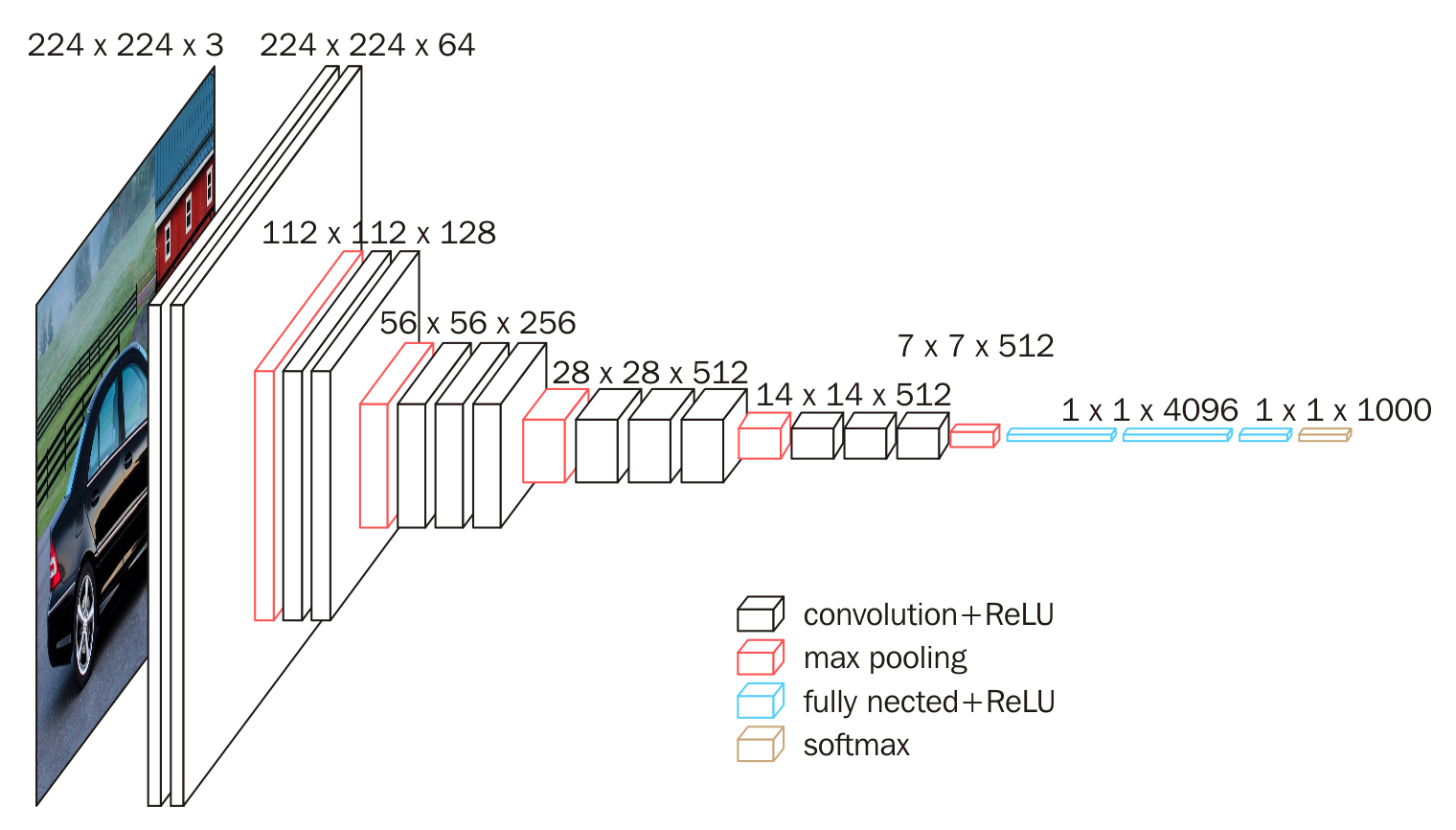
VGG使用了更小的卷积核, 首次提出用多个小卷积核代替一个大卷积核的观点. 比如用两个3x3卷积代替一个5x5卷积, 用三个3x3卷积代替一个7x7卷积, 这样能增加非线性映射, 保证了模型的感知域是相同的, 但却减小了模型参数量.
同时, VGG也指出了在AlexNet中使用的局部响应归一化可能没有增益, 因为在实验中并没有给VGG带来性能提升.
除此外, VGG构建了16-19层的稳定卷积神经网络, 证明了网络深度的增加可以带来性能提升.
GoogLeNet
GoogLeNet也称为Inception, 其第一个版本在与VGG出世的同一年ImageNet中取得了冠军.
在VGGNet中发现, 在加宽和加深一个网络时, 模型效果会得到提升. 但是与之对应的就是参数数量上的增加, 和对梯度消失和弥散的不可控, 这就导致反向传播的效果差, 也意味着过拟合风险增加. 所以在加宽和加深模型的同时尽可能的减少参数, 肯定能够带来性能的提升.
其实上述所指的方法就是将全连接层替换为更加稀疏的网络结构. 因为大多数硬件是针对稠密数据计算的, 对于稀疏数据的计算没有优化, 所以稠密数据和稀疏数据的计算效果是相似的. 应该找到一种方法实现同时利用网络内的稀疏性, 又能利用密集矩阵的高性能计算. 根据文献人们知道, 将稀疏矩阵聚类为密集的子矩阵可以提高计算性能, 这就成为了GoogLeNet的核心思想: 怎样用密集成分来近似最优的局部稀疏结构.
Inception v1
稀疏连接有两种方法, 其一在空间上的局部连接, 也就是CNN的方法, 另一是在特征维度上将稀疏连接进行处理, 也就是在通道维度上处理. GoogLeNet v1通过设计密集结构来近似一个稀疏的CNN. 相关论文Going deeper with convolutions. 对于相同尺寸更多数量的卷积核, 提取出的特征更加稀疏, 而更少数量的卷积核提取的特征更加稠密. 同时使用不同尺寸的卷积核, 分别提取不同尺度的特征, 但保持总的卷积核数量不变, 这样提取出的特征密度更大, 并且不同尺度之间具有弱相关性, 这在现在的CNN中早已被广泛运用, 也称多尺度卷积. 最早的Inception模块如下:
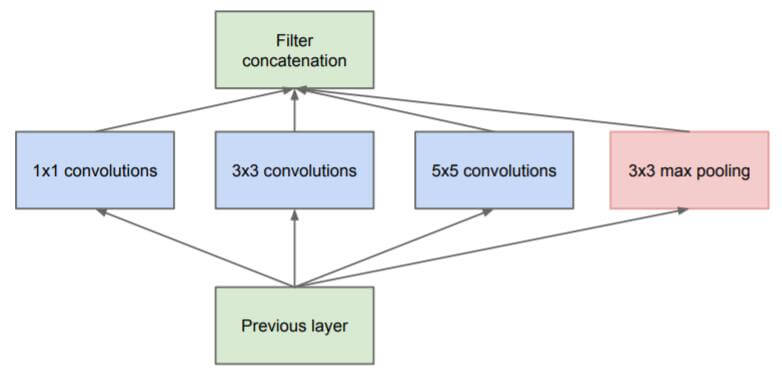
多尺度卷积时在图像周围使用补0的方式来维持不同尺度的卷积特征图尺寸相同, 即TF中CNN的SAME Padding方式.
上述的Inception块容易导致运算量很大, 因为最后不同尺度的卷积核和池化是concat在一起的, 就有可能导致并行堆叠产生的维度越来越大, 使计算更困难, 所以Inception采用了更多的1x1卷积来减少维度和参数. 这种1x1卷积除了减小参数量, 还增加了非线性拟合能力.

Inception采用了大量的Inception块结构进行堆叠, 并另外增加了两个辅助的softmax分支, 意在避免梯度消失和为输出做辅助分类, 将loss加权后加到最终分类结果中, 文中认为辅助分类器只在训练末期提高准确率. 在最后实际测试时, 这两个辅助的分支会被去掉, 去掉后并不会导致模型性能有明显的降低. 作者认为辅助分类器起到的作用更像是正则化.
Inception v1已经尽可能的抛弃掉FC层, 只是为了方便大家对模型进行FineTune才在最后加入的FC.
Inception v1完整结构图如下:
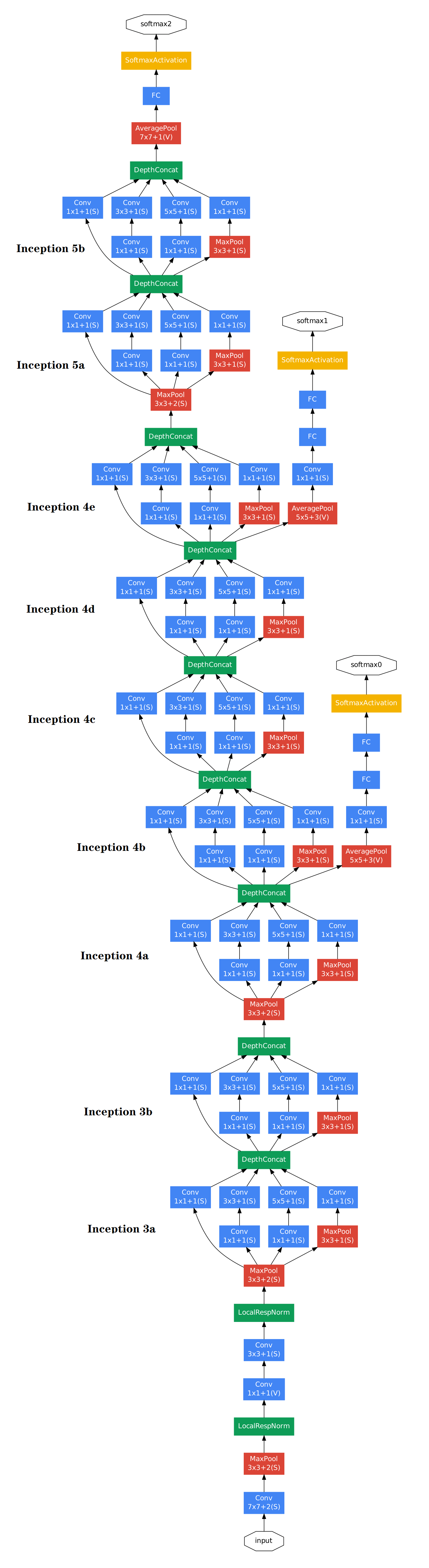
最终卷积层后采用全局池化, 而非FC层, 全局池化有助于减少参数量.
Inception v2/Inception v3
凭借Inception v1的优秀表现, 2015年GoogLeNet团队又对其挖掘改进, 在Rethinking the Inception Architecture for Computer Vision提出了Inception v1的升级版本Inception v2/v3.
在论文开头, 作者提出了4个网络结构设计原则:
- Avoid representational bottlenecks, especially early in the network.
- Higher dimensional representations are easier to process locally within a network.
- Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
- Balance the width and depth of the network.
- 避免信息表征的瓶颈, 尤其是在网络早期. (不要过早压缩和降维原来的信息)
- 更高维的表征能更容易的在网络中局部处理. (增加每层的卷积核数量能获得更低耦合度的特征)
- 空间聚合在低维嵌入时能在不损失太多表征能力的情况下完成. (可以先用1x1对输入特征降维再执行大卷积核卷积, 如果对输入特征直接池化, 会损失很多信息)
- 网络的深度和宽度要平衡.
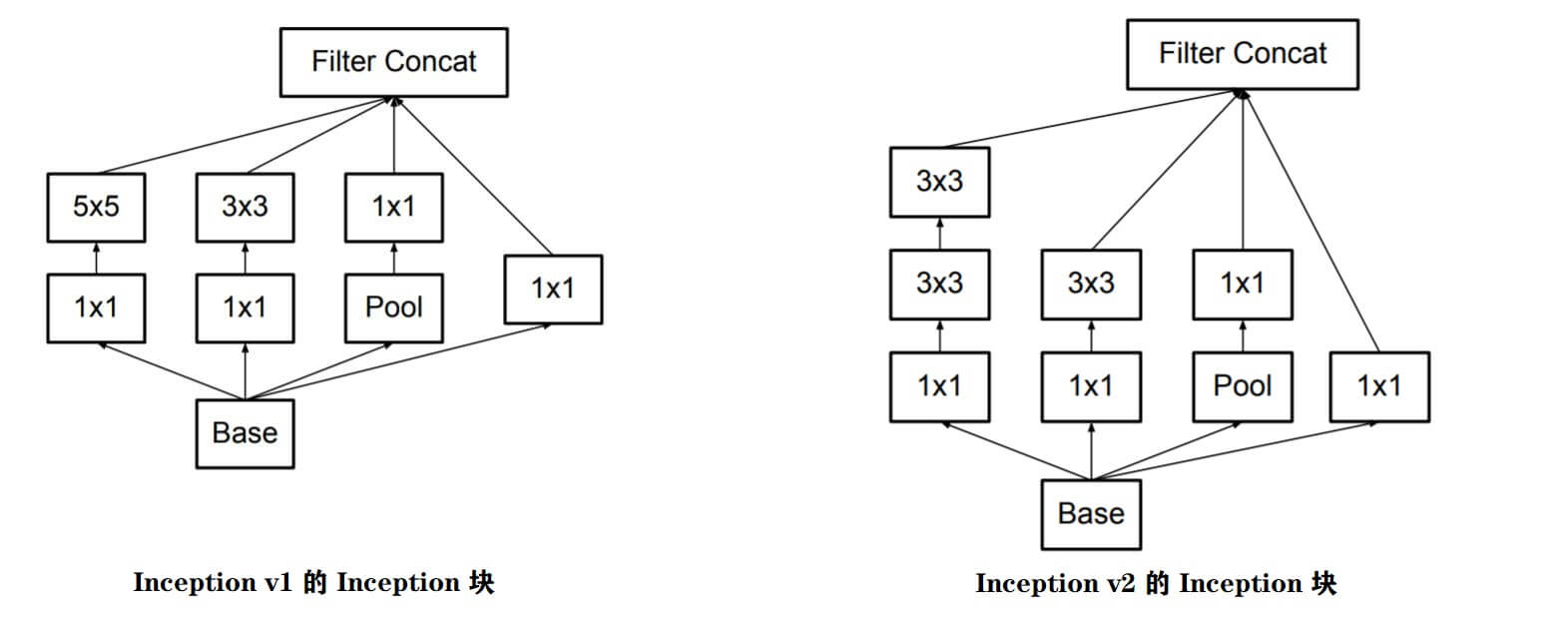
Inception v2基于VGG对用多个小卷积核代替大卷积核的思想, 将Inception v1中设计的Inception块进行了优化, 将5x5的卷积核替换为2个3x3的卷积核.
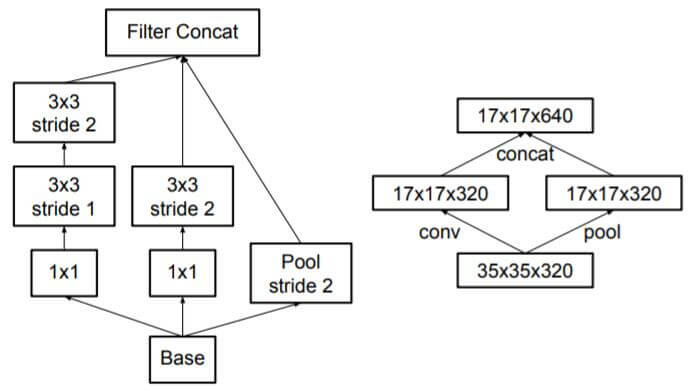
有没有能压缩更多参数的方法呢? 确实有, 通过非对称卷积, 每个nxn的卷积核都可以继续由1个1xn卷积核和1个nx1卷积核代替(Figure 6), 这样比原来参数更少, 也能实现更加高效的降维. 在Inception v2中, 设定n=7. 不要忘记论文开头的第一个原则, 在网络早期使用这种操作效果并不好. 除去降维外, 基于第二个准则, 设计了Figure 7 这种用来对特征提升维度的Inception模块. 提升后的高维特征更有益于模型的理解和处理, 也更加稀疏. 这种结构只在最后粗糙的8x8输入使用.
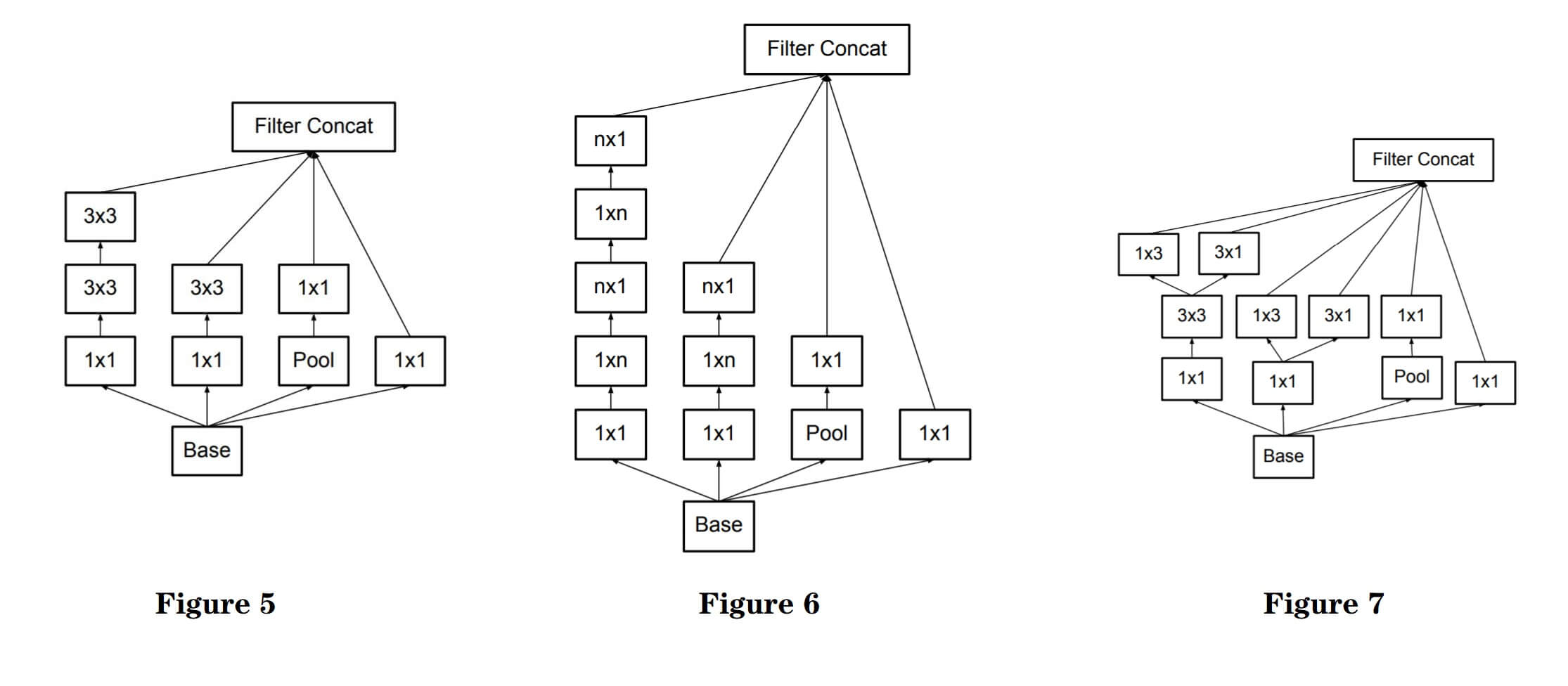
除此外, 还用并行结构对池化做了改进. 如果先池化后卷积可以减少, 直接进行池化, 可以减少运算量, 但会引入特征表示瓶颈. 为了遵循论文提出的第一个准则, 为了避免特征表示瓶颈, 先卷积后池化, 但这样运算量就会很大.
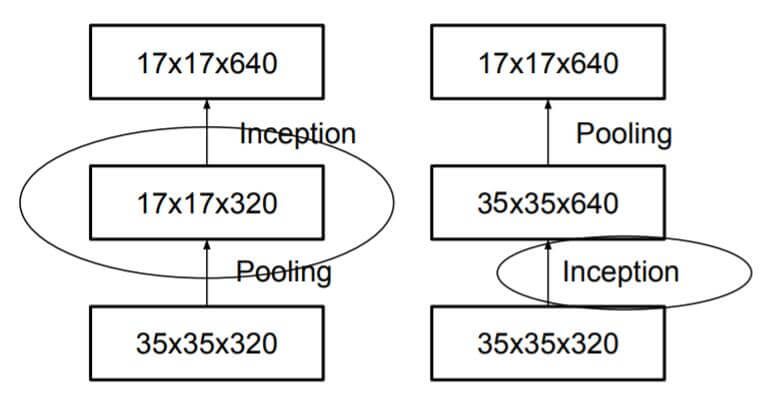
作者找到了一种两全其美的方法, 即卷积和池化同时进行, 再将它们的结果concat起来, 这样即避免了特征表示瓶颈, 也没有引入很多的计算量.
在Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift 中已经提到过Batch Normalization, 能够对网络模块之间达到解耦的效果, 加快收敛速度. 顺带改进了Inception v2.
相较于Inception v2, Inception v3只做了少量改动, 在先前基础上还进行了如下更改:
使用RMSProp做优化器.
使用标签平滑防止过拟合.
标签平滑可以看做是一种添加到损失公式中的一种正规化组件, 因为独热编码后的标签只有0和1, 可能有些过于绝对, 标签平滑提供了一种手段来使其中的0也能分配到一些数值. 我下面给出代码, 便能告诉你它的实现方式.
a = tf.constant([0, 0, 1.]) b = tf.constant([0, 1.]) # input_tensor is a tensor in tensorflow def label_smoothing(input_tensor, epsilon=0.1): classes = input_tensor.get_shape().as_list()[-1] # compute the number of classes return (1 - epsilon) * input_tensor + (epsilon / classes) print(label_smoothing(a)) print(label_smoothing(b)) # label smoothing(a): [0.03333334, 0.03333334, 0.93333334] # label smoothing(b): [0.05 0.95]辅助分类器使用了Batch Norm, 加快模型收敛速度.
7x7卷积拆成了1x7和7x1卷积的叠加, 同时输入图像从224x224变为299x299.
Inception v2/v3结构如下:
Inception v4
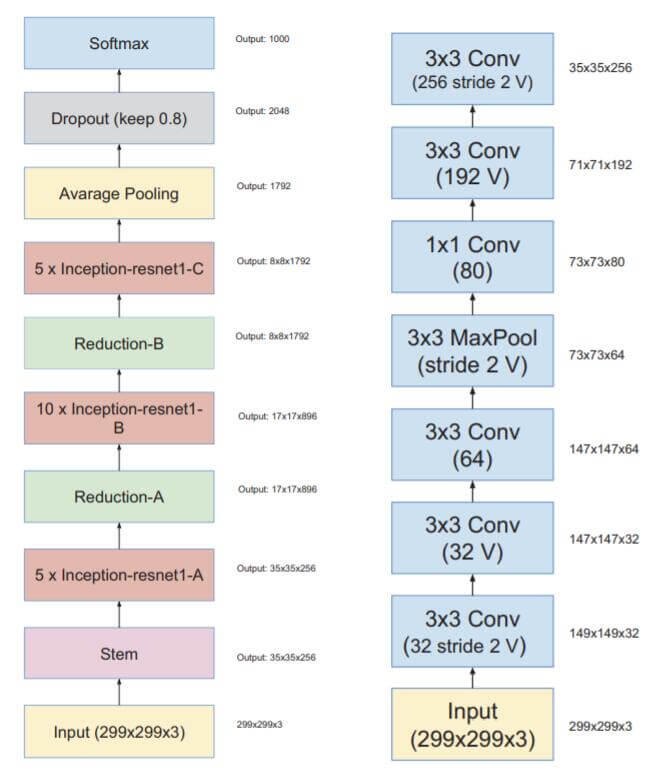
Inception v4比较保守, 对原来的版本进行了梳理, Inception v4在2016年的Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning中提出. 该论文中不但提出了Inception v4, 还借鉴了ResNet的思想, 研究了若干种Inception与残差连接之间的结合方式, 做了相当多的实验.
首先看Inception v4的大体结构(左)和主干部分(右):
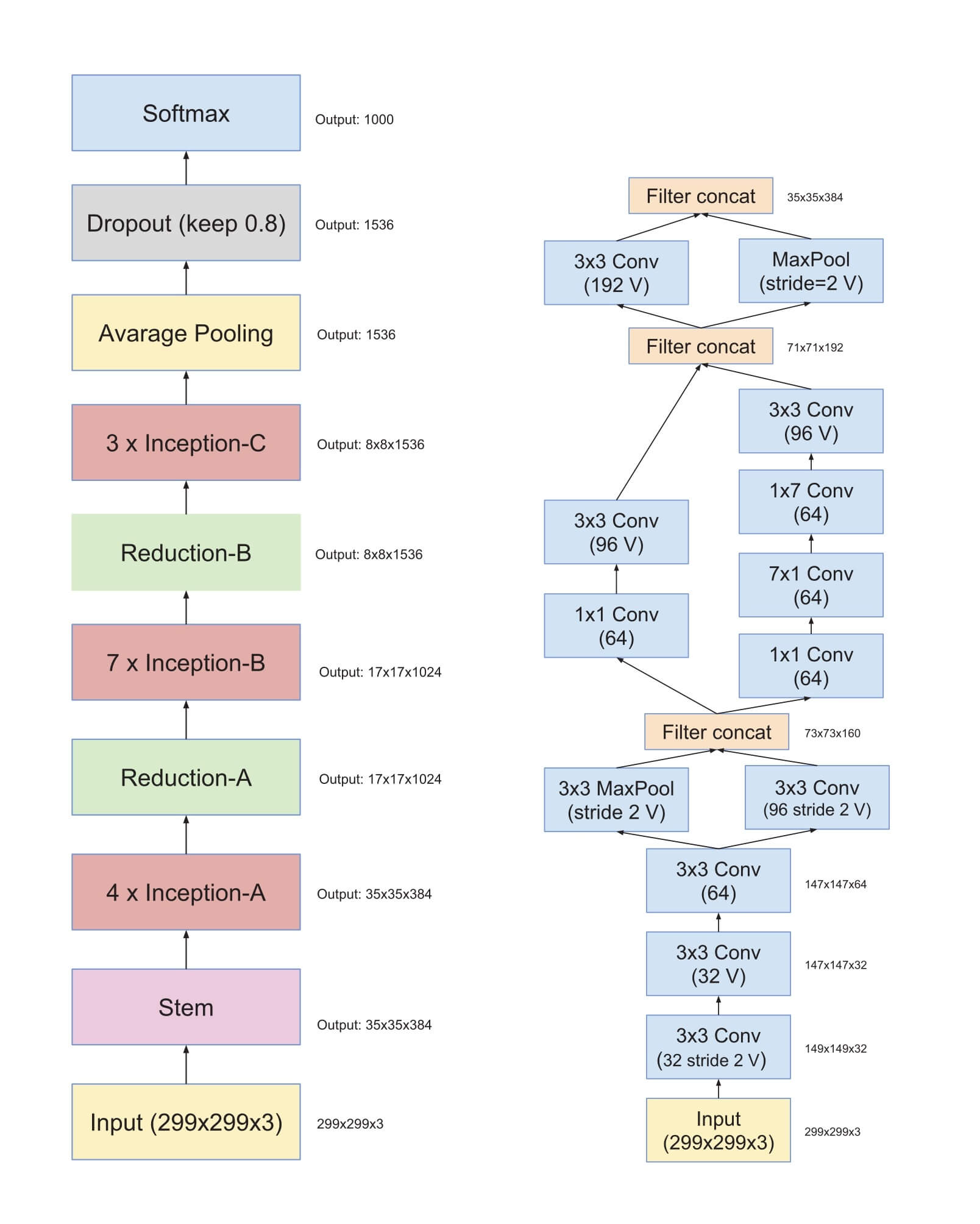
Inception模块都有了相应改动, 相比v3添加了平均池化和1x1卷积, 下图从左到右分别为Inception-A, Inception-B, Inception-C:
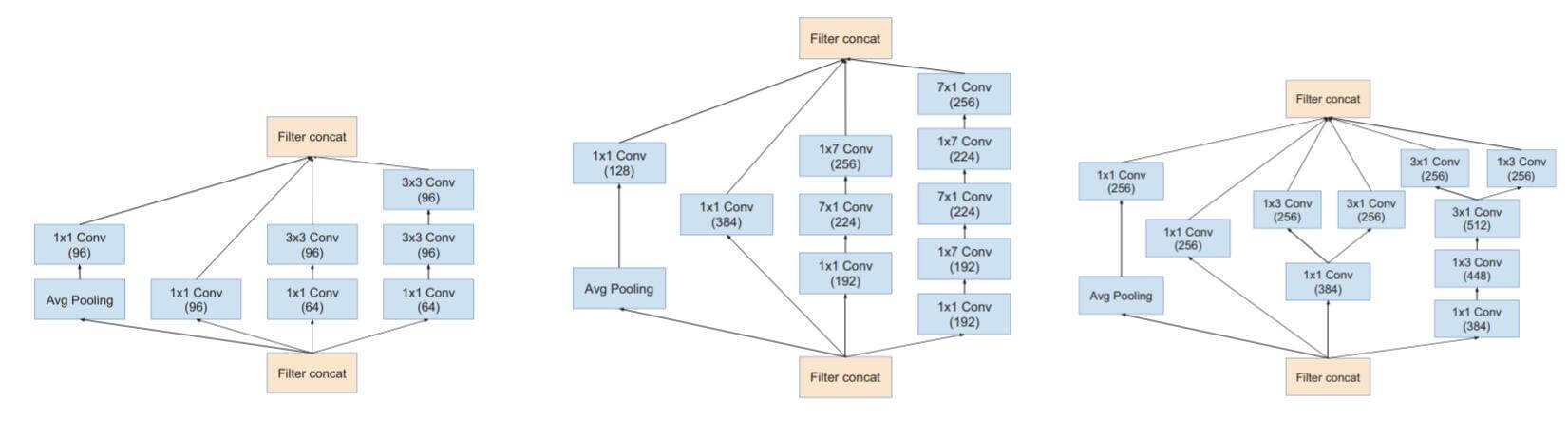
还有两种降维结构, 下图分别为35x35到17x17的Reduction-A和17x17到8x8的Reduction-B:

多次使用1x1卷积进一步降低了参数数量, 并且设计上更加简单一致, 抛去了Inception v3中不必要的部分, 比如辅助分类器等结构.
Inception-ResNet
Inception-ResNet结合了ResNet的思想, 与Inception v4出自同一篇论文. Inception-ResNet在Inception原有的基础上添加了残差链接, 作者研究了残差连接的作用, 指出残差连接并非能明显提升模型精度, 而是会加快训练的收敛速度. 在此基础上提出了两个版本的Inception-ResNet.
无论是Inception-ResNetv1还是Inception-ResNetv2都遵循同一个架构(左), 但Inception-ResNetv1采用了图示主干(右), 而Inception-ResNetv2却沿用了Inception v4的主干:
Inception-ResNetv1
Inception-ResNetv1采用的Inception块如下, 下图从左到右分别为Inception-ResNet-A, Inception-ResNet-B, Inception-ResNet-C:

35x35到17x17的Reduction与Inception v4相同, 17x17到8x8是新设计的结构:
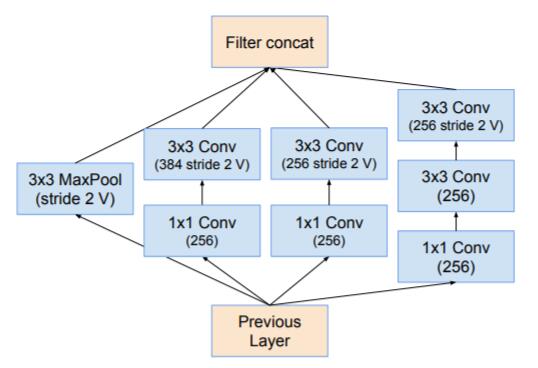
Inception-ResNetv1与Inception v3计算复杂度相近.
Inception-ResNetv2
Inception-ResNetv2沿用了Inception v4的主干, Reduction结构与Inception-ResNetv1完全相同.
只有三种j调节过参数的Inception-Res块. 其实v1和v2的不同只在于参数的不同和主干Stem的不同.

Inception-ResNetv2与Inception v4计算复杂度相近.
残差连接的问题
在引入残差连接后, 卷积核数量如果太多, 会导致训练不稳定, 甚至会出现网络训练休眠, 在池化层之前输出就为0. 对此引入一个放缩因子, 通过乘以一个非常小的系数再相加, 这样使得网络重新激活. 一般scale取0.1 ~ 0.3之间的值, 引入后不会降低精度还能使得网络更加稳定.

当然图中的Inception可以替换为任意的子网络.
Xception
2016年, Google利用深度可分离卷积对Inception v3进行了改良, 在Xception: Deep Learning with Depthwise Separable Convolution 中提出Xception模型(起名应该是模仿XGboost, 也是Extreme Inception的意思).
关于深度可分离卷积可以单独开一篇文章了, 为了保证Inception系列的完整性, 先挖个坑.
ResNet
在《卷积神经网络小结》一文中, 在残差块部分有对残差网络的描述.
随着网络深度的加深, 模型训练变得越来越复杂, 即使是使用Batch Norm或ReLU也无法解决梯度爆炸和梯度消失的现象, 仍然无法把网络做的足够深. 2015年何恺明在Deep Residual Learning for Image Recognition 中提出了带有跳跃连接的神经网络ResNet, 在2015年的ILSVRC中夺得冠军.
人们发现并不是网络越深性能越好, 例如下图中56层的模型无论是在训练集还是测试集的误差都比20层的模型要高得多, 到20层后的模型再向上堆叠效果反而会变差.
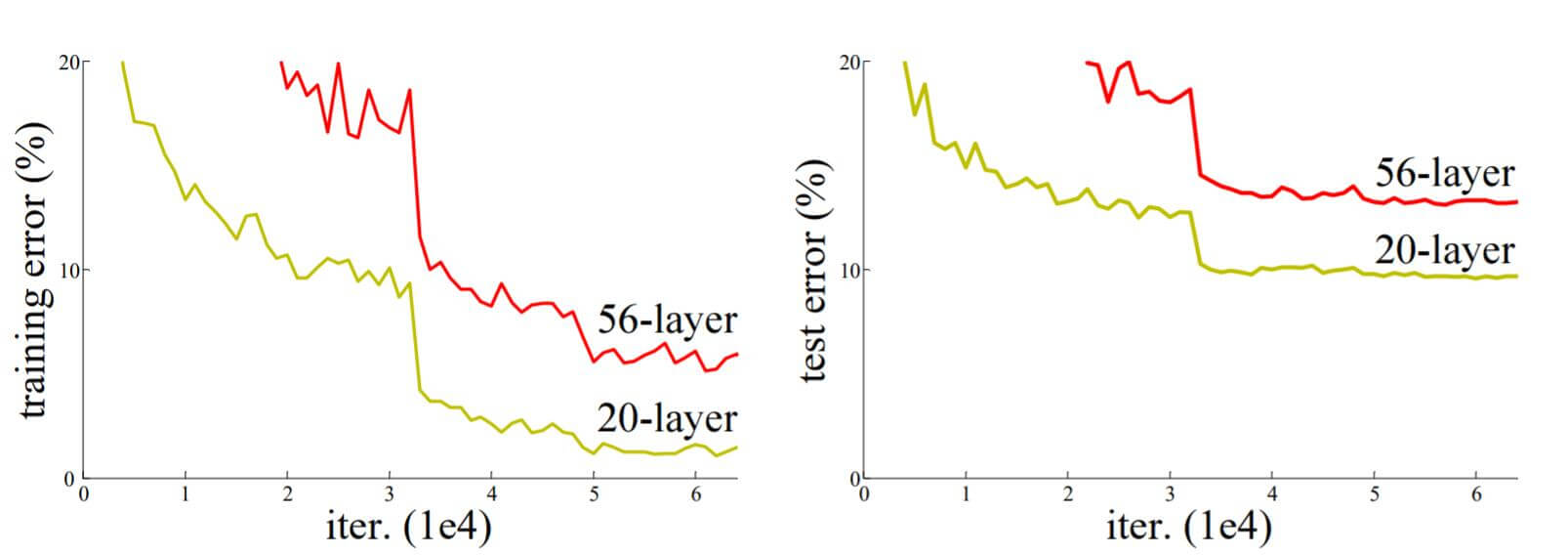
在反向传播中, 神经网络层数越多, 信息损失的就越多, 十分有可能发生梯度爆炸和梯度消失. 对于一个准确率近乎饱和网络来说, 再在这个网络的基础上添加新的结构是会使性能变差的, 上述问题也称为退化问题. 除非添加的神经层实现的映射是恒等映射 , 即f(x) = x, 这样就能使网络在加深的同时还没有增加误差, 解决了模型性能和模型深度之间的悖论. 也就是说如果某层已经达到了趋近于饱和的性能, 那么接下来的学习目标就变为学习恒等映射. 以保证后面的其他层不会因为冗余层而导致精度下降.
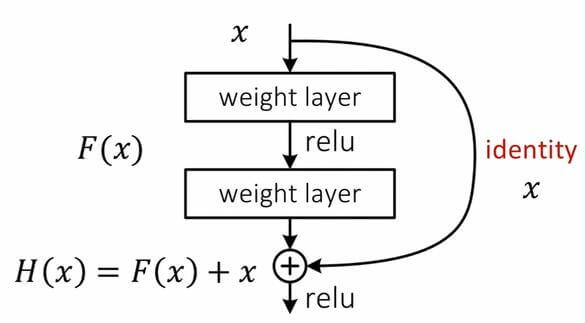
从图中能很明显的看出, 这种恒等映射思想和LSTM中的思想极其相似, 当时何恺明也是基于LSTM得到的启发. 二者都尝试通过借鉴邻近的短期信息来减缓深层模型带来的梯度消失或爆炸的问题, 使得邻近的特征得以更长的传播. 而加法与乘法不同, 加法的梯度变化取决于信息之间的独立叠加, 而非乘法一样体现出输入信息之间的相互控制.
“残差”二字来源于目标值H(x)与冗余层前的输入值x的差值, 即后面的学习目标应该使残差目标F(x) = H(x) - x 逼近与0. 这种跳跃连接也称为Skip connections, 这种结构有良好的数学性质, 在进行反向传播时, 恒等映射的导数为1, 不会造成导数丢失.
当然, 上述内容都不能违背一个基本假设: 对于一个有能力学习到恒等映射的深层网络, 它的性能绝对不会它的近乎饱和的浅层网络性能差.
ResNet结构与VGG19的对比图如下:
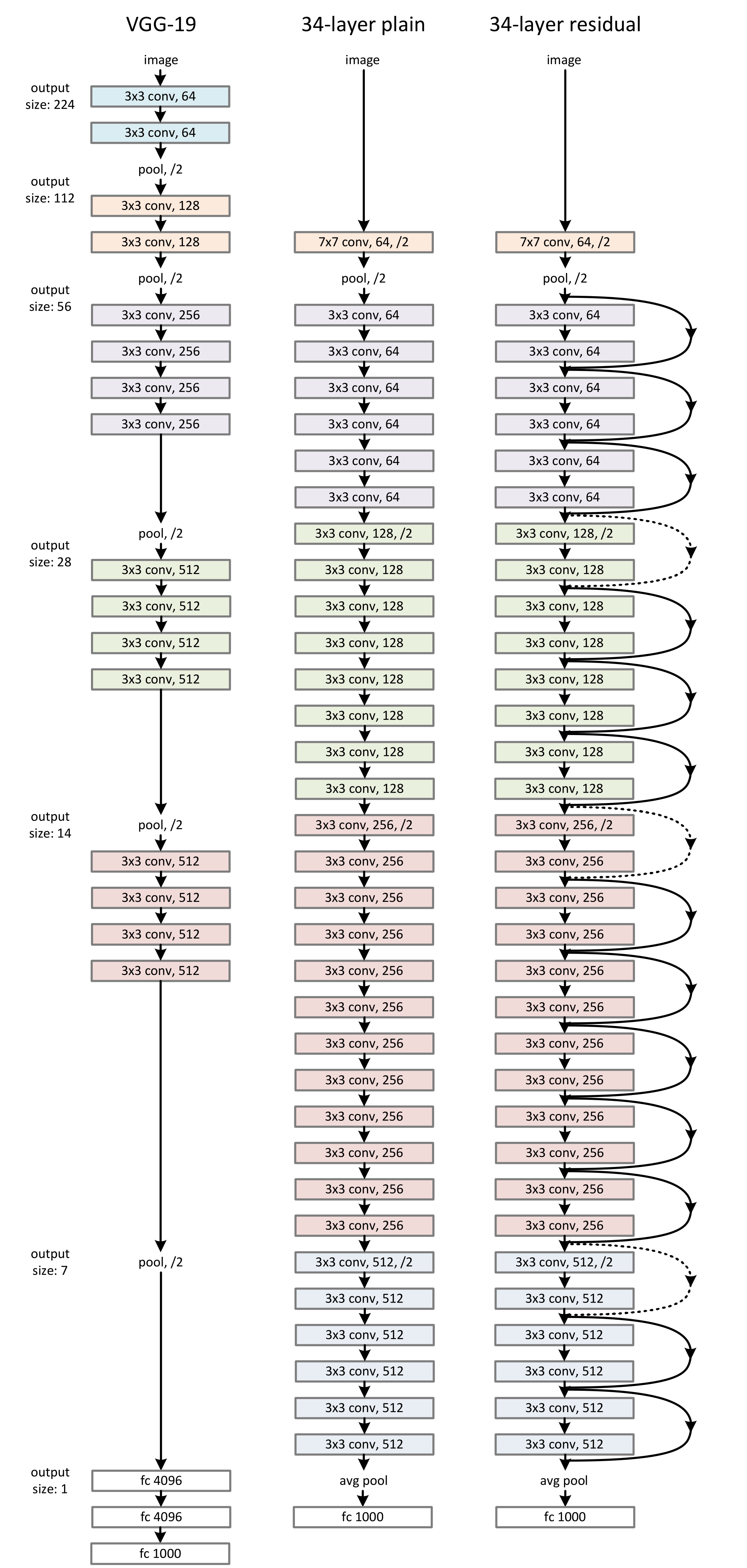
在最右侧, 有两种Skip connection的实现:
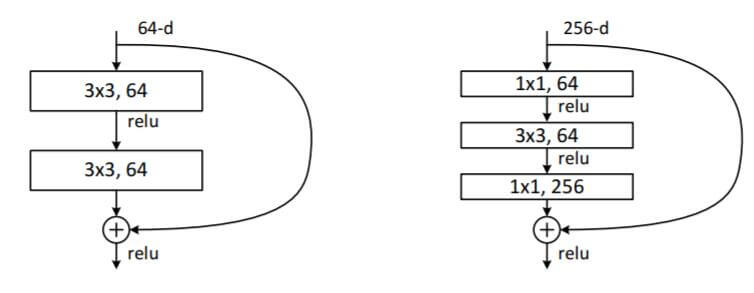
左侧对应的是实线的实现方式, 右侧对应的是虚线的实现方式. 虚线的残差块中采用了1x1卷积来降低参数数量. 对于更深层的网络必须采用右侧的实现方式.
在论文中, 作者给出了不同层数的ResNet设计参数:

ResNet确实也做到了使得网络足够深, 甚至能达到152层. 也解决了网络越深越难训练的问题. 但是冗余层过多会带来更多的计算问题. 并导致特征过于冗余.
DenseNet
为了解决ResNet在特征上的冗余问题, 在2016年Densely Connected Convolutional Networks中沿用了ResNet和Highway Network的思想, 提出了DenseNet. 在Skip connections的基础上实现了特征复用. 作者提出了Dense Block作为新的网络结构. 作者认为通过更多的连接能够保证层与层之间的信息能最大程度的保留.
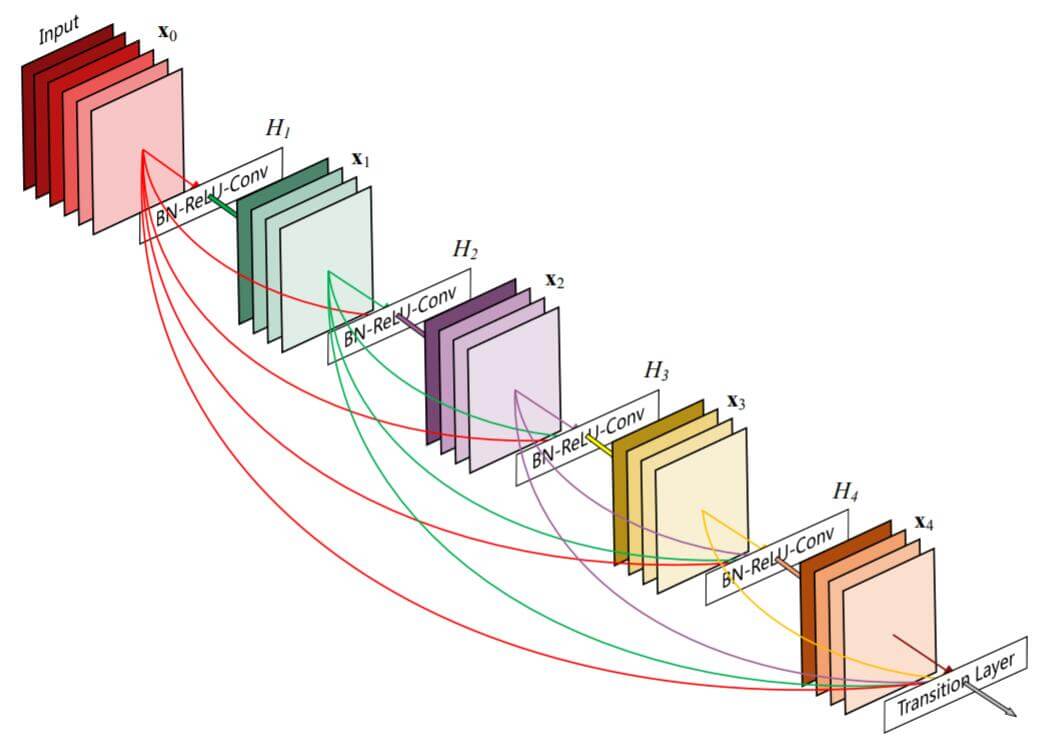
Dense Block 相对于Residual Block来说更为激进和密集, 将同一个块中所有的层进行互联, 即每层都会接收前面所有层的输出作为额外输入, 与ResNet不同的地方在于, 连接并非相加, 而是直接concat, 这样就必须在块与块之间添加减小特征维数的结构.

这种更密集的连接提供了更高的特征利用率, 在同等性能下减少了参数.
与ResNet相同, 在论文中作者也给出了不同深度的DenseNet设计参数:
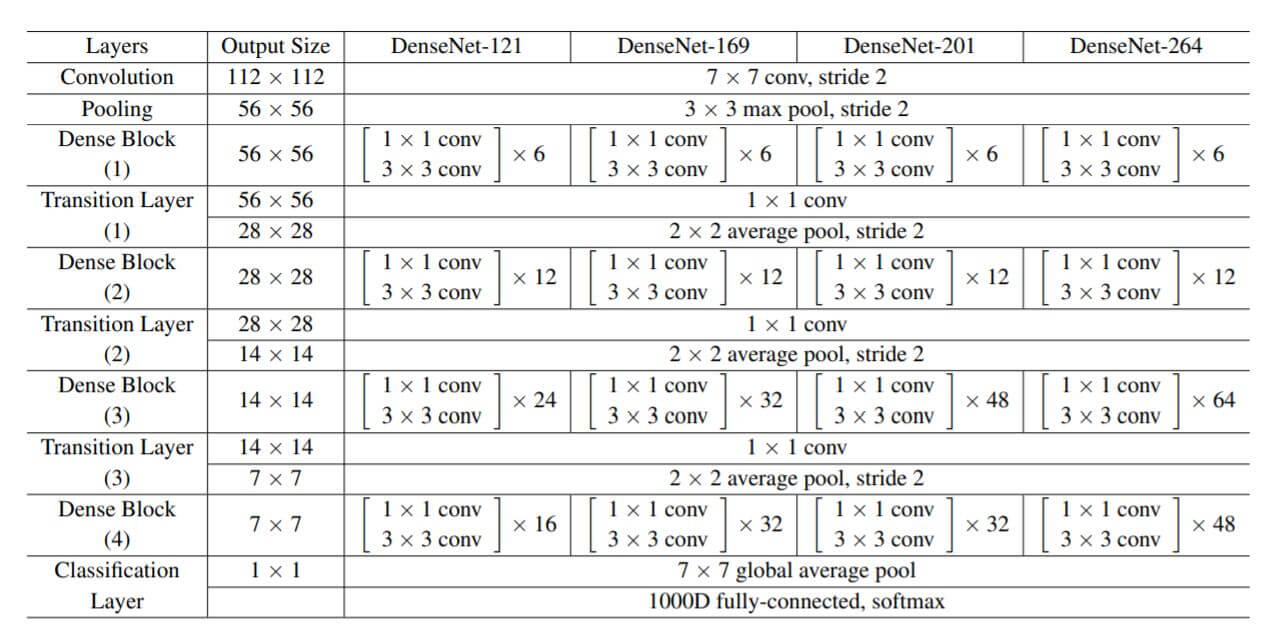
总结
本文的内容也都是浅尝辄止, 能够快速掌握近些年CNN的发展方向, 想深入了解还是需要精读论文. 由于CV方向应用落地快, 近些年CNN的研究也是突飞猛进, 提出了很多新CNN的结构, 这些新的结构并没有被写入.
下图出自Benchmark Analysis of Representative Deep Neural Network Architectures.
在这张图中, 圆圈越大, 模型参数越多, 圆圈越靠上, Top1准确率越高, 圆圈越靠右, 计算量越大. 相对位置越靠左上角, 模型的综合素质越好.
通过这种可视化, 可以更方便的对比模型之间的差距, 也方便梳理CNN的发展历史.
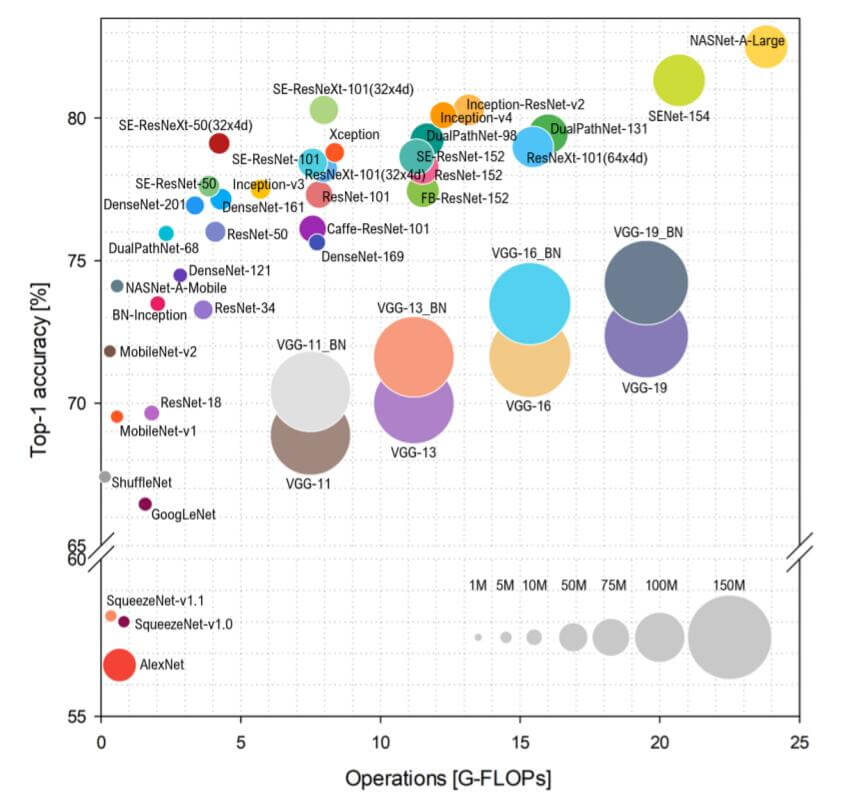
除文中提到的模型外, 在图中值得说一说的其他模型:
- SqueeeNet: 2016年提出, 虽然准确率不高, 但大幅减少了模型参数, 减少了对算力和硬件的需求.
- MobileNet: 2017年提出, 在维持其准确率的同时, 保证了移动端的使用.
- NASNet: 2017年提出, 使AI能够在特殊任务上自行优化网络结构.
- SENet: 2017年提出, 通过网络反馈对不同的Feature Map分配权重.

