2024.5.27: 稍微补充了UIE的其中一个改进版MetaRetriever.
本文前置知识:
扩展阅读:
通用信息抽取(上) - UIE, USM, InstructUIE
本文为介绍通用信息抽取领域经典模型的上篇, 介绍了UIE, USM, InstructUIE三个模型:
- UIE: ACL 2022, Unified Structure Generation for Universal Information Extraction.
- USM: AAAI 2023, Universal Information Extraction as Unified Semantic Matching.
- InstructUIE: 暂挂arxiv, InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction.
三个模型文中报告的实验效果依次递增, 碍于篇幅原因, 本文不包含对实验部分的解读, 对实验感兴趣的读者还请自行阅读.
UIE: Unified Structure Generation for Universal Information Extraction
第一个模型叫做UIE, 论文出自ACL 2022, Unified Structure Generation for Universal Information Extraction.
UIE算是打开了近年通用信息抽取的新时代.
我印象中, 当时是Generative Information Extraction刚冒出头的时候. 比较出名的有NER里面的BARTNER, 后来这种方法也被迁移到ABSA中叫BARTABSA, 它们可以直接从索引中抽取Span, 得到Target. 还有一类是直接做Text2Text的, 比如在EE里面的TEXT2EVENT, TANL, RE里的REBEL 等等, 按照结构化的规则用Language Modeling的方式生成Target. 上述两种方法虽然略有不同, 但它们都遵循着将输出结构线性化, 并结构化生成的原则, 来处理各类IE task.
这种生成式IE的发展, 和当时T5走上舞台以及人们对In Context Learning的探索脱不开关系.
那么, 各类任务都可以通过Generative的方式来实现, 这些任务是不是也可以统一到一起呢?
作者认为, 各类任务是可以在任务形式上得到统一的:
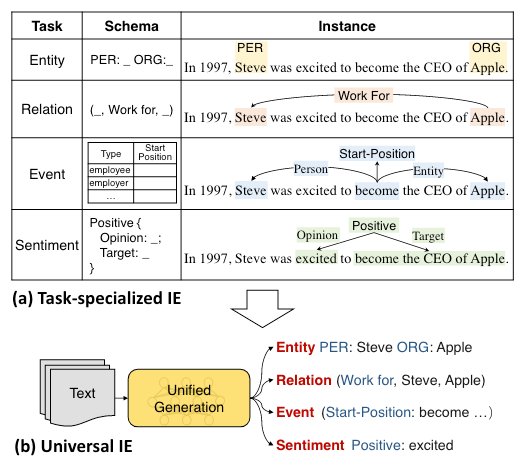
很明显的, 对于特定任务下的IE, 它们可以通过作者设定的结构化生成方式, 来将它们完成统一, 以此来利用不同IE task下跨任务的知识, 从而达到只用一个模型来兼顾各种任务的效果.
Unified Structure Generation for Universal Information Extraction
Structured Extraction Language for Uniform Structure Encoding
各类IE任务都可以被转化为text-to-structure的形式, 而任意IE结构生成的过程可以被拆分为两个原子操作:
- Spotting: 从句子中定位任务需要的目标信息片段, 比如一个实体或者触发词的位置.
- Associating: 判断两个片段之间的关联, 比如实体之间的关系, 或者是事件中每个论元扮演的事件角色.
作者将这两个操作在文本结构化生成中体现出来:

上述结构化的文本被作者称为Structured Extraction Language(SEL). 所以SEL就是要找到Spot Name的Span, 并且生成Span和Span之间的Asso Name. 作者通过这种嵌套的结构化文本来表征任意的IE任务目标.
作者在这里展示了一个例子, 对于句子Steve became CEO of Apple in 1997., 我们来一起完成RE, EE, NER三个经典IE任务:

- 蓝色: RE, 抽取出头实体
Steve, 尾实体Apple, 他俩之间的关系, 也就是Asso Name是work for. - 红色: EE, 抽取出事件类型
start-position, 触发词是became, 这个事件下对应的三个论元Steve,Apple,1997分别扮演employee,employer,time的事件角色. 所以这里的触发词是以SPOT结构存在的. - 黑色: NER, 实际上还有蓝色中也有一部分. 能抽取出
Steve,Apple,1997分别为person,organization,time类型的实体.
所以, SEL可以把任意的IE任务拆解为找Span, 和判断Span之间的关系这两个最小的操作.
Structural Schema Instructor for Controllable IE Structure Generation
在上面一节中可以发现, 不同的任务有不同的Schema, 所以必须要用某种方式把Schema引入, 并令它控制要抽取的内容. 所以作者提出了Structural Schema Instructor(SSI), 很自然的就能想到把Schema作为Prompt(在这里也可以称为Prefix)放到模型当中.
UIE整体的形式化为, 对于输入文本序列$x=[x_1, \dots, x_{|x|}]$, 和结构化的Schema $s=[s_1, \dots, s_{|s|}]$ , UIE直接将Schema和文本拼接到一起作为输入:
$$
y = \text{UIE}(s \oplus x)
$$
$y=[y_1, \dots, y_{|y|}]$ 为SEL序列.
Structural Schema Instructor
SSI的目的是描述任务, 并引导UIE抽取出任务需要的SEL. 所以它包含三个部分:
- SPOTNAME: 比如NER中的
person. - ASSONAME: 比如RE中的
work for. - 特殊Token: 比如
[spot],[asso],[text], 用来区分输入文本中的内容到底是归属于哪个部分.
输入文本Text加上SSI以后的UIE在做RE, EE, NER的例子如下:
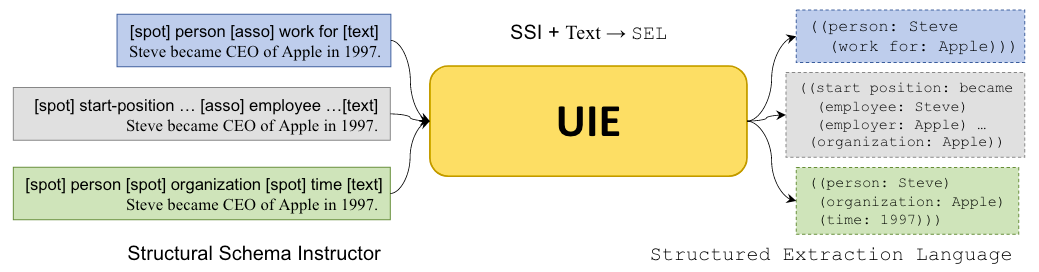
UIE的完整输入形式化描述如下:
$$
\begin{aligned}
s \oplus x= & {\left[s_1, s_2, \ldots, s_{|s|}, x_1, x_2, \ldots, x_{|x|}\right] } \\
= & {[[\text{ spot }], \ldots[\text { spot }] \ldots, } \\
& {[\text { asso }], \ldots,[\text { asso }] \ldots, } \\
& {\left.[\text { text }], x_1, x_2, \ldots, x_{|x|}\right] }
\end{aligned}
$$
这种SSI的方式在面对特别多数量的Spot或者Asso的时候, 会导致序列长度变得特别长, 附带一大坨东西, 详情可以看原论文的附录Table 11. 如果碰到这种情况, 对显存是不太友好的.
Structure Generation with UIE
对于给定的SSI $s$ 和输入句子$x$, UIE用Encoder-Decoder架构(T5, BART等为代表)来实现从 SSL + Text -> SEL 的转换. 作者在这里也是认为, 直接将结构化结果以生成式范式输出的好处在于, 可以直接共享预训练模型中的知识. 比如location 既可以表征它的自然语义, 也作为[asso], 所以文本和标签的知识是可以被共享的.
首先用Encoder得到输入句子的每个Token的表示$\mathbf{H}=\left[\mathbf{s}_1, \ldots, \mathbf{s}_{|s|}, \mathbf{x}_1, \ldots, \mathbf{x}_{|x|}\right]$:
$$
\mathbf{H}=\operatorname{Encoder}\left(s_1, \ldots, s_{|s|}, x_1, \ldots, x_{|x|}\right)
$$
然后是用Decoder自回归的完成解码:
$$
y_i, \mathbf{h}_i^d=\operatorname{Decoder}\left(\left[\mathbf{H} ; \mathbf{h}_1^d, \ldots, \mathbf{h}_{i-1}^d\right]\right)
$$
在输出<eos> 后表示输出终止.
Pre-training and Fine-tuning for UIE
Pre-training Corpus Construction
在预训练阶段的主要语料由以下三部分组成:
- $\mathcal{D}_{\text{pair}}$ 是按照Text-Structure准备好的平行语料, 记为$\mathcal{D}_{\text{pair}}=\set{(x, y)}$. 来自Wikipedia, 用于UIE的预训练, 赋予UIE这种文本转结构化输出的能力.
- $\mathcal{D}_{\text{record}}$ 是只有$y$ 的结构化数据(也就是文中所说的SEL), 来自ConceptNet和Wikidata.
- $\mathcal{D}_{\text{text}}$ 是无结构化文本, 来自Wikipedia.
Pre-training
作者以T5-v1.1为预训练模型, 完成Seq2Seq任务. 对于上述三种不同的数据格式构成的数据源, 作者分别拿它们过来做了不同的预训练:
- Text-to-Structure Pre-training using $\mathcal{D}_{\text{pair}}$: 作者认为, 只用Positive Schema可能会导致UIE的泛化能力不足, 所以作者还构建了Negative Schema来增强UIE的泛化能力. 记Positive Schema为$s_{+}=s_{\mathrm{S}+} \cup s_{\mathrm{a}+}$, 作者随机采样出Negative Spot $s_{\mathrm{S}-}$ 和Negative Asso $s_{\mathrm{a}-}$, 从而构建出Meta Schema $s_{\text{meta}}= s_{+} \cup s_{\mathrm{S}-} \cup s_{\mathrm{a}-}$, 然后在Meta Schema上完成训练:
$$
\mathcal{L}_{\text {Pair }}=\sum_{(x, y) \in \mathcal{D}_{\text {pair }}}-\log p\left(y \mid x, s_{\text {meta }} ; \theta_e, \theta_d\right)
$$
其中$\theta_e, \theta_d$ 分别为Encoder和Decoder的参数.
- Structure Generation Pre-training with $\mathcal{D}_{\text{record}}$: 因为$\mathcal{D}_{\text{record}}$ 只有$y$, 所以UIE Decoder这时候直接单独拿出来用, 当成传统意义上的Language Model来用, 直接生成SEL:
$$
\mathcal{L}_{\text {Record }}=\sum_{y \in \mathcal{D}_{\text {record }}}-\log p\left(y_i \mid y_{<i} ; \theta_d\right)
$$
- Retrofitting Semantic Representation using $\mathcal{D}_{\text{text}}$: $\mathcal{D}_{\text{text}}$ 是无结构化文本$x$. 在text-to-structure pre-training时, 作者也像T5一样使用了MLM的Denoising task, 来将损坏的文本恢复出来:
$$
\mathcal{L}_{\text {Text }}=\sum_{x \in \mathcal{D}_{\text {text }}}-\log p\left(x^{\prime \prime} \mid x^{\prime} ; \theta_e, \theta_d\right)
$$
其中$x^\prime$ 为Corrupted Text, $x^{\prime\prime}$ 为重建的目标Span.
作者提到, 这个任务可以有效的解决对
SPOTNAME和ASSONAMEToken语义的灾难性遗忘.作者没有详细解释, 我个人的理解是, 因为Label和Text的知识被共享, 也确实插入了
[spot], [asso], [text]这样的Token来区分某个Token到底是Text还是SSI, 但Text仍然可能被插入的SSI所污染, 而且也容易导致Token在SSI和Text之间的语义混淆. MLM任务执行的时候是没有SSI插入的, 所以我更倾向于认为, 这里用一个MLM的任务是为了保证Token作为纯文本时的语义能被一定程度的保留. 而且这个任务是继承T5的, 感觉还是为了保持预训练时候的一些能力.
如果把(SSI, Input, Output)看成一个三元组, 可以将上面三个任务归纳一下:
| Data | SSI | Input | Output |
|---|---|---|---|
| $\mathcal{D}_{\text{pair}}$ | $s$ | $x$ | $y$ |
| $\mathcal{D}_{\text{record}}$ | None | None | $y$ |
| $\mathcal{D}_{\text{text}}$ | None | $x^\prime$ | $x^{\prime\prime}$ |
最后的Loss就是上面说的三者加在一起:
$$
\mathcal{L}=\mathcal{L}_{\text {Pair }}+\mathcal{L}_{\text {Record }}+\mathcal{L}_{\text {Text }}
$$
On-Demand Fine-tuning
在预训练过后, UIE需要在某个IE Task上做微调. 对于给定的有标签的语料$\mathcal{D}_{\text {Task }}=\set{(s, x, y)}$, 直接在语料上用Teacher-Forcing做Finetune即可:
$$
\mathcal{L}_{\mathrm{FT}}=\sum_{(s, x, y) \in \mathcal{D}_{\text {Task }}}-\log p\left(y \mid x, s ; \theta_e, \theta_d\right)
$$
为了缓解曝光偏差问题, 作者提出了拒绝机制. 即在SEL $y$ 中, 以概率$p_\epsilon$ 随机的插入一些Negative spot和Negative asso, 并将它们对应的info span设定为[NULL]:

如上例中, 如果模型错误的生成了SPOTNAME: facility, 模型仍然在自回归生成的下一步有可能生成[NULL] 来撤销这次错误的生成.
Paddle-UIE
非常值得一提的是, 这篇工作的一部分是本文的一作和二作在百度实习时完成的, 所以百度在这篇文章中稿后, 也发布了Paddle版本的UIE, 是一个开箱即用的模型, 并且有各种不同的规模, 非常的方便, 读者可以自行尝试.
不过Paddle版本的UIE的实现方式并不同, 只是利用了UIE的大致思想, 通过构建Prompt的方式, 并用两个FFN来轮询每个Schema Element在文中对应的Span, 基座用的则是ERNIE:
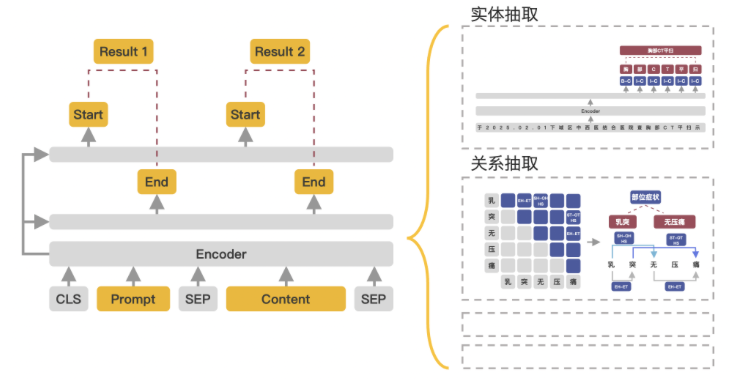
虽然UIE非常简单, 说白了就是T5 + 结构化生成来做IE任务, 但它确实成为了近两年通用IE中非常具有里程碑意义的方法.
不得不说, 在LLM兴起的前夕这个节骨眼下, UIE算是给信息抽取任务统一打了个样.
另外, 在ACL Findings 2023上也有一个基于检索的UIE改进方法MetaRetriever, 用Meta Learning教会模型从Knowledge Base里面检索知识, 然后用检索到的知识作为上下文再做UIE:
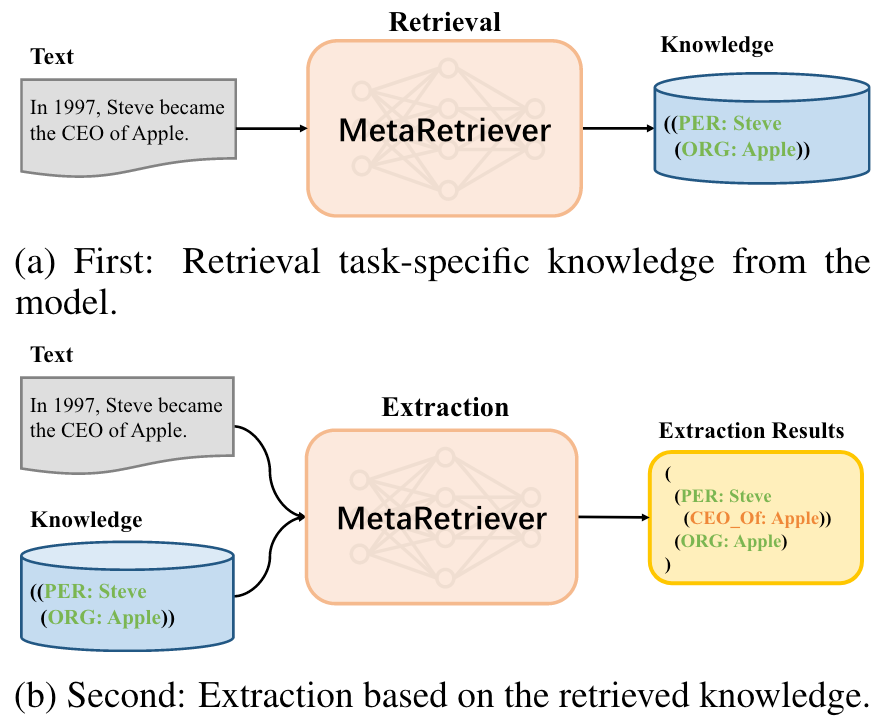
所以它是一种检索增强的方法. 如果单从效果上来讲, 不如我们接下来要讲的UIE续作USM.
USM: Universal Information Extraction as Unified Semantic Matching
第二个模型叫做USM, 论文出自AAAI 2023, Universal Information Extraction as Unified Semantic Matching.
名字上一看就知道, USM和UIE一脉相承, 事实上USM是UIE的续作.
USM认为, UIE是一个Seq2Seq的黑盒, 非常难以确定什么时候UIE的知识迁移有效, 什么时候无效, 所以需要对知识的显式建模, 以明确知识迁移的有效性, 鲁棒性和可解释性.
因此, USM将所有IE任务解耦为两个操作, Structuring和Conceptualizing:
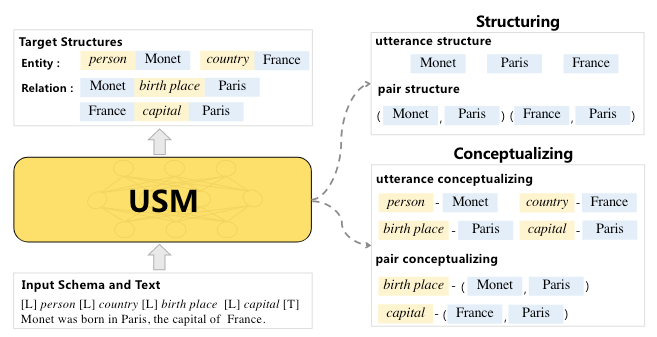
- Structuring: 从句子中抽取和标签无关的基本子结构, 其实就是抽取文本和文本对. 比如抽取Entity Mention
Monet, 事件触发词born in, 或者某种关系的实体对(Monet, Paris), 或者事件的论元(born in, Paris). - Conceptualizing: 将子结构与目标语义标签对应, 也就是对文本或者文本对的标签做判定. 比如说使得语义标签
person和Entity MentionMonet相对应, 它的含义就是判断Monet的实体类型为person.
其实这两个操作和UIE中的Spotting和Associating的本质是一样的, 都是找Span, 和判断Span之间的关系. 或者甚至可以说, 信息抽取各类任务的目标就是在找Span和Span之间的关系.
当标签以语义Token的形式给定的时候, 上述两个操作可以统一的被抽象成一个Directed Token Linking的操作, 并且可以使得所有IE Task共享知识.
Unified Semantic Matching via Directed Token Linking
USM的Linking包含三种类型, 再通过Schema约束的解码就可以得到目标输出:
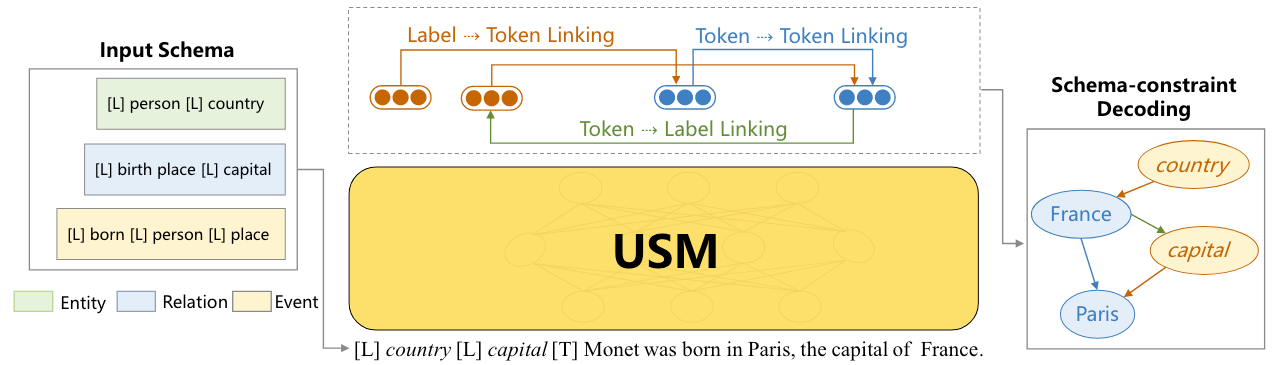
Schema-Text Joint Embedding
首先, 我们用一个Encoder来同时编码Schema Token $l=\set{l_1, l_2, \dots, l_{||}}$ 和Text Token $t=\set{t_1, t_2, \dots, t_{|t|}}$ 一并拼接后的序列, 得到一个Label-Text联合编码的表示$\mathbf{H}=\left[\mathbf{h}_1, \mathbf{h}_2, \dots, \mathbf{h}_{|l|+|t|}\right]$:
$$
\mathbf{H}=\operatorname{Encoder}\left(l_1, l_2, \ldots, l_{|l|}, t_1, t_2, \ldots, t_{|t|}, \mathbf{M}\right)
$$
其中$\mathbf{M} \in \mathbb{R}^{(|l| + |t|) \times (|l| + |t|)}$ 为Attention的Mask矩阵, 来控制每个Token是否能给予其他Token注意力.
Directed Token Linking
Token-Token Linking for Structuring
我们在之前说过, Structuring需要抽取句中的文本和文本对, 它们分别被称为Utterance和Association Pair(也是Span Pair, 记为(Subject, Object)), 它们均可以用Token Linking的方式实现:
- Utterance的抽取即同一个连续Span的Head Token和Tail Token的Linking(H2T). 比如某个实体的Entity Mention.
- Association Pair的抽取即两个存在关联的Span的Head Token的Linking(H2H)和Tail Token的Linking(T2T), 也就是头对头尾对尾. 比如关系三元组的实体对, 或者是事件中的触发词和论元对.

综上, 每个Token Pair $\left\langle t_i, t_j\right\rangle$ 是否存在Token-Token Linking (H2T, H2H, T2T), 可以通过计算得分$\mathbf{s}_{\mathrm{TTL}}\left(t_i, t_j\right)$ 来判断:
$$
\mathbf{s}_{\mathrm{TTL}}\left(t_i, t_j\right)=\operatorname{FFNN}_{\mathrm{TTL}}^l\left(\mathbf{h}_t^i\right)^T \mathbf{R}_{j-i} \operatorname{FFNN}_{\mathrm{TTL}}^r\left(\mathbf{h}_t^j\right)
$$
其中, $\operatorname{FFNN}^{l/r}$ 为输出大小为$d$ 的前馈神经网络, $\mathbf{R}_{j-i} \in \mathbb{R}^{d \times d}$ 为苏神提出的RoPE, 用于编码Token之间的相对位置关系.
Label-Token Linking for Utterance Conceptualizing
下面需要对Label和Token之间做Token Linking, 来完成前面提到的Conceptualizing, 这一小节中先处理Utterance.
对于给定的Label Token Embedding $\mathbf{h}^l_1, \mathbf{h}^l_2, \dots, \mathbf{h}^l_{|l|}$ 和Text Token Embedding $\mathbf{h}^t_1, \mathbf{h}^t_2, \dots, \mathbf{h}^t_{|t|}$, Utterance Conceptualizing需要判断Label Token和Utterance Token或者Association Pair中的候选Object之间是否有链接.
这一操作的就把Text Mention指向了Label, 比如NER中的(person, Monet), (country, France), 或者EE中事件类型和触发词构成的元组(born, born in), RE中关系类型和尾实体构成的元组(birth place, Paris).
其实上面的例子包含了两种情况:
- 把Span的标签直接分配给Span, 比如NER的Entity Type分配给Entity Mention.
- 把Span Pair之间的关系标签分配给Association Pair中的Object, 比如RE中把关系类型分配给Object.

如果做Label和Span的Linking, 则需要分别链接Label Head Token和Span Head Token(L2H), Label Tail Token和Span Tail Token(L2T).
与前面类似的, 每个Label-Text Token Pair $\left\langle l_i, t_j\right\rangle$ 是否存在Label-Token Linking(L2H, L2T), 通过计算得分$\mathbf{s}_{\mathrm{LTL}}\left(l_i, t_j\right)$ 来判断:
$$
\mathbf{s}_{\mathrm{LTL}}\left(l_i, t_j\right)=\operatorname{FFNN}_{\mathrm{LTL}}^{\text {label }}\left(\mathbf{h}_i^l\right)^T \mathbf{R}_{j-i} \operatorname{FFNN}_{\mathrm{LTL}}^{\text {text }}\left(\mathbf{h}_j^t\right)
$$
Token-Label Linking for Pairing Conceptualizing
这节来处理Association Pair的概念化.
因为在Utterance Conceptualizing中, 我们已经建立了Label到Association Pair中的Object的链接了, 所以我们只需要将Association Pair中的Subject再有向链接到Label, 就可以根据多条路径来确定一个三元组(Subject, Association, Object).
这三条路径分别是:
- Token-Token Linking构造的
(Subject, Object). - Label-Token Linking构造的
(Association, Object). - 即将在Token-Label Linking中构造的
(Subject, Association).

如果要从Span链接到Label, 则需要分别链接Span Head Token和Label Head Token(H2L), 以及Span Tail Token和Label Tail Token(T2L).
类似的, 每个Text-Label Token Pair $\left\langle t_i, l_j\right\rangle$ 是否存在Token-Label Linking(H2L, T2L), 通过计算得分$\mathbf{s}_{\mathrm{TLL}}\left(t_i, l_j\right)$ 来判断:
$$
\mathbf{s}_{\mathrm{TLL}}\left(t_i, l_j\right)=\operatorname{FFNN}_{\mathrm{TLL}}^{\mathrm{text}}\left(\mathbf{h}_i^l\right)^T \mathbf{R}_{j-i} \mathrm{FFNN}_{\mathrm{TLL}}^{\text {label }}\left(\mathbf{h}_j^t\right)
$$
Schema-constraint Decoding for Structure Composing
跟着作者来看一个具体的例子, 感受一下Linking和解码的流程:
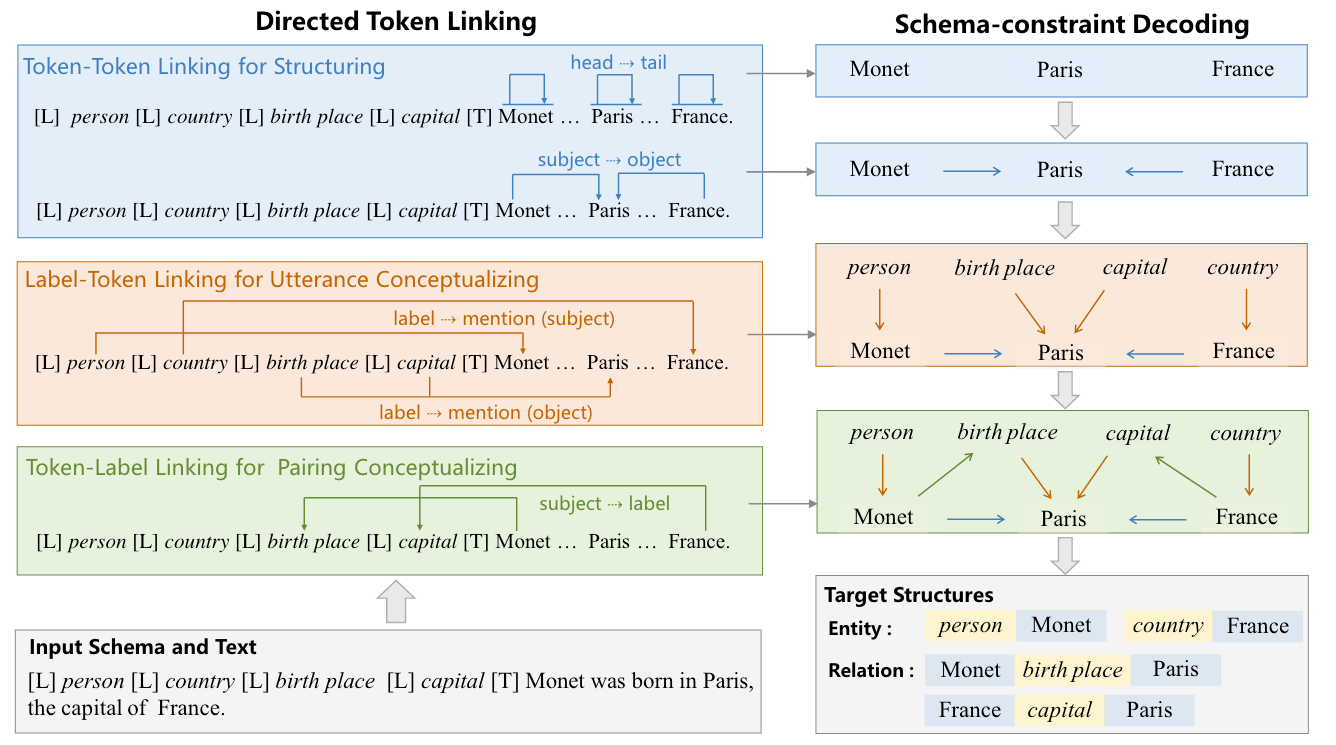
对于输入的Schema[L] person [L] country [L] birth place [L] capital [T] 和输入句子 Monet was born in Paris, the capital of France, 有:
- 首先经过Token-Token Linking, 抽取得到
Monet,Paris,France,(Monet, Pairs),(France, Pairs). - 然后通过Label-Token Linking, 得到
(person, Monet),(country, France),(birth place, Paris),(capital, Paris), 这样就得到了Label对应的候选Object. - 最后用Token-Label Linking, 得到
(Monet, birth place),(France, capital), 完成Subject和Label的链接. - 由于第一步, 抽取得到
(Monet, birth place),(France, capital). 并且基于第一步的结果, 抽取得到两个三元组(Monet, birth place, Paris),(France, capital, Paris).
该过程中, 抽取是互不干扰且高度并行的.
到这里, USM的模型部分就全部讲解完了. 不知道读者是否能联想到, USM实际上是UniRel的超集.
Learning from Heterogeneous Supervision
Pre-training
USM采用了三种有监督信号来预训练:
- $\mathcal{D}_{\text{task}}$: 有标训练数据, 也就是IE特定的数据.
- $\mathcal{D}_{\text{distant}}$: 远程监督数据, 有文本和知识库对齐的数据, 在这个过程中也使用了UIE中的Meta Schema.
- $\mathcal{D}_{\text{indirect}}$: 间接监督数据, 由其他可能与IE相关任务的数据组成, 比如MRC相关, KBQA相关的数据.
我感觉这个间接监督用的挺巧, 我估计作者这里用的MRC数据大多是抽取式MRC的数据, 任务形式其实和信息抽取是完全一样的.
作者在文中写到, 每条MRC数据由
(question, context, answer)组成, question就可以当做Label Schema, answer当做Mention, Context当做输入文本. 这样还增强了USM的泛化能力.
Learning function
在预训练时, 所有数据集都可以被表示为$\set{(x_i, y_i)}$, $x_i, y_i$ 分别为文本和USM的Linking标签(就是TTM, LTM, TLM对应的三张表). 因为表中会出现很多负样本Token Pair, 非常稀疏, 所以作者在这里采用了苏神的了类别不平衡Loss作为损失函数:
$$
\begin{aligned}
\mathcal{L}=\sum_{m \in \mathcal{M}} & \log \left(1+\sum_{(i, j) \in m^{+}} e^{-s_m(i, j)}\right) +\log \left(1+\sum_{(i, j) \in m^{-}} e^{s_m(i, j)}\right)
\end{aligned}
$$
其中$\mathcal{M}$ 代表USM的三种Linking Type, $m^+$ 代表有链接的Token Pair, $m^-$ 代表没有链接的Token Pair. $s_m(i, j)$ 代表Linking操作$m$ 下Token Pair $(i, j)$ 之间的Linking得分.
在特定IE Task上使用时, 还需要继续Finetune.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
第三篇论文是InstructUIE, 论文暂挂了arxiv, InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction.
在LLM时代, 有UIE必有InstructUIE.
作者首先是对比了之前的UIE, USM, 和本文提出的InstructUIE的区别:
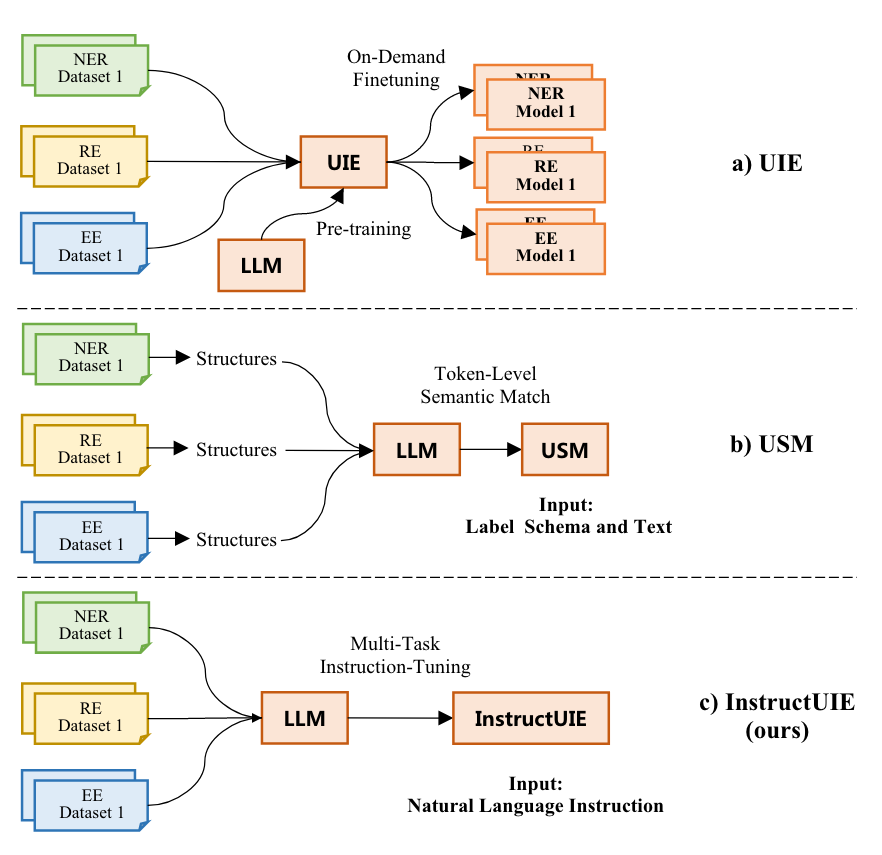
作者对于UIE和USM中写的”LLM”都是广义LLM, 比如T5-base / large或者BERT-base / large这种级别的模型, 而非LLaMA这样的狭义LLM, InstructUIE采用的才是7B及以上的这种狭义LLM.
作者认为:
- UIE需要在每种任务上进行Finetune, 导致对没见过的Schema或者在低资源场景下表现会差.
- USM有两个缺陷, 第一个是将IE转化为语义匹配任务, 使得USM难以应用在生成类模型下. 第二是需要对每个词都做语义匹配, 导致了训练和推理时间的增加.
我感觉, UIE的缺陷是因为它采用的T5-v1.1 base / large规模不够大, 而作者描述的USM的这两个缺陷也并不存在, 十几B的LLM自回归生成难道会比USM的二三百M的模型时间短吗?
Overview
其实LLM来做UIE, 直接用图里的内容就能完全概括:
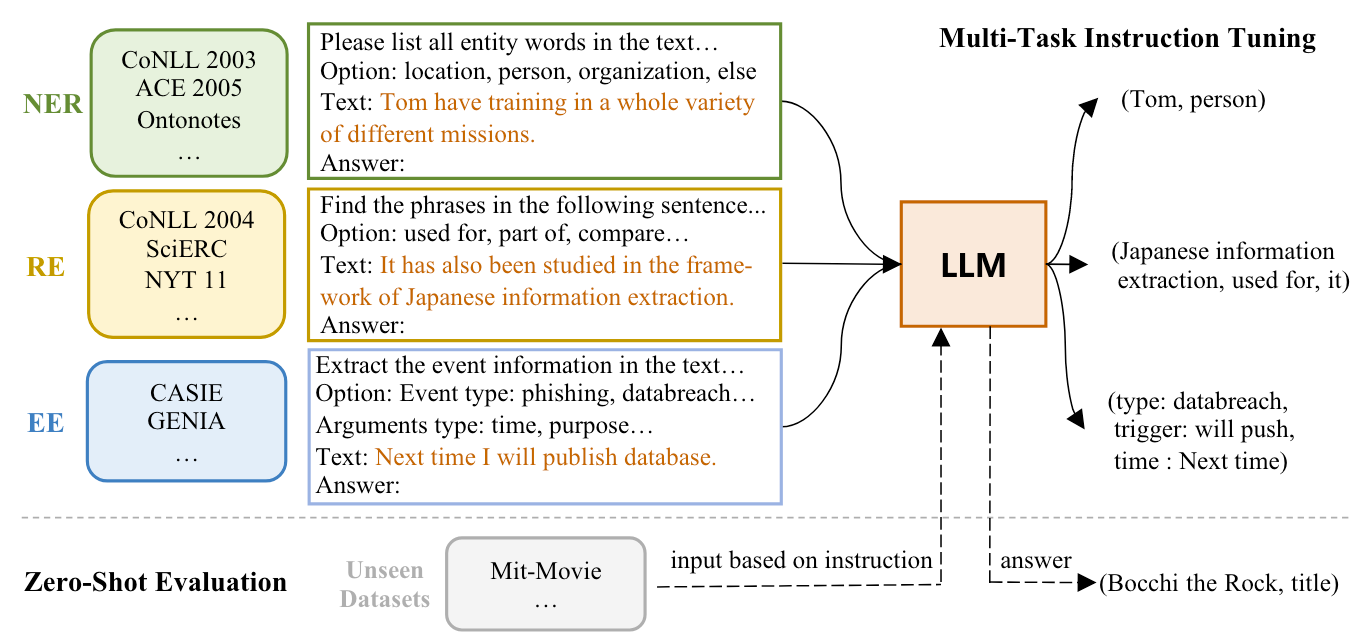
就是用Instruct Tuning指挥LLM, 在自然语言驱动下完成各类IE任务. InstructUIE采用FlanT5 11B作为预训练基座.
Task Schema
在预训练阶段, InstructUIE采用所有有标数据作为训练数据. 输入到LLM中的内容由以下内容组成:
- Task Instruction: 用自然语言描述的能指挥LLM完成指定IE任务的Instruct. 比如NER任务中的其中一条Instruct为
Please list all entity words in the text that fit the category. Output format is "type1: word1; type2: word2".. - Options: 对输出标签做的约束, 比如NER的实体类型仅能为
person,organization,location等等. - Text: 要预测的句子文本.
LLM要输出的内容就是任务的直接结果. 不同任务的预期输出不同:
- NER:
entity tag: entity span. - RE:
relationship: head entity, tail entity. - EE:
event tag: trigger word, argument tag: argument span. - 当没有任何结构化信息时则输出
None.
Auxiliary Tasks
作者还提出了一系列辅助任务来保证InstructUIE的性能:
- NER: 额外加入抽取Span, 对实体类型的判断.
- RE: 抽取有关系存在的实体对, 对实体对之间的关系进行判断.
- EE: 识别事件的触发词, 识别事件的论元.
其实就是把各类IE任务拆解为粒度更细的子任务, 来提升LLM对这个任务的理解能力.
IE INSTRUCTIONS
作者提出了一个新的数据集IE INSTRUCTIONS, 该数据集收集了在NER, RE, EE上共32个公开可用的数据集, 并保证了它们的多样性, 数据来自于科学, 医疗, 社交媒体, 交通, 新闻百科等领域:
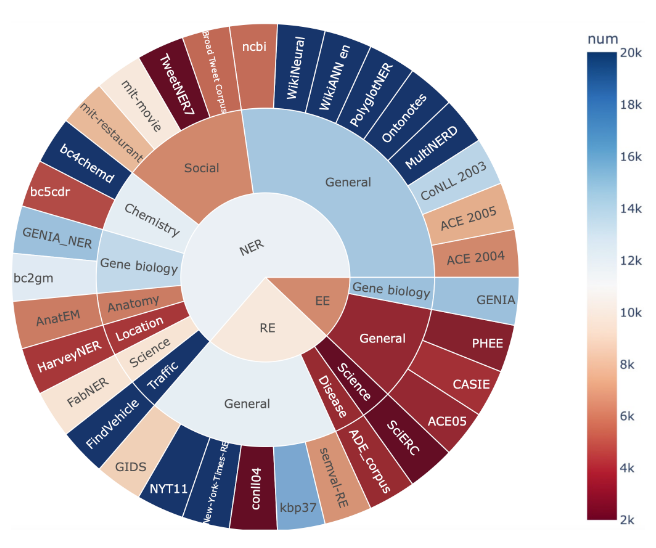
作者主要针对上述数据做出了三项改动:
- 统一了各类数据集中语义相同但表述不同的标签名称.
- 将特殊格式的标签转换为自然语言的语义标签, 可能需要去掉下划线, 转换缩写等.
- 保证了所有任务的输入输出格式均为文本到文本.
注: 读者在阅读InstructUIE的文章时, 需注意实验部分结果分为两部分, 一种是Supervised Settings, 另一种是Zero-shot Settings.
在Supervised Settings下, InstructUIE先在IE INSTRUCTIONS上做多任务预训练, 后仍会在特定数据集上全量微调. Zero-shot Settings下, InstructUIE则在与测试集不相交的数据集上训练, 没有微调.
所以实际上InstructUIE与UIE, USM相比, 在训练上并无优势, 因为它还是得在特定任务上Finetune.
通用信息抽取未完待续, 挖的坑要填.

