本文前置知识:
通用信息抽取(下) - UniEX, Mirror, RexUIE
本文为介绍通用信息抽取领域经典模型的下篇, 将会介绍了UniEX, Mirror, RexUIE三个模型:
- UniEX: ACL 2023, UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective.
- Mirror: EMNLP 2023, Mirror: A Universal Framework for Various Information Extraction Tasks.
- RexUIE: EMNLP Findings 2023, RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction.
碍于篇幅原因, 本文不包含对实验部分的解读, 对实验感兴趣的读者还请自行阅读.
也可以太长不看. 单从性能角度来讲, 全监督任务上RexUIE > Mirror ≈ USM ≈ UniEX, Few shot设置中RexUIE > Mirror > USM.
UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective
本篇第一个模型为UniEX, 论文出自ACL 2023, UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective.
UniEX将信息抽取任务建模为一个Token Pair的解析问题, 即将所有IE Task目标的抽取都拆分为Span Detection, Classification, Association这三个问题. 在解决这三个子问题后, 直接通过解码获得IE Task Target:
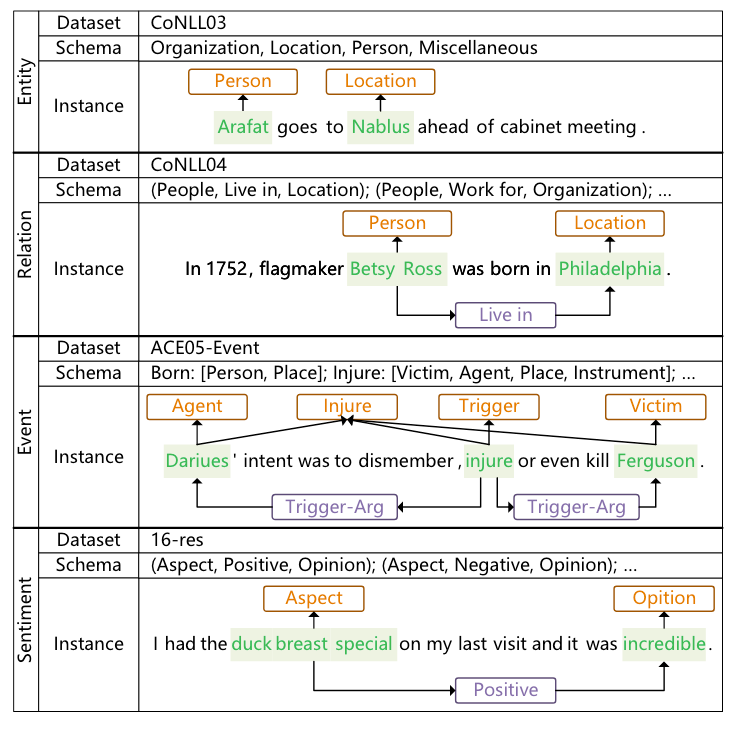
相较于Task - Specialized IE, UniEX可以处理更多的IE任务, 相较于生成式UIE, UniEX也可以更快更好地完成:
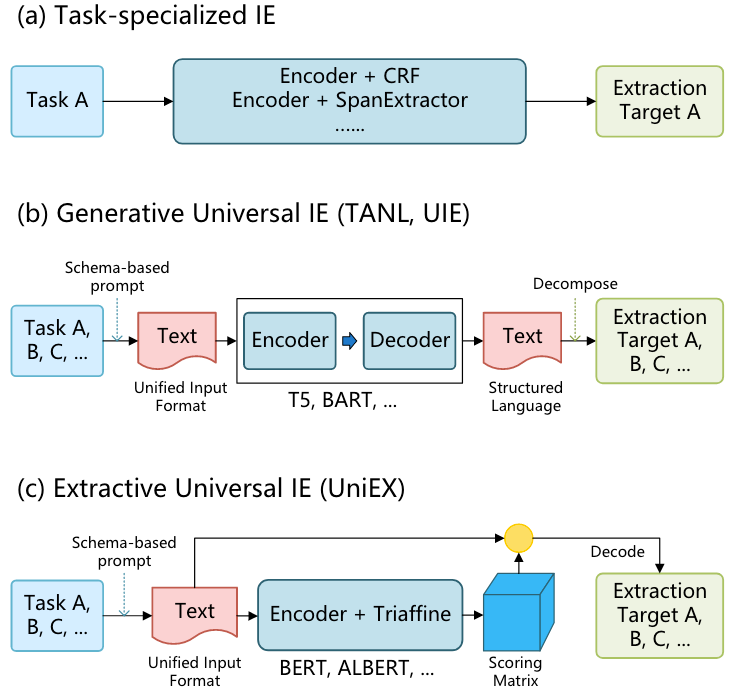
The UniEX Framework
Unified Input
在UIE任务中, 大多模型都需要以IE Task的Schema作为Prompt, 来指导模型要抽取的内容.
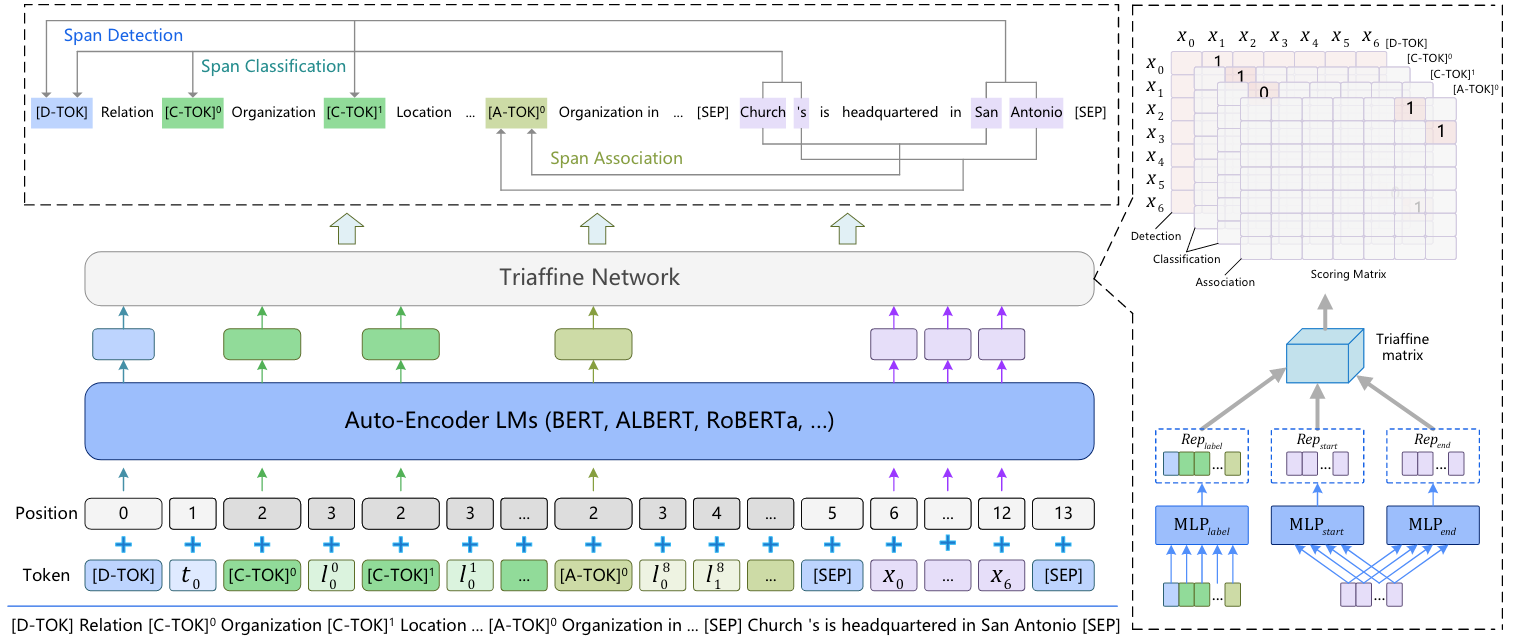
在UniEX中有三种特殊Token:
[D-TOK]承担类似[CLS]的任务, 来捕获全局语义信息, 由基于任务的Schema $s_d$ 组成, 用于Span Detection.[C-TOK]和[A-TOK]则扮演类似[SEP]的角色, 分别分隔用于Span Classification的Schema $s_c$ 和用于Span association的Schema $s_a$.
对于输入文本$x$, 和上面提到的特殊Token构成的集合$s$, 整个模型输入序列$x_{inp}$ 是上述内容的拼接:
$$
\begin{aligned}
x_{i n p}= & \left\{[\mathrm{D}-\mathrm{TOK}]^i s_d^i\right\}_{i=1}^{N_{s d}}\left\{[\mathrm{C}-\mathrm{TOK}]^i s_c^i\right\}_{i=1}^{N_{s c}} \\
& \left\{[\mathrm{A}-\mathrm{TOK}]^i s_a^i\right\}_{i=1}^{N_{s a}}[\mathrm{SEP}] x[\mathrm{SEP}] .
\end{aligned}
$$
例如, 要抽取句子Church 's is headquartered in San Antonio 中的所有关系, 那就将上述输入序列转换为:
[D-TOK] Relation Extraction [C-TOK-0] Organization [C-TOK-1] Location ... [A-TOK-0] Organization in ... [SEP] Church 's is headquartered in San Antonio [SEP]能够看到, 前面的Organization, Location 都是实体类型的Text Prompt, Organization in 则为关系的Text Prompt.
当Text Prompt比较复杂时, 输入序列中的Prompt就会对Prompt之间和输入句子产生干扰.
因此, 作者先将每个Schema Token都标注成独立的位置编码, 例如下图:
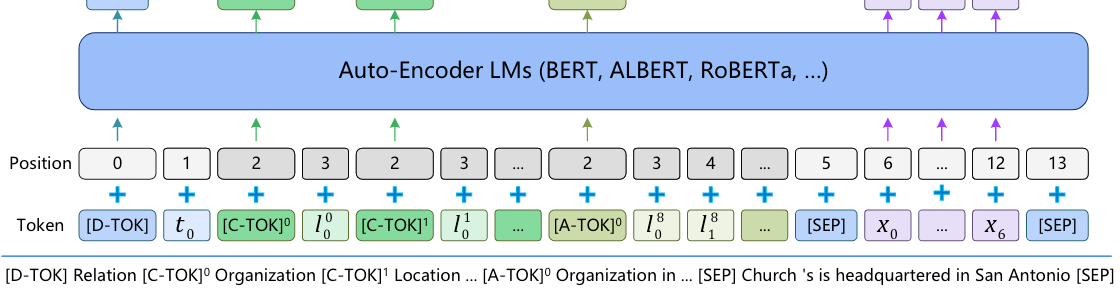
每个[C-TOK] 和[A-TOK] 位置编码都是2, 对应的Schema Token都是顺次, 从而消除前面一大长串Schema对文本位置的不利影响.
其次, 由于不同Schema Token会互相影响, Mask需要保证不相关的Token之间互相不可见. 例如, 有些关系是绑定实体类型的, 则关系表示不应该收到不相关的实体类型表示影响. 假设存在三元组类型为$(e^1, r^1, e^2)$, $(e^1, r^2, e^3)$, 那么Schema对应的Mask应该是这样的:
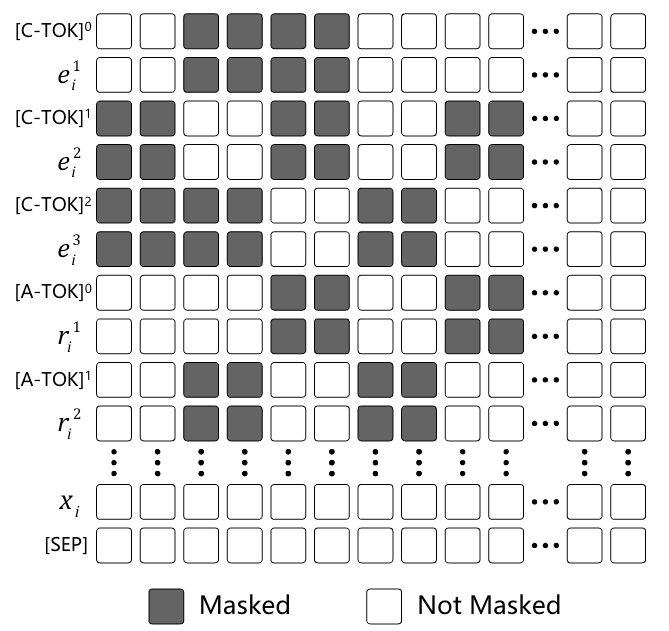
即在三元组类型$(e^1, r^1, e^2)$中, 与关系类型$r^1$ 相对应的实体类型$e^1, e^2$ 对于$r^1$ 是可见的, $r^1$ 对于$e^1, e^2$ 来说也是可见的. $(e^1, r^2, e^3)$ 同理.
更加具体的对于各类信息抽取任务来说, 只有关系类型和事件类型存在上述情况, 因为它们可以和实体类型或者事件角色 / 触发词绑定. 除此以外, 实体, 关系, 事件类型中均互相不可见.
Backbone Network
UniEX用RoBERTa或者ALBERT这样的BERT - like PLM对输入序列进行编码.
形式化的, 用Encoder输入序列$x_{inp}$, , 基于Schema的Mask $M_{mask}$ 对所有输入编码:
$$
H_s, H_x=\text { Encoder }\left(x_{i n p}, p o s, M_{\text {mask }}\right)
$$
$H_s, H_x$ 分别为Schema表示和文本表示.
Triaffine Attention for Span Representation
在前文提过, UniEX将UIE任务拆分为Span Detection, Span Classification, Span Association三个子任务. 从Span视角来看, 上述三个子任务都可以分别在不同由Span构成的二维表上完成.
那么具体要如何标注这张表呢:
- 对于Span Detection, 则直接将
[D-TOK], 也就是[CLS]的表示拿来构建一张二维表, 直接标注第$i$ 个Span的起止位置$(s_i, e_i)$ 即代表该Span有效. - 对于Span Classification, 目标为判断每个Span的类型(实体 / 论元 / 触发词 / 事件类型). 将每种类型的Token
[C-TOK]都构建一张对应的二维表, 在每张特定类型的表上标注第$i$ 个Span的起止位置$(s_i, e_i)$, 即可得到该Span的类型. - 对于Span Association, 第$i$ 和第$j$ 个Span之间如果存在关联(关系类型 / 情感类型), 则需要将对应的
[A-TOK]的表示拿来构建一张二维表, 在每张特定类型的表上标注Span对的交错起始位置$(s_i, s_j)$ 和Span对的交错结束位置$(e_i, e_j)$.
仅当Span能够被检测到时, Span Classification和Span Association的预测结果才是有效的.
多说无益, 可以直接看作者附录中给出的一个关系抽取的例子:
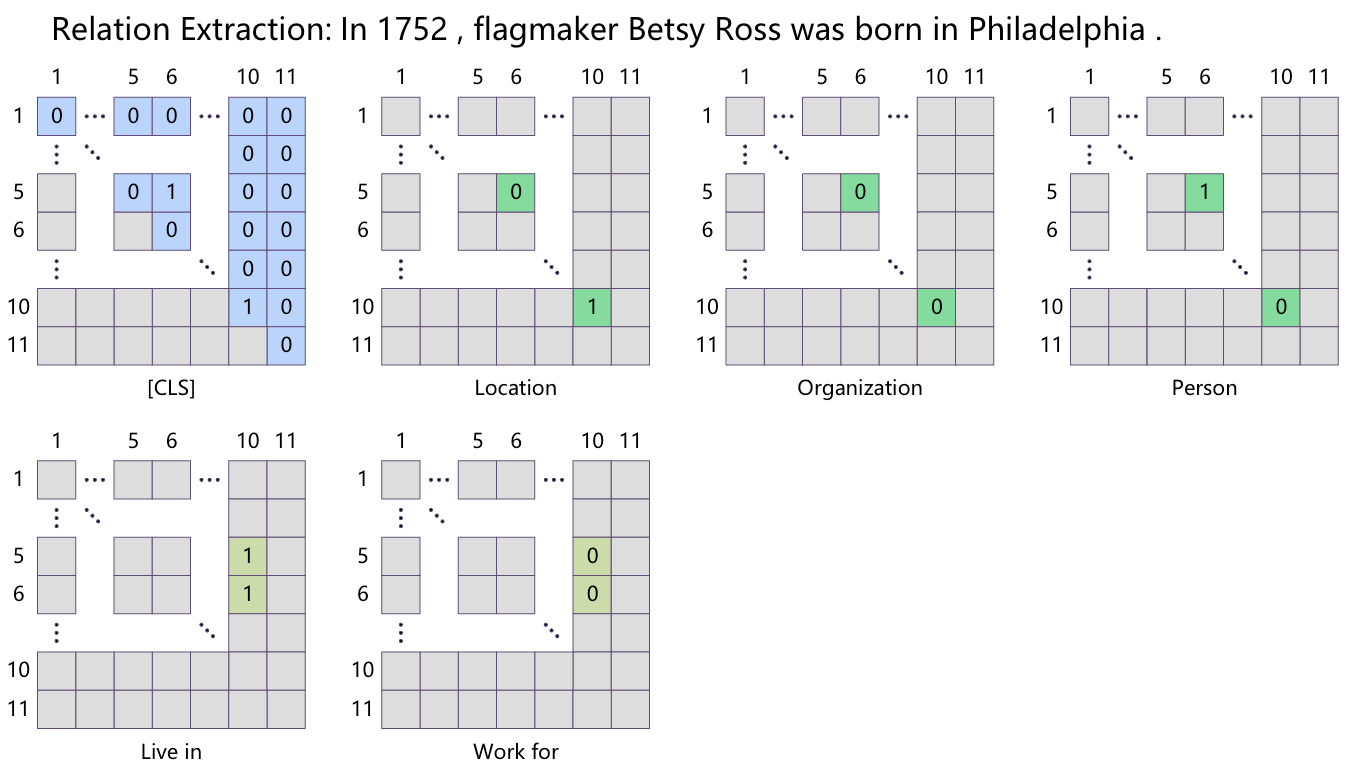
下标为5, 6, 10的单词分别为Besty, Ross 和Philadelphia. 蓝色, 绿色, 黄绿色分别为用于完成Span Detection, Span Classification, Span Association三个子任务的矩阵:
- 在
[CLS]构成的二维表中, (5, 6)位置为1, 标注出了SpanBesty Ross和Philadelphia. - 在
[C-TOK]对应实体类型Location和Person构成的表中, Person表(5, 6)为1, Location表的(10, 10)为1, 分别标注出了Philadelphia为Location,Besty Ross为Person. - 在
[A-TOK]对应关系类型为Live in构成的表中, (5, 10), (6, 10)为1, 标注出了(Besty Ross, Live in,Philadelphia).
如何用模型完成上述标注方法呢?
假设输入文本Token数量为$N_x$, Schema Token的数量为$N_s$, 作者使用三仿射来同时建模Schema表示$H_s \in \mathbb{R}^{N_s \times d}$ 与输入文本的起始表示$H_x^s \in \mathbb{R}^{N_x \times d}$ 和结束表示$H_x^e \in \mathbb{R}^{N_x \times d}$ 的交互, 得到最终的标注得分$S \in \mathbb{R}^{N_s \times N_x \times N_x}$:
$$
\begin{gathered}
H_x^s=\mathrm{FFN}_s\left(H_x\right) \\
H_x^e=\mathrm{FFN}_e\left(H_x\right) \\
S=\sigma\left(\mathcal{W} \times_1 H_s \times_2 H_x^s \times_3 H_x^e\right)
\end{gathered}
$$
其中, $\mathcal{W} \in \mathbb{R}^{d \times d \times d}$ 为三仿射打分权重, $\sigma (\cdot)$ 为Sigmoid函数.
EX Training Procedure
UniEX构造的是三仿射打分矩阵, 直接用BCE完成优化:
$$
\begin{aligned}
\operatorname{BCE}(y, \hat{y}) & =-(y \cdot \log (\hat{y})+(1-y) \cdot \log (1-\hat{y})) \\
\mathcal{L} & =\sum_{r=1}^{N_s} \sum_{p=1}^{N_x} \sum_{q=1}^{N_x} \operatorname{BCE}\left(Y_{r, p, q}, S_{r, p, q}\right)
\end{aligned}
$$
此外, UniEX在有监督设置下不需要在远程监督数据集和其他数据集上做预训练, 只需要在IE数据集上一起训就好.
UniEX与通用信息抽取(上)中提到的USM 在全监督任务上性能表现不分伯仲.
Mirror: A Universal Framework for Various Information Extraction Tasks
第二个模型Mirror, 论文来自EMNLP 2023, Mirror: A Universal Framework for Various Information Extraction Tasks.
据作者所述, Mirror这个名字的来源:
The name, Mirror, comes from the classical story Snow White and the Seven Dwarfs, where a magic mirror knows everything in the world. We aim to build such a powerful tool for the IE community.
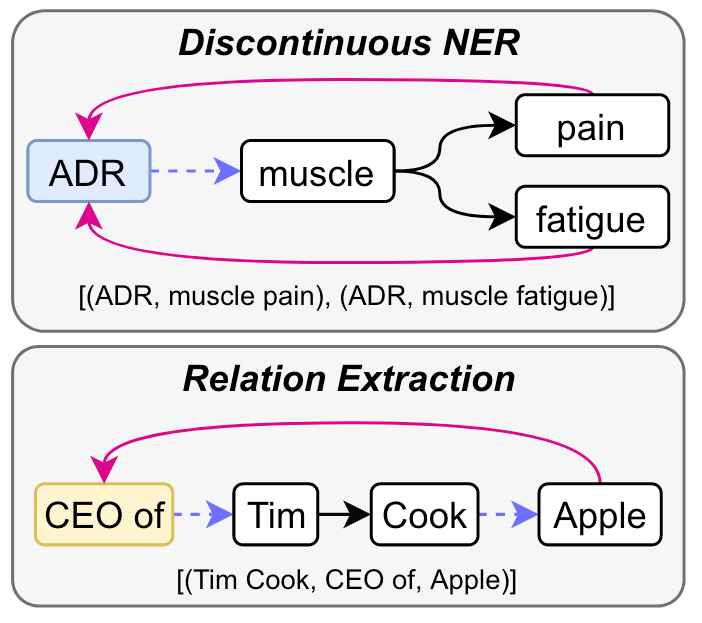
Mirror将IE Task统一为多槽元组的抽取问题, 并将要抽取的信息转换为找Multi-Span Cyclic Graph, 这样使得连续或不连续的Span都可以被确定:
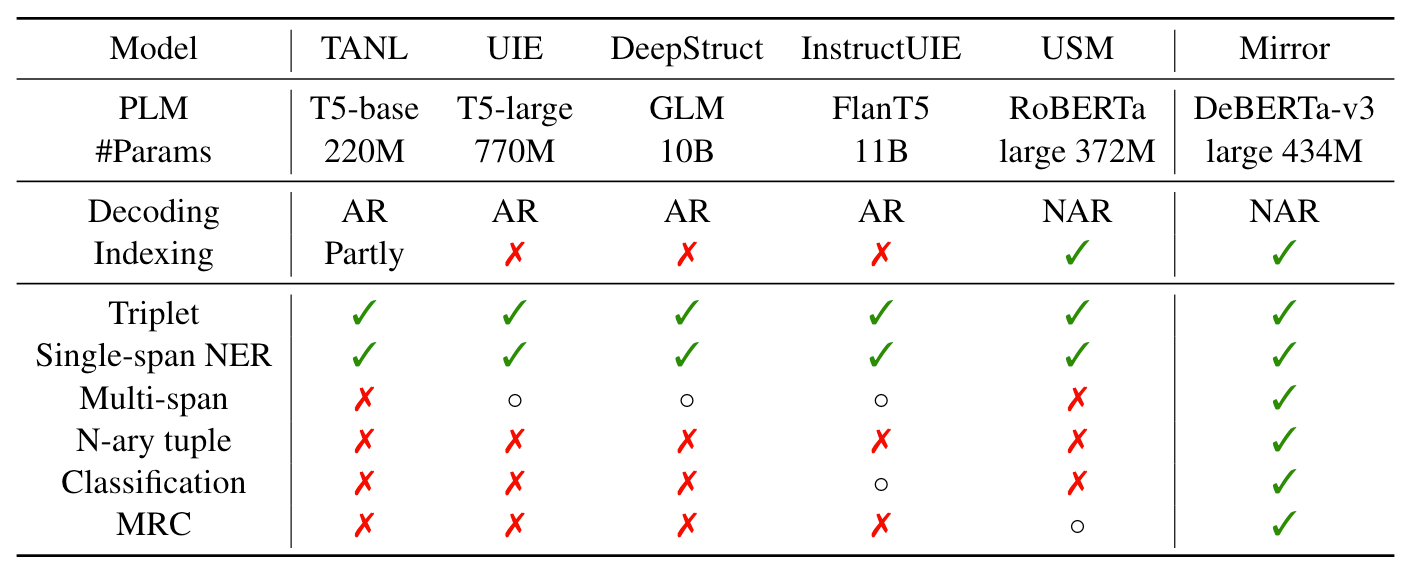
此外, Mirror和之前的UIE方法(UIE, USM, InstructUIE)存在一些区别, 因为作者将它扩展到了Multi Span, N元组抽取, 分类和MRC任务上. 之前介绍的UIE模型大多不能处理扩展出来的这些任务:
Mirror Framework
Unified Data Interface
作者将各类IE任务统一为Instruction + Schema Labels + Text的形式, 使得模型能处理任何形式IE任务:
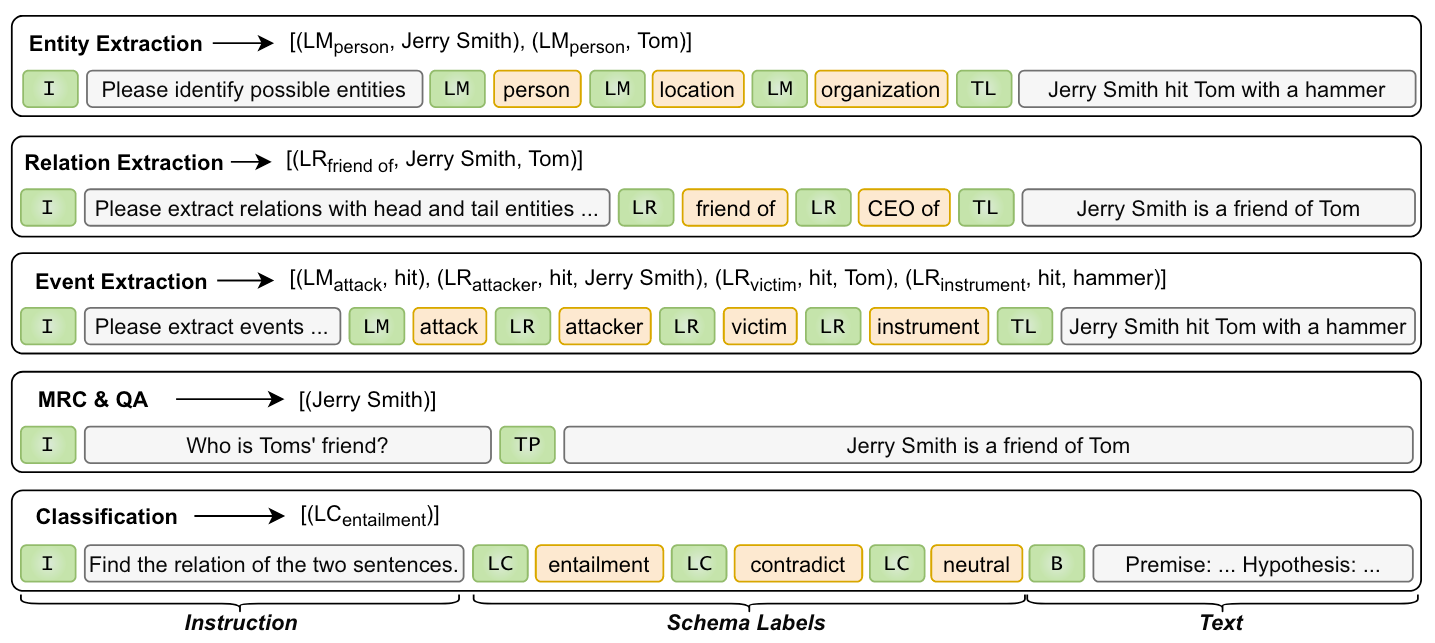
图中的绿色Token代表分隔不同内容:
[I]: Instruction.[LM]: Label Mentions.[LR]: Label Relations.[LC]: Classifications.[TL]: 分隔Text和Schema Label.[TP]: 后面是MRC或者QA, 没有Schema.[B]: 分类任务里的背景类.
前文提过, 任何IE任务都可以建模为抽取多槽元组的问题, 进而变为找到Multi Span Cyclic Graph的问题. 例如:
- NER: 抽取(entity type, entity mention)的二元组. entity type为特殊Token
[LM]. - RE: 抽取(relation, head entity, tail entity)的三元组. relation为特殊Token
[LR]. - EE: 有些特殊, 需要区分事件触发词和事件角色. 触发词为抽取(event type, trigger), event type为特殊Token
[LM], 事件角色为抽取(event role, trigger, mention), event role为特殊Token[LR]. 因为同一个事件的触发词是相同的, 因此触发词和不同事件角色可以被解码到同一事件里面. - MRC & QA: 抽取(answer)元组, 简单粗暴.
- Classification: 抽取(class)元组, 即特殊Token
[LC].
Multi-slot Tuple and Multi-span Cyclic Graph
作者设计了三种连接来确定循环图, 从而抽取Multi-Slot Tuple:
- Jump Connection: 蓝虚线, 用于连接Tuple里的不同槽位.
- Consecutive Connection: 黑实线, 用于连接同一个实体的不连续Span.
- Tail-to-Head Connection: 粉实线, 用于构成闭环, 从Tuple的最后一个元素指向首个元素, 它决定了图的边界.
其实Jump Connection和Tail-to-Head Connection就是W2NER里面的NNW和THW.
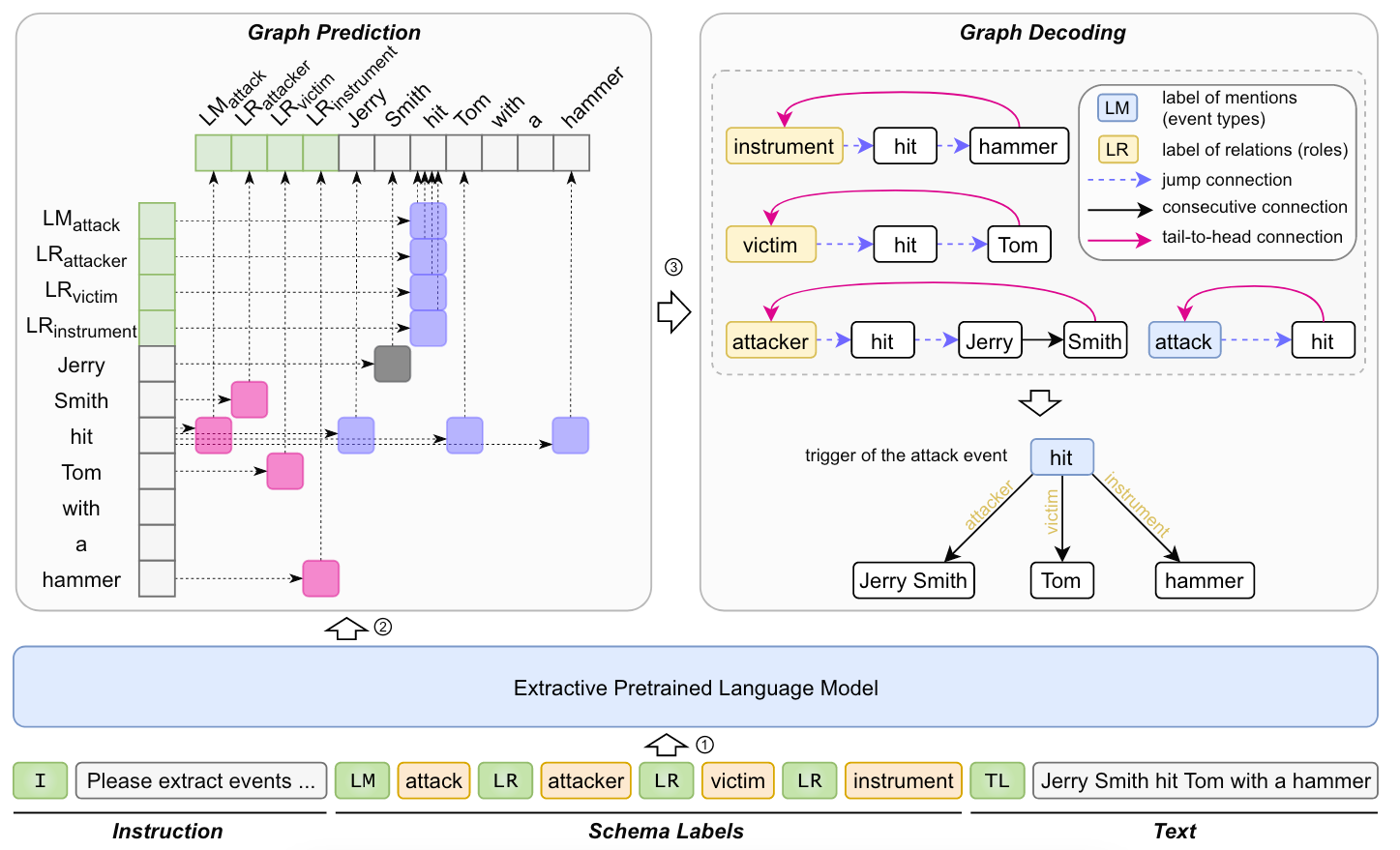
Model Structure
模型结构是比较简单的. 用BERT-like的PLM获得每个Token的表示$h_i$ 后, 用两个FFNN和双仿射构成三张二维表, 用于分别得到作者设计的三种连接:
$$
\begin{gathered}
\tilde{h}_i=\operatorname{FFNN}_s\left(h_i\right), \quad \tilde{h}_j=\mathrm{FFNN}_e\left(h_j\right) \\
p_{i j}^k=\operatorname{sigmoid}\left(\tilde{h}_i^{\top} U \tilde{h}_j / \sqrt{d_h}\right),
\end{gathered}
$$
其中, FFNN为附带苏神RoPE的FFNN. $U \in \mathbb{R}^{d \times 3 \times d }$ 为双仿射矩阵, 3为构成循环图的三种连接.
由于是二分类任务, 用苏神的多标签损失函数优化模型:
$$
\mathcal{L}(i, j)=\log \left(1+\sum_{\Omega_{\mathrm{neg}}} e^{p_{i j}^k}\right)+\log \left(1+\sum_{\Omega_{\mathrm{pos}}} e^{-p_{i j}^k}\right)
$$
其中$\Omega_{\mathrm{neg}}$ 为负例($\mathcal{A}_{ij}^k=0$), $\Omega_{\mathrm{pos}}$ 为正例($\mathcal{A}_{ij}^k=1$).
虽然性能也不够亮眼, 但Mirror有自己的优势, 比如可以处理不连续的Span, 这是很多基于Span的UIE方法没有考虑到的.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
最后一个方法RexUIE, 论文出自EMNLP Findings 2023, RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction.
RexUIE(Recursive Method with Explicit Schema Instructor for UIE)单从名字上便可以看出它的特性, 它能够递归的根据任意形式的Schema抽取信息.
先前的UIE方法只能判断两个Span之间的关系, 而不能处理更多元(例如四元组, 甚至是五元组)的关联.
并且, 对于显式的Schema限制, 之前的一些UIE方法也没有做干涉. 比如关系类型”work for”的头尾实体类型必须分别为”person”和”organization”. 这对模型泛化和低资源场景有害.
综上, 作者提出RexUIE, 可以处理任何形式的Schema:
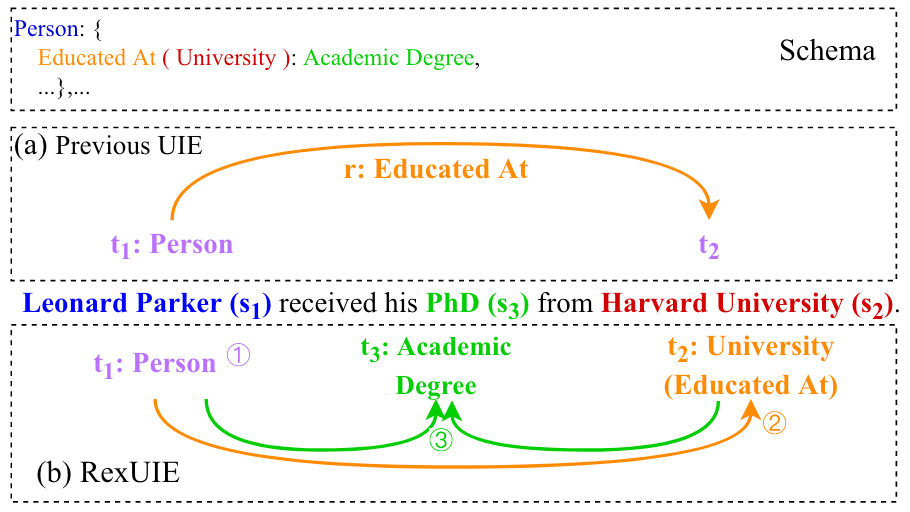
根据Schema, RexUIE有:
- 抽取出实体类型为”Person”的实体
Leonard Parker. - 抽取出关系类型为”Educated At”的尾实体
Harvard University, 并根据关系类型对实体类型的限制, 同时得到Harvard University的实体类型为”University”. - 继续根据Schema和已知的元组(
Leonard Parker, “Person”), (Harvard University, “Educated At (University)”), 继续抽取出SpanPhd对应的类型为”Academic Degree”.
其实这种层次化抽取的思路并不稀奇, Paddle-UIE实现里面用的就是这种.
Redefine Universal Information Extraction
对于$n$ 个Span的文本$\mathbf{s} = [s_1, s_2, \dots, s_n]$ 和其对应的Schema定义的类型$\mathbf{t} = [t_1, t_2, \dots, t_n]$, UIE目标是要抽取出每个$(s_i, t_i)$ Pair. 形式化的, 需要最大化如下概率:
$$
\begin{aligned}
& \prod_{(\mathbf{s}, \mathbf{t}) \in \mathbb{A}} p\left((\mathbf{s}, \mathbf{t}) \mid \mathbf{C}^n, \mathbf{x}\right) \\
= & \prod_{(\mathbf{s}, \mathbf{t}) \in \mathbb{A}} \prod_{i=1}^n p\left((s, t)_i \mid(\mathbf{s}, \mathbf{t})_{<i}, \mathbf{C}^n, \mathbf{x}\right) \\
= & \prod_{i=1}^n\left[\prod_{(s, t)_i \in \mathbb{A}_i \mid(\mathbf{s}, \mathbf{t})_{<i}} p\left((s, t)_i \mid(\mathbf{s}, \mathbf{t})_{<i}, \mathbf{C}^n, \mathbf{x}\right)\right]
\end{aligned}
$$
其中, $\mathbf{C}^n$ 为深度为$n$ 的树形层次化Schema, $\mathbb{A}$ 为标注了信息的序列. 所以从公式中来看, 其实就是按照层次结构抽取每一层的信息, 更深层的信息可以在浅层Schema的约束下得到.
RexUIE
RexUIE用循环递归的Query来不断抽取信息, 并将每层Schema对应Span类型的预测结果添加到最终结果集中, 即图中的ESI:
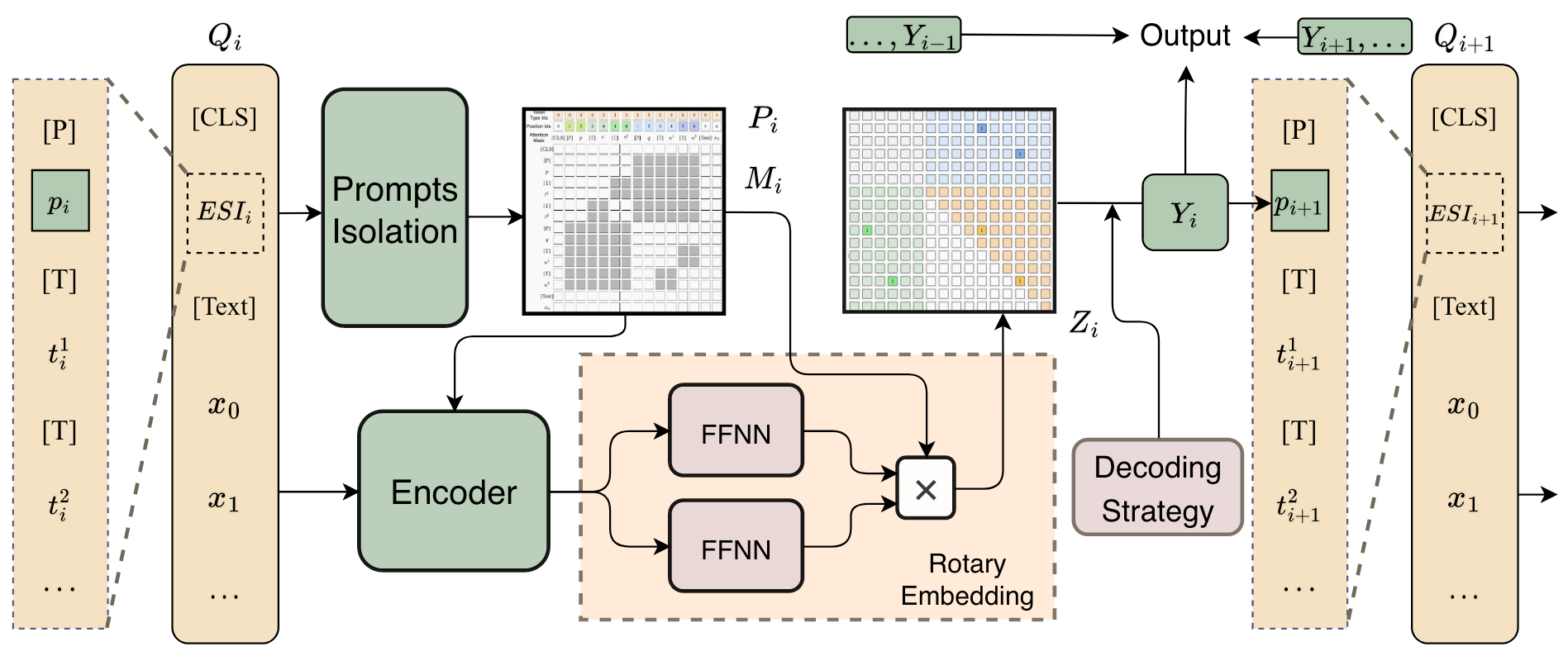
Framework of RexUIE
对于第$i$ 个Query $Q_i$, 其表征$h_i$ 可以用PLM作为Encoder得到:
$$
h_i=\operatorname{Encoder}\left(Q_i, P_i, M_i\right)
$$
$P_i, M_i$ 分别为$Q_i$ 对应的Prompt和Mask. $Q_i$ 的构成在下面会提到.
接着用两个FFNN来构成一张Query $Q_i$ 对应的二维得分矩阵$Z_i$:
$$
Z_i^{j, k}=\left(\mathbf{F F N N}_q\left(h_i^j\right)^{\top} \mathbf{R}\left(P_i^k-P_i^j\right)\mathbf{F F N N}_k\left(h_i^k\right)\right) \otimes M_i^{j, k}
$$
$\mathbf{R}\left(P_i^k-P_i^j\right)$为苏神提出的RoPE, 用来表征位置$P_i^k$, $P_i^j$ 之间的相对位置信息.
在获得第$i$ 个Query对的得分矩阵$Z_i$ 后, 直接应用解码, 并将解码得到的结果$Y_i$ 添加到信息抽取结果集$\mathcal{Y} = \set{Y_1, Y_2, \dots}$ 中. $Y_i$ 会被用于构成下一轮迭代的Query $Q_{i+1}$.
最后, 用苏神的类别不平衡Loss来优化RexUIE:
$$
\begin{gathered}
\mathcal{L}_i=\log \left(1+\sum_{\hat{Z}_i^j=0} e^{\bar{Z}_i^j}\right)+\log \left(1+\sum_{\hat{Z}_i^k=1} e^{-\bar{Z}_i^k}\right) \\
\mathcal{L}=\sum_i \mathcal{L}_i
\end{gathered}
$$
$\bar{Z}_i$ 为展平后的$Z_i$ , $\hat{Z}_i$ 则为展平后的Binary Ground Truth.
Explicit Schema Instructor
对于输入的文本$\mathbf{x}$ 和第$i$ 个Query抽取出的结果$(\mathbf{s}, \mathbf{t})_{<i}$, 直接将抽取结果$p_i$ 和一个特殊Token [P]作为Prefix拼在Type之前, 形成$Q_i$, 如下所示:
$$
Q_i=[\mathrm{CLS}][\mathrm{P}] p_i[\mathrm{T}] t_i^1[\mathrm{T}] t_i^2 \ldots[\mathrm{Text}] x_0 x_1 \ldots
$$
如果觉得有点困惑, 可以阅读完下面两小节后看例子.
Token Linking Operations
下面该说说如何在二维表上完成标注, 从而抽取Span对应的Type, 即抽取每个$(s_i, t_i)$了.
在RexUIE中, 表填充的结果$\hat{Z}$ 是由二维得分矩阵$Z$ 通过阈值$\delta$ 得到的一个二元标注矩阵:
$$
\tilde{Z}^{i, j}=\left\{\begin{array}{cc}
1 & \text { if } Z^{i, j} \geq \delta \\
0 & \text { otherwise }
\end{array}\right.
$$
当Linking满足作者设计的三种Linking的方式时, 二元标注矩阵中的对应位置为1, 即Linking有效:
- Token Head-Tail Linking: 还是用来检测Span. 判断Span的起止位置.
- Token Head-Type Linking: Span的起始位置链接到对应类别的特殊Token
[T]. - Type-Token Tail Linking: 类别特殊Token
[ T]链接到对应Span的结束位置.
下面来看一个例子, 假如任务给定的Schema如下:
{“person”: {“work for (organization)”: null}, “organization”: null }对应的得分矩阵的Ground Truth如下:
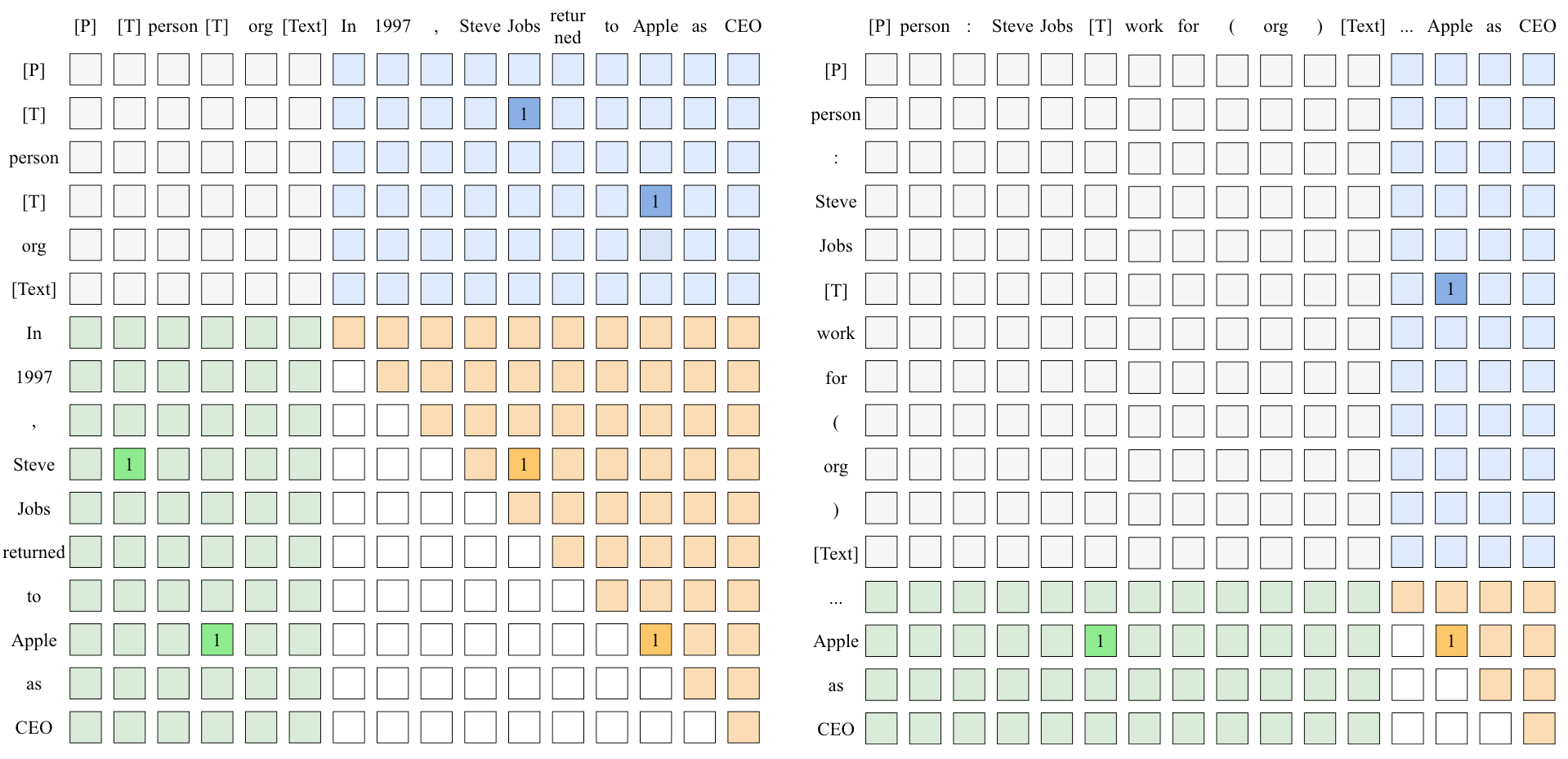
绿色区域为Token Head-Type Linking, 蓝色为Type-Token Tail Linking, 橘色为Token Head-Tail Linking.
而左侧的矩阵为抽取第一层Schema时的序列, 即没有Prefix, 并且要抽取的类型就是Schema的最外圈, “person”和”organization”. 所以第一步实际上在做NER.
右侧矩阵为抽取Schema的第二层, 即”work for (organization)”的抽取, 能看到上一层的抽取结果”person: Steve Jobs“ 被补充到了Prefix里面, 并将要抽取的类型做了替换. 第二步实际上在做RE.
USM的标注方法比RexUIE要更加复杂, 这是因为USM要求所有Linking被一次性并行标注, 但实际上解决”Span之间的关联”的问题被RexUIE在递归的过程中被巧妙的分解了, 拆解为Span本身和其类型的抽取过程.
Prompts Isolation
若在结构化Schema的某一层中有多条预测结果, 那在构成Query的时候就会有多条Query, 编码和预测很耗时. 为了节省时间, RexUIE索性直接简单的将多个Prefix Group放到同一个Query中.
除此外, Prefix和Prompt比较混乱, 都会对其他内容产生互相影响. 所以RexUIE中做了如下限制:
- Token Type ids: 将用Token Type ids区分Prompt和正文$\mathbf{x}$.
- Position ids: 对不同的Type给予相同的起始位置编码. 不同的Prefix Group的位置编码都是独立的.
- Attention Mask: 对于Mask来说, 不同的Type之间是不可见的, 不同Prefix Group之间的Token也是不可见的.
上述过程如下所示:
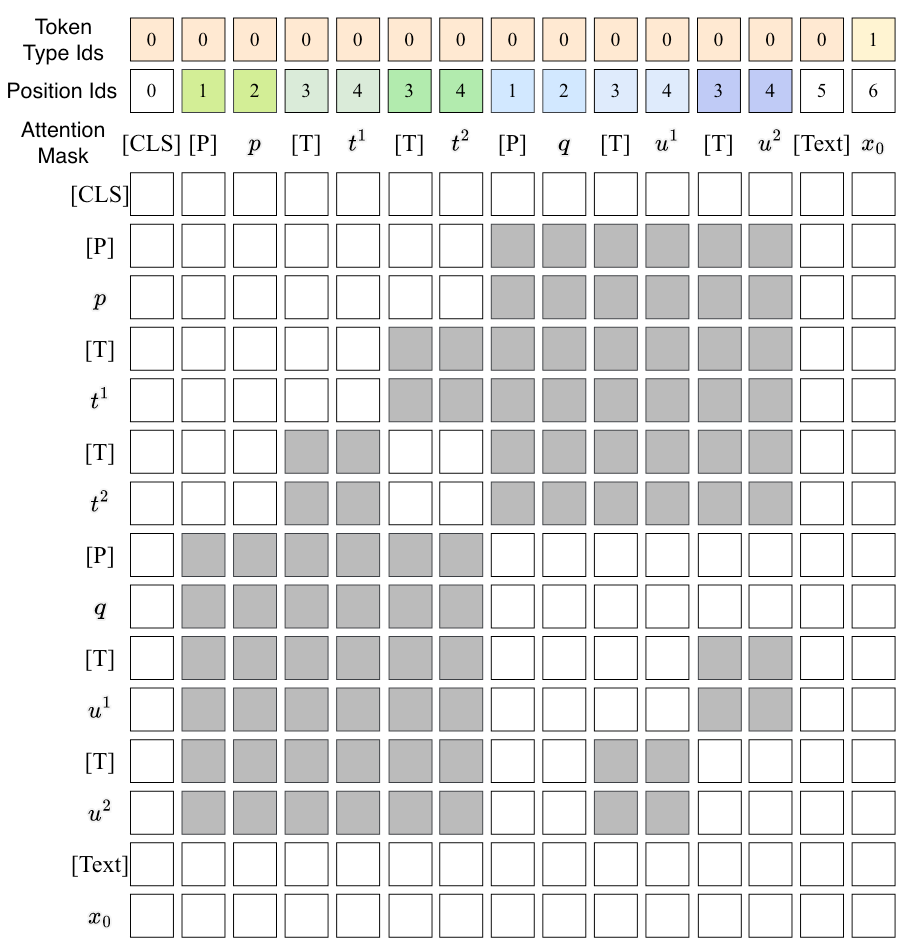
明显的观察到两个Prefix Group之间是不可见的, 并且具有均为起始为1的位置编码. 每组中构成Query的上次预测结果$p, q$ 是能够对所在组的Type给予注意力的.
因此, 在打分矩阵完成预测时, 可以直接同时处理多组Prefix构成的Query.
下面可以举个作者附录中的例子, 比如在CoNLL04上完成RE.
结构化Schema为:
{“organization”: {“organization in ( location )”: null}, “other”: null, “location”: {“located in ( location )”: null}, “people”: {“live in ( location )”: null, “work for ( organization )”: null, “kill ( people )”: null}}首先按最外层Schema判断Span的类型, 其实在这里先进行的是NER:
[CLS][P][T] location[T] organization[T] other[T] people[Text] The self-propelled rig Avco 5 was headed to shore with 14 people aboard early Monday when it capsized about 20 miles off the Louisiana coast , near Morgan City , Lifa said.[SEP]抽取得到(Morgan City, “location”), (Louisiana, “location”), (Lifa, “people”). 如此的三个元组便对应了三个Prefix Group. 接着根据关系类型对实体类型的限制, 判断第一层抽取结果对应的第二层Schema类型. 例如”location”对应的Schema第二层为”located in ( location )”, 而”person”对应的有三个类型”live in ( location )”, “work for ( organization )”和”kill ( people )”. 将第二层抽取组成如下的Query, 再次进行抽取:
[CLS][P] location: Morgan City[T] located in ( location )[P] location: Louisiana[T] located in ( location )[P] people: Lifa[T] kill ( people )[T] live in ( location )[T] work for ( organization )[Text] The self-propelled rig Avco 5 was headed to shore with 14 people aboard early Monday when it capsized about 20 miles off the Louisiana coast , near Morgan City , Lifa said.[SEP]从例子中不难看到, RexUIE的抽取内容全部来自Schema, 所以它对Span的抽取是严格遵守Schema限制的.
Pre-training
RexUIE预训练数据由三部分组成:
- $\mathcal{D}_{distant}$: WikiPedia的远程监督数据.
- $\mathcal{D}_{superv}$: IE任务的公开数据集.
- $\mathcal{D}_{mrc}$: 和USM一样, 采用了MRC的数据来增强模型对Prompt的理解能力.
RexUIE在性能上要优于USM. 尤其是在Few - Shot上比USM提升要更显著.
Summary
由于信息抽取领域存在大量的共性, 因此各类IE任务被统一是大势所趋. 它们都可以被抽象为找Span, 判断Span之间的关联, 进而转换为各类花式分类问题, 当然也可以通过Generative的方法来完成. 全监督设置已经不能满足大家疯狂刷点, 由于各类任务大一统带来的多任务学习共享知识的能力, 也带着这个领域朝着Zero - Shot和Few - Shot迈进. 至此, 通用信息抽取篇结束.
如果需要了解更多关于通用信息抽取领域前沿, 还可以阅读:
最后, 是一些个人想法.
其实按照正向思路, 是在LLM时代期待一下LLM在IE Task上的应用, 最起码在目前来看LLM在IE任务上做的并不够好, 还有提升空间. 但是更多时候, 如果下游任务的知识已经蕴含在LLM内部了, 真的有必要做IE吗?
如果反过来思考一下, IE Task经历了这么长的时间, 早就已经相对趋于成熟.
所以在这里说一个暴论, IE任务从文本而来, 那最终形态还得再回到文本里去. 从IE Task能为LLM带来什么的角度思考问题会更有价值, 也更有可能是未来IE的出路. 比如在IE有监督指导下的数据合成, 或许能够保证LLM的训练数据更加安全可靠, 从而体现出IE本身的价值.

