W2NER: Unified Named Entity Recognition as Word - Word Relation Classification
本文是论文Unified Named Entity Recognition as Word-Word Relation Classification 的阅读笔记和个人理解, 论文来自AAAI 2022.
Basic Idea
在之前, NER可以被独立的分为Flat, Overlapped, Discontinuous 三大类. 最近有些工作尝试将上述三类NER归整到一个统一的NER框架当中, 当前主要有基于Span的和Seq2Seq两大类, 这两类模型要么对边界识别能力不足, 要么受到曝光偏差影响.
当然, Nested可以视为是一种Overlapped的特殊情况.
作者尝试提出一个统一的NER框架W2NER, 将NER转变成一个单词间的关系分类问题:
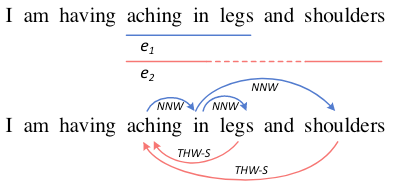
在上例中, aching in legs 和aching in shoulders 分别是连续实体和不连续实体, 依照Token之间的关系判断可以将它们分离出来.
W2NER
NER as Word-Word Relation Classification
无论是对于Flat, Overlapped, Discontinuous这三类NER中的哪一类, 都可以被抽象为从对于给定的$N$ 个Token或单词$X=\set{x_{1,}x_{2,}\dots, x_N}$ 中抽取出Token Pair$(x_{i,}x_j)$ 之间的关系$\mathcal{R}$, 其中$\mathcal{R}$ 可以是$\text{None}$, $\text{Next-Neighboring-Word}$ (NNW), 或者$\text{Tail-Head-Word-}\star$ (THW-*).
结合下图来说明这三种Token Pair之间的关系的含义:
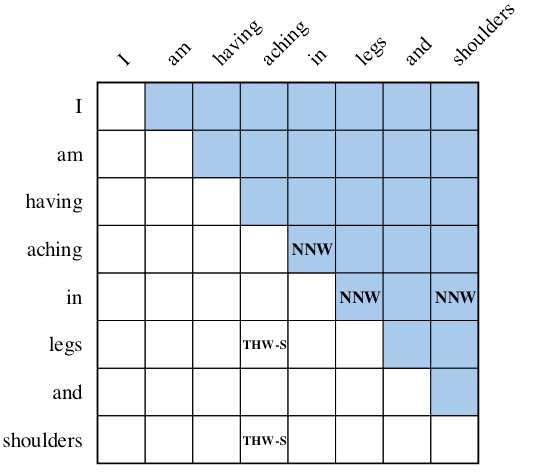
对于每行Token $x_i$ 和每列Token $x_j$, 即Token Pair$(x_{i,}x_j)$, 其之间的关系代表着:
- $\text{None}$: 该Token Pair之间不存在任何关系.
- $\text{Next-Neighboring-Word}$: $(x_{i,}x_j)$ 位于一个实体提及中, 且在该实体提及中, 行Token $x_i$ 是列Token $x_j$ 的前一个Token.
- $\text{Tail-Head-Word-}\star$: $(x_{i,}x_j)$ 位于一个实体提及中, 且在该实体提及中, 行Token $x_i$ 是该实体提及的结束Token, 列Token $x_j$ 为该实体提及的起始Token. $\star$ 代表该实体提及的实体类型.
从标签设计上来说, NNW指明了Token之间的连续性. THW指明了实体边界和实体类型. 熟悉信息抽取这块的小伙伴可能会觉得这个THW有些似曾相识. 在文末Summary我会指出它的来源.
在上图例子中, 实体aching in legs, aching in shoulders 分别是一个连续实体和不连续实体, 它们共享了aching in.
通过提到的NNW关系, 可以建立(aching -> in), (in -> legs), (in -> shoulders) 之间的关联. 然后再通过THW关系, 定位实体的边界和它们对应的类型(legs -> aching, Symptom), (shoulders -> aching, Symptom). 我们根据THW反向往回找, 就能解码出对应的整个实体提及了.
Unified NER Framework
整个W2NER的概览图如下:
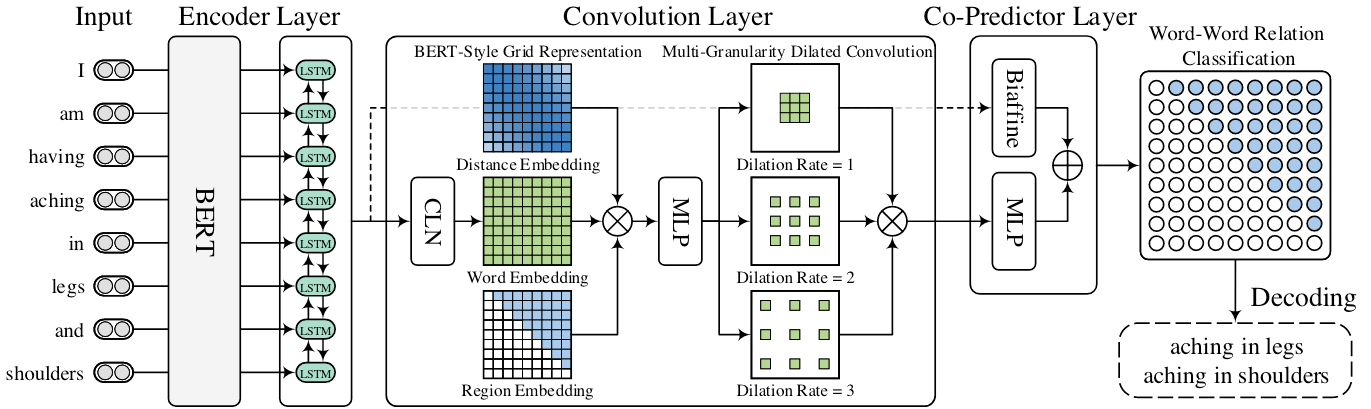
大致可以分为Encoder Layer, Convolution Layer, Co - Predictor Layer和最后的Decoding.
Encoder Layer
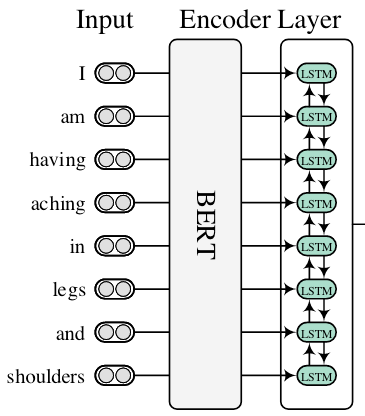
对于给定的句子$X = \set{x_{1,}x_{2,}\dots, x_N}$, 首先使用BERT获得每个Token或者Word $x_i$ 的表示. 每个Word可能由多个Token组成, 使用最大池化获得每个Word的表示. 接着用一个双向LSTM完成编码. 记最终编码表示$\mathbf{H}=\left\{\mathbf{h}_1, \mathbf{h}_2, \ldots, \mathbf{h}_N\right\} \in \mathbb{R}^{N \times d_h}$, 其中$d_h$ 为Word表示的维度.
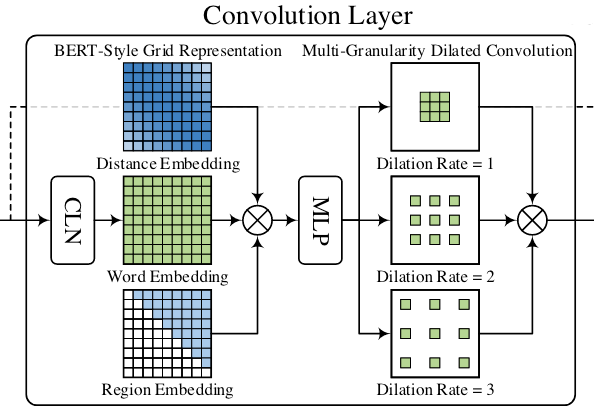
Convolution Layer
由于W2NER会构成一个2D的表格, 采用Conv2D来聚合表格信息就比较合适:
Conditional Layer Normalization
表格可以被看做是一个三维矩阵$\mathbf{V} \in \mathbb{R}^{N \times N \times d_h}$, $\mathbf{V}_{ij}$ 代表Word Pair $(x_{i,}x_j)$ 的表示. 由于输入的句子是有向的, 而作者设计的Word Pair间关系也是有向的, 作者希望这种有向条件关系能够被表示出来. 例如, $(x_{i,}x_j)$ 之间的关系是由 $x_i$ 指向 $x_j$ 时, 应该有$\mathbf{h_j}= f(x_{j} \mid x_{i})$.
作者使用Conditional Layer Normalization(CLN)来建模这种隐含关系:
$$
\mathbf{V}_{i j}=\operatorname{CLN}\left(\mathbf{h}_i, \mathbf{h}_j\right)=\gamma_{i j} \odot\left(\frac{\mathbf{h}_j-\mu}{\sigma}\right)+\lambda_{i j}
$$
$\mathbf{h}_i$ 将用于生成缩放系数$\gamma_{ij}$ 和平移系数$\lambda_{ij}$:
$$
\begin{aligned}
\gamma_{ij} = \mathbf{W}_{\alpha}\mathbf{h}_{i}+ \mathbf{b}_{\alpha}\\
\lambda_{ij} = \mathbf{W}_{\beta}\mathbf{h}_{i}+ \mathbf{b}_{\beta}
\end{aligned}
$$
$\mu, \sigma$ 分别是$\mathbf{h}_j$ 中跨元素的均值和标准差:
$$
\mu=\frac{1}{d_h} \sum_{k=1}^{d_h} h_{j k}, \quad \sigma=\sqrt{\frac{1}{d_h} \sum_{k=1}^{d_h}\left(h_{j k}-\mu\right)^2}
$$
$h_{jk}$ 代表$\mathbf{h}_j$ 的第$k$ 维.
BERT-Style Grid Representation Build - Up
虽然BERT里面包含了Word Embedding, Positional Embedding, Segment Embedding, 但作者觉得还不够, 因此仿照BERT构建一种新的表格表示, 由三部分组成:
- CLN得到的Word Pair表示$\mathbf{V} \in \mathbb{R}^{N \times N \times d_h}$.
- Word Pair之间的相对位置信息记作$\mathbf{E}^d \in \mathbb{R}^{N \times N \times d_{E_d}}$.
- 上下三角的区域Embedding$\mathbf{E}^t \in \mathbb{R}^{N \times N \times d_{E_t}}$.
把上面三种表示拼接到一起, 再用一个MLP整合, 即Position - Region Aware Representation $\mathbf{C} \in \mathbb{R}^{N \times N \times d_c}$:
$$
\mathbf{C}=\operatorname{MLP}_1\left(\left[\mathbf{V} ; \mathbf{E}^d ; \mathbf{E}^t\right]\right)
$$
Multi - Granularity Dilated Convolution
用2D卷积在2D表格上做聚合是比较符合我们直觉的.
前人实验表明, 空洞卷积可以有更大的感受野, 在NLP上表现良好, 在此使用空洞卷积来捕获二维表格上的信息:
$$
\mathbf{Q}^l=\sigma\left(\operatorname{DConv}_l(\mathbf{C})\right)
$$
$l$ 为空洞卷积的膨胀系数.
多粒度主要体现在不同的膨胀系数, 作者将三种不同膨胀系数的空洞卷积抽出的特征拼接到一起:
$$
\mathbf{Q}= \left[\mathbf{Q}^{1}, \mathbf{Q}^{2}, \mathbf{Q}^{3}\right] \in \mathbb{R}^{N \times N \times 3d_c}
$$
作者在代码里写的与论文中似乎不同, 代码中使用的空洞卷积是顺序的, 即$\mathbf{Q}^1=\sigma\left(\operatorname{DConv}_1(\mathbf{C})\right)$, $\mathbf{Q}^2=\sigma\left(\operatorname{DConv}_2(\mathbf{Q}^1)\right)$, $\mathbf{Q}^3=\sigma\left(\operatorname{DConv}_3(\mathbf{Q}^2)\right)$, 而不是像文中叙述的分别对$\mathbf{C}$ 做空洞卷积激活再拼接, 不过这不是很重要.
Co - Predictor Layer
Co - Predictor由双仿射和MLP两个组件同时对前面Encoder Layer的特征$\mathbf{H} \in \mathbb{R}^{N \times d_h}$ 和Convolution Layer特征$\mathbf{Q} \in \mathbb{R}^{N \times N \times 3d_c}$ 做聚合, 得到Logits:
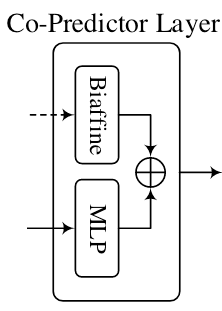
Biaffine Predictor
Biaffine Predictor的作用对象是Encoder所抽取出的特征, 用两个MLP分别获得Subject和Object对应的表示, 然后再用双仿射获取Logits:
$$
\begin{aligned}
\mathbf{s}_i &=\operatorname{MLP}_2\left(\mathbf{h}_i\right) \\
\mathbf{o}_j &=\operatorname{MLP}_3\left(\mathbf{h}_j\right) \\
\mathbf{y}_{i j}^{\prime} &=\mathbf{s}_i^{\top} \mathbf{U} \mathbf{o}_j+\mathbf{W}\left[\mathbf{s}_i ; \mathbf{o}_j\right]+\mathbf{b}
\end{aligned}
$$
这些都是NER里面比较常规的操作了, 不过多赘述.
MLP Predictor
MLP的作用对象是前面空洞卷积获得的特征$\mathbf{Q}$, 用于聚合Convolution Layer获得的每个格子中的信息:
$$
\mathbf{y}_{i j}^{\prime \prime}=\operatorname{MLP}\left(\mathbf{Q}_{i j}\right)
$$
最后简单的将两个Logits相加到一起即可(也可以视为是同等权重求和):
$$
\mathbf{y}_{i j}=\operatorname{Softmax}\left(\mathbf{y}_{i j}^{\prime}+\mathbf{y}_{i j}^{\prime \prime}\right)
$$
双仿射没对卷积得到的特征操作, 而是以Encoder Layer的$\mathbf{H}$ 为输入, 也可以是看成一种从Encoder Layer拉出来的残差连接吧.
Decoding
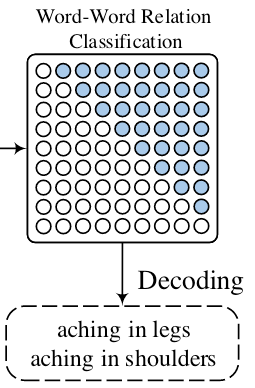
对于Word Pair之间的关系解码, 可以抽象为一个有向图的路径查找, 即利用NNW(蓝)找到有向图中的实体提及路径, THW(红)来提供辅助信息:
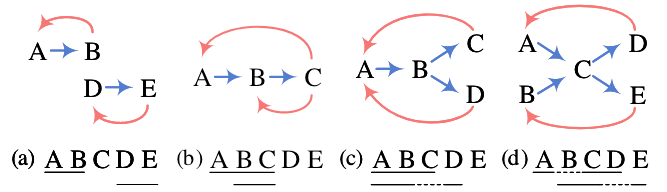
- (a): 两个Flat实体. 对于简单的完全Flat的情况, 其实两条路径
A -> B,D -> E就可以标注出来, THW在此时仅标注它们的实体类型. - (b): 两个重叠实体(该情况也是嵌套), 此时单纯用NNW没法解码出两个嵌套实体, 但THW在使得其可以解码出两个嵌套实体
ABC,BC. - (c): 含有重叠的一个Flat实体和一个不连续实体. NNW可以找到
A -> B -> C和A -> B -> D这两条边, 在THW的辅助下解码出实体ABC和ABD. - (d): 最为复杂的情况, 两个部分重叠且不连续的实体. 同样是通过NNW无法单独解码出, 但在THW辅助下可解码出.
其实就是用NNW和THW结合成环, 环即实体.
Learning
因为是填表式的Token Pair分类, 所以采用多分类交叉熵就好:
$$
\mathcal{L}=-\frac{1}{N^2} \sum_{i=1}^N \sum_{j=1}^N \sum_{r=1}^{|\mathcal{R}|} \hat{\mathbf{y}}_{i j}^r \log \mathbf{y}_{i j}^r
$$
其中$N$ 为句子中单词总数, $\hat{\mathbf{y}}_{i j}$ 为WordPair $(x_{i,}x_j)$ 之间的Golden Label, $\mathbf{y}_{i j}$ 则为模型预测概率分布, $r$ 代表预定义好的关系集合$\mathcal{R}$ 的关系.
Experiments
详细的实验参数设置请参照原论文. 另外, 在阅读实验部分时, 要关注W2NER强大的任务形式统一能力.
Datasets
根据现有的三大类NER采用了三大类不同的数据集:
- Flat: CoNLL - 2003, OntoNotes 5.0(English), OntoNotes 4.0, MSRA, Weibo, Resume.
- Overlapped: ACE2004, ACE2005, GENIA.
- Discontinuous: 三个英文数据集CADEC, ShARe13, ShARe14, 两个中文数据集ACE2004, ACE2005.
Flat NER
在Flat NER上六个数据集结果如下:
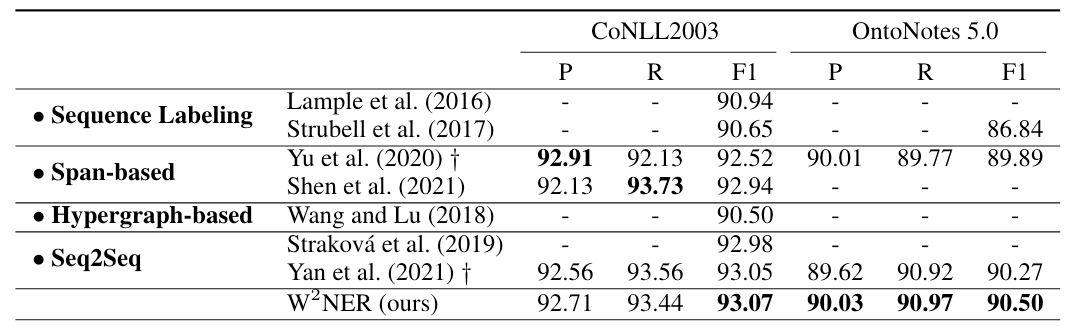

在Flat上结果不多说了, W2NER表现很好.
Overlapped NER
在Overlapped NER三个数据集上表现如下:
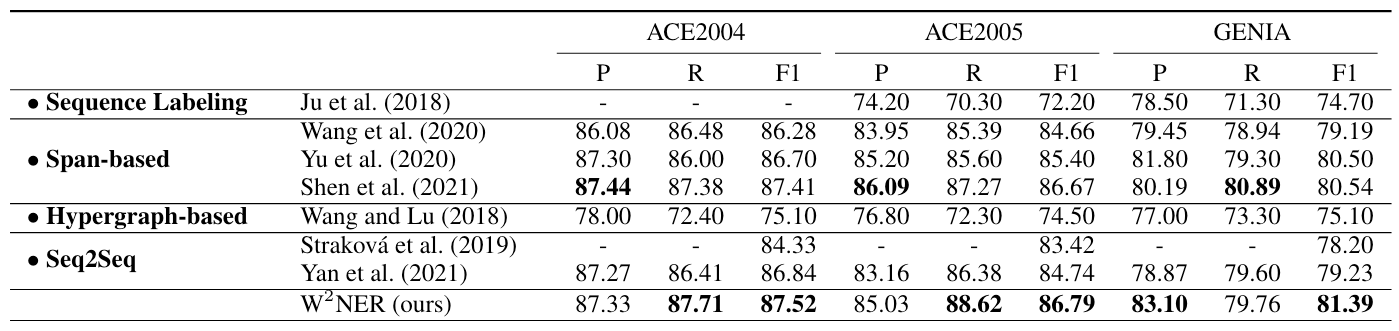
能够看到W2NER的Recall和Precision都维持在不错的水平.
Discontinuous NER
现有NER在Discontinuous NER上比较具有挑战性, 这部分应重点关注, 三个英文数据集上结果如下:
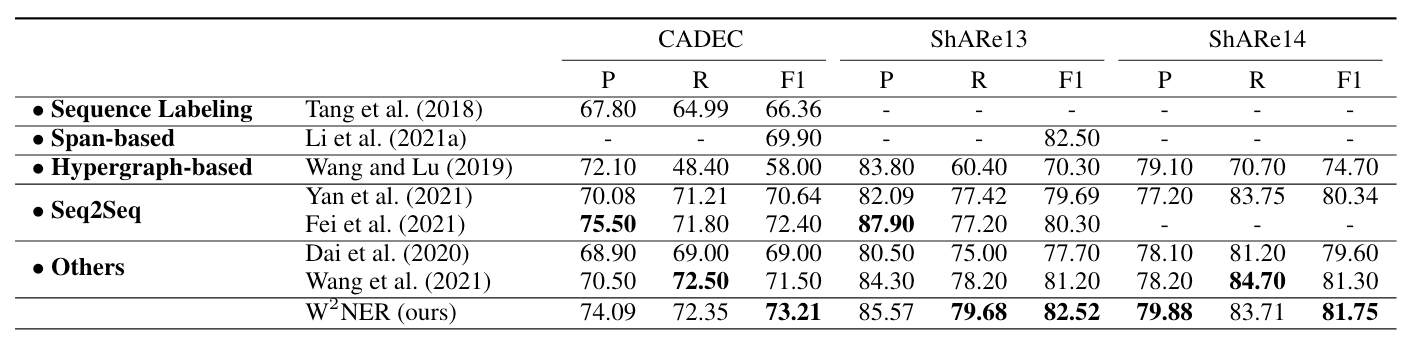
W2NER较其他方法拥有很好的性能, 要记得它在其他NER上表现仍然很猛.
两个中文数据集上结果如下:
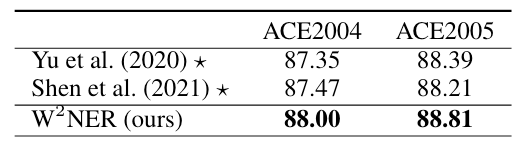
Baseline两篇论文并没有在中文数据集上跑过, 这是作者自行使用官方源码得到的结果. 在两个数据集上领先Baseline半个点.
因为上述数据集也是含有Flat实体的, 所以作者做了ShARe14上重叠和不连续实体的预测性能:
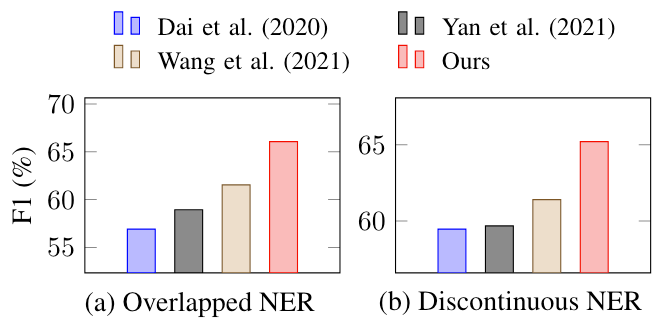
在重叠和不连续这两类比较难的问题下, W2NER相较于其他模型是有明显提升的, 而且差距不小. 其实在附录里还有其他两个数据集的对比, 提升也很明显.
Model Ablation Studies
各组件消融实验结果如下:
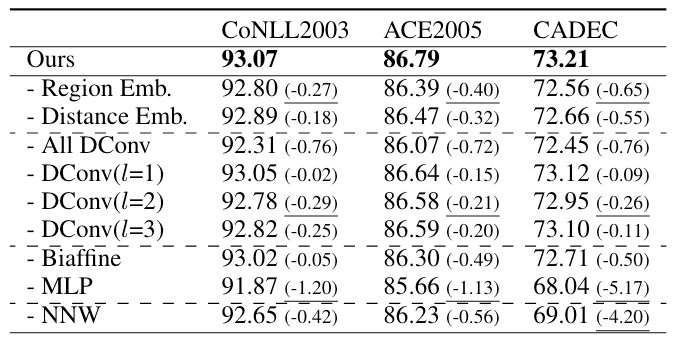
作者在文中的消融实验部分叙述非常简单, 能从结果中看到比较关键的有Region Embedding, 膨胀系数为2的空洞卷积, MLP, 以及NNW的标签设计. 其实相对位置编码和双仿射影响也不少.
空洞卷积的话好像组合起来性能提升比较多.
MLP是挺猛的… 我倒是挺好奇CLN在Convolution Layer里面的作用, 可惜作者没有做实验.
Summary
W2NER构建出一张Word Pair之间的二维表, 将现有的三大类NER任务转化成单词间的关系分类问题, 因此可以统一到同一个NER框架当中.
模型中, 引入了Conv2D来从二维表结构中获取信息, 并将Encoder Layer的信息和Convolution Layer的信息剥离开, 用Co -Predictor单独得到Logits.
从实验结果来看, W2NER展现出强大的NER任务形式统一能力, 并且性能良好, 以至于在实验部分作者也不需要过多的分析.
这种基于Token Pair的分类方式很大程度受到TPLinker的启发(也就是我在文中说的THW的相似性). 其实不光在NER, 在情感分析中, 以及其他信息抽取领域中已经逐渐成为主流.

