本文前置知识: Vision & Language Pretrained Model 总结.
2025.05.06: 应评论区要求, 更新了Qwen-VL系列(Qwen-VL, Qwen2-VL, Qwen2.5-VL).
Multimodal Large Language Model 总结
最近MLLM的进展实在是太快了, 必须得赶紧写一篇博客出来了… 再不写这些知识就要过期了…
所以, 本文只是以总结的形式梳理了近期比较有代表性的MLLM, 推荐有基础后再阅读.
Revolution of Visual-Language Adapter
目前的MLLM基本组成有三部分, Visual Backbone, V-L Adapter, LLM:
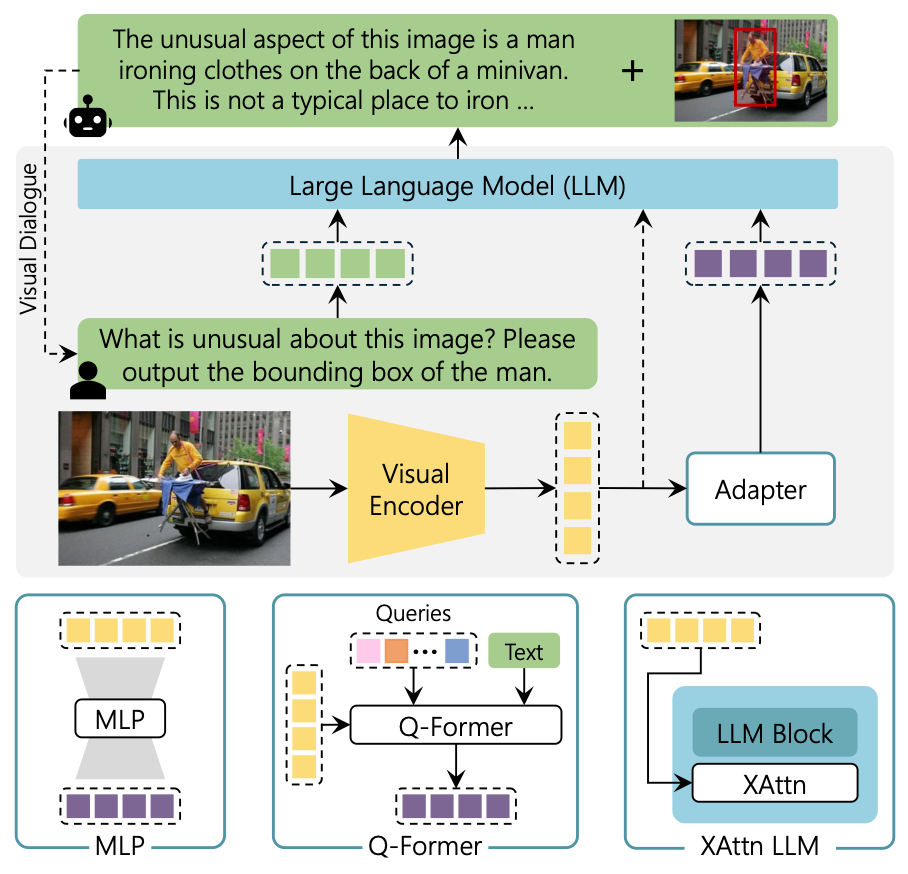
该图出自The Revolution of Multimodal Large Language Models: A Survey.
之前的MLLM基本在LLM内部没有什么变化, Visual Encoder基本也用的CLIP的Vision Encoder, 主要区别在于Adapter上.
Flamingo
Flamingo代表了在LLM主干中加入Cross Attention从而用视觉增强文本表示的一派.
Flamingo将视觉信息融入LLM的方式是在LM Block的主干上串行的加入一个用Cross Attention增强文本表示的模块, 从而让文本表示中能融入视觉信息:
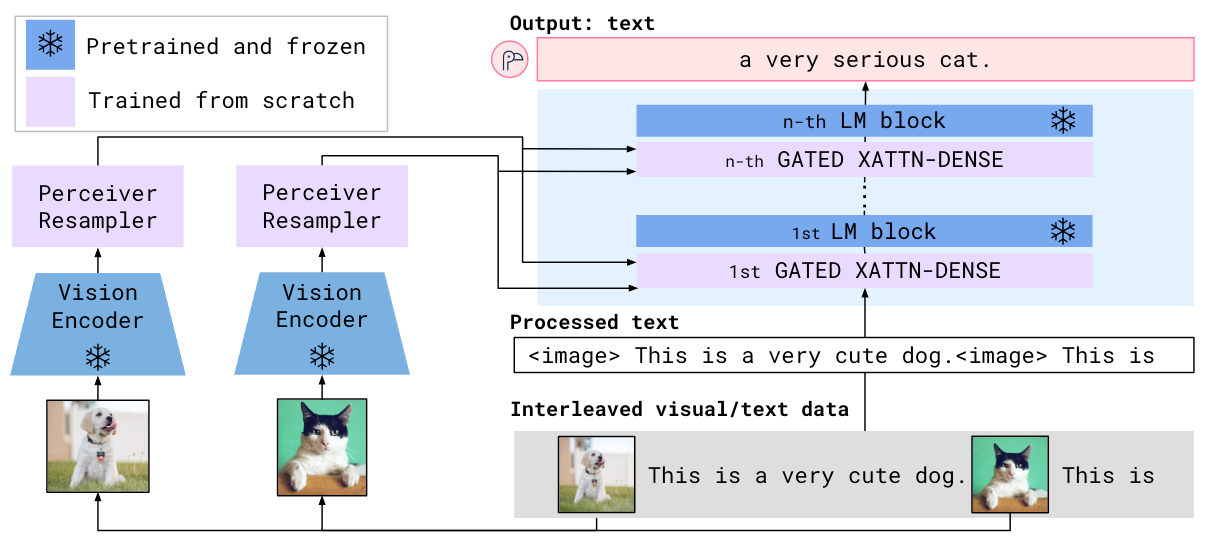
预训练LM为Chinchilla 1.4 / 7 / 70B.
作者在每个LM Block前面加上了一个Gated Cross - Attention Block. 结构如下:
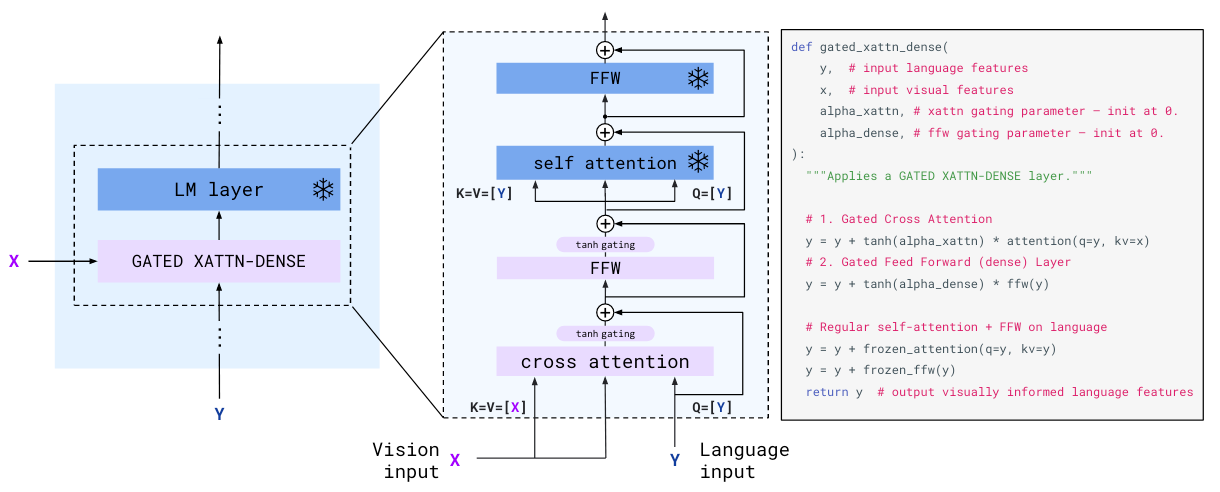
以Language为Query, Vision input为Key和Value, 并用Tanh和残差做一下过滤, 决定视觉增强的文本表示流通率的门控系数为全0初始化, 跟LoRA有点类似.
其中Receiver Resampler是用类似BLIP和CoCa的Query和Cross-Attention汲取有效的视觉信息:
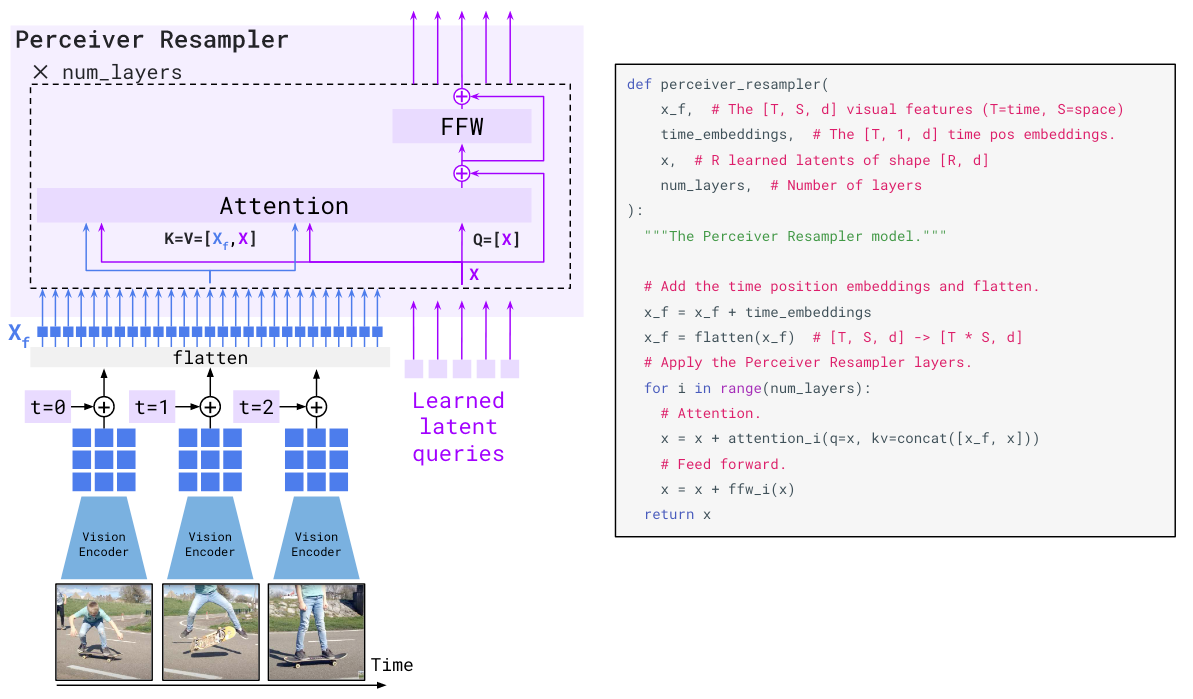
Resampler中Cross Attention的Key和Value是Visual Representation和Query Representation的拼接.
比较有趣的是作者提到了Flamingo对交错图文(Interleaved Image Text)的数据的处理方法:
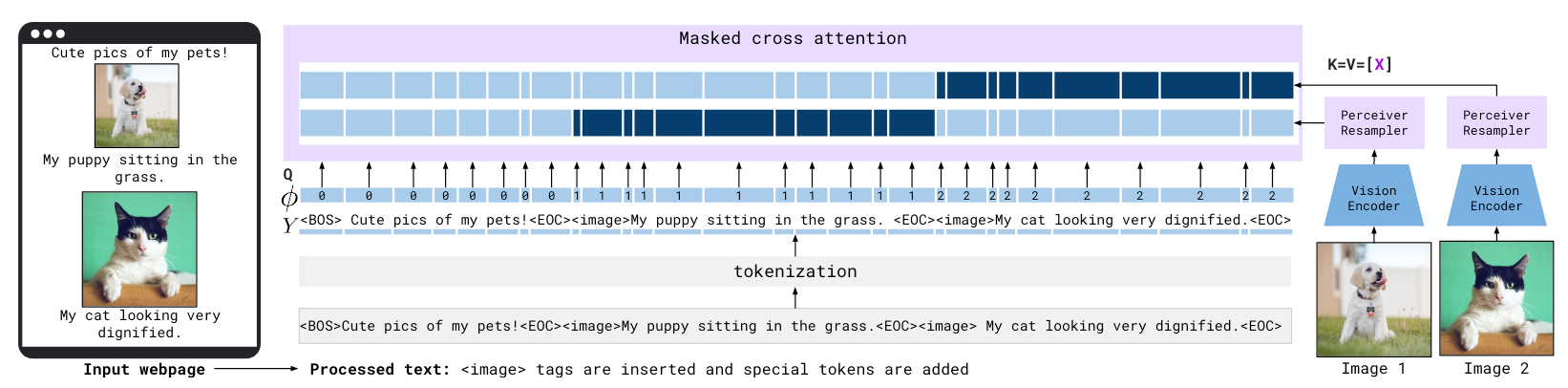
在一系列文本和一系列图像构成的图文交错数据中, 每个文本块中Token在Cross - Attention中只能对对应的Visual Token做Attention(深蓝色), 而无法对其他Visual Token做Attention(浅蓝).
在作者的实验中, 将作者构建的交错图文数据集去掉后, 模型效果下降非常恐怖.
BLIP-2 / InstructBLIP
BLIP-2开创了以VL对齐的Q - Former抽取视觉信息送给LLM的先河.
BLIP-2
BLIP-2我们在VLP总结里面其实已经讲过了, 在这里只是简单的把它粘过来, 以保证内容完整性.
出发点: 当前大规模模型在预训练期间的高额计算消耗太大, 数据也用的特别多.
作者引入一个lightweight Querying Transformer (Q - Former)来完成Visual & Language模态的桥接过程:
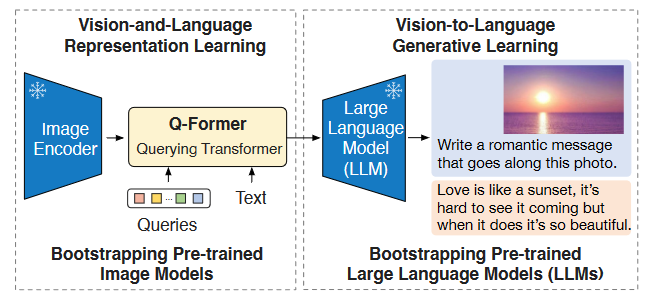
作者把Q - Former的训练拆分为两个阶段:
- 首阶段: 让Q - Former从Freeze Image Encoder中学习VL表示.
- 次阶段: 从Freeze LLM中学习VL表示.
Q - Former结构和首阶段预训练如下:
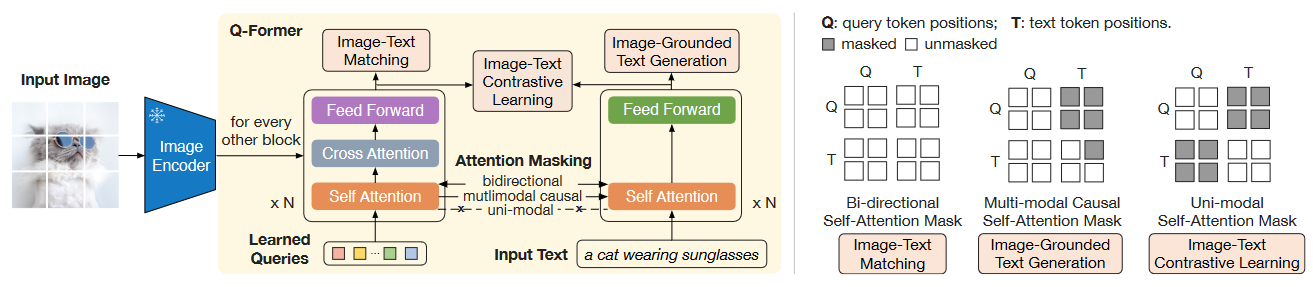
Q - Former实际上由双塔的两个Transformer组成, 分别被称为Image Transformer和Text Transformer. 结构上类似于BLIP中的Image - Grounded Text Encoder和Text Encoder.
Image Transformer的SA和Text Transformer的SA参数是共享的(这点和VLMo出奇的一致). Learnable Query从Image Transformer给入, 通过CA来从Frozen Image Encoder中获取视觉信号.
作者还在文中补充了一个小细节, 实际上的Visual Key Value采用的是Image Encoder的倒数第二层输出, 而不是最后一层, 效果会稍微好一点, 这点与大家使用Stable Diffusion的时候取CLIP的倒数第二层输出有点类似.
所以从结构上来看, 首阶段的训练目标是希望Query能够学到从Image Encoder中抽取对Text最有用的内容. 再看训练任务也是这样, 设计了三种:
- ITC(Image - Text Contrastive Learning): 虽然说是老生常谈的Loss, 但因为Query经过Trm以后得到的表示有多个, 所以作者计算了多个Query与Text Transformer
[CLS]的余弦相似度, 选择相似度最大的作为正样本. 为了避免信息泄露, 在做ITC的时候要保证Q和T之间是互相不可见的(最右侧Mask). - ITG(Image - grounded Text Generation): 使得Q对T完全可见, T单独用causal Mask, 然后生成图文匹配的文本段. 这就要求Query必须覆盖Image的全部信息, 且Query抽取出的信息必须是有效的(中间Mask).
[CLS]也被换成[DEC]. - ITM(Image - Text Matching): ITM也是常见Loss, Q必须拥有两个模态的信息才能一起判断图文是否匹配, 作者对所有Query都计算ITM Loss, 最后取平均作为Logits, 同时也使用Hard Negative.
次阶段预训练, 直接用Q - Former完成图生文:
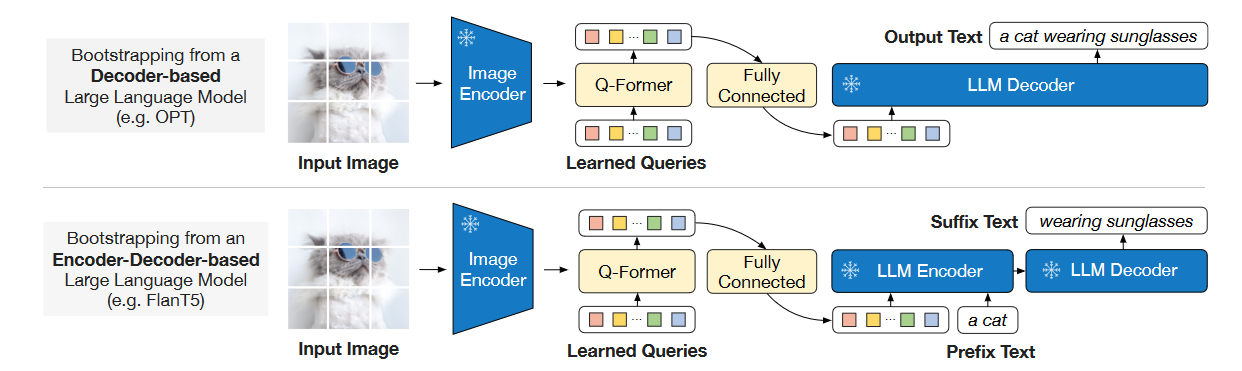
由于在首阶段中Q - Former已经完成了Query从Image Encoder中抽取关键信息的学习, 这也就使得Visual Signal可以被Query以Soft Visual Prompt的形式传递给LLM. 所以Q - Former中的Text Transformer变得不再必要, 可以被丢弃. Query表示还需要过一层Linear Project和大模型输入维度对齐.
如果不要首阶段直接硬学的话, 由于没有Text Transformer打辅助, 所以想要让Q - Former学到从Image中抽取出更多有关文本的信息会更难. 但文本模态在Q - Former首阶段训练中起到的实际上是一个Grounding的作用, 根据Language来让Learnable Query抽取更多有用的信息.
InstructBLIP
延续BLIP-2的Q - Former, 在Q - Former中添加了Instruct, 从而使得Q - Former能完成Instruction-aware Visual Feature Extraction, 从而将Visual Feature从静态的变为动态的, 能够做到instruction following:
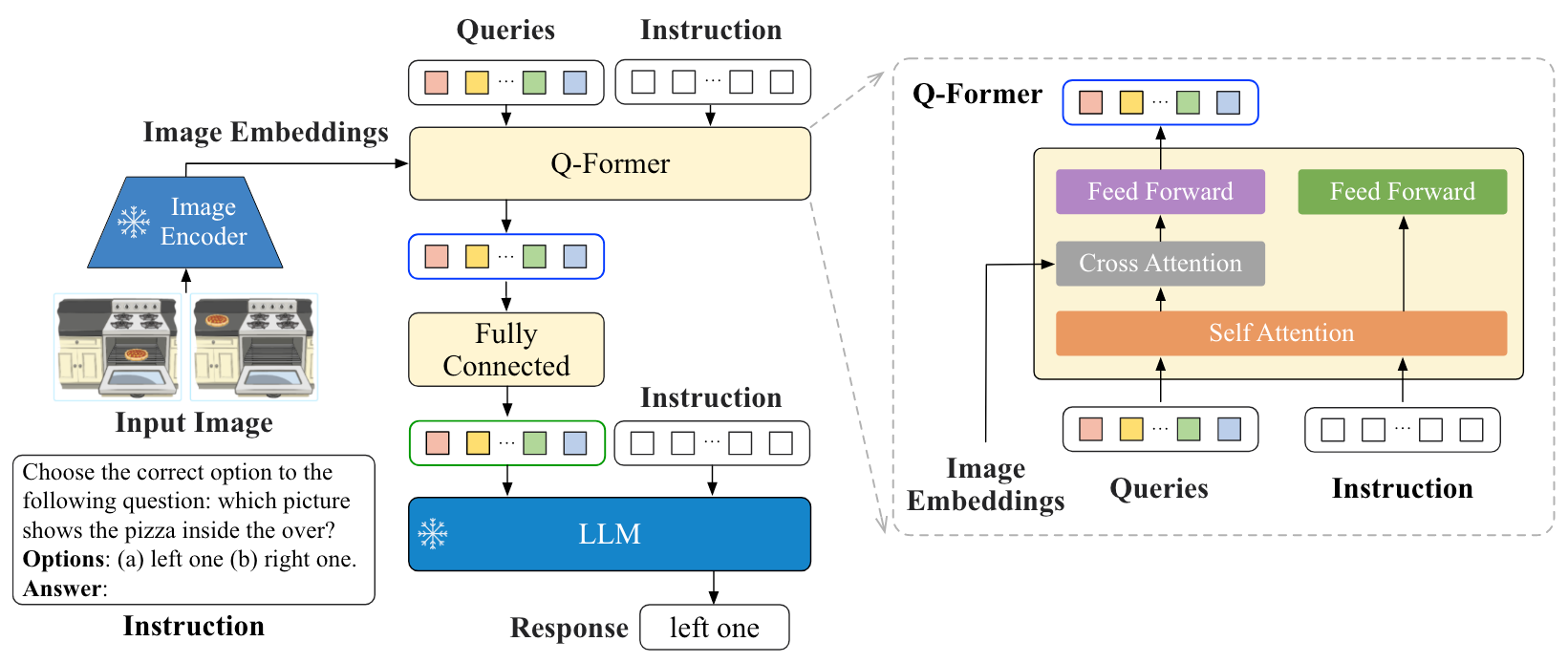
其余细节基本一致.
直接使用BLIP-2里面已经对齐好的Q - Former作为初始化(看做是预训练), 然后直接在Q - Former和LLM侧继续进行指令微调, 使Q - Former能够理解指令, 并完成指令引导的视觉特征抽取. 指令构造来自人工手动.
与之类似的还有同样为BLIP系列续作的X-InstructBLIP, 但审稿人似乎认为这种方法并没有具备很大的贡献, 以及实验不够充分缺乏与当前的MLLM对比, 于是在ICLR 24被拒稿了.
LLaVA系列
LLaVA代表了整个使用MLP为Adapter的一派.
LLaVA
与BLIP-2的Q - Former不同, LLaVA抛弃了沉重的Visual Extractor设计:
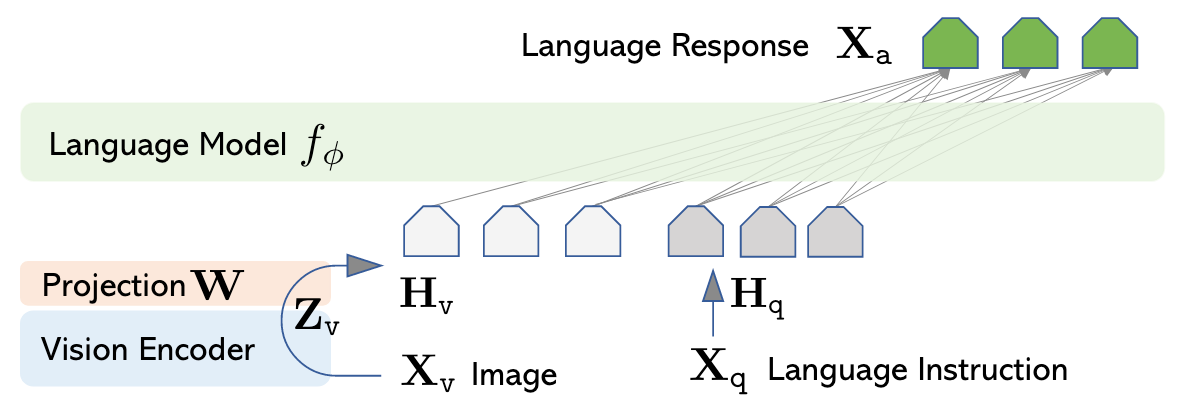
用预训练的CLIP抽取的Visual Feature作为Vision Signal, 再用一次Linear Projection后送到LLM里面.
在LLM中, Visual Token仍然是Autoregressive Encoding的.
LLaVA训练的时候遵循多轮对话:

在第一轮对话的时候把图像信息附加进去即可.
作者设计了两阶段微调, 让LLM能适配Visual Input:
- Stage 1: Pre - training for Feature Alignment, 只调Linear Projection的参数, 使Visual Feature和LLM Embedding Space对齐.
- Stage 2: Fine - tuning End-to-End, 让Linear Projection和LLM一起调.
比较有意思的是, LLaVA的指令数据集是用LLM(ChatGPT / GPT4)生成的, 通过把图像中的信息以自然语言描述出来从而传递给更高阶的LLM, 让LLM生成指令数据.
比如直接把图中物体的Caption和BBox都传进去, 然后让LLM生成三种类型的问题:

LLaVA的表现超过了BLIP-2.
LLaVA 1.5
LLaVA 1.5是LLaVA的改进版本:
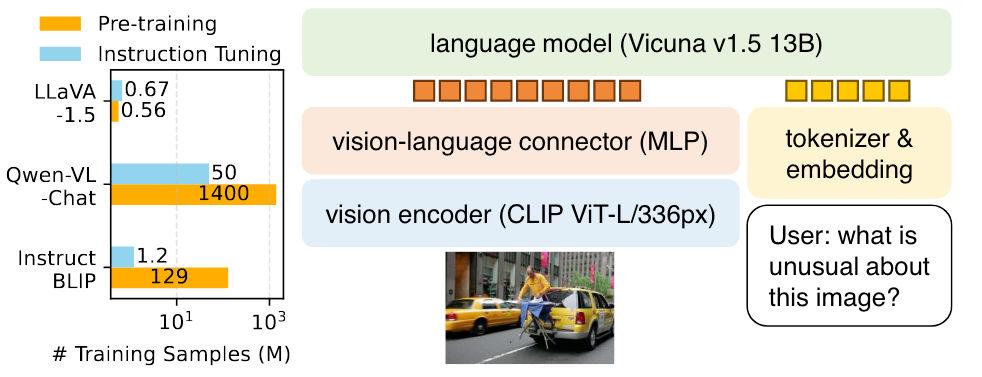
主要做了如下改动:
- 限制了LLM的输出格式, 让LLaVA直接以简短的方式回答, 有利于VQA任务.
- 从一层Linear Project变成了两层MLP.
- 加入了学术方面的数据集, 用于解锁LLaVA对视觉区域细粒度理解能力.
- 提高了图像分辨率, 并加入了额外数据源.
LLaVA-NeXT(LLaVA-1.5-HD)
增强了推理, OCR和World Knowledge.
通过动态分辨率输入, 支持”任意”分辨率大小的图像作为输入(实际训练阶段最大支持4倍):
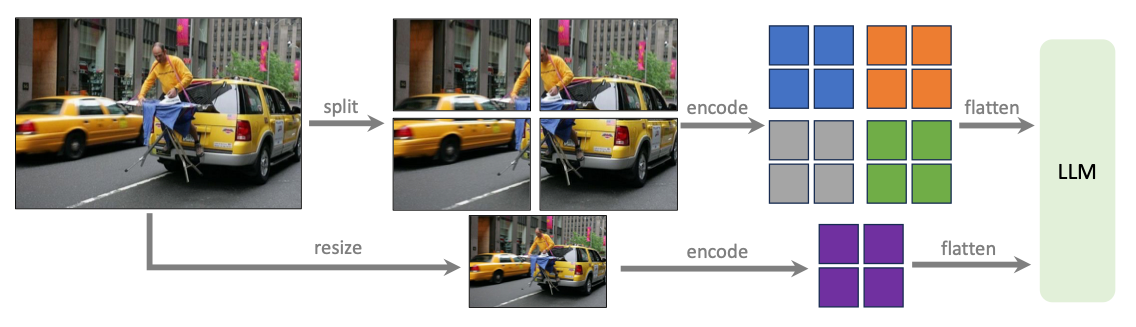
把大图切分为小Patch, 分别用Visual Encoder编码, 再把一个下采样的图编码, 作为全局信息, 全拼接后一起送给LLM.
特性如下:
- 支持动态分辨率输入.
- 采用更强的用户指令数据, 加入更多跟文档以及图片理解的数据.
- 增大LLM backbone的Scale.
Qwen-VL系列
Qwen-VL
- 论文: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond.
- 代码: GitHub - QwenLM/Qwen-VL: The official repo of Qwen-VL (通义千问-VL) chat & pretrained large vision language model proposed by Alibaba Cloud..
Model Architecture
Qwen-VL是一个9.6B的MLLM. Vision Encoder(OpenCLIP的ViT-bigG初始化)占1.9B, LLM(Qwen-7B初始化)占7.7B, VL-Adapter占0.08B, 其设计遵循BLIP-2的Q-Former的形式.
Inputs and Outputs
- Image Input: 由Visual Encoder和Adapter处理的固定长度的Patch Embeddings, 用
<img>,</img>进行包裹. - Bounding Box Input & Output: 进行Grounding的时候, 需要用到Bounding Box. Bounding Box会被Normalize到
[0, 1000)之间, 并且用<box> (X_topleft, Y_topleft), (X_bottomright, Y_bottomright) </box>来描述. 如果是Reference Grounding, 则将Reference Sentence 用<ref>,</ref>包裹.
结合各类具体任务, 格式如下:
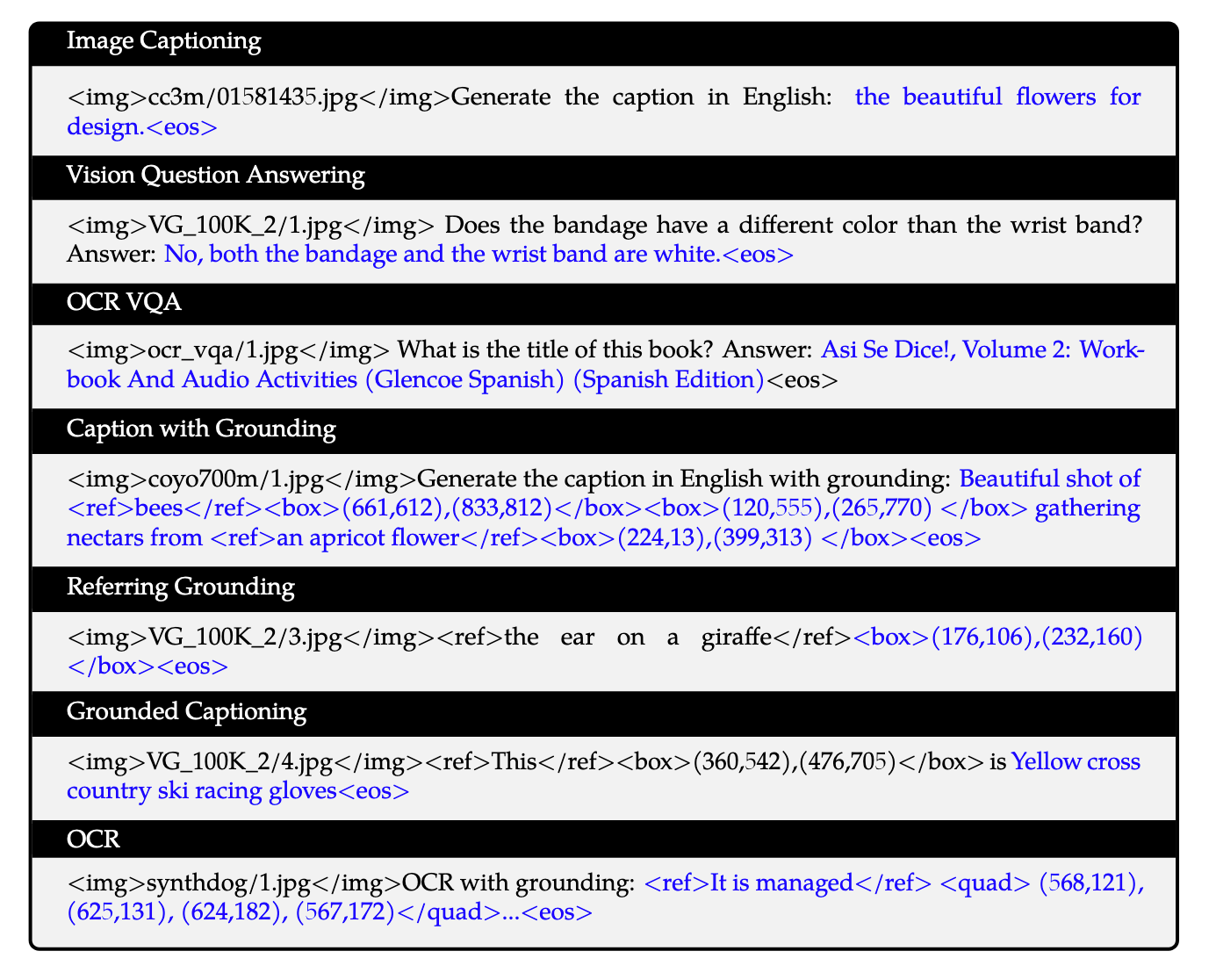
Training
Qwen-VL经历了三个阶段的训练:
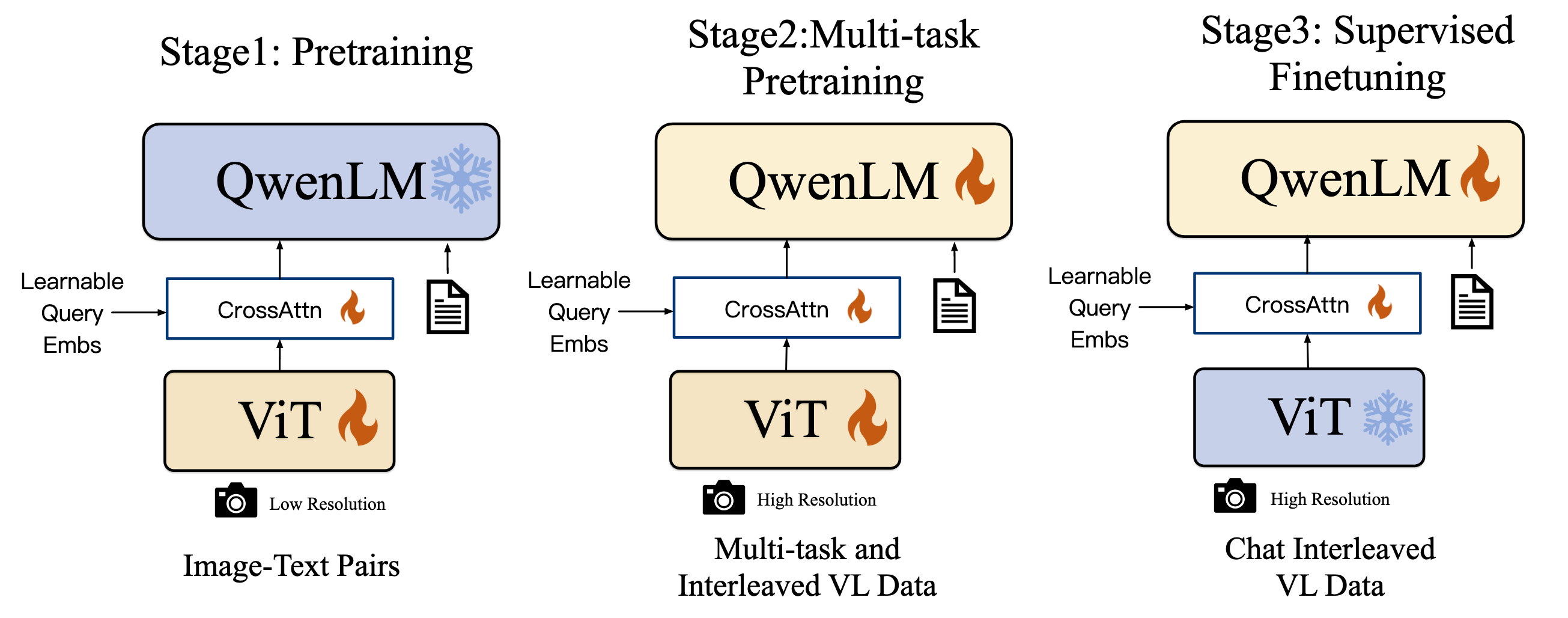
- Pre-training: 在低分辨率($224 \times 224$)的图像上用ViT和Adapter, QwenLM是frozen的. 做Image-Guided Text Generation, 做Vision-Language初步对齐, 用了50亿图文对, 清洗后14亿, 其中有77.3%的英语数据, 22.7的中文数据.
- Multi-task Pre-training: 经历过第一阶段的预训练后, 解冻所有组件. 输入图像也换成高分辨率($448 \times 448$)的. 把Caption, VQA, Grounding, OCR, Pure-text Autoregression等任务串起来放到一起训. Caption和OCR的数据占比比较大, 其次是Grounding. 不难看出这块主要是为了对齐, 而且OCR一定程度加强了MLLM对图中文字的利用能力.
- Supervised Fine-tuning: 冻住ViT, 解冻QwenLM和Adapter. 提高Qwen-VL的Instruction Following和Dialog Performance.
Experiments
Qwen-VL当时也探索了高分辨率图像输入和Global / Window Attention对MLLM的影响, 以目前的视角来看是当今的研究重点之一, 而且也为Qwen-VL系列的后续工作打下了基础.
Training Loss的话肯定是越高分辨率的图像输入效果越好, 但是Window Attention不如Global Attention:
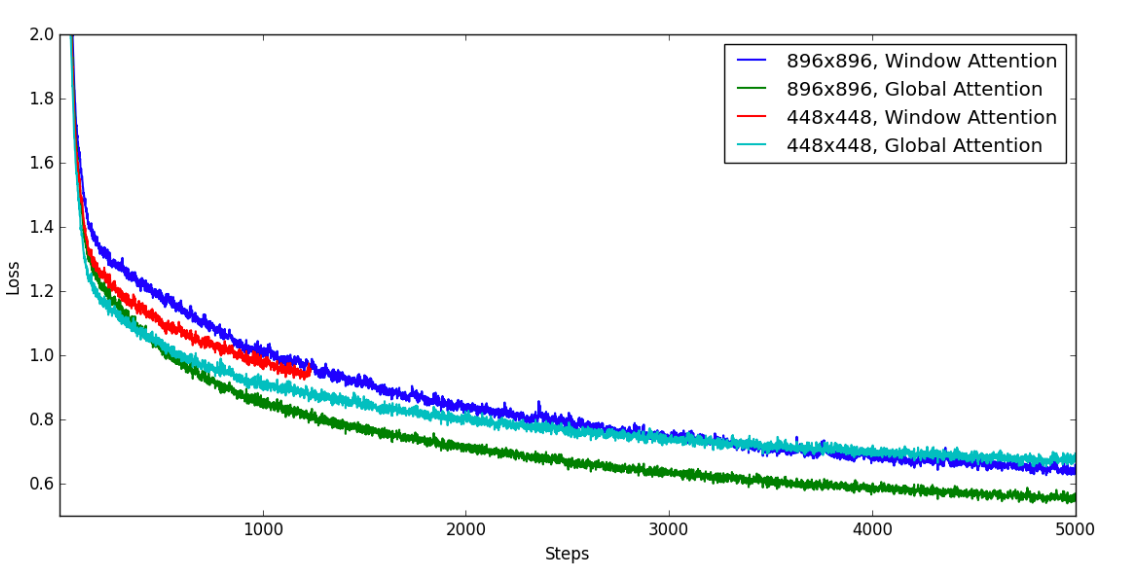
训练速度上其实Window Attention仅在$896 \times 896$下有优势, $448 \times 448$设置下区别不大:

Qwen2-VL
- 论文: Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.
- 代码: transformers/src/transformers/models/qwen2_vl/modeling_qwen2_vl.py at main · huggingface/transformers · GitHub.
Model Architecture
Qwen-VL的续作, 在Qwen-VL的基础上添加了一些特性. Visual Encoder换成了Apple的DFN ViT, 去掉了Cross-Attention, LLM换成Qwen2.
Naive Dynamic Resolution:
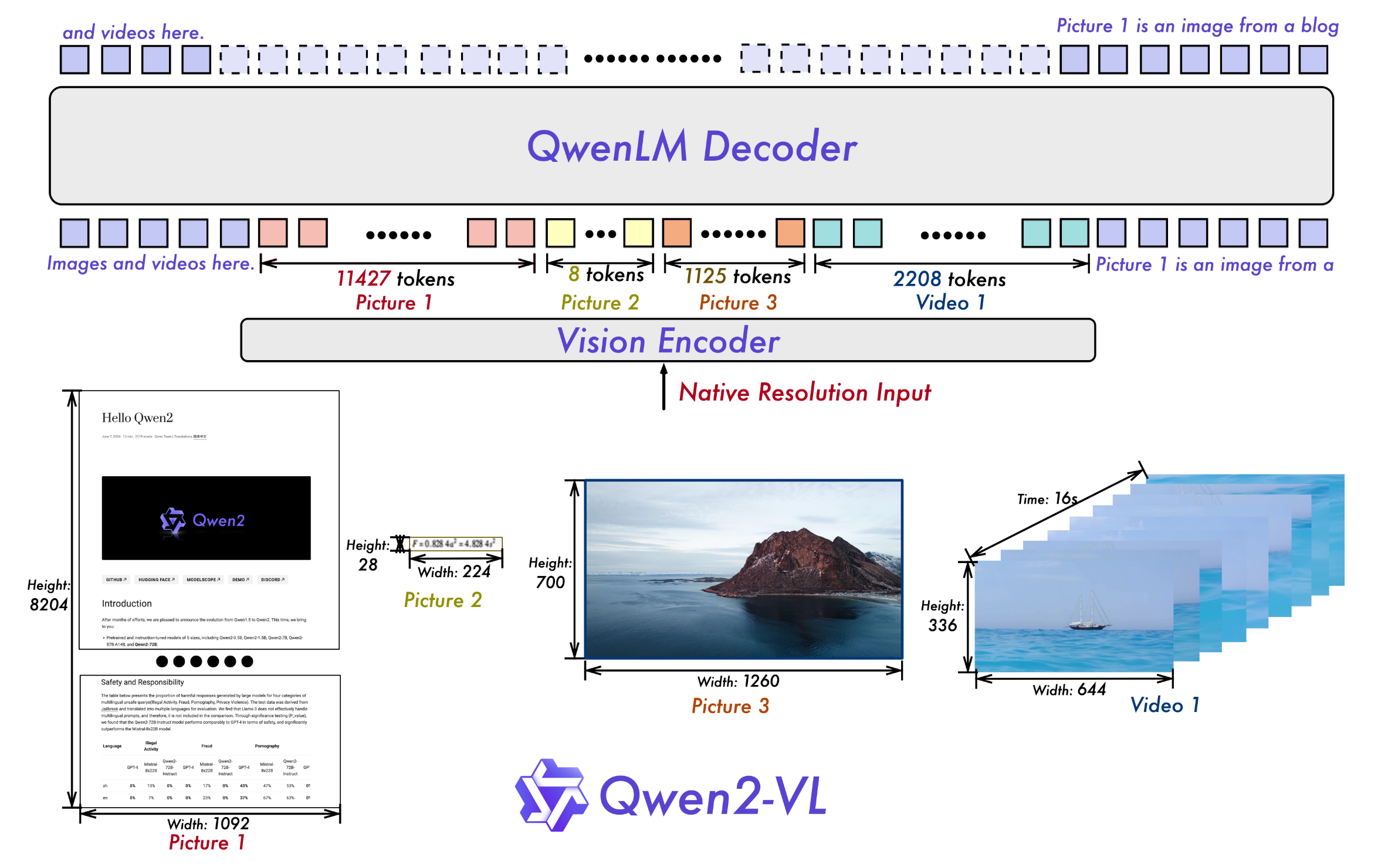 Qwen2-VL提供了一种朴素的动态分辨率支持, 将ViT中的绝对位置编码改为2D-RoPE, 从而支持任意分辨率图像作为输入. 并且为了减少推理资源消耗, 还在后面加了个MLP, 将每$2 \times 2$ 的Patch Token Merge成一个. 所以用`patchsize=14`的ViT提取$224 \times 224$图像, 加上`<|vision_start|>`, `<|vision_end|>`两个用于标识Visual的Special Token, 一共应有66个Token. 这部分想知道具体怎么实现的建议看下代码.
Qwen2-VL提供了一种朴素的动态分辨率支持, 将ViT中的绝对位置编码改为2D-RoPE, 从而支持任意分辨率图像作为输入. 并且为了减少推理资源消耗, 还在后面加了个MLP, 将每$2 \times 2$ 的Patch Token Merge成一个. 所以用`patchsize=14`的ViT提取$224 \times 224$图像, 加上`<|vision_start|>`, `<|vision_end|>`两个用于标识Visual的Special Token, 一共应有66个Token. 这部分想知道具体怎么实现的建议看下代码.Multimodal Rotary Position Embedding (M-RoPE):

视频是3D-RoPE(Temporal, Height, Width), 图像是2D-RoPE(Height, Width), 文本是1D-RoPE(Text Position), 然后把它们拼接在一起. 这里的视频Temporal维是视频输入帧的序号.
实际上这是苏神的博客中已经提过的一种将RoPE扩展到Multimodal的一种解法, 把图像的2D-RoPE和文本的1D-RoPE结合起来, 已附链接, 感兴趣的可以看一下:
- Transformer升级之路:17、多模态位置编码的简单思考 - 科学空间|Scientific Spaces.
- “闭门造车”之多模态思路浅谈(三):位置编码 - 科学空间|Scientific Spaces.
- Unified Image and Video Understanding: Qwen2-VL采用了图像和视频混合训练的方式, 来加强对图像和视频信息的理解能力. 在用视频训练时, 每秒采样2帧, 并用深度为2的Conv 3D来处理视频帧, 也就是将视频的两帧的同位置Patch整合为单个Patch Token. 为了兼容长视频理解, 限制视频Token数最大为16384. 图像可以向视频侧对齐兼容Conv 3D, 将一张图片复制一次, 当做视频的两帧来处理.
Training
训练和Qwen-VL是一样的, 也是分为渐进式的三个阶段:
- 第一阶段只训练Visual Encoder.
- 第二阶段解冻所有的参数.
- 第三阶段只训练LLM.
Data Format:
- Dialogue Data: 使用了ChatML的格式. 图像用
<|vision_start|>,<|vision_end|>包裹, 不同角色(User / Assistant)的回复在<|im_start|>,<|im_entd|>中:
- Visual Grounding: 和Qwen-VL也是一样的, Normalize到
[0, 1000)之间, 然后用<|box_start|> (X_topleft, Y_topleft), (X_bottomright, Y_bottomright) <|box_end|>来描述. 如果有Reference就用<|object_ref_start>,<|object_ref_end|>包裹:
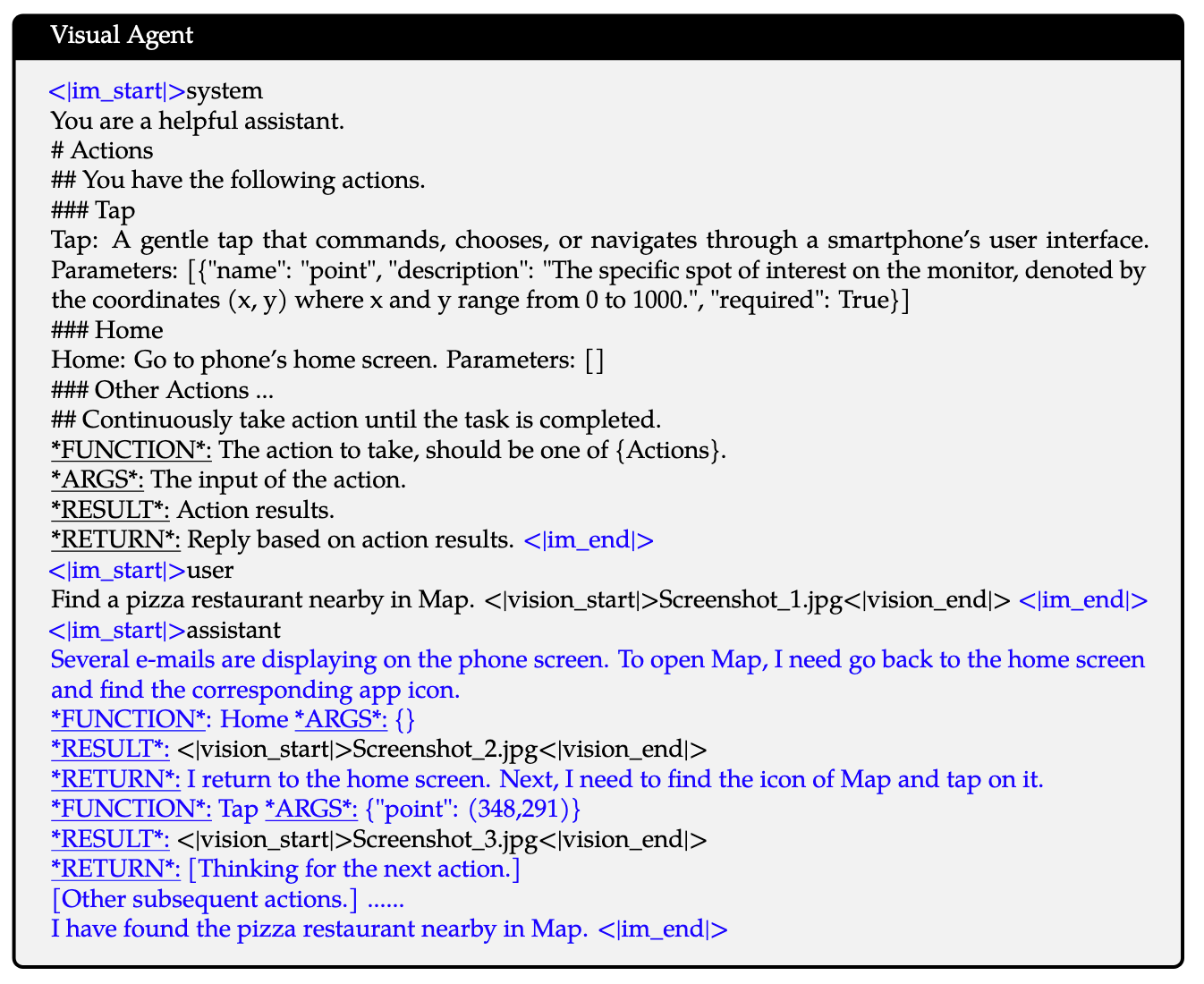
- Visual Agent: Qwen2-VL将能力扩展到Visual Agent. 使得MLLM能够使用Tools与环境交互, 并依赖返回结果迭代:
Experiments
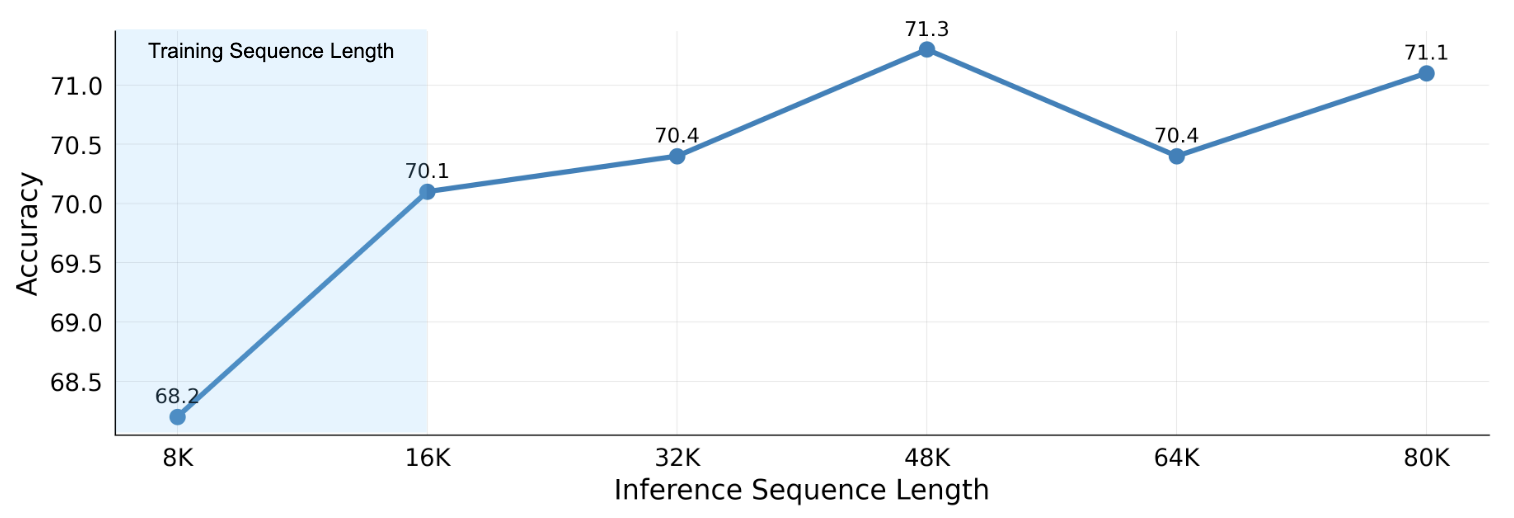
实验部分测试了M-RoPE在视频任务上的良好外推性:
Qwen2.5-VL
- 论文: Qwen2.5-VL Technical Report.
- 代码: GitHub - QwenLM/Qwen2.5-VL: Qwen2.5-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.
能明显感觉到, Qwen2.5-VL自从最近出来了以后, 受关注度就比较高.
Model Architecture
整体结构如下:
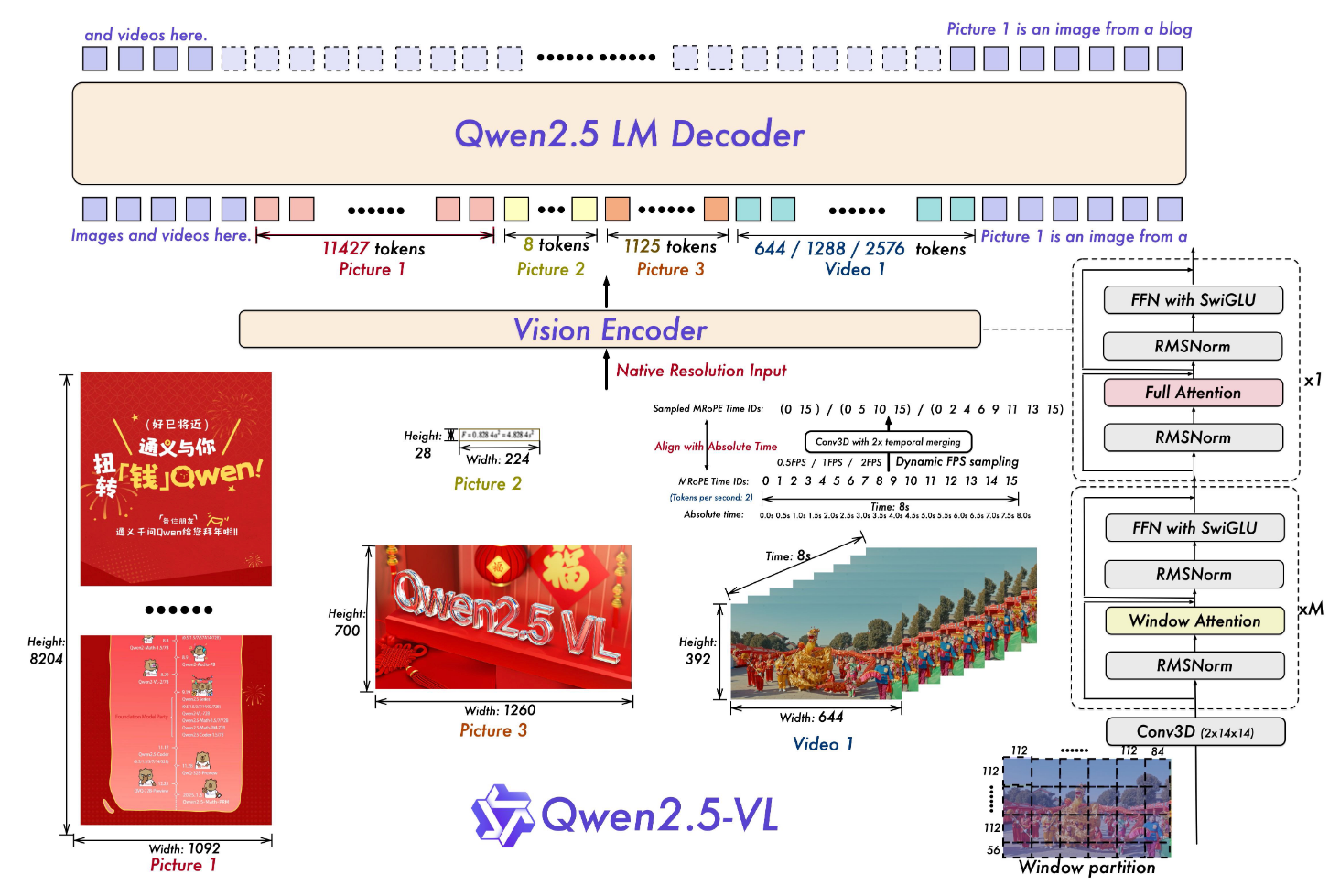
还是老三样, LLM(Qwen2.5), Visual Encoder(一个重新训练的ViT), MLP-based VL Merger(两层Linear, 并对$2 \times 2$ 的Patch聚合).
Fast and Efficient Vision Encoder:
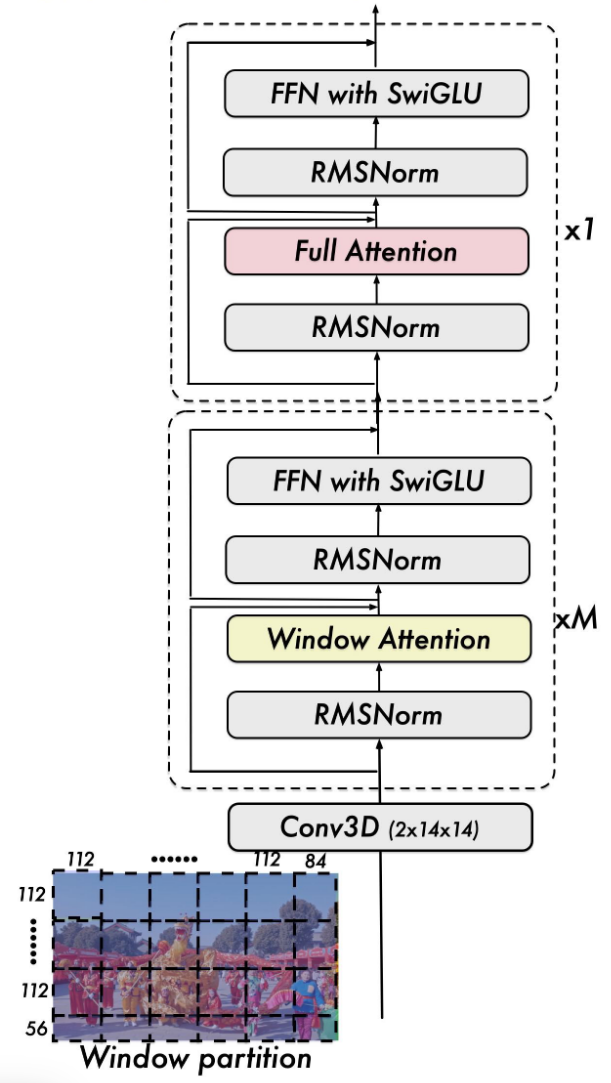
作为Qwen2-VL的升级版, Qwen2.5-VL从Visual Encoder上融入了和Swin Transformer同款的Window Attention, 这其实就是Qwen-VL里面实验部分的回旋镖.
Window Attention由于不做全交互, 所以在计算效率上具有一些优势. Qwen2.5-VL在Visual Encoder中只有四层仍然采用Global Attention, 其余各层采用最大窗口为$112 \times 112$(对应$8 \times 8$个Patch)的Window Attention. 所以Visual Encoder是M层Window Attention + 1一层Global Attention交替组成的:
 此外, Qwen2.5-VL重新训了一个ViT, 并将其中做了一些与LLM结构的对齐设计, 比如Layer Norm替换为RMS Norm, 激活函数换SwiGLU. 训练包含一些常规的阶段, CLIP Pre-Training, Vision-Language Alignment, Finetune. 为了增强Visual Encoder的鲁棒性, 在训练期间图像会进行随机宽高比采样, 从而适应不同分辨率图像作为输入.
此外, Qwen2.5-VL重新训了一个ViT, 并将其中做了一些与LLM结构的对齐设计, 比如Layer Norm替换为RMS Norm, 激活函数换SwiGLU. 训练包含一些常规的阶段, CLIP Pre-Training, Vision-Language Alignment, Finetune. 为了增强Visual Encoder的鲁棒性, 在训练期间图像会进行随机宽高比采样, 从而适应不同分辨率图像作为输入.Native Dynamic Resolution and Frame Rate:
与之前的Qwen-VL, Qwen2-VL不同的是, Qwen2.5-VL不再对图像 / 视频中的坐标进行重新缩放, 而是直接采用像素坐标作为输入, 不再限制模型对原生像素位置的学习能力.
与图像动态采样宽高比类似的, 对于视频输入, Qwen2.5-VL采用了动态帧率训练和绝对时间编码, 通过调整M-RoPE来增强模型对不同FPS的适应能力.
Multimodal Rotary Position Embedding Aligned to Absolute Time:
在Qwen2-VL中, M-RoPE是建立在视频输入帧序号之上的, 虽然这样可以建模输入视频帧的相对位置(事件的发生前后), 但是对于视频中的绝对时间信息就没有塞进时间位置编码里.
在Qwen2.5-VL中, 不像一些其他直接使用时间戳文本作为输入的对齐方式, 而是将视频帧序号与绝对时间对齐:
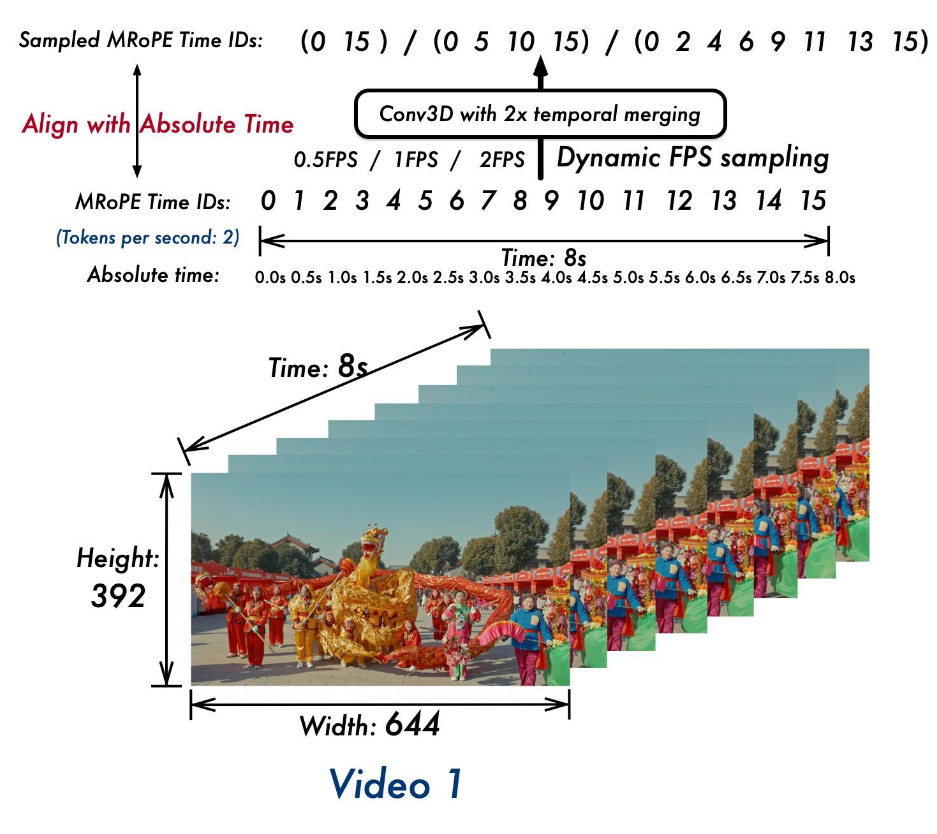
例如, 图中的2FPS, 1秒2帧, 8秒就是16帧, 对应的M-RoPE ID就是0-15. 由于还有一个Conv 3D, 会将两帧聚合为一个Token, 所以最后就只需要8帧的M-RoPE IDs. 其他FPS同理.
这里也可以理解为, 视频的3D M-RoPE中的Temporal维不再采用输入帧的序号, 而是将绝对时间映射为M-RoPE ID, 算是一个小细节上的改动吧.
这部分改动应该是要配合动态FPS训练, 因为在动态FPS下没有绝对时间信息的问题会更加显著.
Pre-Training
Pre-Training Data:
Qwen2.5-VL在数据方面也做了不少工作, 从Qwen2-VL的1.2 trillion Token(这一数字在Qwen2-VL论文里似乎写的是1.4…)扩展到4 trillion Token. 里面除了网上爬下来的清洗数据, 还有一部分合成数据.
数据中包含多种形式: Image caption, Interleaved Image-Text data, OCR data, Visual Knowledge, Landmark, Multi-modalAcademic Questions, Localization data, Document Parsing data, Video Descriptions, Video Localization, Agent-based Interaction data.
- Interleaved Image-Text Data: 由于交错图文对数据质量很差, 噪声很多(比如图文不相关等), 但是对MLLM又必不可少. Qwen团队使用了一套清洗交错图文对数据的方式. 先进行标准数据清理, 然后用一个内部模型分别从四阶段对数据进行打分: 纯文本质量, 图文相关性, 图文互补性, 信息密度平衡来评估.
- Grounding Data with Absolute Position Coordinates: 前面提到过, Qwen2.5-VL不再对Bounding Box进行标准化. 这部分除了公开数据集还引入了合成数据, 例如用Grounding DINO, SAM之类的模型直接打标.
- Document Omni-Parsing Data: 也是合成的. Qwen2.5-VL合成了一大批文档数据.
- OCR Data: 除了多语言的数据集成, 还引入了一部分合成数据. 尤其是对于图表类数据, 用
matplotlib,seaborn,plotly等一些可视化库合成了100w样本. 还有一些是内部数据. - Video Data: 在训练过程中采用动态FPS. 对于时长超过半小时的视频, 用多帧合成的方式来获得长视频的描述. 对于Video Grounding, 采用HMSF的格式统一时间戳格式.
- Agent Data: 感知方面的数据是通过一些收集到的页面, APP截图来合成按钮的位置, 截图描述等. 决策方面数据是从开源数据中合成的带注释的多步轨迹. 统一了移动端和桌面端的Action. 然后用人工过滤和标注了一些推理步骤.
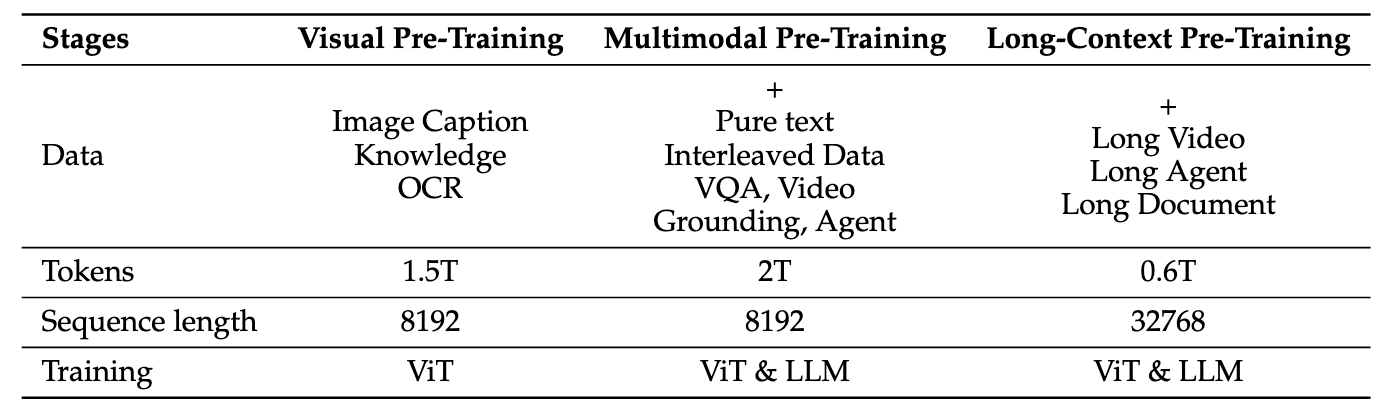
Qwen2.5-VL的训练过程: 先只训ViT, 然后解冻所有参数做Multimodal Pre-Training, 最后再针对长上下文做Pre-Training. 采用的数据分别如下:
Post-training
Qwen2.5-VL先后进行了SFT和DPO.
Data Filtering Pipeline:
为提升SFT数据质量, 进行两阶段Pipeline过滤:
- Domain-Specific Categorization: 用另外一个Qwen2-VL衍生出的模型对QA问题进行层次化分类, 分为30个细粒度子类.
- Domain-Tailored Filtering: 结合Rule-based Filtering和Model-based Filtering对文档处理, OCR, Visual Grounding进行分类别的过滤. 详细看原论文吧.
Rejection Sampling for Enhanced Reasoning:
这部分作者没有写的很细. 主要是对一些会对模型产生误导或者让模型产生错误模式的数据被过滤掉.
- 对于一些推理数据集, Qwen2.5-VL使用中间训练得到的Checkpoint对这部分推理数据进行对比评估, 只保留模型输出与Ground Truth相同的样本作为训练数据.
- 然后去掉了导致模型出现一些混合代码, 过长或者重复模式的数据.
- 最后作者针对只依赖单一模态的问题做了Rule-based和Model-based两种方法过滤, 但是文章里没有细提.
最后, 在进行SFT和DPO时, ViT都Frozen. SFT时在纯文本, 图文对, 视频上进行Finetune. DPO采用图文对和纯文本对齐.
Rethinking Design of MLLM
从Flamingo并入LLM主路的Cross Attention, 再到BLIP-2里Q - Former, 再到LLaVA直接用简单的MLP就完成视觉信号输入, 确实可以得出一些关于MLLM设计的结论, 并引导MLLM的设计走向.
Prismatic VLMs
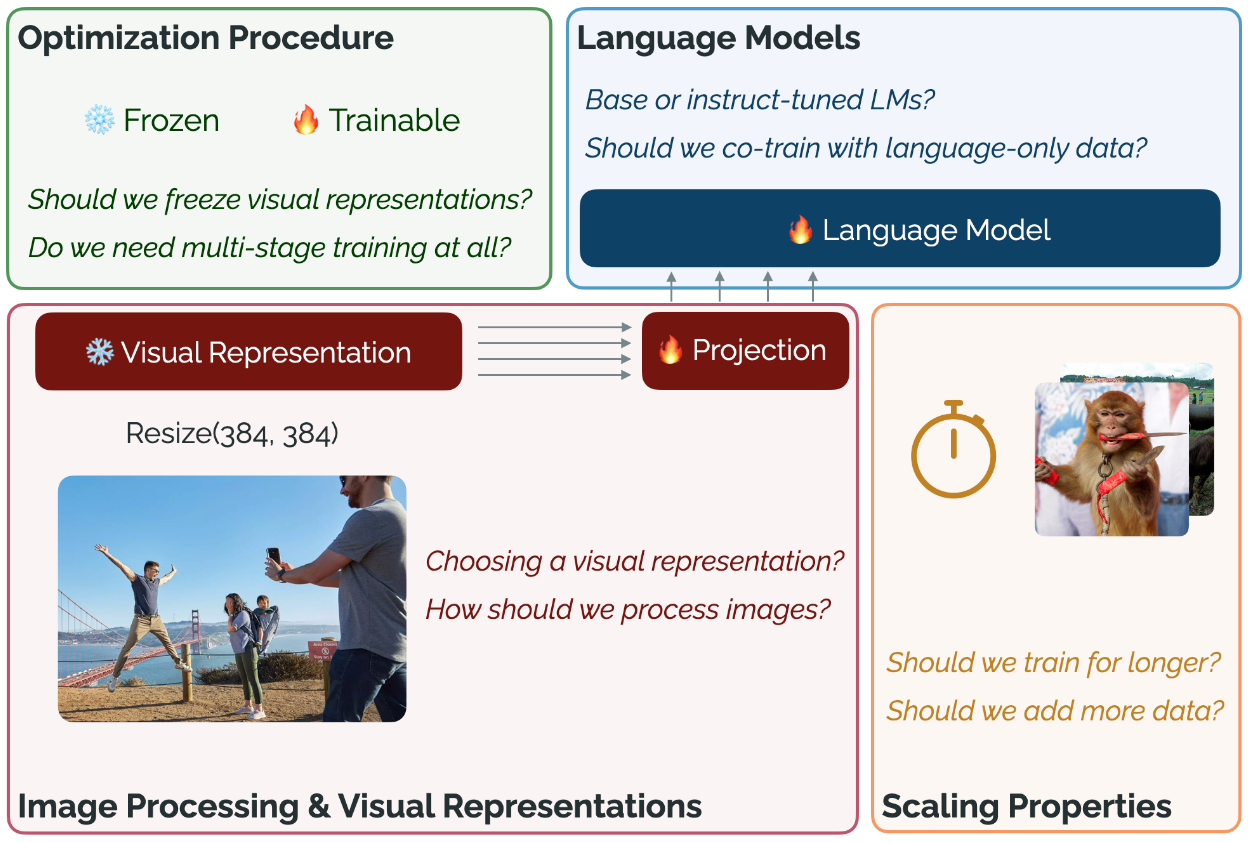
作者探寻了四个维度的VLM设计, 并给出了一些结论:
- Optimization Procedure:
- Multi - Stage Training: LLaVA中是分两个阶段训练, 第一个阶段训练Projection Layer, 第二个阶段全Finetune. 本文作者发现其实直接略过第一阶段也可以, 这样还可以节省训练时间.
- Full Finetuning through Visual Backbones: 在上述单阶段过程中, 必须要把Visual Backbone Freeze住, 不然模型会崩掉, 尤其是Location Task(这个结论和训练数据也可能有关).
- Image Processing and Pretrained Visual Representations:
- Choosing a Pretrained Vision Representation: 同规模下, 用VL Contrastive训练过的CLIP, SigLIP比纯视觉无监督DINOv2和有监督的ViT效果要好.
- Image Processing across Visual Backbones: 对于CLIP而言, 简单的Resize比Crop-Resize要好, SigLIP则在简单的Resize和Letterbox Padding上表现类似. 不同模型似乎不太一样, 无法得出一个确信的结论.
- Scaling Image Resolution: 高分辨率确实好.
- Ensembling Different Visual Representations: 集成DINOv2和SigLIP的特征效果最好.
- Language Models:
- Base vs. Instruct - Tuned LMs: 没有经过指令微调的LLM和经过指令微调的LLM表现近似, 并且没有经过指令微调的base LLM出现幻觉更少.
- Do Better LMs Lead to Better VLMs?: LLM本身的表现与VLM最终表现不一定有很强的关联.
- Co-training on Language-only Safety Data: 加入Text-Only的安全数据后, 性能只有一点点下降, 但是增加了不少在对话过程中的安全性.
- Scaling Properties Around Training Time and Data:
- Are we Undertraining?: 很多方法都只Train了一个epoch, 实际上有些模型没有充分训练, 还可以继续训练第二个epoch.
- Adding Additional Vision-Language Data: 更多样性的数据堆Scaling VLM很重要.
MM1
Apple团队的工作, 除了从模型角度揭示了一些MLLM的设计表现, 也从数据角度进行了分析.
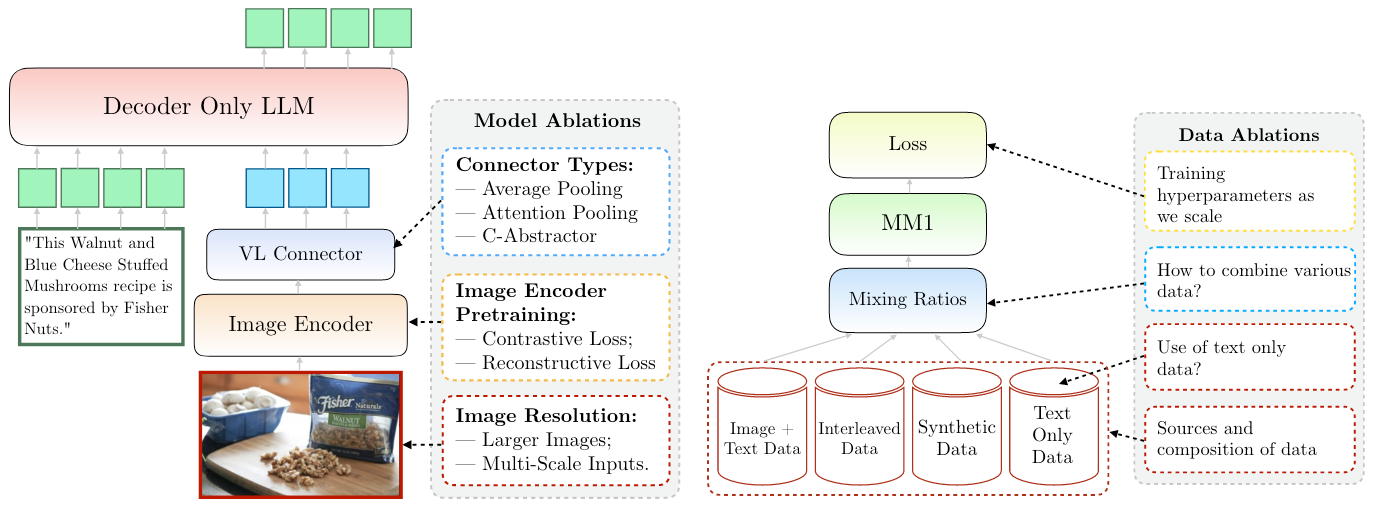
这里直接给出论文中得出的结论:
- Visual Encoder: 图像分辨率影响最大, 然后才是Visual Backbone的Size和数据.
- VL Adapter: Visual Token的数量和图像分辨率最关键, VL Adapter的类型反而不太重要.
- Data:
- 交错数据对提升Few - Shot和Text - Only影响很大, Caption数据对Zero - Shot提升比较大.
- Text-Only数据对Few - Shot和Text - Only性能提升有帮助.
- 合理图文数据配比能带来更好的MM性能并保持住纯文本任务上的性能.
- 合成数据有助于Few - Shot Learning.
Idefics2
来自抱抱脸团队的工作. 文中对MLLM的可能设计做了探索, 最终探索得到的模型结构如下:
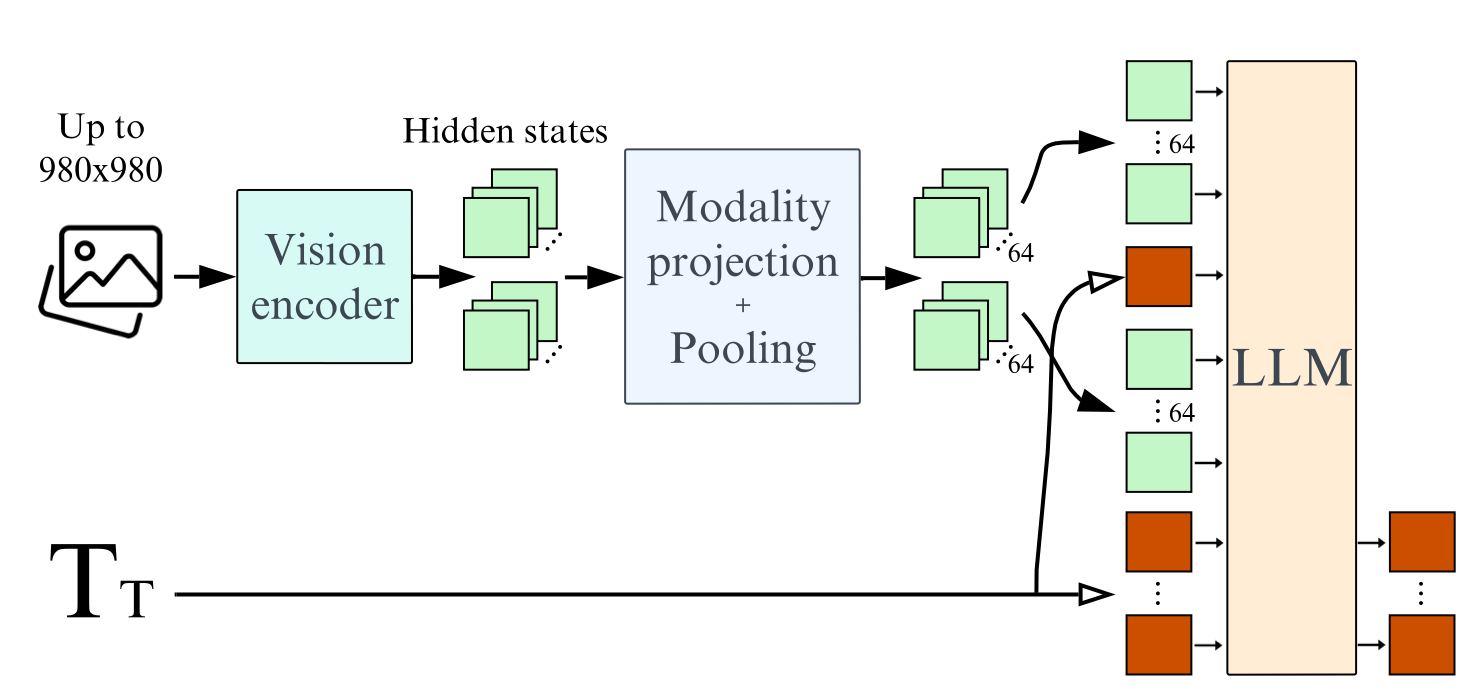
输入图像 -> Visual Encoder -> Projection + Pooling -> 大图分割成小图, 且可能和文本交错 -> LLM -> 输出文本.
一些关键结论:
- 固定参数量下, LLM的质量相比于Visual Backbone的质量对VLM的影响更大(这点和Prismatic VLMs有冲突).
- Cross - Attention(Flamingo并入LLM主干的Cross Attention)比Autoregressive(指不改动Decoder Only的LLM本身, 比如LLaVA)的表现在单模态Backbone冻结的时候效果要好, 但当Backbone解冻的时候, 反而Autoregressive Manner会更好一些, 即使Cross - Attention吃了更多参数.
- Fully Autoregressive的架构的预训练Backbone如果都解冻会导致模型发散, 用LoRA可以缓解这个问题.
- Visual Token过多时, 通过Learnable Pooling来减少Visual Token的数量可以很明显的增加下游任务上的推理效果和训练 / 推理速度.
- 对在固定大小的正方形图像预训练的Visual Backbone, 采用LoRA等方式来保留图像的原始长宽比和分辨率, 不会降低性能, 并且同时还能加速训练和推理并减少显存.
- 在训练时将大图变为拆分出的多张小子图和大图本身, 都作为Visual Token输入到模型当中, 可以在推理阶段用推理效率换来更多的推理性能, 尤其是在涉及到阅读图像中文本的任务中更为明显.
经过一系列摸索以后发现, 之前纠结的VL Adapter形式似乎并不是很重要, 图像分辨率和Visual Token数是重要的, 这也会成为未来(现在已经)的主流发展方向.
除去上述三篇论文以外, 还建议大家阅读一下这个知乎问题, 里面也有很多真知灼见:
- 多模态大语言模型(MLLM)为什么最近的工作中用BLIP2中Q - Former结构的变少了?.
- 也有一些工作对Q - Former的问题做了一些分析:
Do not Stop Generation!
LLM主要还是面向AIGC, 生成还是有很多要做的工作.
NExT-GPT
上面讲的都是一些VLM, 有没有扩展到更多模态的工作?
NExT-GPT提出了从文本 / 图像 / 语音 / 视频作为输入再到上述四种模态生成的LLM框架:
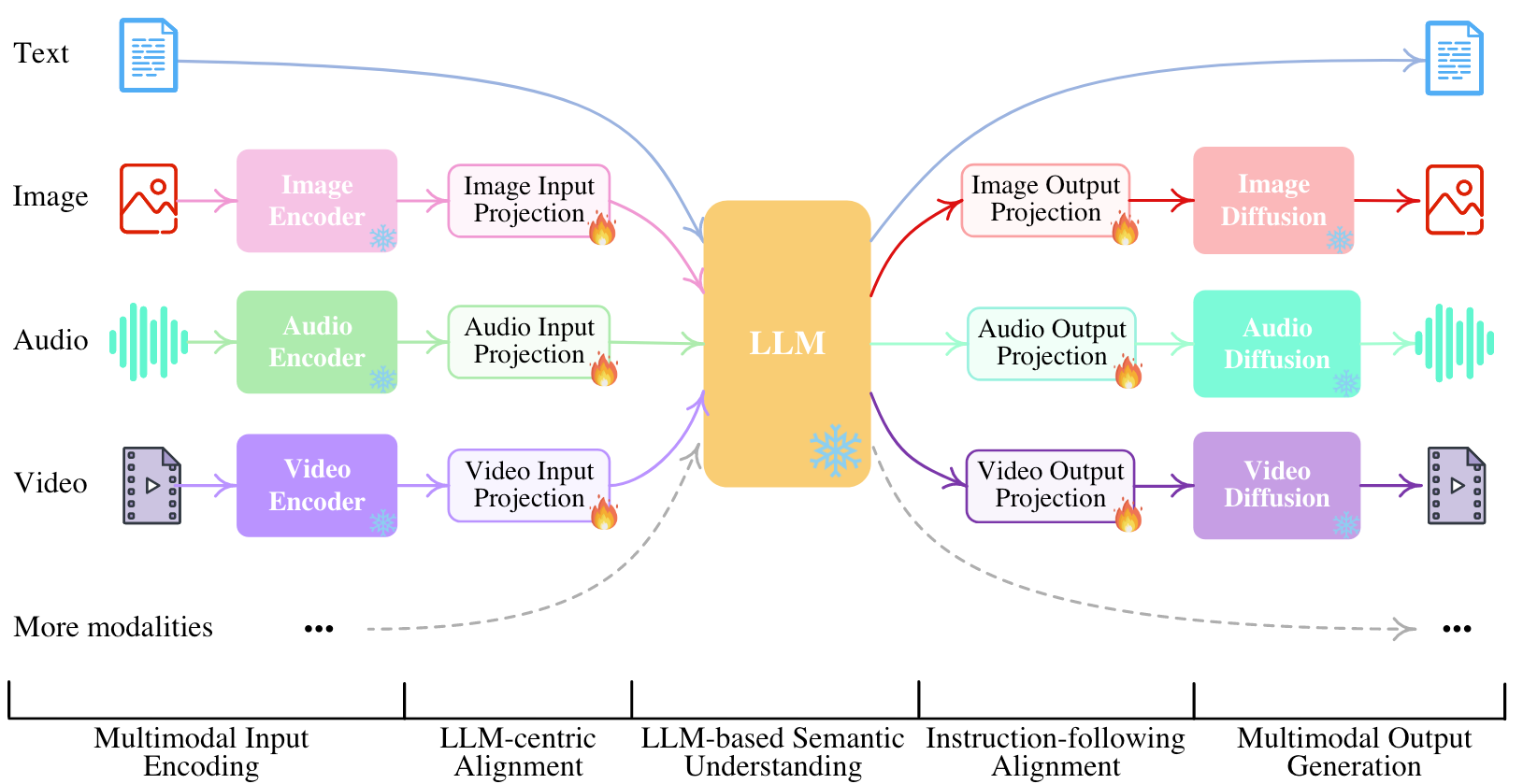
能非常明显的从图中观察到, NExT-GPT是纯粹的LLM Centric, 所有其他模态的编码和生成都围绕LLM来构建. 所有模态都跟Language进行了对齐, 所以可以完成任意模态到Text再到任意模态的生成.
当进行对话时, NExT-GPT能够根据对话过程中生成的特殊Token及其表示来生成对应模态的内容:
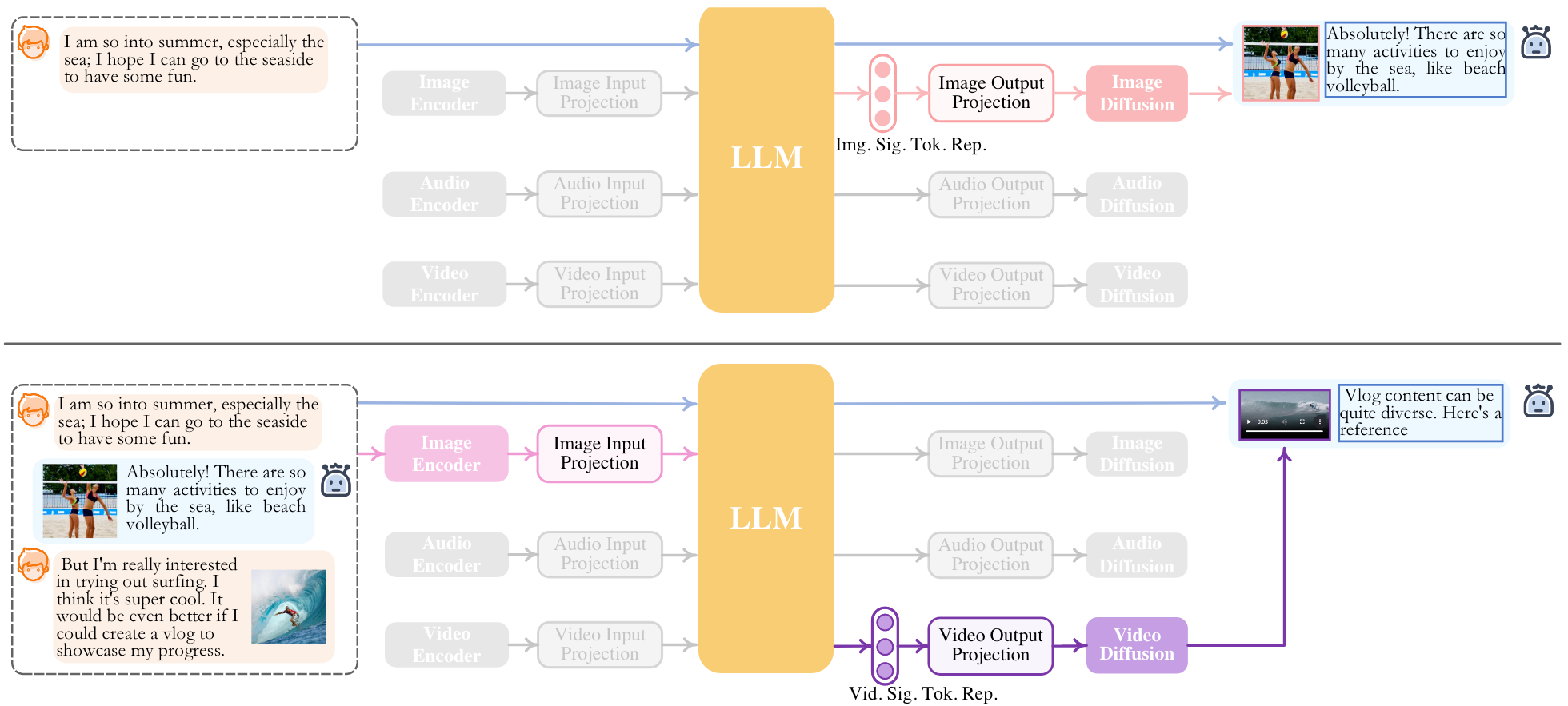
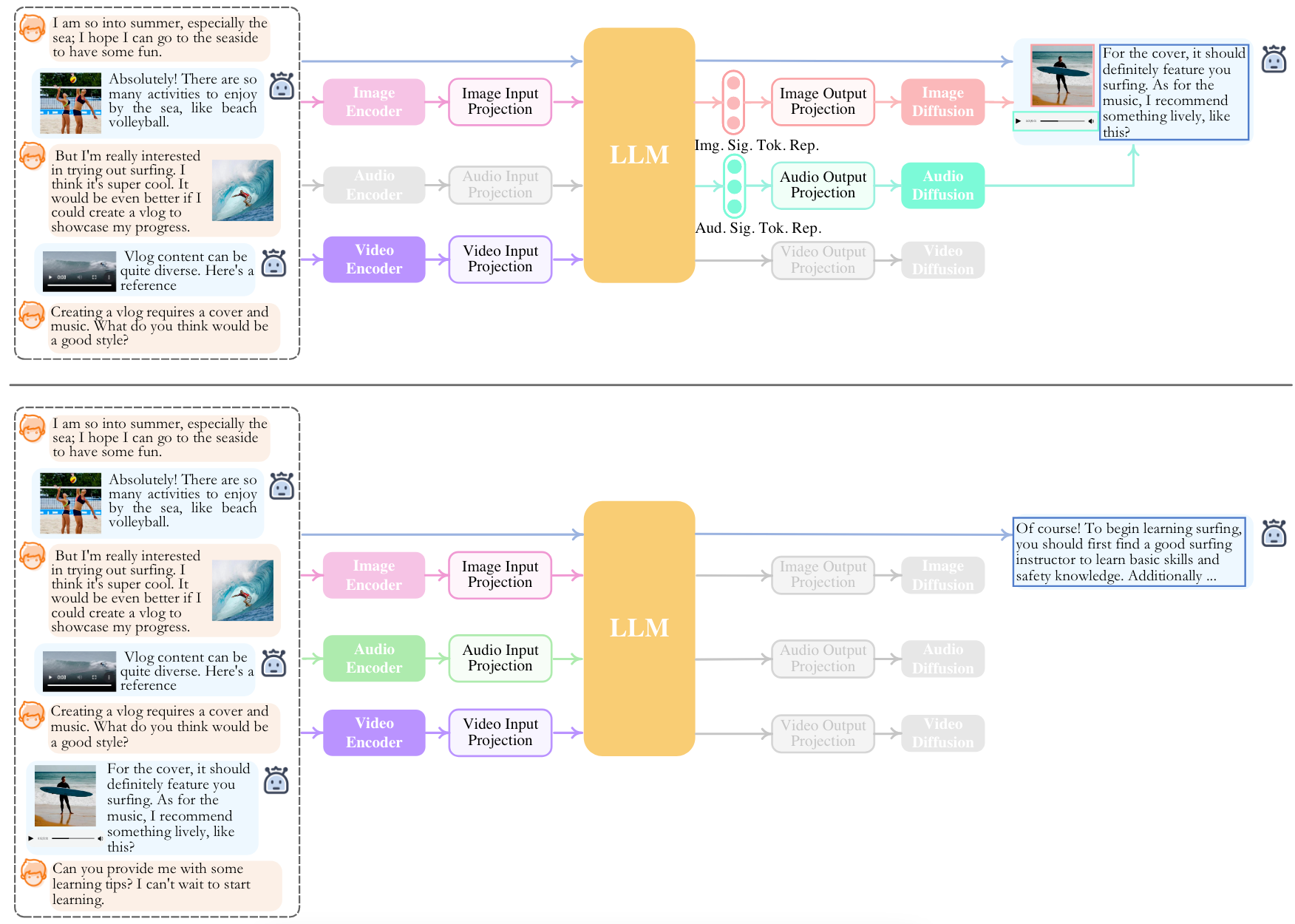
特殊的Token有<IMG_i>, <AUD_i>, <VID_i>, 这些特殊Token的表示会被作为每种模态的Diffusion里面的Condition来引导对应模态生成.
作者用ImageBird当做编码器, 同时编码Image, Audio, Video作为输入.
在优化模型时, 主要做了Encoder和Decoder两侧的模态对齐.
因为要将所有模态都和Text对齐, 所以可以拿除文本以外的模态Encoder抽取出的表示经过Projection, 在各模态Caption的过程中完成Encoder侧对齐:
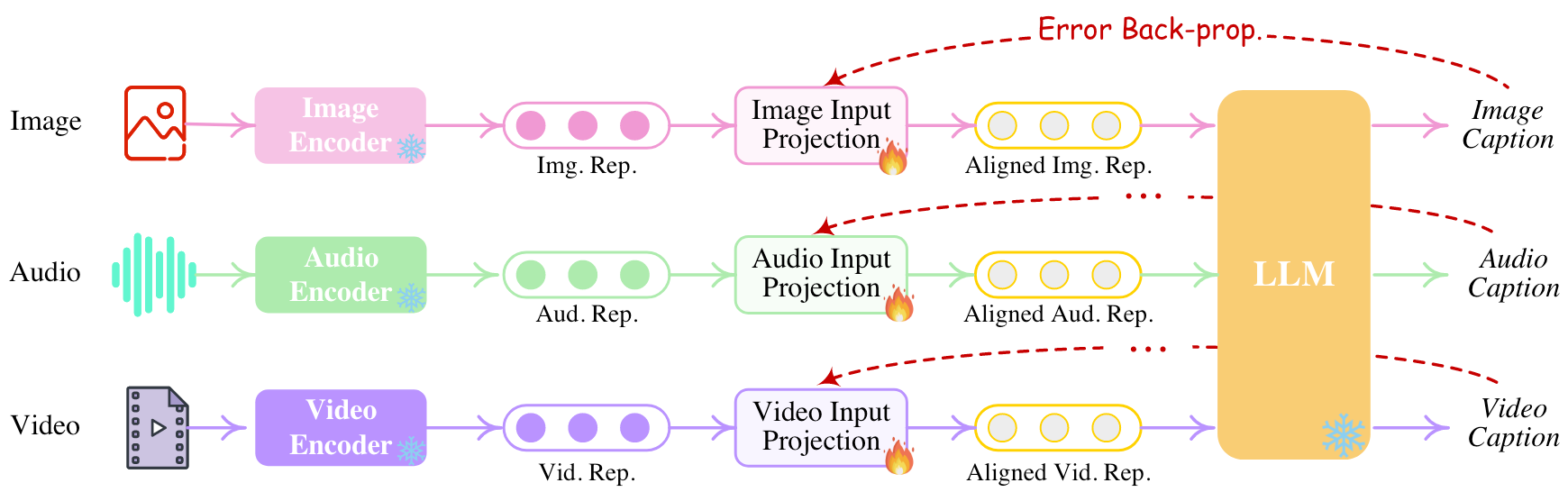
同样的, 由于有各模态Diffusion的Caption, 可以将Diffusion的Text Encoder对Caption编码后的表示(Condition)与LLM输出的特殊Token经过Projection后的表示对齐, 从而完成Decoder侧对齐:
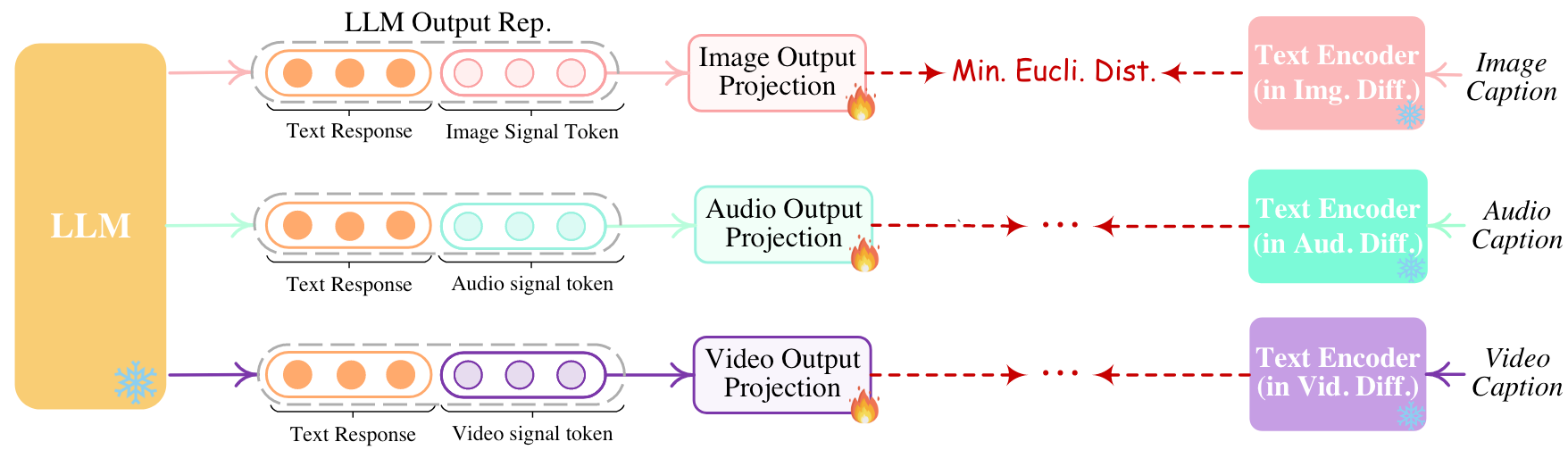
为了让NExT-GPT在对话过程中拥有模态迁移的能力, 还需要进行Modality-switching Instruction Tuning. 对LLM做LoRA Tuning, 并设计几种模态切换的对话场景:
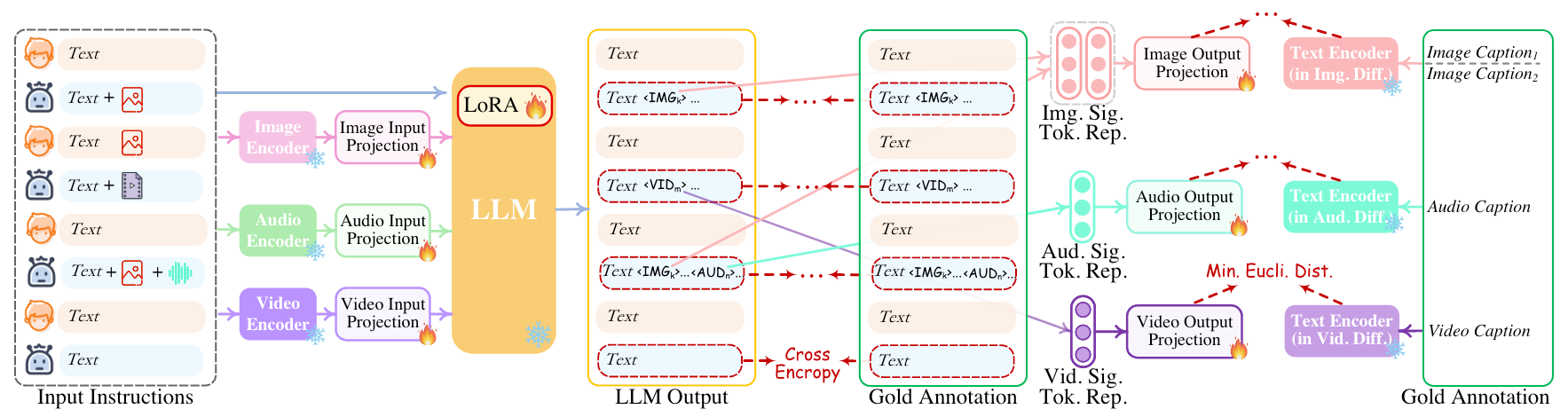
指令数据集根据GPT4和各种模态的Caption共同构造, 之后再人工筛选一下.
DreamLLM
DreamLLM提出了一种能够处理图文交错数据的方法, 并且这种方法能在原始多模态空间中采样生成:
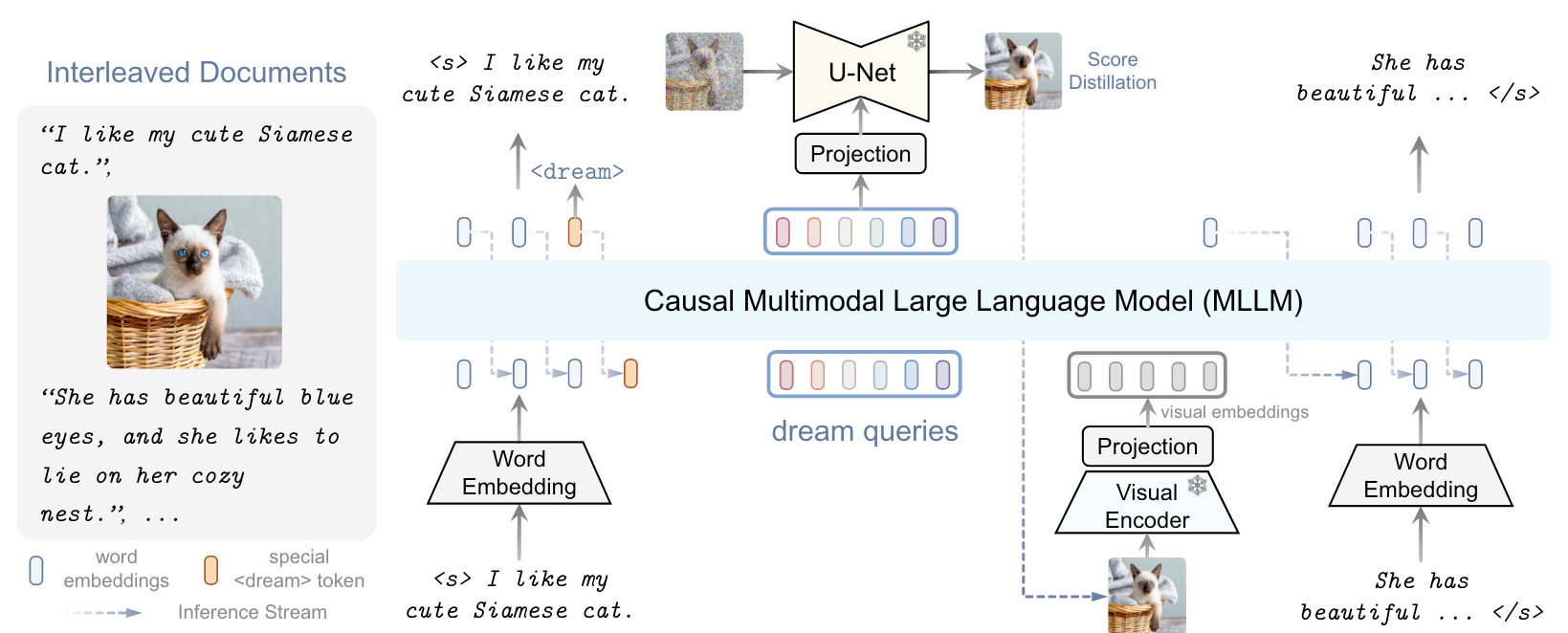
当DreamLLM需要生成图像的时候, 会生成一个特殊的Dream Token <dream>.
一旦生成这个Token, 就说明LLM需要生成图像了. 接着会有若干个Dream Query以Autoregressive Manner喂给到LLM里, 最后这组Dream Query的表示会被用于生成Diffusion Model的Condition. 生成的图像会被Visual Encoder和Projection重新提取为Visual Embedding输入到模型中.
由于这种方式是直接生成或处理的图像, 不需要用CLIP之类的模型对Visual Embedding进行对齐, 所以整个生成过程都是在原始多模态空间中进行的.
训练分为三个阶段, 整个过程Diffusion Model都是冻住的:
- Alignment Training: Linear Visual Projector, Linear Condition Projector和Learnable Dream Embedding解冻, 用30M图文对对齐所有Projector和Dream Query, 在这个期间做图文理解和文图生成. 这样就可以把除了LLM以外的所有组件初步对齐到一个偏于LLM的Multimodal Space.
- I-GPT Pretraining: 解冻LLM, 做大规模文本图像的联合生成式建模, 将所有组件对齐到真正的Multimodal Space.
- Supervised Fine-tuning: 加上指令按下游任务Finetune.
Joint / Interleaved Image-Text Generation
本身LLM其实是一个Universal Decoder, 它的能力一定不止于Text Generation. 如果能够直接统一Visual Token和Text Token生成的方式, 则会带来更灵活的生成效果. 有多种方式可以达到这个效果, 其中一种就是用VQ(Vector Quantization)把视觉图像变成离散化Token, 将Codebook里的离散Token.
当然, VQ这个过程不是必要的, 因为有很多种方式可以达到这个效果, 从DreamLLM里就可以看出来.
因此, 在需要生成图像的时候, 只需要MLLM预测出对应的Visual Token, 然后再交给Diffusion之类的Visual Decoder做个解码, 就能拿到需要的图像了. 这样做的好处是整个Token Space对Vision和Language都是Joint Training的, 能达到非常灵活的输出效果…
比如说在对话过程中, 模型发现用户难理解就直接出个图, 甚至也可以从用户输入的图像中截取一部分做辅助说明(生成Visual Token, 然后再Decode回去), 也可以同时在对话中处理图像并返还给用户.
再结合Flamingo, Idefics2和MM1中发现的交错数据带来的提升, 以及DreamLLM这种交错生成框架的出现, 如果这条线能做Work的话, 能够推测出Joint / Interleaved Generation的时代就要来了, 我比较看好它和Diffusion结合在一起的发挥.
这个部分暂时没什么时间, 没法串起来讲一下, 因为补这条线需要从VQ-VAE先开始讲起, 而且它还在不断演进中… 所以只能给大家一个阅读思路:
- 预备知识:
- SPAE: SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs.
- VLTokenizer: Beyond Text: Frozen Large Language Models in Visual Signal Comprehension.
- LaVIT: UNIFIED LANGUAGE-VISION PRETRAINING IN LLM WITH DYNAMIC DISCRETE VISUAL TOKENIZATION.
- SEED系列:
- Chameleon: Chameleon: Mixed-Modal Early-Fusion Foundation Models.
- TiTok: An Image is Worth 32 Tokens for Reconstruction and Generation.
- SETOKIM: Towards Semantic Equivalence of Tokenization in Multimodal LLM.

