本文前置知识:
- BERT: 详见ELMo, GPT, BERT.
A Unified MRC Framework for Named Entity Recognition
本文是论文A Unified MRC Framework for Named Entity Recognition的阅读笔记和个人理解, 论文来自ACL 2020.
Basic Idea
作者认为, 基于单标签设计的模型不适合在处理Flat NER的同时, 处理嵌套NER任务, 因为一个Token仅可被分配给一个实体, 但在嵌套NER问题中, 一个Token往往隶属于多个实体.
下面有一个嵌套NER的例子:
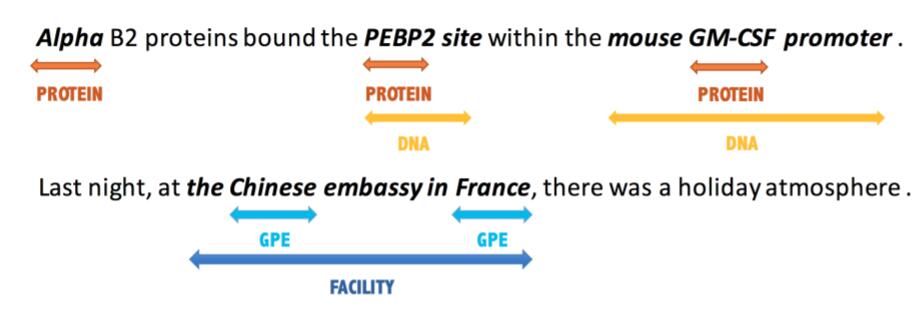
这个句子中, PEBP2 为蛋白质, 但PEBP2 site是一种DNA, 实体间存在嵌套关系.
作者尝试将NER任务迁移到MRC的框架下, 同时解决Flat NER和Nested NER问题, 因为在MRC中, 抽取两嵌套实体, 仅仅只是回答两个不同类别的问题.
Unified MRC Framework for NER
Task Formulation
NER Task Formulation
对于给定的长度为$n$ 的输入序列$X=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}$, 对于每个在序列中的实体, 都有一个预先定义好的标签$y \in Y$, $Y$ 为预先定义好的实体所有可能的类型.
Dataset Constraction
为了将NER任务迁移到MRC框架下, 作者将数据集视为$(\text{QUESTION}, \text{ANSWER}, \text{CONTEXT})$ 的三元组形式. 对于每个实体的类型$y \in Y$, 都需要一个与之对应的长度为$m$ 的自然语言问题$q_y=\set{q_1, q_2, \dots, q_m}$, 实体被标注为$x_{\text{start}, \text{end}} = \set{x_{\text{start}, }x_{\text{start+1}, }\dots, x_{\text{end}-1, }, x_{\text{end}}}$, 且同一实体的$\text{start}$ 必在$\text{end}$ 前.
$X$ 和$Y$ 在NER任务中是已存在的, 还缺少问题$\text{QUESTION}$, 需要根据标签$y$ 进一步生成问题$q_y$, 来凑齐$(q_y, x_{\text{start,end}}, X)$ 的形式.
Query Generation
问题生成是一个非常重要的注入先验知识的过程, 作者尝试了多种生成问题的方式, 最终选择”Annotation guideline notes”, 作者认为这种方法能不产生歧义问题. 这种方法直接使用数据集构建者发配给标注者的标注提示作为问题, 更符合NLP的处理风格.
其方法例子如下表所示:

感觉这玩意就是一种Prompt啊… 给模型对应类型的实体信息提示, 以获取相应类型的实体位置.
Model Details
Model Backbone
现在需要把前面所说的$(q_y, x_{\text{start,end}}, X)$ 整合进MRC框架下. 作者以BERT作为模型的Backbone, 把问题$q_y$ 和句子$X$ 一并输入进去, 格式为$\left\{[\mathrm{CLS}], q_{1}, q_{2}, \ldots, q_{m},[\mathrm{SEP}], x_{1}, x_{2}, \ldots, x_{n}\right\}$.
最后可以获得BERT抽取出的句子$X$ 所对应的上下文表示$E \in \mathbb{R}^{n \times d}$.
作者在这里直接舍弃了问题的表示, 或许在某些问题中, 问题起到增强的作用.
Span Selection
在MRC任务中, 问题的答案一般是基于抽取式的, 也就是直接基于问题和原文内容, 直接在原文中指出问题所在的位置.
往往在MRC中有两类抽取答案的策略:
- 用两个$n$ 元分类器, 分别获取问题的$\text{start}, \text{end}$ 位置.
- 用两个二元分类器, 判断每个Token所对应的位置是否是$\text{start}$, 是否是$\text{end}$.
作者在这里选择第二种, 因为第一种只能抽取出一组$\text{start}, \text{end}$, 而第二种可以抽取出多个$\text{start}, \text{end}$, 这样有更大希望命中与问题$q_y$ 对应的实体.
这两种方法生成Label的时候都可能会有稀疏问题, 可以用Focal Loss等方式缓解.
Start and End Index Prediction
对于从BERT获取来的表示$E \in \mathbb{R} ^{n \times d}$, 首先预测$n$ 个token分别是否为$\text{start}$ 的概率:
$$
P_{\text {start }}=\operatorname{softmax}_{\text {each row }}\left(E \cdot T_{\text {start }}\right) \in \mathbb{R}^{n \times 2}
$$
其中$P_{\text{start}}$ 是是否为$\text{start}$ 的概率分布, $T_{\text{start}} \in \mathbb{R} ^ {d\times 2}$ 是权重矩阵. End Index的获取方式同理, $T_{\text{end}} \in \mathbb{R} ^ {d\times 2}$ 也是权重矩阵, $P_{\text{end}}$ 为是否为$\text{end}$ 的概率分布.
Start - End Matching
一般的NER任务中, 一句话都会包含多个实体. 经过了上一步的Index Prediction, 我们应该获得了多个$\text{start}$ 和多个$\text{end}$ 的概率分布.
如果只是简单的遵循最近匹配$\text{start}$ 和$\text{end}$ 的原则, 是没有办法解决实体嵌套问题的. 因此, 作者考虑一个模型来专门做$\text{start}$ 和$\text{end}$ 的匹配.
先根据我们前面求得的概率分布$P_{\text{start}}$ 和$P_{\text{end}}$ 来确定$\text{start}$ 和$\text{end}$ 的位置:
$$
\begin{aligned}
&\hat{I}_{\text {start }}=\left\{i \mid \operatorname{argmax}\left(P_{\text {start }}^{(i)}\right)=1, i=1, \cdots, n\right\} \\
&\hat{I}_{\text {end }}=\left\{j \mid \operatorname{argmax}\left(P_{\text {end }}^{(j)}\right)=1, j=1, \cdots, n\right\}
\end{aligned}
$$
其中${}^{(i)}$ 代表矩阵的第$i$ 行.
对于任意的$i_{\text{start}} \in \hat{I}_{\text{start}}$ 和$i_{\text{end}} \in \hat{I}_{\text{end}}$, 都直接用一个神经网络接一个Sigmoid做二分类判断是否匹配:
$$
P_{i_{\text {start }}, j_{\text {end }}}=\operatorname{sigmoid}\left(m \cdot \operatorname{concat}\left(E_{i_{\text {start }}}, E_{j_{\text {end }}}\right)\right)
$$
$m \in \mathbb{R} ^{1 \times 2d}$ 为可学习权重.
Train and Test
在训练时, 首先要计算选择起点和终点的损失:
$$
\begin{aligned}
\mathcal{L}_{\text {start }} &=\mathrm{CE}\left(P_{\text {start}}, Y_{\text {start }}\right) \\
\mathcal{L}_{\text {end }} &=\mathrm{CE}\left(P_{\text {end}}, Y_{\text {end }}\right)
\end{aligned}
$$
然后是匹配模型的Span匹配损失, 也是用交叉熵来衡量:
$$
\mathcal{L}_{\text {span }}=\operatorname{CE}\left(P_{\text {start}, \text { end }}, Y_{\text {start, end }}\right)
$$
最后联合优化这些损失:
$$
\mathcal{L}=\alpha \mathcal{L}_{\text {start }}+\beta \mathcal{L}_{\text {end }}+\gamma \mathcal{L}_{\text {span }}
$$
$\alpha, \beta, \gamma \in [0, 1]$, 均为超参, 来控制三个损失对任务总目标的贡献.
Experiments
详细的参数设置请参照原论文.
原文在实验部分的写作采用的是QA的方式, 这种方式很利于集中读者的注意力.
Nested NER
对于嵌套NER任务, 实验在英文数据集ACE 2004, ACE 2005, GENIA, KBP2017上进行, 结果如下:
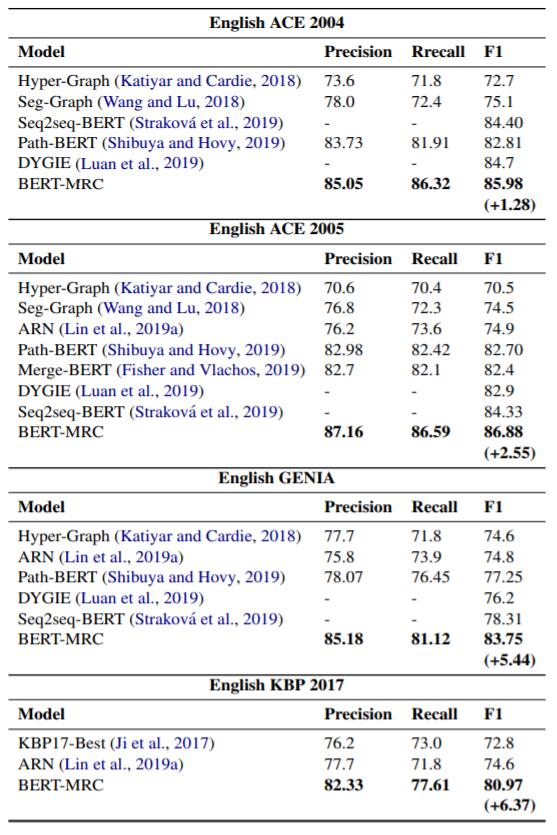
性能涨幅较大.
Flat NER
对于Flat NER任务, 在英文数据集CoNLL 2003, OntoNotes 5.0, 中文数据集MSRA, OntoNotes 4.0 上进行, 实验结果如下:
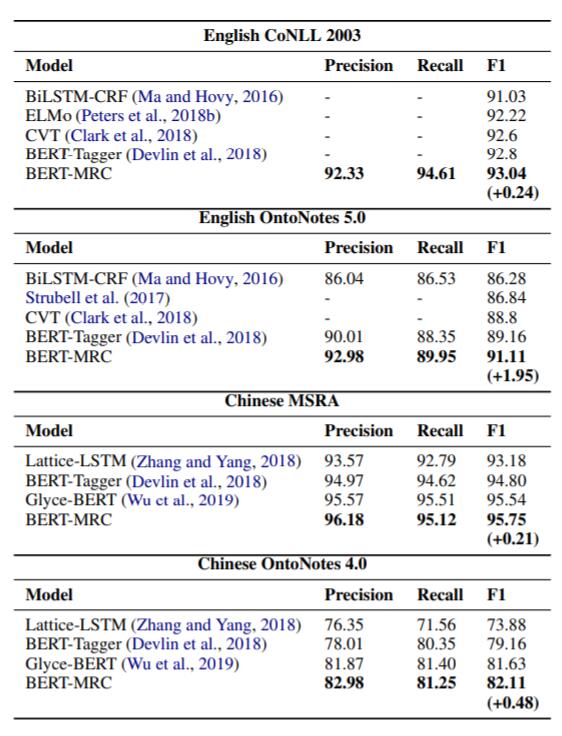
在Flat NER任务上也有一些提升, 结合嵌套NER任务, 此框架确实能很好的处理这两种情况.
BERT - Tagger就是把原始BERT拿来做NER任务, 后续其他实验也用这个Baseline做了对比,
Ablation studies
Improvement from MRC or from BERT
作者将预训练的BERT和其他没有预训练的Baseline放在一起做了个比较:
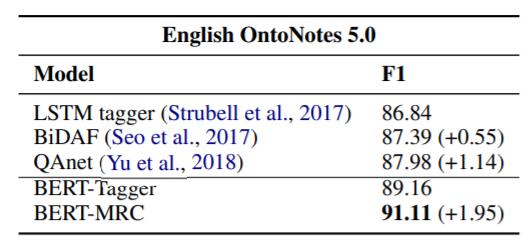
BiDAF和QAnet都是基于MRC方法的模型, 没有经过预训练, 但仍然比LSTM要强, 这证明了本框架的有效性. 再将预训练的BERT与没预训练的模型相比, BERT的性能要优于其他模型.
作者还做了一次Case Study, 将BERT的Attention Matrix展示了出来:
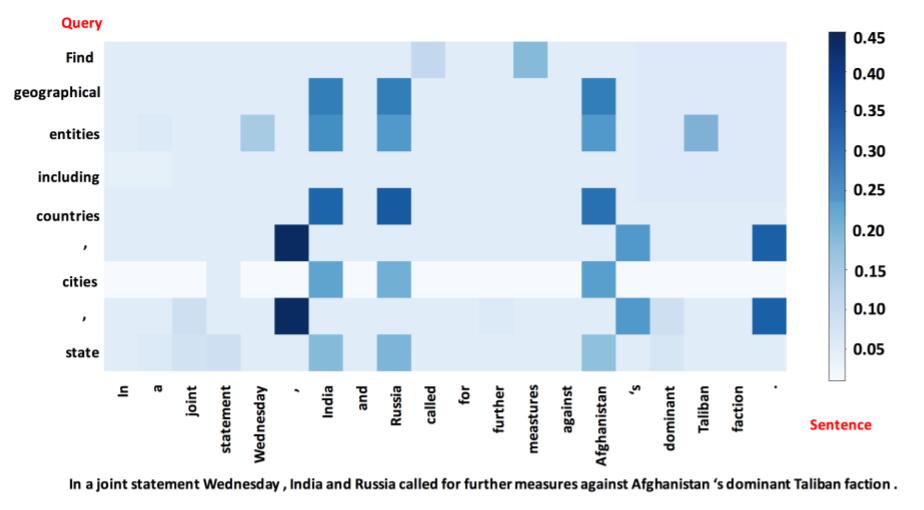
输入句子中的Flevland 与问题中的geographical, cites, state 相关性都比较大.
How to Construct Queries
问题构建的方式十分重要, 作者尝试了多种构建的问题的方法, 以Tag ORG 为例:
- Position index of labels: 问题直接由Tag的索引构成, 例如”one”, “two”, “three”.
- Keyword: 使用Tag描述中的关键词, 如”organization”.
- Rule - based template filling: 用模板生成问题, 例如”which organization is mentioned in the text”.
- Wikipedia: 使用维基百科中对Tag的定义, 例如”an organization is an entity comprising multiple people, such as an institution or an association”.
- Synonyms: 使用牛津词典中找到的Tag的同义词, 例如”association”.
- Keyword + Synonyms: 将关键词和同义词拼接起来.
- Annotation guideline notes: 本文的方法, 例如”find organizations including companies, agencies and institutions”.
上述方法在English OntoNotes 5.0 上的结果如下:
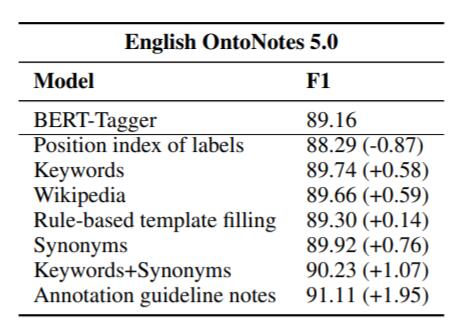
只使用索引相当于添加噪声, 反而有负影响. 其他方法都能带来一定程度的信息提示作用, 作者所使用的方法效果最佳.
Zero - shot Evaluation on Unseen Labels
为测试模型的Zero - shot能力, 作者在CoNLL 2003上训练, 在OntoNotes 5.0上做了测试, 结果如下:
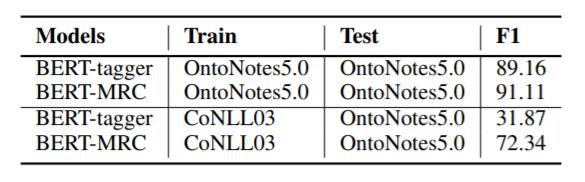
BERT - tagger在迁移后所剩的F1仅为31.87%, 与BERT - MRC相差甚远, 证明此框架有一定泛化能力.
Size of Training Data
为证明Query中注入先验知识的重要性, 作者在OntoNotes 4.0上做了使用不同数据对模型影响的实验:
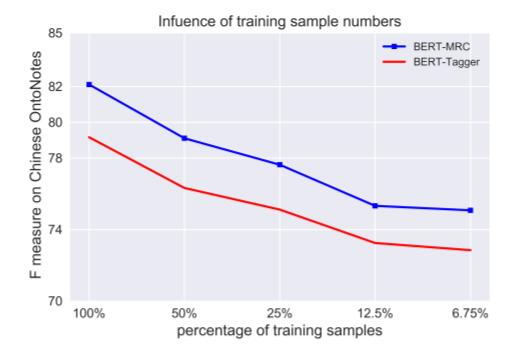
BERT - MRC在使用50%数据时已经能达到BERT - Tagger使用100%数据的性能.
Summary
作者从抽取式MRC的角度, 使用边界模型, 同时解决了Flat NER和Nested NER问题, 并在实验部分强调了Query注入先验知识对模型的影响.
但伴随这种Tagging框架的稀疏问题也不能忽视, 只能用一些小Trick去缓解, 但不能从根本上解决问题.
虽然本文是一篇面向NER的论文, 但实际上, 在RE与NER相结合的任务, 关系三元组抽取(Relational Triple Extraction, RTE)中, 有相当深远的影响.

