OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
本文是论文OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction 的阅读笔记和个人理解, 论文来自COLING 2022.
Basic Idea
作者认为, 在事件抽取任务中, 实际上包含下述三种类型的事件:
Flat Event:

最为一般的事件, 不涉及到重叠或嵌套问题.
Overlapped Event:
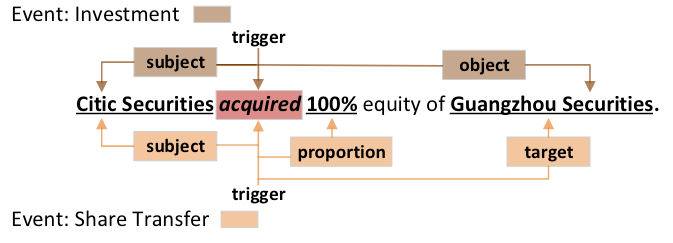
重叠事件被定义为拥有相同的触发词或至少拥有一个扮演不同事件角色的相同事件论元的事件集.
例如,
acquired同为Investment和Share Transfer这两种不同类型的事件的触发词,Guangzhou Securities在上述两个事件中扮演不同的事件角色.可能上述表述不够直观, 在CasEE论文中, 将重叠事件区分为三种详细情况:
- 触发词重叠: 两个不同类型的事件同时共享一个触发词.
- 多事件论元重叠: 某个论元在多个事件中扮演不同的角色.
- 单事件论元重叠: 某个论元在同一个事件中扮演不同的角色.
准确的来说, 只要满足上述三种类型其中之一的都可以算作是重叠事件, 满足两条或者三者都满足的也可以是重叠事件.
按照现有的EE论文来看, 相同的论元在不同事件中扮演相同的事件角色是不算重叠的, 至于为什么还不是很清楚.
Nested Event:
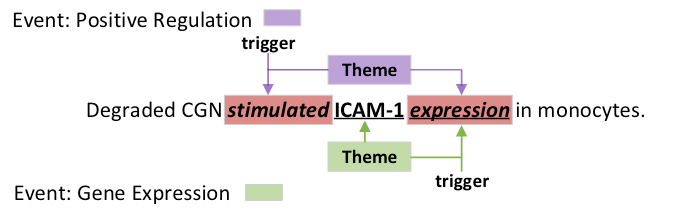
嵌套事件被定义为某一事件的论元是另一事件的触发词的两个事件.
例如, 在事件Positive Regulation中, 其Theme角色的论元expression是另一事件Gene Expression的触发词.
上述描述来自我自己总结, 可能有些不严谨, 作者在原论文中仅仅是给出了三个例子, 并未对这三种类型的事件下严格定义.
在前人的工作中, 常常仅处理Flat Event而忽略了Overlapped和Nested两种类型的事件. 即使有处理后两种事件的模型也常基于Pipeline而存在误差的错误传播问题. 作者希望将上述三种类型的事件纳入到一个简单而有效的框架下标注, 更具体的是建模为单词间的关系分类问题.
熟悉NER的小伙伴可能会想到AAAI 2022的一篇文章, 它们确实有相当大的关联.
OneEE
Problem Formulation
对于给定的由$N$ 个Token或单词组成的句子$X=\set{x_{1,}x_{2,}\dots, x_{n}}$ 和预定义好的事件类型$e \in \mathcal{E}$, 事件抽取的任务目标出Token对$(x_{i,}x_j)$ 之间的Span关系$\mathcal{S}$ 和论元关系$\mathcal{R}$.
上述事件类型$\mathcal{E}$, Span关系类型$\mathcal{S}$, 论元关系类型$\mathcal{R}$ 的含义如下:
- $\mathcal{S}$: Span关系代表起始Token$x_i$ 和结束Token$x_j$ 之间存在的Span关系,
S-T,S-A分别代表触发词的Span和事件论元的Span. - $\mathcal{R}$: 角色关系意味着触发词$x_i$ 所对应的论元$x_j$ 在事件中扮演的事件角色.
- $\text{NONE}$: 该Word Pair之间不存在任何关系.
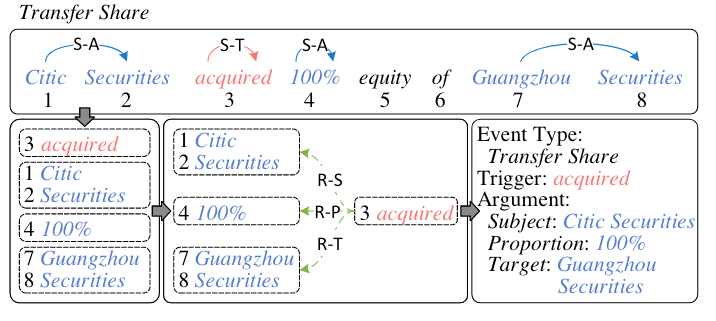
结合下述两个例子可以比较好的理解这种标注方式:
Event: Investment

在事件类型
Investment中, 论元Citic Securities中Citic和Securities之间的Span关系为S-A, 即论元的Span. 同理, 论元Guangzhou Securities中Guangzhou和Securities的Span关系也是S-A. 而该类型对应的触发词acquired的Span关系为S-T, 代表触发词的Span.在该类型事件中, 触发词
acquired和论元Citic Securities中每个Token的角色关系为R-S, 代表Citic Securities是该事件中的Subject,acquired和Guangzhou Securities中的每个Token的角色关系为R-O, 代表Guangzhou Securities是该事件中的Object.Event: Transfer Share

还是同样的例子, 在事件类型
Transfer Share中,Citic Securities和Guangzhou Securities的Span关系被以同样方式标出. 在角色关系中, 论元Guangzhou Securities的每个Token和触发词acquired之间的关系为R-T, 代表Guangzhou Securities是该事件中的Target. 在该例子中,100%也是该事件的论元, 扮演该事件中的Proportion.
Overview
模型概览图如下:
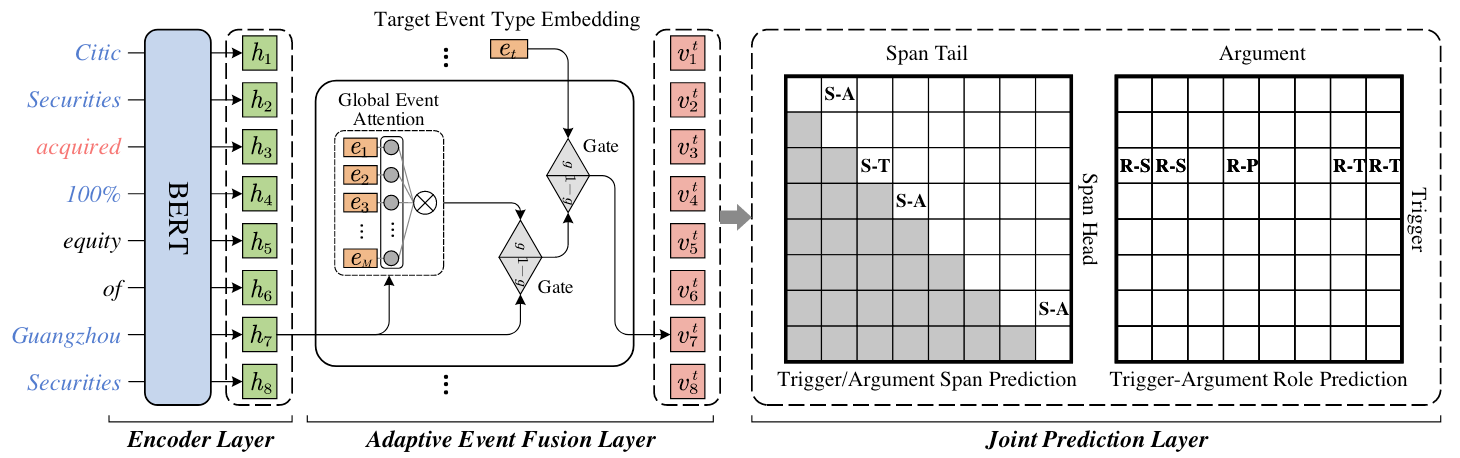
Encoder Layer
想必编码层不需多说, 直接用BERT获取特征:
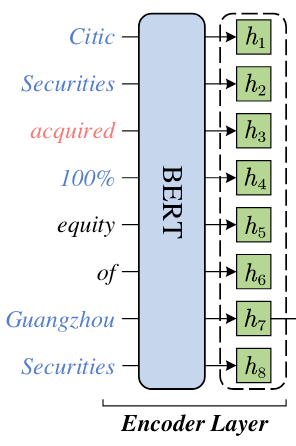
用BERT获得给定的句子$X=\set{x_{1,}x_{2,}\dots, x_{n}}$ 的特征, 然后用MaxPooling将Word的多个连续Token表示转为单词表示$\boldsymbol{H}=\set{\boldsymbol{h}_{1,}\boldsymbol{h}_{2,}\dots,\boldsymbol{h}_{N}} \in \mathbb{R}^{N\times d_h}$.
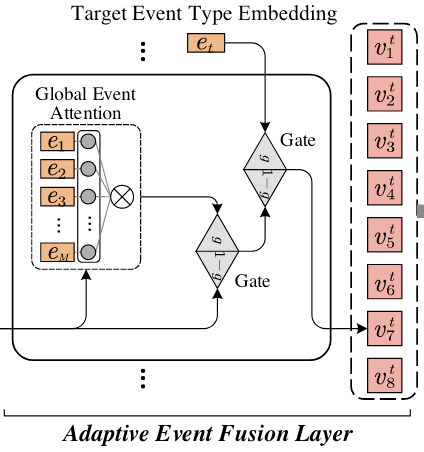
Adaptive Event Fusion Layer
由于作者设计的框架目标是为了预测出目标事件$e_t$ 所限定下的Word Pair之间的关系, 所以生成Event - Aware的表格表示是非常重要的. 因此, 作者设计了一个事件信息感知的自适应融合层, 将信息整合到词表示中.
该层引入门控和注意力机制, 将全局事件信息和, 如下图所示:
Attention Mechanism
作者将注意力机制用于抽取, 首先介绍了一下注意力机制:
$$
\operatorname{Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\top}}{\sqrt{d_h}}\right) \boldsymbol{V}
$$
其中$\sqrt{d_h}$ 为缩放因子, $\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}$ 为Query, Key, Value向量.
Gate Fusion Mechanism
门控机制可以滤去信息流中夹杂着的噪声, 作者使用门控实现两个信息流的动态融合:
$$
\begin{aligned}
\operatorname{Gate}(\boldsymbol{p}, \boldsymbol{q}) &=\boldsymbol{g} \odot \boldsymbol{p}+(1-\boldsymbol{g}) \odot \boldsymbol{q} \\
\boldsymbol{g} &=\sigma\left(\boldsymbol{W}_g[\boldsymbol{p} ; \boldsymbol{q}]+\boldsymbol{b}_g\right)
\end{aligned}
$$
其中$\boldsymbol{p}, \boldsymbol{q}$ 为输入向量, $\boldsymbol{g}$ 为一个全连接层和Sigmoid得到的信息通过概率, $\sigma(\cdot)$ 为Sigmoid激活函数, $\odot, [;]$ 分别为逐元素点乘和拼接操作.$\boldsymbol{W}_{g,}\boldsymbol{b}_g$ 为可训练参数.
接着, 作者需要获取每个词所需要的全局事件表示.
对于给定的$M$ 个随机初始化事件类型Embedding$\boldsymbol{E}=\set{\boldsymbol{e}_{1,}\boldsymbol{e}_{2,}\dots, \boldsymbol{e}_{M}}\in \mathbb{R}^{M\times d_h}$, 以原来词表示$\boldsymbol{H}$ 为Query, 以事件类型Embedding $\boldsymbol{E}$ 当做Key和Value做软查询:
$$
\boldsymbol{E}^g=\operatorname{Attention}\left(\boldsymbol{W}_q \boldsymbol{H}, \boldsymbol{W}_k \boldsymbol{E}, \boldsymbol{W}_v \boldsymbol{E}\right)
$$
其中$\boldsymbol{W}_{q,}\boldsymbol{W}_{k,}\boldsymbol{W}_v$ 均为可训练参数. 这样对于每个词都可以获得与之对应的全局事件表示.
从操作上来看, 该操作将原表示拆分成若干种事件Embedding的组合.
为了将全局事件信息整合到词表示中, 还需要进一步的将原表示通过门控机制滤去不需要的信息, 判断事件感知信息和原表示语义的流通量, 最后进一步和目标事件$\boldsymbol{e}_t$ 相结合:
$$
\begin{aligned}
\boldsymbol{H}^g &=\operatorname{Gate}\left(\boldsymbol{H}, \boldsymbol{E}^g\right) \\
\boldsymbol{V}^t &=\operatorname{Gate}\left(\boldsymbol{H}^g, \boldsymbol{e}_t\right)
\end{aligned}
$$
其中$\boldsymbol{e} \in \boldsymbol{E}$ 是目标事件类型的Embedding, $\boldsymbol{V}^t=\set{\boldsymbol{v}_{1},\boldsymbol{v}_{2},\dots,\boldsymbol{v}_N}$ 为最终获得的事件感知的词表示.
如果设计门控机制的时候, 不附带句子本身的语义信息$\boldsymbol{H}$, 单纯使用$\boldsymbol{E}^g$ 作为表格特征, 则会严重限制模型的表达能力.
Joint Prediction Layer
在Adaptive Event Fusion Layer中, 获取了事件感知的词表示$\boldsymbol{V}^t$, 现将其用于Word Pair$(w_{i}, w_j)$ 的二维表构建, 再按照我们已经讲过的标注方式在二维表上完成Span关系和角色关系的标注:
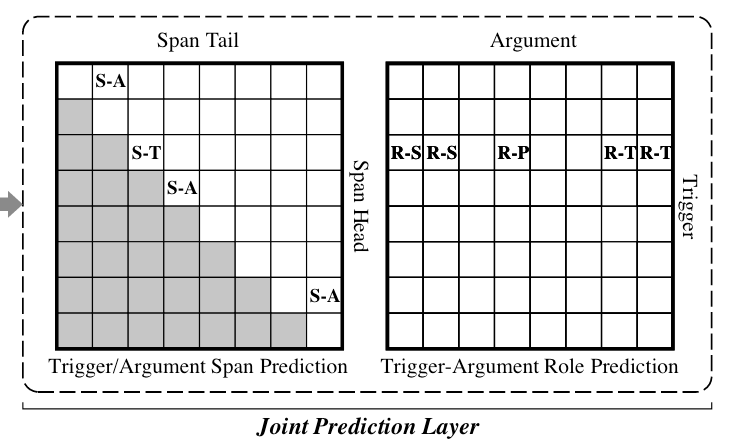
Distance - Aware Score
为了将相对位置信息和词对表示整合到一起, 作者在这里采用相对位置感知的打分函数. 沿着苏神Roformer的乘性位置编码思路, 作者将相对位置信息加入到打分过程中:
$$
\begin{aligned}
\operatorname{Score}\left(\boldsymbol{p}_i, \boldsymbol{p}_j\right) &=\left(\boldsymbol{R}_i \boldsymbol{p}_i\right)^{\top}\left(\boldsymbol{R}_j \boldsymbol{p}_j\right) \\
&=\boldsymbol{p}_i^{\top} \boldsymbol{R}_{j-i} \boldsymbol{p}_j
\end{aligned}
$$
其中$\boldsymbol{R}_{i,}\boldsymbol{R}_{j}$ 为$\boldsymbol{p}_{i,}\boldsymbol{p}_j$ 的相对位置Embedding, 并且$\boldsymbol{R}_{j-i}=\boldsymbol{R}_{i}^{\top}\boldsymbol{R}_j$.
因此, 可以得到目标事件类型为$t$ 的Word Paird$(x_{i,}x_j)$ 之间的Span得分$c_{ij}^s$ 和角色得分$c_{ij}^r$:
$$
\begin{aligned}
&c_{i j}^s=\operatorname{Score}\left(\boldsymbol{W}_{s 1} \boldsymbol{v}_i^t, \boldsymbol{W}_{s 2} \boldsymbol{v}_j^t\right), \\
&c_{i j}^r=\operatorname{Score}\left(\boldsymbol{W}_{r 1} \boldsymbol{v}_i^t, \boldsymbol{W}_{r 2} \boldsymbol{v}_j^t\right),
\end{aligned}
$$
其中$\boldsymbol{W}_{s 1}, \boldsymbol{W}_{s 2}, \boldsymbol{W}_{r 1}, \boldsymbol{W}_{r 2}$ 为可训练参数, $\boldsymbol{v}_{i}^{t}, \boldsymbol{v}_j^t$ 是由Adaptive Event Fusion Layer中得到的$\boldsymbol{V}^t$ 的分量.
Training Details
由于OneEE采用的是二分类多标签的标注方式, 所以会存在类别不平衡的问题, 必须对该问题进行处理. 常规的方法是用Focal Loss处理.
作者没有使用Focal Loss, 而是使用了一种改进版的二分类多标签Loss, 该Loss理论上能够在不经过Focal Loss或者精调阈值的情况下取得不错的效果:
$$
\mathcal{L}^{\star}=\log \left(e^\delta+\sum_{(i, j) \in \Omega^{\star}} e^{-c_{i j}^{\star}}\right)+\log \left(e^\delta+\sum_{(i, j) \notin \Omega^{\star}} e^{c_{i j}^{\star}}\right)
$$
其中, $\Omega^\star$ 为Word Pair之间的关系$\star$, $\delta$ 设置为0.
虽然作者在原论文中引用的是Circle Loss, 但作者在这里实际上是直接采用苏神设计的改进版的二分类多标签损失, 因为苏神发表博客的时候是2020年.
关于这个Loss, 我觉得这里直接放苏神文章的链接比较合适, 推荐大家直接阅读苏神的原文:
- Circle Loss: [2002.10857] Circle Loss: A Unified Perspective of Pair Similarity Optimization
- 将“softmax+交叉熵”推广到多标签分类问题 - 科学空间|Scientific Spaces
- 多标签“Softmax+交叉熵”的软标签版本 - 科学空间|Scientific Spaces
- 不成功的尝试:将多标签交叉熵推广到“n个m分类”上去 - 科学空间|Scientific Spaces
后续两篇文章是苏神就多标签问题进一步做的其他尝试, 有余力可以阅读一下.
最后将标注Span关系表和角色关系表的损失相加:
$$
\mathcal{L}=\sum_{t \in \mathcal{E}^{\prime}}\left(\sum_{s \in \mathcal{S}} \mathcal{L}^s+\sum_{r \in \mathcal{R}} \mathcal{L}^r\right)
$$
其中$\mathcal{S}^\prime$ 为从$\mathcal{S}$ 中采样的采样策略.
采样策略在论文的附录中.
作者认为, 在训练阶段引入所有的事件类型Embedding进来会导致较高的计算资源消耗, 所以作者常使用一个采样出来的事件类型子集$\mathcal{E}^{\prime}$ 代替原来的事件类型集$\mathcal{E}$, $\mathcal{E}^\prime$ 由一个正事件类型和$K-1$ 个负事件类型组成.
Inference
在推理时, 作者采用的解码策略如下:
作者将其总结为四个步骤:
- 找到触发词和论元的起始位置和结束位置.
- 将对应的起始位置和结束位置整合成触发词或论元的Span.
- 根据关系$\text{R}-\star$ 匹配论元和触发词的事件角色.
- 将事件类型赋予该事件.
作者在附录中还特别给出了一个Nested EE例子:
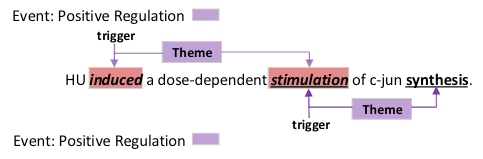
在该例子中, stimulation 作为了同一个类型的事件Positive Regulation 的论元和触发词, 按照本文开头给出的定义, 它是一种嵌套事件.
该事件解码示意图如下:
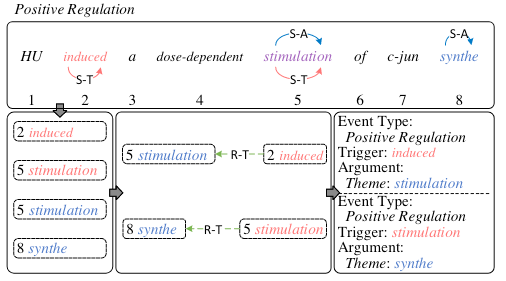
首先用Span关系抽取出整个句子中所包含的所有触发词induced, stimulation, 和论元stimulation, synthe. 由于作者所采用的标注策略是一种多标签分类策略, 所以stimulation 的S-A, S-T 两种Span关系能够同时被抽取出来.
接着按照角色关系找出两个触发词所对应的论元的角色, 最后就可以解码出两个同类型的嵌套事件.
Experiments
详细的参数设置请参照原论文.
Datasets
据作者统计, FewFC中将近22%的句子都有Overlapped Event, 而Genia11, Genia13有将近18%的句子有Nested Event, 具体细节如下所示:
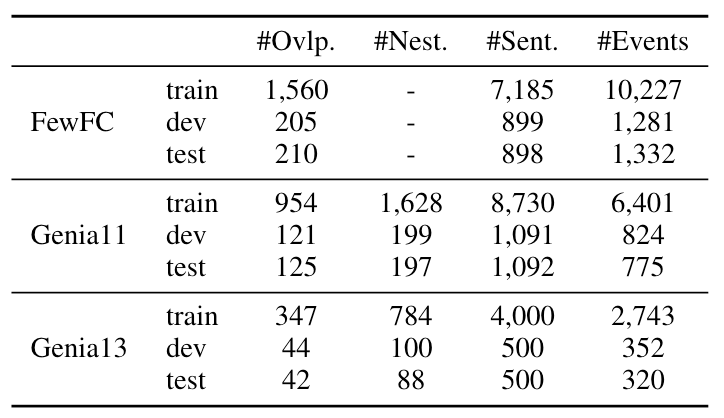
Evaluation Metrics
目前的事件抽取任务还比较困难, 因此还是采用的不同子任务的抽取评估指标, 主要是下述四个子任务:
- Trigger Identification(TI): 触发词Span抽取正确.
- Trigger Classification(TC): 触发词抽取正确, 且触发词所对应的事件分类正确.
- Argument Indentification(AI): 论元Span抽取正确且对应的事件类型正确.
- Argument Classification(AC): 论元抽取正确且其对应的事件角色分类正确.
实验将对它们的P, R, F1进行比较.
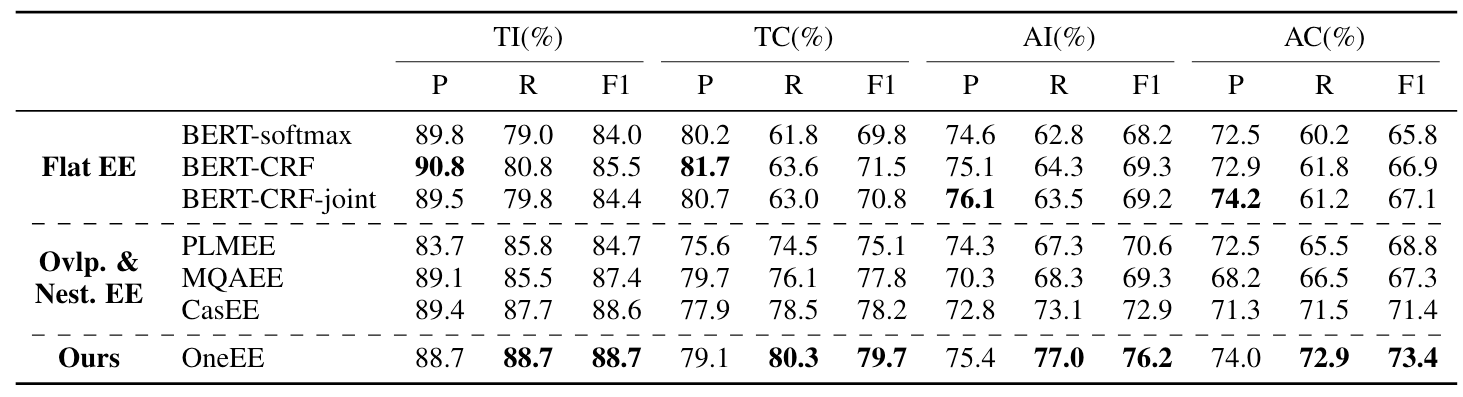
All EE
在FewFC这种重叠事件抽取数据集上结果如下:
在嵌套事件抽取数据集Genia11和Genia13表现如下:
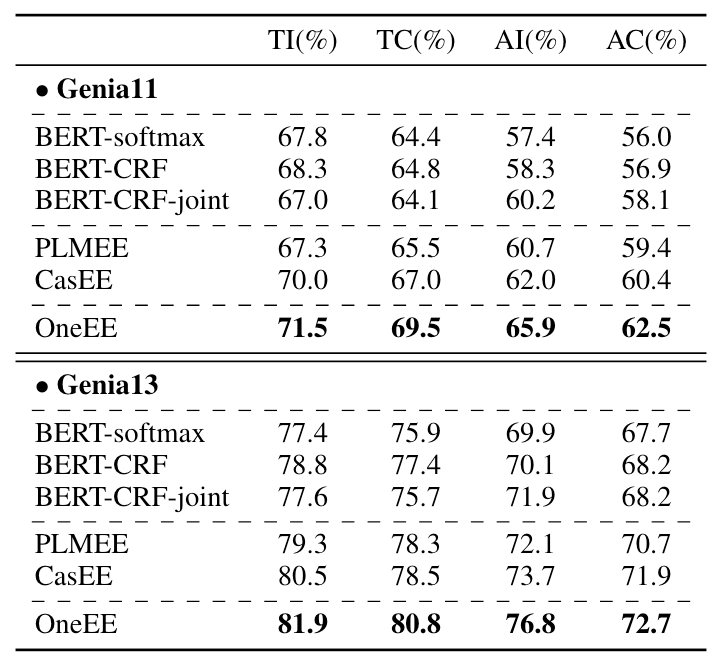
无论是什么数据集, OneEE在EE的各个子任务上相较于之前的模型都具有显著优势.
Overlapped and Nested EE
为验证OneEE对重叠和嵌套事件的处理能力, 作者统计了FewFC中至少含有1个Overlapped Event的句子和Genia11中至少含有1个Nested Event的句子的实验结果, 如下所示:
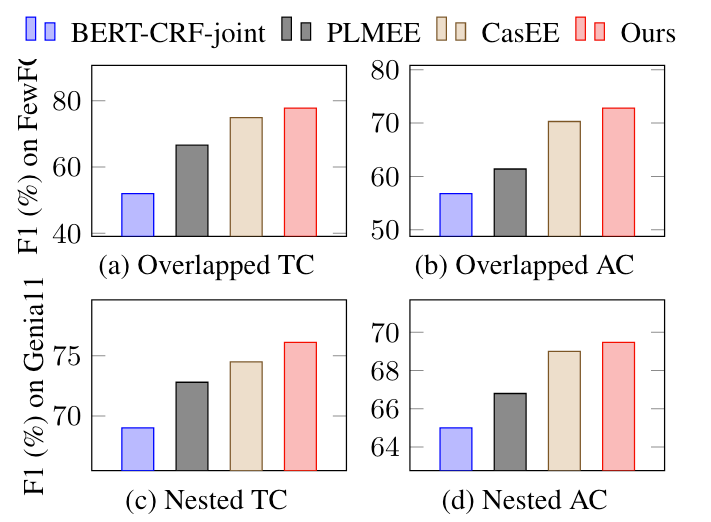
(a), (b)图分别代表FewFC中的触发词重叠, 论元重叠. (c), (d)分别代表Genia11中的触发词嵌套和论元嵌套.
从结果上来看, OneEE对这几种重叠和嵌套都有比CasEE更好的处理性能.
Ablation Study
Effects of the Modules in the Fusion Layer
在FewFC上进行的消融实验效果如下:
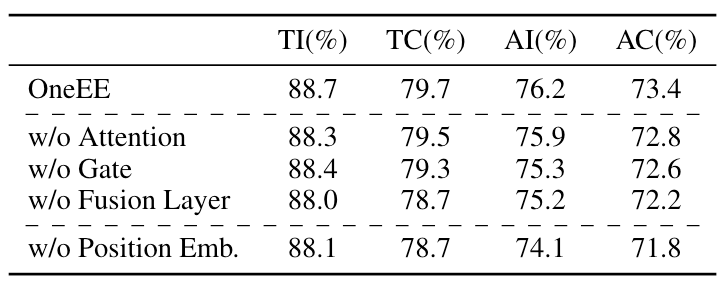
从中可以看出, 影响比较大的是去掉位置Embedding, 由此可以看出位置信息的重要性. 其次比较重要的是去掉Fusion Layer, 说明事件的信息其实也比较有用.
w/o Gate代表作者去掉门控机制, 而更改为将两个向量加在一起, 从结果来看影响并不是很大, 感觉有可能模型能够自己学出来一个过滤掉无用信息的机制?
Effect of the Distance - aware Tag Prediction
为了进一步探究位置信息对OneEE的影响, 作者按照距离将FewFC的测试集分为六组, 相对位置对OneEE的影响到底有多大:
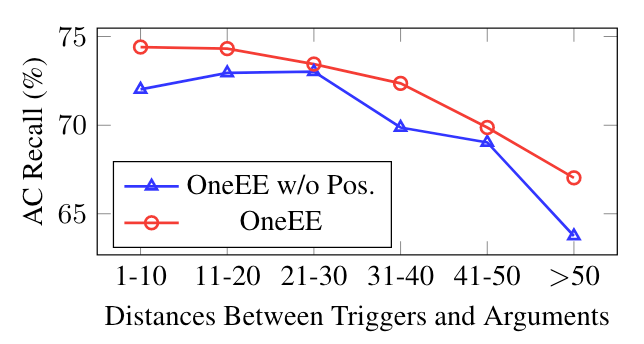
随着触发词和论元之间的相对距离增大, 带位置编码的OneEE比去掉位置编码的OneEE标注AC Recall要高. 同时, 随着距离增大到50以上的时候, 二者均有显著衰减.
Parameter Number & Efficiency Comparisons
作者对比了不同模型的抽取阶段数, 参数数量, 推理速度, 如下所示:
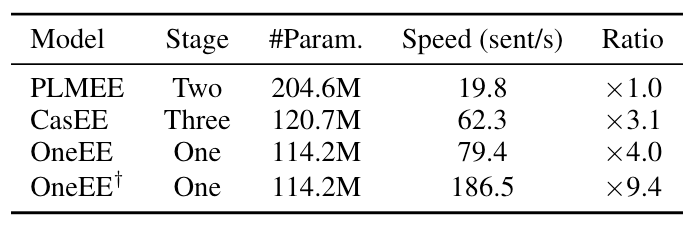
直观上来讲, OneEE的参数数量其实就比BERT多了一点点, 同时速度也比CasEE稍快一些.
Analysis
Analysis of 4 Role Label Strategies
作者探索了四种不同的角色关系标注策略, 如下所示:
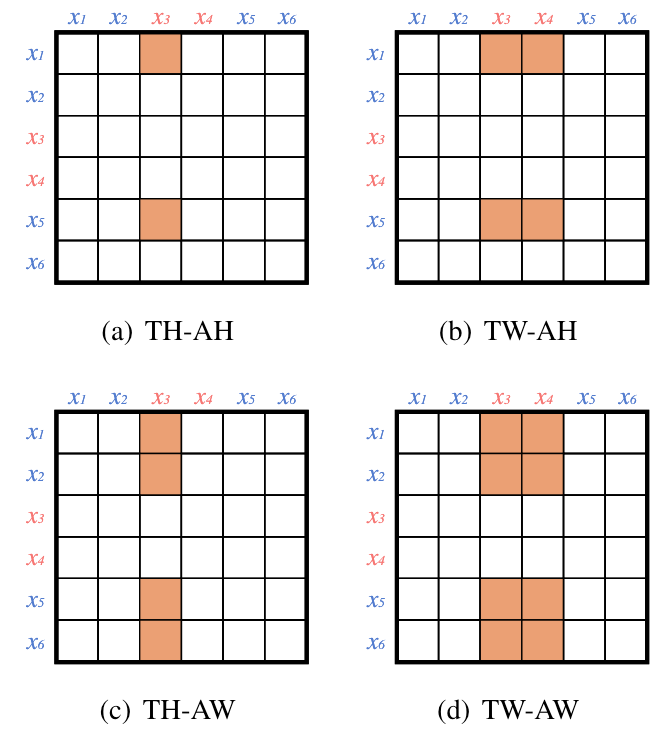
它们分别为:
- TH-AH(Trigger Head-Argument Head): 标注触发词起始位置和论元的起始位置.
- TW-AH(Trigger Word-Argument Head): 标注触发词的所有单词和论元的起始位置.
- TH-AW(Trigger Head-Argument Word): 标注触发词的起始位置和对应的论元的所有单词.
- TW-AW(Trigger Word-Argument Word): 标注触发词的所有单词和论元的所有单词.
上述四种不同的标注策略在FewFC和Genia11上的对比结果如下:
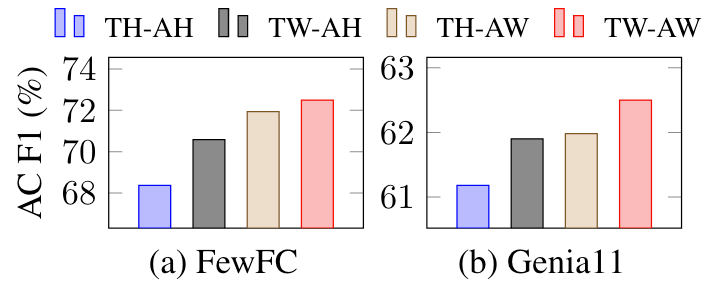
TW-AW 相较于其他标注策略要好很多, 作者猜测原因是因为它比其他策略更稠密.
让我比较意外的是在重叠场景下
TW-AH和TH-AW有很大差距.
Analysis of Event Number
对于句子中所包含的不同数量的事件, 对比结果如下:
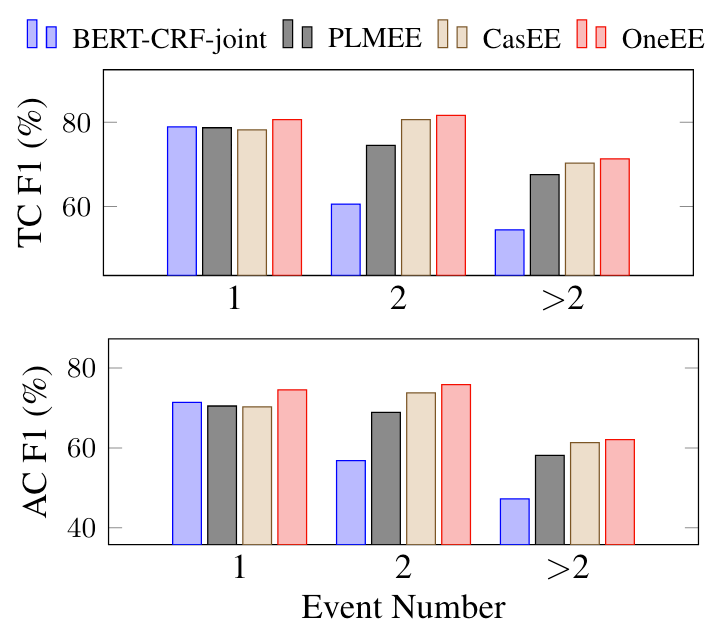
随着句子中事件数量的增多, OneEE的综合表现与CasEE逐渐持平, 但对于事件数量为1或2的句子, 对论元的抽取和角色分类效果是比CasEE有肉眼可见的优势的.
Summary
OneEE采用了一套基于表填充式的单阶段标注策略, 将事件抽取下的Flat Event, Overlapped Event, Nested Event统一为词对关系判断问题, 整合到同一个框架下处理, 同时还注意将事件类型作为感知, 融入到表填充过程中, 达到了目前事件抽取领域下的最好结果.
论文中的实验对该方法的探究是比较完备的, 从多个方面对该问题进行了较为精准的剖析.
事实上, OneEE与AAAI 2022的另一篇论文W2NER上的作者署名重复度很高, 它们所采用的方法也是类似的, 都是将信息抽取问题转化为词对之间的关系判断问题, 将嵌套, 重叠类似的难题放到统一框架下处理.
