本文前置知识:
- BERT(详见ELMo, GPT, BERT)
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
本文是论文KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation 的阅读笔记和个人理解.
顺带吐槽一下这论文第一版和第二版差的也太大了…
Basic Idea
作者指出, PLM不能直接从文本中获取常识. 相反, KGE经常能获得知识图谱中实体和关系的有效表示, 却不能捕捉上下文. 基于这个简单的观察, 作者希望将常识注入PLM, 这样PLM不但能学到常识, 还能学到有效而丰富的信息表示.
并且在已经注入知识的PLM中, 作者还观察到以下问题:
- 实体嵌入和语言分离, 不方便表示空间的对齐. KGE模型很少将KG结构作为输入, 并很少结合文本信息, 因此无法帮助PLM.
- 需要实体链接器, 在传播时容易出现错误.
- 与普通PLM相比, 查找实体的表示会带来额外的开销.
而文本描述有与实体相关的丰富信息, 能够帮助文本语义空间与KG的符号空间对齐:
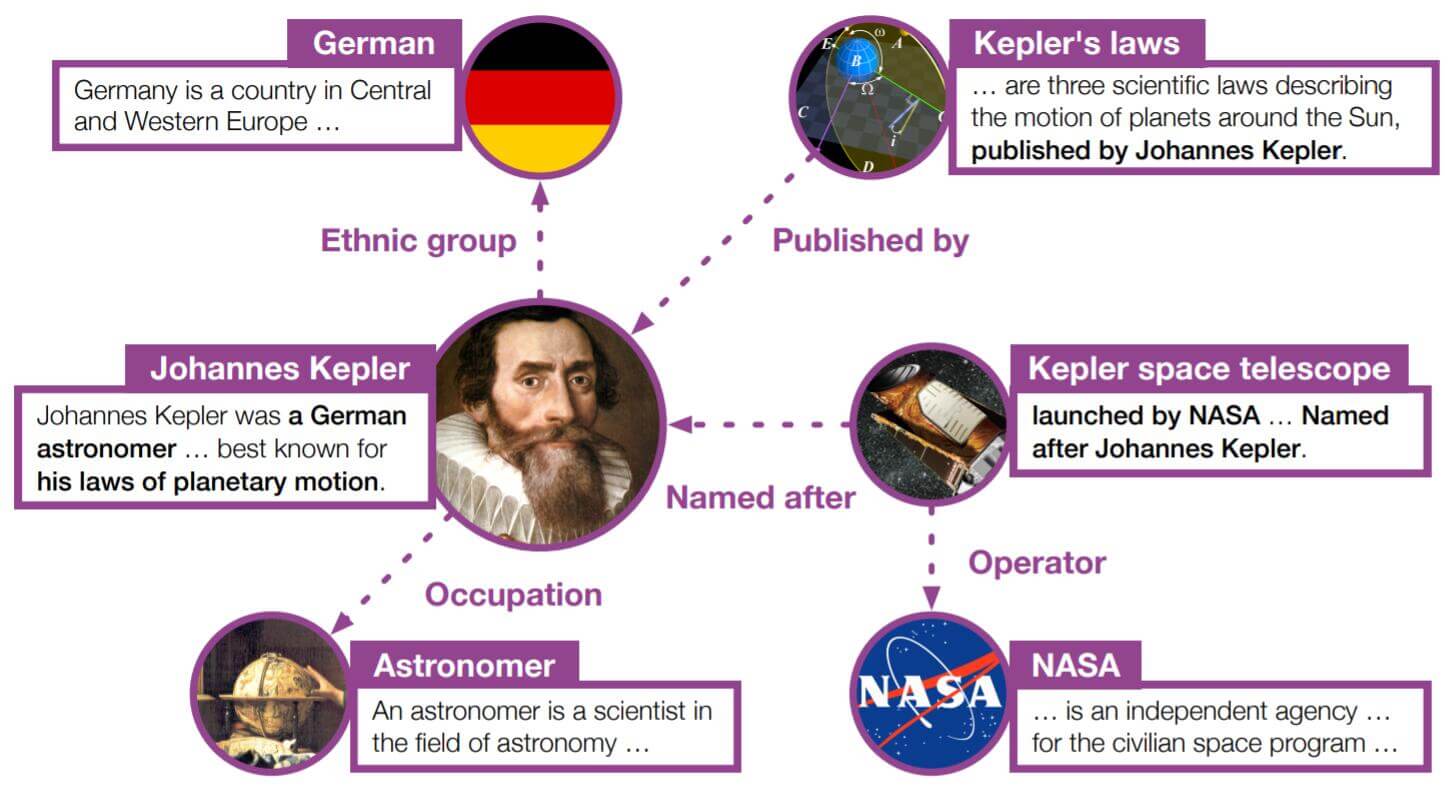
作者将实体结合其描述用PLM编码, 对KRL和PLM的目标进行联合优化.
KEPLER
KEPLER(Knowledge Embedding and Pre - trained LanguagE Representation)是一个KGE和PLM表示统一的模型. 所以它包含了PLM和KE的联合优化目标.
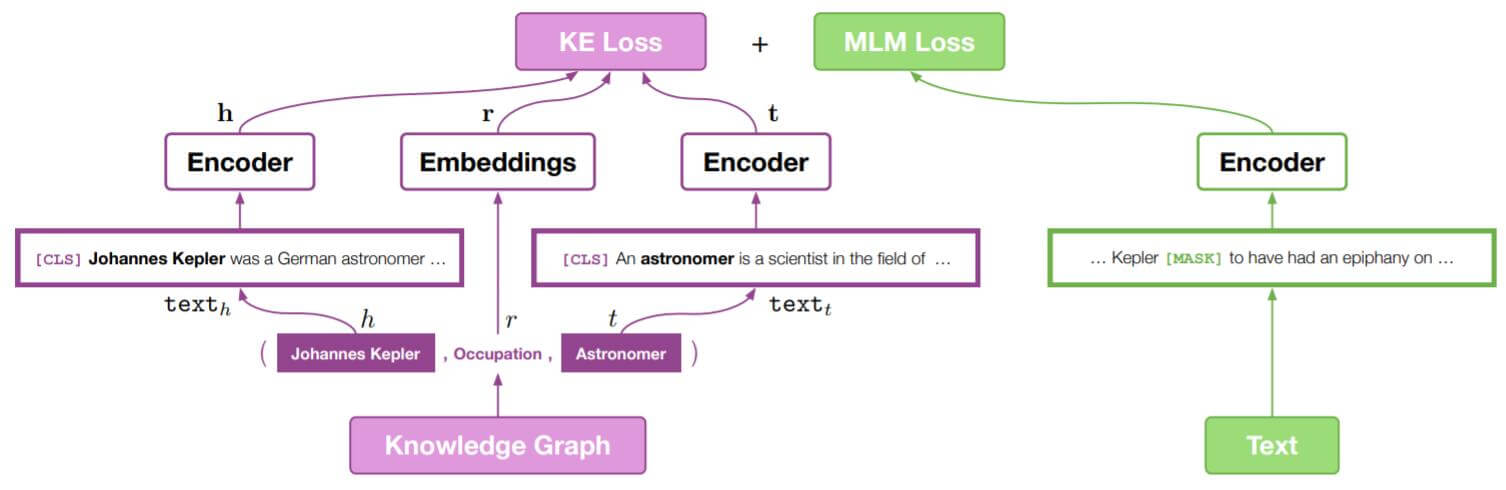
Encoder
作者使用了Transformer Encoder(其实就是BERT)作为文本编码器. 即Transformer Encoder将$N$ 个Token的序列$(x_1,\dots, x_N)$作为输入, 然后经过$L$ 层Transformer Encoder的堆叠计算, 得到$d$ 维的上下文表示$\mathbf{H}_i, 1\leq i \leq L$. 每层编码器$\mathrm{E}_i$由多头自注意力和前馈神经网络组成, 每层的Encoder表示记为:
$$
\mathbf{H}_i=\mathrm{E}_i(\mathbf{H}_{i-1})
$$
对于任意文本$\text{text}$, 作者希望将经过编码后的$\mathrm{[CLS]}$ 处的输出$\mathrm{E}_{[\mathrm{CLS}]} $ 做为文本的表示.
在KEPLER中, 作者和RoBERTa一样使用了BPE, 与之前出现的Knowledge - Enhanced Model相比较, 这里没有使用额外的实体连接器或者知识集成层.
Knowledge Embedding
与其他KGE方法一样, KEPLER将实体和关系映射进一个$d$ 维的空间中, 并且使用打分函数训练.
但是KEPLER和普通的KGE方法又不一样, 它不再存储Embedding, 而是将实体结合它们本身的描述编码做为Embedding. 作者设计了两种结合实体描述的方法:
- 只用实体描述.
- 使用实体描述和关系描述.
Using Entity Descriptions
对于三元组$(h, r, t)$, 只使用三元组就是对头实体$h$ 的描述$\text{text}_h$和尾实体$t$ 的描述$\text{text}_t$ 分别进行编码, 然后再将关系$r$ 单独嵌入:
$$
\begin{aligned}
\mathbf{h} &=\mathrm{E}_{[\mathrm{CLS}]}\left(\operatorname{text}_{h}\right) \\
\mathbf{t} &=\mathrm{E}_{[\mathrm{CLS}]}\left(\operatorname{text}_{t}\right) \\
\mathbf{r} &=\mathbf{T}_{r}
\end{aligned}
$$
其中$\mathbf{T}_r$ 代表关系$r$ 的Embedding权重.
Using Entity and Relation Descriptions
与只使用实体描述不一样, 因为BERT是可以对两段文字联合编码的, 所以这种方法可以将头实体描述和关系放在一起使用:
$$
\mathbf{h}_{r}=\mathrm{E}_{[\mathrm{CLS}]}\left(\operatorname{text}_{h, r}\right)
$$
具体一点, $\mathrm{text}_{h,r}$ 代表头实体$h$ 和其三元组关系$r$的描述, 在二者之间像BERT输入两段信息一样加上特殊的分隔符$[\mathrm{SEP}]$ 做为区分. 尾实体仍然单独输入进BERT.
我认为该方法最少有两个问题:
- 头实体获得关系描述加成(也有可能是污染), 尾实体没有被考虑到.
- BERT捕捉上下文的能力被局限了, 仅能体现在描述的上下文当中, 并不能根据语境调整实体的表示.
Konwledge Embedding Loss and Score Function
KE部分的损失如下:
$$
\mathcal{L}_{\mathrm{KE}} =-\log \sigma\left(\gamma-d_{r}(\mathbf{h}, \mathbf{t})\right)
-\sum_{i=1}^{n} \frac{1}{n} \log \sigma\left(d_{r}\left(\mathbf{h}_{\mathbf{i}}^{\prime}, \mathbf{t}_{\mathbf{i}}^{\prime}\right)-\gamma\right)
$$
其中$(h_i^\prime, r, t_i^\prime)$是负采样得到的样本, $\sigma$ 是Sigmoid函数, $\gamma$ 是间隔, $d_r$ 是打分函数, KEPLER沿用TransE的打分函数:
$$
d_{r}(\mathbf{h}, \mathbf{t})=\lVert\mathbf{h}+\mathbf{r}-\mathbf{t}\rVert_{p}
$$
作者使用的是一阶范数, 即$p=1$.
Masked Language Modeling
在Masked Language Model上, KEPLER沿用了BERT和RoBERTa的MLM训练损失, 结构和Mask方式都没有发生任何变化. 在分类时仍然是在Encoder的最后一层输出$\mathbf{H}_{L,j}$ 后接上和字典等同大小的$W$ 路分类器.
因为RoBERTa的效果比较好, 所以直接用$\text{RoBERTa}_{\mathrm{BASE}}$ 的参数初始化.
Training Objectives
训练目标就是之前提到过的KGE部分和MLM部分之和:
$$
\mathcal{L}=\mathcal{L}_{\mathrm{KE}}+\mathcal{L}_{\mathrm{MLM}}
$$
这两部分目标是共享Encoder的, 在训练时可以采样不同类型的文本(倾向于优化KE或者MLM)作为训练数据.
Experiments
DataSet
作者需要使用不同数据优化KE和MLM.
KE Objective: Wikidata5M
因为作者需要大规模的KG, 并且必须包含对应的实体和关系描述, 最好还要支持Inductive Setting, 这样的数据集基本不存在, 所以作者自己根据Wikidata和Wikipedia构建了一个新的包含实体关系描述文本的大规模KG数据集Wikidata5M.
Wikidata5M比现在的常用数据集大得多, 并几乎涵盖了所有领域:
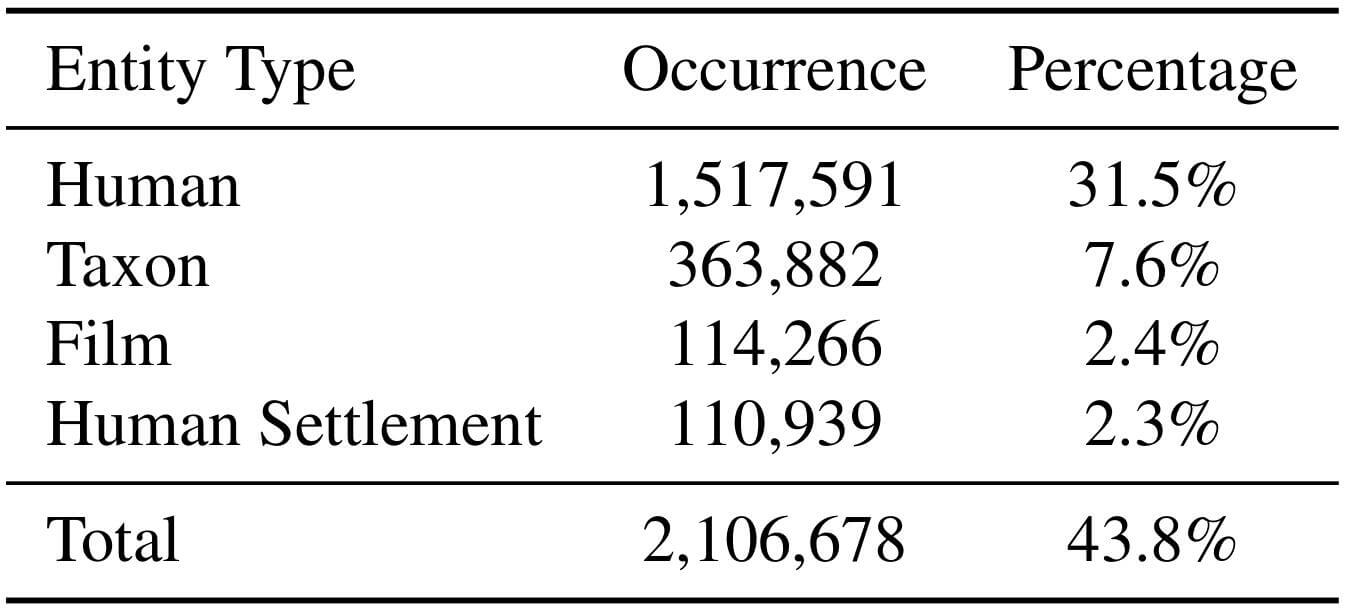
Wikidata5M中实体类型统计:
DataSplit
数据可以按照两种设置进行划分:
Transductive Setting: 在绝大多数KG数据集中使用, 对于训练集, 验证集, 测试集共享所有实体, 但并不知道完整三元组.
Inductive Setting: 训练集, 验证集, 测试集中, 实体和三元组都不共享. 这更考验模型的推断能力, 也更困难. 但它更符合现实世界的应用情况. 具体数据集划分情况如下:
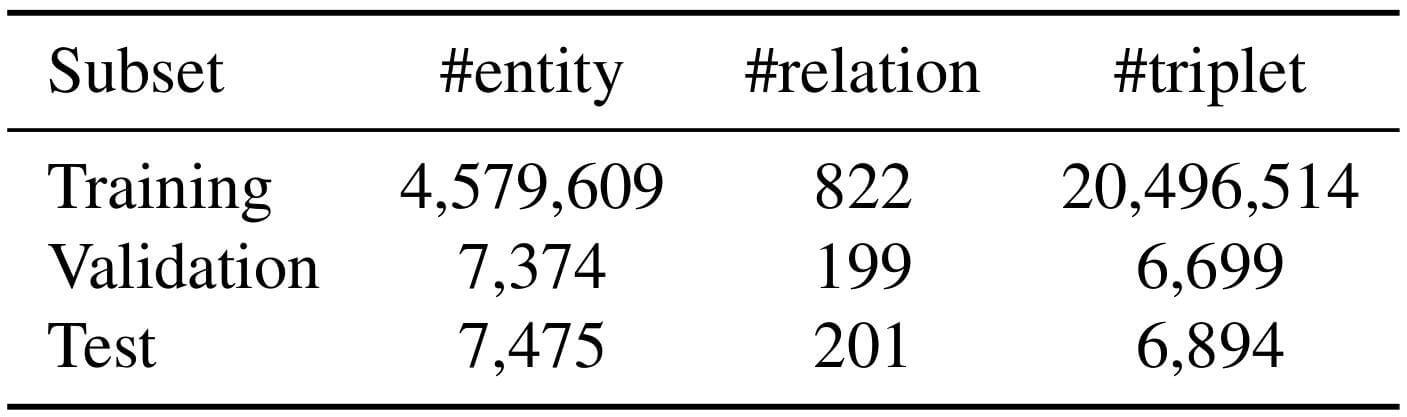
Benchmark
作者用之前常用的KGE模型测试了Wikidata5M的难度, 分别比较了它们在Wikidata5M上的MRR, MR, HITS@1, 3, 10.
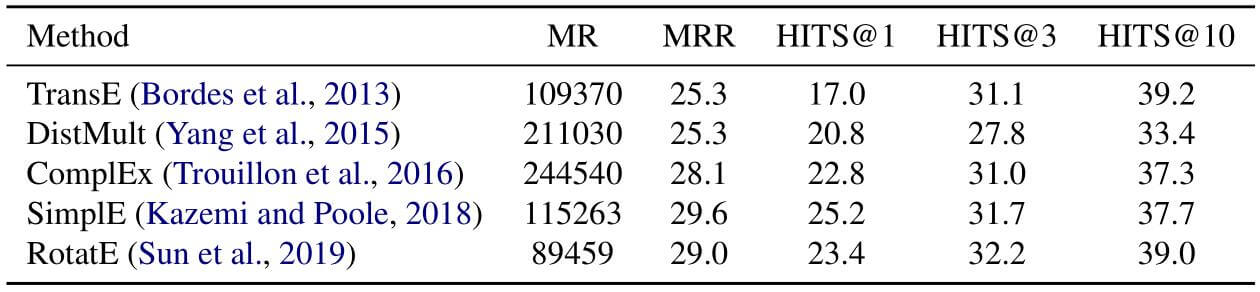
确实非常难, 很多流行的数据集都没取得太好的效果. 因为Wikidata包括了各种不同类型的实体和关系, 作者也建议大家使用大规模数据集以确保模型能够被充分测试.
MLM Objective
作者使用优化MLM的数据集有:
- BookCorpus.
- English WIkipedia.
Pre - Training Settings
关于参数设置我就不再提了, 详见原文. 主要叙述一下在后面实验经常比较的内容.
KE Settings
对于KE的优化, 作者设计了三种设置:
- KEPLER - Wiki: 用Wikidata5M训练KEPLER, 总使用描述的前512个Token. 当使用实体和关系一起作为输入时(Using Entity and Relation Descriptions), 模型被称为KEPLER - Wiki - rel.
- KEPLER - WordNet: 用WordNet训练KEPLER, 作者尝试将更多的语言知识融入进去, 或许会有益于NLP任务. WordNet中的关系数量相对来说非常少, 所以只采用实体描述.
- KEPLER - W + W: 联合训练Wikidata5M和WordNet. 损失函数相应的发生变化:
$$
\mathcal{L}=\mathcal{L}_{\mathrm{Wiki}}+ \mathcal{L}_{\mathrm{WordNet}}+\mathcal{L}_{\mathrm{MLM}}
$$
RoBERTa
KEPLER是基于RoBERTa的, RoBERTa采用了更大的语料库进行训练. 为公平起见, 作者训练了RoBERTa*, 也是用RoBERTa的权重进行初始化, 但用相同的语料库, 并只对它的MLM目标继续优化.
这样设计实验应该是为了凸显出加入KE Loss带来的变化.
NLP Tasks
在NLP任务中, 作者主要和其他Knowledge Enhanced Model在NLP任务上横向对比.
Relation Classification
TACRED
TACRED是人为标注用于关系分类的数据集. 在TACRED上表现如下:
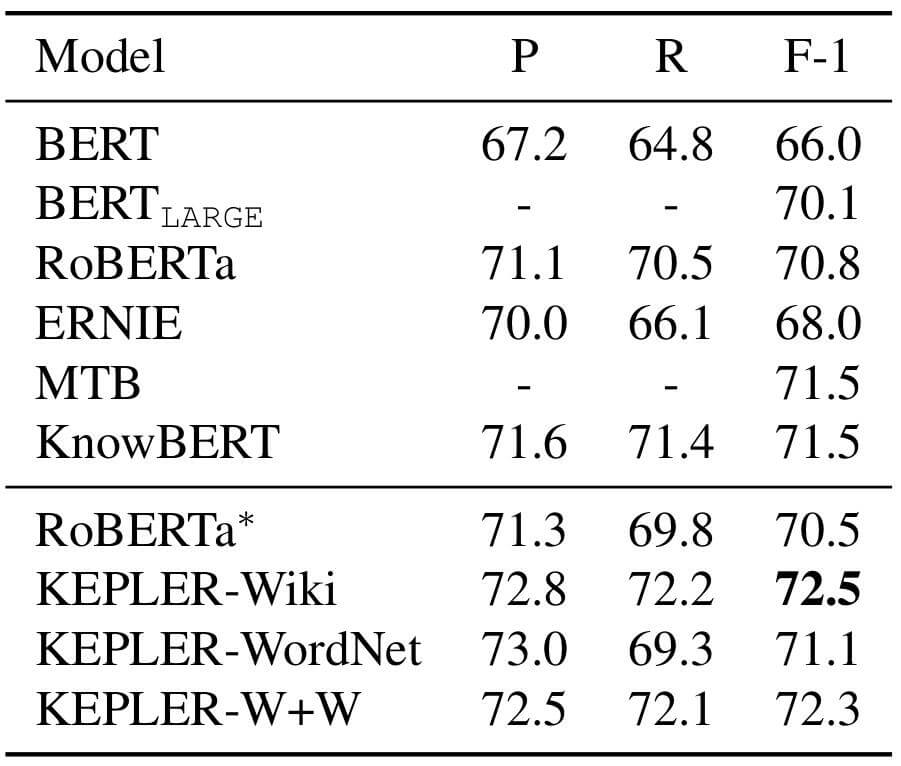
KEPLER - Wiki表现很棒, 与RoBERTa*相比有很大进步, 但KEPLER - WordNet表现只比RoBERTa*好一点点. KEPLER - W + W和KEPLER - Wiki表现相当, 作者认为是WordNet限制了性能.
FewRel
FewRel是用于体现Few - Shot能力的关系分类数据集, 其2.0版本添加了更多的领域. 在FewRel上表现如下:
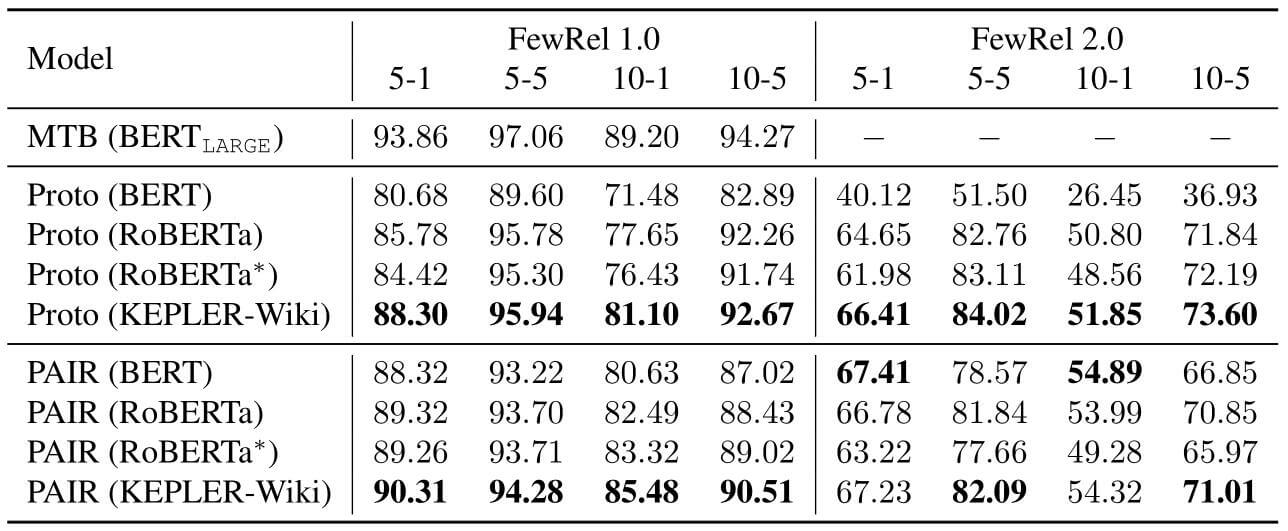
就作者给出的结果来看, KEPLER - Wiki表现很不错. 作者认为在FewRel1.0和2.0上的差异是因为2.0版本加入了医疗类的数据.
Entity Typing
KEPLER在OpenEntity上的表现如下:
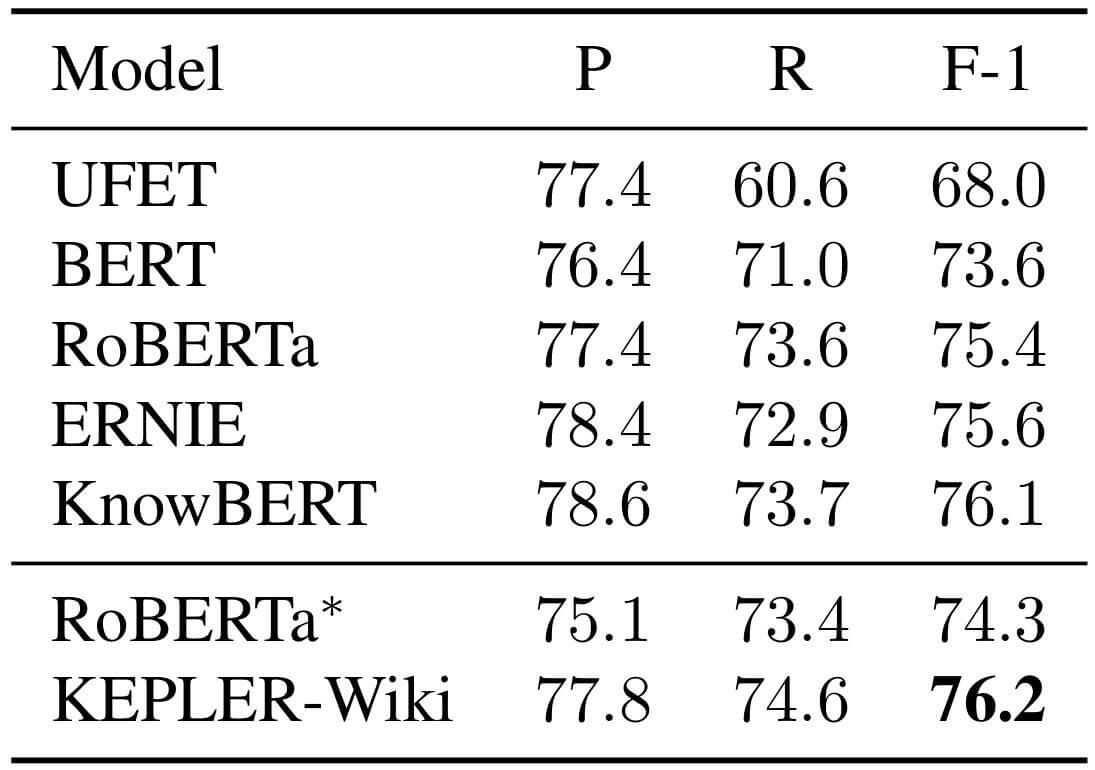
从F1 Score上来看, KEPLER表现不错.
GLUE
GLUE(General Language Understanding Evaluation)是用来评判语言理解能力的测试, 这种任务不需要知识, 但需要理解能力. 作者通过GLUE尝试证明KEPLER对NLU任务表现没有退化.
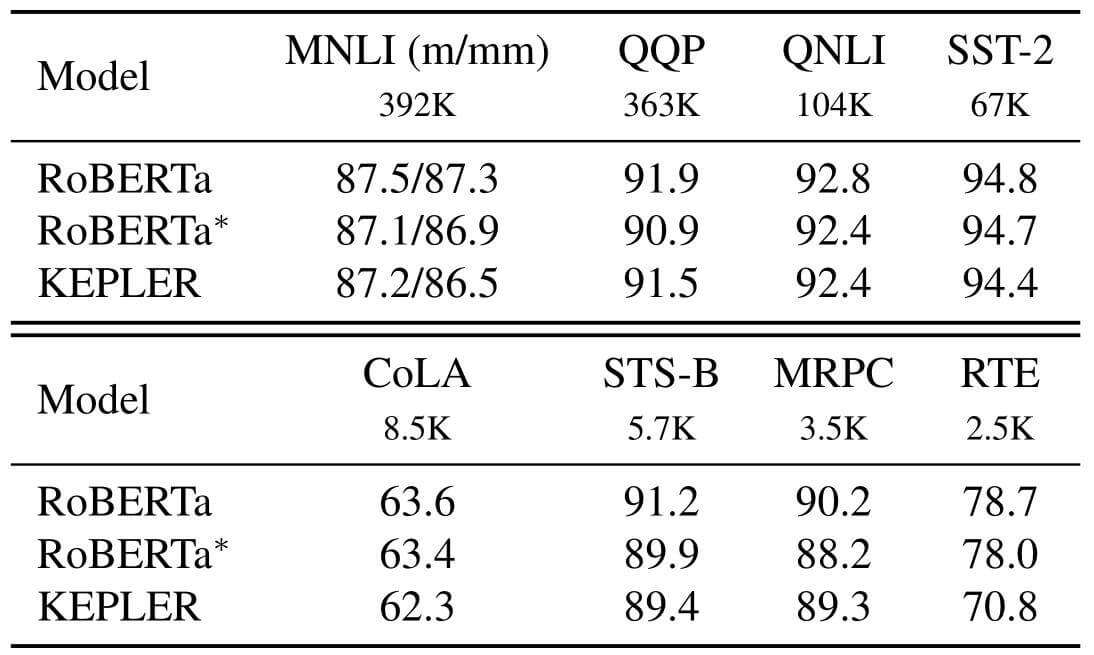
在比较大的数据集上KEPLER表现相对正常, 在比较小的数据集上例如RTE, KEPLER退化的比较严重. 一般来说 , KEPLER对NLU没有明显副作用.
即然RoBERTa*训练与KEPLER使用的是相同数据集, 那么按理说会因描述类的文本数据扩充而提升文本理解能力, 实际上却没有. 从这个角度来看, PTM和KE并不能给NLU任务带来增益, 甚至还会有减益. 应该还有更深层的原因.
KG Tasks
作者在KG的Task上不能使用常用数据集, 因为它们都没有高质量的实体描述, 并且不支持Inductive Setting.
Transductive Setting
在该设置中, 所有实体在所有阶段均是可见的, 但三元组不可见. 作者将其与TransE性能进行比较:

用TransE当Baseline是不是有点太不公平了?TransE没有使用任何额外辅助信息, 实体关系描述肯定算引入辅助信息了. 作者在文中列出三条理由, 但我不是很认同.
Inductive Setting
在该设置中, 所有实体和三元组在各阶段都不共享. 作者将也引入实体描述的DKRL(也是作者提出的模型)作为Baseline进行比较:
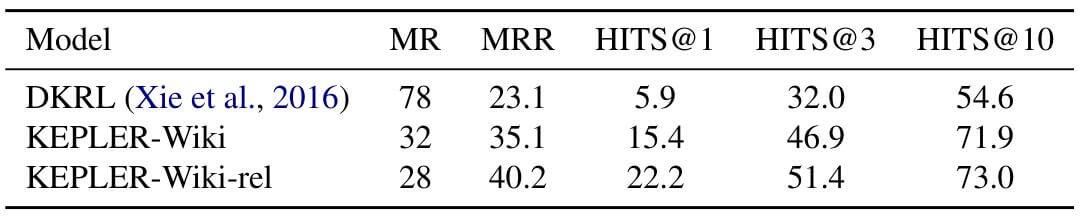
KEPLER - Wiki - rel比KEPLER - Wiki要强大许多, 并且比DKRL提升巨大.
Ablation Study
KEPLER是一个多任务学习的模型, 作者希望探究对KEPLER性能提升的因素.
作者先将RoBERTa, RoBERTa*(仅使用MLM Loss), KEPLER - KE(仅使用KE Loss), KEPLER - Wiki在TACRED上进行测试:
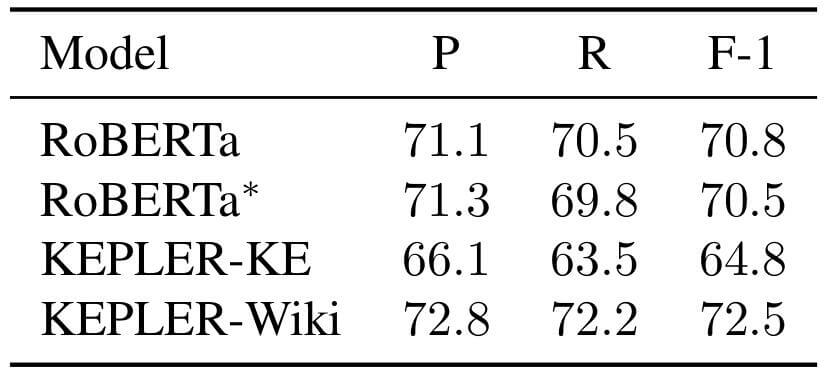
相比于RoBERTa, RoBERTa*和KEPLER - KE性能下降了, 作者说这证明了KE Loss和MLM Loss都是必不可缺的.
作者希望进一步量化的去看看KEPLER到底学到了多少知识, 在TACRED中在对实体进行Mask(ME, Masked Entity)和只保留实体(Only Entity)的情况下, 重新对关系进行分类, 结果如下:

KEPLER - Wiki学习到一些知识, 比用同等数据训练出来的RoBERTa*效果要更好一些.
Summary
作者分别从PLM和KGE两个方面总结了KEPLER的优点:
- KEPLER作为PLM, 将常识集成进了语言表示, 并且具有强大的语言理解能力, 并且增强了抽取知识的能力, 能够直接适应很多NLP任务.
- KEPLER作为KEM, 能够使用丰富的文本信息, 能在文本描述的引导下预测从没见过的实体.
在我看来, KEPLER其实很一般. 而且它有一些很明显的缺陷, 它没有很好地将实体描述中的相关做进一步扩展, 例如它没有很好地利用KG作为图的优势. 而且它的上下文提取能力获取的实体和关系表示是静态的, 并不能根据上下文改变实体的表达.
除去KEPLER本身外, 作者贡献了一个大规模附带文本描述的数据集.
最后, 就注入知识是否有益于NLU这个问题来说, 答案还是不明确. 从直觉的角度来说, KEPLER本身就能从上下文中利用BERT的结构学到一些语法知识, 在注入知识的情况下应该进一步提升NLU能力, 而现在很多工作实验结果则不然.

