Robust Speech Recognition via Large-Scale Weak Supervision
本文是论文Robust Speech Recognition via Large-Scale Weak Supervisions 的阅读笔记和个人理解. 论文来自ICML 2023. 个人推荐看Arxiv版本的, 因为在ICML的版本中似乎阉割了一些内容.
Whisper
Whisper是OpenAI推出的语音处理模型, 使用清理后680k小时的大规模语音数据(弱监督)训练, 在诸多语音下无需微调, 性能超过或近似人类表现.
Data Processing
Whisper没有做很重的预处理和标准化. 数据均来自互联网, 来自各种环境, 各种录音环境, 各种说话人, 各种语言.
但从互联网上获取的数据质量太低了, 作者采用了一些方法来提高数据质量:
- 现有许多Transcripts都来自于现成的ASR系统, 作者基于一些启发式方法来检测机器生成的Transcripts, 并将它们过滤掉.
- 使用Audio Language Detector, 如果语音和转录语言不匹配, 则滤去该数据. Transcript是英文的除外, 会被当做
X -> en的数据用于Speech Translation. 并在此时用模糊去重减少数据集中的重复. - 将Audio与Transcripts按照30s的切片间隔拆分为若干个切片. 并将其中没有语音的Segment用于Voice Activity Detection.
- 在训练初始模型后, 汇总各数据源以及其模型表现, 并根据数据源和性能的组合来手动检查过滤数据集.
- 最后, 在Training Set和Validation Set, 基于Transcripts做去重.
Model
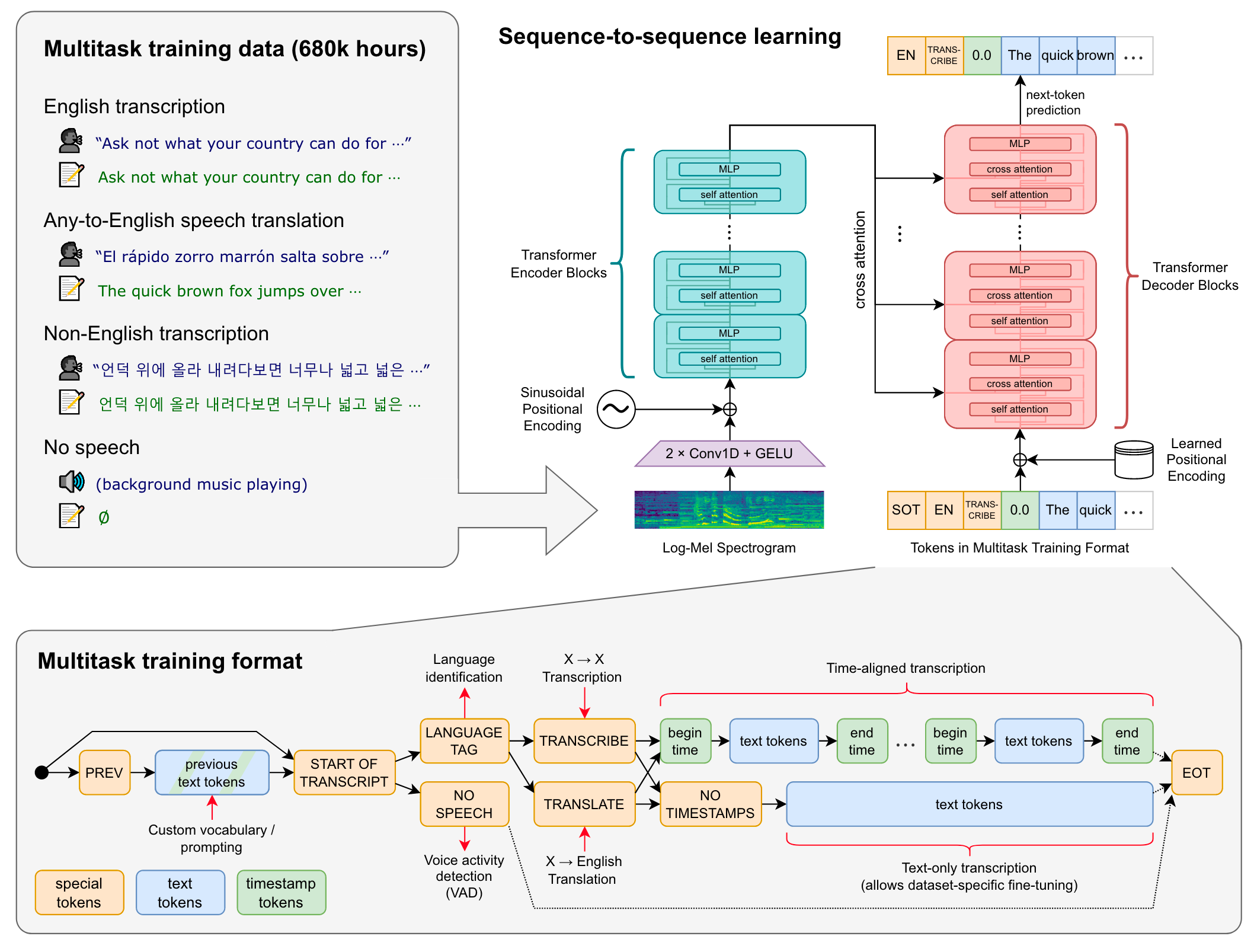
模型层面, Whisper是一个常标准的Encoder - Decoder Transformer.
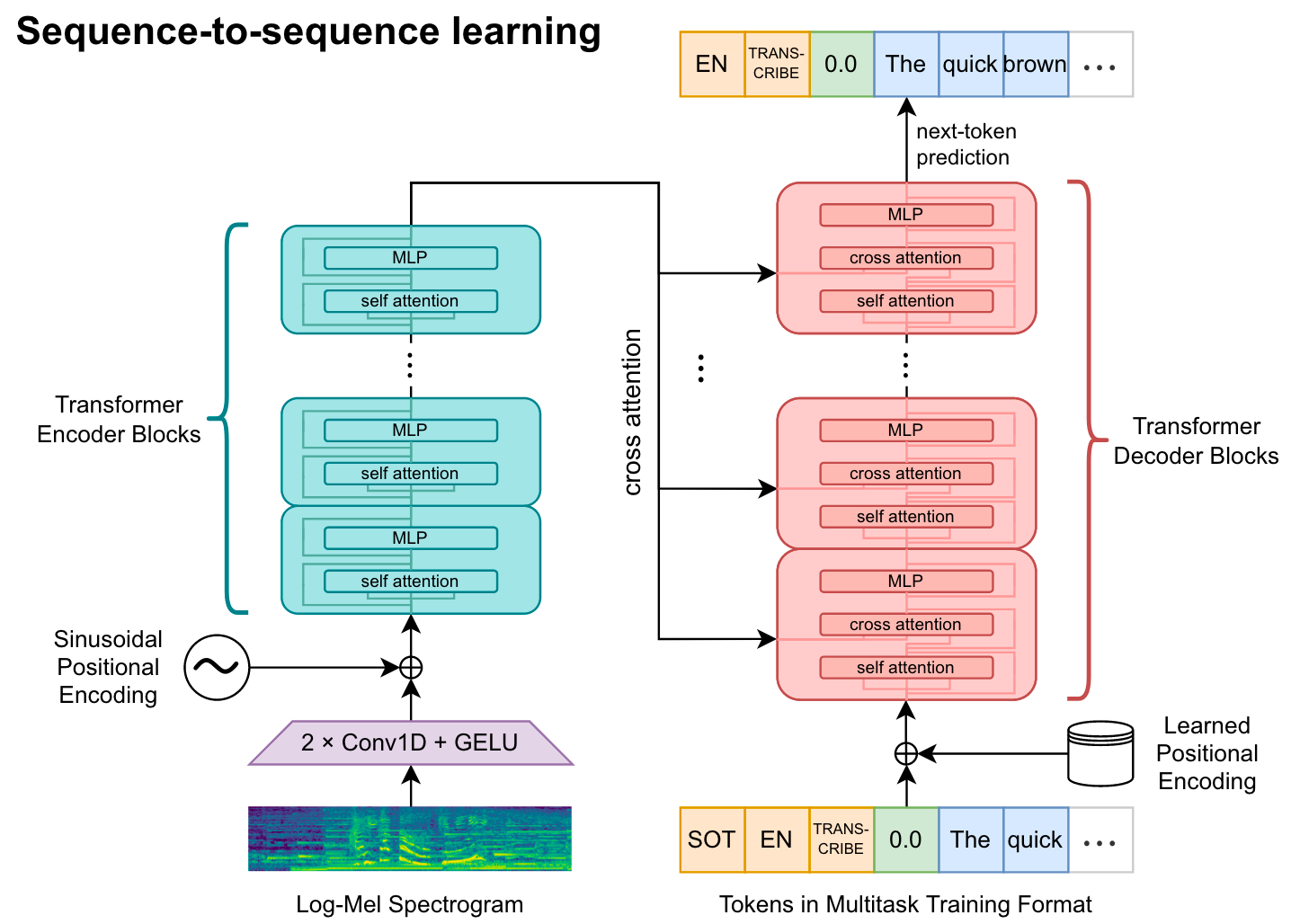
在输入到Encoder之前, 所有的音频都重采样16kHz, 输入音频数据归一化到[-1, 1] 之间近乎0均值, 并用80维的对数梅尔谱滤波器提取梅尔谱特征.
所有的Transformer Block都是pre-norm.
- Encoder: Audio Encoder. Encoder侧由两个
Conv1d和Gelu将梅尔频谱转换为Audio Segment Representation. 转换后再加上正余弦位置编码. - Decoder: Text Decoder. Decoder侧输入的是离散Token, 添加可学习的位置编码. 由于预期输出的Token不止英文, 是一个Multilingual Generation Task, 所以作者直接在GPT - 2的词表基础上扩充了其他语言的Token.
单从模型角度来看, Whisper还是非常简单的.
Multitask Format
一个完整的语音处理系统应包括许多任务, 例如Transcription, Translation, Voice Activity Detection, Alignment, Language Identification等:
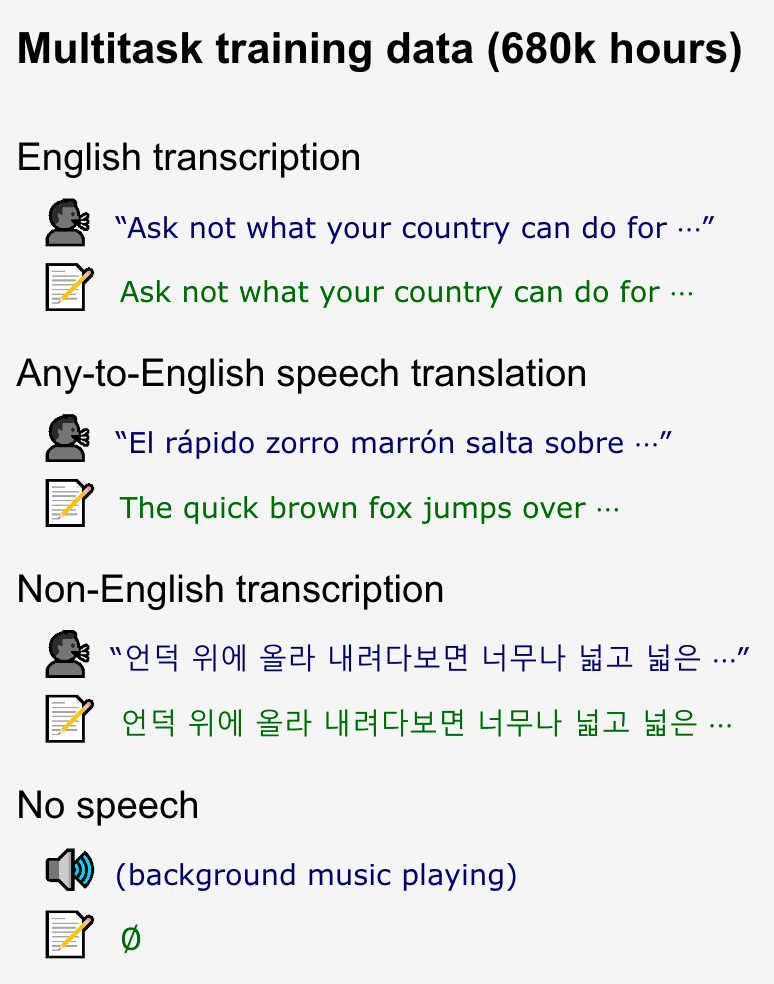
这些任务形式都可以被Decoder当做Input Token而形式统一. 尤其是Transcription还可以因上下文历史当做条件送入Decoder而在Long - form Transcription中受益(对话历史可以消歧, 生成更流畅的结果等等).
Decoder的Autoregressive Token的生成流程如下(其实就是一个完整的系统):
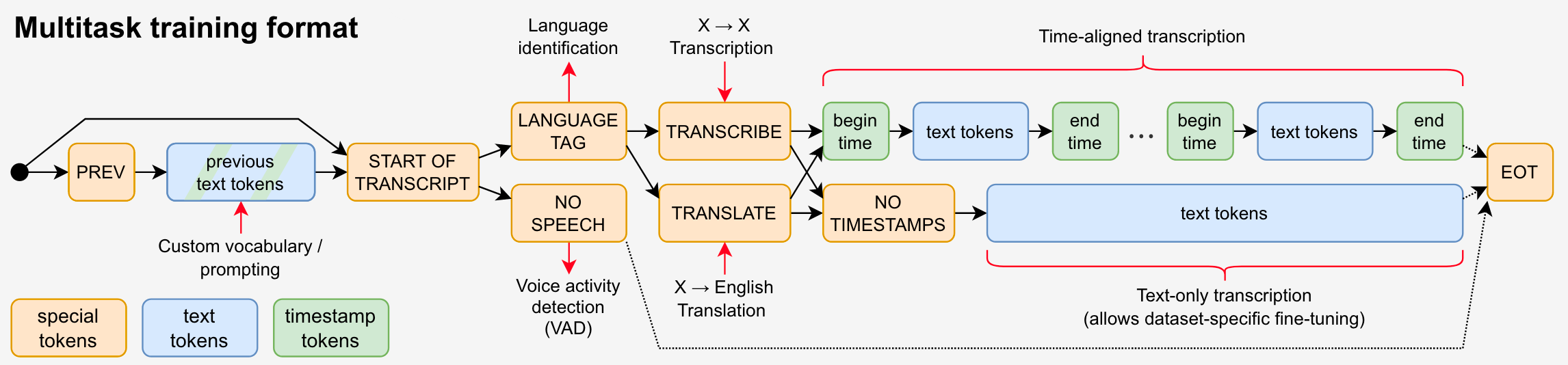
结合示意图来看:
- 首先, 需要
<|startoftranscript|>声明Transcription要开始了, 类似于Language Model中的<sos>. - 接着, 判断Audio Segment中是否有语音(Voice activity detection):
- 如果有语音, 输出语音的语言类型(Language identification).
- 如果没有语音, 则需要输出
<|nospeech|>. 直接结束转录.
- 然后, 判断任务类型. 即
<|transcribe|>与<|translate|>. - 声明是否需要Time stamps:
- 如果需要Time stamps, 则生成
<起始时间戳> + <转录文本> + <结束时间戳>. Time stamps量化到最近的20ms内(Time - aligned Transcription). - 如果不需要, 生成
<|notimestamps|>, 后续只需要生成Transcription后的文本.
- 如果需要Time stamps, 则生成
- 最后, 结束转录时输出
<|endoftranscript|>, 类似于Language Model中的<eos>.
Experiments
详细的模型参数设置和实验设置, 以及数据集的相关信息请参考原论文.
Zero - shot & Evaluation Metrics
Whisper的预期是做一个强大的语音处理系统, 下文中所有实验的评估方式都是Zero - Shot的.
ASR中一般使用WER 作为评估指标. 但WER也可能因格式对齐之间的差异, 导致较低的WER. 这种问题在Whisper这种Zero - Shot模型的设置下尤为显著.
因此, Whisper采用了在计算WER的一种Text Normalization方法来解决这个问题, 主要是包括一些标点的去处, 语气词的去除, 还有数字的规范化等. 细节详见原论文, transformers上已经有了实现.
Whisper中使用的Text Normalization相比于Fair Speech的Normalizer有更好的效果:
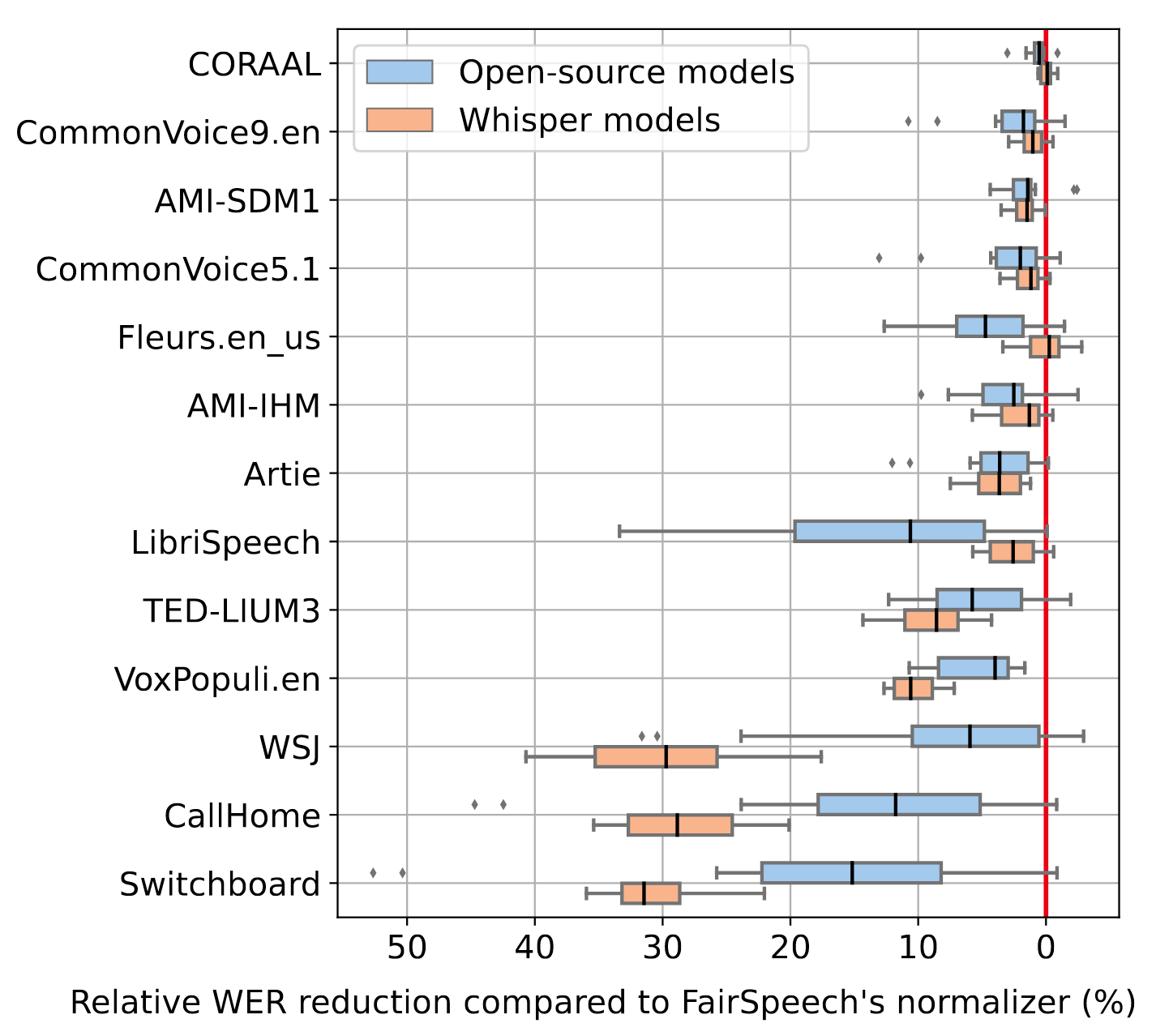
English Speech Recognition
按照前人提出的”Effective Robustness“, 作者做出了Whisper与其他有监督ASR模型在LibriSpeech和其他12个English Academic ASR数据集上性能表现:
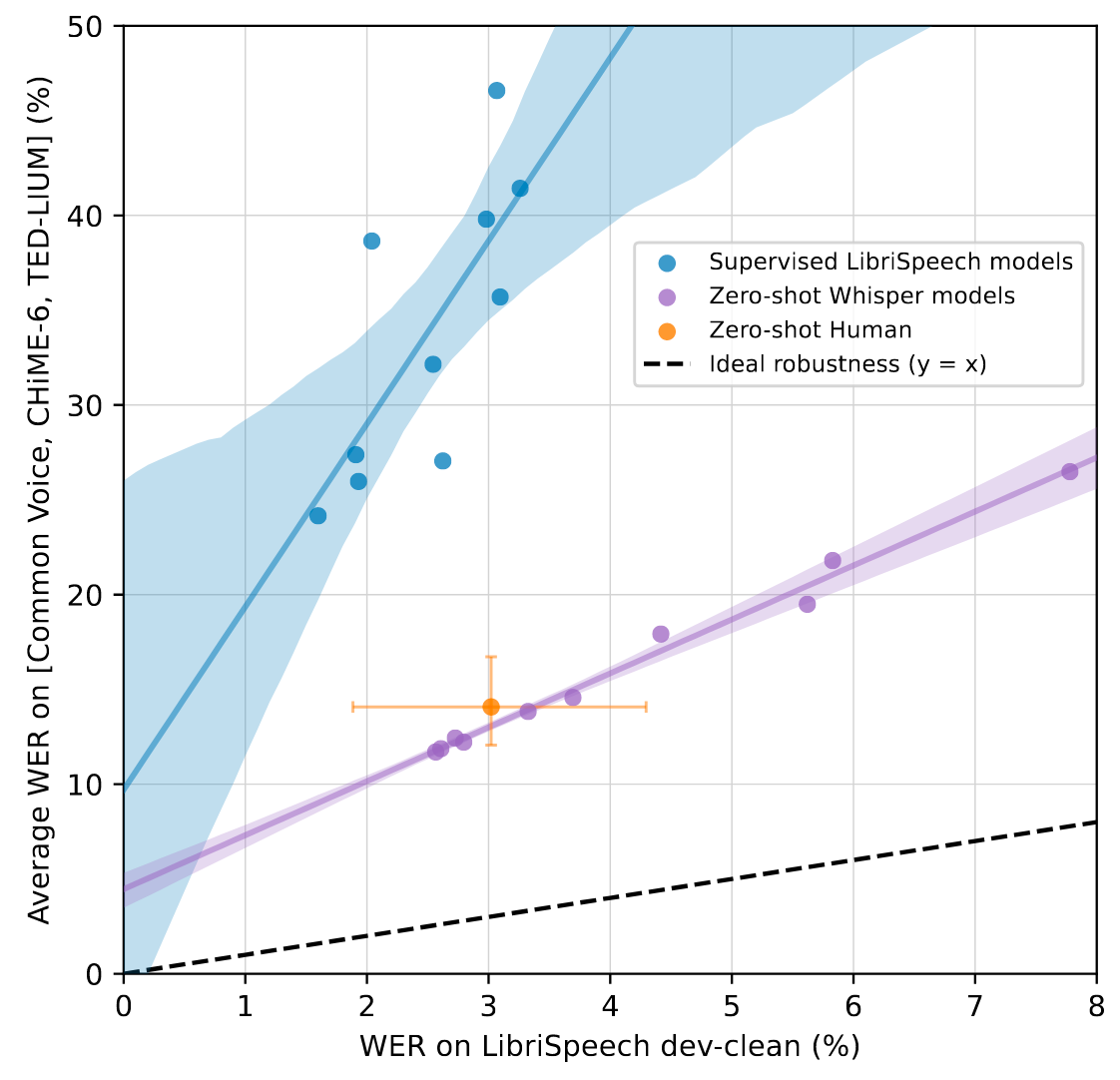
Whisper上的不同坐标点代表不同规模与配置的Whisper.
Whisper的弱监督后训练出来的表现与人类表现出的模式更相似, 在分布内外的不同数据集上具有更好的泛化能力, 表现也更加稳定. 而有监督ASR模型仅在分部内表现是良好的, 在分布外表现和分部内具有更大的差异.
与wav2vec 2.0在各类数据集上的Zero Shot比较结果如下:
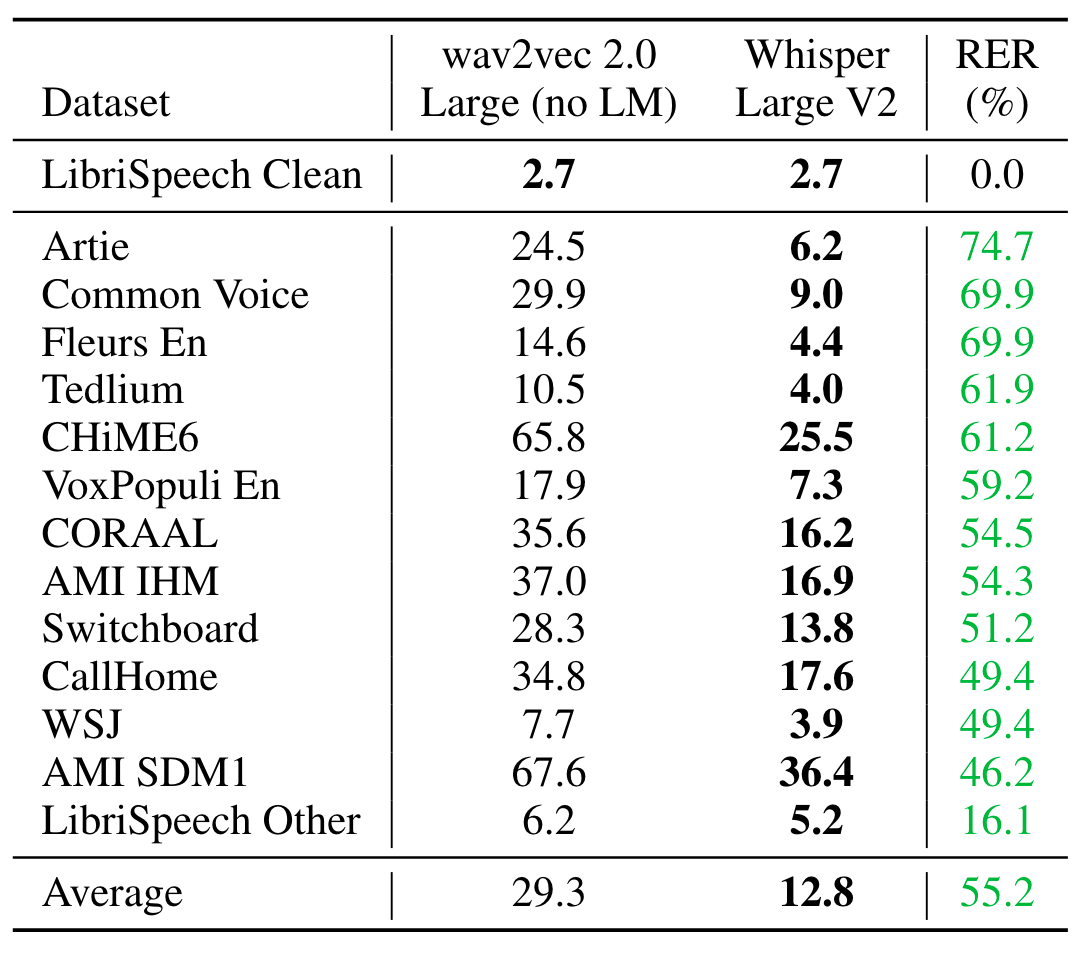
尽管它们在LibriSpeech Clean上具有相同的WER, 但Whisper在其他数据集上的表现远超wav2vec, 这也佐证了研究分布外鲁棒性的重要性.
Multi - lingual Speech Recognition
在Multilingual LibriSpeech, VoxPopuli两个多语言的ASR数据集上结果如下:
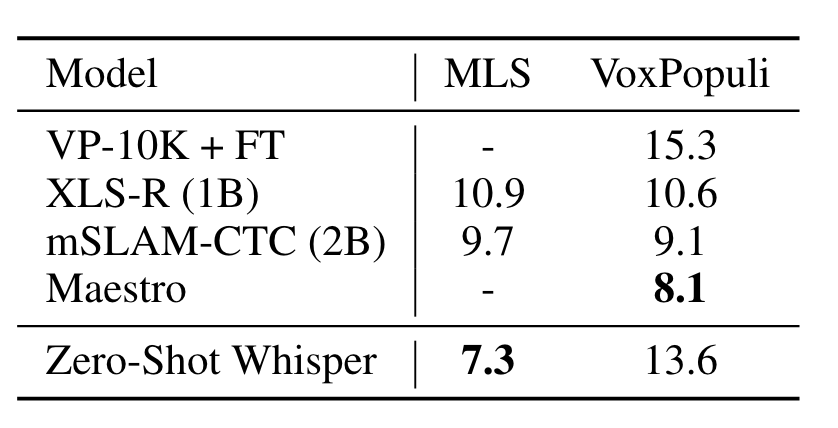
Whisper在MLS上表现非常好, VoxPopuli上表现不佳. 作者解释为其他模型将VoxPopuli作为无监督数据来源, 并且具有更多的有监督数据.
此外, 作者做出了在Fleurs上各语言有监督预训练数据量与各语言ASR之间的性能表现相关图:
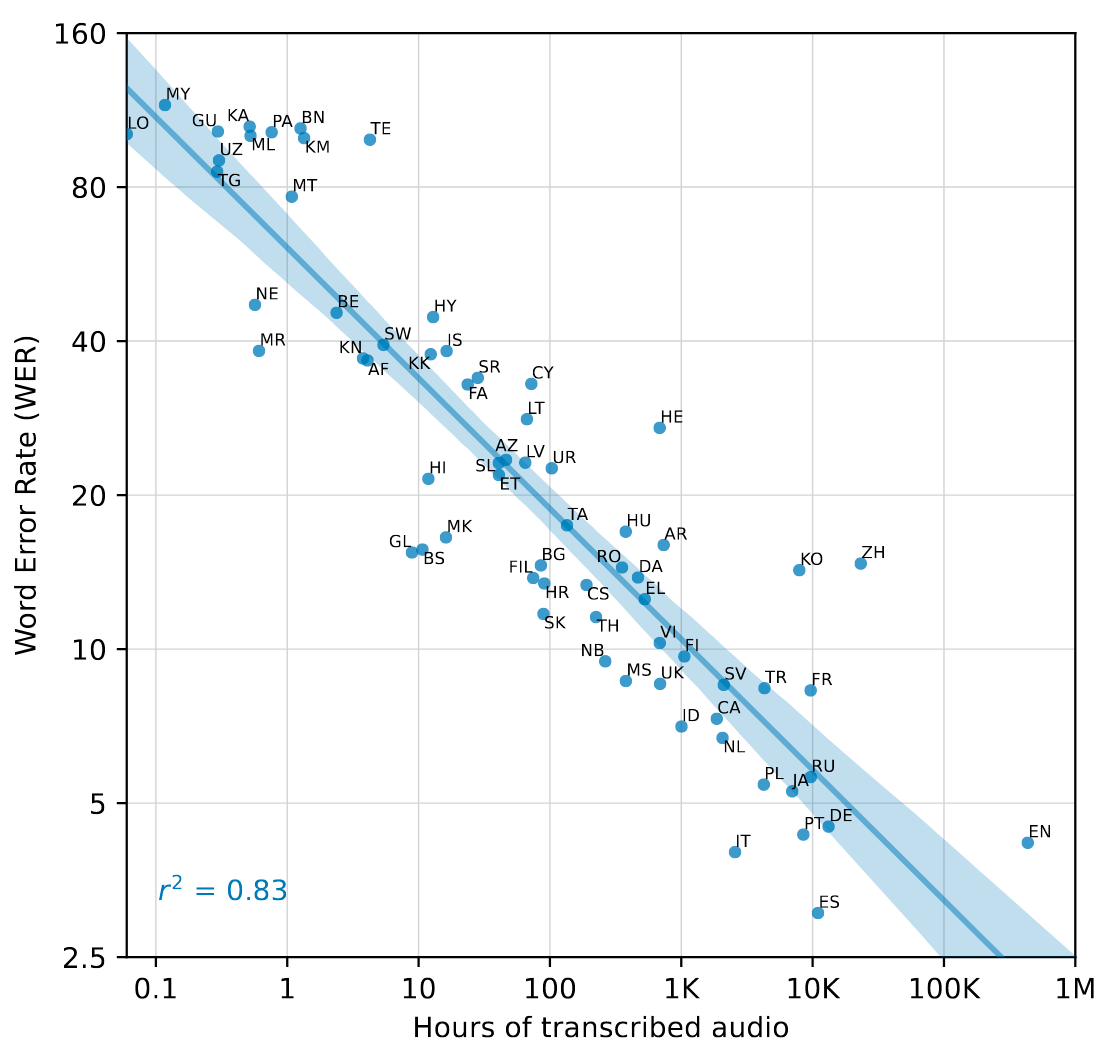
数据越多性能越好, 大约是每增加16倍数据WER就会减少一半. 大多数语言都符合作者发现的相关性. 少量语言例如中文(ZH), 韩语(KO), 希伯来语(HE)等偏离该规律可能是因为特殊的语系或者是数据质量, 分词之类导致的.
英语看起来也有点偏离, 可能是因为英语的边际效用导致受益递减.
看起来它们都具有自己独特的文字, 也就意味着这些语言的Token不与英文共享, 确实不太容易从Multilingual Knowledge中受益.
Translation
作者在CoVoST2的子集上, 按照High, Mid, Low-resource, 测试了X -> En 各模型的表现(指标是BLEU), 结果如下:
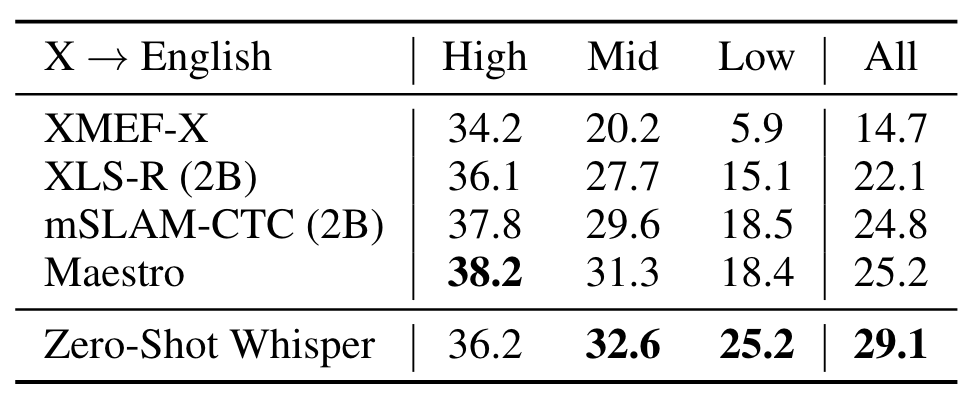
Whisper在Zero - Shot下达到了SOTA, 在高资源情况下也能达到媲美Finetune的效果.
对不同语言进行更细致的分析, 将Fleurs从语言识别转为X -> en 的翻译数据集, 以英文的Transcription当做Reference, 结果如下:
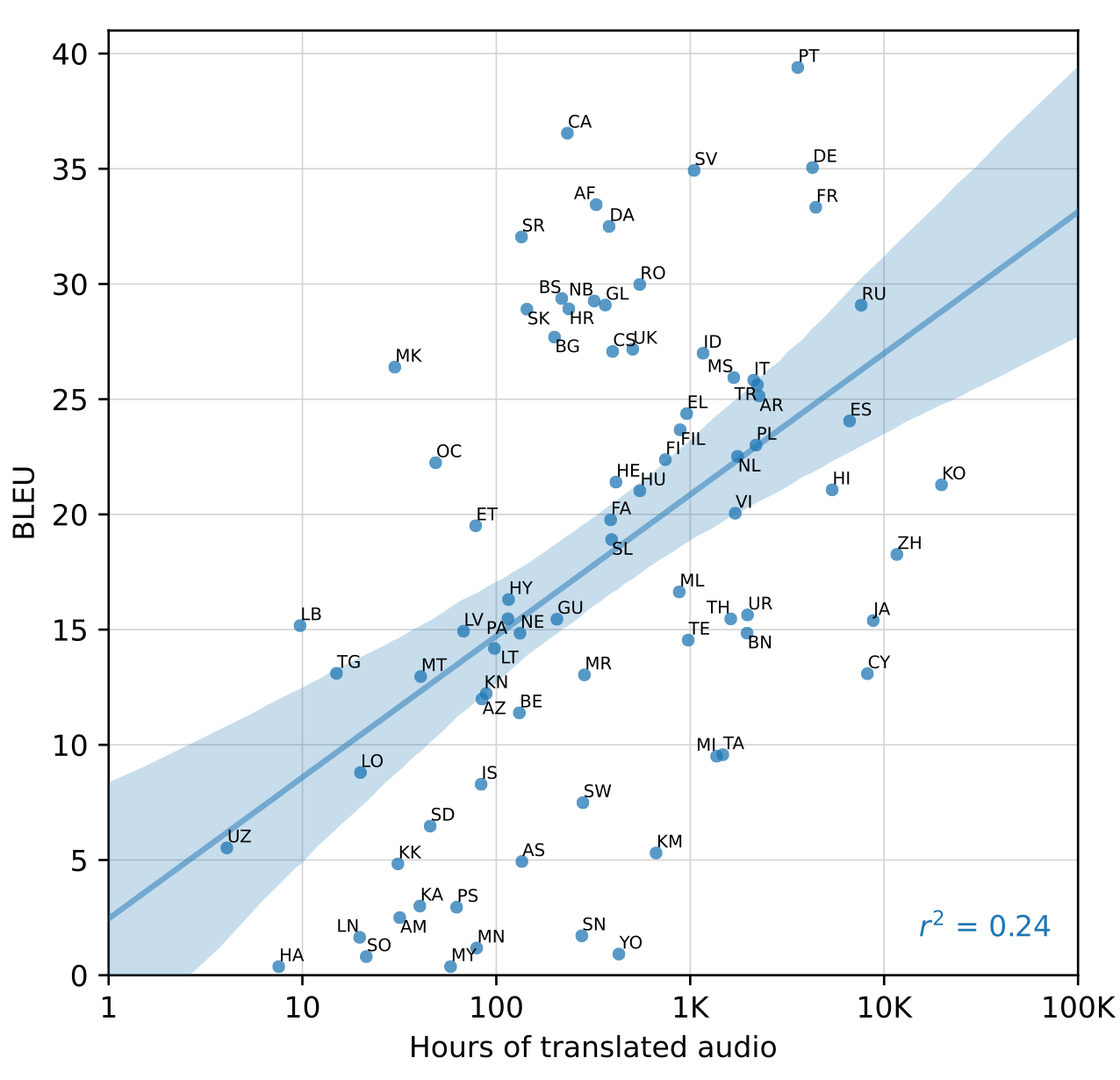
增加数据确实可以让模型效果更好, 但是也有非常多的异常值.
作者认为是Fleurs中存在很多语言识别错误, 例如将英语错分为威尔士语(CY), 虽然”威尔士语”有9k小时的数据, 但是BLEU却只有13. 大多的威尔士语音频只不过是带有英文字幕的英文音频. 因此它被错误的划分到Translation而不是Transcription当中.
应该是这部分实验没做好, 所以没放在ICML的正式论文当中.
Language Identification
Whisper在Fleurs数据集上做的Language Identification, 结果如下:

Whisper的Zero - Shot结果却是无法与有监督的方法媲美. 作者认为一部分原因是Fleurs上的其中20多种语言Whisper完全没有见过. 如果仅看重叠的82种见过的语言, Whisper可以做到80.3%的Acc.
Long - form Transcription
Strategies for Reliable Long - form Transcription
Whisper在训练的时候, 固定了上下文窗口长度为30s. 作者设计了多种启发式的方法来暂时缓解长文本转录中单个窗口中预测不准确对后续其他窗口产生负面影响的方法.
这套方法中包括:
- 用Beam为5的Beam Search预测对数概率当做Score Function, 以此减少Greedy Decoding的重复问题.
- 以0作为起始的Temperature(即直接选取概率最大的Token), 当Token的平均概率分布低于-1或者文本的gzip压缩率高于2.4时, 以0.2为增长的步长增加Temperature. 当Temperature低于0.5时, 以前一个窗口的Transcription作为条件预测下一个窗口可以提高性能. 这种对Temperature的控制被称为”Temperature Fallback“.
- 将
<nospeech>Token的阈值设为0.6, 且用对数概率阈值为-1能够提高Whisper检测语音活动的能力. - 将Initial Timestamps设置为0到1之间能避免前几个词作为输入的错误模式.
每一种方案都可以带来一定的收益, 但在各种数据集之间的提升并不是均匀的:
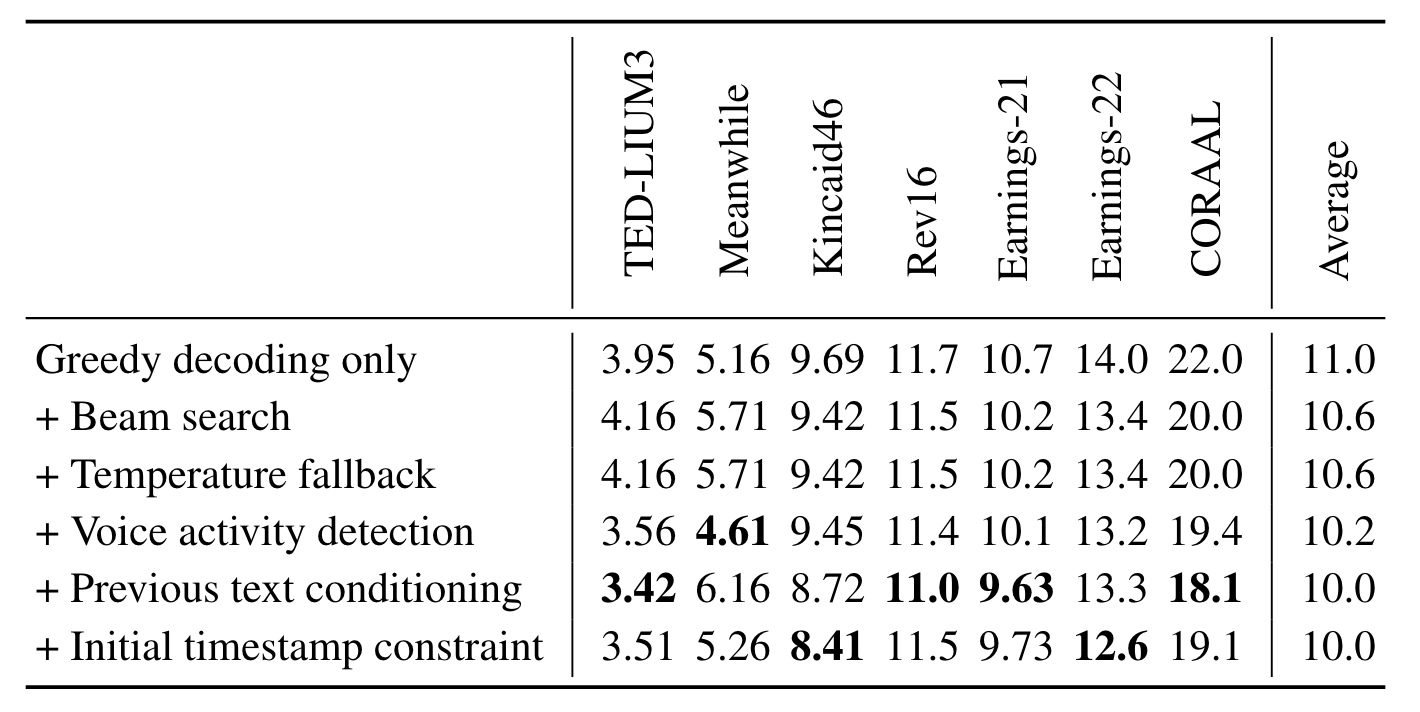
作者也提到, 上述方法实际上并没有办法完全消除错误预测带来的危害, 只是当做临时解决方案使用.
Comparison with Other ASR Models
在7个Long - form Transcription Dataset上和其他ASR模型对比表现如下:
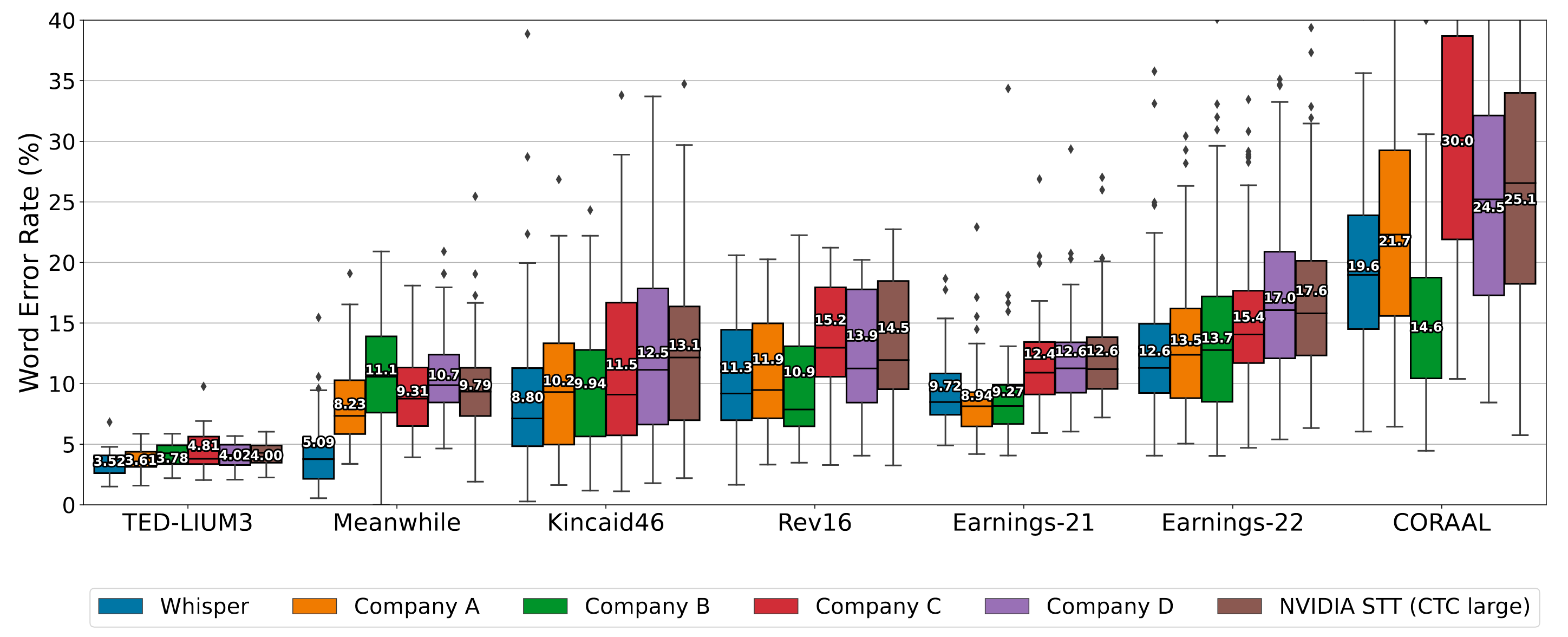
Whisper的总体表现是相对稳定的, 而且发挥的非常好.
Comparison with Human Performance
由于数据集中的模糊或错标, WER很难说明数据集的改进空间. 作者从Kincaid46中选了25个录音, 找了5个专业的转录员来做转录, 其中一个计算机辅助(E), 剩余四个完全人工. 结果如下:
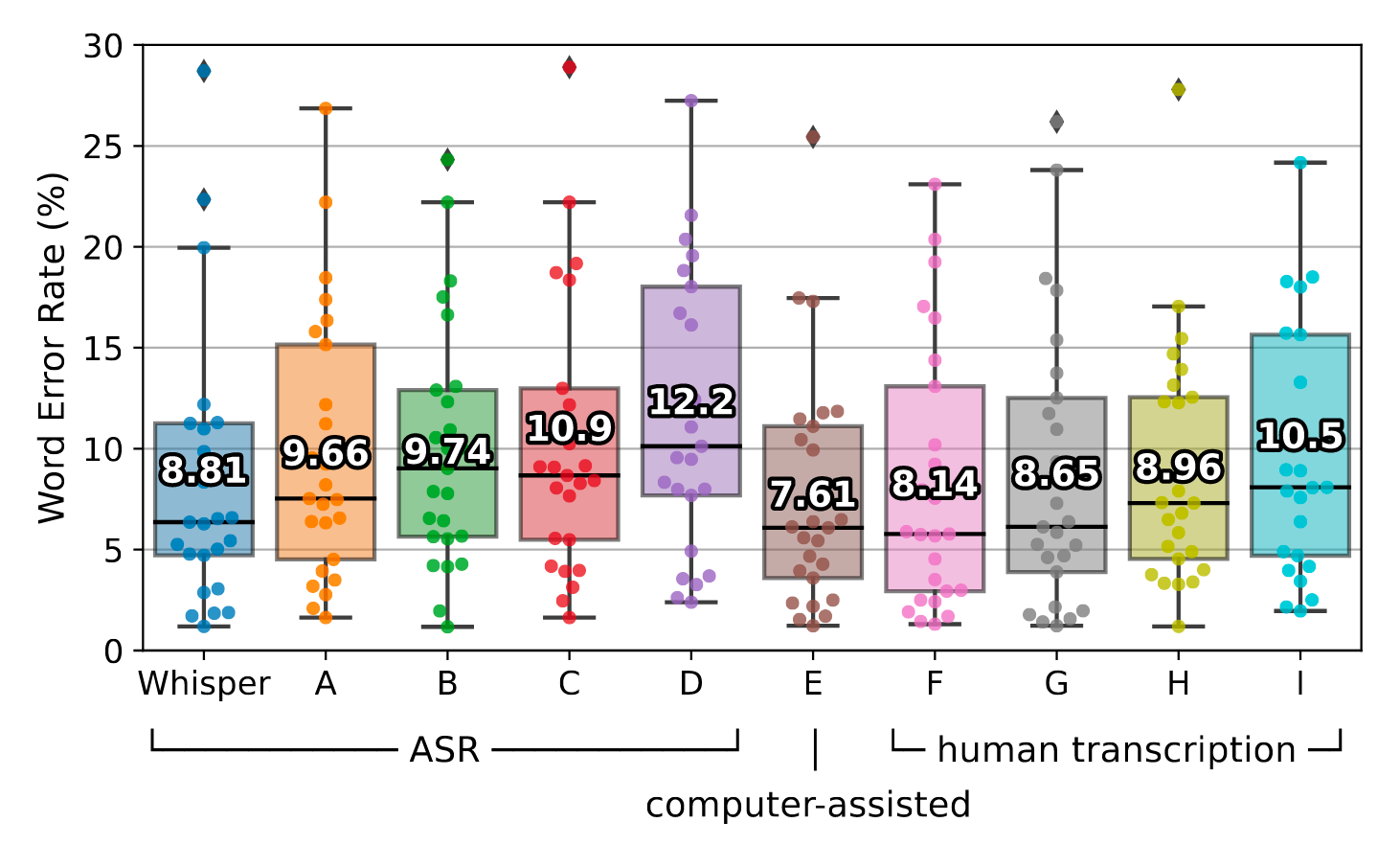
Whisper仍然存在8.81的WER, 但是它在长格式转录的表现已经是目前ASR系统中最接近人类水平的了, 与纯人工相比差距不到1%.
Robustness to Additive Noise
进一步测量Whisper的鲁棒性, 作者向测试数据添加一定的白噪声和酒吧中的噪声.
酒吧中的噪声被认为是一种更自然更契合现实场景的噪声, 确实更符合ASR应用的真实情况.
让我联想到平时看过的一些做不同类型白噪音的Up主, 这些噪声更具多元化, 不知道目前有没有相关的研究?
与其他Finetune过或预训练过的模型之间相比, 表现如下:
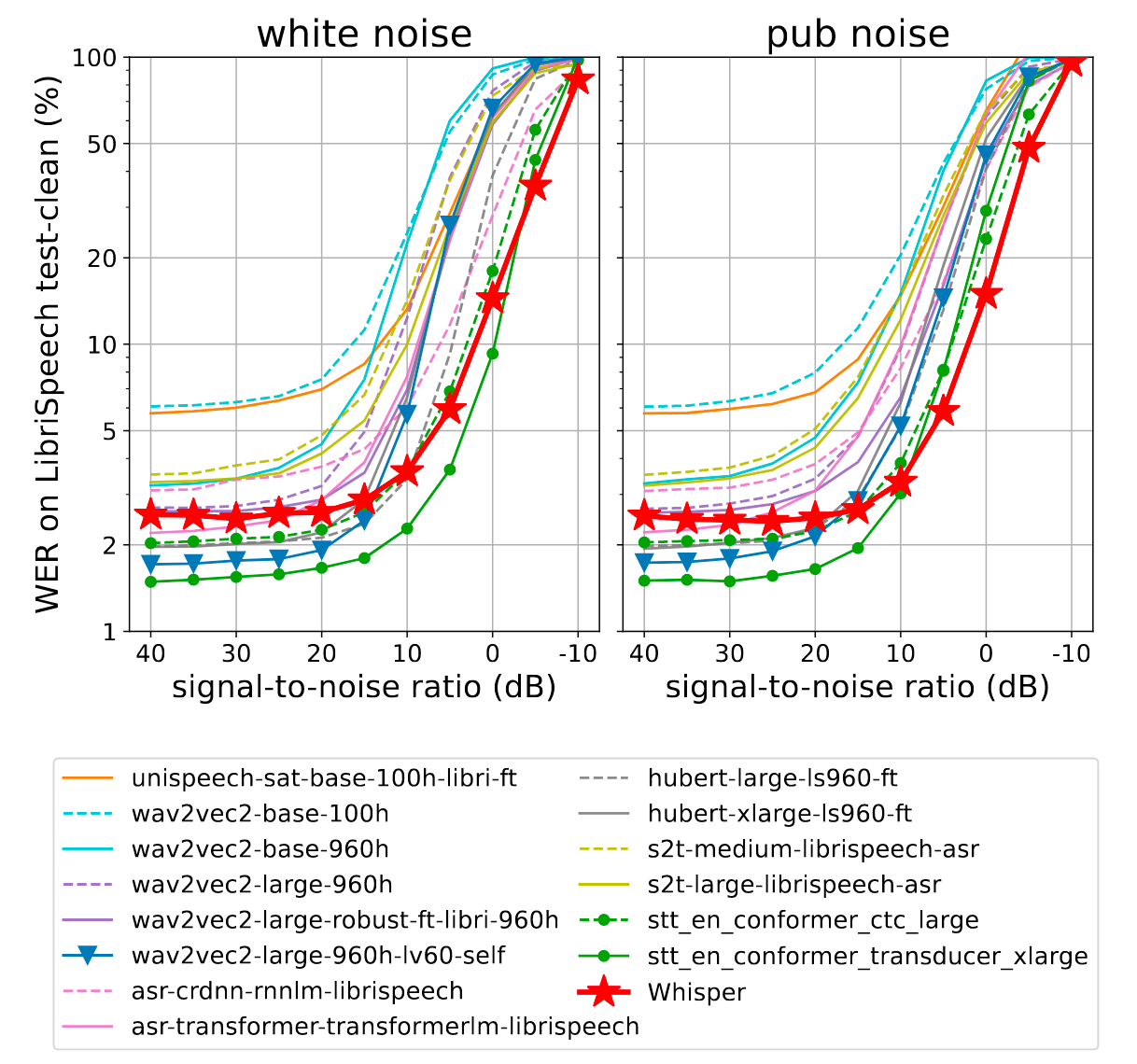
明显的, Whisper相较于其他ASR模型具有更好的抗噪能力.
比较有趣的是, Whisper在添加了一点点噪声的情况下表现还会比不加噪声好一些, 很有可能说明Whisper训练预料中本身就是附带一部分噪声的, 人工添加的噪声使得分布与预训练时更相似.
Analysis and Ablations
Dataset Scaling
Whisper在ASR, MSR, Translation上随语音数据小时数变化如下:
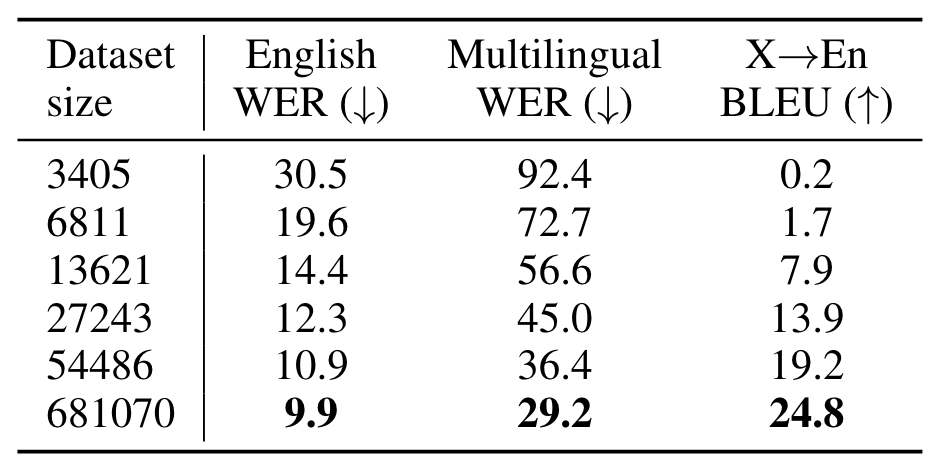
数据越多越好, 数据确实是影响模型性能最关键的要素之一.
Model Scaling
WER随模型Scaling变化表现如下:
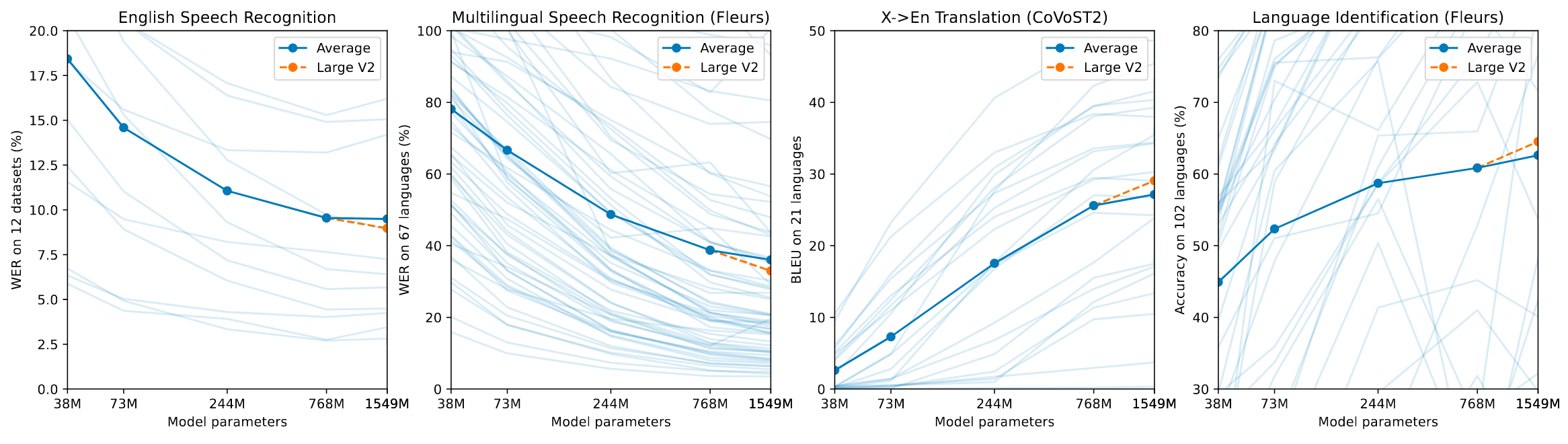
越大越好. 但是英语似乎快摸到底了.
Multitask and Multilingual Transfer
在不同训练量下, 多任务多语言模型和只训英语的模型在英语语音识别数据集上的表现如下:
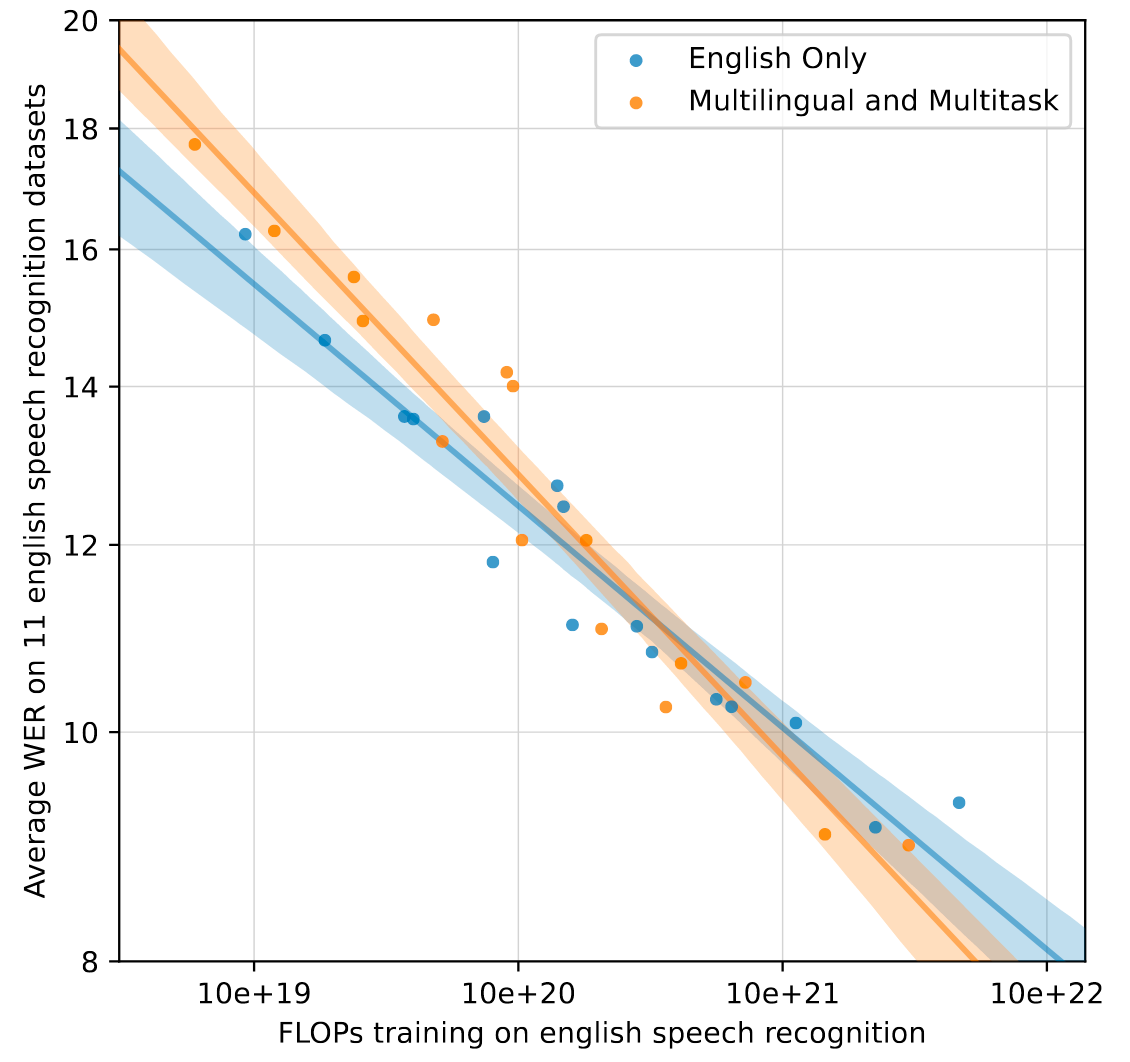
多语言多任务混合模型在训练量达到一定标准后, 拥有比只用英语数据训练模型更好的上限. 但在量达到之前, 还是会因为多语言多任务而加大模型的学习难度, 从而不利于英语任务的表现.
Summary
Whisper作为非常有代表性, 且成功的大大大工程, 已经在ASR领域被广泛运用, 技术已经算是非常成熟.
Whisper作为一个跨模态模型, 采用了便于扩展的Encoder - Decoder架构, 由于任务要求输出的是文本, 所以Whisper也可以从多任务统一为Next Token Prediction中受益, 语言之间的关联性也可以让Whisper在各类语言的Zero Shot都有不俗的表现.
在Whisper论文中进行的各类实验, 也为语音领域未来大大大工程的模型提供了指导. 虽然模型本身并不复杂(这也是当今的趋势), 但不得不从数据清洗, Text Normalization上看出OpenAI对工程问题的分析与处理还是相当细致的.
此外, Whisper非常有OpenAI的风格. 其实也能从CLIP(Vision-Language)和Whisper(Audio-Language)中看出OpenAI在迈向各种模态大大大的野心.
Recommended
最后, 根据ASR神器:Whisper使用指南扩展中提到的, 推荐两篇论文:
- 加速: Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
- 幻觉: WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
也推荐阅读OpenAI源码中的Temperature Fallback.

