2021.03.09: 修正关于引入逆三元组的影响.
2021.04.18: 更新一篇更早的类似论文GAKE.
LightCAKE: A Lightweight Framework for Context-Aware Knowledge Graph Embedding
本文是LightCAKE: A Lightweight Framework for Context-Aware Knowledge Graph Embedding的阅读笔记和个人理解.
Basic Idea
作者提出, 现有的KGE模型无法很好地平衡图上下文信息与模型计算的复杂度.
作者指出, 许多的KGE模型都忽略了图中所蕴含的上下文信息(其实用图的多跳信息概括更为生动). 而作者将图中蕴含的信息分为两种, 实体上下文信息和关系上下文信息:
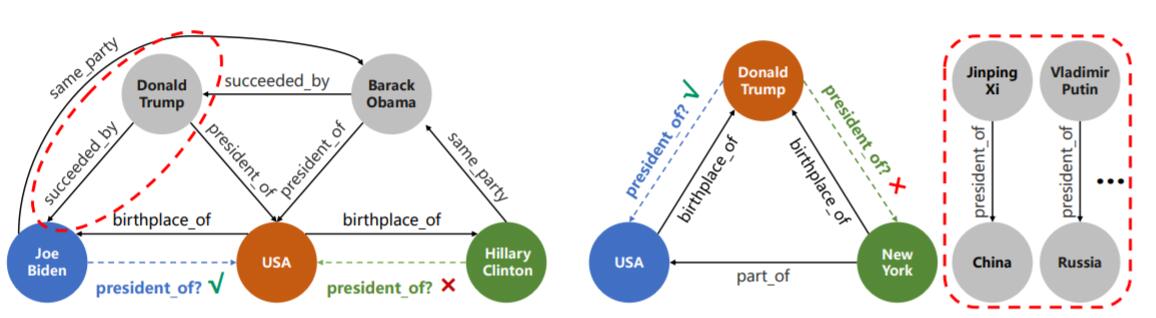
图中普通虚线代表需要被预测的关系, 而红色虚线所圈的内容是对预测有重大帮助的部分. 许多模型直接将二者全部忽略, 或是只关注其中的一种.
左侧图中从实体邻居的角度出发, 特朗普是拜登的一阶邻居, 考虑二者之间的关系将对预测有很大帮助.
右侧图中从关系对应的实体对角度出发, “president_of” 关系下所有的头尾实体都对预测特朗普是否是总统有帮助.
因此, 作者希望提出一种轻量级的框架, LightCAKE(Lightweight Framework for Context-Aware Knowledge Graph Embedding) 来解决上述问题. 既然涉及到图信息的集成, 那么采用图算法更为合适. 例如GNN, 能够很好地聚合邻居节点的信息, 也能够捕获一部分来自高阶邻居的多跳信息.
LightCAKE
Context Star Graph
在说明框架的运作方式之前, 先对实体上下文和关系上下文下个定义:
- Entity Context: 对于头实体$h$, 实体上下文被定义为$h$ 的邻居, $\mathcal{C}_{\text {ent }}(h)=\{(r, t) \mid(h, r, t) \in \mathcal{G}\}$.
- Relation Context: 对于关系$r$, 关系上下文被定义为$r$ 下的全部头尾实体对, $\mathcal{C}_{r e l}(r)=\{(h, t) \mid(h, r, t) \in \mathcal{G}\}$.
在图结构中, 实体和关系的上下文能一次性的构建:
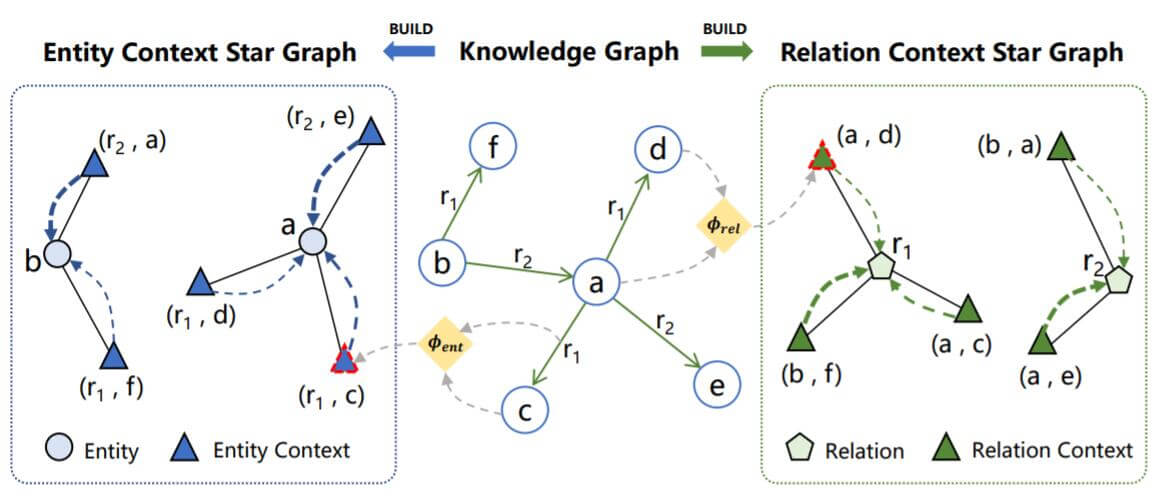
作者在论文中计算实体上下文$\mathcal{C}_{\text {ent }}(h)$ 时只考虑了$h$ 的出边邻居, 忽略了入边邻居. 对于三元组$(h, r, t) \in \mathcal{G}$, 作者都创建一个逆三元组$(t, r^{-1}, h)$, 使得头实体和尾实体之间的边变为双向边(图中虚线部分).
Inverse Triplet是否会导致Inverse Leakage?
实际上这里不会导致标签泄露. 在FB15K和WN18中引入的大量逆关系导致Leakage的原因并不是因为主动引入了逆三元组. 而是因为原本的三元组构建中就包含逆三元组, 在划分训练集和测试集的时候, 将部分互逆三元组对划分到了训练集和测试集两部分, 所以在测试集中的三元组可以由训练集过拟合得到, 从而导致的标签泄露.
而这里主动引入逆三元组, 若原数据集中不存在互逆三元组对, 那么训练时是不会将信息泄露给测试集的. 比如原来的三元组存在于训练集, 引入的新逆三元组也应该属于训练集, 这样就不会造成标签泄露.
事实上, 现在很多KGE方法都是这样做的.
LightCAKE Details
LightCAKE被作者分为两部分:
- 将实体或关系上下文编码进Embedding(Encode).
- 迭代聚合上下文节点的信息(Attention).
每次迭代的更新方程如下:
$$
\begin{array}{l}
e_{h}^{(l+1)}=e_{h}^{(l)}+\sum\limits_{\left(r^{\prime}, t^{\prime}\right) \in \mathcal{C}_{\text {ent }}(h)} \alpha_{h,\left(r^{\prime}, t^{\prime}\right)}^{(l)} \phi_{\text {ent }}\left(e_{r^{\prime}}, e_{t^{\prime}}\right) \\
e_{r}^{(l+1)}=e_{r}^{(l)}+\sum\limits_{\left(h^{\prime}, t^{\prime}\right) \in \mathcal{C}_{r e l}(r)} \beta_{r,\left(h^{\prime}, t^{\prime}\right)}^{(l)} \phi_{\text {rel }}\left(e_{h^{\prime}}, e_{t^{\prime}}\right)
\end{array}
$$
每次在原来Embedding的基础上有权重地聚合了图结构中的多跳信息. 其中$\phi$ 代表编码函数, $\phi(\cdot): \mathbb{R}^{d} \times \mathbb{R}^{d} \rightarrow \mathbb{R}$. $l$ 是迭代的次数, $0\leq l\leq L$.
$\alpha_{h,\left(r^{\prime}, t^{\prime}\right)}^{(l)}, \beta_{r,\left(h^{\prime}, t^{\prime}\right)}^{(l)}$ 分别是在实体上下文星图和关系上下文星图中对其他节点的注意力:
$$
\begin{aligned}
\alpha_{h,\left(r^{\prime}, t^{\prime}\right)}^{(l)}=\frac{\exp \left(\psi\left(e_{h}^{(l)}, e_{r^{\prime}}^{(l)}, e_{t^{\prime}}^{(l)}\right)\right)}{\sum_{\left(r^{\prime \prime}, t^{\prime \prime}\right) \in \mathcal{C}_{e n t}(h)} \exp \left(\psi\left(e_{h}^{(l)}, e_{r^{\prime \prime}}^{(l)}, e_{t^{\prime \prime}}^{(l)}\right)\right)} \\
\beta_{r,\left(h^{\prime}, t^{\prime}\right)}^{(l)}=\frac{\exp \left(\psi\left(e_{h^{\prime}}^{(l)}, e_{r}^{(l)}, e_{t^{\prime}}^{(l)}\right)\right)}{\sum_{\left(h^{\prime \prime}, t^{\prime \prime}\right) \in \mathcal{C}_{r e l}(r)} \exp \left(\psi\left(e_{h^{\prime \prime}}^{(l)}, e_{r}^{(l)}, e_{t^{\prime \prime}}^{(l)}\right)\right)}
\end{aligned}
$$
其中, $\psi$ 是具体的打分函数, 也就是具体的KGE方法, 例如TransE, DistMult等.
通过$L$ 次迭代, 就能得到一组上下文增强的Embedding $e_{h}^{(L)}, e_{r}^{(L)}, e_{t}^{(L)}$. 然后分别计算出在已知头实体和尾实体条件下未知关系$r$ 条件概率:
$$
p(r \mid h, t)=\frac{\exp \left(\psi\left(e_{h}^{(L)}, e_{r}^{(L)}, e_{t}^{(L)}\right)\right)}{\sum_{r^{\prime} \in \mathcal{R}} \exp \left(\psi\left(e_{h}^{(L)}, e_{r^{\prime}}^{(L)}, e_{t}^{(L)}\right)\right)}
$$
根据计算得出的条件概率$p(r \mid h, t)$, 用极大似然来优化Embedding:
$$
\mathcal{L}=-\frac{1}{|\mathcal{D}|} \sum_{i=0}^{|\mathcal{D}|} \log p\left(r_{i} \mid h_{i}, t_{i}\right)
$$
对于作者文中所采用的两种方法TransE和DistMult, 作者将它们的打分函数代入后写出了改进方法的详细形式, 在此没有必要列出了.
作者注意到, 与图相关的GNN算法存在过参数化的问题, 所以整套LightCAKE框架没有添加任何额外的参数.
Experiments
作者认为, 使用Relation Prediction与使用Link Prediction一定程度上是等价的, 所以这里采用了Relation Prediction作为评估任务.
我个人认为还是有些不同, Relation Prediction的难度比Link Prediction难度要小得多.
Main Results
作者选用了现在效果比较好的Baseline, ComplEx, SimplE, RotatE, DRUM, R - GCN和改进后的TransE, DistMult性能做了对比:
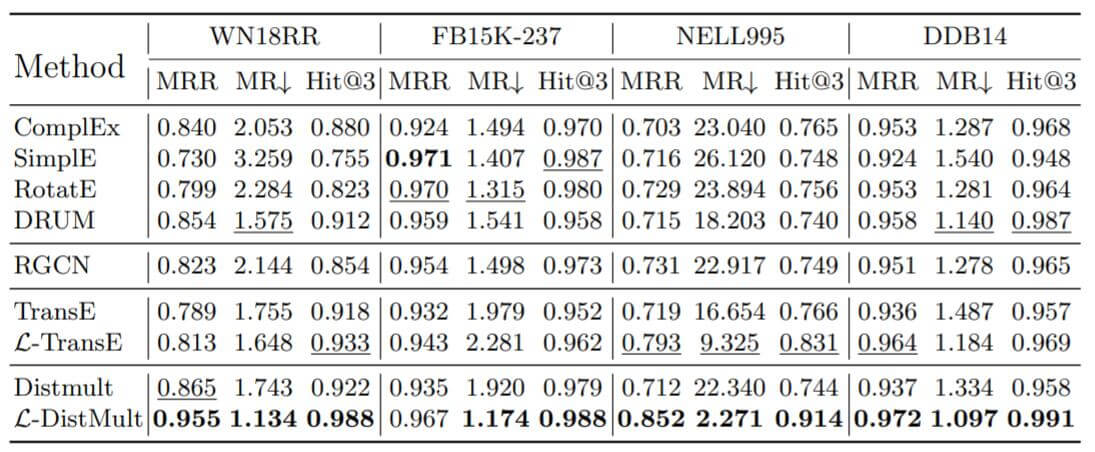
改进后的方法不但性能上比现在已有的方法性能要好, 而且性能与没改进前要高许多(针对MRR来说).
Ablation Study and Analysis on Number of Iterations
作者在消融实验中逐步引入图多跳信息, 查看引入的信息对性能产生的影响, 也探究了迭代次数对Embedding产生的影响. 作者将引入信息的程度分为四个等级:
- 不引入任何图结构的信息.
- 只引入关系上下文信息, 记为$\mathcal{L}_{rel}$.
- 只引入实体上下文信息, 记为$\mathcal{L}_{ent}$.
- 引入实体和关系上下文信息, 记为$\mathcal{L}$.
实验结果如下:
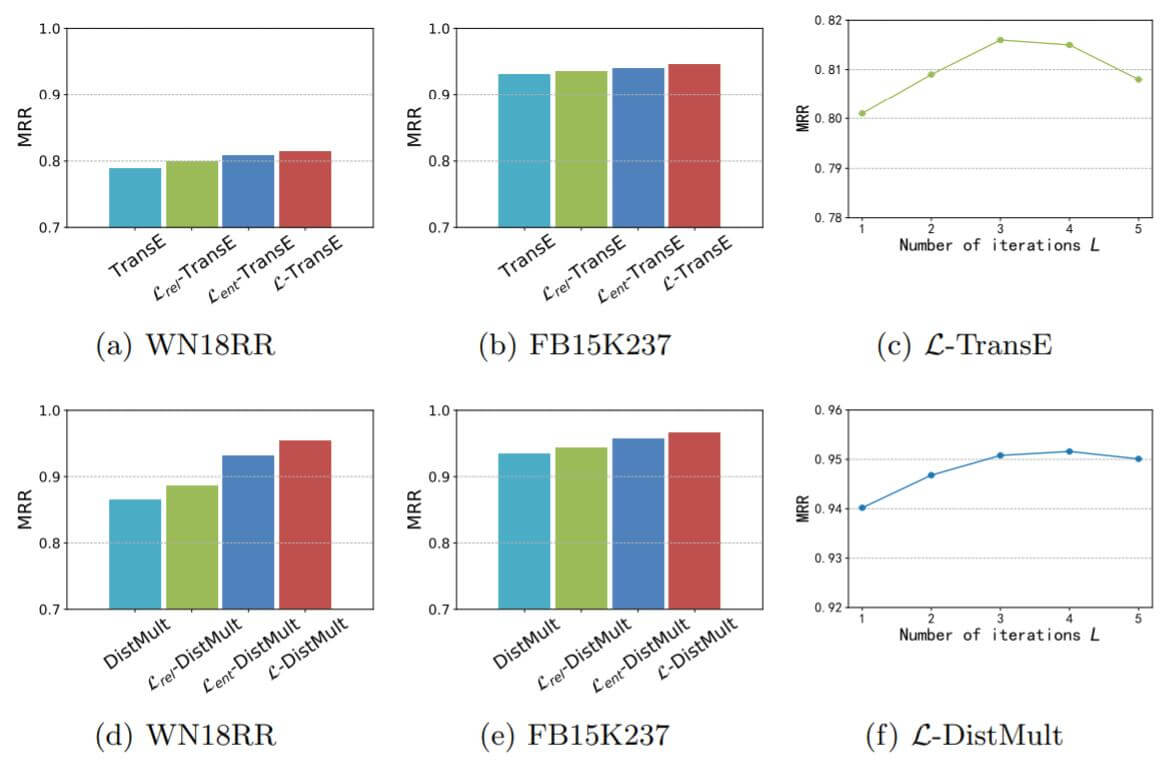
随着引入信息的逐渐增加, 模型性能逐渐提高. 引入实体信息后的提升比引入关系信息要大.
关于迭代轮数, 迭代过多次数反而会导致性能下降, 控制在3 ~ 4 次为宜.
Efficiency Analysis
作者将改进前后和基于图的算法(R - GCN)做了效率上的比较:
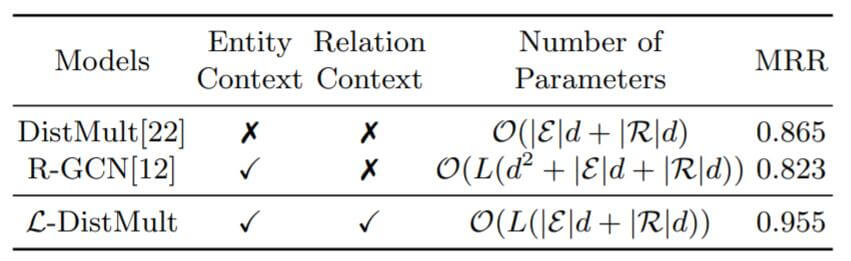
DistMult在改进后增加了L倍的复杂度, 但却获得了实体和关系上的图结构信息双加成, 效果提升显著. 而R - GCN的时间复杂度比较高, 没有利用图上的关系信息.
Summary
LightCAKE是一个轻量级的集成图多跳信息的KGE框架, 无需添加任何额外的参数, 仅用部分计算量就将关系和实体上下文信息全部集成了起来, 整体非常简洁. 作者也注意到了GNN中的过参数化问题, 这点很宝贵. 但实验部分采用了Relation Prediction作为评估, 我仍然期待它在Link Prediction上的效果.
对我的启发:
- 要利用好图结构优势, 图中蕴含着多种多跳信息, 不能白白浪费它们. 从可解释的角度, 图结构也占有优势.
- 注意各类方法在KGE中的过参数化(尤其是GNN), 有时候参数过多也不是啥好事, 可能不利于优化, 还增加了时间复杂度.
- 引入实体, 关系双角度信息, 能更好的刻画节点. 如果有更多角度的信息, 能更精确的找到节点定位.
经评论区老哥指路, LightCAKE的Entity Context的定义和GAKE(COLING2016)的Neighbor Context定义是一样的, 并且同样也是用Attention分配上下文的对Embedding的影响, 用极大似然优化. 只是GAKE还额外定义了Path Context和Edge Context, 而LightCAKE可以使用别的打分函数. 整体上来讲, 这两篇论文非常像.

