本文前置知识:
- BERT: 详见ELMo, GPT, BERT.
本文是论文KG-BERT: BERT for Knowledge Graph Completion的阅读笔记和个人理解.
Basic Idea
在先前的KGE方法中, 虽然它们能学到独特的实体关系表示, 但是却忽略了上下文. 句法和语义信息在大规模文本数据中没有得到很好的利用, 它们仅仅使用了实体描述, 关系提及或者实体共现.
因为BERT在NLP中作为PLM取得的成果非常亮眼, 所以作者希望将它迁移到知识图谱补全任务中, 测试其在KGC中的性能. BERT是针对自然语言进行处理的, 作者简单的将实体和关系描述放入BERT, 使BERT能够获取KGC的能力, 称之为KG - BERT. 作者称, 这是第一项使用PLM对三元组进行建模的研究.
KG - BERT
既然BERT是基于自然语言的, 那么很容易就想到用实体和关系的描述或者它们的名字放入BERT, 然后获得通过某种训练方式得到三元组的表示. 作者设计了两种训练方式的KG - BERT, 这样能使它被运用到不同的知识图谱补全任务当中.
KG - BERT(a)
在第一种方式中, 作者非常朴素的完全沿用了BERT的方法, 将实体, 关系描述或名字全部放入BERT中, 并用[CLS]处的隐态输出$C$ 来预测三元组是否正确, 该方式与BERT中的NSP任务完全一致. 第一种方式是针对三元组建模的.
例如, 三元组$(\text{SteveJobs}, \text{founded}, \text{AppleInc})$ 中的头实体$\text{SteveJobs}$ 可以表示为它的描述Steven Paul Jobs was an American business magnate, entrepreneur and investor 或者它的名字Steve Jobs, 而尾实体$\text{AppleInc}$ 可以表示为Apple Inc. is an American multinational technology company headquartered in Cupertino, California或者它的名字Apple Inc.
在后续的研究中, NSP已经被证实会在NLP任务中带来副作用.
在不同实体和关系之间用[SEP] 进行分隔, 并且每个Token的描述分别由Token本身的Embedding, Segment Embedding, Position Embedding组成. Segment Embedding因元素类型不同而不同, 头实体和尾实体都使用$e_A$ 作为Segment Embedding, 而关系采用$e_B$.
我们把[CLS]处的隐态输出$C$ 用来计算三元组的分类, 对于三元组$(h, r, t)$, 其打分函数为:
$$
\mathbf{s}_{\tau}=f(h, r, t)=\operatorname{sigmoid}\left(C W^{T}\right)
$$
其中$W$ 是变换矩阵, 和$C$ 乘完后可以获得三元组是否正确的概率$s_\tau$.
在文中写到, $s_\tau$ 是一个二维向量, 包含$s_{\tau0}, s_{\tau1}$. $s_{\tau0} + s_{\tau1}=1$. 这是不是有点多余了… 其实只需要一个一维的$s_{\tau}$ 就足够了, 因为另一半可以用概率和为1算出来.
现在对前面的模型描述进行总结, 整体结构如下:
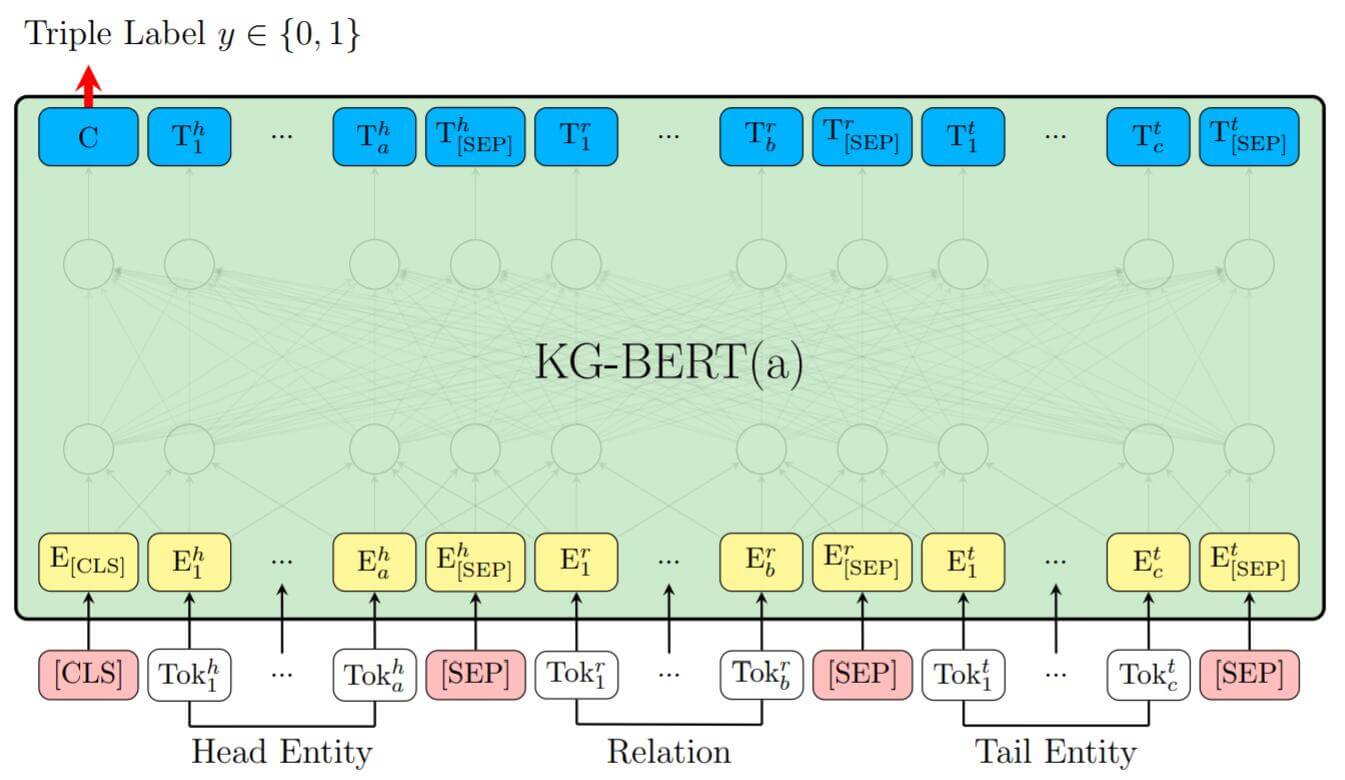
其中优化用的损失函数为BCE:
$$
\mathcal{L}=-\sum_{\tau \in \mathbb{D}+\cup \mathbb{D}^{-}}\left(y_{\tau} \log \left(s_{\tau 0}\right)+\left(1-y_{\tau}\right) \log \left(s_{\tau 1}\right)\right)
$$
其中$y_\tau$ 是三元组是正例还是负例的标签, 在0和1之间取. $\mathbb{D}^{-}$ 代表负例, $\mathbb{D}^{+}$ 代表正例.
负样本仍然是负采样, 仅替换头实体和尾实体得来的:
$$
\mathbb{D}^{-}=\left\{\left(h^{\prime}, r, t\right) \mid h^{\prime} \in \mathbb{E} \wedge h^{\prime} \neq h \wedge\left(h^{\prime}, r, t\right) \notin \mathbb{D}^{+}\right\}
\cup\left\{\left(h, r, t^{\prime}\right) \mid t^{\prime} \in \mathbb{E} \wedge t^{\prime} \neq t \wedge\left(h, r, t^{\prime}\right) \notin \mathbb{D}^{+}\right\}
$$
KG - BERT(b)
在第二种方式中, 作者只使用两个实体$h, t$ 的描述, 来预测它们之间的关系$r$. 在实验中, 作者发现这种结构在预测关系时效果要优于KG - BERT(a).
KG - BERT(b)采用[CLS] 处的隐态输出$C$ 后接一个分类矩阵来预测两实体之间的关系:
$$
\mathbf{s}_{\tau}^{\prime}=f(h, r, t)=\operatorname{softmax}\left(C W^{\prime T}\right)
$$
其中$W$ 为关系的分类矩阵, 多分类也将$\operatorname{sigmoid}$ 换成了$\operatorname{softmax}$.

负样本仍然来源于负采样, 只是对正例三元组的关系进行替换即可.
因为变更了任务, 损失函数不再使用BCE, 而是采用CE进行多分类:
$$
\mathcal{L}^{\prime}=-\sum_{\tau \in \mathbb{D}^{+}} \sum_{i=1}^{R} y_{\tau i}^{\prime} \log \left(s_{\tau i}^{\prime}\right)
$$
其中$y_{\tau i}^{\prime}$ 是关系的独热向量.
Experiments
在实验中, 作者希望探究KG - BERT的下述能力:
- 模型能不能判断没见过的三元组的正确与否?(KG - BERT(a))
- 模型能不能根据给出的单个实体和关系描述预测出另一个实体?(Link Prediction)
- 模型能不能预测两个实体之间的关系?(KG - BERT(b))
作者使用BERT - BASE初始化权重, 因为BASE比LARGE版本所受超参影响更小, 可选择的超参也很少. 其余参数设置详见原论文.
Knowledge Graph Compeltion Tasks
Triple Classification
在三元组分类问题上, 作者在WN11和FB13做了实验:

KG - BERT效果非常明显, 该任务目标与其训练目标是一致的. 作者将其优秀的表现总结如下:
- 输入中含有实体和关系的单词序列(使用了文本描述).
- 三元组分类与BERT训练时的NSP任务类似.
- Token Vector结合了上下文, 在不同的三元组中描述往往是不同的, 因此不同三元组中的相同元素能获得不同表示.
- Self - Attention很强.
作者绘制了测试集准确率随训练集数据量提升的变化曲线:
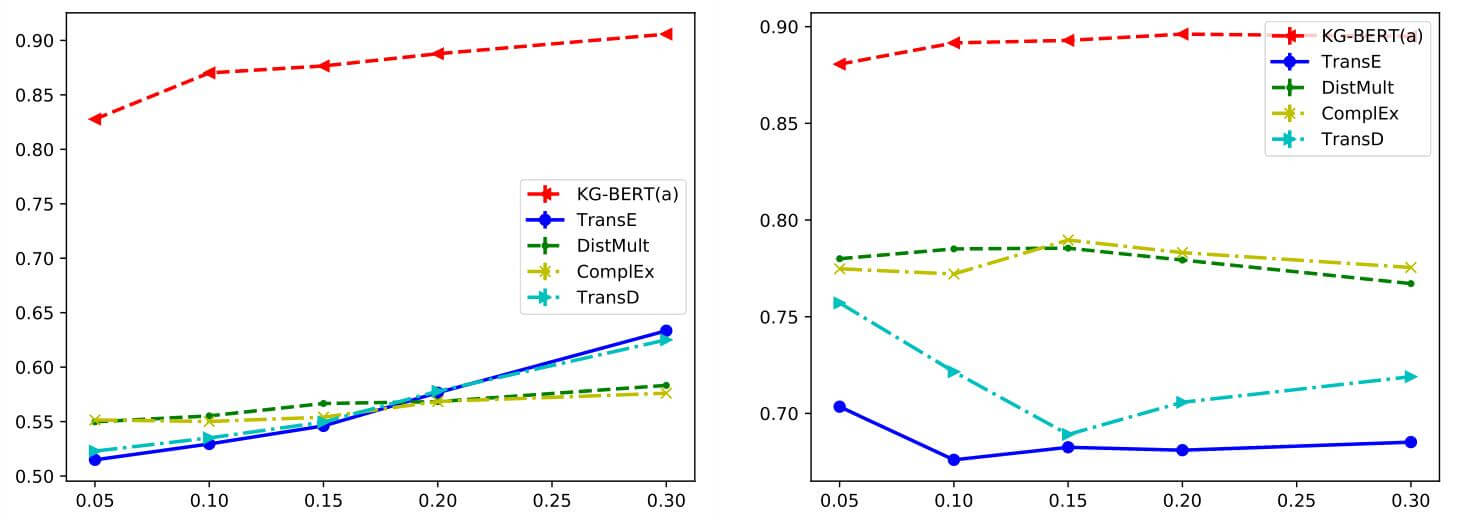
WN11(左), FB13(右). KG - BERT从开始就优于其他模型, 得益于BERT强大的特征抽取能力.
Link Prediction
在链接预测上, 作者对多种模型在WN18RR和FB15k - 237上, 以及UMLS上做了测试:
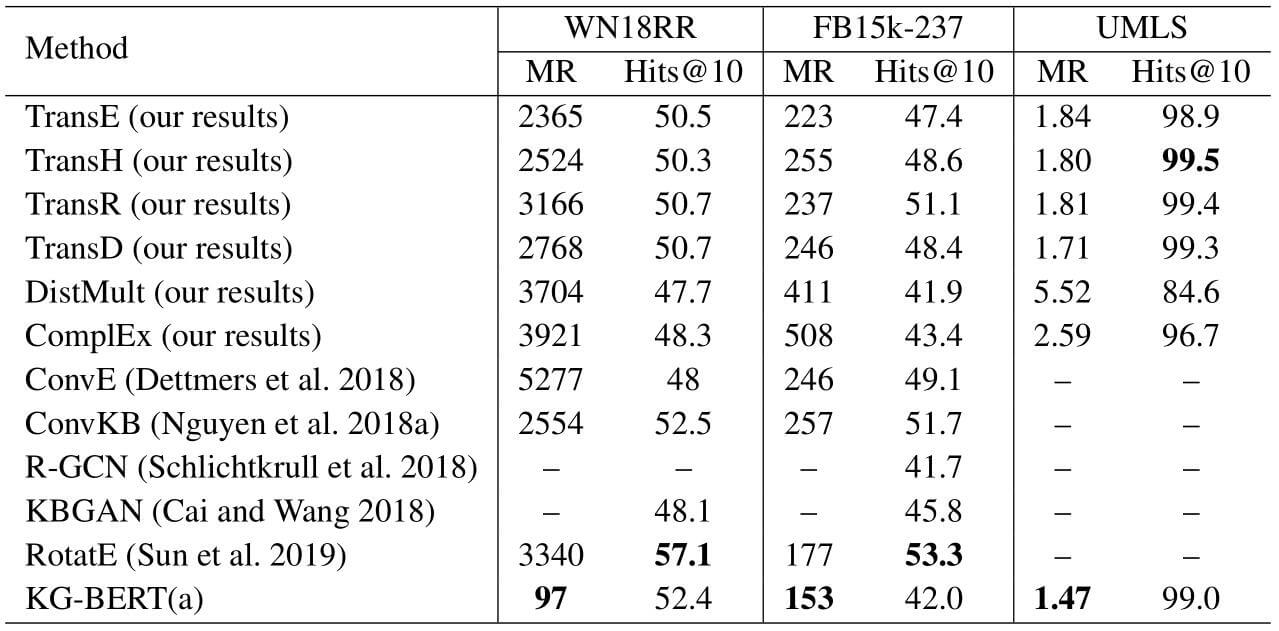
KG - BERT(a)在MR上取得了很好的效果, 但是Hits@10的表现总比MR差很多, 作者对其的解释是KG - BERT虽然能避免实体和关系相关性很强的相似三元组, 但是没有对三元组本身进行明确的建模, 因此不好给定它们的准确排名.
虽然作者在论文中没有明确写出模型输入数据的方法, 但大致能够猜到是对每个实体挨个替换实体描述.
Relation Prediction
作者在FB15k上测试了KG - BERT(b)关系预测的性能:
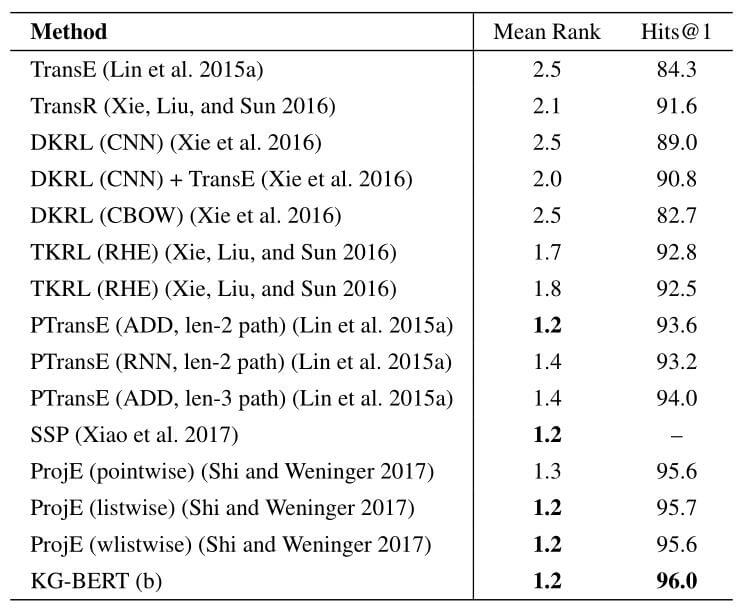
碍于打分函数和模型方法的限制, 没有Conv系列的模型登场. KG - BERT在诸多模型中取得了最好的成绩.
Attention Visualization
对注意力可视化能增强模型的可解释性, 也能一定程度上观察模型所学到的东西是否有效. 我认为这部分可以算作是本文的亮点之一.
作者从KG - BERT(a)取出第11层, 从WN18RR中取出的正例三元组(twenty dollar bill NN 1,hypernym,note NN 6)作为例子, 绘制Attention的可视化情况. 以头实体描述为a United States bill worth 20 dollars, 关系名hypernym, 尾实体描述a piece of paper money, 作为输入序列:

第11层中paper, money具有很高的权重, worth, 20 具有很低的权重. 抛开句子不谈, 模型很好的学到了[SEP]的作用, 因为它在不同的头之间多多少少分配了一些权重.
在KG - BERT(b)中, 以三元组(20th century, /time/event/includes event, World War II)为例:
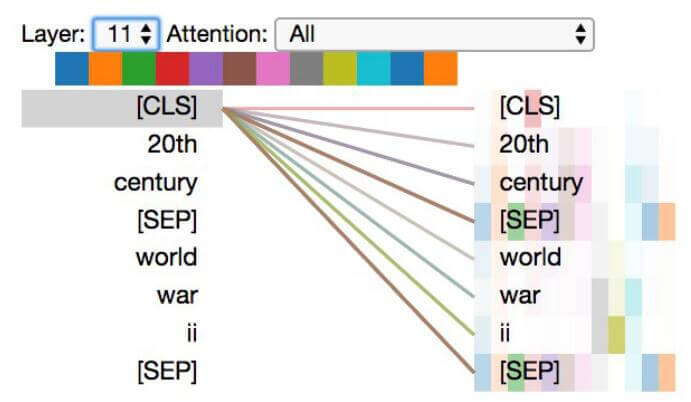
能看到b学到了类似a的模式. 但在这个例子中似乎每个头的注意力更为分散. KG - BERT(b)的目标是对实体进行关系预测, 所以对[CLS] 分配了更高的权重.
Discussions
作者提到, KG - BERT现在最大的问题还是计算成本太过高昂. 尤其是在链接预测的Evaluation时, 因为轮流替换实体描述花费了大量的时间. 作者认为可行的方法是使用像ConvE那样的1 - N Scoring或者采用更加轻量级的语言模型.
Summary
KG - BERT是BERT最早在KG上的应用. 输入数据的方式也非常的简单, 符合我们的直觉, 效果也还不错. 从现在的眼光来看, 与KG相结合的BERT最好不要再使用之前的训练方式.
缺点是没有对三元组进行直接的建模, 计算成本比较高.
只是NSP任务在BERT上已经被证明会给BERT带来副作用, 如果要沿用KG - BERT的训练方式, 就需要对NSP任务在KG - BERT上的效果进行研究, 如果去掉NSP任务需要用什么任务来代替?

