本文前置知识:
Pytorch实现: VQ - VAE
本文是VQ - VAE的Pytorch版本实现, 并做了VQ - VAE在MNIST和宝可梦重建的可视化.
本文的代码已经放到了Colab上, 打开设置GPU就可以复现(需要科学上网).
![]()
如果你不能科学上网, 应该看不到Open in Colab的图标.
Preparing
老规矩, 先导包:
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import matplotlib.pyplot as pltVQ - VAE
在VQ系列的原论文中, 通常都采用CNN Encoder和Decoder来完成图像的编码和重构. 因为CNN本身就带有空间先验和特征图下采样的功能, 比较好完成压到低维再重建的过程, 也比较有利于VQ对原图大小的压缩.
咱们这里索性丢掉大脑, 随性一点. 直接采用没有任何空间先验的MLP(一个被砍掉位置编码的Linear Patch Embedding)来实现Encoder和Decoder. 即每个Image Patch都直接被一个MLP编码为一个表示.
在实现Linear Patch Embedding时, 直接用
nn.Conv2d, 并保证kernel_size和stride都相等就可以实现, 与ViT的实现是一致的.
Encoder是一个nn.Conv2d 和一个nn.Linear, 中间随便加个nn.ReLU:
class Encoder(nn.Module):
def __init__(self, input_size, output_size, hidden_size, patch_size) -> None:
super().__init__()
self.cnn = nn.Conv2d(input_size, hidden_size, kernel_size=patch_size, stride=patch_size)
self.relu = nn.ReLU()
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.cnn(x)
x = self.relu(x)
x = self.linear(x.permute(0, 2, 3, 1)) # [b, c, h, w] -> [b, h, w, c]
return xDecoder用的则是反卷积 nn.ConvTrasnpose2d:
class Decoder(nn.Module):
def __init__(self, input_size, output_size, hidden_size, patch_size) -> None:
super().__init__()
self.cnn = nn.ConvTranspose2d(input_size, hidden_size, kernel_size=patch_size, stride=patch_size)
self.relu = nn.ReLU()
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.cnn(x)
x = self.relu(x)
x = self.linear(x.permute(0, 2, 3, 1))
return x.permute(0, 3, 1, 2)VQ - VAE则是Encoder, Decoder, Codebook三部分组成, 需要注意的点在代码下面说:
class VQVAE(nn.Module):
def __init__(self, input_size, output_size, hidden_size, codebook_size, patch_size) -> None:
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
self.codebook_size = codebook_size
self.patch_size = patch_size
self.encoder = Encoder(input_size, hidden_size, hidden_size, patch_size=patch_size)
self.decoder = Decoder(hidden_size, output_size, hidden_size, patch_size=patch_size)
self.codebook = nn.Embedding(codebook_size, hidden_size)
# init
nn.init.uniform_(
self.codebook.weight, -1.0 / self.codebook_size, 1.0 / self.codebook_size
)
def forward(self, x):
# [b, c, h, w]
batch_size = x.size(0)
z_e = self.encoder(x)
sqrt_patches = z_e.size(1)
# VQ
z_e = z_e.view(-1, self.hidden_size)
embeddings = self.get_codebook_embeddings()
nearest = torch.argmin(torch.cdist(z_e, embeddings), dim=1)
z_q = self.codebook(nearest)
# Straight - Through Estimator(STE)
decoder_input = z_e + (z_q - z_e).detach()
decoder_input = decoder_input.view(batch_size, sqrt_patches, sqrt_patches, self.hidden_size)
decoder_input = decoder_input.permute(0, 3, 1, 2)
x_hat = F.sigmoid(self.decoder(decoder_input))
return x_hat, z_e, z_q
def get_codebook_embeddings(self):
return self.codebook.weight
中间需要注意下维度变换(patch_size 用p代替):
- 原图输入
x:[b, c, h, w]. - Encoder输出
z_e:[b, h/p, w/p, c]. - VQ时用的
z_e:[bhw/(p^2), c], 因为后面要和Codebook Embedding做最近邻替换, 所以这里直接展平前三个Dim. - VQ过后的
z_q:[bhw/(p^2), c], 大小同上. decoder_input:[b, c, h/p, w/p].- 重建的
x_hat:[b, c, h, w], 与输入一样.
在forward 返回x_hat, z_e, z_q, 因为计算Loss的时候要用.
Straight - Through Estimator
这里稍微说一下STE吧:
# Straight - Through Estimator(STE)
decoder_input = z_e + (z_q - z_e).detach()从式子的形式上来看, 因为后面z_q - z_e 的部分梯度被detach掉了, 所以计算梯度时, 这个式子可以看成decoder_input = z_e. 相当于Decoder梯度复制到了Encoder一份, 但是这样做也就导致了Codebook被晾在一边了, Codebook不能通过VQ Loss来更新自己的Embedding.
所以, 特别注意: 在直接把Decoder的梯度给Encoder时(STE), 这里提供一种可能更好的实现方法, 不知道在原文中作者为什么没有使用:
# Straight - Through Estimator(STE)
decoder_input = z_q + (z_e - z_e.detach())这种方式可以让Encoder, Decoder, Codebook三者都同时训练, 因为这样做的仍然可以保证decoder_input 从数值上是z_q, 梯度同时通过z_q, z_e 同时分别回传到Codebook和Encoder.
而且也不光我发现了这个问题, 小牛组的同学也发现了这一点.
Loss
VQ - VAE文中采用的Loss:
$$
L=\underbrace{\log p\left(x \mid z_q(x)\right)}_{\text{Reconstruction}}+\underbrace{\left||\operatorname{sg}\left[z_e(x)\right]-e|\right|_2^2}_{\text{VQ}}+\beta\underbrace{\left||z_e(x)-\operatorname{sg}[e]|\right|_2^2}_{\text{Commitment}}
$$
都是MSE, 三个MSE求和即可, 需要的z_e, z_q 在forward 中都给过回传. 注意公式中的Stop Gradient Operator, 要对相应的部分detach:
criterion = nn.MSELoss()
# ......
x_hat, z_e, z_q = model(x)
recon_loss = criterion(x_hat, x)
vq_loss = criterion(z_q, z_e.detach())
commit_loss = criterion(z_e, z_q.detach())
loss = recon_loss + vq_loss + beta * commit_lossTraining
Training Loop前的一些定义, 和模型相关的参数:
hidden_size: 中间隐层大小.codebook_size: Codebook的Embedding数量.input_size: 其实就是Channel.patch_size: 每个Patch的宽和高. 比如定义为4时. MNIST输入图像的原宽高为28x28, 在VQ的时候就会有每行每列28/4=7个Patch, 一张图共7x7个Patch.
代码如下:
epochs = 200
batch_size = 256
hidden_size = 256
codebook_size = 128
input_size = 1
patch_size = 4
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lr = 1e-4
beta = 0.25
train_loader = DataLoader(
data_train, batch_size=batch_size, shuffle=True, num_workers=0
)
test_loader = DataLoader(
data_valid, batch_size=batch_size, shuffle=False, num_workers=0
)
model = VQVAE(
input_size=input_size, output_size=input_size, hidden_size=hidden_size, codebook_size=codebook_size, patch_size=patch_size
)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr)
criterion = nn.MSELoss()
valid_losses = []
train_losses = []
best_loss = 1e9
best_epoch = 0Training Loop, 采用Validation Set上Reconstruction Loss最低的作为Best Checkpoint:
for epoch in range(epochs):
print(f"Epoch {epoch}")
model.train()
train_loss = 0.0
for idx, (x, _) in enumerate(train_loader):
x = x.to(device)
current_batch = x.size(0)
x_hat, z_e, z_q = model(x)
recon_loss = criterion(x_hat, x)
vq_loss = criterion(z_q, z_e.detach())
commit_loss = criterion(z_e, z_q.detach())
loss = recon_loss + vq_loss + beta * commit_loss
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % 100 == 0:
print(
f"Training loss {loss: .3f} \t Recon {recon_loss.item(): .3f} \t VQ / Com {vq_loss.item(): .3f} \t in Step {idx}"
)
train_losses.append(train_loss / idx)
valid_loss, valid_recon, valid_vq = 0.0, 0.0, 0.0
model.eval()
with torch.no_grad():
for idx, (x, _) in enumerate(test_loader):
x = x.to(device)
current_batch = x.size(0)
x_hat, z_e, z_q = model(x)
recon_loss = criterion(x_hat, x)
vq_loss = criterion(z_q, z_e.detach())
commit_loss = criterion(z_e, z_q.detach())
loss = recon_loss + vq_loss + beta * commit_loss
valid_loss += loss.item()
valid_recon += recon_loss.item()
valid_vq += vq_loss.item()
valid_losses.append(valid_loss / idx)
print(
f"Valid loss {valid_loss: .3f} \t Recon {valid_recon: .3f} \t VQ / Com {valid_vq: .3f} in epoch {epoch}"
)
if valid_recon < best_loss:
best_loss = valid_recon
best_epoch = epoch
torch.save(model.state_dict(), "best_model_mnist")
print("Model saved")最后做下Training Loss和Validation Loss:
plt.plot(train_losses, label="Train")
plt.plot(valid_losses, label="Valid")
plt.legend()
plt.title("Learning Curve")
plt.show()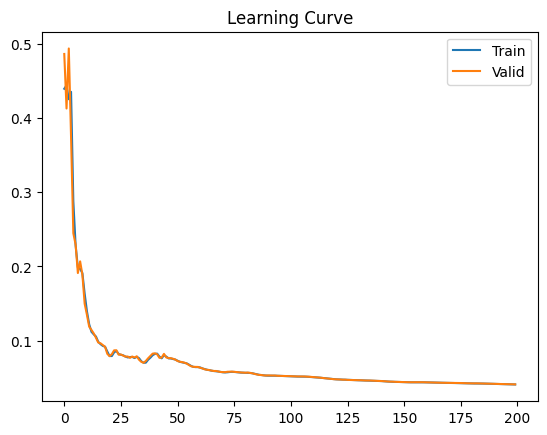
Visualization
虽然VQ - VAE不能自己生成图片, 但是我们可以做重构手写数字与输入原图的对比:
imgs = []
batch_size = 10
test_loader = DataLoader(data_valid, batch_size=batch_size, shuffle=True, num_workers=0)
model.load_state_dict(torch.load("./best_model_mnist"))
model.to(device)
with torch.no_grad():
model.eval()
for idx, (x, _) in enumerate(test_loader):
if idx == 10:
break
x = x.to(device)
x_org = x
x_hat, z_e, z_q = model(x)
imgs.append(x_org)
imgs.append(x_hat)
res = torchvision.utils.make_grid(torch.cat(imgs, dim=0), nrow=batch_size)
img = torchvision.transforms.ToPILImage()(res)
img.show()奇数行为输入的原图, 偶数行为VQ - VAE重构出来的图片, 这是Colab里生成的:

我自己本地跑的:

感觉生成的效果其实还不错, 有些地方其实能看到Patch的白线.
其实, 还可以看Codebook Embedding都学到了什么先验, 只需要把Embedding拿出来放到模型, 让Decoder重构即可:
with torch.no_grad():
model.eval()
decoder_input = model.get_codebook_embeddings().data[:, :, None, None]
x_hat = torch.nn.functional.sigmoid(model.decoder(decoder_input))
res = torchvision.utils.make_grid(x_hat,nrow=batch_size)
img = torchvision.transforms.ToPILImage()(res)
img.show()
每个Code都是原图中按Patch划分的小细节, 有些是灰色的, 看起来这些应该是冗余的Code, 几乎不会用到重构当中, 所以我们的codebook_size 对于MNIST来说设的有点大了.
Pokemon!
延续传统的番外篇, 与我们在Pytorch实现: VAE中做的事情相同, 这里向RGB三通道的数据继续探索, 很多代码都是重复的.
每个人都想做从零开始的宝可梦训练大师! 在李宏毅老师的课程中层提到过生成神奇宝贝的事情. 下面就来尝试下. 数据集下载点我, 原始数据大小为(3, 40, 40). 本节代码没有放到Colab上, 与在MNIST上的过程大同小异, 感兴趣可以自己尝试.
懒得改模型了, 还是采用被砍位置编码的Linear Patch MLP作为Encoder / Decoder的 Encoding / Reconstruction结构, 即便相较于有空间先验的CNN来说还是略烂一点.
老规矩, 先导包:
import os
import random
from PIL import Image
import torch
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt定义一个宝可梦数据集, 只是存放图片路径, 并对transforms的一个封装, 转PIL.Image 和转Tensor 的活都交给他来干:
class Pokemon(Dataset):
def __init__(self, image_paths, transform=None):
super(Pokemon, self).__init__()
self.image_paths = image_paths
if transform is not None:
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, item):
return self.transform(self.image_paths[item])随机打乱宝可梦图片路径, 切分为Training Set和Validation Set:
root = "./pokemon"
image_paths = [os.path.join(root, x) for x in os.listdir(root)]
random.shuffle(image_paths)
train_image_paths = image_paths[: int(0.8 * len(image_paths))]
valid_image_paths = image_paths[int(0.8 * len(image_paths)): ]
pokemon_train = Pokemon(train_image_paths, transform=transform)
pokemon_valid = Pokemon(valid_image_paths, transform=transform)然后就是定义一些训练前的参:
epochs = 1000
batch_size = 128
hidden_size = 256
codebook_size = 128
input_size = 3
patch_size = 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lr = 1e-3
beta = 0.25
transforms = transforms.Compose([
lambda x: Image.open(x).convert("RGB"),
transforms.ToTensor(),
])
data_train = Pokemon(train_image_paths, transform=transforms)
data_valid = Pokemon(valid_image_paths, transform=transforms)
train_loader = DataLoader(
data_train, batch_size=batch_size, shuffle=True, num_workers=0
)
test_loader = DataLoader(
data_valid, batch_size=batch_size, shuffle=False, num_workers=0
)
model = VQVAE(
input_size=input_size, output_size=input_size, hidden_size=hidden_size, codebook_size=codebook_size, patch_size=patch_size
)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr)
criterion = nn.MSELoss()因为是三通道数据嘛, 这里给了更多的训练时长, lr 也拉得更大了. input_size 需要调整为3, patch_size 的粒度调的比较细, 每个Patch大小为2x2, 这样一张宝可梦图片由(40/2)^2=400 个Patch(在我们的模型中Patch也是Code)组成, 相较于原来的1600像素点压缩了4倍.
Training Loop也和上面基本一样, 几乎把MNIST代码拿过来就能用了, 宝可梦数据集没有标签, 所以只改了一点点:
for epoch in range(epochs):
# ......
for idx, x in enumerate(train_loader):
x = x.to(device)
# ......
with torch.no_grad():
for idx, x in enumerate(test_loader):
x = x.to(device)
# ......最后也用和MNIST一样的代码把重建结果画出来:
with torch.no_grad():
model.eval()
for idx, x in enumerate(test_loader):
if idx == 10:
break
x = x.to(device)
x_org = x
x_hat, z_e, z_q = model(x)
imgs.append(x_org)
imgs.append(x_hat)
res = torchvision.utils.make_grid(torch.cat(imgs, dim=0), nrow=batch_size)
img = torchvision.transforms.ToPILImage(mode="RGB")(res)
img.show()


能看到, 虽然颜色上和原图有一点差别, 轮廓和结构大差不差都学的差不多了, 而且还挺清晰的. 数据集本身也比较小, 有些小细节非常难学到. 里面有很多老朋友… 整体表现其实还是挺好的.
同样, 看下每个Codebook Embedding都学到了什么:
with torch.no_grad():
model.eval()
decoder_input = model.get_codebook_embeddings().data[:, :, None, None]
x_hat = torch.nn.functional.sigmoid(model.decoder(decoder_input))
res = torchvision.utils.make_grid(x_hat,nrow=batch_size)
img = torchvision.transforms.ToPILImage(mode="RGB")(res)
img.show()基本就是一些图中像素组合的模式:

我也尝试了patch_size 为4, codebook_size 为256时的组合, 而且学习时间要更长, 但是效果不太好, 这很合理:
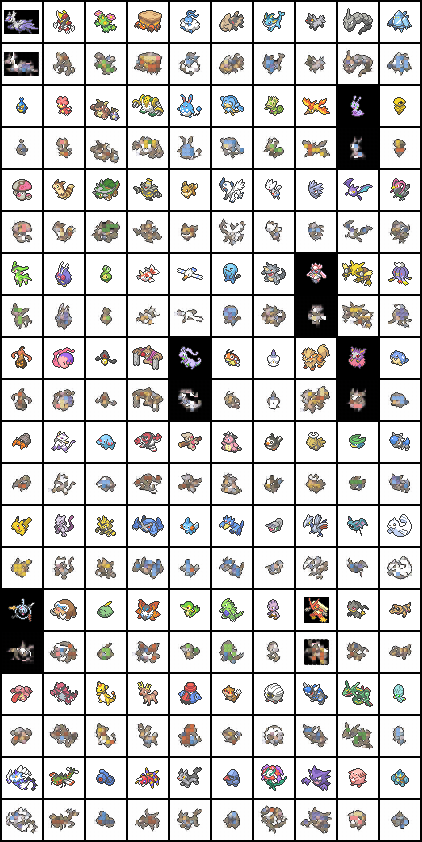
学到的Code:

显然, 此时由于Patch粒度太粗, 以及Decoder结构过于简单, 且没有任何先验, 模型的重建能力还是比较差的, 但是一个大概的轮廓还是能学出来的, 只是每个Patch重建的细节不够好. 毕竟我们的Decoder不像Stable Diffusion的Decoder一样强大嘛.

