Relational Triple Extraction: One Step is Enough
本文是论文Relational Triple Extraction: One Step is Enough 的阅读笔记和个人理解, 论文来自IJCAI 2022.
Basic Idea
作者认为当前的RTE方法大多包含两步, 首先抽取出头尾实体的边界位置, 然后再把它们转化成三元组. 作者认为大多数的方法仍然存在误差累计的问题, 比如头 / 尾实体边界的识别错误会影响最终生成的三元组.
因此, 作者希望提出一个非常简单的单步抽取模型来解决误差累计. 具体的, 作者希望从句子中生成候选实体, 并从二部图链接的视角来描述头实体到尾实体的链接过程, 这样逻辑上只有一步, 如下图所示:
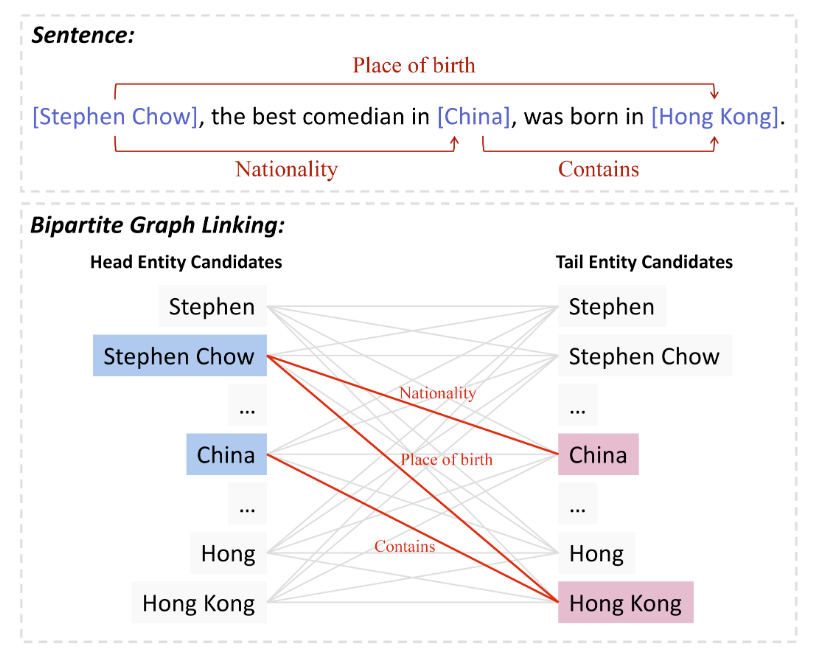
从图中可以看出, 作者通过穷举Span的方式构造了大量的候选实体, 并在它们之间做二部图链接, 以形成三元组.
其实就是用穷举Span把实体边界抽取绕开了, 直接做实体之间的链接.
DirectRel
DirectRel的模型设计是十分简单的:
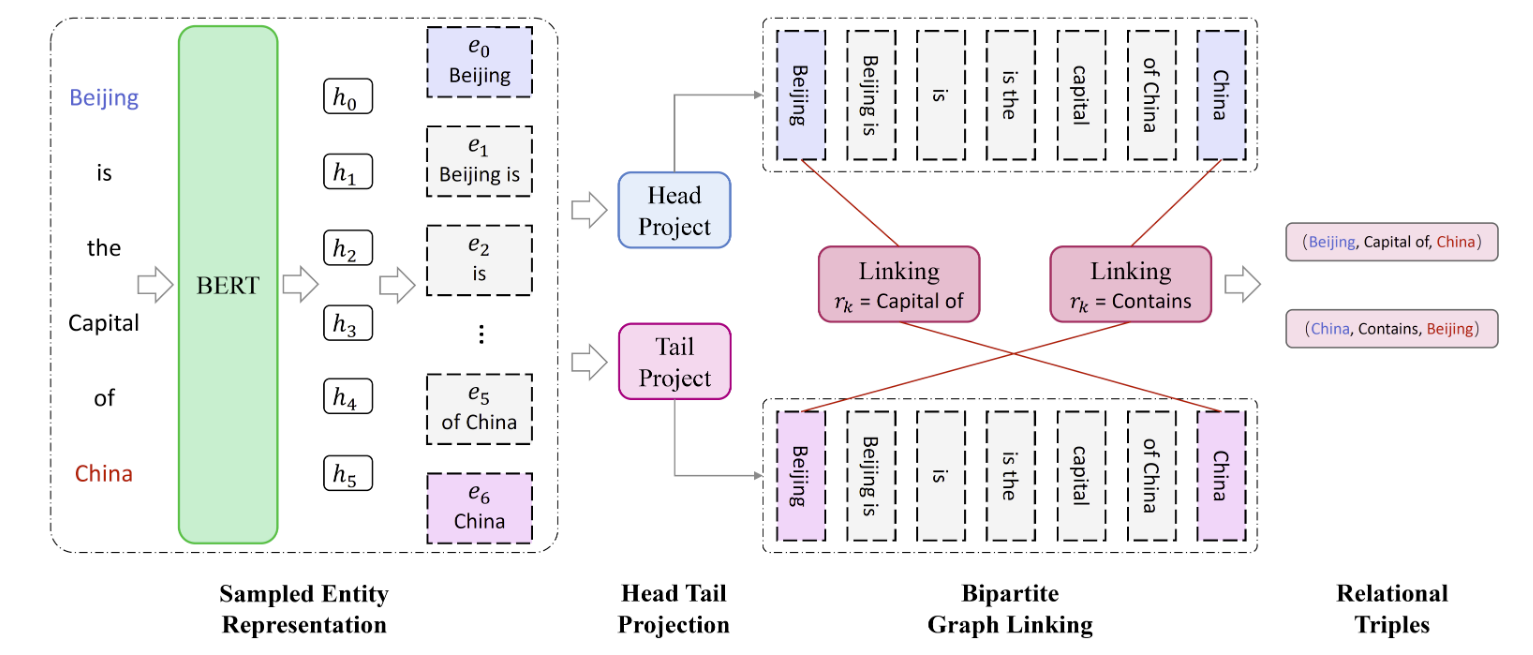
从图上来看, 先生成实体表示, 然后把实体表示分别投影到Subject和Object的空间, 接着对两个空间内的实体表示做二部图匹配, 从而构造出三元组. 图中展示了一种EPO的情况, 即使头尾实体相同, 也是可以抽取出来的.
Task Definition
对于给定的$L$ 个Token的句子$\mathcal{S}=\set{w_1, w_2, \dots, w_l}$ 以及$K$ 个已经定义好的关系$\mathcal{R}=\set{r_{1}, r_{2}, \cdots, r_K}$, RTE的目标为识别出句子$\mathcal{S}$ 中的所有$N$ 个三元组$\mathcal{T}=\left\{\left(h, r, t\right)|h,t\in \hat{\mathcal{E}}, r \in \mathcal{R}\right\}$, $\hat{\mathcal{E}}$ 为三元组中的头尾实体, 而不是句子中出现的所有命名实体.
Candidate Entities Generation
在预处理时, 作者穷举出所有长度小于$C (C<L)$ 的连续的Token Span作为候选实体. 例如, $C=2$ 时, 句子”Beijing is the capital of China”的候选实体为$\mathcal{E}$={“Beijing”, “Beijing is”, “is”, “is the”, “the”, “the Capital”, “Capital”, “Capital of”, “of”, “of China”, “China”}.
如果句子有$L$ 个Token, 那么候选实体数量为$|\mathcal{E}|$:
$$
|\mathcal{E}|=L \times C+\frac{C}{2}-\frac{C^2}{2}
$$
作者注意到, 这样做会不可避免的引入过多的负样本候选实体, 并带来非常大的计算开销. 因此, 作者只从生成的所有候选实体$\mathcal{E}$ 中随机采样出$n_{neg}$ 个负样本实体, 和三元组Ground Truth中的正样本实体构成新的子集$\overline{\mathcal{E}}$ 作为训练中的候选实体集.
作者在实验中设置负样本候选实体个数为100.
采样仍然不能解决推理过程中的计算开销问题, 只能加速训练过程并解决正负样本不均衡的问题.
Bipartite Graph Linking
对于给定的句子以及其候选实体$\overline{\mathcal{E}}$ , 使用BERT来抽取句子中Token的特征$\boldsymbol{h}_{i}\in \mathbb{R}^d$:
$$
\left[\boldsymbol{h}_1, \boldsymbol{h}_2, \ldots, \boldsymbol{h}_L\right]=B E R T\left(\left[\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_L\right]\right)
$$
其中$\boldsymbol{x}_i$ 为输入句子中第$i$ 个Token的表示.
为了将候选实体表示出来, 作者简单的采用候选实体的起始Token和结束Token的平均来作为候选实体表示$\boldsymbol{e}_i$:
$$
\boldsymbol{e}_i=\frac{\boldsymbol{h}^{\text {start }}+\boldsymbol{h}^{e n d}}{2}
$$
接着, 将所有实体表示$\boldsymbol{E}$ 投影到头尾实体的语义空间里, 可以由两个线性层拿到:
$$
\begin{aligned}
\boldsymbol{E}_{\text {head }} &= \boldsymbol{W}^{T}_{h}\boldsymbol{E}+ \boldsymbol{b}_{h}\\
\boldsymbol{E}_{\text {tail }} &= \boldsymbol{W}^{T}_{t}\boldsymbol{E}+ \boldsymbol{b}_{t}
\end{aligned}
$$
其中, $\boldsymbol{W}_h, \boldsymbol{W}_{t} \in \mathbb{R}^{d_{e}\times d}, \boldsymbol{b}_{h,}\boldsymbol{b}_t$ 为可训练参数.
然后直接就做Subject和Object的二部图链接, 预测出头实体和尾实体在关系$k$ 下链接存在的概率:
$$
\boldsymbol{P}^k=\sigma\left(\boldsymbol{E}_{\text {head }}^T \boldsymbol{U}_k \boldsymbol{E}_{\text {tail }}\right)
$$
其中, $\sigma$ 为Sigmoid激活函数, $\boldsymbol{U}_{k} \in \mathbb{R} ^ {d_{e}\times d_e}$ 为关系$k$ 特化的矩阵. 当三元组$\boldsymbol{P}^k_{ij}$ 成立的概率大于阈值$\theta$ 时, 则构成一个三元组.
这样引入双线性的缺点就是, 每种关系都会带来一个大小为$\boldsymbol{U}_{k} \in \mathbb{R} ^ {d_{e}\times d_e}$ 的矩阵, 在WebNLG中关系比较多, 双线性矩阵就会非常多.
Objective Function
因为作者用的是二部图匹配, 所以损失函数用的是二分类交叉熵:
$$
\mathcal{L}=-\frac{1}{|\overline{\mathcal{E}}| \times K \times|\overline{\mathcal{E}}|} \times
\sum_{i=1}^{|\overline{\mathcal{E}}|} \sum_{k=1}^K \sum_{j=1}^{|\overline{\mathcal{E}}|}\left(y_t \log \left(\boldsymbol{P}_{i j}^k\right)+\left(1-y_t\right) \log \left(1-\boldsymbol{P}_{i j}^k\right)\right)
$$
其中, $|\overline{\mathcal{E}}|$ 为训练中使用的实体数量, $K$ 为预定义好的关系数量, $y_t$ 为三元组$(e_{i,}r_{k,}e_{j})$ 的Golden Label.
Experiments
详细的实验设置请参照原论文.
Datasets
仍然是选用NYT, WebNLG的精准匹配版本以及其部分匹配版本NYT*, WebNLG*作为数据集, 统计信息如下:
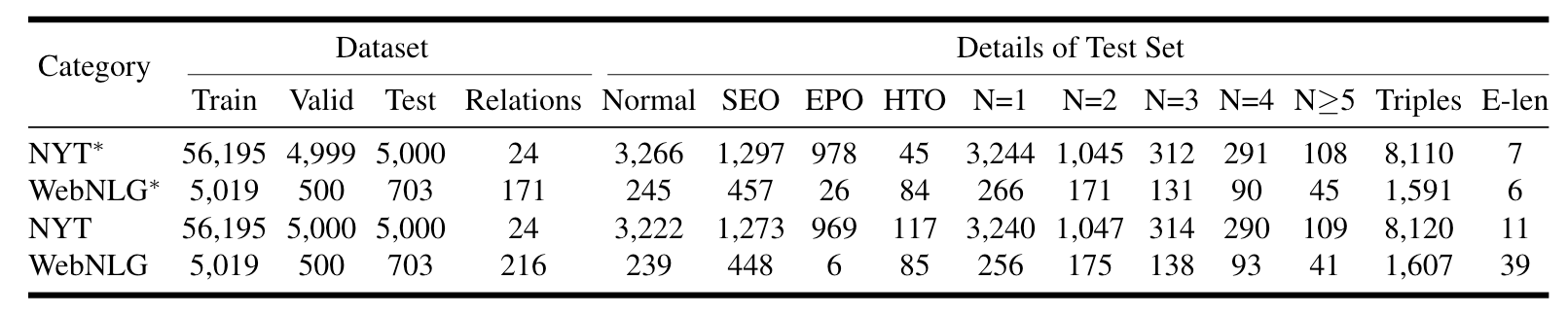
作者额外添加了一个实体长度的统计, WebNLG里面的实体长度似乎有些很长.
Main Results
在上述数据集上, DirectRel实验结果如下:
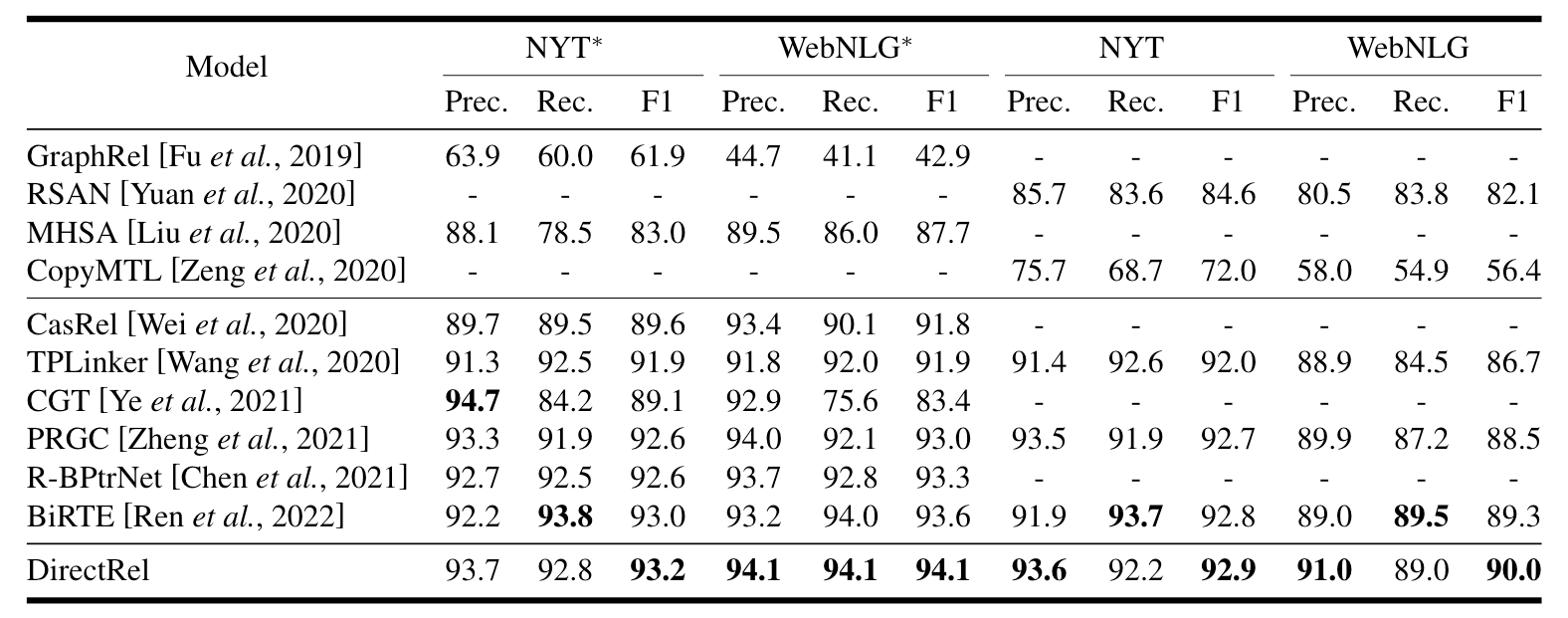
DirectRel在Baseline里面达到了SOTA, 在NYT上领先不是很多.
Detailed Results on Complex Scenarios
DirectRel在不同类型三元组的表现如下:
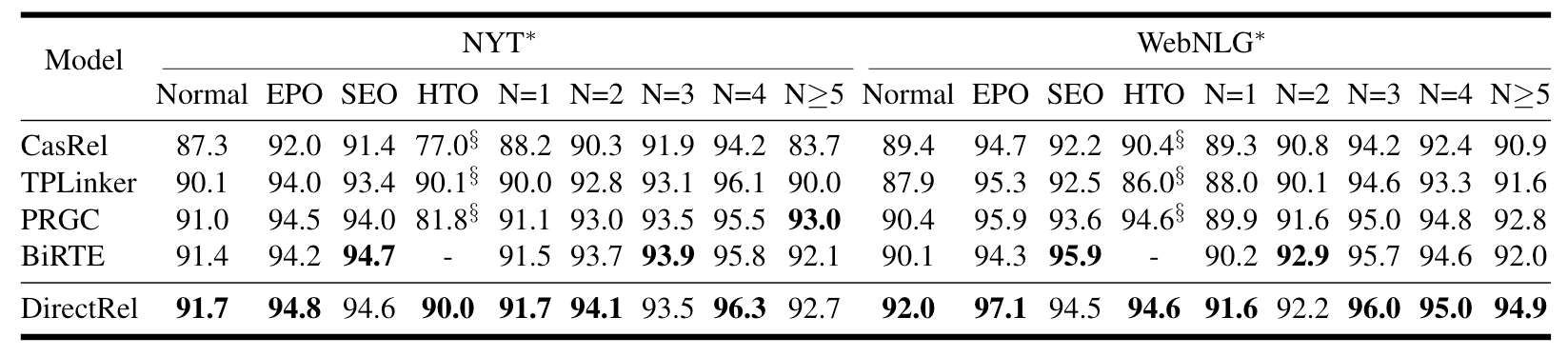
DirectRel似乎对SEO的处理要略差一点, 说明DirectRel处理一对多的三元组能力差一点. 它其他的都还不错.
Results on Different Sub - tasks
不同子任务上, DirectRel结果如下:
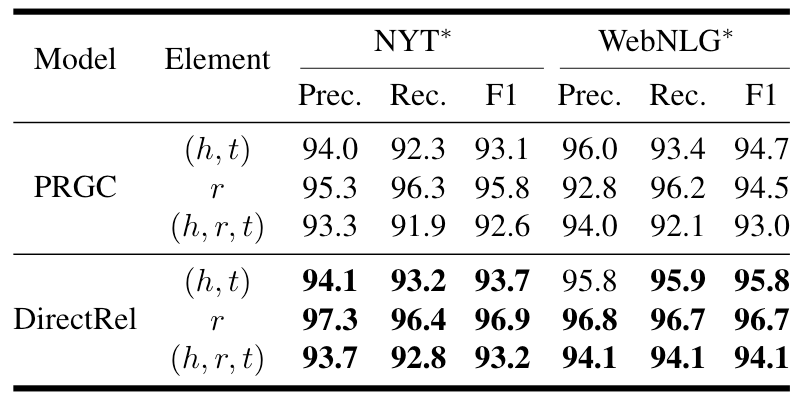
这里主要是为了证明单阶段抽取效果, 和PRGC比了一下, DirectRel是全面领先的(其实和其他Baseline比也一样).
Parameter Analysis
为了证明随机采样候选实体的好处, 作者做了采样数量关于每个Batch训练时间, GPU显存占用, 性能的变化曲线(从左至右):
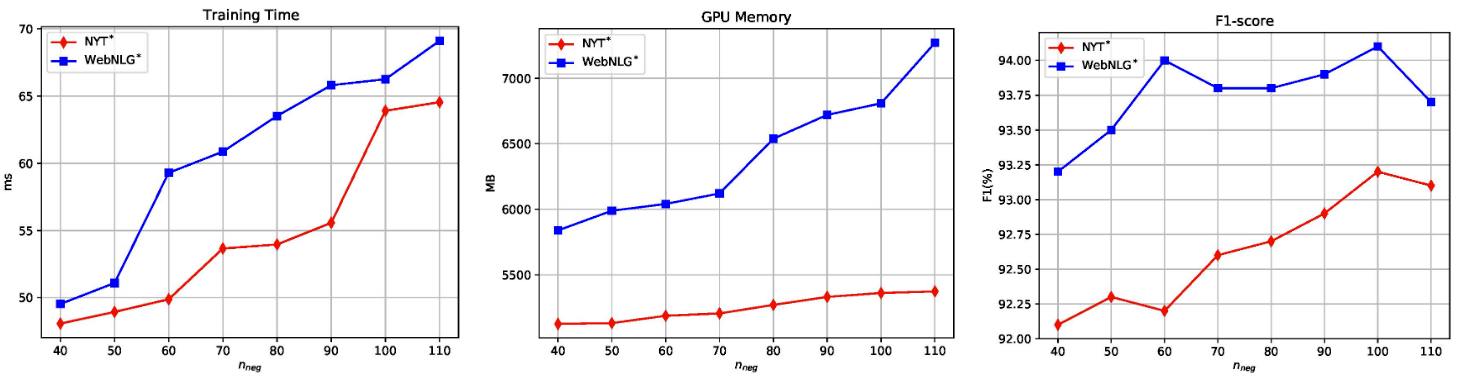
随着采样数量增大, 训练时间边长, 显存占用变大, 但性能也是随之增大的, 到100左右不再增长.
训练速度在3090上看起来还是挺快的, 粗略的算了一下在WebNLG上跑完也就需要三个多小时.
Error Analysis
作者分析了测试集中DirectRel的实体识别错误类型, 分为Span分割错误, 实体未找到, 和实体角色错误:

可以看到, 最大一部分错误来源是实体角色错误, 也就是说头尾实体可能搞反了.
Summary
事实上DirectRel和OneRel出自同一个组, 这两篇文章的风格如出一辙, 基于简单的出发点, 提出简单的模型, 单阶段抽取, 然后从效率和性能两个方面论述模型的优点. 我推荐把OneRel也顺手看一看.
无论是OneRel还是DirectRel, 它们的本质仍然是一种填表的方法, 所以还是单阶段了, 但是没有很单阶段.
模型本身非常简单, 论文写作技巧上还是非常值得学习的.

