Can We Predict New Facts with Open Knowledge Graph Embeddings? A Benchmark for Open Link Prediction
本文是论文Can We Predict New Facts with Open Knowledge Graph Embeddings? A Benchmark for Open Link Prediction的阅读笔记和个人理解.
Basic Idea
作者指出, 虽然人们已经在特定领域的知识图谱上取得了成功, 但先前的方法都不是基于开放域的.
作者希望探讨是否有可能从开放知识图谱中通过非规范化的文本直接推断出新的事实, 即能否依据原始文本完成开放域的Link Prediction.
Open Knowledge Graph
开放知识图谱的三元组经常由文本三元组组成, 即$(\text { subject text, relation text, object text) }$, 由于文本信息非常嘈杂, 其中含有很多噪声, 因此同一种关系或者实体对应着非常多种不同的文本表述:
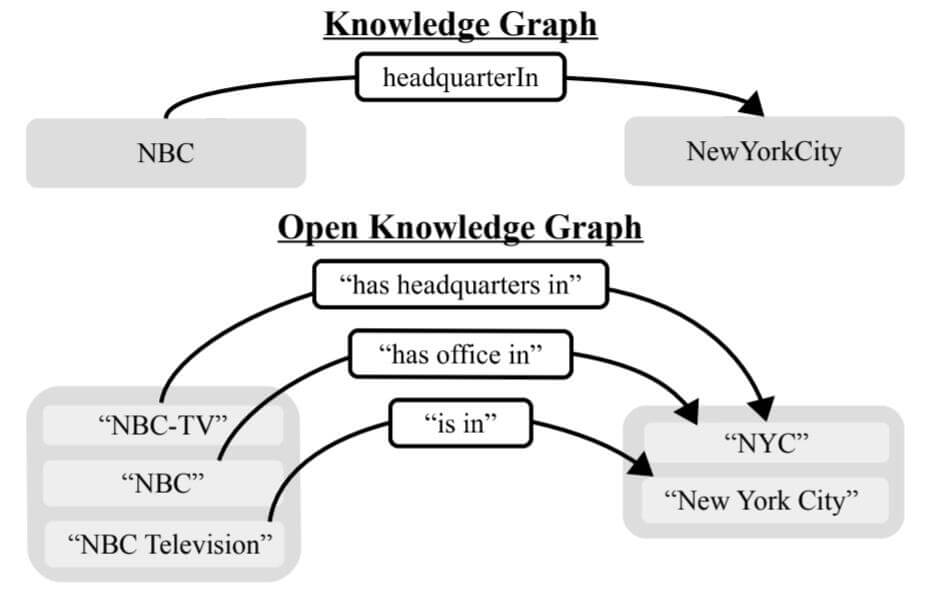
例如, NBC这一实体可能对应着{NBC - TV, NBC, NBC Television}这一实体集合.
对于同一实体的不同自然语言表述在原文中似乎被称为是Entity Mention, 但我没想好到底翻译成什么, 暂称实体集合或实体提及.
能看到, 因为使用自然语言文本来表示三元组, 导致实体和关系非常不规范. 但是Open KG中通常包括着更多的文字表述, 也可以被捕获更多的信息.
Open KG不直接编码知识, 即使在文字描述中已经给出了实体本身, 在其中还可能含有大量的概念化知识.
在OKG中, 其结构应该是能自动构建的, 因为其涉及到自然语言的复杂性, 应该不需要实体和关系的词表.
Open Link Prediction
Link Prediction
Link Prediction在一般的KG中经常被用于测试模型的推断能力.
假设$\mathcal{E}$ 是实体$i, j$ 的集合, $\mathcal{R}$ 是关系$k$ 的集合, 那么知识图谱$\mathcal{T} \subseteq \mathcal{E} \times \mathcal{R} \times \mathcal{E}$. 如果从QA的角度来考虑, 查询头实体$i$ 和尾实体$j$ 的问题就分别被描述为$q_{h}=(?, k, j)$ 和 $q_{t}=(i, k, ?)$. 并且, 它们可能分别在训练集中单独出现过, 但并未以三元组的的形式一起出现.
例如(NBC, headquarterIn, ?), 就是在询问NBC在哪个地方设立了总部.
Open Link Prediction
Difference Between LP and OLP
在开放域知识图谱中, Link Prediction相应的被转化为Open Link Prediction:
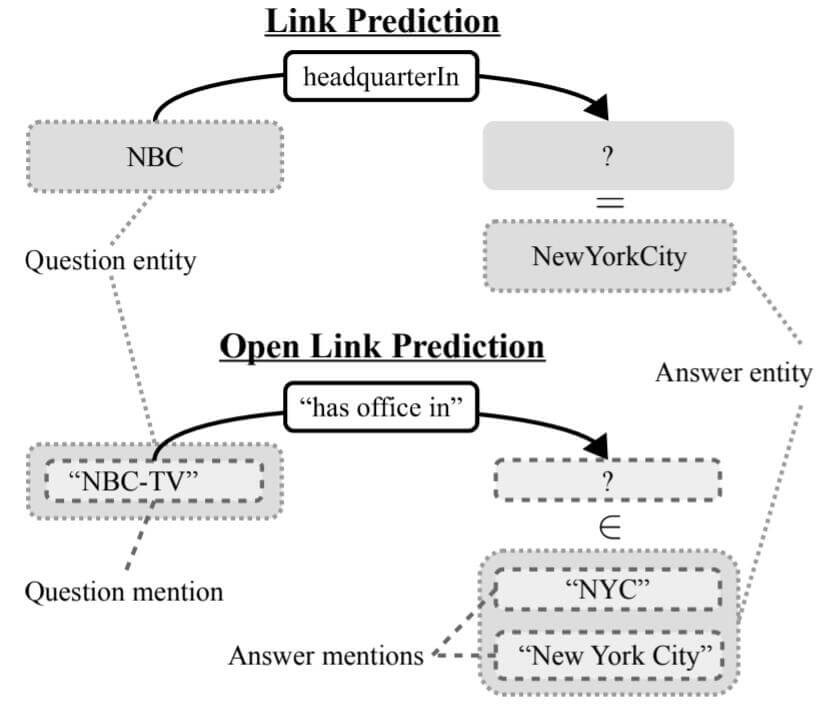
由于OKG自身的特性, 实体和关系被转化为实体提及(Entity Mention)和开放关系(Open Relation). 如果对应到QA中, 问题和答案可能都会有多种不同的表述. 甚至对于不同时间点, 对于同一实体都会产生不同的表述.
作者将每个实体提及和开放关系以非空的Token序列对待, 记Token的词表为$\mathcal{V}$. 记开放集$\mathcal{M}=\mathcal{V^+}$, 代表OKG中所观察到的元素集合, 即实体提及$i,j \in \mathcal{M}(\mathcal{E})$ 和开放关系$k \in \mathcal{M}(\mathcal{R})$. 故$\mathcal{T} \subset \mathcal{M} \times \mathcal{M} \times \mathcal{M}$.
在OLP中, 其任务目标是预测新且正确的问题$(i, k, ?)$ 或 $(?, k, j)$ 的答案. 答案来自于$\mathcal{M}(\mathcal{E})$, 但问题可能来自于$\mathcal{M}$ 中的任意的实体提及和开放关系.
例如, 对于问题("NBC - TV", "has office in ", ?), 我们想要的答案是的NewYorkCity的实体提及{"New York", "NYC", ...}中的任意一条表述.
Evaluation Protocol
KGs and Entity Ranking
先回顾一下在普通KG模型在Link Prediction中的实体排名规则.
对于三元组$z=(i, j, k)$, 模型对问题$q_{h}(z)=(?, k, j)$ 或$q_{t}(z)=(i, k, ?)$ 进行排名时, 有两种设置:
- Raw: 直接依据于正确的实体$j$ 或 $i$ 的排名.
- Filtered: 依据于$q_t(z)$ 或 $q_h(z)$ 只保留正确答案$j$ 或 $i$ 的排名. 即滤去了除$j$ 和$i$ 外的其他所有正确答案后的排名.
OKGs and Mention Ranking
出于在OKG中所出现的种种的问题, 作者将一般KG中评估用的协议改进到了OKG中.
在OKG中, 问题可能会有多个等价的正确答案, 所以一定要考虑答案的实体提及. 相同的, 作者对OLP也提出两种设置:
- Raw: 依据于正确答案提及的最高排名.
- Filtered: 滤去评估实体外其余正确答案后的所有实体提及, 然后再在评估实体的提及中选择最高排名.
作者将上述流程用下图来概括:
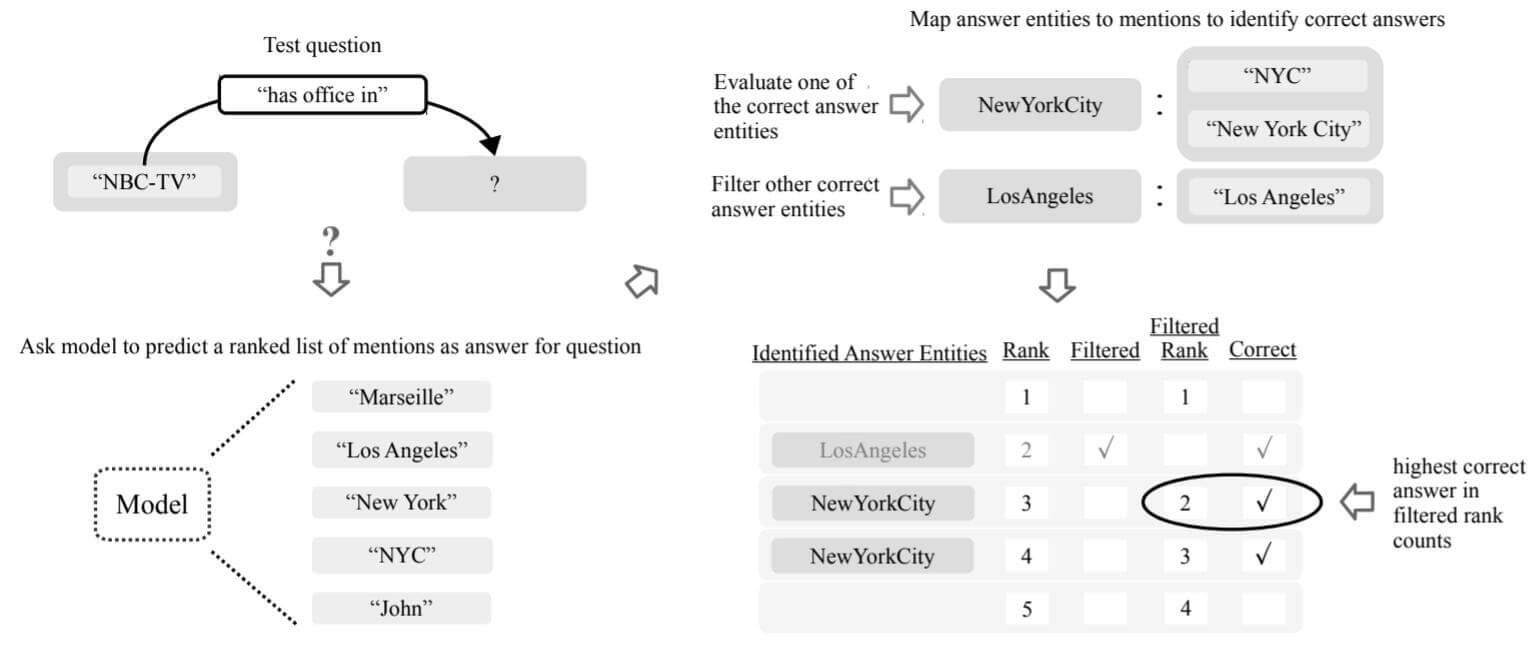
- 对于给定的问题, 对所有答案的实体提及进行排名.
- 将除评估实体外的其余正确答案的所有实体提及从排名中过滤掉, 并将其标记为”filtered”.
- 选择评估实体的提及中排名最高的作为其排名.
综上, 根据作者提出的协议, 我们在评估时需要以下两方面数据准备:
- 问题的正确实体提及的标注数据.
- 同一个实体的所有实体提及.
根据这两个要求, 作者接下来自制了所需的数据集.
Creating the Open Link Prediction DataSet
在OKG中, 经常伴随着Test Leakage, 因此模型能够毫不费力的推断出真正的事实. 因此, 验证集和测试集的数据必须精心准备, 否则将出现模型能力的误判. 所以作者需要自己按照需求制作OLP的数据集.
Source DataSet
OLPBENCH是基于OPIEC的创建的.
三元组从维基百科抽取的过程如下所示:

借助维基百科的超链接, 直接就完成了实体消歧, 即直接生成实体的所有实体提及.
作者将实体链接前后的数据展示在表中, 以方便大家了解这个过程:

在没有实体链接前, 实体的表述是不规范的, 关系表述也是不规范的. 在链接后, 生成了实体到提及之间的映射, 实体被唯一的确定了下来.
Evaluation data
作者认为, 验证集和测试集的数据需要满足很多严格的要求, 以此来解决OKG中出现的问题.
Data Quality
评估数据可能是非常具有挑战性的, 因为其中含有非常多的噪声.
作者非常简单的通过规则来筛选关系. 不考虑长度小于3个Token的关系, 理由如下:
- 短关系通常是长关系的一部分.
- 长关系更难以被普通的KG构建方法所捕捉
- 使用短关系抽取的实体注释噪声经常更多.
Human Effort for Data Creation
在Mention Ranking Protocol中, 作者引入了实体相关的知识来完成实体消歧的工作, 作者希望评估引入实体知识对模型选择的作用, 因此作者按照人工干预的程度对测试集和验证集进行划分, 并探究在它们基础上选择模型后的模型表现. 人工干预越多, 引入的实体知识就越多.
作者将验证集划分为以下三种:
- Test and Valid - Linked data: 绝大多数都是人工制造的, 能根据实体提及找到正确的实体. 并可以使用Mention Ranking Protocol.
- Valid - Mention data: 引入了一部分人工. 没有使用实体链接, 但保证了数据与测试数据的相同分布. 如果目标领域可以使用NER的话, 验证集可能会自动通过NER生成.
- Valid - All data: 没有人工干预. 基本维持了原始文本的样子.
Training Data
在普通的KG中, 人们经常通过删除逆关系来解决Test Leakage. 但在Open KG中, 因为自然文本的嘈杂, 更有可能通过文本中所包含的内容导致Test Leakage.
这种Leakage会导致数据集的制作和划分更加困难, 在评估模型时, 还需要某种方法判断模型是否在真正推断信息. 因此, 作者想更深入的量化在验证集中到底有多少问题能够不通过整个问题的信息来回答, 即只给出头实体或者关系是否能成功预测尾实体. 在不借助整个问题信息来回答问题时, 往往是借助统计信息来回答的, 即只回答最常共现的答案, 而不是真正在做推断.
例如:
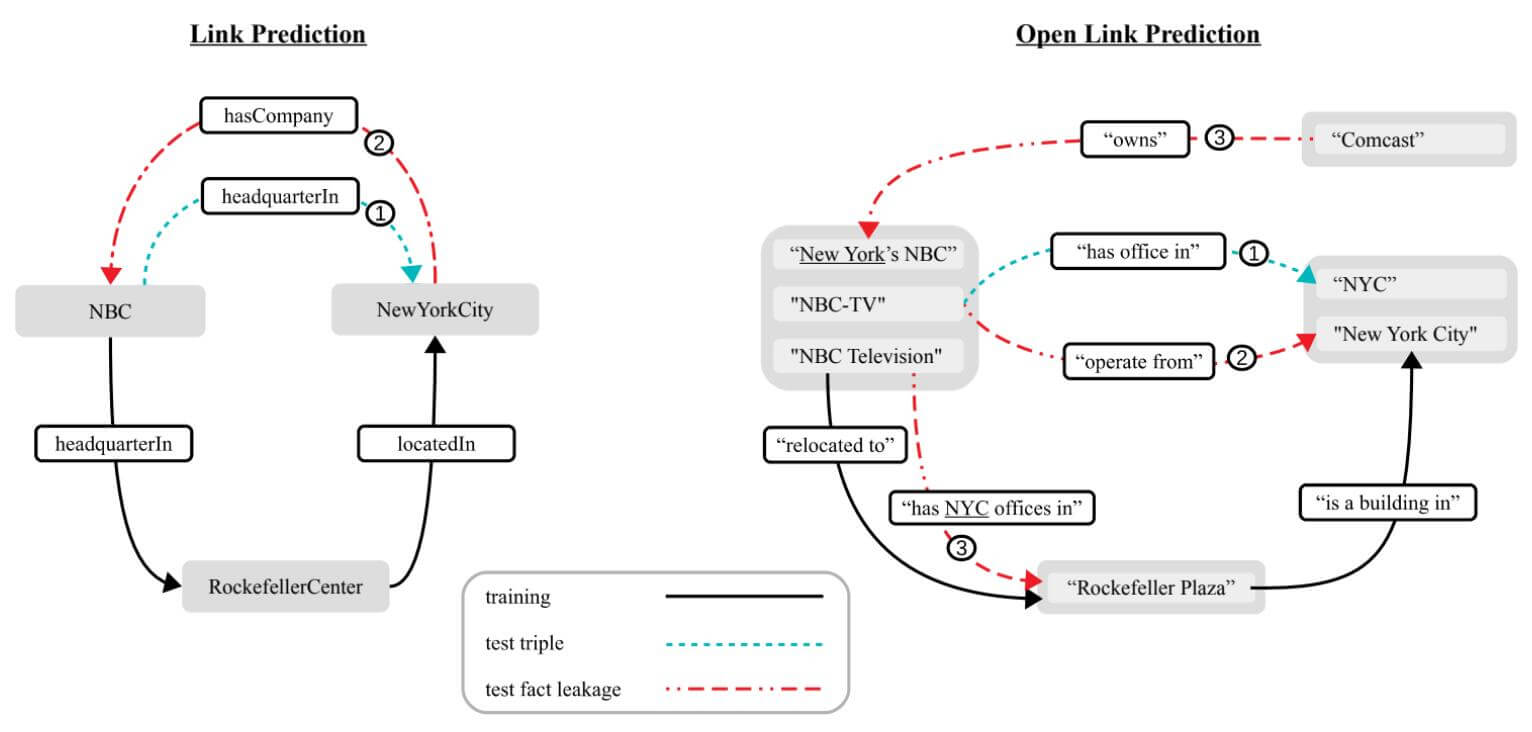
图中左侧为传统KG中的Test Leakage, 逆关系②hasCompany, 模型通常能够很容易的利用其信息建立与①headquaterIn 的联系, 从而不加推断的给出答案.
图中右侧为OKG中的Test Leakage, 图中①和②直接就是相同的关系描述, 当然会导致Leakage. 而最上方③中的尾实体描述New York's NBC 也会导致①的Leakage. 最下方③的开放关系描述也会导致相同的Leakage.
作者尝试对OKG上的训练集移除Leakage划分了三种等级:
Simple Removal: 仅仅删除三元组$(i, k, j)$, 而三元组中的$i$ 和 $j$ 的提及全部被保留.
Basic Removal: 删除三元组$(i, k, j)$ 和三元组$(j, k ,i)$, 并删除$i$ 和$j$ 的所有提及.
Thorough Removal: 在BASIC Removal的基础上, 额外按照以下规则移除三元组:
- $(i, \ast, j)$ 和 $(j, \ast, i)$.
- $(i, k +j, \ast)$ 和 $(\ast, k+i, j)$.
- $(i+k+j, \ast, \ast)$ 和 $(\ast, \ast, i+k+j)$.
基于规则移除更多的从自然语言的角度考虑了更严格的移除方式.
Open Knowledge Graph Embeddings
作者提出了一种用于开放知识图谱的KGE方法, 以便评估不同设定对模型所带来的影响.
因为开放知识图谱中实体和关系的多重表述性, 必须对实体和关系进行Token Level Modeling, 这样才能保证模型能处理任何长度的实体和关系输入. 我们默认Token以Token Embedding作为输入.
作者将模型分为关系模型和组合函数两部分:
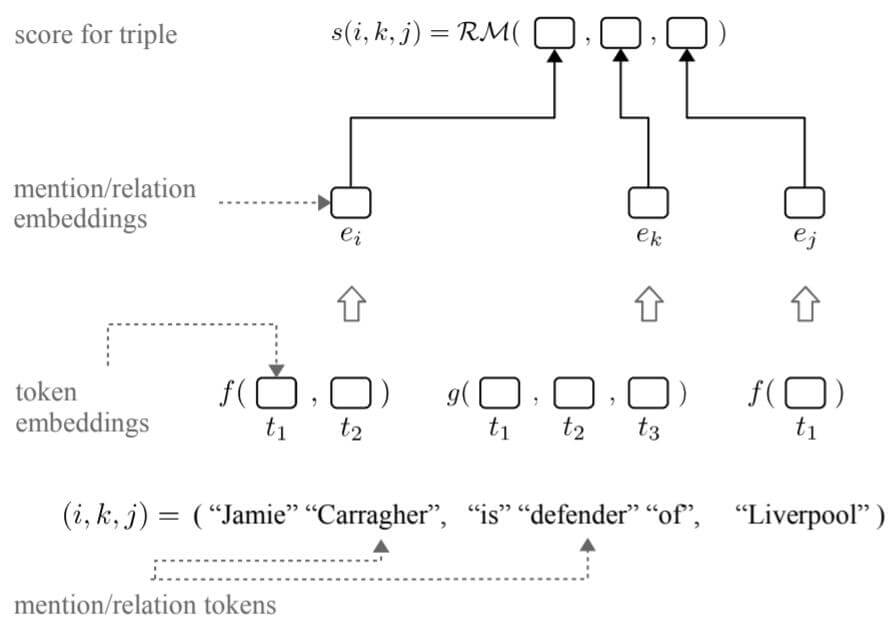
实体和关系都是由多个Token组成的, $\mathcal{V}(\mathcal{E})^{+}$ 是从词表$\mathcal{V}(\mathcal{E})$ 中提取的非空序列, 若用$d, o \in \mathbb{N}_+$ 分别代表实体和关系的嵌入维度, 则实体嵌入函数$f$ 为$f: \mathcal{V}(\mathcal{E})^{+} \rightarrow \mathbb{R}^{d}$, 同理关系嵌入函数$g$ 为$g: \mathcal{V}(\mathcal{R})^{+} \rightarrow \mathbb{R}^{o}$. 那么在实体和关系分别嵌入完后, 使用关系打分函数$\mathcal{RM}$ 对这对开放三元组打分, $\mathcal{R} \mathcal{M}: \mathbb{R}^{d} \times \mathbb{R}^{o} \times \mathbb{R}^{d} \rightarrow \mathbb{R}$.
总结下, 对于给定的三元组$(i, k, j)$, $i, j \in \mathcal{V}(\mathcal{E})^{+}$, $k \in \mathcal{V}(\mathcal{R})^{+}$, 其得分可以被计算为:
$$
s(i, k, j)=\mathcal{R} \mathcal{M}(f(i), g(k), f(j))
$$
Experiments
Models and Training
Prototpical Model
作者将COMPLEX作为最后的关系打分函数, 将LSTM作为组合函数$f$ 和$g$, COMPLEX + LSTM作为评估方法好坏的基准模型.
Diagnostic Models
作者希望能量化有多少问题是无需问题的全部信息就能够给出答案, 作者提出两个用于对比的模型:
- Predict - With - Rel: 对于问题只需要根据关系就能给出答案. 例如对于问题$(i, k, ?)$ 只需要根据$(r, ?)$ 就能够进行作答. 考虑到有头实体和尾实体的区别, 使用两个打分函数对其进行建模, 将其打分函数记为:
$$
s_{t}(k, e)=g(k)^{T} f(j), \quad s_{h}(i, k)=f(i)^{T} g(k)
$$
其中$s_{t}: \mathbb{R}^{o} \times \mathbb{R}^{d} \rightarrow \mathbb{R}$, $s_{h}: \mathbb{R}^{d} \times \mathbb{R}^{o} \rightarrow \mathbb{R}$, 分别为$(i, k, ?)$ 和$(?, k, j)$ 所设计.
- Predict - With - Ent: 与前者类似, 直接忽略关系, 只计算实体对$(i, j)$ 的分数, 打分函数被设计为:
$$
s_{e}(i, j)=f(i)^{T} f(j)
$$
Results
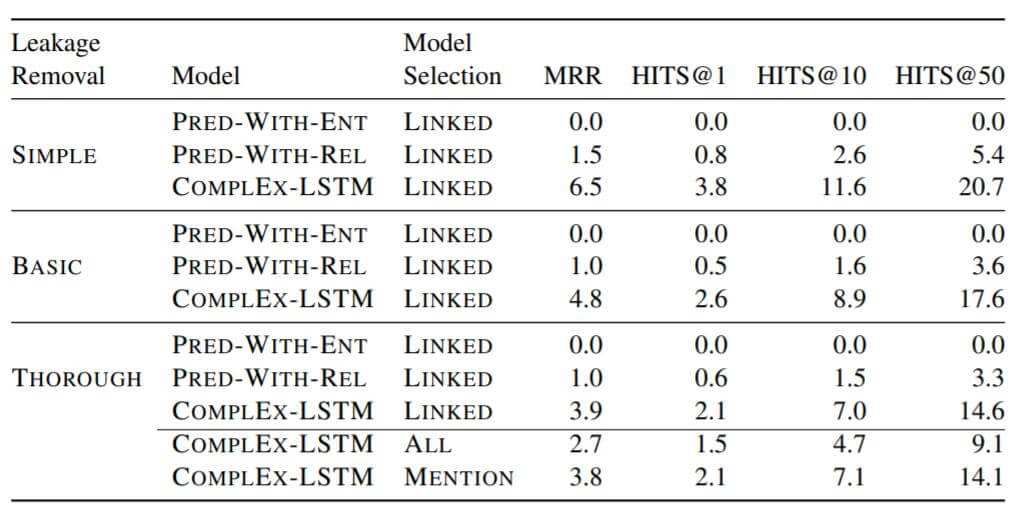
作者在测试集上分别用三种验证集选择模型, 并使用了不同的模型和不同的Leakage Removal方式, 结果如下:
作者在验证集上比较了不同验证集对模型性能的影响:
Influence of Leakage
从测试集结果能看出, 不同泄露移除方式下的COMPLEX - LSTM表现不同. Leakage移除越严格, 模型的性能就越差. 说明在训练集中确实存在着大量的Test Leakage, 在开放知识图谱中, 该现象十分严重.
Influence of Non - Relational Information
从测试集结果中看出, 所有的只使用Entity信息预测结果均为0, 而只使用关系进行预测, 仍然能够达到全部信息预测性能的20% ~ 25%.
Effectiveness of Mention - Ranking
从验证集结果中能看出, 使用LINKED验证集的效果是最好的. 因为在三种验证集中, 只有LINKED能够使用实体到实体提及的映射, 即Mention Ranking Protocol, 这确实证明了OKG中引入实体知识消歧的重要性.
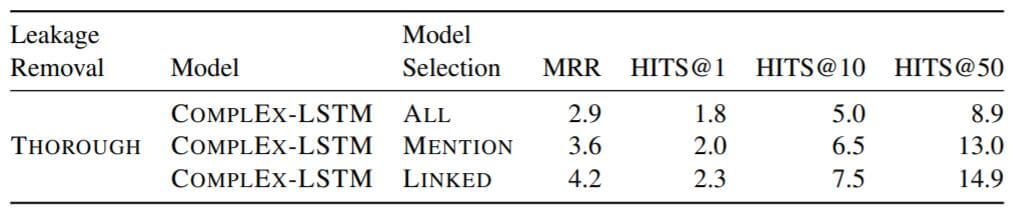
Influence of Model Selection
从测试集结果中看出, 在THOROUGH设定下的COMPLEX + LSTM对于不同的验证集表现不同. 人工干预最多的LINKED性能最好, 但MENTION和ALL的表现其实相差无几, 没有人工干预的ALL的表现最差. 作者认为只使用包含实体提及的验证数据就足够了, 这样可以避免昂贵的实体消歧. 此外, 即使在验证集上LINKED和MENTION表现差距很大, 但实际上在测试集中并不能很好的体现出它们二者的差异, 作者认为使用自己所提出的协议来计算MRR并不能有益于模型选择.
Overall Performance
与COMPLEX在普通KG上的性能进行对比, 在OKG上的性能下降十分明显. 作者认为有以下四个原因;
- OKG中的文本噪声过多.
- 评估数据的难度非常大.
- OKG非常的零散, 导致信息流被抑制.
- 问题不一定知道所有的正确答案.
Model and Data Errors
作者将错误的Link Prediction分为三类:
- correct sense / wrong entity: 排名最高的提及在语义上是可以理解的, 但是不正确.
- wrong sense: 预测的结果小方向上是不对的, 但大方向上正确, 还靠点边.
- noise: 与预测结果完全不一致, 压根不沾边.
100个采样收集的错误案例分类如下:
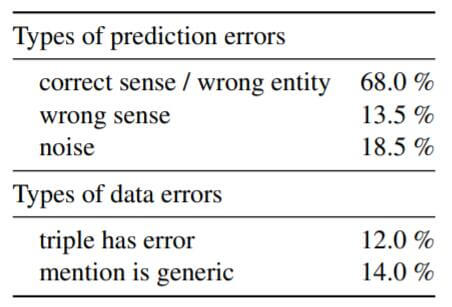
下面一栏中, 作者评估了在OPEIC中发生的提取错误三元组和概念性的事实. 从中看到, 模型的低性能大多并不是噪声所致. 有74%的预测都是正确的但是不常见的事实.
Summary
作者根据开放知识图谱和普通知识图谱之间的特性差异提出了Open Link Prediction, 并提出了OKG中的评估协议. 作者建立了新的数据集OLPBENCH, 包含了实体到实体提及之间的映射.
最后, 作者全面的评估了OKG中模型选择, Leakage, 非关系信息所带来的影响.
本文仍然有诸多不理解的地方, 对OKG接触的还比较少, 等有新理解后会后续补充.

