本文是两篇KGE方向的预警论文的阅读笔记和个人理解. 预警类的工作其实是比较少见的, 对领域的发展也非常有指导意义.
2020.11.22: 更新Reciprocal Relation.
2021.05.13: 修正Reciprocal Relation描述.
A Re - evaluation of Knowledge Graph Completion Methods
首先来看第一篇论文A Re-evaluation of Knowledge Graph Completion Methods.
Background
这篇论文是在深度学习参与时代背景下提出的. 有相当多的深度学习方法被当做黑箱使用在Knowledge Embedding中. 例如普通的CNN, RNN, GNN, 到现在的Attention, 甚至是胶囊网络也有被用于KGE的研究.
作者敏锐的观察到, 虽然基于DL的方法有非常明显的提升, 但有些方法呈现出在不同数据集上的不一致性. 作者基于这一个问题, 深度剖析了基于卷积神经网络的几种方法呈现错误实验结果的原因.
Observations
Inconsistent Improvements on Different DataSet
基于DL的方法在FB15k - 237上的MRR表现十分良好, 但到WN18RR上就出现了问题:
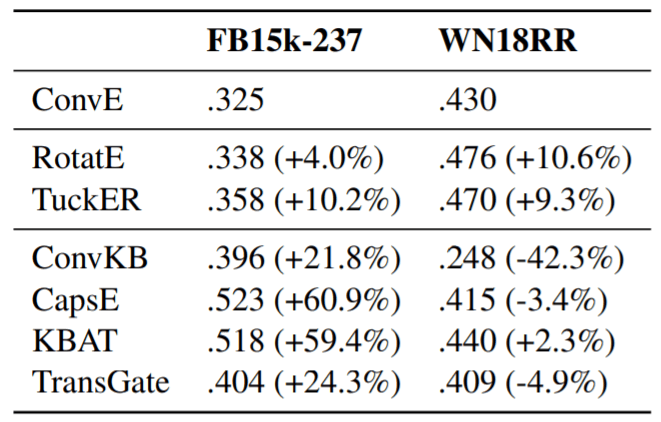
仔细看实验结果, 传统的建模方法例如RotatE, TuckER在两个数据集上相比ConvE是都有提升的, 只是提升的幅度不同. 而有些基于DL的方法在WN18RR上居然出现了退化的现象, 并且ConvKB的退化居然这么明显. 即使WN18RR是比较困难的数据集, 也不应该呈现大幅度的表现不一致.
Score Functions
作者在FB15k - 237上做了个测试, 作者发现很多正确三元组和负采样得来的三元组居然具有相同Score:
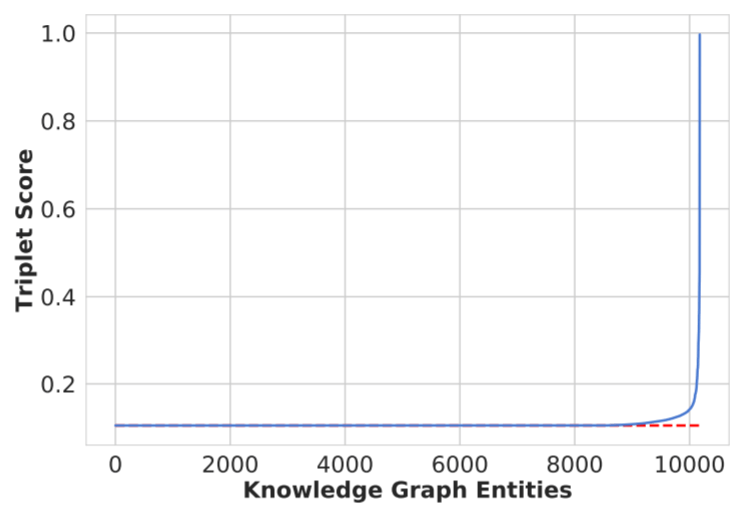
这意味着无论输入是什么, 输出始终恒定(这不是离谱吗), 作者进一步在三种基于CNN的方法上做了对比:
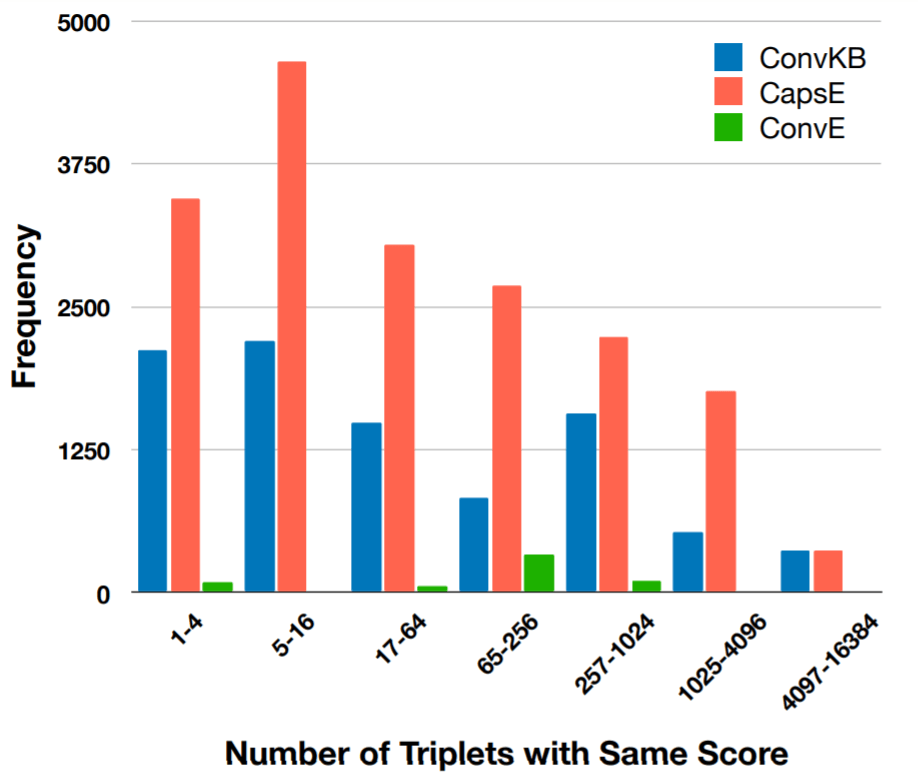
从图中可以看到, 同是基于CNN的KGE方法, 刚才呈现退化的ConvKB和CapsE出现异常的次数非常多, 而一致提升的ConvE异常次数却非常少.
Root of the Problem
经过作者的深入研究后, 发现居然是ReLU的锅:
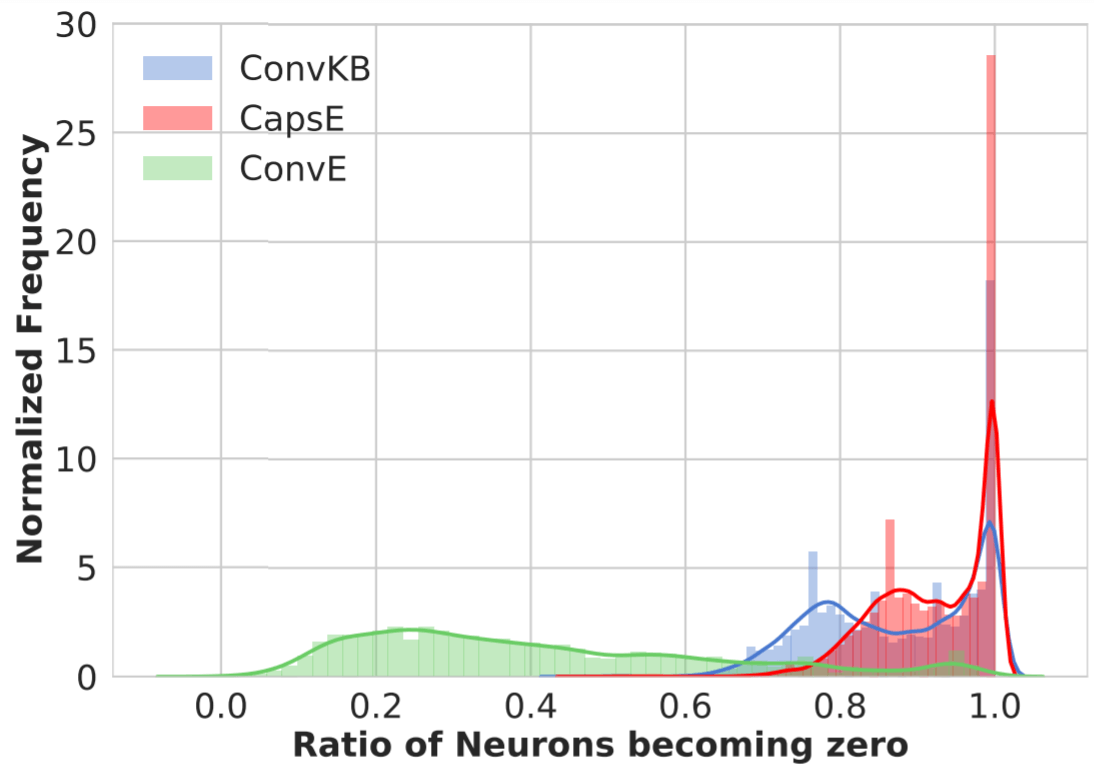
可能模型输出的结果, 但最后通过ReLU激活的时候, 这些负数全都被过滤成零了, 这也就导致了许多三元组的得分完全一致. 该实验曲线与上一个实验趋势是保持一致的.
其实这个现象被称为Dead Neuron, 因为ReLU将数据滤掉后, 会导致在BP时一整条链上的导数全为0, 也就不再更新梯度, 神经元的权重将得不到更新. 我想出的解决方案是使用Leaky ReLU等在负值域上有斜率的函数, 但同时激活函数作为NN中很重要的部分, 在更换后可能会对模型产生不可知的影响.
New Evaluation Protocol
因为很多三元组的Score都相同, 导致最后在排名进行挑选时会出现不公平的现象. 假设正确的三元组是在相同得分的候选三元组中稳定分布的, 作者提出了三种选择策略:
- TOP: 将正确的三元组插入待预测插入到分数相同的候选三元组前.
- BOTTOM: 将正确的三元组插入待预测插入到分数相同的候选三元组后.
- RANDOM: 将正确的三元组随机插入待预测插入到分数相同的候选三元组中.
- 作者认为这样做有效的原因是, 在Link Prediction中, 我们先计算所有负采样三元组的得分, 并将其排列, 最后再计算正确三元组得分, 将其放到合适的位置. 在选择三元组时, 选择排行最靠前的三元组. 如果调整了正确三元组的插入位置, 就能从一定程度上解决CNN模型性能虚高的问题.
- 在论文中这部分的观点我不是很认同, 我更倾向于是模型本身的问题而非评估协议的问题. 当然在Evaluation Protocol上动手也可以矫正实验结果, 但不能从根本上解决问题.
在FB15k -237上实验结果如下(作者也在WN18RR上做了实验, 结果一致):

作者提到, 在原来的论文中, ConvE, RotatE, TuckER使用的协议是类似于RANDOM的方法, 而ConvKB, CapsE, KBAT使用的是TOP.
通过观察, 基于TOP的结果都显示出虚高的性能, 而且刚才问题最严重的的CapsE性能虚高最为明显. 基于BOTTOM的结果都虚低. 而RANDOM的结果相对来说要公平一些.
Summary
经过研究发现基于DL的KGE方法仍然存在一些问题, 在某些数据集上呈现出性能虚高的问题, 这些方法都具有误导性, 作者鼓励用文中的方法进行评估, 相对来说更加公平. 质疑类的论文价值很高, 但我认为作者提出的问题并没有从根本上解决.
YOU CAN TEACH AN OLD DOG NEW TRICKS! ON TRAINING KNOWLEDGE GRAPH EMBEDDINGS
然后再来看第二篇论文YOU CAN TEACH AN OLD DOG NEW TRICKS! ON TRAINING KNOWLEDGE GRAPH EMBEDDINGS.
Background
随着KGE受到大家的重视, 越来越多的方法涌现出来, 并且在实验中SOTA. 但实际上大家击败的Baseline可能并不是该模型发挥的真正水平, 因为模型的性能是一定会与超参选择和训练有关. 许多研究人员将优秀的模型参数设置移植过来, 事实上该参数设置可能并不能在自己的模型上达到良好的效果. 除此外, 模型之间采用不同的方法导致很难横向对比也是一个很大的问题.
因此, 作者希望能够采用更大的超参搜索范围和更多种训练技巧, 来对这些模型的性能量化和总结.
以下是在论文中将要比较的模型, 粗体表示首次出现:
作者将对以下模型进行汇总, 其中粗体代表该方法首次在各类模型中使用:
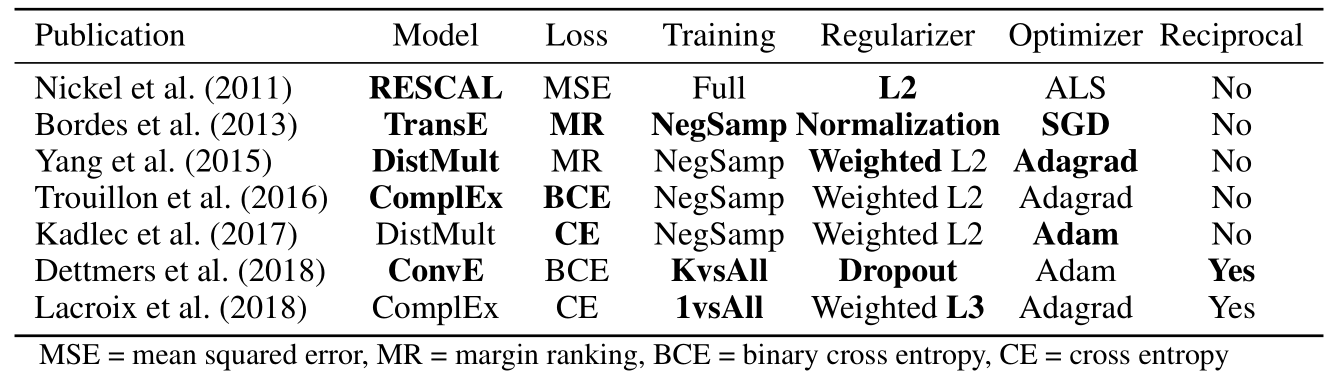
作者的研究只关注纯KGE模型, 不包括引入辅助信息的KGE模型.
Models, Traning, Evaluation
该部分中, 对于常见的领域类问题被我跳过了, 即论文中的前四点:
- Multi - relational link prediction.
- Knowledge graph embeddings (KGE).
- Evaluation.
- KGE models.
Training Type
现在常用的有三种训练类型, 分别是:
- 负采样: 将正样本中的任一元素随机替换作为负样本(有些模型中只替换头实体和尾实体).
- 1 vs ALL: 打乱头和尾实体的位置, 由单个三元组生成全部负例(略存疑).
- K vs ALL: 批量构建头实体或尾实体非空的一个Batch, 如果在训练集中出现则为正例, 否则为负例. 这种方法在ConvE中首次出现, 在其中被作者称为1 - N Score.
Loss Functions
一般也只有下列四种Loss:
- MSE(Mean Square Error).
- MR(Margin Ranking), 也称为Hinge Loss.
- BCE(Binary Cross Entropy).
- CE(Cross Entropy).
Reciprocal Relations
对于Link Prediction任务来说, 对于同一关系, 分别预测头实体和尾实体的打分函数应该是不同的.
但实际上我们不用规定不同的头尾实体打分函数, 我们可以给同种关系以顺逆区分, 即每种关系使用两种不同的Embedding, 将所有问题都转化为预测尾实体, 然后打分函数共享相同的实体Embedding, 这样也能最大限度的节省计算开销.
该方法现在已经广泛的应用于各类KGE方法中, 可能会带来性能提升.
Regularization
现在一般使用的是L2正则化, 个别研究人员推荐使用L3正则. TransE使用归一化. 关于DL的模型可以使用Dropout, 例如ConvE. 在作者的研究中, 还考虑了L1正则.
Hyperparameters
现在要考虑的超参有Batch Size, Learning Rate, 负采样个数, 实体和关系的正则权重等.
Experiments
Experiments Setup
实验的设置非常琐碎, 但这是作者的主要工作.
- Dataset: 现在最常用的两个数据集FB15k - 237和WN18RR.
- Models: 选用RESCAL, TransE, DistMult, ComplEx, ConvE.
- Evaluation: MRR和HITS@10.
- Hyperparameters: 考虑前面提到的三种Training Type(负采样, 1 vs ALL, K vs ALL), 提到的正则(None, L1, L2, L3, Dropout), 优化器(Adam, Adagrad), Embedding Size(128, 256, 512), 并分别对实体和关系建立权重用于Dropout和正则. 这是作者已知的最大范围的超参搜索空间.
- Training: 最大400Epochs. 每5个Epoch算一次MRR, 并且在有50个Epoch中模型MRR没有5%以上的提升, 则触发早停.
- Model Selection: 作者通过一个框架, 对于每个模型和数据集随机生成(即随机超参搜索)了30中不同的配置, 每种配置都包含不同的Training Type和Loss Function. 在随机搜索后用贝叶斯优化对参数进一步调优.
作者给出了一张汇总表(摘自附录):
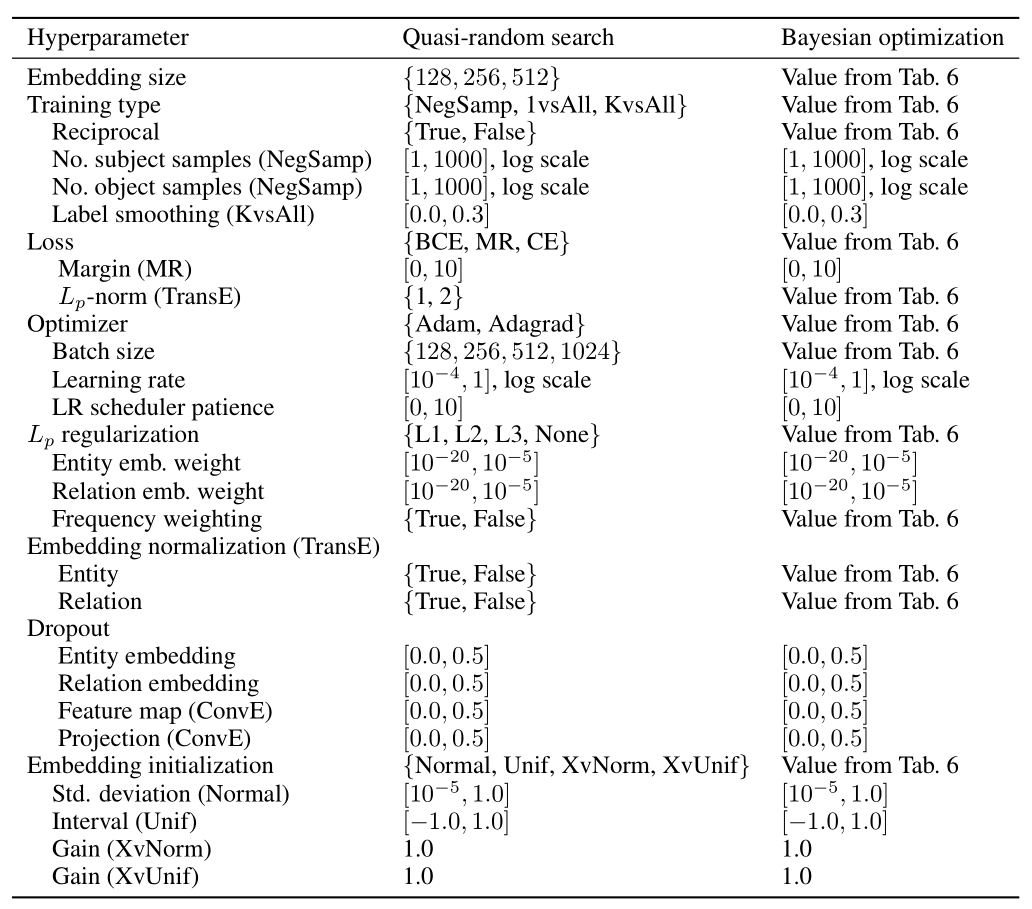
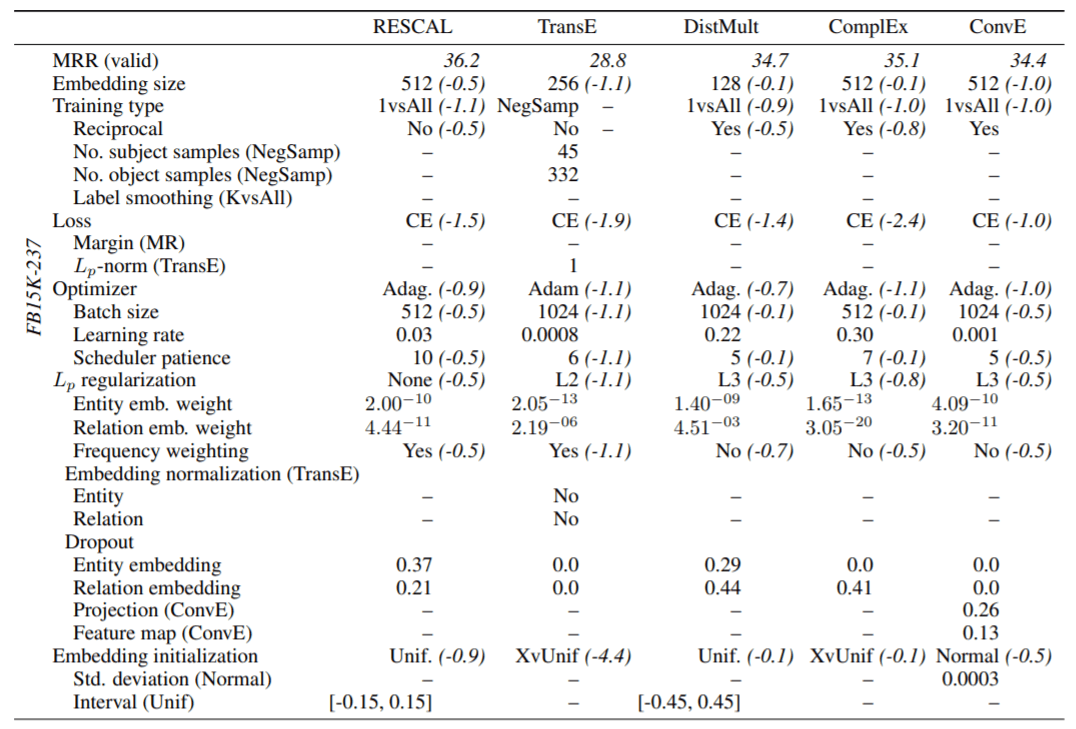
Table 6 是随机搜索在FB15k - 237上的详细最优配置图, 是同级标题下的Impact of Hyperparameters -> Best configurations (quasi-random search)中的第二幅图.
Comparison of Model Performance
作者将搜索过后的模型(Ours)性能与之前发布的最初版模型(First), 以及最近的模型(Recent)和更大号的模型(Large)进行了比较:
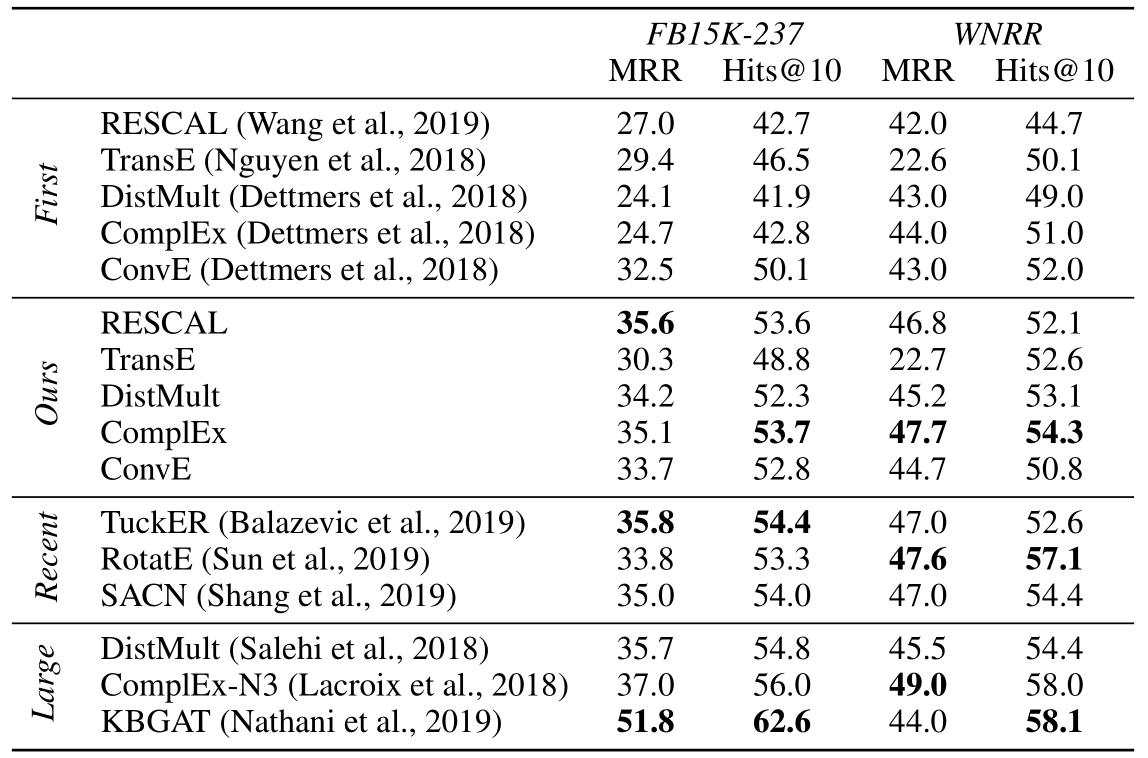
根据实验结果, 得到以下结论:
- 经过重新超参搜索后的模型相比于原作者首次发布有了巨大提升.
- 在作者重新训练的这些模型之间, 性能差距逐渐缩小, 甚至发生逆转.
- 有些模型例如RESCAL, 相比于最近新发布的模型也没差多少.
Impact of Hyperparameters
Anatomy of Search Space
作者将搜索空间所有的模型的所有结果做了一张箱型图:
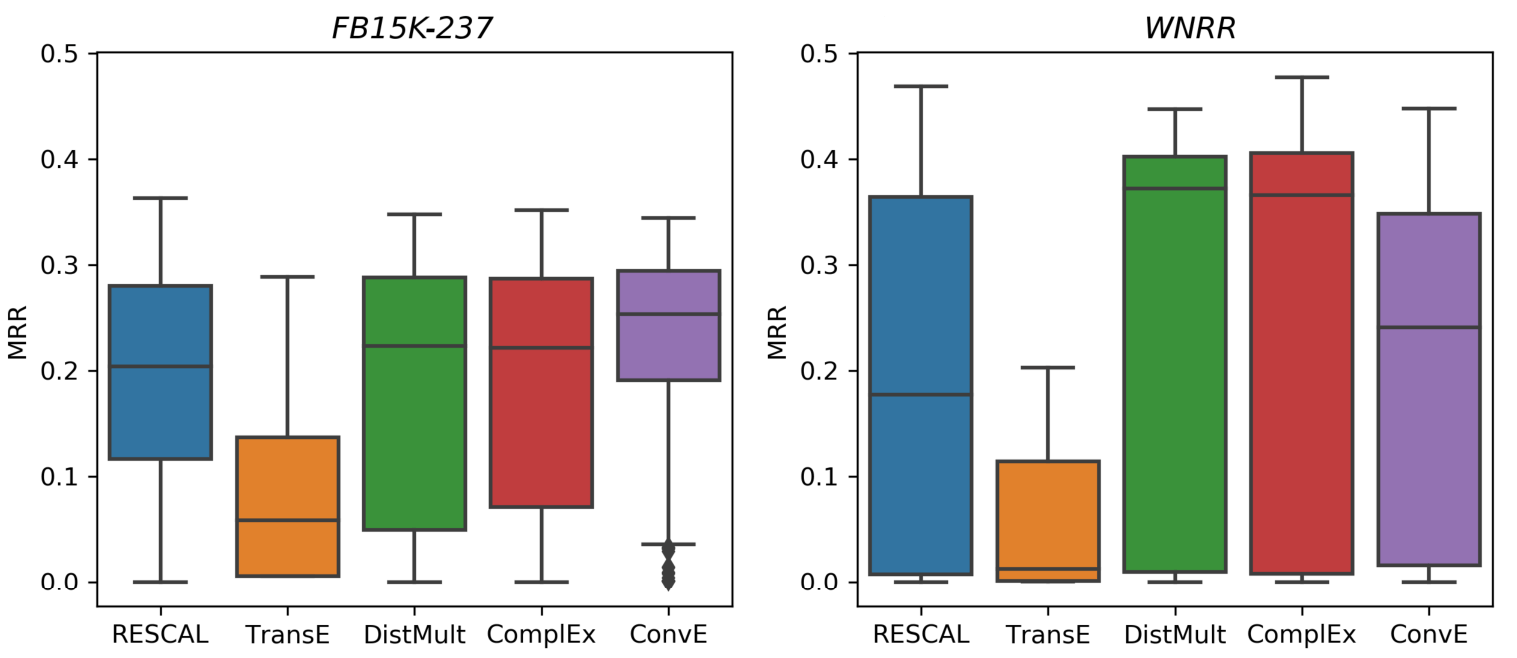
从箱型图得到以下结论:
- 不同类型的超参和训练方式给模型带来的影响巨大, 大多的模型性能均值和上限基本一致, 下限差的有点多.
- TransE的结果不太好, 这是因为其他模型都有大概200种配置, 而TransE只有60种.
- 各个模型的表现在FB15k - 237上似乎要稳定一些, WN18RR上最优和最差差距很大.
Best configurations (quasi-random search)
作者给出了在随机搜索后得到最佳结果的配置(简略), 括号内是不使用该参数导致MRR减少的值:
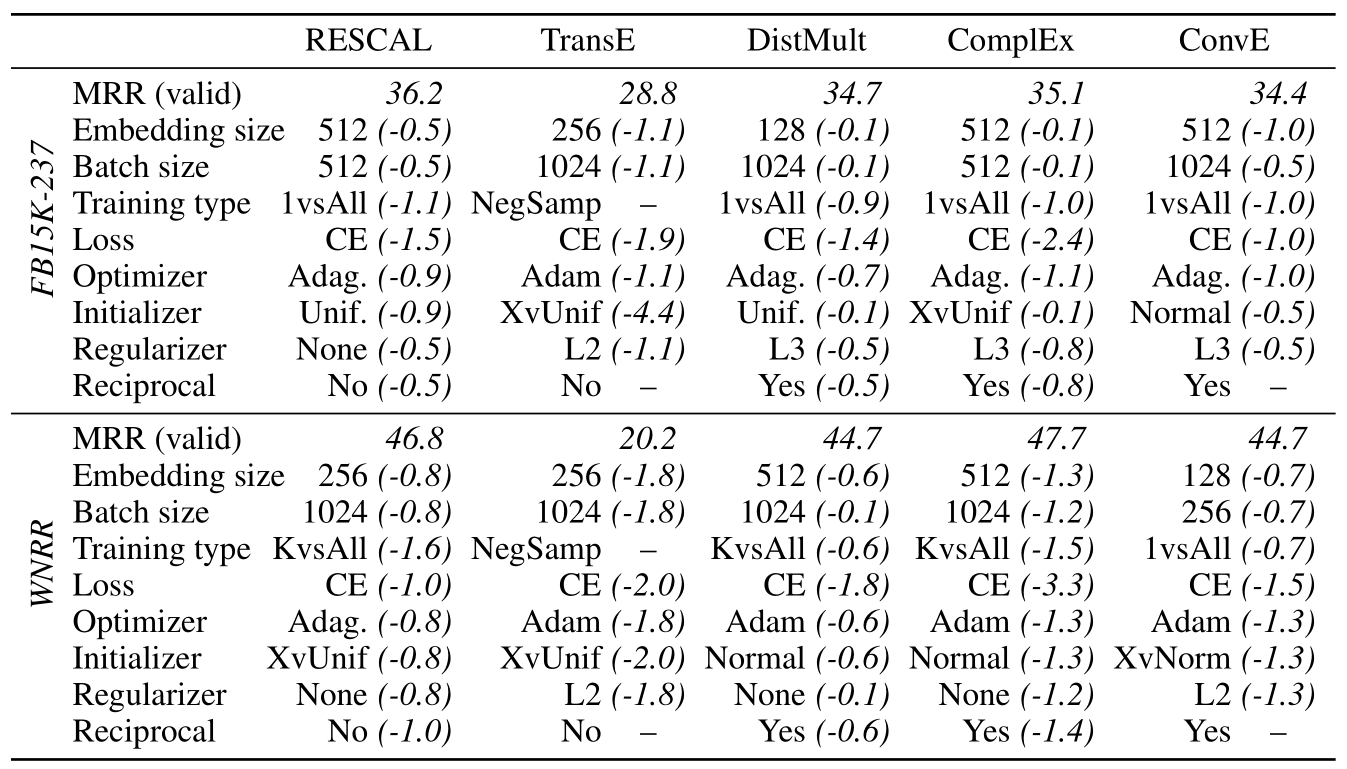
从表中发现不了什么规律, 每个模型所使用的最佳配置基本不同. 但随机搜索时CE性能似乎比较好.
各模型经过随机搜索在FB15k - 237上的详细最优配置(详细):
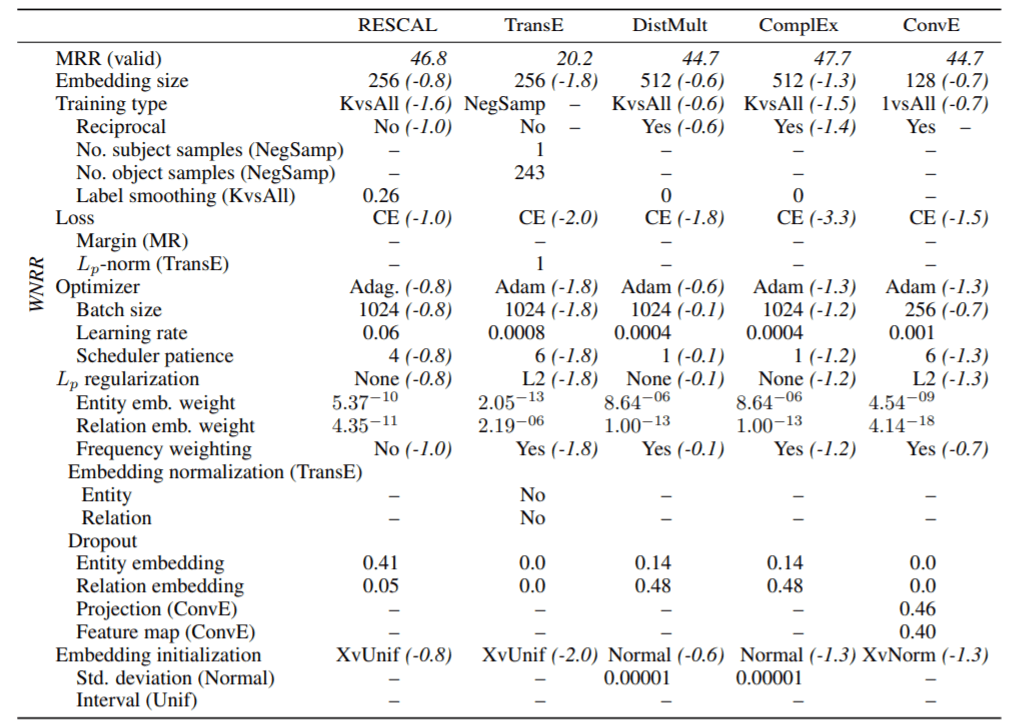
各模型经过随机搜索在WN18RR上的最优配置(详细):
Best configurations (Bayesian optimization)
各模型经过贝叶斯优化在各数据集上的最优配置:
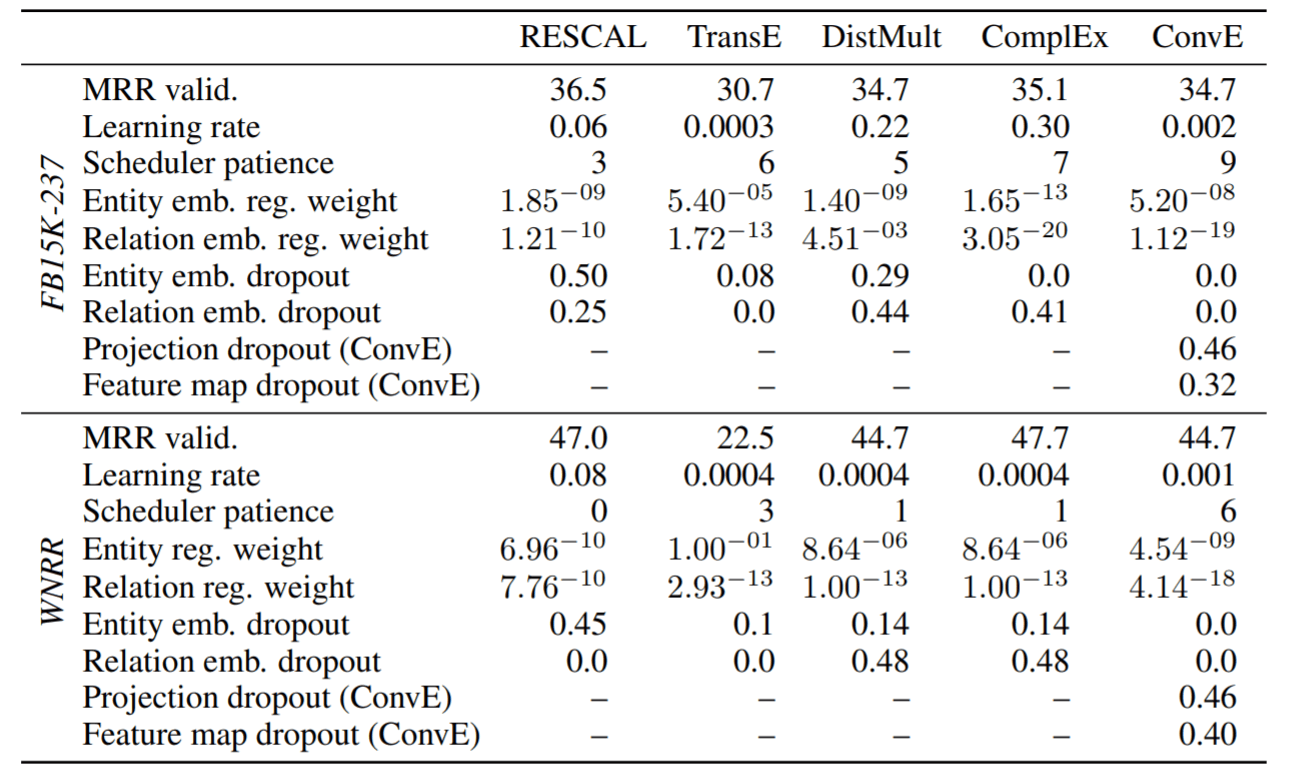
贝叶斯优化后的效果比随机搜索的结果又稍稍提升了一点.
Impact of Training Type and Loss Functions
作者在随机搜索上给出了不同训练技巧和不同损失函数的箱型图:
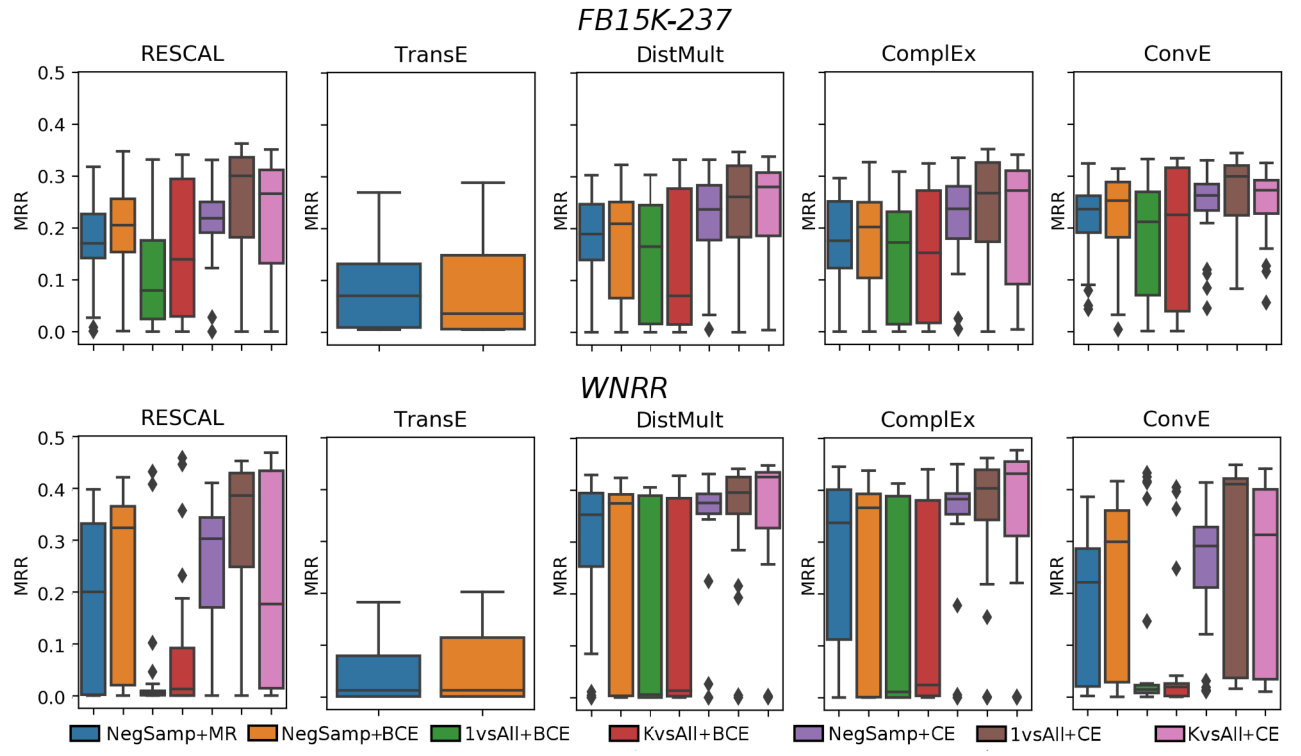
除了能体现出不同训练技巧和不同损失函数对不同模型的影响之外, 再次说明数据集也是一个非常重要的原因.
在图中还能看出来咖啡色组(1 vs ALL + CE)和粉色组(K vs ALL + CE)的上限非常高, 平均水平也不错. 这说明CE可能比其他损失函数要稍好些.
Summary
这篇论文显示了参数配置在KGE模型上的重要性. 作者用了非常大的超参数搜索空间, 来说明有些模型的性能不一定像它在初始论文中看起来的表现一样. 在作者的更大范围的超参搜索和修改训练方式后, 模型之间的差距逐渐缩小, 甚至结果反转(有点NFL的意思).
本论文还有更多的结果在附录中, 主要是对更细粒度的组合做的箱型图, 其实都说明不了什么规律性的问题, 本来就没有规律可言. 给我们最大的启发就是KGE有些模型的性能需要重新审视, 对于不同的参数可能会出现截然不同的性能, 作者也鼓励使用更大参数搜索范围尽可能的将模型真实的性能展现出来, 方便大家做比较.
最后, 对作者的钻研精神和科研毅力致敬.

