K邻近KNN K-Nearest Neighbor
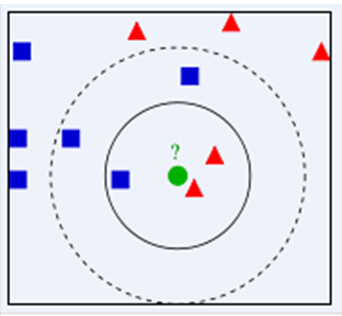
K邻近是一种非常简单的监督学习分类方法. KNN指的是每个样本都可以通过它最近的K个样本来代表. 比方说在下述图片中, 若K=3, 找到距离未知样本即绿色圆圈最近的3个样本, 在该范围内红色三角占$\frac 2 3$, 则绿色圆圈被认为是红色三角的类别. 若K=5, 则蓝色方块所占的比例为$\frac 3 5$, 绿色圆圈被认为是蓝色方块. 如果K的取指不同, 则未知样本的类别也会产生改变, 所以结果很大程度取决于K的选择.
当然, 在这个过程中距离不一定是欧氏距离, 还可以选择曼哈顿距离.
$$
d(x, y) = \sqrt{\sum_{k=1}^n |x_k - y_k|}
$$
在实际应用过程中, 还可以基于距离的远近进行加权平均或投票, 距离越近的样本权重越大.
KNN是一种Lazy learner, 也就是懒惰学习算法. 它不需要训练, 只是单纯的记住所有的训练样本, 在进行预测时根据已经记住的训练集去寻找临近, 从而获得结果.

