AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
- 论文: AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment, ACL 2023 Findings, Zhou Zhao组.
- 代码: GitHub - RickyL-2000/AlignSTS: Findings of ACL 2023 | AlignSTS: a speech-to-singing (STS) model based on modality disentanglement and cross-modal alignment.
Basic Idea
语音到歌声转换(Speech-to-Singing Voice Conversion, STS)旨在生成与语音记录相对应的歌声样本. 但由于无文本时, 歌声的音高轮廓(Pitch Contour)与语音内容(Speech Content)之间难以对齐而导致难以学习.
因此, 作者提出AlignSTS, 基于一种显式的跨模态对齐来建模STS任务. 作者从Rhythm入手来对齐Speech Content & Singing Pitch Contour.
AlignSTS
Problem Formulation
设语音梅尔谱为$S_{\text{sp}}$, 设歌声梅尔谱为$S_{\text{sg}}$.
AlignSTS将语音信号$S_{\text{sp}}$ 建模为内容 Content $\boldsymbol{c}_{\text{sp}}$, 音色 Timbre Identity $\boldsymbol{i}_{\text{sp}}$, 音高 Pitch $\boldsymbol{f}_{\text{sp}}$, 和节奏 Rhythm $\boldsymbol{r}_{\text{sp}}$ 几种信号的融合:
$$
S_{\text{sp}}=g\left(\boldsymbol{c}_{\text{sp}}, \boldsymbol{i}_{\text{sp}}, \boldsymbol{f}_{\text{sp}}, \boldsymbol{r}_{\text{sp}}\right)
$$
其中$g(\cdot)$ 为多模态融合函数.
STS(Speech to Singing)的任务目标是训练一个网络$f_\theta$, 在保持说话人音色 $\boldsymbol{i}_{\text{sp}}$ 和内容 $\boldsymbol{c}_{\text{sp}}$ 不变的情况下, 生成Speech Pitch $\boldsymbol{f}_{\text{sp}}$ 转换为Singing Pitch $\boldsymbol{f}_{\text{sg}}$ 后的歌声频谱$\widehat{S_{\text{sg}}}$:
$$
\widehat{S_{\text{sg}}}=f_{\theta}\left(\boldsymbol{c}_{\text{sp}}, \boldsymbol{i}_{\text{sp}}, \boldsymbol{f}_{\text{sg}}, \boldsymbol{r}_{\text{sg}}\left(\boldsymbol{c}_{\text{sp}}, \boldsymbol{f}_{\text{sg}}\right)\right)
$$
在上式中, 由于Singing Rhythm $\boldsymbol{r}_{\text{sg}}$ 暗含时间信息, 所以应该根据Speech Content $\boldsymbol{c}_{\text{sp}}$ 与Singing Pitch $\boldsymbol{f}_{\text{sg}}$ 而变化.
Method Overview
AlignSTS将语音与歌声视为一系列唱法信息的融合, 进一步可以将每种唱法(Variance)信息看做是不同的模态.
在STS中, Pitch和Rhythm为主要的转换模态, 它们能够被并行解耦, 但是转换过程需要仔细设计Variance的合成逻辑.
作者认为, 从表面看, Phoneme Sequence和Pitch Contour似乎没什么关联, 但实际上人类在创作的时候极有可能利用二者之间的对齐关系进行旋律创作:
- 根据歌词(Lyrics)和旋律(Melody), 来确定合适的音素(Phoneme), 音符(Note)的起始时间和结束时间.
- 根据Phoneme Sequence是非常有可能依赖Rhythm来排列的, 与Melody结合得到歌声.
因此, AlignSTS基于上述假设, 做出如下设计:
- 将Speech Signal分解为一系列解耦的Variance Information.
- 根据Speech到Singing的转换过程中发生改变的Pitch Contour($\boldsymbol{f}_{\text{sp}} \rightarrow \boldsymbol{f}_{\text{sg}}$)来调整Singing Rhythm $\boldsymbol{r}_{\text{sg}}$.
- 根据调整后的Rhythm重新与Speech Content对齐, 然后进行多模态融合来整合Variance Information.
AlignSTS主要框架图如下:
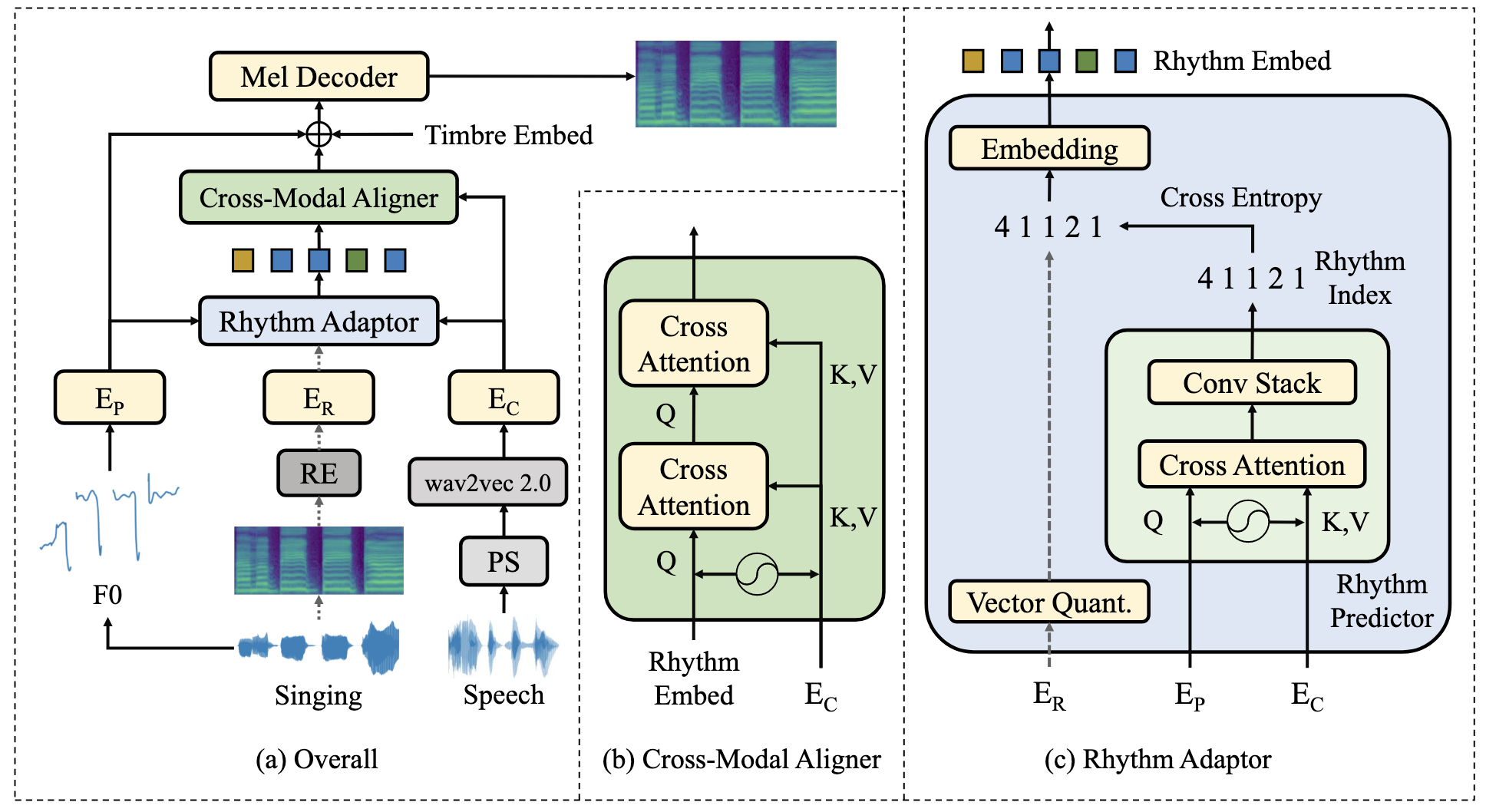
AlignSTS主要有四个模块: Encoder, Rhythm Adapter, Cross-Modal Aligner, Mel-Decoder. Encoder和Mel-Decoder不是本文的重点. 图中虚线代表仅在训练时使用, 推理阶段不使用.
就像之前提到的, AlignSTS以Rhythm为切入点来改善Pitch和Content之间的对齐关系.
- Rhythm Adapter (c): 用于填补Pitch与Content之间的Gap, 对Rhythm Representation采用了VQ的设计.
- Cross-Modal Aligner (b): 用于重新对齐Inference时预测出的Rhythm与输入的Speech Content Feature, 以此重新指导歌声合成.
Information Perturbation
语音样本和歌声样本都可以被分解为Content, Pitch, Rhythm, Timbre等唱法特征.
每种特征需要分别以不同的方式解耦抽取出来:
- Linguistic Content: 用wave2vec 2.0来提取Speech Content.
- Pitch: 提取基频轮廓F0作为音高信息. 基频轮廓被量化为256个值(即256个类).
- Timbre: 使用开源的说话人识别API Resemblyzer抽取音色信息, Resemblyzer可以根据声音生成一个256维向量.
- Rhythm: Rhythm可以控制每个Phoneme的Duration和Speed, 所以它能提供Duration和Content. 但是从模式上来说, 歌声比语音的强度普遍波动更大, 所以作者用处理后的歌声样本的时域能量轮廓(Energy Contour) $\boldsymbol{e}_t$ (每个时刻的值为各频域的L2范数)来表征Rhythm.
具体的, 将Energy Contour使用标准正态分布标准化, 并且用Sigmoid函数$\sigma(\cdot)$ 将Energy Contour进行归一化:
$$
\boldsymbol{r}_t=\sigma\left(\beta\times\frac{\boldsymbol{e}_t-\operatorname{mean}(\boldsymbol{e})}{\operatorname{std}(\boldsymbol{e})+\epsilon}\right)
$$
其中, $\epsilon$ 来避免零除. $\beta$ 为一个超参, 用于控制标准化程度. $\boldsymbol{r}_t$ 为得到的Rhythm Representation.
通过这种方式, 作者解耦出了Rhythm, 同时保留了Duration. 例如, 在歌曲中的一句”I’m a big big girl”中有:
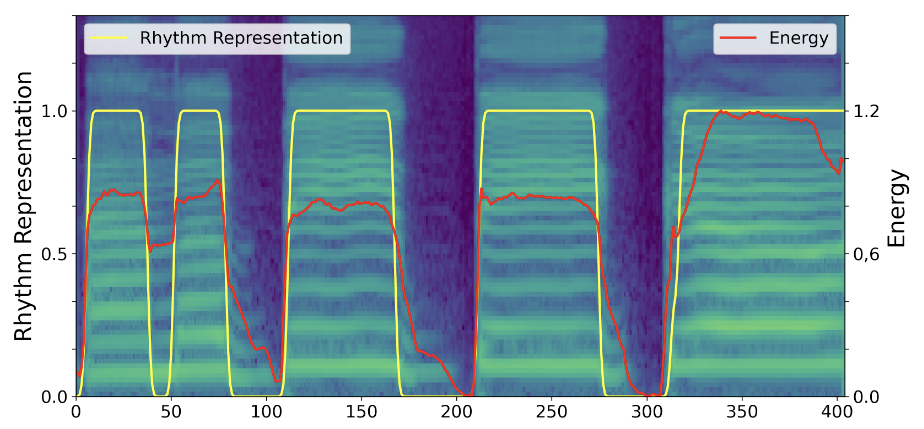
明显的, Rhythm Representation(黄线)的Duration是要更加清晰的, 对于Phoneme的区分要更友好.
似乎不同音素转换之间的过渡也被构造的表示抹掉了… 但作者最重要的想法应该就是只保留Duration作为已解耦的Rhythm, 不同音素之间的过渡方式通过其他模块或者用其他唱法信息来补充学习.
Encoder
对于Singing F0 $\boldsymbol{f}_{\text{sg}}$, Rhythm $\boldsymbol{r}_{\text{sg}}$, Speech Content $\boldsymbol{c}_{\text{sp}}$, 分别用$\mathrm{E}_{\mathrm{P}}$, $\mathrm{E}_{\mathrm{R}}$, $\mathrm{E}_{\mathrm{C}}$ 来编码, Encoder都是两层1D Conv Layer的堆叠:
$$
\boldsymbol{x}_{\mathrm{P}}=\mathrm{E}_{\mathrm{P}}\left(\boldsymbol{f}_{0}\right), \boldsymbol{x}_{\mathrm{R}}=\mathrm{E}_{\mathrm{R}}(\boldsymbol{r}), \boldsymbol{x}_{\mathrm{C}}=\mathrm{E}_{\mathrm{C}}(\boldsymbol{x})
$$
Rhythm Modality Modeling
歌声信号中的Rhythm可以被视为是一系列离散的时间动态状态, 如Attack, Sustain, Transition, Silence等.
Rhythm在AlignSTS用VQ Module来提取, 从而获得一个离散的Rhythm表示$e \in {\mathbb{R}^{K \times D}}$, $K$ 为每个Latent Embedding $e_k \in \mathbb{R}^{D}, k \in 1, 2, \dots, K$ 的维度.
使用VQ-VAE中的Commitment Loss来优化离散的Rhythm Embedding:
$$
\mathcal{L}_{\text{C}}=\left\Vert z_e(x)-\operatorname{sg}[e]\right\Vert _2^2
$$
其中, $z_e(\cdot)$ 为VQ Module, $\text{sg}$ 为停止梯度运算符. Commitment Loss仅让VQ Module得到的Rhythm Embedding $z_e(x)$ 与Codebook中的Embedding $e$ 靠近.
为了让Singing Rhythm $\boldsymbol{r}_{\text{sg}}$ 条件依赖于Speech Content $\boldsymbol{c}_{\text{sp}}$, 可以采用Cross-Attention来实现. 具体的, 以Pitch $X_P$ 为Query, Content $X_C$ 为Key和Value做CA, 得到的是融合时需要的Target Content Feature:
$$
\begin{align}
\text{Attention}(Q, K, V)&=\text{Attention}\left(X_{P}, X_ {C}, X_{C}\right) \\
&=\operatorname{Softmax}\left(\frac{X_{P} X^{T}_{C}}{\sqrt{d}}\right) X_{C} \\
\end{align}
$$
$X_P, X_C$ 会先被投影到Query, Key, Value的表示空间中.
Rhythm Predictor
但是在Inference时没有歌声的能量轮廓, Rhythm此时是不可用的, 所以VQ Module只能用于Training. 因此, 需要一个Rhythm Predictor来预测Rhythm Class.
作者将Rhythm Predictor设计为一些Cross-Attention和卷积层的堆叠.
Rhythm是离散的, 用交叉熵来训练Rhythm Predictor:
$$
\mathcal{L}_{\text{R}}=-\frac{1}{T}\sum_{t=1}^{T}\sum_{c=1}^{K} y_{t, c}\log\left(\hat{y}_{t, c}\right)
$$
其中, $T$ 为总共的时间帧数量, $y_{t,c}$ 为VQ Module生成的Rhythm Embedding的下标索引, 即当$t$ 时刻的Rhythm Class $c$ 为$k_t$ 时, $y_{t, c}=1$. $\hat{y}_{t, c}$ 为预测出的Rhythm Indices.
所以Rhythm Adapter大概就是下面这个样子:
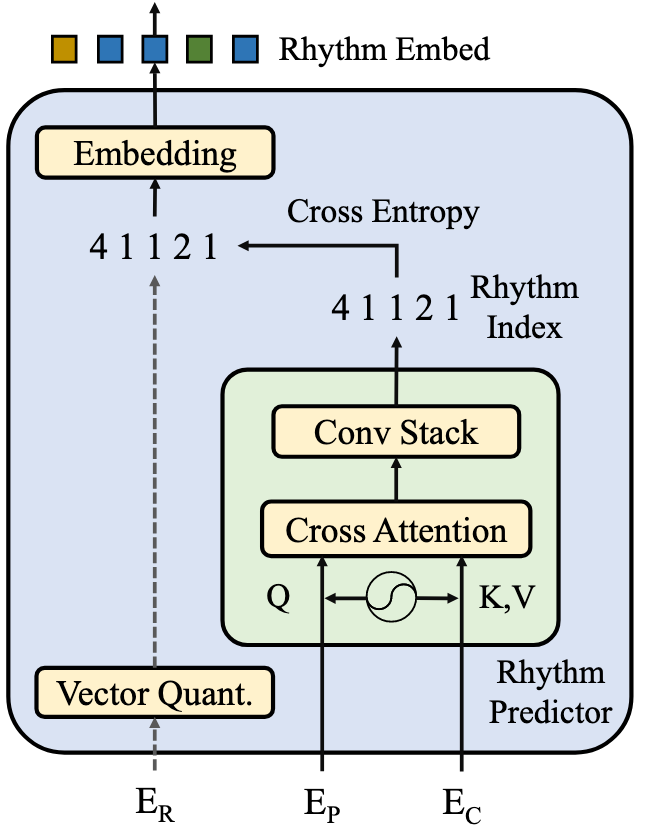
- 训练时已知歌声的Rhythm, 得到Rhythm Encoder $\mathrm{E}_{\mathrm{R}}$ 对Rhythm编码后的表示, 然后用VQ Module得到Rhythm Indices, 以此更新Rhythm Codebook Embeddings.
- 在推理的时候, Rhythm Predictor以Pitch Encoder $\mathrm{E}_{\mathrm{P}}$ 对Pitch编码后的表示为Query, Content Encoder $\mathrm{E}_{\mathrm{C}}$ 对Content编码后的表示为Key, Value, 做完Cross-Attention后再用Conv Stack预测出Rhythm Indices.
Cross-Modal Alignment
在通过VQ得到了Rhythm Sequence之后, 还需要Cross-Modal Aligner来重新对齐Rhythm和Content, 得到融合时的Rhythm Feature.
Cross-Modal Aligner采用两层Cross-Attention Layer来重对齐Rhythm和Content:
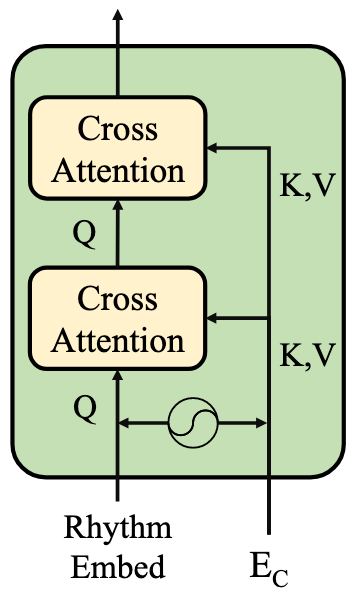
用Rhythm Embeddings $e$ 作为Query, 并再次以Content Encoder $\mathrm{E}_{\mathrm{C}}$ 对Content编码后的表示为Key, Value, 实现这种Soft-Selection.
所以实际上Rhythm Predictor里的CA和Cross-Modal Aligner的CA都是以Content为Key, Value, 只不过是分别以Pitch和VQ过后的Rhythm Embedding为Query.
当所有的唱法信息都被重新对齐后, 终于集齐了这几种特征, 可以准备召唤神龙了:
- Pitch: 直接通过Pitch Encoder $\mathrm{E}_{\mathrm{P}}\left(\boldsymbol{f}_{0}\right)$ 得到.
- Content: 在Rhythm Predictor中, 以Pitch为Query得到. 因此与Pitch具有相同的Shape.
- Rhythm: 在Cross-Modal Alignment中, 以VQ后的Rhythm Embedding为Query得到. 而Rhythm Embedding在VQ前与上面的Content同Shape, 所以Rhythm也与Pitch同Shape.
- Timbre: 对于一段音频仅只有一个向量, 没有时间长度的维度.
除了Timbre, 剩下的三个的时间长度都是一样的. Timbre可以直接通过广播与其他三者相加, 从而完成最后的跨模态融合.
这部分原文里写的挺乱的, 没写到底是用哪个Content做融合, 看了下代码才对得上. 而且代码里配置文件里面还写了个
q_rhythm_bridge: False, 也就是没加VQ以后的Rhythm Embedding… 有点难绷, 反正大概意思就是几个特征加一下, 咱们在这也不纠结了.
Rhythm的解耦建模明确了Word / Phoneme的数量与它们的顺序, 正常情况下, Content和Rhythm应该是按顺序一一对应的, 所以Attention Matrix应该偏向于集中在主对角线附近. 所以, 作者希望进一步采用两种令注意力学到主对角线附近的约束来建模这种先验.
Attention and Alignment Regulation
Attention Windowing
对于每个时间步$t$ 对应的作为Query的中间位置$p_t$, Key / Value的序列$\hat{\boldsymbol{x}}$ 被限制在一个窗口大小为$2w$ 的窗口内:
$$
\hat{\boldsymbol{x}}=\left[\boldsymbol{x}_{p_t-w}, \ldots, \boldsymbol{x}_{p_t+w}\right]
$$
对于在窗口外的元素, Attention Matrix被填充以$-10^8$ 来限制它们被给予Attention.
作者设定的Window Size是一个长度百分比, 即每个窗口占序列中的百分比.
Guided Attention Loss
为了进一步限制Attention Matrix近似对角阵, 作者用Loss加以约束引导模型学习:
$$
\mathcal{L}_{\text{attn}}=\frac{1}{TN}\sum_{t=1}^{T}\sum_{n=1}^{N}\alpha_{t,n}w_{t,n}, \quad \text{where} \quad w_{t, n}=1-\exp\left(-\frac{\left(\frac{n}{N}-\frac{t}{T}\right)^2}{2g^2}\right)
$$
其中$\mathrm{T}, \mathrm{N}$ 分别为Query, Key的长度, $w_{t, n}$ 为约束后的权重分布, $g$ 为控制集中在对角线附近的超参, 通常设为0.1. 因此, 当$at, n$ 离对角线很远时, 则Key项对应的Loss系数会更大, 会被给予更大的惩罚.
Mel-Decoder
作者采用一个Diffusion Model, ProDiff的Teacher Model作为Mel-Decoder来完成更好的合成. 对Decoder施加两个Reconstruction Loss:
- MAE Loss: $\mathcal{L}_{\text{MAE}}=\left\Vert \boldsymbol{x}_\theta\left(\alpha_t \boldsymbol{x}_0+\sqrt{1-\alpha_t^2}\boldsymbol{\epsilon}\right)-\boldsymbol{x}_0\right\Vert$.
- SSIM Loss: $\mathcal{L}_{\text{SSIM}}=1-\text{ SSIM}\left(\boldsymbol{x}_{\theta}\left(\alpha_{t} \boldsymbol{x}_{0}+\sqrt{1-\alpha_{t}^{2}}\boldsymbol{\epsilon}\right), \boldsymbol{x}_{0}\right)$.
Training and Inference
Loss主要由5个项组成:
- VQ里面的Commitment Loss $\mathcal{L}_{\text{C}}$.
- Rhythm Predictor的分类损失 $\mathcal{L}_{\text{R}}$.
- Cross-Modal Alignment的Guided Loss $\mathcal{L}_{\text{attn}}$.
- MAE Loss $\mathcal{L}_{\text{MAE}}$.
- SSIM Loss $\mathcal{L}_{\text{SSIM}}$.
在训练和推理时:
- 在训练阶段, Cross-Modal Aligner直接用VQ Module生成的Rhythm Embedding作为输入, 同时把对应的索引给Rhythm Predictor用CE来训练.
- 在推理阶段, VQ Module采用Rhythm Predictor预测得到的Rhythm Indices再从Codebook中查表得到的Embedding作为Rhythm Embedding.
我粗看代码里VQ Module在训练的时候还用了EMA, 来保证Codebook更新不会过快, 否则会影响其他依赖于Rhythm Embedding的模块参数更新.
Experiment
详细的实验设置和超参数设置请参照原论文.
Dataset & Evaluation
Dataset
数据集采用PopBuTFy, 这是一个歌声美化(Singing Voice Beautifying, SVB)的数据集. 作者收集并标注了一个PopBuTFy的子集的语音数据, 形成一个Speech-Singing Paired Dataset. 其中有16个歌手的152首英文歌, 大约5.5小时, 以及约3.7小时的语音记录.
Evaluation
- Objective Metrics:
- LSD(Log-Spectral Distance): 用于衡量两个频谱之间的距离.
- RCA(Raw Chroma Accuracy): 用于预测的F0与真实F0在感知上的差距.
- RRD(Rhythm Representation Distance): 使用生成的梅尔谱计算得到的Rhythm与Ground Truth的Rhythm之间的欧氏距离来衡量对Rhythm的恢复能力.
- Subjective Metrics:
- MOS-Q: 表示合成歌声音频的整体质量.
- MOS-P: 表示自然度和连贯性.
LSD衡量的是生成结果与GT之间的全局预测的好坏, 而RCA偏向于Pitch预测的好坏, RRD偏向于Rhythm预测的好坏.
Main Results
在数据集上主要实验结果如下:
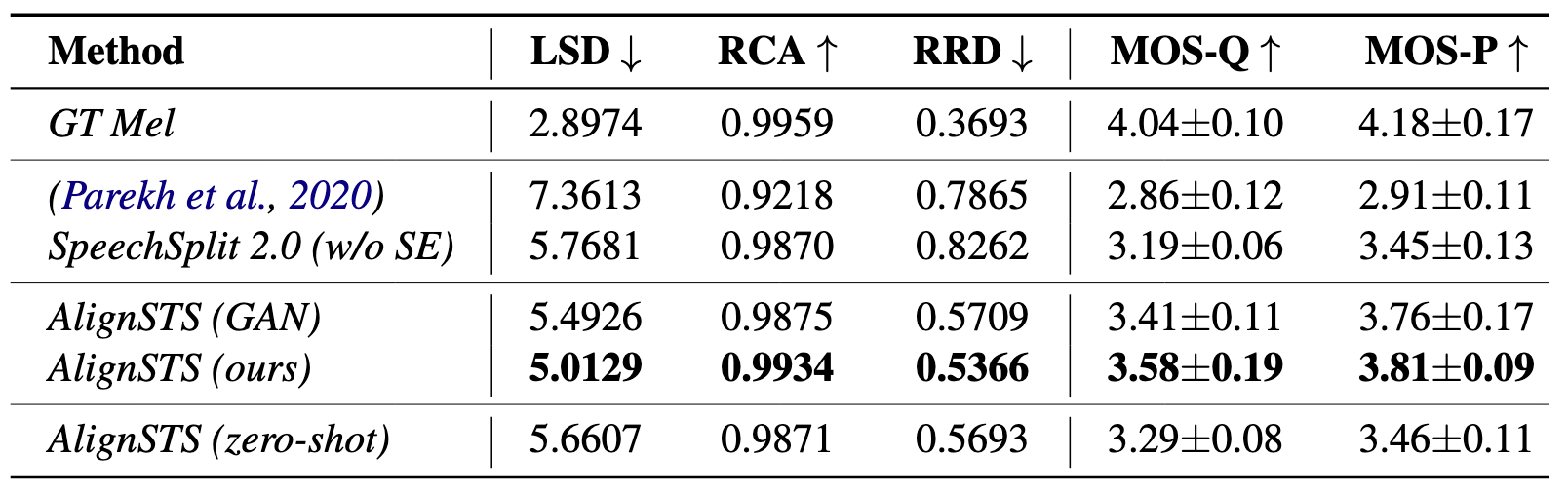
其中的AlignSTS(GAN)是将Diffusion Model替换为GAN的结果.
结果上来说, AlignSTS比其他Baseline要大幅领先, 但相较于GT还是有显著差距. 在作者提出的评估指标RRD上, AlignSTS具有较大的优势, 说明AlignSTS对Rhythm建模是相对合理的.
作者在这里提到的Zero-Shot Speech-to-Singing Conversion指的是只使用Singing Sample执行Singing-to-Singing的训练, 即对同一段Singing Sample提取Rhythm和Content, 但是推理的时候采用Speech作为输入. 从结果上发现, 即使AlignSTS做Zero-Shot, 似乎也能取得一个与其他Baseline不做Zero-Shot时相当甚至还好的效果.
下图是生成的梅尔谱可视化:

图(a), (b)分别为表格中的第一二个Baseline, 图(c)为AlignSTS, 图(d)为GT. 从梅尔谱上来看, 前两个Baseline明显在Rhythm的编排上比AlignSTS差得多. 细节上来说, AlignSTS要优于前两个Baseline, 但也能看出AlignSTS在高频的细节上还有很多不足.
Ablation Study
消融实验上选择CMOS-Q(Comparative Mean Opinion Score of Quality), CMOS-P(Comparative Mean Opinion Score of Prosody)作为评估指标, 结果如下:
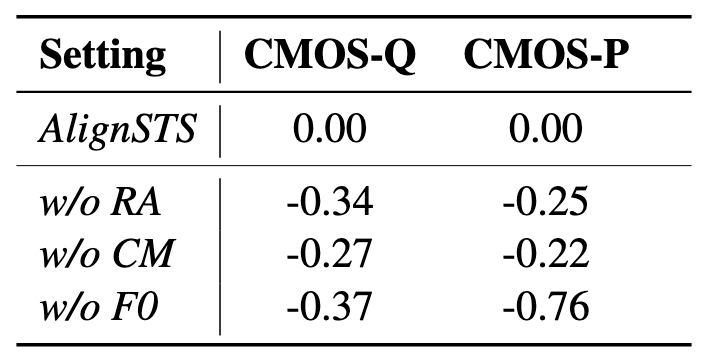
- w/o RA: 使用线性插值来拉伸Speech Rhythm Representation代替Rhythm Adapter, 直接用于Cross-Modal Alignment中.
- w/o CM: 去掉Cross-Modal Alignment, 直接把Content Encoder得到的表示线性拉伸到与Pitch Contour相同的长度, 以此适应Rhythm, 然后直接把所有的Feature相加做融合.
- w/o F0: 直接在融合中去掉Pitch, 只将Rhythm, Content, Timbre加到一起.
从消融实验结果上来看, 影响最大的是F0. Rhythm Adapter和Cross-Modal Alignment去掉后掉点情况近似.
Attention Weights Visualization
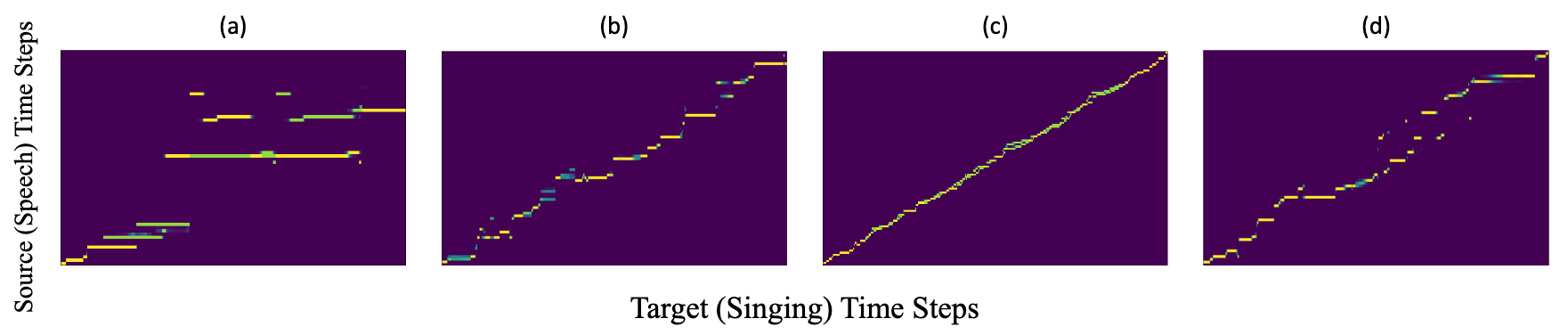
上图依次为:
- (a) / (b): 不加 / 加Alignment Regulation的Cross-Attention.
- (c) / (d): AlignSTS Training / Inference时的Zero-Shot.
从Visualization上能明显的看出作者采用的两种约束的训练效果. 如果不加限制, Attention Matrix直接起飞, 加完约束后明显集中在主对角线附近了.
按照前文中的实验部分, Training的Zero-Shot做的是Singing-to-Singing, 当Singing Sample同时作为Content和Rhythm输入时, Attention被约束的非常好, 近乎线性模式. 在推理阶段做的才是Speech-to-Singing, 能发现AlignSTS对于未见过的Speech Sample也仍然有一定的能力将Attention集中在主对角线附近.
此外, 我个人认为Zero-Shot的强大泛化应该暗示了Speech & Singing Pair之间的紧密联系.
Summary
AlignSTS将STS任务建模为一系列唱法信号的转换与融合的过程, 并以离散的形式建模包含时间信息的Rhythm, 并以Rhythm为切入点来完成Speech Content和Singing Pitch之间的Cross-Modal Alignment, 也引入了一些先验来显式指导对齐的过程.
不过从5202年这个ASR相当成熟(有Whisper这种鲁棒性非常强的ASR工具)的时间点来看, 但对齐来说, Text-based Alignment也许也能做的更轻松些.

