2020.08.24: 更新word2vec的部分内容.
NLP相关知识
整个流程: 分词 Tokenize -> 预处理 Preprocess -> 特征工程 Feature engine -> ML.
分词 Tokenize
就是把每个句子按照词语分开, 包括标点. 只有分词后才方便后续对句子的过滤. 中文分词和英文分词是不一样的. 英文分词只需要直接分离标点和空格就行, 中文分词常会因为不同NLP库的处理模式不同而结果不唯一. 有时候分词没那么容易, 在社交语言中和常常会有拼写错误, 缩写, URL, emoji, 单位名称书写不统一… 常常用正则一块处理掉. 值得注意的是, 有时去除它们不一定能带来好的效果.
文本预处理
库这用NLTK用的多. 对于词形归一和词干提取, 无论是哪种方法都不能正确地处理所有的单词, 常常会引入噪声, 需要结合实际效果而定.
词形归一 Lemma
把所有词的变形, 全部都归为一个形式. 通过语言学家的wordnet进行归一化. 但是Lemma的过程中常常会因为不考虑单词词性而归一错误, 这时候就需要附加标注的词性(Pos Tag)进行映射.
词干提取 Stemming
简单来说就是直接把不影响词性的词根直接砍掉.
停止词 Stopwords
停止词也叫停用词, 在英语里面遇到的a, the, or 等使用频率很高的词基本都是停止词. 去掉停止词后仍然可以表达出句子的意思, 去掉停止词可以节省大量的空间. 但是停止词也不是什么任务都去掉的, 比如判断文章相似度之类或者给文章打分的任务就不应该去除停止词, 因为去除后会导致句子结构发生变化.
特征工程 Feature Engineering
基本语义特征
主要是一些句子上的差别. 将各种描述句子的特征加加减减.
问题1和问题2的符号差异, 问号差异, 问题1和问题2分别的句子长度, 长度差异, 长度差异率, 字符数量差异, 字符差异率, 情感分析差异, 起始词(疑问词)的差异, 共享词的交, 并, 数量差异, 数量差异率, fuzz_qratio, fuzz_WRatio, fuzz_partial_ratio, partal_token_sort_ratio, token_set_ratio…
距离特征有cosine_word2vec, cityblock_distance, canberra_distance, euclidean_distance, braycurits_distance, minkowski_distance, skew_q1, skew_q2, kur_q1, kur_q2, wmd.
TF-IDF
TFIDF(Term Frequency - Inverse Document Frequency) 词频 - 逆文本频率. TF即词的词频, IDF可以帮助我们理解这个词的重要程度.
TF(Term Frequency): 一个term在文档中出现的频繁程度. 但是词频并不能反映这个词语的重要性, 有时候它们出现很多次, 但却没有什么意义比如停用词, 没有意义的词语没法起到文本分类的作用.
对于词语$i$, 在文档$j$ 有:
$$
TF_{i, j} = \frac{n_{i, j}}{\sum_k n_{k, j}} = \frac{某个词在文章中出现的次数}{文章的总词数}\
$$
所以就需要将他们乘个缩放因子, 来平衡掉出现次数过多但无意义的影响.
IDF(Inverse Document Frequency) 逆文档频率, 它与一个词常见程度成反比, 这样越普遍的词语, 越没有实际意义. 对于语料库文章总数$\left| D\right|$, 包含词语$j$ 的文档数$\left| j:t_i \in d_j \right|$ 有:
$$
IDF_i= \log{\frac{\left | D \right |}{1+\left| j:t_i \in d_j \right|}} = \log{\frac{语料库的文档总数}{包含该词的文档数+1}}
$$
加1是为了规避词语不在语料库中分母为0的情况.
而TF-IDF就是TF和IDF的乘积. 能够看出来, 某个词语在某篇文章出现的次数越多越重要, 在所有文章中出现的次数越多越不重要.
$$
TFIDF = TF \times IDF
$$
但是TF-IDF也有缺陷, 它忽略了文本中词语的位置信息. 有些文章的段首明显句首的权重更高. 其次有些文章的关键词可能只出现了1-2次.
词袋模型 Bag of words model
词袋模型(Bag of words model) 将每段文本都由装着词的袋子表示, 对于比如对于以下文本:
- John likes to watch movies. Mary likes movies too.
- John also likes to watch football games.
能够生成一个含有10个不同词语的词表:
[John, likes, to, watch, movies, also, football, games, Mary, too]
然后结合单词出现的次数, 能够将句子表示为:
- [1, 2, 1, 1, 2, 1, 1, 0, 0, 0]
- [1, 1, 1, 1, 0, 0, 0, 1, 1, 1]
词袋模型能够将文本转化为向量, 但是却没有保留文本之间的语序, N元语法对这个问题进行了改善.
N-Gram
N元语法(N-Gram)基于N-1马尔科夫假设, 即句子中的第$n$个单词被认为和前$m$个单词相关, 即:
$$
P(x_1, x_2,… , x_n) = P(x_1)P(x_2|x_1)\cdots P(x_n|x_{n-m},…,x_{n-1})
$$
如果一个词出现只依赖于它前面的一个词, 称为Bi-gram, 如果依赖于前面的两个词, 称为Tri-gram.
一般就采用$N=2$或$N=3$即Bi-gram和Tri-gram. 用极大似然估计来计算频率, 有:
$$
\begin{aligned}
&p(w_n|w_{n-1})=\frac{C(w_{n-1}w_n)}{C(w_{n})}\\
&p(w_n|w_{n-1}w_{n-2})=\frac{C(w_{n-2}w_{n-1}w_n)}{C(w_{n-2}w_{n-1})}\\
&p(w_n|w_{n-1}\cdots w_2w_1)=\frac{C(w_1w_2\cdots w_n)}{C(w_1w_2\cdots w_{n-1})}
\end{aligned}
$$
举个二元语法的例子:
- oh I am Sam oh
- oh Sam I am oh
- oh I do not like eggs and ham. oh
I 出现了三次, I am 出现了两次, 所以求得$p(am|I) = \frac{C(I\ am)}{C(am)}=\frac{2}{3}$, 同样计算出:
$$
\begin{aligned}
P(I|oh) &= \frac{2}{3}, P(Sam|am)=\frac{1}{2}, P(oh|Sam)=\frac{1}{2}\\
P(do|I)&=\frac{1}{3}, P(not|do)=\frac{1}{1}, P(like|not)=\frac{1}{1}
\end{aligned}
$$
Word2Vec
Word to vector是一种浅层神经网络, 构建一个保留了单词的上下文相似性的低维向量来表示语料库中的文本. 在训练完成后, Word2Vec可以映射每个词到一个向量(也就是词向量). 词向量一般是稠密的, 低维(不像One-hot维数很高). Word2Vec是词嵌入(Word Embedding)的一种. 在词嵌入空间当中, 词意相似的词语通常具有相同的方向, 比如各种水果可能在空间中的位置类似. 值得一提的是, Embedding这种技术在人脸识别当中也叫作编码, 经常将人脸图片在空间中编码为一个向量, 与其他的向量进行比对, 也是利用相似度算法判断是否为该人, 原理实际一致.
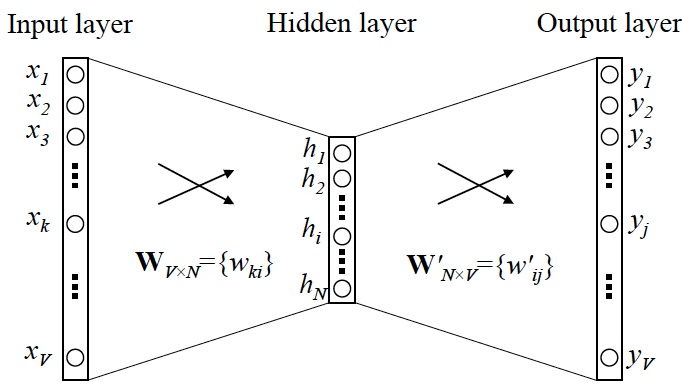
整体步骤如下:
- 在Input Layer, 某个词语被转化为One-Hot向量(高维, 稀疏)
- 在Hidden Layer, 稀疏向量被做了一次线性变换, 即$Wx+b$. 或者视为隐藏层神经元不激活.
- 获得对应词语在稠密空间的映射.
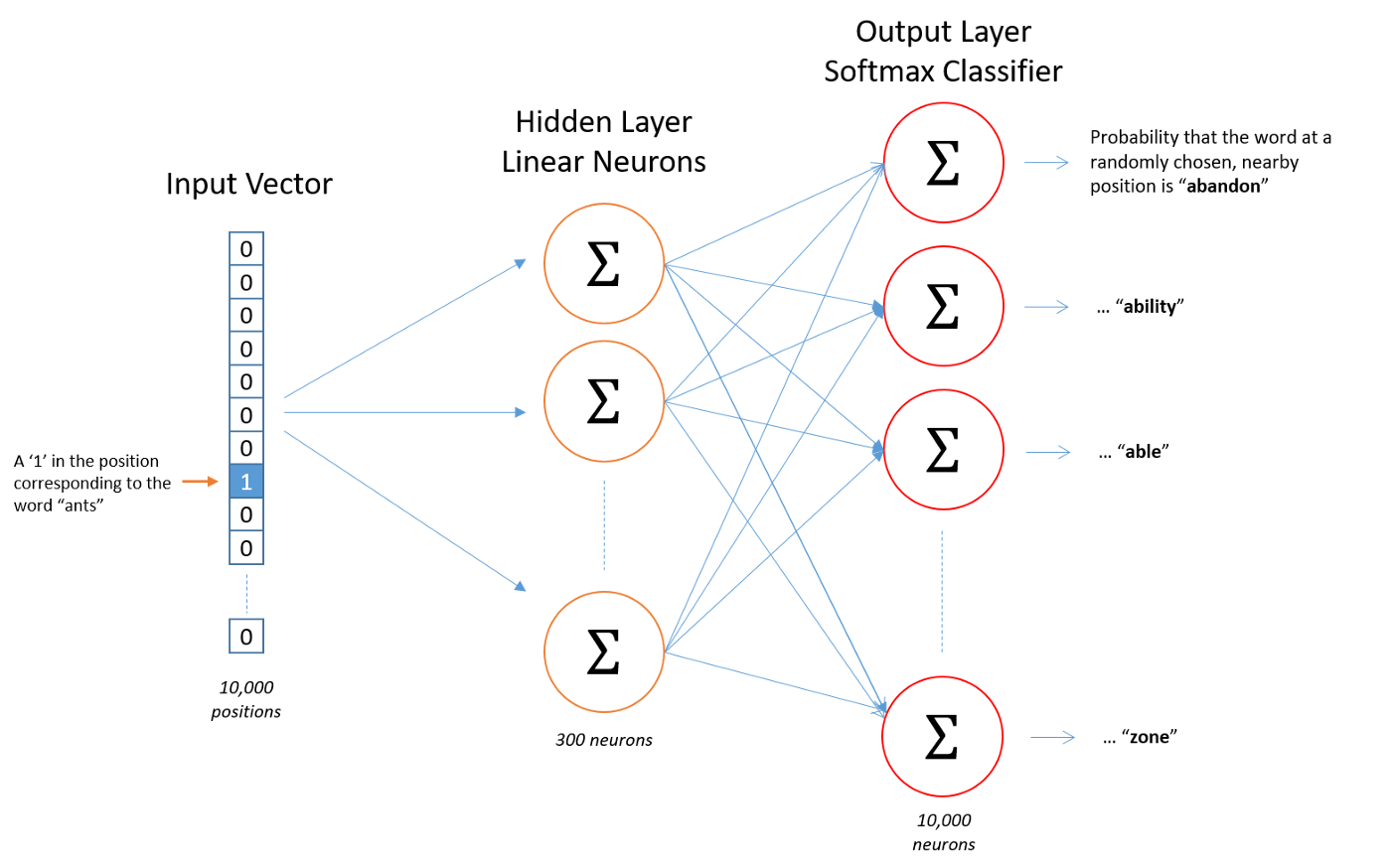
由于输入向量是一个独热稀疏向量, 那么实际上就可以直接获得Hidden Layer中的唯一神经元权重被激活, 也就对应了唯一的词向量, 完成这个映射过程, 也就获得了这个词所对应的embedding形式. 如下图左侧矩阵是某个词的独热向量, 右侧是词嵌入矩阵, 二者做矩阵乘法可以获得这个词所对应的嵌入式表示.

Xin Rong制作了展示词嵌入是如何训练的的网站.
现在基本上Word2Vec有两种变体用的是最多的, 一种是CBOW, 一种是Skip-gram. 两种算法在进行优化时所采用的函数不同, 这二者的结构是完全相反的. 详见原论文.
CBOW
CBOW(Continuous Bag-of-Words Model), CBOW是通过上下文来预测中心词. 即在已知上文$w_{t-c}, w_{t-c+1}, \dots, w_{t-1}$和下文$w_{t+1}, w_{t+2}, \dots, w_{t+c}$1的情况下预测中心词$w_t$.
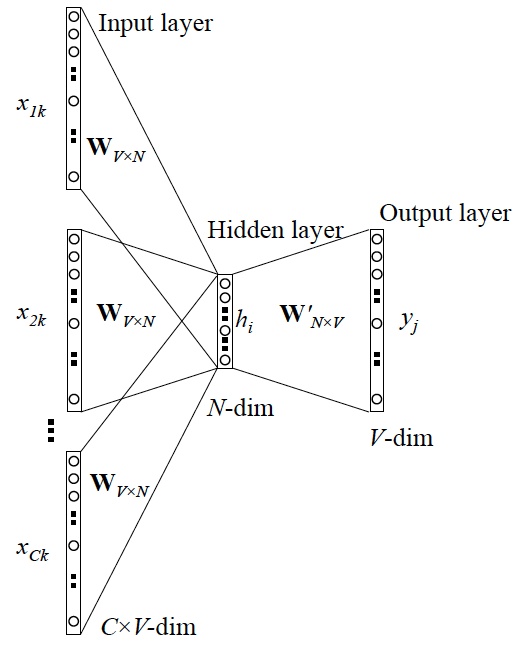
在中间的隐藏层中, 我们对$w_{t-c}, \dots, w_{t-1}, w_{t+1}, \dots, w_{t+c}$的向量相加, 并除以$2c$. 最终输出层经过Softmax得到一个近似独热的向量.
根据极大似然, 对于单词集合$T$, 最终要最大化:
$$
L=\frac{1}{T}\sum_t{\log{P(w_t|w_{t-c}\cdots w_{t+c})}}
$$
Skip-Gram
Skip-gram通过中心词预测上下文.
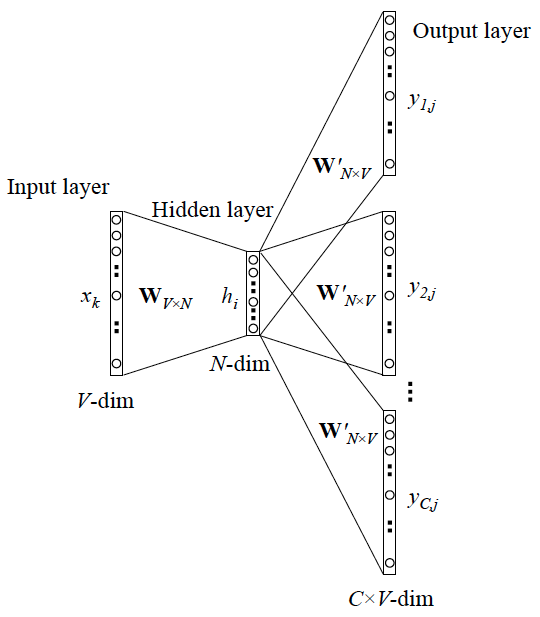
最后也是通过Softmax得出来很多近似独热的向量, 也是最大化如下函数:
$$
J=\frac{1}{T}\sum_{t=1}^T{\sum_{-c \leq j \leq c, j \neq 0}{\log p(w_{t+j}|w_t)}}
$$
相似度算法
余弦相似度
对于余弦$\cos$想必都是了解的, 其实余弦相似度就是通过两个向量之间的余弦值来衡量相似度. 两个向量越不相似, 夹角就越大, 余弦值也越大. 这个向量可以是来自于任何文本向量化后的向量(比如TF-IDF和Word2Vec).
由向量内积:
$$
a\cdot b = \vert \vert a \vert \vert \ \vert \vert b \vert \vert \cos{\theta}
$$
有:
$$
similarity = \cos{\theta} = \frac{A \cdot B}{\vert\vert A\vert\vert \ \vert\vert B\vert\vert} = \frac{\sum\limits_{i=1}^nA_i\times B_i}{\sqrt{\sum\limits_{i=1}^n(A_i)^2}\times \sqrt{\sum\limits_{i=1}^n(B_i)^2}}
$$
相似度的范围在$(-1, 1)$之间, 1表示它们完全相同, 0表示相互独立, -1表示完全相反. 如果是$TF-IDF$下的向量, 由于不能为负数, 两个向量角度不大于90度.
Jaccard相似度
Jaccard相似度是在没有将文本数据向量化之前的一种度量. 它处理的是集合, 在NLP问题上就是两个句子的词语集合. Jaccard相似度是由Jaccard系数引出来的.
$$
\displaylines{
J(A, B) = \frac{|A \cap B|}{|A \cup B|}\\
d_j(A, B) = 1 - J(A, B) = \frac{|A \cup B| - |A\cap B|}{|A \cup B|}
}
$$
与余弦相似度不同的是, 面对重复的词, Jaccard相似度不会有影响, 因为它是集合上的运算, 自带去重的效果, 如果是余弦相似度则会受到影响.
词移距离
词移距离WMD(Word Move Distance)是基于Word2vec特性开发出来的, 当单词经过Word2Vec映射成一个词向量的时候, 语义相近的单词距离会比较近, 比如king和queen在词向量空间中的距离就比sky和apple的近.
我在项目中用到的是直接用所有单词的词向量加权求和, 然后再用欧氏距离进行比较, 就能衡量两个句子的相似度, 还有用TF-IDF作为权重, 加权求和. 但是词移距离后续的叙述很麻烦, 不再详细说了, 因为涉及到求解和词转移代价等.

