目标检测
目标检测是CV里一个重要方向, 对于一张图片, 我们应该能够给出图中含有的物体(单个或多个)的位置以及他们的大小和类别.
目标定位
假设我们已经能够利用CNN对一张图片是否含有某个物体而进行分类. 应该先搞清楚要的输出是什么.
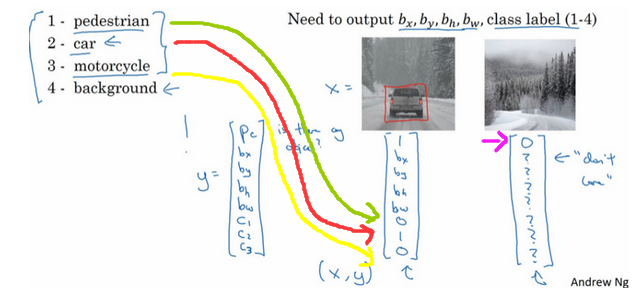
在上图的例子中, $P_c$为图中是否有物体, $b_x, b_y, b_w, b_h$分别为物体的x, y, width, height即物体的未知参数, 有了它们就能画出物体的边界框bounding box, $C_1, C_2, C_3$是是否属于图中所示的三个类. 如果$P_c$为0, 那么剩下的数据也不用关心了.
特征点检测
根据目标定位的原理, 我们甚至可以手动要求神经网络输出某些特殊的位置信息, 叫做特征点.
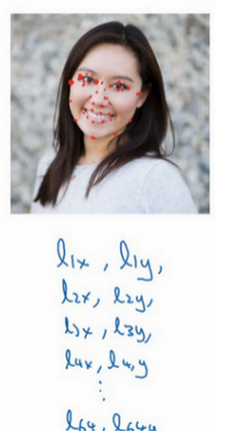
是否有人脸, 特征点对组成了神经网络的输出, 每个特征点对都可用$l_x, l_y$来表示. 然后可以根据得到的特征点位置来进行判断, 比如说人物的表情, 或其他人物面部分析等, 同理也可以左人体的体态识别. 当然数据集必须有人为标注的特征点位置.
滑动窗口实现
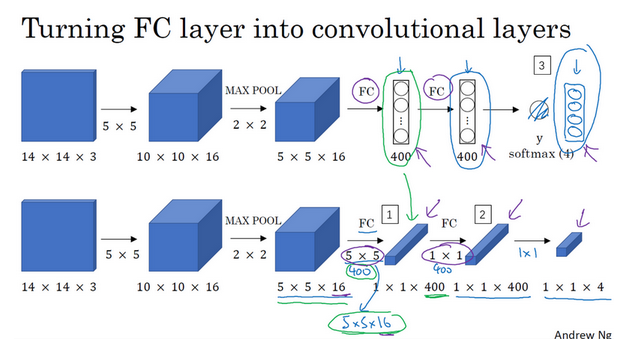
这里介绍了一种将神经网络替换成卷积神经网络从而降低参数个数, 但达到相同效果的方法, 即全卷积神经网络, 利用$1\times1$卷积代替稠密神经网络. 这里不再赘述.
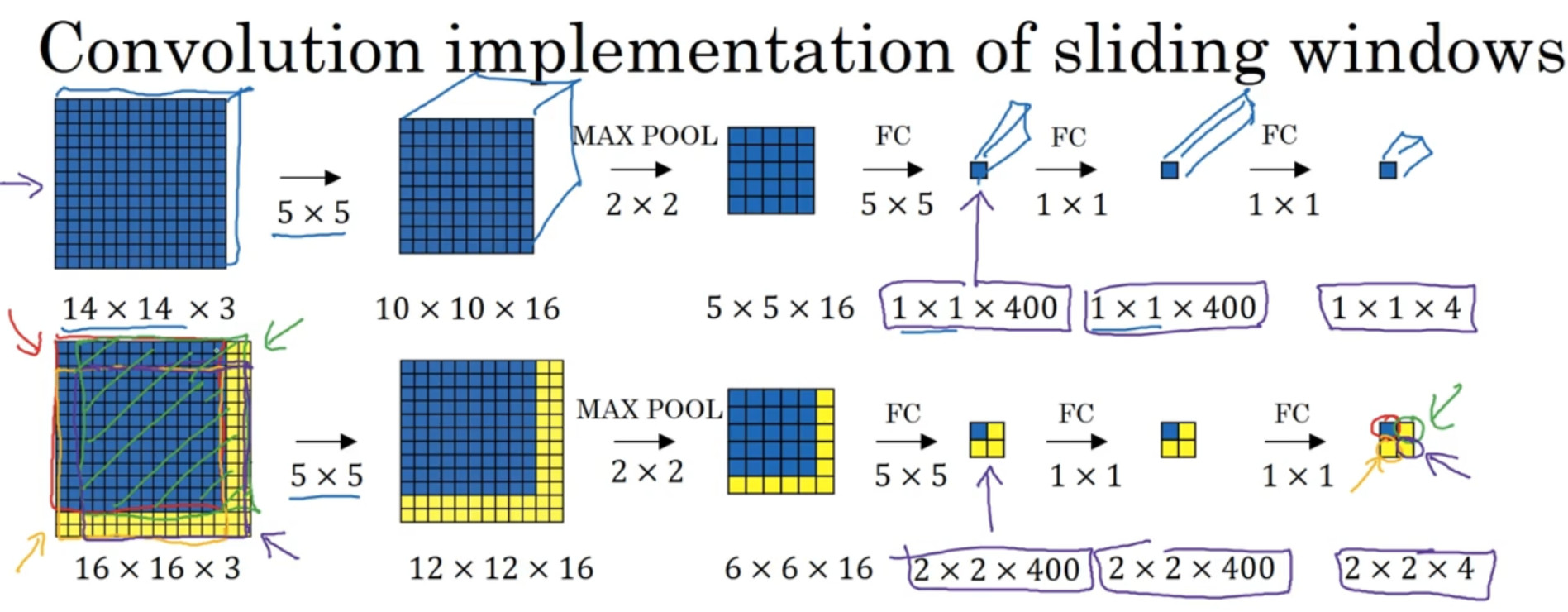
对一个$16\times 16$的图片进行卷积时, 如果我们的网络接受的输出是$14\times 14$的, 无需把原图片拆分成4个$14\times 14$的子集, 因为这样做会引入很高的卷积重复率和训练成本. 直接将$16\times 16$的图片作为一个整体, 所有原来的参数不变, 仍然进行卷积, 只是说最终的输出不再是$1\times 1$而是$2\times2$, 一次性计算就能完成上面四次计算的结果.
Bounding Box
在上面已经了解了用卷积确定物体在图片中的位置, 以及物体的类别. 但是对于物体的具体位置, 不能用图片粗略的窗口划分代替物体的位置, 明显和物体的真实位置是不匹配的.
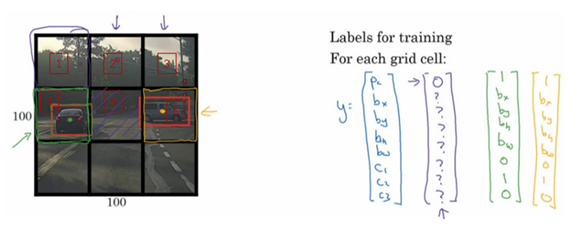
假设将图片分为$3\times3$的区域, 每个区域会产生一个列向量, 内容和我们前面说过的预测值相同. 一张图就会产生$3\times3\times8$的结果. Yolo会取对象的中点, 将该对象分配给对象中点的格子.
交并比
交并比是用来衡量边界框是否标注正确的函数. 函数非常简洁, 假设我们预测的边界框$A$和物体的真实边界框$B$, 交并比$IoU$为:
$$
IoU = \frac{A\cap B}{A\cup B}
$$
在CV里, 一般约定俗成的说, 如果$IoU\geq 0.5$视为检测正确.
非极大值抑制
非极大值抑制可以保证每个物体只被检测一次. 如果采用比较细的划分, 可能物体会比每个划分出来的网格大, 那么每个网格都认为物体的中心在自己的格中, 这样物体就被计算了很多次.
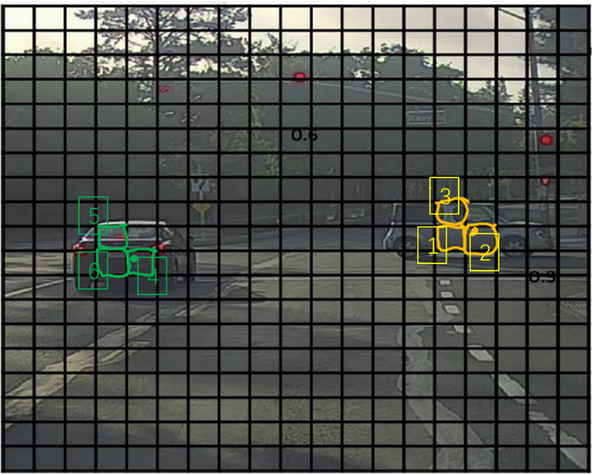
非极大值抑制会取概率最高的$P_c$格子(如果是预测多个类别, 那么$P_c$为多个类的概率的乘积), 并去掉周围$IoU$很高的一圈bounding box, 得到最终的结果.
- 按照置信度对所有候选框进行排序
- 将置信度最高的候选框添加到输出候选框列表中, 并将其从输入候选框中删除
- 计算挑选出的候选框与当前所有输入候选框之间的IoU
- 删除IoU大于阈值的输入候选框
- 重复第2-4步, 直到输入候选框列表为空
Anchor Boxes
Anchor解决了一个格子只能预测一个对象的问题, 使得其能检测多个对象. Anchor boxes是一种预先加载对象的形状的边界框, 将预测标签进行扩展, 每个anchor box对应一个bounding box的参数量.

每个对象除了被分配到一个格子中, 还被分配到一个和对象形状交并比最高的anchor box中.

