XGBoost
XGBoost是Extreme Gradient Boosting的缩写, 作者是陈天奇大神. XGB因为其高准确率, 易于使用而在各类数据科学竞赛譬如Kaggle, 天池等十分流行. XGB与GBDT十分相似, 可以将XGB视为是GBDT的一个优化形式. 事实上, 如果不考虑工程实现和解决问题上的一些差异, XGB与GBDT比较大的不同就是目标函数的定义.
背景知识
模型和参数
对于最为常见而简单的线性模型来说, 其预测值为:
$$
\hat{y}_i = \sum_j \theta_j x_{ij}
$$
对不同的任务和模型来说, $\theta$ 有着不同的含义. 这个$\theta$ 是模型中不确定的部分, 我们需要通过反复学习来调整它使得它趋近于最优.
目标函数
对于一般的任务来说, 在训练时就是要找到一个最优参数$\theta$ 使得预测的效果最好. 定义一个目标函数来衡量与训练数据的拟合程度.
$$
\text{obj}(\theta) = L(\theta) + \Omega(\theta)
$$
其中$L$ 是训练损失函数, $\Omega$ 是正则项. 一般来说损失函数有多种选择, 例如大多数梯度提升算法的MSE:
$$
L(\theta) = \sum_i (y_i-\hat{y}_i)^2
$$
或者Logistics损失:
$$
L(\theta) = \sum_i[ y_i\ln (1+e^{-\hat{y}_i}) + (1-y_i)\ln (1+e^{\hat{y}_i})]
$$
正则项的作用是通过约束模型的复杂度而避免过拟合, 一个模型过于复杂时, 它的泛化能力会被约束, 当预测新的没见过的数据时能力会大打折扣. 换言之, 一个好的模型会在方差和偏差之间达到平衡.
L1正则:
$$
\Omega(w)=\sum_i^W|w_i|
$$
L2正则:
$$
\Omega(w)=\sum_i^Ww_i^2
$$
回归树 CART
CART(Classification And Regression Tree)是XGB的基学习器. 在XGB官网上给出了一个讲解CART回归树的例子, 利用CART来预测谁会玩电脑游戏.
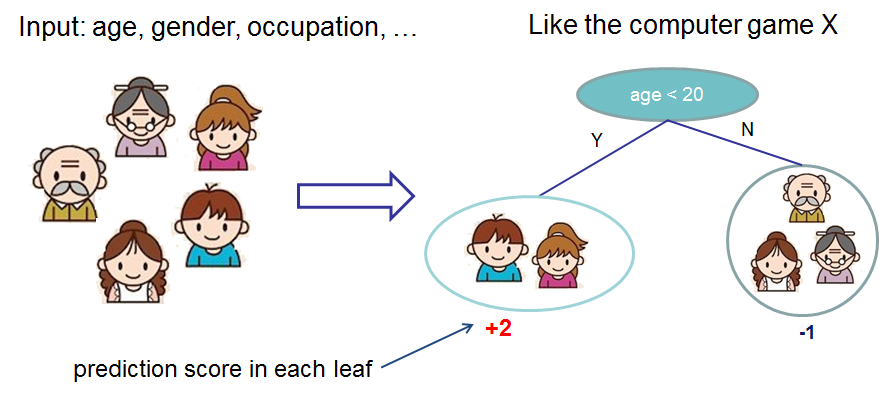
CART利用输入的特征来划分输入样本, 并在每个叶子节点上都有一个预测权重, 这与分类决策树有些不同.
树每次进行划分, 实际上是将搜索空间进行分割:
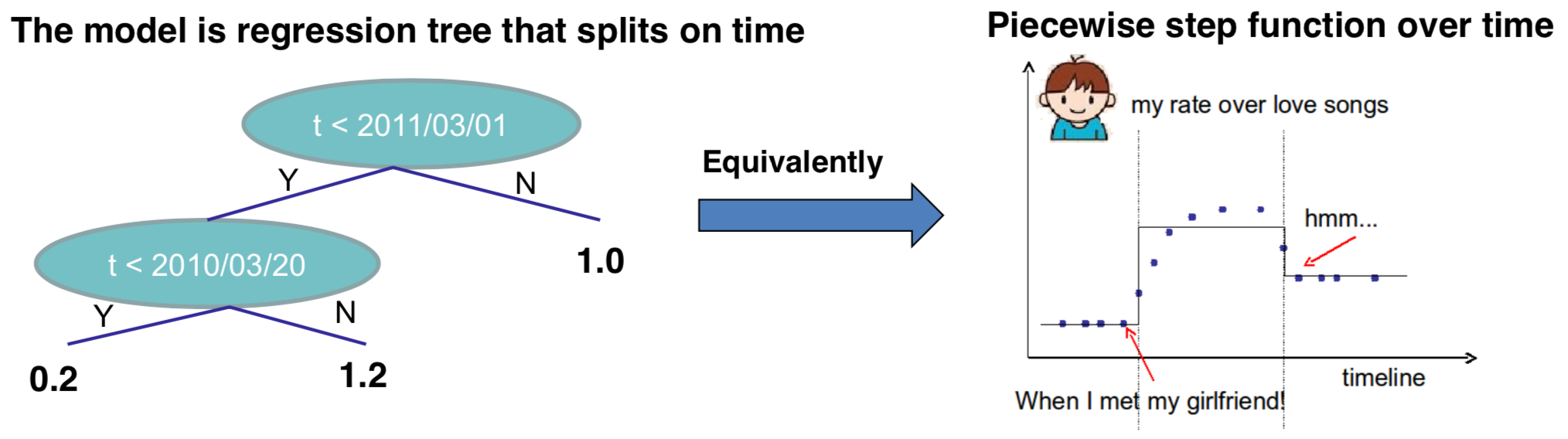
通常, 一棵树的预测能力不够强大, 所以需要将多棵树集成起来.

将这两棵树的得分都加起来, 发现小男孩的得分是最高的. 事实上这两棵树在做互补的工作. 假设我们有$K$ 棵树, 分类函数为$f$, $\mathcal {F}$ 是包含所有回归树的函数空间, 那么对于第$i$ 类最终的预测值$\hat{y_i}$为:
$$
\hat{y}_i = \sum_{k=1}^K f_k(x_i), f_k \in \mathcal{F}
$$
最终的目标函数就变成了:
$$
\text{obj}(\theta) = \sum_i^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \Omega(f_k)
$$
我们必须要求出来的其实就是$f_k$, 一旦有了这个函数, 就能得知树的结构和叶子节点所对应的权值.
回归树的优势:
- 应用广泛,比如 GBM 和随机森林等。几乎一半的数据挖掘比赛获胜者都是靠树的集成方法取胜的
- 你不需要将特征标准化,因为做不做输入特征缩放结果是一样的.
- 能够学习到更多特征之间的高阶关系.
- 具有可扩放行(scalable),应用于工业界.
树的提升
前面已经介绍完了基学习器, 接下来该说说如何训练它们了. 对于时间步$t$, 目标函数就变成了:
$$
\text{obj} = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t)}) + \sum_{i=1}^t\Omega(f_i)
$$
增量训练
在XGB中, 作者指出学习树的结构比传统优化问题要困难得多, 并且一次性的学习到所有树结构很难, 所以在这里采用了一次向上加一棵树的策略:
$$
\begin{split}\hat{y}_i^{(0)} &= 0\\
\hat{y}_i^{(1)} &= f_1(x_i) = \hat{y}_i^{(0)} + f_1(x_i)\\
\hat{y}_i^{(2)} &= f_1(x_i) + f_2(x_i)= \hat{y}_i^{(1)} + f_2(x_i)\\
&\dots\\
\hat{y}_i^{(t)} &= \sum_{k=1}^t f_k(x_i)= \hat{y}_i^{(t-1)} + f_t(x_i)\end{split}
$$
这实际上使得XGB每次都去拟合残差, 也就是预测值和真实值之间的差.
在每次训练都要优化目标函数:
$$
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t)}) + \sum_{i=1}^t\Omega(f_i) \\
& =\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\right)+\Omega\left(f_{t}\right)+\text { constant }\end{split}
$$
假设MSE为损失函数, 代入目标函数式:
$$
\begin{split}\text{obj}^{(t)} & = \sum_{i=1}^n \left(y_i - (\hat{y}_i^{(t-1)} + f_t(x_i))\right)^2 + \sum_{i=1}^t\Omega(f_i) \\
& = \sum_{i=1}^n [2(\hat{y}_i^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + \mathrm{constant}\end{split}
$$
这里的$\hat{y}_i^{(t-1)} - y_i$就是上一轮的残差. 这里MSE体现出非常好的数学性质, 它既含有$f_t(x_i)$ 的一次项, 也含有二次项, 这对求出新树结构非常有帮助. 但是对于其他损失函数不一定能够获得这么好的数学性质, 因此一般都是通过泰勒展开来获得这个一次项和二次项. 不知你还记得不记得二阶泰勒展开:
$$
f(x+\Delta x) \approx f(x)+f^{\prime}(x) \Delta x+\frac{1}{2} f^{\prime \prime}(x) \Delta x^{2}
$$
因为我们每过一个时间步$t$ 拟合的都是残差, 所以我们可以把新加入的$f_t(x_i)$ 看做是$\Delta x$, $\hat{y}_{i}^{(t-1)}$ 看做是$x$, 就能将损失函数展开:
$$
l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\right)=l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)
$$
其中的$g_i$ 和$h_i$ 分别是$f_t(x_i)$ 的一阶偏导和二阶偏导:
$$
\begin{split}g_i &= \frac{\partial l(y_i, \hat{y}_i^{(t-1)})}{\partial{\hat{y}_i^{(t-1)}}}\\
h_i &= \frac{\partial l(y_i, \hat{y}_i^{(t-1)})}{\partial^2{\hat{y}_i^{(t-1)}}} \end{split}
$$
注: 这步能够展的原因是$y_i$ 是一个常数, 其实$l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\right)$ 只是一个与$\hat{y}_{i}^{(t-1)}$ 和$f_t(x_i)$ 相关的函数.
目标函数就变成了:
$$
\begin{split}
\text{obj}^{(t)} & = \sum_{i=1}^n l(y_i, \hat{y}_i^{(t)}) + \sum_{i=1}^t\Omega(f_i) \\
& =\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\right)+\Omega\left(f_{t}\right)+\text { constant } \\
& = \sum_{i=1}^n [l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t) + \mathrm{constant}
\end{split}
$$
对于每个新的时间步$t$, 上一个时间步$t-1$所对应的损失$l(y_i, \hat{y}_i^{(t-1)})$是一个常数, 去掉目标函数中所有与优化无关的常数部分:
$$
\sum_{i=1}^n [g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)
$$
模型复杂度
XGB在正则项这里对树模型的生长加以约束. 对于树模型, $T$ 为叶子节点的总数, 设$w$ 为叶子节点的权重序列, 是一个$T$ 维的向量, $q$ 为树的结构, 那么$q(x)$ 就能表示样本$x$ 落在叶子中的位置, $w_{q(x)}$ 就是叶子中样本$x$ 所对应的权重. $d$ 为输入实例的维数.
$$
f_t(x) = w_{q(x)}, w \in R^T, q:R^d\rightarrow \{1,2,\cdots,T\}
$$
例如:
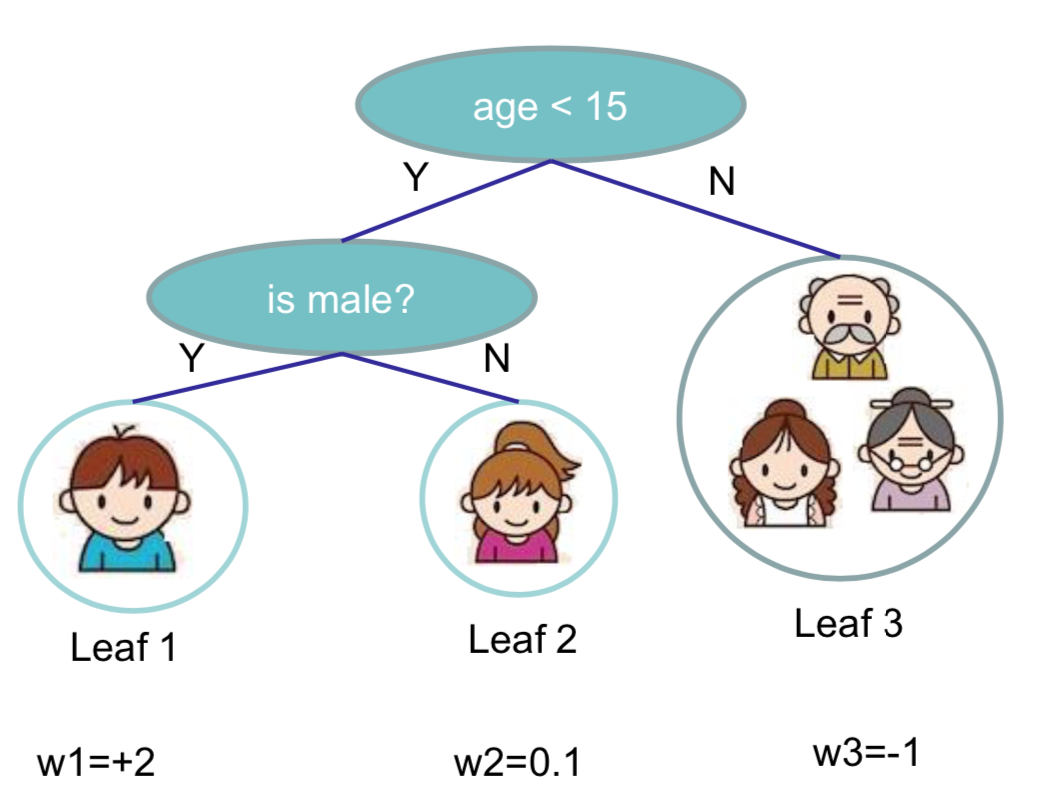
在XGB中, 定义正则项如下:
$$
\Omega(f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2
$$
第一项为叶子节点的数目, 第二项为叶子节点权重的L2范数. 那么在上面那个例子中, 正则项$\Omega$ 为:
$$
\Omega = 3\gamma + \frac{1}{2}\lambda(4+0.01+1)
$$
假设用$I_j = \{i|q(x_i)=j\}$ 来表示叶子节点$j$ 的样本集, 其中包含叶子$j$ 的所有样本$x_i$. 将其从$i$ 表示转化为用$j$ 表示的形式:
$$
\begin{split}
\text{obj}^{(t)} & \approx \sum_{i=1}^{n}\left[g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\Omega\left(f_{t}\right) \\
&=\sum_{i=1}^{n}\left[g_{i} w_{q\left(x_{i}\right)}+\frac{1}{2} h_{i} w_{q\left(x_{i}\right)}^{2}\right]+\gamma T+\gamma \frac{1}{2} \sum_{j=1}^{T} w_{j}^{2} \\
&=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\gamma\right) w_{j}^{2}\right]+\gamma T\end{split}
$$
并定义$G_j = \sum_{i\in I_j} g_i ,\quad H_j = \sum_{i\in I_j} h_i$, 则原目标函数又可以写为:
$$
\text{obj}^{(t)} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T
$$
树的结构如果是已经固定的, $G_j$ 和 $H_j$ 就是可以计算的了. 此时目标函数就是一个关于$w_j$ 的一元二次方程, 直接利用最值公式得解:
$$
\begin{split}w_j^\ast &= -\frac{G_j}{H_j+\lambda}\\
\text{obj}^\ast &= -\frac{1}{2} \sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T\end{split}
$$
下面是一个计算$\text{obj}$ 的例子:

分数越小, 结构就越好.
学习树结构
优化工作已经基本做完了, 但是还没有提到如何确定一棵树的结构. XGB使用了和CART回归树一样的想法, 遍历所有特征的所有特征划分点, 但使用的目标函数不一样. 利用贪心算法, 不断地枚举不同树的结构, 然后利用打分函数来寻找出一个最优结构的树, 接着加入到模型中, 不断重复. 叶子分裂也是依赖于分裂前后的$\text{obj}$ 而决定的. 分裂后需要检测这次分裂是否会给损失函数带来增益:
$$
\begin{split}
Gain &= \text{obj}_{L+R} - (\text{obj}_L + \text{obj}_R) \\
& = [-\frac{1}{2} \frac{(G_L+G_R)^2}{H_L+H_R+\lambda}+\gamma] - [-\frac{1}{2} (\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda})+ 2\gamma ] \\
&=\frac{1}{2} \left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma
\end{split}
$$
分裂前后的信息$Gain$ 是如何理解的? $Gain$ 实际上是分裂后的信息减去了分裂包含的信息, 也就是目标函数$Obj$ 的相反数. 不分裂则视$L+R$ 为一个整体. 所以才有了$Gain$ 中的第三项.
如果分裂后$Gain>0$ , 说明这次分裂能够使得目标函数下降. 如果$Gain<0$, 说明分裂不能使得目标函数下降, 这次分裂失败了.
找到最优分枝点的有效方法其实就是在排序后的实例上从左到右线性地扫描, 这样就足以决定按此特征的最佳分割. 以年龄作为特征为例:
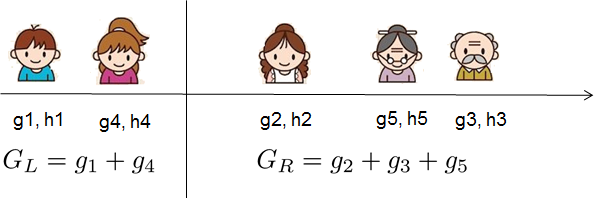
只要求出每一边的$G$ 和$H$ 的和, 然后计算$Gain$, 就能找到分枝点.
使用
XGB用Python就可以非常简单的使用.
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' }
num_round = 2
bst = xgb.train(param, dtrain, num_round)
# make prediction
preds = bst.predict(dtest)总结

- XGBoost官方文档 - 强推
- XGBoost论文
- 这篇博客也翻译的非常非常棒, 可以多读一下.
- 在知乎高赞中曾经有一篇文章写的不错, 原作者的博客已经无法使用了, 但在CSDN上有人曾转载过.
- 20道XGB面试题
- XGBoost的工程师手册

