A Frustratingly Easy Approach for Entity and Relation Extraction
本文是论文A Frustratingly Easy Approach for Entity and Relation Extraction 的阅读笔记和个人理解. 论文来自NAACL 2021. 本文为RTE问题中, 探讨NER和RE任务间关系的系列三部曲中的第二篇.
Basic Idea
最近的工作对NER和RE引入了联合训练, 即将NER和RE在多任务学习下一起解决. 并且联合模型经常使用同一个共享的Encoder解码, 解决问题的效果也都还不错, 这使得人们认为共享Encoder能够更好的解决这两个任务, 且认为联合模型能缓解错误误差传递的问题.
作者认为, Pipeline模型不一定真弱于联合学习模型. 因此希望构建一个简单的Pipeline模型来击败联合学习模型的SOTA, 来打破人们的固有观念.
PURE
PURE(the Princeton University Relation Extraction system)简单的分为实体模型和关系模型两部分, 训练时完全分开训练. 因为是Pipeline, 所以关系模型使用实体的Golden Label训练.
用如下一张图可以简单概括:

- (a) 实体模型: 根据Span的表示, 判断给定的Span的实体类型.
- (b) 关系模型: 根据Span对的表示, 判断给定的Span对的关系类型.
- (c) 批计算的关系模型: 关系模型的一种加速实现.
Problem Definition
本文所采用的方法是基于Span的方法, 因此给出基于Span的视角下问题的定义和NER, RE的定义.
对于给输入句子$X$ 含有$n$ 个Token$x_1, x_2, \dots, x_n$. 令$S$ 为$X$ 中的长度为$L$ 的Span集合, 即$S=\{s_1, s_2, \dots, s_m\}$, $\mathrm{START}(i), \mathrm{END}(i)$ 分别代表$s_i$ 的起始和结束切片Token.
- NER: 对于预定义的实体类型集合$\mathcal{E}$, 基于Span的NER任务为判断每个Span $s_i \in S$ 的实体类型$y_e(s_i) \in \mathcal{E}$, 若Span不是实体, 则记为$y_e(s_i) = \epsilon$. 任务的最终输出为$Y_e=\set{(s_i, e): s_i \in S, e \in \mathcal{E}}$.
- RE: 对于预定义的关系类型集合$\mathcal{R}$, RE任务为判断每个Span对$s_i\in S, s_j \in S$ 之间的关系类型$y_r(s_i, s_j) \in \mathcal{R}$, 若Span对之间不存在关系, 则记为$y_r(s_i, s_j) = \epsilon$. 任务最终输出为$Y_r = \set{(s_i, s_j, r): s_i, s_j \in S, r \in \mathcal{R}}$.
Entity Model

实体模型简单的建模为基于Span的模型, 先用BERT获得输入Token $x_t$ 的上下文表示$\mathbf{x}_t$, 对于某个Span $s_i \in S$, 它的表示如下:
$$
\mathbf{h}_{e}\left(s_{i}\right)=\left[\mathbf{x}_{\mathrm{START}(i)} ; \mathbf{x}_{\mathrm{END}(i)} ; \phi\left(s_{i}\right)\right]
$$
其中, $\phi{(s_i)}$ 为Span长度的Embedding.
Span的表示仅简单的使用了Span边界以及Span长度信息, 而非把Span内部所有信息全部囊括. 基于Span的模型经常只使用边界上的信息, 可能是假设边界蕴含的语义更强.
在得到Span表示$\mathbf{h}_{e}\left(s_{i}\right)$ 后, 直接用一个FeedForward Network就能预测得到实体类型的概率分布:
$$
P_{e}\left(e \mid s_{i}\right)=\operatorname{softmax}\left(\mathbf{W}_{e} \mathrm{FFNN}\left(\mathbf{h}_{e}\left(s_{i}\right)\right)\right.
$$
Relation Model
在实体模型得到了实体的Span $s_i, s_j$ 的表示$\mathbf{h}_e(s_i), \mathbf{h}_e(s_j)$ 后, 也直接接一个FeedForward Network就能预测Span间关系类型.
但作者认为, 实体模型得到的边界表示只能捕获每个单独实体周围的上下文信息, 没法感知到Span之间的依存信息, 而这种依存信息是对RE非常重要的.
所以, 作者在Span周围插入了独立的Text Marker指导模型获得Span间的依存关系:

具体来说, 对于给定的输入句子$X$ 和每个存在$e_i, e_j \in \mathcal{E} \cup \set{\epsilon}$ 的Subject - Object Span对$s_i, s_j$, 定义了四种类型的Text Marker, $\left\langle\mathrm{S}: e_{i}\right\rangle,\left\langle/ \mathrm{S}: e_{i}\right\rangle, \left\langle\mathrm{O}: e_{j}\right\rangle,\left\langle/ \mathrm{O}: e_{j}\right\rangle$, 分别插入到Subject的前后和Object的前后.
这种Text Marker除了提供了Subject和Object的角色信息, 实体边界信息, 还提供了实体类型信息.
即插入Text Marker后的输入序列$\widehat{X}$ 为:
$$
\begin{aligned}
&\widehat{X}=\ldots\left\langle\operatorname{S}: e_{i}\right\rangle, x_{\operatorname{START}(i)}, \ldots, x_{\operatorname{END}(i)},\left\langle/ \mathrm{S}: e_{i}\right\rangle \\
&\ldots\left\langle\mathrm{O}: e_{j}\right\rangle, x_{\mathrm{START}(j)}, \ldots, x_{\mathrm{END}(j)},\left\langle/ \mathrm{O}: e_{j}\right\rangle, \ldots
\end{aligned}
$$
注意, 这种Type Marker对于每个Subject - Object Span对都是在最初输入文本$X$ 上重新插入的, 每个不同的Span对都能生成一个不同的输入文本$\widehat{X}$. 这在关系判断阶段引入了巨大的计算量, 作者在后文对这一点进行了改进.
接着使用不同于实体模型的第二个Encoder捕获关系模型下Subject和Object的表示:
$$
\mathbf{h}_{r}\left(s_{i},s_{j}\right)=\left[\widehat{\mathbf{x}}_{\widehat{\operatorname{START}}(i)} ; \widehat{\mathbf{x}}_{\widehat{\operatorname{START}}(j)}\right]
$$
$\widehat{\operatorname{START}}(i), \widehat{\operatorname{START}}(j)$ 为$\left\langle\mathrm{S}: e_{i}\right\rangle, \left\langle\mathrm{O}: e_{j}\right\rangle$ 的在$\widehat{X}$ 的下标.
仅使用Text Marker的起始作为Subject和Object的表示, 在这里结束位置信息仅作为区分实体是否结束的标志.
同样的, 在表示后面用一个FeedForward Network来预测关系类型:
$$
P_{r}\left(r \mid s_{i}, s_{j}\right)=\operatorname{softmax}\left(\mathbf{W}_{r} \mathbf{h}_{r}\left(s_{i}, s_{j}\right)\right)
$$
Cross - sentence context
跨句信息对预测实体类型和关系是有帮助的.
作者简单的使用固定大小为$W$ 的滑动窗口, 来获取更长的上下文. 假设输入句子有$n$ 个单词, 则滑动窗口可以分别获得左侧和右侧的$(W - n) / 2$ 个单词作为额外上下文.
Training & inference
两个模型分别用交叉熵优化即可:
$$
\begin{aligned}
&\mathcal{L}_{e}=-\sum_{s_{i} \in S} \log P_{e}\left(e_{i}^{\ast} \mid s_{i}\right) \\
&\mathcal{L}_{r}=-\sum_{s_{i}, s_{j} \in S_{G}, s_{i} \neq s_{j}} \log P_{r}\left(r_{i, j}^{\ast} \mid s_{i}, s_{j}\right)
\end{aligned}
$$
$e_i^\ast$ 为$s_i$ 的真实实体类型, $r_{i, j}^\ast$ 为$s_i, s_j$ 间的真实关系类型.
Differences from DYGIE++
作者的方法与DYGIE++非常相似, 因此在这里强调了与它的不同:
- 作者用两个独立的Encoder分别做NER和RE任务, 而非用MTL(Multi - task Learning)的角度去看待.并且关系模型所需的实体类型信息能完全产生于实体模型.
- 引入了Text Marker, 在关系模型中Span对的表示不同.
- 使用跨句信息, 而不是使用Beam Search和图网络.
Efficient Batch Computations
在加入Type Marker时, 每个实体对都有不同的$\widehat{X}$, 即使输入的原句子$X$ 相同, 也会因为Type Marker的位置, 类型不同而必须重新计算整句表示, 这种计算开销实在是太大了, 所以作者提出了一种加速的近似模型.
首先, 把所有Text Marker全部添加到句子的尾部, 并令Text Marker与实体的起始位置, 结束位置的Position Embedding共享:
$$
\begin{aligned}
&\mathrm{P}\left(\left\langle\mathrm{S}: e_{i}\right\rangle\right), \mathrm{P}\left(\left\langle/ \mathrm{S}: e_{i}\right\rangle\right):=\mathrm{P}\left(x_{\mathrm{START}(i)}\right), \mathrm{P}\left(x_{\mathrm{END}(i)}\right) \\
&\mathrm{P}\left(\left\langle\mathrm{O}: e_{j}\right\rangle\right), \mathrm{P}\left(\left\langle/ \mathrm{O}: e_{j}\right\rangle\right):=\mathrm{P}\left(x_{\mathrm{START}(j)}\right), \mathrm{P}\left(x_{\mathrm{END}(j)}\right)
\end{aligned}
$$
$P(\cdot)$ 代表取Token的位置ID.
然后, 对Attention Layer添加约束, 强制Text Token只能Pay Attention to Text, 不能对Marker分配注意力权重, 而Marker Token可以对所有Token分配注意力.
这样就能拿到一组纯净而共享的Text表示, Text表示没有Type Marker干预.
给出一个例子:

图中Text Marker均位于句子尾部, 并且mor 和[S:Md] 共享相同的Position Embedding, ##pa 和[/S:Md] 共享相同的Position Embedding.
在运行RE模型的时候, 因为Text Token表示不再与Marker Token相关, 所以不用重复计算Text的表示, 直接用Marker表示可以一次性计算句子中所有的实体对之间的关系, 把同一个句子中的所有实体对的关系预测完全压缩到单个句子中.
Experiments
Datasets
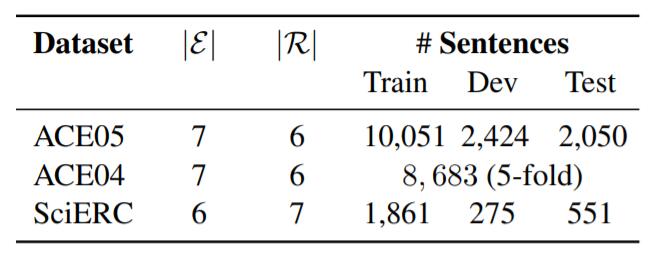
实验中使用的数据集是ACE04, ACE05, SciERC, 统计数据如下:
Main Results
在上述三个数据集上的结果如下:
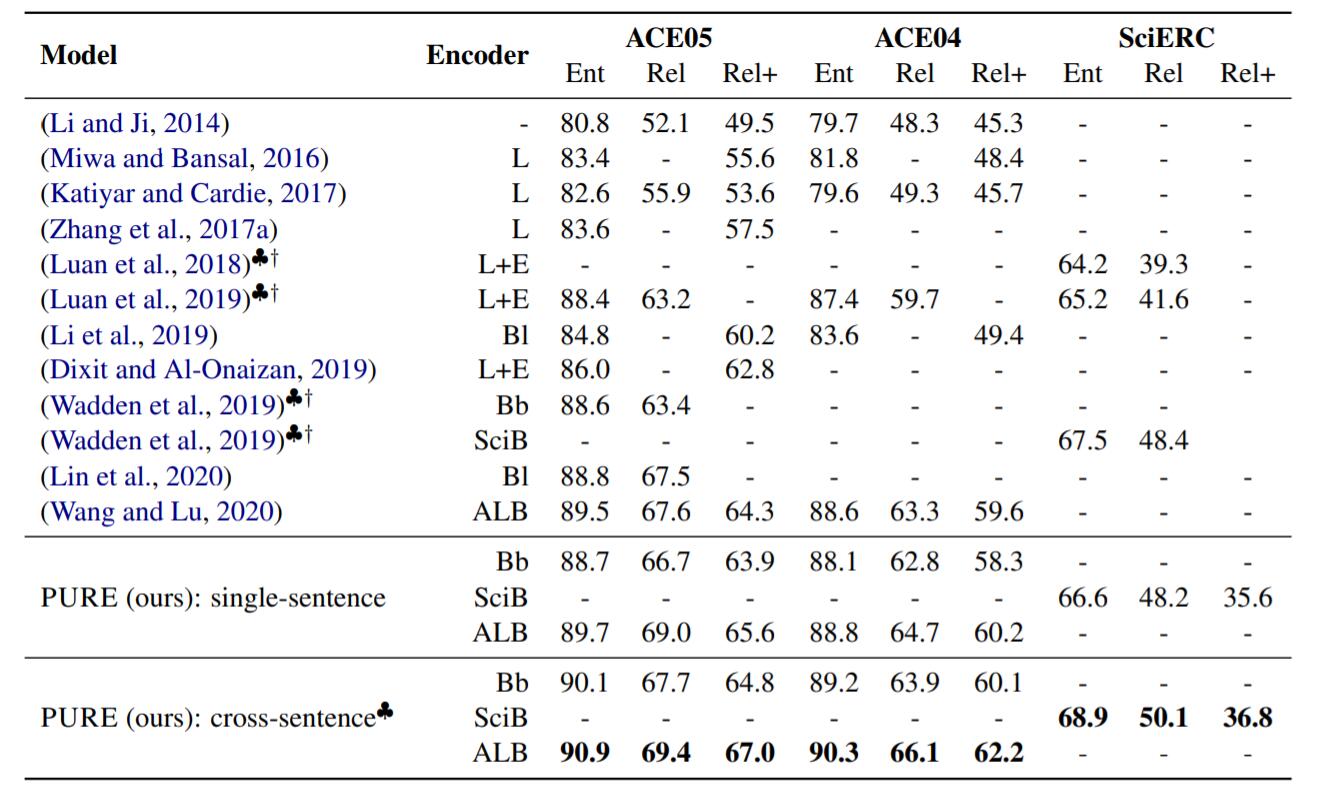
♣代表引入跨句, †代表引入额外数据. 结果中L = LSTM, L + E = LSTM + Elmo, Bb = BERT - base, Bl = BERT - large, SciB = SciBERT(规模与Bert - base相同), ALB = ALBERT - xxlarge - v1. Rel为实体边界准确且关系准确, Rel+为实体边界和实体类型, 关系均准确.
其中Wang and Lu是TSE 的结果. ALBERT下的PURE比TSE性能要好一点. Wadden是DYGIE++的结果.
在单句情况下PURE达到了SOTA, 在跨句情况下更是比单句要高上一层.
Batch Computations and Speedup
近似的关系模型效果如下:
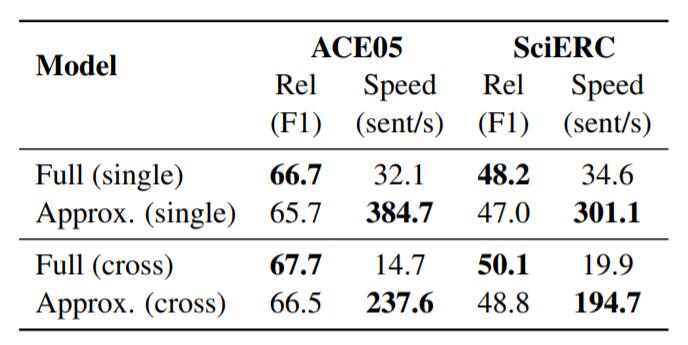
近似模型基本上掉了一个点左右, 但是耗时有明显下降.
Analysis
Importance of Typed Text Markers
不同类型的Type Markers也对关系模型性能有着影响, 在ACE05和SciERC上结果如下:
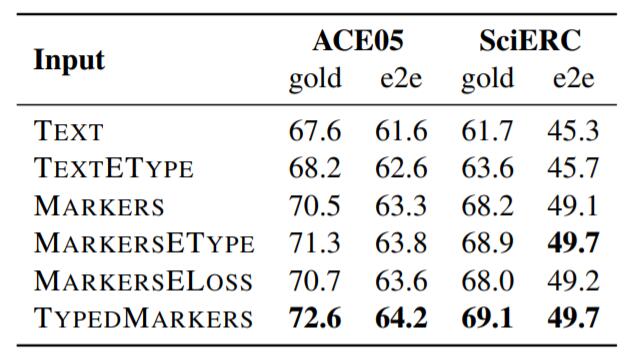
gold为使用Golden Entity, e2e代表端到端, 也就是训练时直接使用实体模型的结果.
上表对应了6种输入关系模型前的Span表示方法:
- TEXT: 直接用原Text的每个实体的的起始Token Embedding.
- TEXTETYPE: 在TEXT基础上拼接Entity Type Embedding.
- MARKERS: 使用不包含实体类型的边界Text Marker的Embedding.
- MARKERSETYPE: 在MARKERS基础上拼接实体类型Embedding.
- MARKERSELOSS: 使用不包含实体类型的边界Text Marker Embedding, 并引入一个辅助Loss, 用边界表示判断实体类型.
- TYPEDMARKERS: 正文中所使用的方法.
能看到, 不同类型的Type Markers前前后后能差出四个点来, 增益非常大.
Modeling Entity-Relation Interactions
作者探究了共享Encoder对性能的影响, 在ACE05上结果如下:
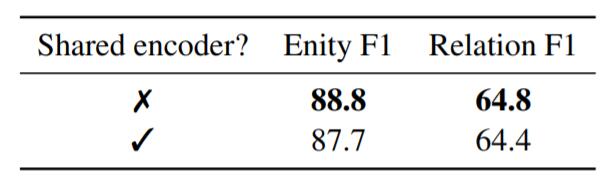
当两个模型共享Encoder联合优化时, 性能都有下降, 解释为两个任务形式不同, 使用面向单一任务的单一Encoder比共享要专一. 简单的共享Encoder对作者的方法无益.
作者在论文脚注处写到, 某些方法的作者提到共享Encoder有提升.
论文中的用词很严谨, 一是”简单共享”, 二是”对我们模型没有好处”, 个人认为对于大多数模型共享是否有害还无法一锤定音.
但是再想想, 如果使用纯Pipeline不共享Encoder, 那就有了两个独立的Encoder, 相对于共享一个Encoder来说, 多了一倍预训练参数, 涨一点性能上去是理所应当的吧?
Mitigating Error Propagation
误差的错误传播在联合抽取中一直是没有被解决的问题, 正是因为这一问题, 才提出的联合抽取模型.
作者探究了关系模型采用实体模型预测出来的实体, 而不是Golden Entity时的F1:
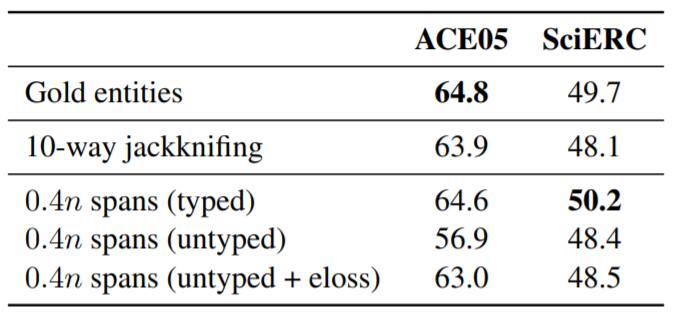
10 - way jackknifing就是十折交叉, 即为把数据划分成十份, 并且每个模型都用其中9份训练, 预测最后1份, 每个模型都对应着1份的预测结果, 把它们作为关系模型的输入, 然后训练关系模型.
结果表明使用实体模型的预测结果不如使用Golden Entity训练, 解释为实体模型的预测为关系模型在训练时带来了更多的噪声, 导致性能下降. Pipeline的曝光偏差影响或许并不像我们想的那样.
作者尝试召回更多实体, 把实体模型输出分数最高的40%作为关系模型的输入, 然后用Beam Search得到结果, 发现F1仍在下降. 结果并没有表明误差错误传播的问题存在, 同时召回更多实体在训练时也会引入更多的噪声, 因为关系模型还需要判断Span是不是实体.
Effect of Cross - sentence Context
作者研究了滑动窗口大小$W$ 对模型性能的影响:
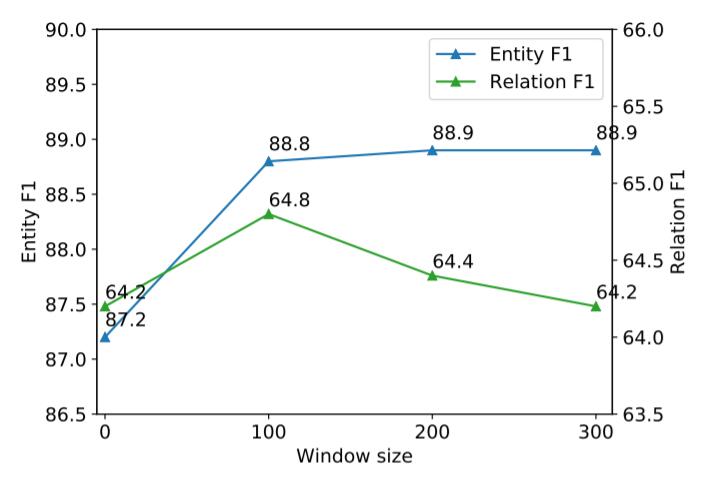
$W=100$ 后提升不大, 甚至对关系模型有负面影响.
Summary
本篇论文主要指出了基于Pipeline的模型不一定要弱于已经存在的联合抽取模型. 属于”逆行者”类论文. 在印象中, Pipeline性能是要弱于joint模型的, 因为其误差错误传播问题比较大.
本文使用两个极其简单且完全没有交互的Encoder, 用基于Span的Pipeline模型达到了联合抽取模型的SOTA效果, 并指出关系模型中的效率问题, 给出了一个近似实现. 此外, 针对联合抽取任务中Pipeline模型存在的偏见做出了探究, 奇怪的是误差的错误传播在本模型中并没有得到体现.

