Large Model并行优化
为什么要并行优化?
大就是好, 虽然丛2019年人们的认识普遍就是大就是好, 这个概念在当今依然没有被改变, 只是有了更深刻的认识.
所以, 为什么要并行?
- 虽然大就是好, 模型太大显存吃不消(空间).
- 虽然大就是好, 但是模型太大速度也吃不消(时间).
目标即难点:
- 大模型训练时, 中间过程保存的变量及参数成为负担.
- 大模型训练时, 通信开销不可忽视.
当今经典分布式并行优化方式主要有三种:
- 流水线并行(Pipeline Parallelism).
- 数据并行(Data Parallelism).
- 张量并行(Tensor Parallelism).
数据并行 Data Parallelism
顾名思义, 数据并行(DP)是直接在Batch的维度上进行划分, 将多个Batch拆分到多个节点上进行计算.
参数服务器 Parameter Server
数据并行最经典的例子是参数服务器(Server), 会在每个节点(Wokrer)上都存储同一份模型, 然后将Batch下放到每个不同的Wokrer上, 完成Forward和Backward, 最后将每个Wokrer算完的梯度回传到一个参数服务器上, 由参数服务器聚合各节点的梯度, 再将聚合后的梯度 / 新的模型参数 广播到各个Wokrer上:
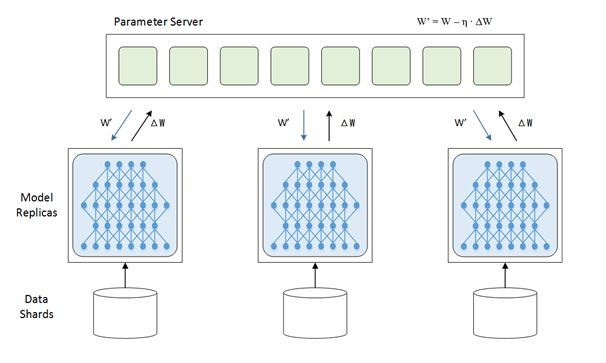
各个计算节点(Wokrer) 将梯度上传到参数服务器之后, 参数服务器可能会有两种实现:
- PS计算平均梯度(或加权梯度), 并代替各Worker完成模型参数更新, 之后将参数下放到各计算节点中.
- PS代替仅仅计算平均梯度(或加权梯度), 但不更新模型参数, 而是将计算完的梯度下放到各个Worker当中, 由各个节点自主更新各节点上的模型参数.
而聚合梯度外加下放梯度这个过程, 被称为”AllReduce“.
由于计算体系内的带宽各不同, 主要考虑AllReduce的开销, 不同的参数服务器聚合方式可能会产生不同的耗时.
数据并行在每个Worker上都存放了一份模型参数, 所以其实造成了大量冗余, 并且Server需要向每个Worker都传输一份梯度 / 模型参数.
所以, 每当Worker在接收参数或者梯度的时候, 一直在空转, 造成了利用率不高. 为了避免这种情况, 可以将梯度异步更新, 让Worker拿旧的模型参数来跑新的数据, 但是异步也不能太异步, 可以设定一个延迟步数来保证权重不会太久没有发生更新.
异步更新由于拿到的梯度不稳定, 会减缓收敛速度, 发散的风险也提高了.
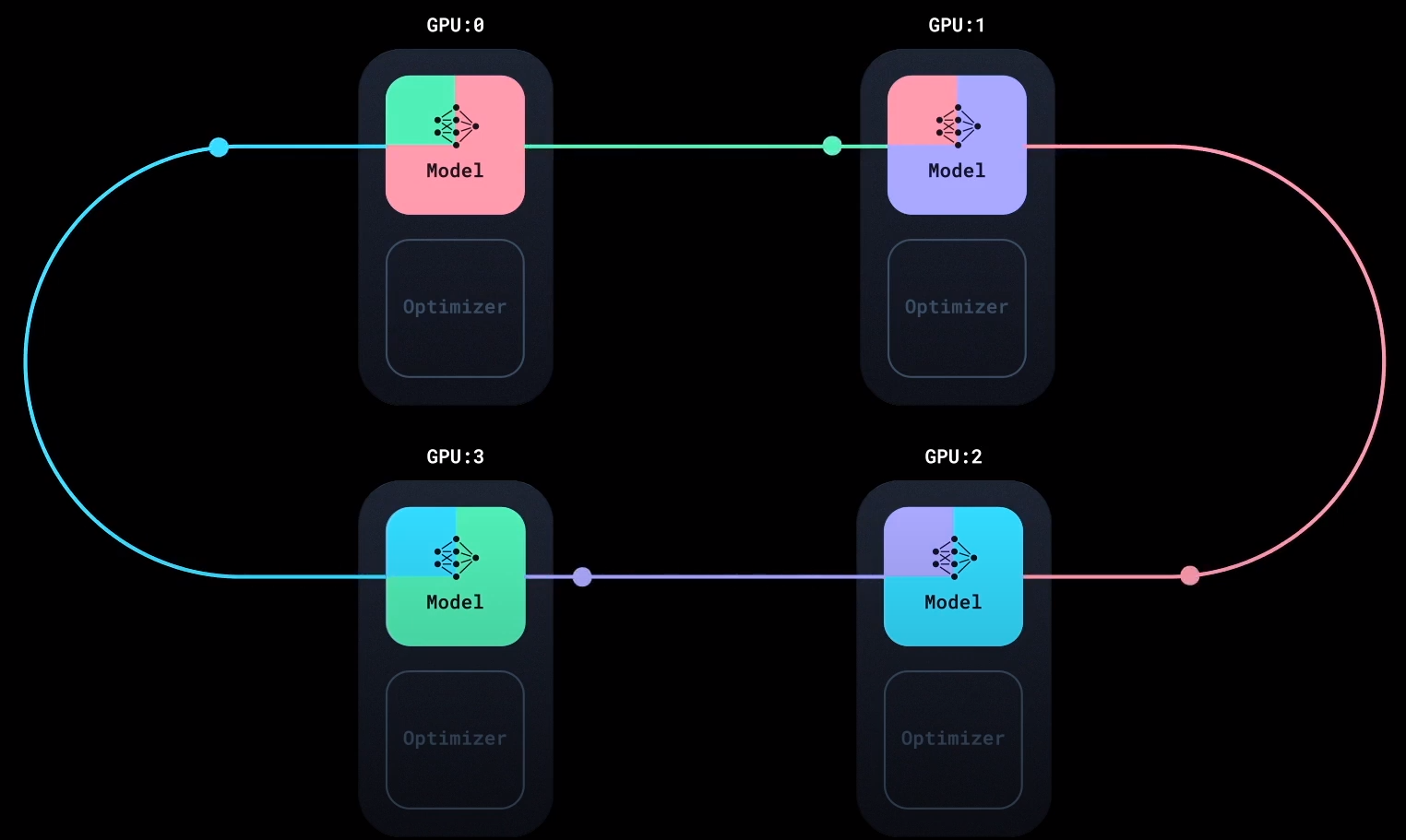
Ring - AllReduce
Ring - AllReduce, 现在Pytorch的分布式数据并行(DDP)用的就是这种实现方式, 用于多机训练场景.
DP中最大的缺点就是在AllReduce中, Server需要和其他所有的Worker通信, 这个通信过程使得每个Worker的计算通信比不高. Server有问题, 那就把所有的通信压力全部转移到Worker上, 人人都是Worker, 人人又都是Server.
Ring-AllReduce将该过程拆分为两个部分, Reduce - Scatter和All - Gather.
Reduce - Scatter
在Reduce - Scatter中, 所有Worker都在拓扑结构上与相邻的两个Worker通信, 因此构成一个拓扑环(Ring):
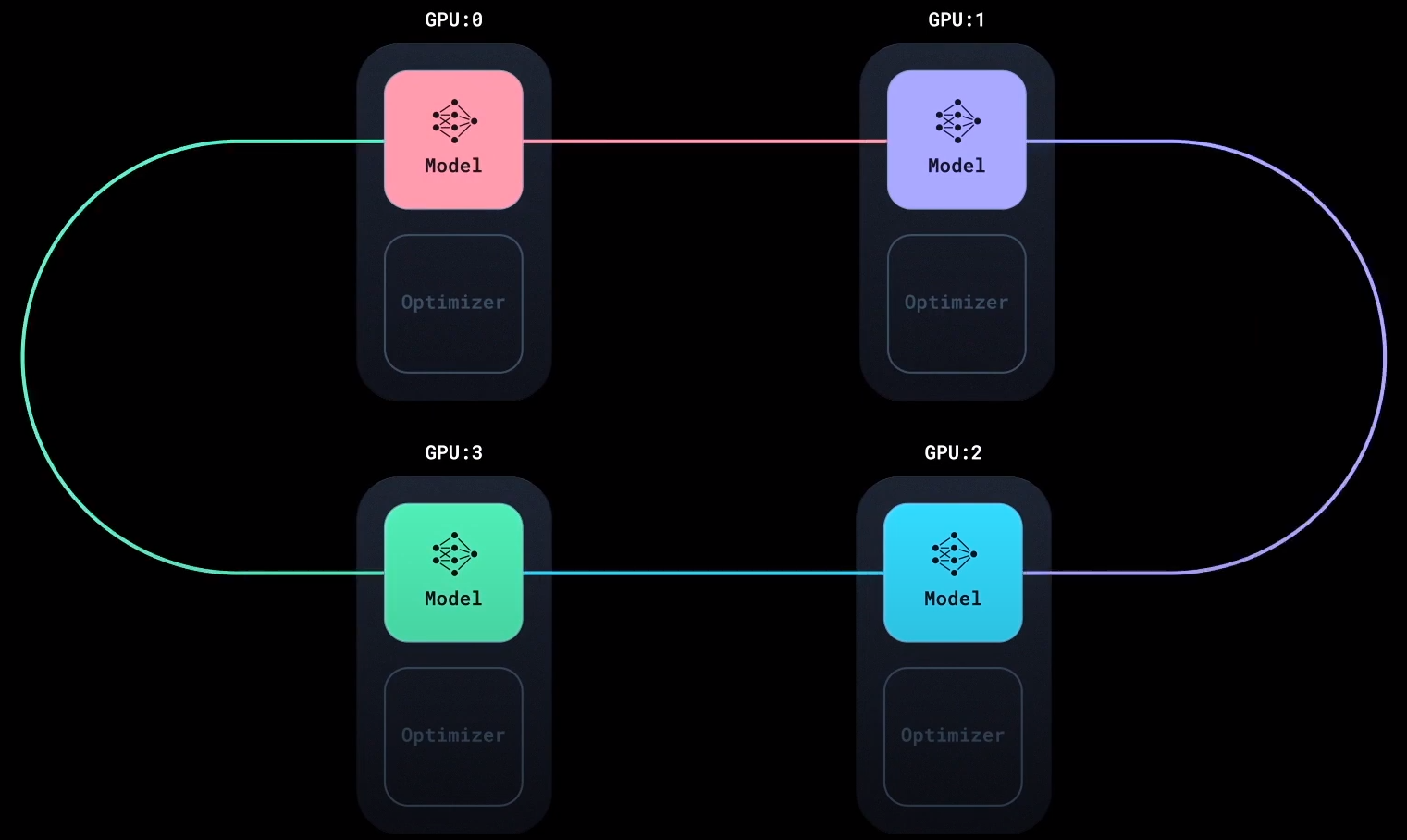
假设一共有$N$ 块GPU, 每块GPU记为$i$, 且$i = 1, 2, \dots, N$. 那么我们把每块GPU上计算得到的梯度拆分为$N$ 份, 称为 $i$ 的 $N$ 个Gradient Chunk $G_i$.
每次通信时, 每块GPU $i$ 都会将自己的某个梯度块 $G_i[i]$ 传递到拓扑环上相邻的下一块GPU $i+1$ 上, 使得下一块GPU的梯度块$G_{i+1}[i] = G_{i+1}[i] + G_i[i]$.
$i$ 同时接收拓扑环中上一块GPU $i-1$ 的某个梯度块$G_{i-1}[i-1]$, 加到自己的对应位置梯度块$G_{i}[i-1]$ 上面, 使得$i$ 的GPU的梯度块$G_{i}[i-1] = G_{i}[i-1] + G_{i-1}[i-1]$:
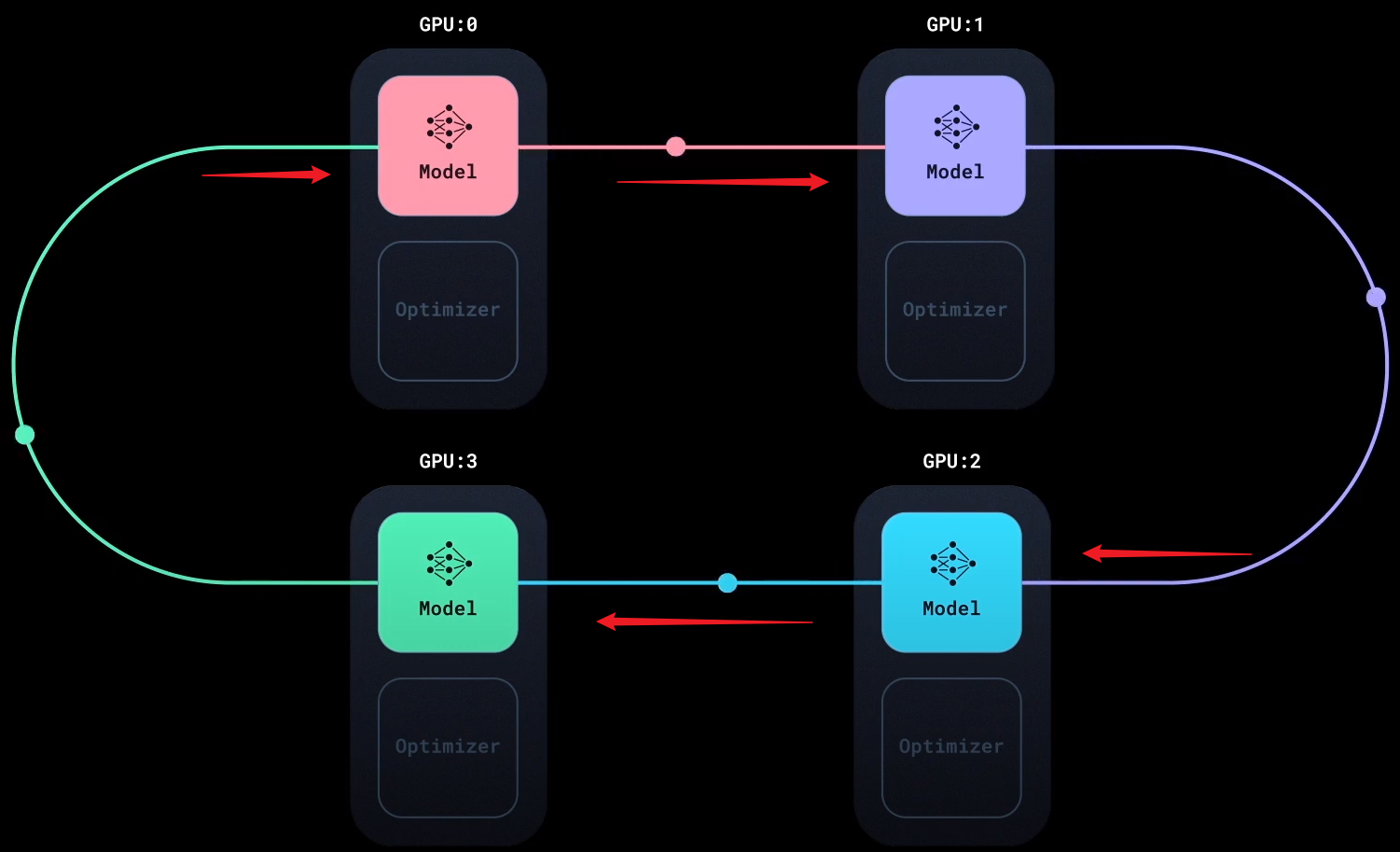
如此反复, 每块GPU都会发送出上次自己接收到梯度块的位置的梯度块到下一个相邻节点, 并接收上个节点送来的梯度块:
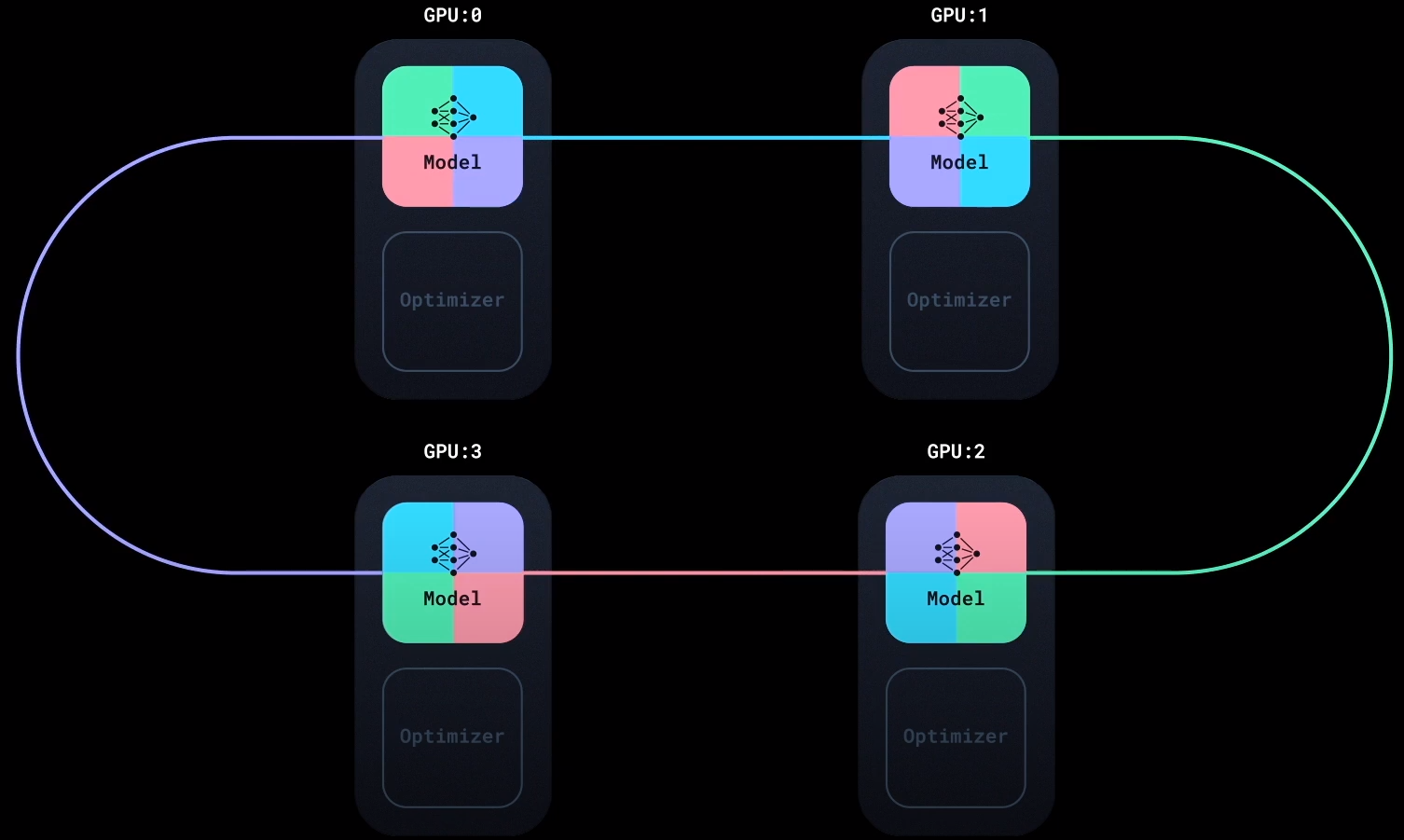
经过$N-1$ 次传递后, 每块GPU上都拥有了一个完整的梯度块, 这个梯度块被累加过$N$ 次, 也就是经过所有GPU运算得到的梯度之和. 即对于每块GPU $i$, 都应有$G[i]=G_{i}[i]= \sum_{j=1}^{N} G_j[i]$.
All - Gather
All - Gather与Reduce - Scatter过程几乎完全一样, 只不过把累加操作变为了直接替换的操作, 将每块GPU上得到的一块”完整的梯度块”发送到拓扑环上下个相邻节点:
同样是经过$N-1$ 次操作后, 每块GPU上便拥有了经过所有数据计算得到的完整梯度:
此时在每块GPU上分别完成模型参数更新.
通信量分析
假设模型参数大小为$\Phi$, 则梯度大小也为$\Phi$, 每个梯度块的大小为$\frac{\Phi}{N}$, 对于单块GPU来说有:
- Reduce - Scatter的通信量为$(N-1)\frac{\Phi}{N}$.
- All - Gather的通信量也为$(N-1)\frac{\Phi}{N}$.
所以单卡通信总量为$2(N-1)\frac{\Phi}{N}$, 当$N \rightarrow \infty$ 时, 全卡通信总量可以近似为$2N\Phi$. 虽然通信量与DP相同, 但Ring - AllReduce把负载均摊到了每个Worker上.
Reduce - Scatter的本质是从通信角度把Server - Worker之间的串行通信变为了Worker之间的并行通信, 同时利用了所有GPU的计算资源.
之所以对每块GPU上的梯度分块就是这个原因, 如果梯度不分块, 又从环退化回了串行通信.
模型并行 Model Parallelism
单卡装不下模型的时候, 最自然的想法就是把模型的各个部分拆分到每个GPU上分别做Forward和Backward, 然后最后再汇总起来:
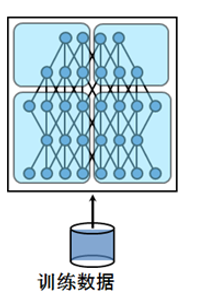
说起来轻巧, 怎么拆呢?
流水线并行 Pipeline Parallelism
最简单的, 按层拆呗, 流水线并行也可以被看做是层间并行. 把模型的所有层分成多份, 分别拆到每块GPU去算. 但是这样在Forward和Backward时都会有问题, 由于模型Forward是顺序串行的, 所以Forward和Backward也是顺序串行的. 即使是这样做了, 还是会存在两个问题:
- 串行导致GPU利用率很低, 大部分时间在空转.
- 随着模型规模的增大, 每块GPU上每层的中间状态的显存开销也非常大. 虽然这个原因不是流水线并行本身导致的, 但它会因模型大小而削弱模型并行所带来的优势.
针对上述两点, 有两种解决办法.
其中一种缓解的方法, 就是把数据并行也引入. 把所有数据再划分为若干个Batch给到GPU训练, 之前的Batch叫做Mini Batch, 那再次划分的Batch叫做Micro Batch.
在引入Micro Batch以后, 每个GPU可以直接进行流水线作业, 将自己的计算结果提交到模型下一层对应的GPU中, 然后再计算下一个Micro Batch的梯度.
另一种解决办法被称为Re - Materialization(Activation Checkpoint), 直接用时间换空间. 几乎不存储中间结果, 除了每块GPU的最终输出, 其余的Activation等到Backward用到的时候直接再让模型Forward一遍就行了.
张量并行 Tensor Parallelism
Megatron是19年遵循张量并行搞出的大模型. 张量并行并不像流水线并行一样, 拆分各层到各块GPU上, 而是对每层里面的矩阵进行拆分, 下放到每块GPU上. 也就是将模型每层操作的一部分放到不同GPU上完成, 所以张量并行也被看做为层间并行. 最基本的有按行切分和按列切分, 并且对于不同的操作, 有不同的切分方式, 在此不详细展开.
ZeRO
请参考:
在数据并行(DP)和分布式数据并行(DDP)中, 都针对通信上负载不均的问题做了优化, 但是仍然没有解决爆显存的问题.
微软的ZeRO 解决了显存上的困难. ZeRO全称为Zero Redundancy Optimizer, 从名字上来看就主要是解决的显存开销, Zero Redundancy.
训练过程中的显存占用主要包含以下几个方面:
- Model State Memory:
- 参数梯度.
- 模型参数.
- 优化器状态. 尤其是Adam这样的优化器, 对于每个参数需要保存Momentum和Variance, 也是大头.
- Activation Memory: 在Forward之后, 通常会保存部分输入输出(Activation)的值, 来方便Backward. 当然这个保存不是必须的, 可以通过重新Forward来再次得到.
- Fragmented Memory: 碎片化存储空间.
由于FP16的计算效率比FP32要高得多, 所以大模型往往是使用混合精度训练的:
- 模型参数$W$ 是FP32, Momentum和Variance也是FP32, 统称为Model States.
- Forward时将FP32的Parameter新建一份FP16备份, 然后用FP16的正常做Forward和Backward. 产生的Activation全部用FP16存储.
- 用FP16的Gradient, 更新FP32的Model States(涉及到Loss Scaling).
最终输出的模型权重应该是FP32而不是FP16.
在权重更新时, 采用FP32而不是FP16, 原因是FP16训练时的精度可能会不够, 容易炸, 特别小的数可能会直接变成0. 而且如果模型参数是FP16而不是FP32, 可能出现参数半天也不变的情况.
根据对混合精度训练的描述, 可以知道模型训练时所需的空间大小, 假设模型参数数量为$\Phi$, 假如以Bytes为单位, 需要的空间如下:
- FP32:
- Parameter: $4\Phi$.
- Momentum: $4\Phi$.
- Variance: $4\Phi$.
- FP16:
- Parameter: $2\Phi$.
- Gradients: $2\Phi$.
总共$16\Phi$, 当然这个值没有包含Activation在内, 因为Activation的存在比较灵活, 所以在此暂不做考虑.
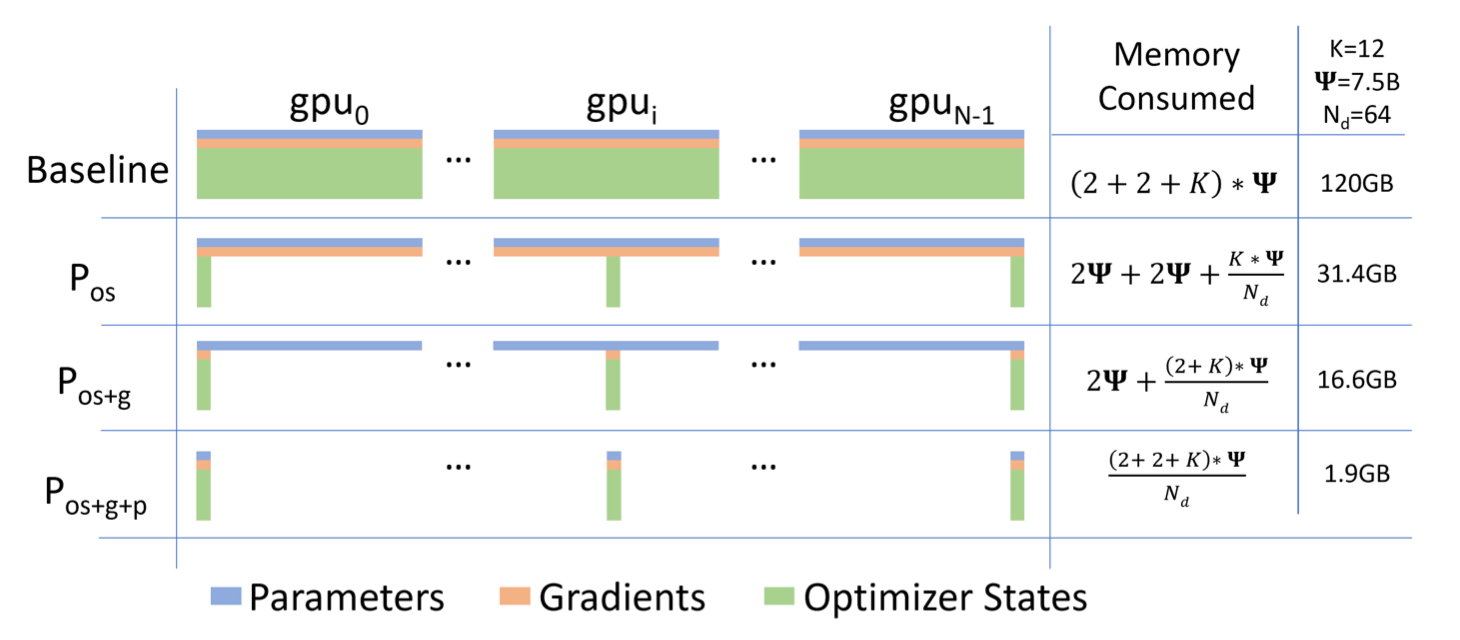
ZeRO - DP
很多States在自己的大多数时间内, 都不会被一直使用, 而是一直拿着, 直到某个被调用的一刻才会用到. ZeRO对这部分States做了优化, 用到时再拿, 而不是一直在每块GPU上拿着.
ZeRO Stage 1
参考Ring - AllReduce, 每块GPU上都有完整的模型参数$W$. 对梯度做一次AllReduce($2\Phi$, 特指单卡通信量, 下同), 所有GPU都能拿到完整的梯度$G$.
在ZeRO Stage 1中, 所有Optimizer States $O$ 被平均拆到了每块GPU上. 模型参数的更新取决于梯度和Optimizer States, 但是现在Optimizer States分布在各块GPU上, 记作$O_i$, 所以只能先结合完整梯度$G$ 来更新一部分模型参数$W_i$, 然后将更新完的这部分$W_i^\prime$ 做一次All - Gather($\Phi$), 所有GPU的模型参数就都是更新完成的了.
ZeRO Stage 2
在Stage 1的基础上, 把梯度也拆分到每块GPU上. 与Ring - AllReduce相似的, 如果每块GPU的最终目标是只维护完整梯度的某一块$G_i$, 那么每块GPU不需要维护除该块以外的梯度, 这是与Ring - AllReduce最大不同的地方, 这节省大量的梯度显存占用.
对梯度做一次Reduce - Scatter($\Phi$), 每块GPU用自己维护的梯度块$G_i$ 来和部分Optimizer States $O_i$ 来更新对应的$W_i \rightarrow W_i^\prime$, 然后再仿照Stage 1的方式将自己更新好的$W^\prime$ 发送出去, 做一次All - Gather($\Phi$), 所有GPU上的参数就都更新完成了.
ZeRO Stage 3
在Stage2的基础上, 模型参数也全部都拆分到每块GPU上, 每块GPU只维护自己的$W_i$. 在做Forward时, 对$W$ 做一次All - Gather($\Phi$), 做完Forward以后立即把不属于自己管理的$W$ 删除.
这样All - Gather并不会导致峰值过高, 做Forward时也可以是分批慢慢做的.
做Backward时, 对$W$ 做All - Gather($\Phi$), 做完以后再删除.
做完Backward以后, 对梯度$G$ 做一次Reduce - Scatter($\Phi$), 以确保自己能拿到自己应该维护的那部分梯度, 聚合后把不属于自己的梯度删除.
之后更新自己应该维护的权重$W_i$, 由于每块GPU只需要维护部分权重$W^\prime$, 所以不需要对$W^\prime$ 再重新All - Gather.
所以其实从ZeRO的Stage1 - 3, 思想都是完全一样的, 不过是分别把Optimizer States, Gradient, Model Parameters分别拆到了每块GPU上, 然后解决它们的通信问题:
ZeRO Stage 3 VS 模型并行
引用原话:
其实ZeRO是模型并行的形式, 数据并行的实质.
模型并行, 是指在Forward和Backward的过程中, 我只需要用自己维护的那块W来计算就行. 即同样的输入X, 每块GPU上各算模型的一部分, 最后通过某些方式聚合结果.
但对ZeRO来说, 它做Forward和Backward的时候, 是需要把各GPU上维护的W聚合起来的, 即本质上还是用完整的W进行计算. 它是不同的输入X, 完整的参数W, 最终再做聚合.
ZeRO - R
ZeRO - R是对模型训练过程中额外产生的内容做的优化, 这个R指的就是Residual States:
- Partitioned Activation Checkpointing: 灵活的存储Activation.
- Constant Size Buffer: 固定内存大小Buffer, 减少GPU之间的通讯次数, 当积攒足够的数据时才进行GPU通讯, 使得带宽利用率更高, 也使得存储大小已知.
- Memory Defragmentation: 对碎片化存储空间重新整合成连续存储空间.
ZeRO-Offload
显存再不够, 实在不行只能扔CPU上了. 因此ZeRO - Offload把Update相关的不需要频繁计算的东西全部扔到了CPU上, 比如FP32的Parameter, FP32的Optimizer States, FP16的Gradient.
剩下Forward和Backward这种频繁需要的部分就全放在GPU上, 比如FP16的Parameter, FP16的Activation.

